
ตัวอย่างเครือข่าย Bayesian [พร้อมการแสดงกราฟิก]
เผยแพร่แล้ว: 2021-01-29สารบัญ
บทนำ
ในสถิติ ตัวแบบความน่าจะเป็นใช้เพื่อกำหนดความสัมพันธ์ระหว่างตัวแปรและสามารถใช้ในการคำนวณความน่าจะเป็นของตัวแปรแต่ละตัว ในหลายปัญหามีตัวแปรจำนวนมาก ในกรณีเช่นนี้ ตัวแบบที่มีเงื่อนไขทั้งหมดต้องการข้อมูลจำนวนมากเพื่อครอบคลุมฟังก์ชันความน่าจะเป็นแต่ละกรณีและทุกกรณี ซึ่งอาจทำได้ยากในการคำนวณแบบเรียลไทม์ มีการพยายามหลายครั้งในการลดความซับซ้อนของการคำนวณความน่าจะเป็นแบบมีเงื่อนไข เช่น Naive Bayes แต่ถึงกระนั้น ก็ยังไม่ได้รับการพิสูจน์ว่ามีประสิทธิภาพ เนื่องจากลดตัวแปรหลายตัวลงอย่างมาก
วิธีเดียวคือการพัฒนาโมเดลที่สามารถรักษาการพึ่งพาแบบมีเงื่อนไขระหว่างตัวแปรสุ่มและความเป็นอิสระตามเงื่อนไขในกรณีอื่นๆ สิ่งนี้นำเราไปสู่แนวคิดของ Bayesian Networks เครือข่ายแบบเบย์เหล่านี้ช่วยให้เราเห็นภาพโมเดลความน่าจะเป็นสำหรับแต่ละโดเมนอย่างมีประสิทธิภาพ และเพื่อศึกษาความสัมพันธ์ระหว่างตัวแปรสุ่มในรูปแบบของกราฟที่ใช้งานง่าย
เรียนรู้ หลักสูตร ML จากมหาวิทยาลัยชั้นนำของโลก รับ Masters, Executive PGP หรือ Advanced Certificate Programs เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
Bayesian Networks คืออะไร?
ตามคำจำกัดความ Bayesian Networks เป็นแบบจำลองกราฟิกความน่าจะเป็นประเภทหนึ่งที่ใช้การอนุมานแบบเบย์สำหรับการคำนวณความน่าจะเป็น มันแสดงถึงชุดของตัวแปรและความน่าจะเป็นแบบมีเงื่อนไขด้วย Directed Acyclic Graph (DAG) เหมาะอย่างยิ่งสำหรับการพิจารณาเหตุการณ์ที่เกิดขึ้นและคาดการณ์แนวโน้มที่สาเหตุที่เป็นไปได้หลายประการที่ทราบเป็นปัจจัยสนับสนุน
แหล่งที่มา
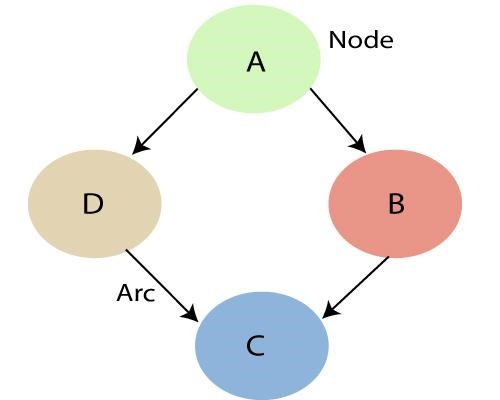
ดังที่กล่าวไว้ข้างต้น โดยการใช้ความสัมพันธ์ที่ระบุโดยเครือข่ายแบบเบย์ เราสามารถรับการแจกแจงความน่าจะเป็นร่วม (JPF) ที่มีความน่าจะเป็นแบบมีเงื่อนไข แต่ละโหนดในกราฟแสดงถึงตัวแปรสุ่ม และส่วนโค้ง (หรือลูกศรชี้ตรง) แสดงถึงความสัมพันธ์ระหว่างโหนด พวกเขาสามารถเป็นได้ทั้งแบบต่อเนื่องหรือไม่ต่อเนื่องในธรรมชาติ

ในแผนภาพด้านบน A, B, C และ D เป็นตัวแปรสุ่ม 4 ตัวที่แสดงโดยโหนดที่กำหนดในเครือข่ายของกราฟ สำหรับโหนด B A คือโหนดหลักและ C คือโหนดย่อย โหนด C เป็นอิสระจากโหนด A
ก่อนที่เราจะเข้าสู่การใช้งาน Bayesian Network มีพื้นฐานความน่าจะเป็นบางประการที่ต้องเข้าใจ
ทรัพย์สิน Markov ในท้องถิ่น
Bayesian Networks ตอบสนองคุณสมบัติที่เรียกว่า Local Markov Property โดยระบุว่าโหนดมีความเป็นอิสระแบบมีเงื่อนไขกับโหนดที่ไม่ใช่ลูกหลานของโหนด เมื่อพิจารณาจากผู้ปกครอง ในตัวอย่างข้างต้น P(D|A, B) เท่ากับ P(D|A) เนื่องจาก D ไม่ขึ้นกับ B ที่ไม่ขึ้นต่อกัน คุณสมบัตินี้ช่วยเราในการทำให้การแจกแจงร่วมง่ายขึ้น Local Markov Property นำเราไปสู่แนวคิดของ Markov Random Field ซึ่งเป็นฟิลด์สุ่มรอบ ๆ ตัวแปรที่กล่าวว่าเป็นไปตามคุณสมบัติของ Markov
ความน่าจะเป็นแบบมีเงื่อนไข
ในวิชาคณิตศาสตร์ ความน่าจะเป็นแบบมีเงื่อนไขของเหตุการณ์ A คือความน่าจะเป็นที่เหตุการณ์ A จะเกิดขึ้นเนื่องจากอีกเหตุการณ์ B ได้เกิดขึ้นแล้ว กล่าวอย่างง่าย p(A | B) คือความน่าจะเป็นของเหตุการณ์ A ที่เกิดขึ้น โดยที่เหตุการณ์นั้น B จะเกิดขึ้น อย่างไรก็ตาม มีความเป็นไปได้ของเหตุการณ์สองประเภทระหว่าง A และ B อาจเป็นเหตุการณ์ที่ขึ้นต่อกันหรือเหตุการณ์อิสระ มีสองวิธีในการคำนวณความน่าจะเป็นแบบมีเงื่อนไข ทั้งนี้ขึ้นอยู่กับประเภท
- ให้ A และ B เป็นเหตุการณ์ที่ไม่ขึ้นต่อกัน ความน่าจะเป็นแบบมีเงื่อนไขจะคำนวณเป็น P (A| B) = P (A และ B) / P (B)
- ถ้า A และ B เป็นเหตุการณ์ที่ไม่ขึ้นต่อกัน นิพจน์สำหรับความน่าจะเป็นแบบมีเงื่อนไขจะได้มาจาก P(A| B) = P (A)
การกระจายความน่าจะเป็นร่วมกัน
ก่อนที่เราจะยกตัวอย่างของ Bayesian Networks ให้เราเข้าใจแนวคิดของ Joint Probability Distribution พิจารณา 3 ตัวแปร a1, a2 และ a3 ตามคำจำกัดความ ความน่าจะเป็นของชุดค่าผสมที่เป็นไปได้ที่แตกต่างกันทั้งหมดของ a1, a2 และ a3 เรียกว่า การแจกแจงความน่าจะเป็นร่วม
ถ้า P[a1,a2, a3,….., an] เป็น JPD ของตัวแปรต่อไปนี้ตั้งแต่ a1 ถึง an แล้ว มีหลายวิธีในการคำนวณการแจกแจงความน่าจะเป็นร่วมโดยเป็นผลรวมของคำศัพท์ต่างๆ เช่น
P[a1,a2, a3,….., an] = P[a1 | a2, a3,….., an] * P[a2, a3,….., an]
= P[a1 | a2, a3,….., อัน] * P[a2 | a3,….., an]….P[an-1|an] * P[an]
สรุปสมการข้างต้น เราสามารถเขียนการแจกแจงความน่าจะเป็นร่วมเป็น
P(X i |X i-1 ,………, X n ) = P(X i |Parents(X i ))
ตัวอย่าง Bayesian Networks
ตอนนี้ให้เราเข้าใจกลไกของ Bayesian Networks และข้อดีของมันด้วยความช่วยเหลือจากตัวอย่างง่ายๆ ในตัวอย่างนี้ ให้ลองจินตนาการว่าเรามีหน้าที่สร้างแบบจำลองคะแนนของนักเรียน ( ม ) สำหรับข้อสอบที่เขาเพิ่งให้ไป จากกราฟเครือข่ายเบย์ที่ให้ไว้ด้านล่าง เราจะเห็นว่าเครื่องหมายนั้นขึ้นอยู่กับตัวแปรอื่นๆ อีก 2 ตัว พวกเขาเป็น,
- ระดับการสอบ ( จ )– ตัวแปรที่ไม่ต่อเนื่องนี้แสดงถึงความยากของการสอบและมีค่าสองค่า (0 สำหรับง่ายและ 1 สำหรับยาก)
- ระดับไอคิว ( ผม ) – แสดงถึงระดับความฉลาดทางปัญญาของนักเรียน และยังมีลักษณะที่ไม่ต่อเนื่องกันโดยมีค่าสองค่า (0 สำหรับค่าต่ำและ 1 สำหรับค่าสูง)
นอกจากนี้ ระดับไอคิวของนักเรียนยังนำเราไปสู่อีกตัวแปรหนึ่ง ซึ่งก็คือคะแนนความถนัดของนักเรียน ( s ) ตอนนี้ ด้วยคะแนนที่นักเรียนทำคะแนนได้ เขาจึงสามารถเข้าศึกษาในมหาวิทยาลัยแห่งใดแห่งหนึ่งได้อย่างปลอดภัย การแจกแจงความน่าจะเป็นสำหรับการเข้าศึกษาในมหาวิทยาลัย ( ก ) แสดงไว้ด้านล่างด้วย

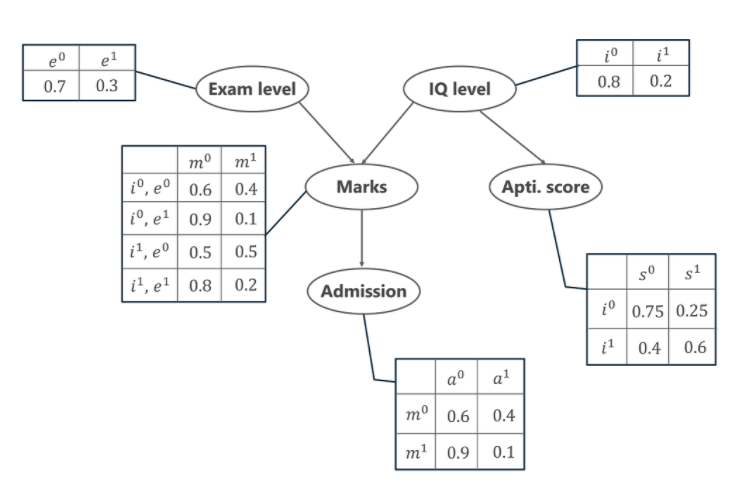
ในกราฟด้านบน เราจะเห็นตารางหลายตารางที่แสดงค่าการกระจายความน่าจะเป็นของตัวแปร 5 ตัวที่ให้มา ตารางเหล่านี้เรียกว่าตารางความน่าจะเป็นแบบมีเงื่อนไขหรือ CPT มีคุณสมบัติบางประการของ CPT ที่ระบุด้านล่าง -
- ผลรวมของค่า CPT ในแต่ละแถวต้องเท่ากับ 1 เนื่องจากกรณีที่เป็นไปได้ทั้งหมดสำหรับตัวแปรหนึ่งๆ มีความครบถ้วนสมบูรณ์ (แสดงถึงความเป็นไปได้ทั้งหมด)
- หากตัวแปรที่มีลักษณะบูลีนมีพาเรนต์บูลีน k ดังนั้นใน CPT ก็จะมีค่าความน่าจะเป็น 2K
กลับมาที่ปัญหาของเราก่อน ให้เราแสดงรายการเหตุการณ์ที่เป็นไปได้ทั้งหมดที่เกิดขึ้นในตารางที่ให้ไว้ด้านบนก่อน
- ระดับการสอบ (จ)
- ระดับไอคิว (i)
- คะแนนความถนัด
- เครื่องหมาย (ม.)
- การรับเข้า (ก)
ตัวแปรทั้งห้านี้แสดงในรูปแบบของ Directed Acyclic Graph (DAG) ในรูปแบบ Bayesian Network พร้อมตารางความน่าจะเป็นแบบมีเงื่อนไข ทีนี้ ในการคำนวณการแจกแจงความน่าจะเป็นร่วมของตัวแปรทั้ง 5 ตัว สูตรจะได้มาจาก
P[a, m, i, e, s]= P(a | m) . พี(ม | ผม อี) . พี(ผม). วิชาพลศึกษา) . P(s | ผม)
จากสูตรข้างต้น
- P(a | m) หมายถึงความน่าจะเป็นแบบมีเงื่อนไขของนักเรียนที่จะเข้าศึกษาตามคะแนนที่เขาทำคะแนนในการสอบ
- P(m | i, e) หมายถึงคะแนนที่นักเรียนจะทำคะแนนตามระดับ IQ และความยากของระดับการสอบ
- P(i) และ P(e) แสดงถึงความน่าจะเป็นของระดับ IQ และระดับการสอบ
- P(s | i) คือความน่าจะเป็นแบบมีเงื่อนไขของคะแนนความถนัดของนักเรียน โดยพิจารณาจากระดับไอคิวของเขา
ด้วยการคำนวณความน่าจะเป็นต่อไปนี้ เราสามารถค้นหาการแจกแจงความน่าจะเป็นร่วมของเครือข่ายเบย์เซียนทั้งหมด
การคำนวณการแจกแจงความน่าจะเป็นร่วม
ให้เราคำนวณ JPD สำหรับสองกรณี
กรณีที่ 1: คำนวณความน่าจะเป็นที่แม้ว่าระดับการสอบจะยาก แต่นักเรียนที่มีระดับไอคิวต่ำและคะแนนความถนัดต่ำก็สามารถผ่านการสอบและเข้าศึกษาในมหาวิทยาลัยได้อย่างปลอดภัย
จากคำกล่าวปัญหาข้างต้น สามารถเขียนการแจกแจงความน่าจะเป็นร่วมได้ดังนี้
P[a=1, m=1, i=0, e=1, s=0]
จากตารางความน่าจะเป็นแบบมีเงื่อนไขด้านบน ค่าสำหรับเงื่อนไขที่กำหนดจะถูกป้อนเข้าสู่สูตรและคำนวณดังนี้
P[a=1, m=1, i=0, e=0, s=0] = P(a=1 | m=1) . พี(ม=1 | ผม=0, อี=1) . พี(i=0) . พี(อี=1) . P(s=0 | ผม=0)
= 0.1 * 0.1 * 0.8 * 0.3 * 0.75
= 0.0018
กรณีที่ 2: ในอีกกรณีหนึ่ง ให้คำนวณความน่าจะเป็นที่นักเรียนจะมีระดับไอคิวสูงและคะแนนความถนัดสูง การสอบนั้นง่ายแต่ไม่ผ่านและไม่รับประกันการเข้าศึกษาต่อในมหาวิทยาลัย
สูตรสำหรับ JPD ถูกกำหนดโดย
P[a=0, m=0, i=1, e=0, s=1]
ดังนั้น,
P[a=0, m=0, i=1, e=0, s=1]= P(a=0 | m=0) . P(m=0 | ผม=1, อี=0) . พี(i=1) . พี(อี=0) . P(s=1 | ผม=1)
= 0.6 * 0.5 * 0.2 * 0.7 * 0.6
= 0.0252
ดังนั้น ด้วยวิธีนี้ เราจึงสามารถใช้ตาราง Bayesian Networks และความน่าจะเป็นในการคำนวณความน่าจะเป็นสำหรับเหตุการณ์ต่างๆ ที่อาจเกิดขึ้นได้
อ่านเพิ่มเติม: แนวคิดและหัวข้อโครงการการเรียนรู้ของเครื่อง
บทสรุป
มีแอปพลิเคชันมากมายสำหรับ Bayesian Networks ในการกรองสแปม การค้นหาเชิงความหมาย การดึงข้อมูล และอื่นๆ อีกมากมาย ตัวอย่างเช่น ด้วยอาการที่กำหนด เราสามารถคาดการณ์ความน่าจะเป็นของโรคที่เกิดขึ้นจากปัจจัยอื่นๆ ที่นำไปสู่โรคได้ ดังนั้น แนวคิดของ Bayesian Network จึงถูกนำเสนอในบทความนี้พร้อมกับการนำไปปฏิบัติด้วยตัวอย่างในชีวิตจริง
หากคุณอยากเชี่ยวชาญด้านการเรียนรู้ของเครื่องและ AI ให้เพิ่มพูนอาชีพของคุณด้วยหลักสูตรขั้นสูงเกี่ยวกับการเรียนรู้ของเครื่องและ AI กับ IIIT-B และมหาวิทยาลัย Liverpool John Moores
เครือข่าย Bayesian มีการใช้งานอย่างไร?
เครือข่ายแบบเบย์คือแบบจำลองกราฟิกที่แต่ละโหนดเป็นตัวแทนของตัวแปรสุ่ม แต่ละโหนดเชื่อมต่อกับโหนดอื่นด้วยส่วนโค้งที่กำหนด แต่ละส่วนโค้งแสดงถึงการแจกแจงความน่าจะเป็นแบบมีเงื่อนไขของผู้ปกครองที่มอบให้เด็ก ขอบตรงแสดงถึงอิทธิพลของผู้ปกครองที่มีต่อลูก โหนดมักจะเป็นตัวแทนของวัตถุในโลกแห่งความเป็นจริงและส่วนโค้งแสดงถึงความสัมพันธ์ทางกายภาพหรือเชิงตรรกะระหว่างกัน เครือข่าย Bayesian ใช้ในแอพพลิเคชั่นมากมาย เช่น การรู้จำคำพูดอัตโนมัติ การจำแนกเอกสาร/รูปภาพ การวินิจฉัยทางการแพทย์ และวิทยาการหุ่นยนต์
เหตุใดเครือข่ายเบย์เซียนจึงมีความสำคัญ
ดังที่เราทราบ เครือข่าย Bayesian เป็นส่วนสำคัญของการเรียนรู้ของเครื่องและสถิติ มันถูกใช้ในการขุดข้อมูลและการค้นพบทางวิทยาศาสตร์ เครือข่ายแบบเบย์คือกราฟอะไซคลิกโดยตรง (DAG) โดยมีโหนดที่เป็นตัวแทนของตัวแปรสุ่มและส่วนโค้งที่แสดงถึงอิทธิพลโดยตรง เครือข่าย Bayesian ใช้ในแอปพลิเคชันต่างๆ เช่น การวิเคราะห์ข้อความ การตรวจหาการฉ้อโกง การตรวจหามะเร็ง การจดจำรูปภาพ เป็นต้น ในบทความนี้ เราจะพูดถึงการใช้เหตุผลในเครือข่ายแบบเบย์ Bayesian Network เป็นเครื่องมือสำคัญสำหรับการวิเคราะห์อดีต การทำนายอนาคต และปรับปรุงคุณภาพของการตัดสินใจ Bayesian Network มีต้นกำเนิดมาจากสถิติ แต่ปัจจุบันนี้ถูกใช้โดยผู้เชี่ยวชาญทุกคน รวมถึงนักวิทยาศาสตร์การวิจัย นักวิเคราะห์การวิจัยการดำเนินงาน วิศวกรอุตสาหการ ผู้เชี่ยวชาญด้านการตลาด ที่ปรึกษาธุรกิจ และแม้แต่ผู้จัดการ
เครือข่ายแบบกระจัดกระจายคืออะไร?
เครือข่ายแบบกระจายแบบเบย์ (SBN) เป็นเครือข่ายแบบเบย์แบบพิเศษที่มีการแจกแจงความน่าจะเป็นแบบมีเงื่อนไขเป็นกราฟแบบกระจาย อาจเหมาะสมที่จะใช้ SBN เมื่อตัวแปรจำนวนมากและ/หรือจำนวนการสังเกตมีน้อย โดยทั่วไปแล้ว Bayesian Networks จะมีประโยชน์มากที่สุดเมื่อคุณสนใจที่จะอธิบายข้อสังเกตหรือเหตุการณ์โดยพิจารณาจากปัจจัยหลายประการ