
UI ทางเลือกเสียงสำหรับผู้ช่วยเสียง
เผยแพร่แล้ว: 2022-03-10สำหรับคนส่วนใหญ่ สิ่งแรกที่นึกถึงเมื่อนึกถึงอินเทอร์เฟซผู้ใช้ด้วยเสียงคือผู้ช่วยเสียง เช่น Siri, Amazon Alexa หรือ Google Assistant อันที่จริง ผู้ช่วยเป็นเพียงบริบทเดียวที่คนส่วนใหญ่เคยใช้เสียงเพื่อโต้ตอบกับระบบคอมพิวเตอร์
ในขณะที่ผู้ช่วยเสียงได้นำ ส่วนติดต่อผู้ใช้เสียง มาสู่กระแสหลัก กระบวนทัศน์ผู้ช่วยไม่ได้เป็นเพียงวิธีเดียว หรือแม้แต่วิธีที่ดีที่สุดในการใช้ ออกแบบ และสร้างส่วนต่อประสานผู้ใช้เสียง
ในบทความนี้ ฉันจะพูดถึงปัญหาที่ผู้ช่วยเสียงประสบและนำเสนอแนวทางใหม่สำหรับอินเทอร์เฟซผู้ใช้เสียงที่ฉันเรียกว่าการโต้ตอบด้วยเสียงโดยตรง
ผู้ช่วยเสียงเป็นแชทบอทด้วยเสียง
ผู้ช่วยเสียงเป็นซอฟต์แวร์ชิ้นหนึ่งที่ใช้ภาษาธรรมชาติแทนไอคอนและเมนูเป็นส่วนติดต่อผู้ใช้ ผู้ช่วยมักจะตอบคำถามและมักจะพยายามช่วยเหลือผู้ใช้ในเชิงรุก
แทนที่จะใช้ธุรกรรมและคำสั่งที่ตรงไปตรงมา ผู้ช่วยจะเลียนแบบการสนทนาของมนุษย์ และใช้ภาษาธรรมชาติแบบสองทิศทางเป็นรูปแบบการโต้ตอบ ซึ่งหมายความว่าทั้งสองรับข้อมูลจากผู้ใช้และคำตอบไปยังผู้ใช้โดยใช้ภาษาธรรมชาติ
ผู้ช่วยคนแรกคือระบบตอบคำถามตามบทสนทนา ตัวอย่างแรกคือ Clippy ของ Microsoft ที่พยายามช่วยเหลือผู้ใช้ Microsoft Office อย่างน่าอับอายด้วยการให้คำแนะนำตามสิ่งที่คิดว่าผู้ใช้พยายามทำให้สำเร็จ ทุกวันนี้ กรณีการใช้งานทั่วไปสำหรับกระบวนทัศน์ผู้ช่วยคือแชทบอท ซึ่งมักใช้สำหรับการสนับสนุนลูกค้าในการสนทนาทางแชท
ผู้ช่วยเสียงเป็นแชทบอทที่ ใช้เสียงแทนการพิมพ์และข้อความ การป้อนข้อมูลของผู้ใช้ไม่ใช่การเลือกหรือข้อความ แต่เป็นคำพูดและการตอบสนองจากระบบก็จะพูดออกมาดัง ๆ ด้วย ผู้ช่วยเหล่านี้อาจเป็นผู้ช่วยทั่วไป เช่น Google Assistant หรือ Alexa ที่สามารถตอบคำถามมากมายด้วยวิธีที่เหมาะสม หรือผู้ช่วยที่กำหนดเองซึ่งสร้างขึ้นเพื่อวัตถุประสงค์พิเศษ เช่น การสั่งอาหารจานด่วน
แม้ว่าบ่อยครั้งที่ข้อมูลที่ผู้ใช้ป้อนเข้ามาเป็นเพียงคำหรือสองคำ และสามารถนำเสนอเป็นการเลือกแทนที่จะเป็นข้อความจริง เมื่อเทคโนโลยีพัฒนาขึ้น การสนทนาก็จะ ปลายเปิดและซับซ้อน มากขึ้น คุณลักษณะที่กำหนดประการแรกของแชทบอทและผู้ช่วยคือการใช้ภาษาธรรมชาติและรูปแบบการสนทนาแทนไอคอน เมนู และรูปแบบธุรกรรมที่กำหนดประสบการณ์ผู้ใช้แอปบนอุปกรณ์เคลื่อนที่หรือเว็บไซต์โดยทั่วไป
การอ่านที่แนะนำ : การ สร้าง AI Chatbot อย่างง่ายด้วย Web Speech API และ Node.js
การกำหนดลักษณะที่สองที่มาจากการตอบสนองของภาษาธรรมชาติคือภาพลวงตาของบุคคล น้ำเสียง คุณภาพ และภาษาที่ระบบใช้กำหนดทั้งประสบการณ์ของผู้ช่วย ภาพลวงตาของการเอาใจใส่และความอ่อนไหวต่อการบริการ และบุคลิกของมัน แนวคิดเกี่ยวกับประสบการณ์การเป็นผู้ช่วยที่ดีก็เหมือนกับ การได้มีส่วนร่วมกับบุคคล จริงๆ
เนื่องจากเสียงเป็นวิธีที่เป็นธรรมชาติที่สุดสำหรับเราในการสื่อสาร การทำเช่นนี้อาจฟังดูยอดเยี่ยม แต่มีปัญหาสำคัญสองประการเกี่ยวกับการใช้การตอบกลับด้วยภาษาที่เป็นธรรมชาติ หนึ่งในปัญหาเหล่านี้ ซึ่งเกี่ยวข้องกับคอมพิวเตอร์สามารถเลียนแบบมนุษย์ได้ดีเพียงใด อาจได้รับการแก้ไขในอนาคตด้วยการพัฒนา เทคโนโลยี AI เชิงสนทนา แต่ปัญหาที่ว่าสมองของมนุษย์จัดการกับข้อมูลอย่างไรนั้นเป็นปัญหาของมนุษย์ ซึ่งไม่สามารถแก้ไขได้ในอนาคตอันใกล้ มาดูปัญหาเหล่านี้กันต่อไป
สองปัญหากับการตอบสนองภาษาธรรมชาติ
อินเทอร์เฟซผู้ใช้เสียงเป็นอินเทอร์เฟซผู้ใช้ที่ใช้เสียงเป็นกิริยาช่วย แต่รูปแบบเสียงสามารถใช้ได้ทั้งสองทิศทาง: สำหรับการป้อนข้อมูลจากผู้ใช้และการส่งออกข้อมูลจากระบบกลับไปยังผู้ใช้ ตัวอย่างเช่น ลิฟต์บางตัวใช้การสังเคราะห์เสียงพูดเพื่อยืนยันการเลือกของผู้ใช้หลังจากที่ผู้ใช้กดปุ่ม เราจะพูดถึงส่วนต่อประสานผู้ใช้แบบเสียงที่ใช้เฉพาะเสียงในการป้อนข้อมูล และใช้อินเทอร์เฟซผู้ใช้แบบกราฟิกแบบเดิมเพื่อแสดงข้อมูลกลับไปยังผู้ใช้
ในทางกลับกัน Voice Assistant ใช้เสียงสำหรับทั้งอินพุตและเอาต์พุต วิธีการนี้มีปัญหาหลักสองประการ:
ปัญหา #1: การเลียนแบบมนุษย์ล้มเหลว
ในฐานะมนุษย์ เรามีความโน้มเอียงโดยกำเนิดที่จะระบุคุณลักษณะที่เหมือนมนุษย์กับวัตถุที่ไม่ใช่มนุษย์ เราเห็นลักษณะของผู้ชายในก้อนเมฆที่ลอยผ่านหรือดูแซนวิชและดูเหมือนว่ากำลังยิ้มให้เรา สิ่งนี้เรียกว่า มานุษยวิทยา

ปรากฏการณ์นี้ใช้กับผู้ช่วยด้วย และเกิดขึ้นจากการตอบสนองทางภาษาตามธรรมชาติ แม้ว่าอินเทอร์เฟซผู้ใช้แบบกราฟิกสามารถสร้างได้ค่อนข้างเป็นกลาง แต่ก็ไม่มีทางที่มนุษย์จะไม่สามารถคิดได้ว่าเสียงของใครบางคนเป็นของคนหนุ่มสาวหรือคนชรา หรือว่าพวกเขาเป็นชายหรือหญิง ด้วยเหตุนี้ผู้ใช้จึงเริ่มคิดว่าผู้ช่วยเป็นมนุษย์จริงๆ
อย่างไรก็ตาม มนุษย์เราเก่งใน การตรวจจับของปลอม น่าแปลกที่ยิ่งมีบางสิ่งที่คล้ายกับมนุษย์มากเท่าใด ความเบี่ยงเบนเล็กๆ น้อยๆ ก็เริ่มรบกวนเรามากขึ้นเท่านั้น มีความรู้สึกน่าขนลุกต่อบางสิ่งที่พยายามทำตัวให้เหมือนมนุษย์แต่ไม่สามารถเทียบเคียงได้ ในหุ่นยนต์และแอนิเมชั่นคอมพิวเตอร์ นี่เรียกว่า "หุบเขาลึกลับ"

ยิ่งเราพยายามทำให้ผู้ช่วยดีขึ้นและเป็นมนุษย์มากขึ้นเท่าไร ประสบการณ์ผู้ใช้ที่น่าขนลุกและน่าผิดหวังอาจเกิดขึ้นได้เมื่อมีบางอย่างผิดปกติ ทุกคนที่ได้ลองใช้ผู้ช่วยอาจสะดุดกับปัญหาของการตอบสนองด้วยสิ่งที่รู้สึกงี่เง่าหรือหยาบคาย
หุบเขาผู้ช่วยเสียงที่แปลกประหลาดก่อให้เกิดปัญหาด้านคุณภาพในประสบการณ์ผู้ใช้ผู้ช่วยที่ยากจะเอาชนะ อันที่จริง การ ทดสอบทัวริง (ตั้งชื่อตามอลัน ทัวริง นักคณิตศาสตร์ชื่อดัง) จะผ่านเมื่อผู้ประเมินที่เป็นมนุษย์แสดงการสนทนาระหว่างเจ้าหน้าที่ทั้งสองไม่สามารถแยกความแตกต่างระหว่างตัวแทนเหล่านั้นว่าสิ่งใดเป็นเครื่องจักรและสิ่งใดเป็นมนุษย์ จนถึงตอนนี้ก็ยังไม่เคยผ่าน
ซึ่งหมายความว่ากระบวนทัศน์ผู้ช่วยกำหนด คำมั่นสัญญาของประสบการณ์การบริการที่เหมือนมนุษย์ ซึ่งไม่สามารถบรรลุได้และผู้ใช้จะต้องผิดหวัง ประสบการณ์ที่ประสบความสำเร็จจะสร้างแต่ความผิดหวังในที่สุด เมื่อผู้ใช้เริ่มไว้วางใจผู้ช่วยที่เหมือนมนุษย์
ปัญหาที่ 2: การโต้ตอบตามลำดับและช้า
ปัญหาที่สองของผู้ช่วยเสียงคือลักษณะผลัดกันเดินของการตอบสนองภาษาธรรมชาติทำให้เกิดความล่าช้าในการโต้ตอบ นี่เป็นเพราะสมองของเราประมวลผลข้อมูลอย่างไร
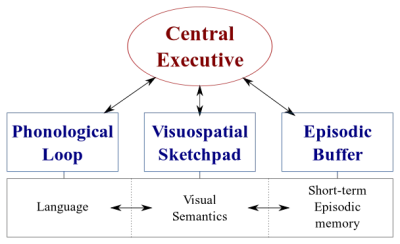
ระบบประมวลผลข้อมูลในสมองของเรามีสองประเภท:
- ระบบภาษา ที่ประมวลผลคำพูด
- ระบบ การมองเห็นที่เชี่ยวชาญในการประมวลผลข้อมูลภาพและเชิงพื้นที่
ทั้งสองระบบสามารถทำงานแบบคู่ขนานกันได้ แต่ ทั้งสองระบบประมวลผลเพียงครั้งละหนึ่งรายการเท่านั้น นี่คือเหตุผลที่คุณสามารถพูดและขับรถไปพร้อม ๆ กันได้ แต่คุณไม่สามารถส่งข้อความและขับรถได้ เนื่องจากกิจกรรมทั้งสองนั้นจะเกิดขึ้นในระบบการมองเห็น

ในทำนองเดียวกัน เมื่อคุณกำลังคุยกับผู้ช่วยเสียง ผู้ช่วยต้องอยู่เงียบๆ และในทางกลับกัน สิ่งนี้จะสร้างการ สนทนาแบบผลัดกันเล่น โดย ที่ส่วนอื่น ๆ จะไม่โต้ตอบอย่างเต็มที่เสมอ
อย่างไรก็ตาม ให้พิจารณาหัวข้อยากๆ ที่คุณต้องการพูดคุยกับเพื่อนของคุณ คุณอาจจะพูดคุยแบบเห็นหน้ากันมากกว่าทางโทรศัพท์ใช่ไหม นั่นเป็นเพราะในการสนทนาแบบเห็นหน้ากัน เราใช้การสื่อสารแบบไม่ใช้คำพูดเพื่อให้การตอบกลับด้วยภาพแบบเรียลไทม์แก่คู่สนทนาของเรา สิ่งนี้จะสร้างวงจรการแลกเปลี่ยนข้อมูลแบบสองทิศทางและช่วยให้ ทั้งสองฝ่ายมีส่วนร่วมอย่างแข็งขัน ในการสนทนาพร้อมกัน
ผู้ช่วยไม่ได้ให้ข้อเสนอแนะภาพแบบเรียลไทม์ พวกเขาใช้เทคโนโลยีที่เรียกว่า end-pointing เพื่อตัดสินใจว่าเมื่อใดที่ผู้ใช้หยุดพูดและตอบกลับหลังจากนั้น และเมื่อพวกเขาตอบกลับ พวกเขาจะไม่ได้รับข้อมูลใด ๆ จากผู้ใช้ในเวลาเดียวกัน ประสบการณ์เป็นแบบทิศทางเดียวและแบบผลัดกันเล่นอย่างเต็มที่
ในการสนทนา แบบเห็นหน้า กัน แบบสองทิศทาง และแบบเรียลไทม์ ทั้งสองฝ่ายสามารถตอบสนองได้ทันทีต่อสัญญาณภาพและภาษา สิ่งนี้ใช้ระบบประมวลผลข้อมูลต่าง ๆ ของสมองมนุษย์ และการสนทนาจะราบรื่นขึ้นและมีประสิทธิภาพมากขึ้น
ผู้ช่วยเสียงติดอยู่ในโหมดทิศทางเดียวเนื่องจากใช้ภาษาธรรมชาติทั้งเป็นช่องสัญญาณเข้าและออก แม้ว่าเสียงจะเร็วกว่าการพิมพ์สำหรับการป้อนข้อมูลถึงสี่เท่า แต่ก็ย่อยได้ช้ากว่าการอ่านอย่างมาก เนื่องจาก ข้อมูลต้องได้รับการประมวลผลตามลำดับ วิธีการนี้จึงทำงานได้ดีสำหรับคำสั่งง่ายๆ เช่น "ปิดไฟ" ที่ไม่ต้องการเอาต์พุตมากจากผู้ช่วยเท่านั้น

ก่อนหน้านี้ ฉันสัญญาว่าจะหารือเกี่ยวกับส่วนต่อประสานผู้ใช้แบบเสียงที่ใช้เสียงสำหรับการป้อนข้อมูลจากผู้ใช้เท่านั้น อินเทอร์เฟซผู้ใช้เสียงประเภทนี้ได้รับประโยชน์จากส่วนที่ดีที่สุดของอินเทอร์เฟซผู้ใช้เสียง — ความเป็นธรรมชาติ ความเร็ว และความสะดวกในการใช้งาน — แต่ไม่ต้องทนทุกข์จากส่วนที่ไม่ดี — หุบเขาลึกลับและการโต้ตอบตามลำดับ
ลองพิจารณาทางเลือกนี้
ทางเลือกที่ดีกว่าสำหรับผู้ช่วยเสียง
วิธีแก้ไขปัญหาเหล่านี้ในผู้ช่วยเสียงคือละเว้นการตอบกลับด้วยภาษาที่เป็นธรรมชาติ และแทนที่ด้วยการตอบกลับด้วยภาพแบบเรียลไทม์ การเปลี่ยนความคิดเห็นเป็นภาพจะทำให้ผู้ใช้สามารถให้และรับข้อเสนอแนะได้พร้อมกัน ซึ่งจะทำให้แอปพลิเคชันตอบสนองโดยไม่ขัดจังหวะผู้ใช้และเปิดใช้งานการไหลของข้อมูลแบบสองทิศทาง เนื่องจากการไหลของข้อมูลเป็นแบบสองทิศทาง ปริมาณข้อมูลจึงใหญ่กว่า
ปัจจุบัน กรณีการใช้งานยอดนิยมสำหรับผู้ช่วยเสียงคือการตั้งนาฬิกาปลุก เล่นเพลง ตรวจสอบสภาพอากาศ และถามคำถามง่ายๆ ทั้งหมดนี้เป็น งานเดิมพันต่ำ ที่ไม่รบกวนผู้ใช้มากเกินไปเมื่อล้มเหลว
ดังที่ David Pierce จาก Wall Street Journal เคยเขียนไว้ว่า:
“ฉันนึกภาพไม่ออกว่าจะจองเที่ยวบินหรือจัดการงบประมาณผ่านระบบสั่งงานด้วยเสียง หรือติดตามการควบคุมอาหารด้วยการตะโกนใส่ส่วนผสมที่วิทยากรของฉัน”
— เดวิด เพียร์ซ จาก Wall Street Journal
งานเหล่านี้เป็นงานที่ต้องใช้ข้อมูลจำนวนมากซึ่งจำเป็นต้องดำเนินการให้ถูกต้อง
อย่างไรก็ตาม ในที่สุด อินเทอร์เฟซผู้ใช้เสียงจะล้มเหลว สิ่งสำคัญคือต้องครอบคลุมเรื่องนี้ให้เร็วที่สุด ข้อผิดพลาดมากมายเกิดขึ้นเมื่อพิมพ์บนแป้นพิมพ์หรือแม้แต่ในการสนทนาแบบเห็นหน้ากัน อย่างไรก็ตาม สิ่งนี้ไม่ได้น่าผิดหวังเลย เนื่องจากผู้ใช้สามารถกู้คืนได้ง่ายๆ โดยคลิกที่ Backspace แล้วลองอีกครั้งหรือขอคำชี้แจง
การกู้คืนจากข้อผิดพลาดอย่างรวดเร็ว นี้ช่วยให้ผู้ใช้มีประสิทธิภาพมากขึ้นและไม่บังคับให้พวกเขาเข้าสู่การสนทนาแปลก ๆ กับผู้ช่วย
โต้ตอบด้วยเสียงโดยตรง
ในแอปพลิเคชันส่วนใหญ่ การดำเนินการจะดำเนินการผ่านการจัดการองค์ประกอบกราฟิกบนหน้าจอ ผ่านการจิ้มหรือปัด (บนหน้าจอสัมผัส) การคลิกเมาส์ และ/หรือกดปุ่มบนแป้นพิมพ์ คุณสามารถเพิ่มการป้อนข้อมูลด้วยเสียงเป็นตัวเลือกหรือกิริยาช่วยเพิ่มเติมสำหรับการจัดการองค์ประกอบกราฟิกเหล่านี้ การโต้ตอบประเภทนี้เรียกว่า การโต้ตอบด้วยเสียงโดยตรง
ความแตกต่างระหว่างการโต้ตอบด้วยเสียงโดยตรงและผู้ช่วยคือ แทนที่จะขอให้อวาตาร์ ผู้ช่วย ทำงาน ผู้ใช้จะจัดการส่วนต่อประสานกราฟิกกับผู้ใช้ด้วยเสียงโดยตรง
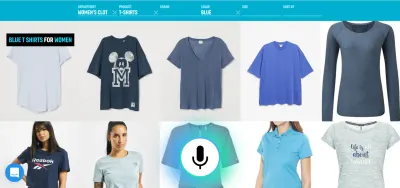
“นี่ไม่ใช่ความหมายใช่ไหม” คุณอาจถาม หากคุณกำลังจะคุยกับคอมพิวเตอร์ มันสำคัญจริงๆ หรือไม่ว่าคุณกำลังพูดกับคอมพิวเตอร์โดยตรงหรือผ่านบุคคลเสมือนจริง? ในทั้งสองกรณี คุณแค่กำลังคุยกับคอมพิวเตอร์!
ใช่ ความแตกต่างนั้นบอบบางแต่สำคัญ เมื่อคลิกปุ่มหรือรายการเมนูใน GUI ( G raphical U ser I nterface) จะเห็นได้ชัดว่าเรากำลังใช้งานเครื่อง ไม่มีภาพลวงตาของบุคคล เรากำลังปรับปรุงการโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์ด้วยการแทนที่การคลิกนั้นด้วยคำสั่งเสียง ในทางกลับกัน ด้วยกระบวนทัศน์ผู้ช่วย เรากำลังสร้าง ปฏิสัมพันธ์ระหว่างมนุษย์กับมนุษย์ในรูปแบบที่เสื่อมลง และด้วยเหตุนี้ การเดินทางสู่หุบเขาลึกลับ
การผสมผสานฟังก์ชันเสียงเข้ากับอินเทอร์เฟซผู้ใช้แบบกราฟิกยังช่วยเพิ่มศักยภาพในการควบคุมพลังของรูปแบบต่างๆ แม้ว่าผู้ใช้จะสามารถใช้เสียงเพื่อควบคุมแอปพลิเคชันได้ แต่ก็สามารถใช้อินเทอร์เฟซแบบกราฟิกแบบเดิมได้เช่นกัน สิ่งนี้ทำให้ผู้ใช้สามารถ สลับไปมาระหว่างการสัมผัสและเสียง ได้อย่างราบรื่น และเลือกตัวเลือกที่ดีที่สุดตามบริบทและงานของพวกเขา
ตัวอย่างเช่น เสียงเป็นวิธีที่มีประสิทธิภาพมากในการป้อนข้อมูลที่สมบูรณ์ การเลือกระหว่างทางเลือกที่ถูกต้องสองสามอย่าง การแตะหรือคลิกน่าจะดีกว่า จากนั้นผู้ใช้สามารถแทนที่การพิมพ์และการเรียกดูโดยพูดว่า "ขอดูเที่ยวบินที่ออกเดินทางจากลอนดอนไปนิวยอร์กในวันพรุ่งนี้" และเลือกตัวเลือกที่ดีที่สุดจากรายการโดยใช้การแตะ
ตอนนี้คุณอาจถามว่า “โอเค มันดูดีมาก ทำไมเราไม่เคยเห็นตัวอย่างอินเทอร์เฟซผู้ใช้ด้วยเสียงมาก่อนเลย? เหตุใดบริษัทเทคโนโลยีรายใหญ่จึงไม่สร้างเครื่องมือสำหรับสิ่งนี้” อาจมีเหตุผลหลายประการสำหรับเรื่องนั้น เหตุผลหนึ่งก็คือกระบวนทัศน์ผู้ช่วยเสียงในปัจจุบันน่าจะเป็นวิธีที่ดีที่สุดสำหรับพวกเขาในการใช้ประโยชน์จากข้อมูลที่ได้รับจากผู้ใช้ปลายทาง อีกเหตุผลหนึ่งเกี่ยวกับวิธีสร้างเทคโนโลยีเสียงของพวกเขา
ส่วนต่อประสานผู้ใช้เสียงที่ใช้งานได้ดีต้องมีสองส่วนที่แตกต่างกัน:
- การรู้จำเสียง ที่เปลี่ยนคำพูดเป็นข้อความ
- องค์ประกอบ การเข้าใจภาษาธรรมชาติ ที่ดึงความหมายจากข้อความนั้น
ส่วนที่สองเป็นเวทย์มนตร์ที่เปลี่ยนคำพูด "ปิดไฟห้องนั่งเล่น" และ "โปรดปิดไฟในห้องนั่งเล่น" เป็นการกระทำเดียวกัน
การอ่านที่แนะนำ : วิธีสร้างการกระทำของคุณเองสำหรับหน้าแรกของ Google โดยใช้ API.AI
หากคุณเคยใช้ผู้ช่วยที่มีจอแสดงผล (เช่น Siri หรือ Google Assistant) คุณอาจสังเกตเห็นว่าคุณได้รับข้อความถอดเสียงแบบเกือบเรียลไทม์ แต่หลังจากที่คุณหยุดพูด ระบบจะใช้เวลาไม่กี่วินาทีก่อนที่ระบบ ดำเนินการตามที่คุณร้องขอจริงๆ นี่เป็นเพราะทั้งการรู้จำคำพูดและความเข้าใจภาษาธรรมชาติที่เกิดขึ้นตามลำดับ
มาดูกันว่าจะเปลี่ยนแปลงได้อย่างไร
การทำความเข้าใจภาษาพูดแบบเรียลไทม์: เคล็ดลับสู่คำสั่งเสียงที่มีประสิทธิภาพมากขึ้น
ความรวดเร็วที่แอปพลิเคชันตอบสนองต่อการป้อนข้อมูลของผู้ใช้เป็นปัจจัยสำคัญในประสบการณ์ผู้ใช้โดยรวมของแอปพลิเคชัน นวัตกรรมที่สำคัญที่สุดของ iPhone รุ่นดั้งเดิมคือหน้าจอสัมผัสที่ตอบสนองและตอบสนองอย่างดีเยี่ยม ความสามารถของส่วนต่อประสานผู้ใช้เสียงเพื่อ ตอบสนองต่อการป้อนข้อมูลด้วยเสียงในทันที มีความสำคัญเท่าเทียมกัน
เพื่อสร้างการแลกเปลี่ยนข้อมูลแบบสองทิศทางที่รวดเร็วระหว่างผู้ใช้และ UI GUI ที่เปิดใช้งานเสียงควรจะสามารถตอบสนองได้ทันที แม้กระทั่งประโยคกลางๆ เมื่อใดก็ตามที่ผู้ใช้พูดอะไรที่สามารถดำเนินการได้ ต้องใช้เทคนิคที่เรียกว่าการ สตรีมความเข้าใจภาษาพูด
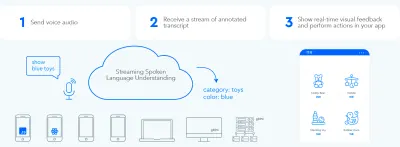
ตรงกันข้ามกับระบบผู้ช่วยเสียงแบบผลัดกันเล่นแบบเดิมๆ ที่รอให้ผู้ใช้หยุดพูดก่อนประมวลผลคำขอของผู้ใช้ ระบบที่ใช้การสตรีมความเข้าใจในภาษาพูดจะพยายามเข้าใจเจตนาของผู้ใช้ตั้งแต่วินาทีแรกที่ผู้ใช้เริ่มพูด ทันทีที่ผู้ใช้พูดอะไรที่สามารถดำเนินการได้ UI จะตอบสนองทันที
การตอบสนองทันทีจะตรวจสอบทันทีว่าระบบเข้าใจผู้ใช้และกระตุ้นให้ผู้ใช้ดำเนินการต่อไป คล้ายกับพยักหน้าหรือ "a-ha" สั้น ๆ ในการสื่อสารระหว่างคนกับมนุษย์ ส่งผลให้มีการรองรับคำพูดที่ยาวและซับซ้อนมากขึ้น ตามลำดับ หากระบบไม่เข้าใจผู้ใช้หรือผู้ใช้พูดผิด การตอบกลับทันทีจะช่วยให้กู้คืนได้อย่างรวดเร็ว ผู้ใช้สามารถแก้ไขและดำเนินการต่อได้ทันที หรือแม้แต่แก้ไขด้วยวาจาด้วยตนเอง: “ฉันต้องการสิ่งนี้ ไม่ใช่ ฉันหมายถึง ฉันต้องการสิ่งนั้น” คุณสามารถลองใช้แอปพลิเคชันประเภทนี้ได้ด้วยตัวเองในการสาธิตการค้นหาด้วยเสียงของเรา
ดังที่คุณเห็นในการสาธิต การตอบกลับด้วยภาพแบบเรียลไทม์ทำให้ผู้ใช้สามารถแก้ไขตัวเองได้อย่างเป็นธรรมชาติ และกระตุ้นให้พวกเขาใช้ประสบการณ์เสียงต่อไป เนื่องจากพวกเขาไม่สับสนโดยบุคคลเสมือน พวกเขาจึงสามารถเกี่ยวข้องกับข้อผิดพลาดที่อาจเกิดขึ้นได้ในลักษณะเดียวกันกับการพิมพ์ผิด ไม่ใช่เป็นการดูถูกส่วนตัว ประสบการณ์จะ รวดเร็วและเป็นธรรมชาติมากขึ้น เนื่องจากข้อมูลที่ป้อนให้กับผู้ใช้ไม่ได้ถูกจำกัดด้วยอัตราการพูดโดยทั่วไปที่ประมาณ 150 คำต่อนาที
การอ่านที่แนะนำ : การออกแบบประสบการณ์เสียงโดย Lyndon Cerejo
บทสรุป
ในขณะที่ผู้ช่วยเสียงเป็นการใช้งานทั่วไปสำหรับส่วนต่อประสานผู้ใช้เสียง แต่การใช้การตอบกลับภาษาธรรมชาติทำให้พวกเขาไม่มีประสิทธิภาพและไม่เป็นธรรมชาติ เสียงเป็นวิธีที่ยอดเยี่ยมในการป้อนข้อมูล แต่การฟังเสียงพูดนั้นไม่ได้สร้างแรงบันดาลใจมากนัก นี่เป็นปัญหาใหญ่ของผู้ช่วยเสียง
อนาคตของเสียงไม่ควรอยู่ในการสนทนากับคอมพิวเตอร์ แต่เป็นการ แทนที่งานของผู้ใช้ที่น่าเบื่อ ด้วยวิธีการสื่อสารที่เป็นธรรมชาติที่สุด: คำพูด สามารถใช้การโต้ตอบด้วยเสียงโดยตรงเพื่อปรับปรุงประสบการณ์การกรอกแบบฟอร์มในเว็บหรือแอปพลิเคชันมือถือ เพื่อสร้างประสบการณ์การค้นหาที่ดียิ่งขึ้น และเพื่อให้สามารถควบคุมหรือนำทางในแอปพลิเคชันได้อย่างมีประสิทธิภาพมากขึ้น
นักออกแบบและนักพัฒนาแอปต่าง มองหาวิธีลดปัญหา ในแอปหรือเว็บไซต์อยู่เสมอ การปรับปรุงส่วนติดต่อผู้ใช้แบบกราฟิกในปัจจุบันด้วยรูปแบบเสียงจะช่วยให้โต้ตอบกับผู้ใช้ได้เร็วขึ้นหลายเท่า โดยเฉพาะอย่างยิ่งในบางสถานการณ์ เช่น เมื่อผู้ใช้ปลายทางอยู่ในอุปกรณ์เคลื่อนที่และกำลังเดินทาง และการพิมพ์ทำได้ยาก อันที่จริง การค้นหาด้วยเสียงสามารถทำได้เร็วกว่าอินเทอร์เฟซผู้ใช้การกรองการค้นหาแบบเดิมถึงห้าเท่า แม้กระทั่งเมื่อใช้คอมพิวเตอร์เดสก์ท็อป
ครั้งต่อไป เมื่อคุณกำลังคิดเกี่ยวกับวิธีการทำให้งานของผู้ใช้บางอย่างในแอปพลิเคชันของคุณใช้งานง่ายขึ้น ใช้งานสนุกขึ้น หรือคุณสนใจที่จะเพิ่ม Conversion ให้พิจารณาว่างานของผู้ใช้นั้นสามารถอธิบายได้อย่างถูกต้องในภาษาธรรมชาติหรือไม่ ถ้าใช่ ให้เสริมอินเทอร์เฟซผู้ใช้ของคุณด้วยรูปแบบเสียง แต่ อย่าบังคับให้ผู้ใช้ สนทนากับคอมพิวเตอร์
ทรัพยากร
- “Voice First Versus The Multimodal User Interfaces of the Future” โจน พาลมิเตอร์ บาจอเรก UXmatters
- “แนวทางสำหรับการสร้างแอปที่เปิดใช้งานด้วยเสียง” Hannes Heikinheimo, Speechly
- “6 เหตุผลที่แอปหน้าจอสัมผัสของคุณควรมีความสามารถด้านเสียง” Ottomatias Peura, UXmatters
- การผสมผสานที่จับต้องได้และจับต้องไม่ได้: การออกแบบอินเทอร์เฟซหลายรูปแบบโดยใช้ Adobe XD, Nick Babich, Smashing Magazine
( Adobe XD สามารถใช้เพื่อสร้างต้นแบบสิ่งที่คล้ายกัน ) - “ประสิทธิภาพที่ความเร็วของเสียง: คำมั่นสัญญาของการดำเนินการที่เปิดใช้งานด้วยเสียง” Eric Turkington, RAIN
- การสาธิตที่แสดงผลการตอบกลับด้วยภาพแบบเรียลไทม์ในการกรองการค้นหาด้วยเสียงของอีคอมเมิร์ซ (เวอร์ชันวิดีโอ)
- Speechly มีเครื่องมือสำหรับนักพัฒนาสำหรับอินเทอร์เฟซผู้ใช้ประเภทนี้
- ทางเลือกโอเพ่นซอร์ส: voice2json