
Apache Kafka: สถาปัตยกรรม แนวคิด คุณลักษณะ & แอปพลิเคชัน
เผยแพร่แล้ว: 2021-03-09Kafka เปิดตัวในปี 2011 ขอบคุณ LinkedIn ตั้งแต่นั้นมา ก็เห็นการเติบโตอย่างไม่น่าเชื่อจนถึงจุดที่บริษัทส่วนใหญ่ที่ติดอันดับ Fortune 500 ใช้งานอยู่ในขณะนี้ เป็นผลิตภัณฑ์ที่สามารถปรับขนาดได้สูง ทนทาน และให้ปริมาณงานสูง ซึ่งสามารถรองรับข้อมูลการสตรีมจำนวนมากได้ แต่นั่นเป็นเหตุผลเดียวที่อยู่เบื้องหลังความนิยมอย่างมากหรือไม่? ดีไม่มี เรายังไม่ได้เริ่มใช้ฟีเจอร์ คุณภาพที่ผลิต และความง่ายที่มอบให้กับผู้ใช้
เราจะดำดิ่งลงไปในภายหลัง ก่อนอื่นมาทำความเข้าใจว่า Kafka คืออะไรและใช้ที่ไหน
สารบัญ
Apache Kafka คืออะไร?
Apache Kafka เป็นซอฟต์แวร์ประมวลผลสตรีมแบบโอเพ่นซอร์สที่มีเป้าหมายเพื่อให้มีปริมาณงานสูงและความหน่วงแฝงต่ำในขณะที่จัดการข้อมูลแบบเรียลไทม์ Kafka เขียนด้วยภาษา Java และ Scala มอบความทนทานผ่านไมโครเซอร์วิสในหน่วยความจำ และมีบทบาทสำคัญในการรักษาเหตุการณ์การจัดหาให้กับ Complex Event Streaming Services หรือที่เรียกว่า CEP หรือระบบอัตโนมัติ
เป็นระบบกระจายที่ป้องกันข้อผิดพลาดและใช้งานได้หลากหลาย ซึ่งช่วยให้บริษัทต่างๆ เช่น Uber สามารถจัดการการจับคู่ผู้โดยสารและคนขับได้ นอกจากนี้ยังให้ข้อมูลตามเวลาจริงและการบำรุงรักษาเชิงรุกสำหรับผลิตภัณฑ์บ้านอัจฉริยะของ British Gas นอกเหนือจากการช่วย LinkedIn ในการติดตามบริการแบบเรียลไทม์ที่หลากหลาย
มักใช้ในสถาปัตยกรรมข้อมูลการสตรีมแบบเรียลไทม์เพื่อนำเสนอการวิเคราะห์แบบเรียลไทม์ Kafka เป็นระบบการส่งข้อความที่รวดเร็ว ทนทาน ปรับขนาดได้ และเผยแพร่และสมัครรับข้อมูล Apache Kafka สามารถใช้แทน MOM แบบเดิมได้ เนื่องจากมีความเข้ากันได้ดีเยี่ยมและสถาปัตยกรรมที่ยืดหยุ่น ซึ่งช่วยให้สามารถติดตามการเรียกใช้บริการหรือข้อมูลเซ็นเซอร์ IoT
Kafka ทำงานได้อย่างยอดเยี่ยมกับ Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink และ Apache Spark สำหรับการนำเข้า การวิจัย การวิเคราะห์ และการประมวลผลข้อมูลการสตรีมแบบเรียลไทม์ ตัวกลางของ Kafka ยังอำนวยความสะดวกในการรายงานติดตามผลที่มีความหน่วงแฝงต่ำใน Hadoop หรือ Spark Kafka ยังมีโครงการย่อยที่ชื่อว่า Kafka Stream ซึ่งทำงานเป็นเครื่องมือที่มีประสิทธิภาพสำหรับการวิเคราะห์แบบเรียลไทม์

สถาปัตยกรรมและส่วนประกอบคาฟคา
Kafka ใช้สำหรับสตรีมข้อมูลแบบเรียลไทม์ไปยังระบบผู้รับหลายราย Kafka ทำงานเป็นเลเยอร์กลางสำหรับการแยกไปป์ไลน์ข้อมูลแบบเรียลไทม์ ไม่พบการใช้งานมากในการคำนวณโดยตรง เข้ากันได้มากที่สุดกับระบบการป้อนช่องทางที่รวดเร็ว แบบเรียลไทม์หรือตามข้อมูลการปฏิบัติงาน เพื่อสตรีมข้อมูลจำนวนมากสำหรับการวิเคราะห์ข้อมูลแบบกลุ่ม
เฟรมเวิร์ก Storm, Flink, Spark และ CEP คือระบบข้อมูลบางส่วนที่ Kafka ทำงานด้วยเพื่อบรรลุผลการวิเคราะห์แบบเรียลไทม์ สร้างการสำรองข้อมูล การตรวจสอบ และอื่นๆ นอกจากนี้ยังสามารถรวมเข้ากับแพลตฟอร์มข้อมูลขนาดใหญ่หรือระบบฐานข้อมูล เช่น RDBMS และ Cassandra, Spark เป็นต้น เพื่อการประมวลข้อมูล การรายงาน และอื่นๆ
แผนภาพด้านล่างแสดงระบบนิเวศของ Kafka:
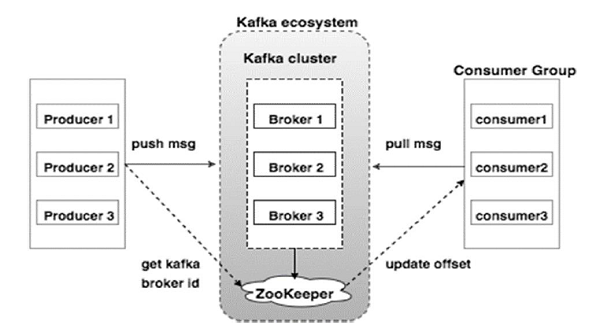
แหล่งที่มา
ต่อไปนี้คือองค์ประกอบต่างๆ ของระบบนิเวศ Kafka ตามที่แสดงในแผนภาพสถาปัตยกรรม Kafka:
1. นายหน้าคาฟคา
Kafka จำลองคลัสเตอร์ที่ประกอบด้วยเซิร์ฟเวอร์หลายเครื่อง ซึ่งแต่ละเครื่องเรียกว่า "โบรกเกอร์" การสื่อสารระหว่างไคลเอนต์และเซิร์ฟเวอร์เป็นไปตามโปรโตคอล TCP ที่มีประสิทธิภาพสูง ประกอบด้วยนายหน้าไร้สัญชาติมากกว่าหนึ่งรายเพื่อรองรับการบรรทุกหนัก โบรกเกอร์ Kafka รายเดียวสามารถจัดการการอ่านและเขียนได้หลาย lacs ทุก ๆ วินาทีโดยไม่กระทบต่อประสิทธิภาพ พวกเขาใช้ ZooKeeper เพื่อรักษาคลัสเตอร์และเลือกหัวหน้านายหน้า
2. ผู้ดูแลสวนสัตว์คาฟคา
ดังที่ได้กล่าวไว้ข้างต้น ZooKeeper มีหน้าที่จัดการโบรกเกอร์ Kafka การเพิ่มหรือความล้มเหลวของนายหน้าในระบบนิเวศ Kafka จะถูกส่งไปยังผู้ผลิตหรือผู้บริโภคผ่านทาง ZooKeeper
3. ผู้ผลิตคาฟคา
พวกเขามีหน้าที่ในการส่งข้อมูลไปยังโบรกเกอร์ ผู้ผลิตไม่ต้องพึ่งพานายหน้าเพื่อรับทราบการรับข้อความ แต่พวกเขากำหนดว่านายหน้าสามารถจัดการและส่งข้อความตามนั้นได้มากน้อยเพียงใด

4. ผู้บริโภคคาฟคา
เป็นความรับผิดชอบของผู้บริโภค Kafka ในการบันทึกจำนวนข้อความที่ใช้โดยการแบ่งพาร์ติชัน การยอมรับข้อความแสดงว่าข้อความที่ส่งก่อนที่จะถูกใช้ไป เพื่อให้แน่ใจว่านายหน้ามีบัฟเฟอร์ไบต์พร้อมที่จะส่งไปยังผู้บริโภค ผู้บริโภคจะเริ่มต้นคำขอดึงแบบอะซิงโครนัส ZooKeeper มีบทบาทในการรักษาค่าออฟเซ็ตของการข้ามหรือกรอกลับข้อความ
กลไกของ Kafka เกี่ยวข้องกับการส่งข้อความระหว่างแอปพลิเคชันในระบบแบบกระจาย Kafka ใช้บันทึกการกระทำ ซึ่งเมื่อสมัครรับข้อมูลเพื่อเผยแพร่ข้อมูลที่มีอยู่ในแอปพลิเคชันการสตรีมที่หลากหลาย ผู้ส่งส่งข้อความถึง Kafka ในขณะที่ผู้รับได้รับข้อความจากสตรีมที่เผยแพร่โดย Kafka
ข้อความถูกรวบรวมเป็นหัวข้อ — คาฟคาพิจารณาอย่างมีประสิทธิผล หัวข้อที่กำหนดแสดงถึงการจัดระเบียบข้อมูลตามประเภทหรือการจัดประเภทเฉพาะ ผู้ผลิตเขียนข้อความให้ผู้บริโภคอ่านโดยอิงตามหัวข้อ
ทุกหัวข้อจะได้รับชื่อเฉพาะ ข้อความใด ๆ จากหัวข้อที่กำหนดที่ส่งโดยผู้ส่งจะได้รับโดยผู้ใช้ทั้งหมดที่ปรับแต่งหัวข้อนั้น เมื่อเผยแพร่แล้ว ข้อมูลในหัวข้อจะไม่สามารถอัปเดตหรือแก้ไขได้
คุณสมบัติของคาฟคา
- Kafka ประกอบด้วยบันทึกการคอมมิตถาวรที่ให้คุณสมัครใช้งาน แล้วเผยแพร่ข้อมูลไปยังหลายระบบหรือแอปพลิเคชันแบบเรียลไทม์
- ทำให้แอปพลิเคชันสามารถควบคุมข้อมูลดังกล่าวได้ Streams API ใน Apache Kafka เป็นไลบรารี่ทรงพลังและน้ำหนักเบาที่อำนวยความสะดวกในการประมวลผลข้อมูลแบบแบตช์ทันที
- เป็นแอปพลิเคชัน Java ที่ให้คุณควบคุมเวิร์กโฟลว์ของคุณและลดความต้องการในการบำรุงรักษาลงอย่างมาก
- Kafka ทำหน้าที่เป็น "ที่เก็บข้อมูลความจริง" ซึ่งกระจายข้อมูลไปยังหลาย ๆ โหนดโดยเปิดใช้งานการปรับใช้ข้อมูลผ่านระบบข้อมูลหลายระบบ
- บันทึกการกระทำของ Kafka ทำให้เป็นระบบจัดเก็บข้อมูลที่เชื่อถือได้ Kafka สร้างแบบจำลอง/สำรองของพาร์ติชันซึ่งช่วยป้องกันข้อมูลสูญหาย (การกำหนดค่าที่ถูกต้องอาจทำให้ข้อมูลสูญหายเป็นศูนย์) นอกจากนี้ยังป้องกันความล้มเหลวของเซิร์ฟเวอร์และเพิ่มความทนทานของ Kafka
- หัวข้อใน Kafka มีพาร์ติชั่นเป็นพันๆ พาร์ติชั่น ทำให้สามารถรองรับปริมาณข้อมูลได้ตามอำเภอใจและการโหลดจำนวนมาก
- Kafka ขึ้นอยู่กับเคอร์เนล OS เพื่อย้ายข้อมูลอย่างรวดเร็ว คลัสเตอร์ของข้อมูลเหล่านี้เข้ารหัสตั้งแต่ต้นทางถึงปลายทาง ผู้ผลิตต่อระบบไฟล์ถึงผู้ใช้ปลายทาง
- การรวมกลุ่มใน Kafka ทำให้ประสิทธิภาพการบีบอัดข้อมูลและลดเวลาแฝงของ I/O
การประยุกต์ใช้ Kafka
บริษัทจำนวนมากที่จัดการกับข้อมูลจำนวนมากในแต่ละวันใช้ Kafka

- LinkedIn ใช้ Kafka เพื่อติดตามกิจกรรมของผู้ใช้และตัวชี้วัดประสิทธิภาพ Twitter รวมเข้ากับ Storm เพื่อเปิดใช้งานเฟรมเวิร์กการประมวลผลสตรีม
- Square ใช้ Kafka เพื่ออำนวยความสะดวกในการเคลื่อนย้ายเหตุการณ์ของระบบทั้งหมดไปยังศูนย์ข้อมูล Square อื่นๆ ซึ่งรวมถึงบันทึก เหตุการณ์ที่กำหนดเอง และเมตริก
- บริษัทยอดนิยมอื่นๆ ที่ใช้ประโยชน์จาก Kafka ได้แก่ Netflix, Spotify, Uber, Tumblr, CloudFlare และ PayPal
ทำไมคุณควรเรียนรู้ Apache Kafka?
Kafka เป็น แพลตฟอร์มการสตรีมเหตุการณ์ ที่ยอดเยี่ยม ที่สามารถจัดการ ติดตาม และตรวจสอบข้อมูลแบบเรียลไทม์ได้อย่างมีประสิทธิภาพ สถาปัตยกรรม ที่ทนทานต่อข้อผิดพลาดและปรับขนาดได้ช่วยให้สามารถรวมข้อมูลที่มีความหน่วงแฝงต่ำ ส่งผลให้มีอัตราการส่งข้อมูลสูงสำหรับเหตุการณ์การสตรีม Kafka ลด "เวลาต่อมูลค่า" ของข้อมูลลงอย่างมาก
มันทำงานเป็นระบบพื้นฐานที่สร้างข้อมูลให้กับองค์กรโดยกำจัด "บันทึก" เกี่ยวกับข้อมูล ซึ่งช่วยให้นักวิทยาศาสตร์ข้อมูลและผู้เชี่ยวชาญสามารถเข้าถึงข้อมูลได้อย่างง่ายดายทุกเวลา
ด้วยเหตุผลเหล่านี้ มันจึงเป็นแพลตฟอร์มสตรีมมิ่งยอดนิยมสำหรับบริษัทชั้นนำหลายแห่ง ดังนั้น ผู้สมัครที่มีคุณสมบัติใน Apache Kafka จึงเป็นที่ต้องการอย่างสูง
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับ Kafka, Big Data คุณควรตรวจสอบ PG Diploma in Software Development Specialization in Big Data ของ upGrad ที่มีกรณีศึกษาและโครงการมากกว่า 7 รายการและการให้คำปรึกษาจากคณาจารย์และผู้เชี่ยวชาญในอุตสาหกรรมระดับโลก โปรแกรม 13 เดือนครอบคลุม 14 ภาษาการเขียนโปรแกรมและสอนการประมวลผลข้อมูล, MapReduce, คลังข้อมูล, การประมวลผลแบบเรียลไทม์, การประมวลผลข้อมูลขนาดใหญ่บนคลาวด์ และทักษะอื่นๆ
ตรวจสอบหลักสูตรวิศวกรรมซอฟต์แวร์อื่นๆ ของเราที่ upGrad