
6 ฟีเจอร์เปลี่ยนเกมของ Apache Spark ในปี 2022 [คุณควรใช้อย่างไร]
เผยแพร่แล้ว: 2021-01-07นับตั้งแต่ที่ Big Data เข้ามาครอบงำโลกของเทคโนโลยีและธุรกิจ ก็มีเครื่องมือและแพลตฟอร์ม Big Data เพิ่มขึ้นอย่างมาก โดยเฉพาะ Apache Hadoop และ Apache Spark วันนี้เราจะเน้นไปที่ Apache Spark แต่เพียงผู้เดียวและพูดคุยกันในเชิงยาวเกี่ยวกับประโยชน์และแอปพลิเคชันทางธุรกิจ
Apache Spark ได้รับความสนใจอย่างมากในปี 2009 และนับตั้งแต่นั้นมา Apache Spark ก็ค่อยๆ เจาะจงเฉพาะกลุ่มสำหรับตัวเองในอุตสาหกรรมนี้ ตามองค์กร Apache Spark เป็น "เครื่องมือวิเคราะห์แบบรวมศูนย์ที่รวดเร็วทันใจ" ที่ออกแบบมาสำหรับการประมวลผลข้อมูลขนาดใหญ่จำนวนมหาศาล ต้องขอบคุณชุมชนที่กระตือรือร้นในวันนี้ Spark เป็นหนึ่งในแพลตฟอร์ม Big Data แบบโอเพนซอร์สที่ใหญ่ที่สุดในโลก
สารบัญ
Apache Spark คืออะไร?
เดิมทีพัฒนาขึ้นใน AMPlab ของมหาวิทยาลัยแห่งแคลิฟอร์เนีย (Berkeley) Spark ได้รับการออกแบบให้เป็นเครื่องมือประมวลผลที่มีประสิทธิภาพสำหรับข้อมูล Hadoop โดยเน้นที่ความเร็วและความสะดวกในการใช้งานเป็นพิเศษ เป็นทางเลือกโอเพนซอร์ซแทน MapReduce ของ Hadoop โดยพื้นฐานแล้ว Spark เป็นเฟรมเวิร์กการประมวลผลข้อมูลแบบคู่ขนานที่สามารถทำงานร่วมกับ Apache Hadoop เพื่ออำนวยความสะดวกในการพัฒนาแอปพลิเคชัน Big Data ที่ซับซ้อนบน Hadoop ได้อย่างราบรื่นและรวดเร็ว
Spark มาพร้อมกับไลบรารีที่หลากหลายสำหรับอัลกอริธึม Machine Learning (ML) และอัลกอริธึมกราฟ ไม่เพียงแค่นั้น ยังรองรับการสตรีมแบบเรียลไทม์และแอพ SQL ผ่าน Spark Streaming และ Shark ตามลำดับ ส่วนที่ดีที่สุดเกี่ยวกับการใช้ Spark คือคุณสามารถเขียนแอป Spark ใน Java, Scala หรือแม้แต่ Python และแอปเหล่านี้จะทำงานได้เร็วกว่า (บนดิสก์) เกือบสิบเท่าและเร็วกว่าแอป MapReduce 100 เท่า (ในหน่วยความจำ)
Apache Spark ใช้งานได้หลากหลายเนื่องจากสามารถปรับใช้ได้หลายวิธี และยังมีการเชื่อมโยงแบบเนทีฟสำหรับภาษาการเขียนโปรแกรม Java, Scala, Python และ R รองรับ SQL, การประมวลผลกราฟ, การสตรีมข้อมูล และการเรียนรู้ของเครื่อง นี่คือเหตุผลที่ Spark ถูกใช้อย่างกว้างขวางในภาคส่วนต่างๆ ของอุตสาหกรรม รวมถึงธนาคาร บริษัทโทรคมนาคม บริษัทพัฒนาเกม หน่วยงานของรัฐ และแน่นอนในบริษัทชั้นนำทั้งหมดของโลกเทคโนโลยี – Apple, Facebook, IBM และ Microsoft
6 คุณสมบัติที่ดีที่สุดของ Apache Spark
คุณสมบัติที่ทำให้ Spark เป็นหนึ่งในแพลตฟอร์ม Big Data ที่มีการใช้งานอย่างกว้างขวางที่สุด ได้แก่:

1. ความเร็วในการประมวลผลที่รวดเร็ว Lighting
การประมวลผลข้อมูลขนาดใหญ่เป็นเรื่องเกี่ยวกับการประมวลผลข้อมูลที่ซับซ้อนจำนวนมาก ดังนั้น เมื่อพูดถึงการประมวลผล Big Data องค์กรและองค์กรต่างๆ ต้องการเฟรมเวิร์กดังกล่าวที่สามารถประมวลผลข้อมูลจำนวนมหาศาลด้วยความเร็วสูงได้ ดังที่เราได้กล่าวไว้ก่อนหน้านี้ แอป Spark สามารถทำงานได้เร็วขึ้นถึง 100 เท่าในหน่วยความจำและเร็วขึ้น 10 เท่าบนดิสก์ในคลัสเตอร์ Hadoop
โดยอาศัยชุดข้อมูลที่กระจายตัวแบบยืดหยุ่น (RDD) ซึ่งช่วยให้ Spark จัดเก็บข้อมูลในหน่วยความจำอย่างโปร่งใส และอ่าน/เขียนลงในดิสก์ได้เฉพาะในกรณีที่จำเป็นเท่านั้น ซึ่งช่วยลดเวลาในการอ่านและเขียนดิสก์ส่วนใหญ่ระหว่างการประมวลผลข้อมูล
2. ใช้งานง่าย
Spark ให้คุณเขียนแอปพลิเคชันที่ปรับขนาดได้ใน Java, Scala, Python และ R ดังนั้นนักพัฒนาจึงได้รับขอบเขตในการสร้างและเรียกใช้แอปพลิเคชัน Spark ในภาษาการเขียนโปรแกรมที่ต้องการ นอกจากนี้ Spark ยังติดตั้งชุดตัวดำเนินการระดับสูงมากกว่า 80 ตัวในตัว คุณสามารถใช้ Spark แบบโต้ตอบเพื่อสืบค้นข้อมูลจากเชลล์ Scala, Python, R และ SQL
3. รองรับการวิเคราะห์ที่ซับซ้อน
Spark ไม่เพียงแต่สนับสนุนการดำเนินการ "แผนที่" และ "ลด" อย่างง่าย แต่ยังสนับสนุนการสืบค้น SQL, ข้อมูลการสตรีม และการวิเคราะห์ขั้นสูง รวมถึง ML และอัลกอริธึมกราฟ มันมาพร้อมกับไลบรารี่ที่ทรงพลัง เช่น SQL & DataFrames และ MLlib (สำหรับ ML), GraphX และ Spark Streaming สิ่งที่น่าสนใจคือ Spark ให้คุณรวมความสามารถของไลบรารีทั้งหมดเหล่านี้ไว้ในเวิร์กโฟลว์/แอปพลิเคชันเดียว
4. การประมวลผลสตรีมตามเวลาจริง
Spark ออกแบบมาเพื่อรองรับการสตรีมข้อมูลแบบเรียลไทม์ ในขณะที่ MapReduce สร้างขึ้นเพื่อจัดการและประมวลผลข้อมูลที่จัดเก็บไว้ในคลัสเตอร์ Hadoop แล้ว Spark สามารถทำได้ทั้งสองอย่างและจัดการข้อมูลในแบบเรียลไทม์ผ่าน Spark Streaming
Spark Streaming แตกต่างจากโซลูชันการสตรีมอื่น ๆ สามารถกู้คืนงานที่สูญหายและส่งมอบความหมายที่แน่นอนได้ทันทีโดยไม่ต้องใช้โค้ดหรือการกำหนดค่าเพิ่มเติม นอกจากนี้ ยังให้คุณใช้รหัสเดิมซ้ำสำหรับการประมวลผลแบบแบตช์และสตรีม และแม้กระทั่งการรวมข้อมูลสตรีมมิงเข้ากับข้อมูลในอดีต
5. มีความยืดหยุ่น
Spark สามารถทำงานได้อย่างอิสระในโหมดคลัสเตอร์ และยังสามารถทำงานบน Hadoop YARN, Apache Mesos, Kubernetes และแม้แต่ในระบบคลาวด์ นอกจากนี้ยังสามารถเข้าถึงแหล่งข้อมูลที่หลากหลาย ตัวอย่างเช่น Spark สามารถทำงานบนตัวจัดการคลัสเตอร์ YARN และอ่านข้อมูล Hadoop ที่มีอยู่ได้ สามารถอ่านได้จากแหล่งข้อมูล Hadoop เช่น HBase, HDFS, Hive และ Cassandra แง่มุมของ Spark นี้ทำให้เป็นเครื่องมือในอุดมคติสำหรับการโยกย้ายแอปพลิเคชัน Hadoop แท้ ๆ โดยที่กรณีการใช้งานของแอปนั้นเป็นมิตรกับ Spark
6. ชุมชนที่กระตือรือร้นและกำลังขยายตัว
นักพัฒนาจาก กว่า 300 บริษัท มีส่วนร่วมในการออกแบบและสร้าง Apache Spark นับตั้งแต่ปี 2009 นักพัฒนามากกว่า 1200 คนได้มีส่วนร่วมอย่างเต็มที่ในการทำให้ Spark เป็นอย่างที่เป็นอยู่ในปัจจุบัน! โดยธรรมชาติแล้ว Spark ได้รับการสนับสนุนจากชุมชนนักพัฒนาที่กระตือรือร้นซึ่งทำงานเพื่อปรับปรุงคุณลักษณะและประสิทธิภาพอย่างต่อเนื่อง ในการเข้าถึงชุมชน Spark คุณสามารถใช้ รายชื่ออีเมล สำหรับข้อสงสัยใด ๆ และคุณยังสามารถเข้าร่วมกลุ่มมีตติ้งและการประชุมของ Spark ได้อีกด้วย
กายวิภาคของ Spark Applications
แอปพลิเคชัน Spark ทั้งหมดประกอบด้วยสองกระบวนการหลัก – กระบวนการ ไดรเวอร์ หลัก และชุดของ กระบวนการ ดำเนินการ
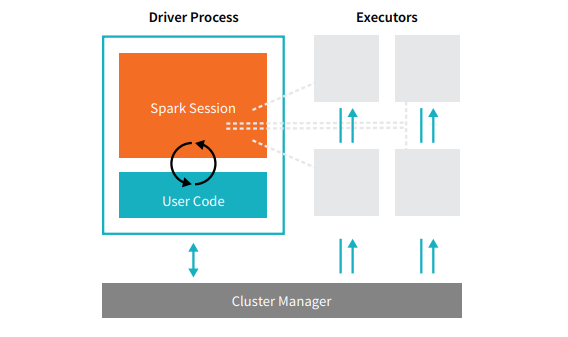

แหล่งที่มา
กระบวนการของไดรเวอร์ที่อยู่บนโหนดในคลัสเตอร์มีหน้าที่ในการเรียกใช้ฟังก์ชัน main() นอกจากนี้ยังจัดการงานอื่นๆ อีกสามงาน – รักษาข้อมูลเกี่ยวกับ Spark Application, ตอบสนองต่อรหัสหรืออินพุตของผู้ใช้, และวิเคราะห์, แจกจ่าย, และจัดกำหนดการงานทั่วทั้งตัวดำเนินการ กระบวนการของไดรเวอร์เป็นหัวใจสำคัญของ Spark Application ซึ่งมีและรักษาข้อมูลที่สำคัญทั้งหมดที่ครอบคลุมอายุการใช้งานของแอปพลิเคชัน Spark
ตัว ดำเนินการหรือกระบวนการ ของตัวดำเนินการ เป็นรายการรองที่ต้องดำเนินงานที่ได้รับมอบหมายจากไดรเวอร์ โดยพื้นฐานแล้ว ผู้ดำเนินการแต่ละรายทำหน้าที่สำคัญสองอย่าง – เรียกใช้โค้ดที่ไดรเวอร์กำหนดและรายงานสถานะของการคำนวณ (บนตัวดำเนินการนั้น) ไปยังโหนดไดรเวอร์ ผู้ใช้สามารถตัดสินใจและกำหนดค่าจำนวนตัวดำเนินการที่แต่ละโหนดควรมี
ในแอปพลิเคชัน Spark ตัวจัดการคลัสเตอร์จะควบคุมเครื่องทั้งหมดและจัดสรรทรัพยากรให้กับแอปพลิเคชัน ในที่นี้ ตัวจัดการคลัสเตอร์สามารถเป็นหนึ่งในตัวจัดการคลัสเตอร์หลักของ Spark ได้ รวมถึง YARN (ตัวจัดการคลัสเตอร์แบบสแตนด์อโลนของ Spark) หรือ Mesos สิ่งนี้ทำให้คลัสเตอร์สามารถเรียกใช้ Spark Applications หลายรายการพร้อมกันได้
แอปพลิเคชัน Apache Spark ในโลกแห่งความเป็นจริง
Spark เป็นแพลตฟอร์ม Big Dara ที่ได้รับคะแนนสูงสุดและใช้กันอย่างแพร่หลายในอุตสาหกรรมสมัยใหม่ ตัวอย่างแอปพลิเคชัน Apache Spark ที่ได้รับการยกย่องในโลกแห่งความเป็นจริง ได้แก่:
จุดประกายสำหรับการเรียนรู้ของเครื่อง
Apache Spark ภูมิใจนำเสนอไลบรารี Machine Learning ที่ปรับขนาดได้ - MLlib ไลบรารีนี้ได้รับการออกแบบมาอย่างชัดเจนเพื่อให้ใช้งานได้ง่าย ปรับขนาดได้ และอำนวยความสะดวกในการผสานรวมกับเครื่องมืออื่นๆ ได้อย่างราบรื่น MLlib ไม่เพียงแต่มีความสามารถในการขยายขนาด ความเข้ากันได้ของภาษา และความเร็วของ Spark เท่านั้น แต่ยังสามารถดำเนินการโฮสต์ของงานการวิเคราะห์ขั้นสูง เช่น การจัดประเภท การจัดกลุ่ม การลดขนาด ต้องขอบคุณ MLlib ที่ทำให้ Spark สามารถใช้สำหรับการวิเคราะห์เชิงคาดการณ์ การวิเคราะห์ความรู้สึก การแบ่งส่วนลูกค้า และข้อมูลคาดการณ์ล่วงหน้า
คุณสมบัติที่น่าประทับใจอีกประการของ Apache Spark อยู่ในโดเมนความปลอดภัยของเครือข่าย Spark Streaming ให้ผู้ใช้ตรวจสอบแพ็กเก็ตข้อมูลตามเวลาจริงก่อนที่จะส่งไปยังที่จัดเก็บ ในระหว่างกระบวนการนี้ จะสามารถระบุกิจกรรมที่น่าสงสัยหรือเป็นอันตรายที่เกิดขึ้นจากแหล่งที่มาของภัยคุกคามได้สำเร็จ แม้ว่าแพ็กเก็ตข้อมูลจะถูกส่งไปยังที่จัดเก็บ Spark ก็ยังใช้ MLlib เพื่อวิเคราะห์ข้อมูลเพิ่มเติมและระบุความเสี่ยงที่อาจเกิดขึ้นกับเครือข่าย คุณลักษณะนี้ยังสามารถใช้สำหรับการตรวจจับการฉ้อโกงและเหตุการณ์
จุดประกายสำหรับ Fog Computing
Apache Spark เป็นเครื่องมือที่ยอดเยี่ยมสำหรับ Fog Computing โดยเฉพาะอย่างยิ่งเมื่อเกี่ยวข้องกับ Internet of Things (IoT) IoT อาศัยแนวคิดของการประมวลผลแบบขนานขนาดใหญ่เป็นอย่างมาก เนื่องจากเครือข่าย IoT ประกอบด้วยอุปกรณ์ที่เชื่อมต่อกันหลายพันเครื่อง ข้อมูลที่สร้างโดยเครือข่ายนี้ในแต่ละวินาทีจึงเกินความเข้าใจ
โดยปกติ ในการประมวลผลข้อมูลปริมาณมากที่ผลิตโดยอุปกรณ์ IoT คุณต้องมีแพลตฟอร์มที่ปรับขนาดได้ซึ่งรองรับการประมวลผลแบบขนาน และจะมีอะไรดีไปกว่าสถาปัตยกรรมที่แข็งแกร่งของ Spark และความสามารถในการคำนวณแบบ Fog เพื่อจัดการกับข้อมูลจำนวนมหาศาล!
Fog Computing จะกระจายข้อมูลและการจัดเก็บข้อมูล และแทนที่จะใช้การประมวลผลแบบคลาวด์ โปรแกรมจะทำหน้าที่ประมวลผลข้อมูลบนขอบเครือข่าย (ส่วนใหญ่ฝังอยู่ในอุปกรณ์ IoT)
ในการทำเช่นนี้ Fog Computing ต้องใช้ความสามารถสามอย่าง ได้แก่ เวลาแฝงต่ำ การประมวลผล ML แบบคู่ขนาน และอัลกอริธึมการวิเคราะห์กราฟที่ซับซ้อน ซึ่งแต่ละอย่างมีอยู่ใน Spark นอกจากนี้ การมีอยู่ของ Spark Streaming, Shark (เครื่องมือสืบค้นแบบโต้ตอบที่สามารถทำงานได้แบบเรียลไทม์), MLlib และ GraphX (เครื่องมือวิเคราะห์กราฟ) ช่วยเพิ่มความสามารถในการคำนวณ Fog ของ Spark
จุดประกายสำหรับการวิเคราะห์เชิงโต้ตอบ
ไม่เหมือนกับ MapReduce หรือ Hive หรือ Pig ที่มีความเร็วในการประมวลผลค่อนข้างต่ำ Spark สามารถอวดการวิเคราะห์เชิงโต้ตอบความเร็วสูงได้ มีความสามารถในการจัดการแบบสอบถามเชิงสำรวจโดยไม่ต้องสุ่มตัวอย่างข้อมูล นอกจากนี้ Spark ยังเข้ากันได้กับภาษาการพัฒนายอดนิยมเกือบทั้งหมด รวมถึง R, Python, SQL, Java และ Scala
เวอร์ชันล่าสุดของ Spark – Spark 2.0 – มีฟังก์ชันการทำงานใหม่ที่เรียกว่าการสตรีมแบบมีโครงสร้าง ด้วยคุณสมบัตินี้ ผู้ใช้สามารถเรียกใช้การสืบค้นที่มีโครงสร้างและโต้ตอบกับข้อมูลการสตรีมในแบบเรียลไทม์
ผู้ใช้ Spark
ตอนนี้คุณทราบดีถึงคุณสมบัติและความสามารถของ Spark แล้ว มาพูดถึงผู้ใช้ที่โดดเด่นสี่คนของ Spark กัน!
1. Yahoo
Yahoo ใช้ Spark สำหรับสองโปรเจ็กต์ โปรเจ็กต์หนึ่งสำหรับปรับแต่งหน้าข่าวสำหรับผู้เยี่ยมชม และอีกโปรเจ็กต์สำหรับเรียกใช้การวิเคราะห์เพื่อการโฆษณา ในการปรับแต่งหน้าข่าว Yahoo ใช้อัลกอริธึม ML ขั้นสูงที่ทำงานบน Spark เพื่อทำความเข้าใจความสนใจ ความชอบ และความต้องการของผู้ใช้แต่ละราย และจัดหมวดหมู่เรื่องราวตามนั้น
สำหรับกรณีการใช้งานครั้งที่สอง Yahoo ใช้ประโยชน์จาก Hive บนความสามารถในการโต้ตอบของ Spark (เพื่อรวมเข้ากับเครื่องมือใดๆ ที่เสียบเข้ากับ Hive) เพื่อดูและค้นหาข้อมูลการวิเคราะห์การโฆษณาของ Yahoo ที่รวบรวมบน Hadoop
2. Uber
Uber ใช้ Spark Streaming ร่วมกับ Kafka และ HDFS เป็น ETL (แยก แปลง และโหลด) ข้อมูลแบบเรียลไทม์จำนวนมหาศาลของเหตุการณ์ที่ไม่ต่อเนื่องเป็นข้อมูลที่มีโครงสร้างและใช้งานได้สำหรับการวิเคราะห์เพิ่มเติม ข้อมูลนี้ช่วยให้ Uber คิดค้นโซลูชันที่ได้รับการปรับปรุงสำหรับลูกค้า

3. Conviva
ในฐานะบริษัทสตรีมมิ่งวิดีโอ Conviva ได้รับฟีดวิดีโอโดยเฉลี่ยมากกว่า 4 ล้านรายการในแต่ละเดือน ซึ่งนำไปสู่การเลิกราของลูกค้าจำนวนมาก ความท้าทายนี้ยิ่งทวีความรุนแรงขึ้นจากปัญหาในการจัดการปริมาณการใช้วิดีโอสด เพื่อต่อสู้กับความท้าทายเหล่านี้อย่างมีประสิทธิภาพ Conviva ใช้ Spark Streaming เพื่อเรียนรู้เงื่อนไขเครือข่ายแบบเรียลไทม์และเพิ่มประสิทธิภาพการรับส่งข้อมูลวิดีโอตามลำดับ ซึ่งช่วยให้ Conviva สามารถมอบประสบการณ์การรับชมที่สม่ำเสมอและมีคุณภาพสูงแก่ผู้ใช้
4. Pinterest
บน Pinterest ผู้ใช้สามารถปักหมุดหัวข้อที่ชื่นชอบได้และเมื่อต้องการในขณะท่องเว็บและโซเชียลมีเดีย เพื่อนำเสนอประสบการณ์ลูกค้าที่เป็นส่วนตัวและดียิ่งขึ้น Pinterest ใช้ความสามารถ ETL ของ Spark เพื่อระบุความต้องการและความสนใจเฉพาะของผู้ใช้แต่ละราย และให้คำแนะนำที่เกี่ยวข้องแก่พวกเขาบน Pinterest
บทสรุป
สรุปได้ว่า Spark เป็นแพลตฟอร์ม Big Data ที่ใช้งานได้หลากหลายมากพร้อมคุณสมบัติที่สร้างขึ้นเพื่อสร้างความประทับใจ เนื่องจากเป็นเฟรมเวิร์กโอเพนซอร์ซ จึงมีการปรับปรุงและพัฒนาอย่างต่อเนื่อง โดยมีการเพิ่มฟีเจอร์และฟังก์ชันใหม่ๆ เข้าไป เนื่องจากแอปพลิเคชันของ Big Data มีความหลากหลายและกว้างขวางมากขึ้น กรณีการใช้งานของ Apache Spark ก็เช่นกัน
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ
ตรวจสอบหลักสูตรวิศวกรรมซอฟต์แวร์อื่นๆ ของเราที่ upGrad