คู่มือเริ่มต้นสำหรับ Convolutional Neural Network (CNN)
เผยแพร่แล้ว: 2021-07-05ทศวรรษที่ผ่านมามีการเติบโตอย่างมากในด้านปัญญาประดิษฐ์และเครื่องจักรที่ชาญฉลาดยิ่งขึ้น สาขานี้ได้ก่อให้เกิดสาขาย่อยจำนวนมากที่เชี่ยวชาญด้านความฉลาดของมนุษย์ที่แตกต่างกัน ตัวอย่างเช่น การประมวลผลภาษาธรรมชาติพยายามทำความเข้าใจและสร้างแบบจำลองคำพูดของมนุษย์ ในขณะที่คอมพิวเตอร์วิทัศน์มุ่งหวังที่จะให้การมองเห็นเหมือนมนุษย์กับเครื่องจักร
เนื่องจากเราจะพูดถึง Convolutional Neural Networks ส่วนใหญ่เราจะเน้นที่การมองเห็นด้วยคอมพิวเตอร์ คอมพิวเตอร์วิทัศน์มีจุดมุ่งหมายเพื่อให้เครื่องจักรสามารถมองโลกในขณะที่เราทำและแก้ปัญหาที่เกี่ยวข้องกับการจดจำภาพ การจัดประเภทภาพ และอื่นๆ อีกมากมาย Convolutional Neural Networks ใช้เพื่อบรรลุงานต่างๆ ของการมองเห็นด้วยคอมพิวเตอร์ หรือที่เรียกว่า CNN หรือ ConvNet พวกเขาปฏิบัติตามสถาปัตยกรรมที่คล้ายกับรูปแบบและการเชื่อมต่อของเซลล์ประสาทในสมองของมนุษย์ และได้รับแรงบันดาลใจจากกระบวนการทางชีววิทยาต่างๆ ที่เกิดขึ้นในสมองเพื่อให้การสื่อสารเกิดขึ้น
สารบัญ
ความสำคัญทางชีวภาพของโครงข่ายประสาทเทียมที่ซับซ้อน
CNN ได้รับแรงบันดาลใจจาก Visual Cortex ของเรา เป็นพื้นที่ของเปลือกสมองที่เกี่ยวข้องกับการประมวลผลภาพในสมองของเรา คอร์เทกซ์การมองเห็นมีส่วนต่าง ๆ ของเซลล์ขนาดเล็กที่ไวต่อสิ่งเร้าทางสายตา
แนวคิดนี้ขยายออกไปในปี 1962 โดย Hubel และ Wiesel ในการทดลองซึ่งพบว่าเซลล์ประสาทที่แตกต่างกันตอบสนอง (ถูกไล่ออก) ต่อการมีอยู่ของขอบที่ชัดเจนของการวางแนวที่เฉพาะเจาะจง ตัวอย่างเช่น เซลล์ประสาทบางเซลล์จะยิงเมื่อตรวจจับขอบในแนวนอน ส่วนเซลล์อื่นๆ จะตรวจจับขอบแนวทแยง และบางเซลล์จะยิงเมื่อตรวจพบขอบแนวตั้ง โดยการทดลองครั้งนี้ Hubel และ Wiesel พบว่าเซลล์ประสาทถูกจัดระเบียบในลักษณะโมดูลาร์ และโมดูลทั้งหมดรวมกันจำเป็นสำหรับการสร้างการรับรู้ทางสายตา
วิธีการแบบแยกส่วนนี้ – แนวคิดที่ว่าส่วนประกอบพิเศษภายในระบบมีงานเฉพาะ – คือสิ่งที่เป็นพื้นฐานของซีเอ็นเอ็น
เมื่อตกลงกันแล้ว มาดูวิธีที่ CNN เรียนรู้ที่จะรับรู้ข้อมูลที่ป้อนเข้าด้วยภาพกัน

การเรียนรู้โครงข่ายประสาทเทียม
รูปภาพประกอบด้วยแต่ละพิกเซล ซึ่งเป็นตัวแทนระหว่างตัวเลข 0 ถึง 255 ดังนั้น รูปภาพใดๆ ที่คุณเห็นสามารถแปลงเป็นการแสดงดิจิทัลที่เหมาะสมได้โดยใช้ตัวเลขเหล่านี้ และนั่นคือวิธีที่คอมพิวเตอร์ทำงานกับรูปภาพเช่นกัน
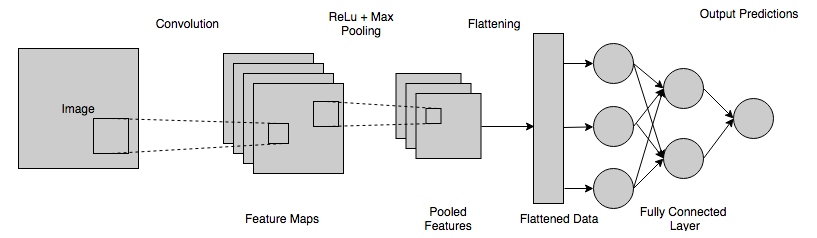
ต่อไปนี้คือการดำเนินการหลักบางประการที่ทำให้ CNN เรียนรู้สำหรับการตรวจจับหรือจำแนกรูปภาพ สิ่งนี้จะทำให้คุณมีแนวคิดว่าการเรียนรู้เกิดขึ้นใน CNN อย่างไร
1. Convolution
Convolution สามารถเข้าใจได้ทางคณิตศาสตร์เมื่อรวมฟังก์ชันที่แตกต่างกันสองฟังก์ชันเข้าด้วยกัน เพื่อค้นหาว่าอิทธิพลของฟังก์ชันที่แตกต่างกันหรือปรับเปลี่ยนกันอย่างไร นี่คือวิธีการกำหนดในทางคณิตศาสตร์:
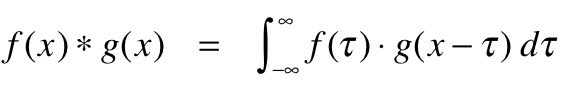
จุดประสงค์ของการบิดคือการตรวจจับลักษณะการมองเห็นต่างๆ ในภาพ เช่น เส้น ขอบ สี เงา และอื่นๆ นี่เป็นพร็อพเพอร์ตี้ที่มีประโยชน์มาก เพราะเมื่อ CNN ของคุณได้เรียนรู้คุณลักษณะของคุณลักษณะเฉพาะในภาพแล้ว จะสามารถรับรู้คุณลักษณะนั้นในส่วนอื่นๆ ของภาพได้ในภายหลัง
ซีเอ็นเอ็นใช้เมล็ดพืชหรือตัวกรองเพื่อตรวจหาคุณลักษณะต่างๆ ที่มีอยู่ในภาพใดๆ เคอร์เนลเป็นเพียงเมทริกซ์ของค่าที่แตกต่างกัน (เรียกว่าน้ำหนักในโลกของ Artificial Neural Networks) ที่ได้รับการฝึกฝนเพื่อตรวจหาคุณลักษณะเฉพาะ ตัวกรองจะเคลื่อนไปทั่วทั้งภาพเพื่อตรวจสอบว่ามีการตรวจพบคุณสมบัติใด ๆ หรือไม่ ตัวกรองดำเนินการบิดเพื่อให้ค่าสุดท้ายที่แสดงถึงความมั่นใจที่มีคุณลักษณะเฉพาะที่มีอยู่
หากมีจุดสนใจในภาพ ผลของการดำเนินการบิดเป็นตัวเลขบวกที่มีค่าสูง หากไม่มีคุณลักษณะนี้ การดำเนินการบิดจะส่งผลให้เป็น 0 หรือตัวเลขที่มีค่าต่ำมาก
มาทำความเข้าใจสิ่งนี้ให้ดีขึ้นโดยใช้ตัวอย่าง ในภาพด้านล่าง ตัวกรองได้รับการฝึกอบรมสำหรับการตรวจจับเครื่องหมายบวก จากนั้น ฟิลเตอร์จะถูกส่งต่อไปยังรูปภาพต้นฉบับ เนื่องจากส่วนหนึ่งของรูปภาพต้นฉบับมีคุณลักษณะเดียวกันกับที่ตัวกรองได้รับการฝึกอบรม ค่าในแต่ละเซลล์ที่มีคุณลักษณะนั้นเป็นจำนวนบวก ในทำนองเดียวกันผลของการดำเนินการบิดก็จะส่งผลให้จำนวนมากเช่นกัน
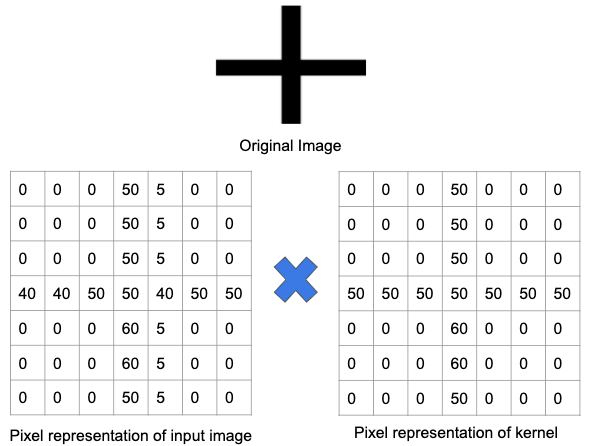
อย่างไรก็ตาม เมื่อฟิลเตอร์เดียวกันถูกส่งผ่านไปยังรูปภาพที่มีชุดคุณลักษณะและขอบต่างกัน ผลลัพธ์ของการดำเนินการบิดจะลดลง ซึ่งหมายความว่าไม่มีเครื่องหมายบวกใดๆ ปรากฏชัดเจนในรูปภาพ
ดังนั้น ในกรณีของรูปภาพที่ซับซ้อนซึ่งมีคุณลักษณะต่างๆ เช่น ส่วนโค้ง ขอบ สี และอื่นๆ เราจำเป็นต้องมีเครื่องตรวจจับคุณลักษณะดังกล่าวจำนวน N
เมื่อฟิลเตอร์นี้ถูกส่งผ่านรูปภาพ จะมีการสร้างแมปคุณลักษณะซึ่งโดยทั่วไปแล้วจะเป็นเมทริกซ์เอาต์พุตที่เก็บการบิดของฟิลเตอร์นี้ไว้ในส่วนต่างๆ ของรูปภาพ ในกรณีของตัวกรองจำนวนมาก เราจะลงเอยด้วยเอาต์พุต 3 มิติ ตัวกรองนี้ควรมีจำนวนช่องสัญญาณเท่ากันกับภาพอินพุตสำหรับการดำเนินการบิด
นอกจากนี้ ตัวกรองสามารถเลื่อนไปบนภาพที่ป้อนในช่วงเวลาต่างๆ โดยใช้ค่าการก้าว ค่าการก้าวแจ้งว่าตัวกรองควรเคลื่อนที่ในแต่ละขั้นตอนมากน้อยเพียงใด
จำนวนของเลเยอร์เอาต์พุตของบล็อกแบบบิดเบี้ยวที่กำหนดสามารถกำหนดได้โดยใช้สูตรต่อไปนี้:

2. แพดดิ้ง
ปัญหาหนึ่งขณะทำงานกับเลเยอร์ที่บิดเบี้ยวคือบางพิกเซลมักจะหายไปในขอบเขตของภาพต้นฉบับ เนื่องจากโดยทั่วไป ตัวกรองที่ใช้มีขนาดเล็ก พิกเซลที่สูญเสียต่อตัวกรองอาจมีจำนวนน้อย แต่สิ่งนี้จะเพิ่มขึ้นเมื่อเราใช้เลเยอร์ที่บิดเบี้ยวที่แตกต่างกัน ส่งผลให้พิกเซลจำนวนมากหายไป
แนวคิดของการเติมเป็นการเพิ่มพิกเซลพิเศษให้กับรูปภาพในขณะที่ตัวกรองของ CNN กำลังประมวลผลอยู่ นี่เป็นวิธีแก้ปัญหาหนึ่งที่ช่วยกรองในการประมวลผลภาพ - โดยการเติมภาพด้วยศูนย์เพื่อให้มีพื้นที่มากขึ้นสำหรับเคอร์เนลเพื่อครอบคลุมทั้งภาพ ด้วยการเพิ่มช่องว่างภายในตัวกรอง ทำให้การประมวลผลภาพโดย CNN มีความแม่นยำและแม่นยำยิ่งขึ้น
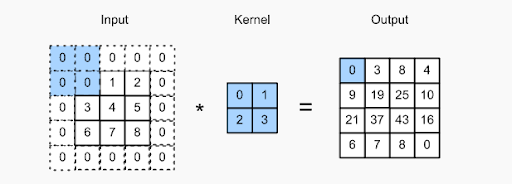

ตรวจสอบรูปภาพด้านบน – ช่องว่างภายในเสร็จสิ้นโดยการเพิ่มศูนย์เพิ่มเติมที่ขอบเขตของรูปภาพที่ป้อน ซึ่งช่วยให้สามารถจับภาพคุณลักษณะที่แตกต่างกันทั้งหมดได้โดยไม่สูญเสียพิกเซล
3. แผนที่การเปิดใช้งาน
แมปคุณลักษณะจะต้องถูกส่งผ่านฟังก์ชันการทำแผนที่ที่ไม่เป็นเชิงเส้น แผนที่คุณลักษณะจะรวมอยู่ในเงื่อนไขอคติแล้วส่งผ่านฟังก์ชันการเปิดใช้งาน (ReLu) ซึ่งไม่เป็นเชิงเส้น ฟังก์ชันนี้มีจุดมุ่งหมายเพื่อนำความไม่เป็นเชิงเส้นจำนวนหนึ่งมาสู่ CNN เนื่องจากภาพที่ตรวจพบและตรวจสอบนั้นมีลักษณะไม่เป็นเชิงเส้นเช่นกัน ซึ่งประกอบด้วยวัตถุต่างๆ
4. เวทีรวม
เมื่อขั้นตอนการเปิดใช้งานสิ้นสุดลง เราจะไปยังขั้นตอนการรวมกลุ่ม โดยที่ CNN จะสุ่มตัวอย่างคุณลักษณะที่เชื่อมโยง ซึ่งช่วยให้ประหยัดเวลาในการประมวลผล นอกจากนี้ยังช่วยลดขนาดโดยรวมของภาพ การใส่มากเกินไป และปัญหาอื่นๆ ที่จะเกิดขึ้นหาก Convoluted Neural Networks ได้รับข้อมูลจำนวนมาก โดยเฉพาะอย่างยิ่งหากข้อมูลนั้นไม่เกี่ยวข้องมากเกินไปในการจำแนกหรือตรวจจับภาพ
การรวมกลุ่มนั้นโดยทั่วไปมีสองประเภท – การรวมสูงสุดและการรวมขั้นต่ำ ในอดีต หน้าต่างจะถูกส่งผ่านไปยังรูปภาพตามค่าการก้าวที่ตั้งไว้ และในแต่ละขั้นตอน ค่าสูงสุดที่รวมอยู่ในหน้าต่างจะถูกรวมไว้ในเมทริกซ์ผลลัพธ์ ในการรวมขั้นต่ำ ค่าต่ำสุดจะถูกรวมเข้าด้วยกันในเมทริกซ์เอาต์พุต
เมทริกซ์ใหม่ที่เกิดขึ้นจากผลลัพธ์เรียกว่าฟีเจอร์แมปแบบรวมกลุ่ม
จากการรวมขั้นต่ำและสูงสุด ข้อดีอย่างหนึ่งของการรวมกันสูงสุดคือช่วยให้ CNN สามารถโฟกัสไปที่เซลล์ประสาทสองสามตัวที่มีค่าสูงแทนที่จะเน้นไปที่เซลล์ประสาททั้งหมด วิธีการดังกล่าวทำให้มีโอกาสน้อยที่จะใส่ข้อมูลการฝึกอบรมมากเกินไปและทำให้การคาดการณ์โดยรวมและลักษณะทั่วไปเป็นไปด้วยดี
5. แฟบ
หลังจากการรวมเสร็จสิ้น การแสดงภาพ 3 มิติของภาพได้ถูกแปลงเป็นเวกเตอร์คุณลักษณะแล้ว จากนั้นจะส่งต่อไปยัง perceptron แบบหลายชั้นเพื่อสร้างผลลัพธ์ ดูภาพด้านล่างเพื่อทำความเข้าใจการดำเนินการแฟบ:
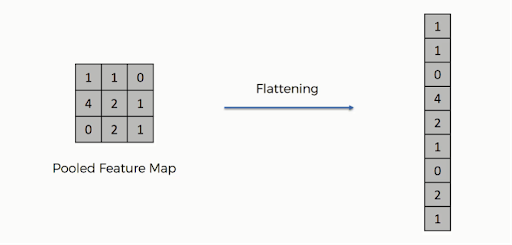
อย่างที่คุณเห็น แถวของเมทริกซ์ถูกต่อกันเป็นเวกเตอร์จุดสนใจเดียว หากมีเลเยอร์อินพุตหลายชั้น แถวทั้งหมดจะเชื่อมต่อกันเพื่อสร้างเวกเตอร์คุณลักษณะที่แบนยาวขึ้น
6. เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ (FCL)
ในขั้นตอนนี้ แผนที่ที่แบนราบจะถูกป้อนไปยังโครงข่ายประสาทเทียม การเชื่อมต่อที่สมบูรณ์ของโครงข่ายประสาทเทียมประกอบด้วยเลเยอร์อินพุต, FCL และเลเยอร์เอาต์พุตสุดท้าย เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์สามารถเข้าใจได้ว่าเป็นเลเยอร์ที่ซ่อนอยู่ในโครงข่ายประสาทเทียม ยกเว้น เลเยอร์เหล่านี้จะเชื่อมต่ออย่างสมบูรณ์ไม่เหมือนกับเลเยอร์ที่ซ่อนอยู่ ข้อมูลจะส่งผ่านเครือข่ายทั้งหมด และคำนวณข้อผิดพลาดในการคาดการณ์ ข้อผิดพลาดนี้จะถูกส่งเป็นข้อเสนอแนะ (backpropagation) ผ่านระบบเพื่อปรับน้ำหนักและปรับปรุงผลลัพธ์สุดท้ายเพื่อให้แม่นยำยิ่งขึ้น
ผลลัพธ์สุดท้ายที่ได้รับจากเลเยอร์ด้านบนของโครงข่ายประสาทเทียมนั้นโดยทั่วไปแล้วจะไม่รวมกันเป็นหนึ่ง ผลลัพธ์เหล่านี้จำเป็นต้องลดจำนวนลงเป็นตัวเลขในช่วง [0,1] ซึ่งจะแสดงถึงความน่าจะเป็นของแต่ละคลาส ด้วยเหตุนี้ จึงใช้ฟังก์ชัน Softmax
เอาต์พุตที่ได้จากเลเยอร์หนาแน่นจะถูกป้อนไปยังฟังก์ชันการเปิดใช้งาน Softmax ด้วยวิธีนี้ ผลลัพธ์สุดท้ายทั้งหมดจะถูกจับคู่กับเวกเตอร์ซึ่งผลรวมขององค์ประกอบทั้งหมดออกมาเป็นหนึ่งเดียว
เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ทำงานโดยดูที่เอาต์พุตของเลเยอร์ก่อนหน้า แล้วพิจารณาว่าฟีเจอร์ใดสัมพันธ์กับคลาสใดคลาสหนึ่งมากที่สุด ดังนั้น หากโปรแกรมคาดการณ์ว่ารูปภาพมีแมวหรือไม่ ก็จะมีค่าสูงในแผนที่การเปิดใช้งานซึ่งแสดงถึงคุณลักษณะต่างๆ เช่น สี่ขา อุ้งเท้า หาง และอื่นๆ ในทำนองเดียวกัน หากโปรแกรมคาดการณ์อย่างอื่น ก็จะมีแผนที่เปิดใช้งานประเภทต่างๆ เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์จะดูแลคุณลักษณะต่างๆ ที่มีความสัมพันธ์อย่างมากกับคลาสและน้ำหนักเฉพาะ เพื่อให้การคำนวณระหว่างตุ้มน้ำหนักและเลเยอร์ก่อนหน้านั้นแม่นยำ และคุณจะได้รับความน่าจะเป็นที่ถูกต้องสำหรับคลาสเอาต์พุตที่แตกต่างกัน
สรุปการทำงานของ CNNs
ต่อไปนี้คือข้อมูลสรุปโดยย่อของกระบวนการทั้งหมดเกี่ยวกับวิธีการทำงานของ CNN และช่วยในการมองเห็นคอมพิวเตอร์:
- พิกเซลที่แตกต่างจากภาพจะถูกป้อนไปยังเลเยอร์ที่เกิดการบิดเบี้ยว
- ขั้นตอนก่อนหน้านี้ส่งผลให้เกิดแผนที่ที่บิดเบี้ยว
- แผนที่นี้ถูกส่งผ่านฟังก์ชันวงจรเรียงกระแสเพื่อสร้างแผนที่ที่ถูกแก้ไข
- ภาพได้รับการประมวลผลด้วยการหมุนวนและฟังก์ชันการเปิดใช้งานที่แตกต่างกันเพื่อระบุตำแหน่งและตรวจจับคุณสมบัติต่างๆ
- เลเยอร์การรวมกลุ่มใช้เพื่อระบุส่วนที่เฉพาะเจาะจงและชัดเจนของรูปภาพ
- เลเยอร์ที่รวมกลุ่มจะถูกทำให้แบนและใช้เป็นอินพุตไปยังเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์
- เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์จะคำนวณความน่าจะเป็นและให้ผลลัพธ์ในช่วง [0,1]
สรุปแล้ว
การทำงานภายในของ CNN นั้นน่าตื่นเต้นมากและเปิดโอกาสมากมายสำหรับนวัตกรรมและการสร้างสรรค์ ในทำนองเดียวกัน เทคโนโลยีอื่นๆ ที่อยู่ภายใต้ปัญญาประดิษฐ์นั้นมีความน่าสนใจและกำลังพยายามทำงานระหว่างความสามารถของมนุษย์กับปัญญาประดิษฐ์ ด้วยเหตุนี้ ผู้คนจากทั่วทุกมุมโลกซึ่งมาจากโดเมนต่างๆ ต่างตระหนักถึงความสนใจในด้านนี้และกำลังดำเนินการตามขั้นตอนแรก
โชคดีที่อุตสาหกรรม AI ยินดีต้อนรับเป็นพิเศษและไม่ได้แยกแยะตามภูมิหลังทางวิชาการของคุณ สิ่งที่คุณต้องมีคือความรู้ด้านเทคโนโลยีพร้อมกับคุณสมบัติพื้นฐาน เท่านี้คุณก็พร้อมแล้ว!
หากคุณต้องการควบคุม ML และ AI ให้เชี่ยวชาญ แนวทางปฏิบัติที่เหมาะสมที่สุดคือการลงทะเบียนในโปรแกรม AI/ML ระดับมืออาชีพ ตัวอย่างเช่น Executive Program in Machine Learning และ AI เป็นหลักสูตรที่สมบูรณ์แบบสำหรับผู้ที่ต้องการวิทยาศาสตร์ข้อมูล โปรแกรมครอบคลุมหัวข้อต่างๆ เช่น สถิติและการวิเคราะห์ข้อมูลเชิงสำรวจ การเรียนรู้ของเครื่อง และการประมวลผลภาษาธรรมชาติ นอกจากนี้ยังมีโครงการอุตสาหกรรมมากกว่า 13 โครงการ เซสชันสดมากกว่า 25 รายการ และโครงการสำคัญ 6 โครงการ ส่วนที่ดีที่สุดเกี่ยวกับหลักสูตรนี้คือคุณจะได้โต้ตอบกับเพื่อนจากทั่วโลก ช่วยอำนวยความสะดวกในการแลกเปลี่ยนความคิดเห็นและช่วยให้ผู้เรียนสร้างความสัมพันธ์ที่ยั่งยืนกับผู้คนจากภูมิหลังที่หลากหลาย ความช่วยเหลือด้านอาชีพแบบ 360 องศาของเราเป็นสิ่งที่คุณต้องการเพื่อให้เป็นเลิศในการเดินทาง ML และ AI ของคุณ!
เป็นผู้นำการปฏิวัติเทคโนโลยีที่ขับเคลื่อนด้วย AI