
สถาปัตยกรรม Apache Kafka: คู่มือฉบับสมบูรณ์สำหรับผู้เริ่มต้น [2022]
เผยแพร่แล้ว: 2021-12-23ก่อนที่เราจะเจาะลึกรายละเอียดของสถาปัตยกรรม Apache Kafka จำเป็นต้องให้ความกระจ่างว่าเหตุใด Kafka จึงกลายเป็นหัวข้อข่าวตั้งแต่แรก ในการเริ่มต้น Apache Kafka ส่วนใหญ่พบว่ามีการใช้งานในสถาปัตยกรรมข้อมูลการสตรีมแบบเรียลไทม์สำหรับการวิเคราะห์แบบเรียลไทม์ Kafka's publish-subscribe message system ทนทาน รวดเร็ว ปรับขนาดได้ และทนต่อข้อผิดพลาด มีกรณีการใช้งานสำหรับสิ่งต่างๆ เช่น การติดตามข้อมูลเซ็นเซอร์ IoT หรือการติดตามการเรียกใช้บริการ
บริษัทต่างๆ เช่น LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal และอื่นๆ อีกมากมายใช้ Apache Kafka ในการประมวลผลข้อมูลการสตรีมแบบเรียลไทม์ ตัวอย่างเช่น LinkedIn ซึ่งเป็นแหล่งกำเนิดของ Kafka ใช้เพื่อติดตามตัวชี้วัดการดำเนินงานและข้อมูลกิจกรรม ในทำนองเดียวกัน สำหรับ Netflix แล้ว Apache Kafka เป็นมาตรฐานโดยพฤตินัยสำหรับความต้องการในการส่งข้อความ อีเวนต์ และการประมวลผลสตรีม
เรียนรู้ การฝึกอบรมการพัฒนาซอฟต์แวร์ออนไลน์ จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
ยูทิลิตีของ Apache Kafka ได้รับความนิยมมากขึ้นด้วยความเข้าใจสถาปัตยกรรม Apache Kafka และส่วนประกอบพื้นฐาน เรามาดูรายละเอียดสถาปัตยกรรมของ Kafka กัน
สารบัญ
แนวคิดสถาปัตยกรรมคาฟคาขั้นพื้นฐาน
แนวคิดต่อไปนี้เป็นพื้นฐานในการทำความเข้าใจสถาปัตยกรรม Apache Kafka:
1. หัวข้อ
หัวข้อ Kafka กำหนดช่องทางในการสตรีมข้อมูล ดังนั้นผู้ผลิตจึงเผยแพร่ข้อความในหัวข้อ และผู้บริโภคอ่านข้อความจากหัวข้อที่สมัครรับข้อมูล ไม่มีการจำกัดจำนวนหัวข้อที่สร้างขึ้นภายในคลัสเตอร์ Kafka และชื่อที่ไม่ซ้ำกันจะระบุแต่ละหัวข้อ

2. โบรกเกอร์
โบรกเกอร์คือเซิร์ฟเวอร์ในคลัสเตอร์ Kafka ที่ทำงานเป็นคอนเทนเนอร์และเก็บหลายหัวข้อด้วยพาร์ติชั่นที่แตกต่างกัน รหัสจำนวนเต็มที่ไม่ซ้ำกันจะระบุโบรกเกอร์ในคลัสเตอร์ Kafka และการเชื่อมต่อกับหนึ่งในโบรกเกอร์เหล่านี้หมายถึงการเชื่อมต่อกับทั้งคลัสเตอร์
3. พาร์ติชั่น
หัวข้อ Kafka แบ่งออกเป็นหลายส่วนที่เรียกว่าพาร์ติชั่น พาร์ติชั่นถูกแยกออกตามลำดับและอนุญาตให้ผู้บริโภคหลายรายอ่านข้อมูลจากหัวข้อเฉพาะแบบคู่ขนานกัน พาร์ติชั่นของหัวข้อกระจายไปตามเซิร์ฟเวอร์หลายตัวในคลัสเตอร์ Kafka และแต่ละเซิร์ฟเวอร์จะจัดการข้อมูลและร้องขอพาร์ติชั่นจำนวนมาก ข้อความจะไปถึงนายหน้าและคีย์ และคีย์จะกำหนดพาร์ติชั่นที่ข้อความนั้นจะไป ดังนั้น ข้อความที่มีคีย์เดียวกันจะไปที่พาร์ติชั่นเดียวกัน ในกรณีที่ไม่ได้ระบุคีย์ พาร์ติชั่นจะถูกตัดสินใจตามวิธีการแบบวนซ้ำ
4. แบบจำลอง
ใน Kafka เรพลิกาเปรียบเสมือนการสำรองพาร์ติชั่นเพื่อให้แน่ใจว่าข้อมูลจะไม่สูญหายในกรณีที่มีการปิดระบบหรือความล้มเหลวตามแผน กล่าวอีกนัยหนึ่ง แบบจำลองคือสำเนาของพาร์ติชัน
5. พาร์ทิชันออฟเซ็ต
เนื่องจากข้อความหรือเร็กคอร์ดใน Kafka ถูกกำหนดให้กับพาร์ติชั่น แต่ละเร็กคอร์ดจึงมีออฟเซ็ตเพื่อระบุตำแหน่งภายในพาร์ติชั่น ดังนั้น ค่าออฟเซ็ตที่เชื่อมโยงกับเร็กคอร์ดช่วยในการระบุตัวตนได้ง่ายภายในพาร์ติชั่น พาร์ติชั่นออฟเซ็ตมีความหมายภายในพาร์ติชั่นนั้น ๆ เท่านั้น และเนื่องจากเร็กคอร์ดถูกเพิ่มไปยังพาร์ติชั่นที่สิ้นสุด เร็กคอร์ดที่เก่ากว่าจะมีค่าออฟเซ็ตต่ำกว่า
6. ผู้ผลิต
ผู้ผลิต Kafka เผยแพร่ข้อความไปยังหัวข้ออย่างน้อยหนึ่งหัวข้อและส่งข้อมูลไปยังคลัสเตอร์ Kafka ทันทีที่ผู้ผลิตเผยแพร่ข้อความไปยังหัวข้อ Kafka นายหน้าจะได้รับข้อความและเพิ่มไปยังพาร์ติชันเฉพาะ จากนั้นผู้ผลิตสามารถเลือกพาร์ติชั่นที่ต้องการเผยแพร่ข้อความได้
7. ผู้บริโภคและกลุ่มผู้บริโภค
ผู้บริโภคอ่านข้อความจากคลัสเตอร์ Kafka เมื่อผู้บริโภคพร้อมที่จะรับข้อความ ข้อมูลจะถูกดึงออกจากนายหน้า ผู้บริโภคอยู่ในกลุ่มผู้บริโภค และผู้บริโภคแต่ละรายภายในกลุ่มใดกลุ่มหนึ่งมีหน้าที่อ่านส่วนย่อยของพาร์ติชั่นของทุกหัวข้อที่สมัครรับข้อมูล
8. ผู้นำและผู้ตาม
ทุกพาร์ติชั่น Kafka มีหนึ่งเซิร์ฟเวอร์ที่เล่นเป็นผู้นำ ผู้นำดำเนินการอ่านและเขียนทั้งหมดสำหรับพาร์ติชันนั้นโดยเฉพาะ ในทางกลับกัน งานของผู้ตามคือการจำลองข้อมูลของผู้นำ เมื่อผู้นำในพาร์ติชั่นเฉพาะล้มเหลว หนึ่งในโหนดผู้ติดตามจะรับบทบาทผู้นำ พาร์ติชันสามารถมีผู้ติดตามได้ไม่มากหรือน้อย
ไดอะแกรมต่อไปนี้เป็นการนำเสนอแบบง่ายของความสัมพันธ์ระหว่างส่วนประกอบสถาปัตยกรรม Apache Kafka ที่กล่าวถึงข้างต้น
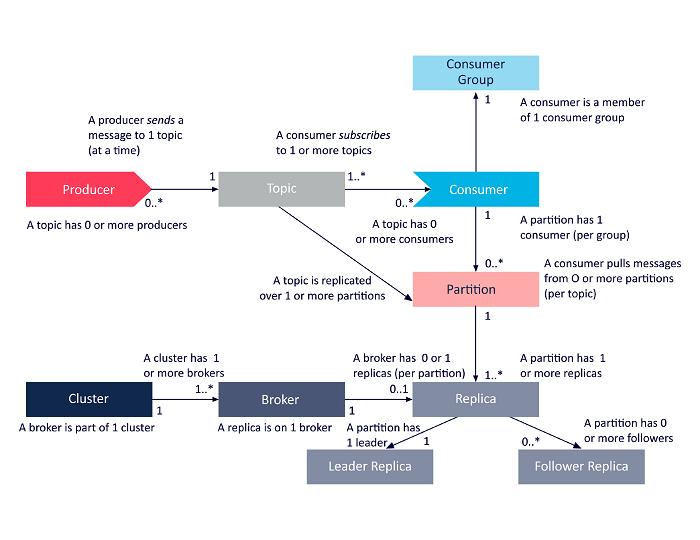
แหล่งที่มา
สถาปัตยกรรมคลัสเตอร์ Apache Kafka
ต่อไปนี้เป็นรายละเอียดเกี่ยวกับส่วนประกอบทางสถาปัตยกรรมหลักของ Kafka:

1. โบรกเกอร์คาฟคา
คลัสเตอร์ Kafka มักประกอบด้วยหลายโหนดที่เรียกว่าโบรกเกอร์ โบรกเกอร์จะรักษาสมดุลของภาระงาน โบรกเกอร์ Kafka แต่ละรายสามารถอ่านและเขียนได้หลายแสนครั้งทุกวินาที นายหน้าทำหน้าที่เป็นผู้นำสำหรับพาร์ติชั่นหนึ่งโดยเฉพาะ ผู้นำมีผู้ติดตามหนึ่งรายหรือหลายราย โดยข้อมูลบนผู้นำจะทำซ้ำตามผู้ติดตามของพาร์ติชันนั้น
ผู้ติดตามจำเป็นต้องอัปเดตข้อมูลของผู้นำอยู่เสมอ ในทางกลับกัน ผู้นำจะติดตามผู้ติดตามที่สอดคล้องกับมัน ถ้าผู้ติดตามไม่ทันกับผู้นำหรือไม่มีชีวิตอยู่แล้ว จะถูกลบออกจากรายการแบบจำลองที่ซิงก์ที่เชื่อมโยงกับผู้นำรายนั้น ผู้นำคนใหม่จะได้รับเลือกจากผู้ติดตามเมื่อผู้นำเสียชีวิต และ ZooKeeper จะดูแลการเลือกตั้ง เนื่องจากโบรกเกอร์ไม่มีสัญชาติ ZooKeeper จึงคงสถานะคลัสเตอร์ไว้ โหนดในคลัสเตอร์จะส่งข้อความฮาร์ตบีตไปยัง ZooKeeper เพื่อแจ้งว่าโหนดเหล่านี้ยังมีชีวิตอยู่
2. ผู้ผลิตคาฟคา
ผู้ผลิต Kafka จะส่งข้อมูลโดยตรงไปยังโบรกเกอร์ที่มีบทบาทเป็นผู้นำสำหรับพาร์ติชั่นเฉพาะ โบรกเกอร์หรือโหนดของคลัสเตอร์ Kafka ช่วยให้ผู้ผลิตส่งข้อความโดยตรง พวกเขาทำเช่นนั้นโดยตอบคำขอสำหรับข้อมูลเมตาที่เซิร์ฟเวอร์ยังมีชีวิตอยู่และสถานะสดของผู้นำพาร์ติชันของหัวข้อ ทำให้ผู้ผลิตสามารถกำหนดคำขอตามนั้นได้ ผู้ผลิตตัดสินใจว่าต้องการเผยแพร่ข้อความในพาร์ติชันใด ข้อความใน Kafka จะถูกส่งเป็นชุด เรียกว่าชุดบันทึก ผู้ผลิตรวบรวมข้อความในหน่วยความจำและส่งเป็นชุดหลังจากผ่านระยะเวลาที่กำหนดหรือหลังจากสะสมข้อความจำนวนหนึ่ง
3. ผู้บริโภคคาฟคา
ผู้บริโภคของ Kafka ออกคำขอไปยังนายหน้าเพื่อระบุพาร์ติชั่นที่ต้องการใช้ ลูกค้าระบุพาร์ติชั่นออฟเซ็ตในคำขอและรับชิ้นส่วนของบันทึก (เริ่มจากตำแหน่งออฟเซ็ต) จากนายหน้า บันทึกประกอบด้วยระเบียนสำหรับช่วงเวลาที่กำหนดได้ซึ่งเรียกว่าระยะเวลาเก็บรักษา
ผู้บริโภคยังสามารถใช้ข้อมูลซ้ำได้ตราบเท่าที่บันทึกมีข้อมูล ผู้บริโภคของ Kafka ทำงานโดยใช้วิธีการดึงข้อมูล ซึ่งหมายความว่านายหน้าจะไม่ส่งข้อมูลไปยังผู้บริโภคทันที อันดับแรก ผู้บริโภคส่งคำขอไปยังนายหน้าเพื่อส่งสัญญาณว่าพวกเขาพร้อมที่จะใช้ข้อมูล ดังนั้นระบบดึงข้อมูลช่วยให้มั่นใจได้ว่าผู้บริโภคจะไม่ถูกครอบงำด้วยข้อความและสามารถติดตามได้หากพวกเขาล้าหลัง
ต่อไปนี้เป็นไดอะแกรมสถาปัตยกรรม Apache Kafka แบบง่าย:
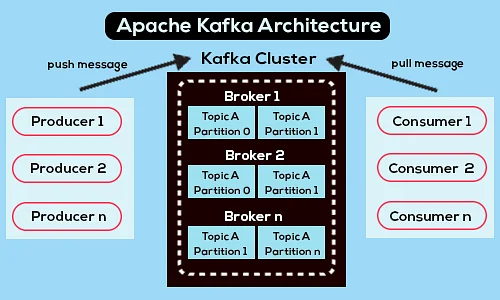
แหล่งที่มา
เรียนรู้เพิ่มเติมเกี่ยวกับ Apache Kafka
สถาปัตยกรรม Apache Kafka API
Apache Kafka มี API หลักสี่ตัว ได้แก่ Streams API, Connector API, Producer API และ Consumer API มาดูกันว่าแต่ละบทบาทต้องมีบทบาทอย่างไรในการเพิ่มความสามารถของ Apache Kafka:
1. สตรีม API
Streams API ของ Kafka อนุญาตให้แอปพลิเคชันประมวลผลข้อมูลโดยใช้อัลกอริธึมการประมวลผลสตรีม เมื่อใช้ Streams API แอปพลิเคชันสามารถใช้อินพุตสตรีมจากหัวข้อเดียวหรือหลายหัวข้อ ประมวลผลด้วยการทำงานของสตรีม สร้างเอาต์พุตสตรีม และส่งไปยังหัวข้ออย่างน้อยหนึ่งหัวข้อในที่สุด ดังนั้น Streams API จึงอำนวยความสะดวกในการแปลงสตรีมอินพุตเป็นเอาต์พุตสตรีม
2. ตัวเชื่อมต่อ API
Connector API ของ Kafka มีประโยชน์สำหรับการสร้าง รัน และจัดการผู้ผลิตและผู้บริโภคที่ใช้ซ้ำได้ ซึ่งเชื่อมโยงหัวข้อ Kafka กับระบบข้อมูลหรือแอปพลิเคชันที่มีอยู่ ตัวอย่างเช่น ตัวเชื่อมต่อไปยังฐานข้อมูลเชิงสัมพันธ์สามารถบันทึกการอัปเดตทั้งหมด และทำให้แน่ใจว่าการเปลี่ยนแปลงนั้นพร้อมใช้งานในหัวข้อ Kafka

3. ผู้ผลิต API
Producer API ของ Kafka อนุญาตให้แอปพลิเคชันเผยแพร่สตรีมของระเบียนไปยังหัวข้อ Kafka
4. API ของผู้บริโภค
Consumer API ของ Kafka อนุญาตให้แอปพลิเคชันสมัครรับข้อมูลจากหัวข้อ Kafka นอกจากนี้ยังช่วยให้แอปพลิเคชันประมวลผลสตรีมบันทึกที่ผลิตในหัวข้อ Kafka เหล่านั้น
ทางข้างหน้า
สถาปัตยกรรม Apache Kafka เป็นเพียงส่วนเล็กๆ ของเครื่องมือและภาษาที่นักพัฒนาซอฟต์แวร์จัดการ สมมติว่าคุณเป็นนักพัฒนาซอฟต์แวร์รุ่นใหม่ที่มีความสนใจในบิ๊กดาต้า ในกรณีนั้น คุณสามารถก้าวแรกสู่เป้าหมายได้ด้วย โปรแกรม Executive PG ของ upGrad ในการพัฒนาซอฟต์แวร์ – ความเชี่ยวชาญเฉพาะด้านใน Big Data
นี่คือภาพรวมของโปรแกรมพร้อมไฮไลท์สำคัญบางประการ:
- Executive PGP จาก IIIT Bangalore พร้อมใบรับรอง Data Science และ Cloud Infrastructure
- เซสชันออนไลน์และการบรรยายสดพร้อมเนื้อหามากกว่า 400 ชั่วโมง
- 7+ กรณีศึกษาและโครงการ
- ภาษาและเครื่องมือการเขียนโปรแกรมมากกว่า 14 ภาษา
- การสนับสนุนอาชีพ 360 องศา
- เครือข่ายเพียร์และอุตสาหกรรม
ลงทะเบียนเพื่อดูรายละเอียดเพิ่มเติม เกี่ยวกับหลักสูตร!
คาฟคาใช้สำหรับอะไร?
Apache Kafka ส่วนใหญ่จะใช้สำหรับการสร้างไปป์ไลน์ข้อมูลการสตรีมแบบเรียลไทม์และแอปพลิเคชันที่ปรับให้เข้ากับสตรีมข้อมูลเหล่านั้น อนุญาตให้จัดเก็บและวิเคราะห์ข้อมูลแบบเรียลไทม์และในอดีตผ่านการส่งข้อความ ที่เก็บข้อมูล และการประมวลผลสตรีม
Kafka เป็นกรอบงานหรือไม่?
Apache Kafka เป็นซอฟต์แวร์โอเพ่นซอร์สที่มีกรอบงานสำหรับการจัดเก็บ อ่าน และวิเคราะห์ข้อมูลการสตรีม เนื่องจากเป็นโอเพ่นซอร์ส Kafka จึงใช้งานได้ฟรีกับนักพัฒนาและผู้ใช้จำนวนมากที่มีส่วนร่วมในคุณลักษณะใหม่ การอัปเดต และการสนับสนุนสำหรับผู้ใช้ใหม่
ทำไมเราถึงต้องการสตรีม Kafka?
Kafka Streams เป็นไลบรารีไคลเอนต์สำหรับสร้างไมโครเซอร์วิสและแอปพลิเคชันการสตรีมที่ข้อมูลอินพุตและเอาต์พุตถูกเก็บไว้ในคลัสเตอร์ Apache Kafka ในด้านหนึ่ง มันให้ประโยชน์ของเทคโนโลยีคลัสเตอร์ฝั่งเซิร์ฟเวอร์ของ Apache Kafka ในอีกทางหนึ่ง มันช่วยลดความยุ่งยากในการเขียนและปรับใช้แอปพลิเคชัน Scala และ Java มาตรฐานบนฝั่งไคลเอ็นต์