
คู่มือการถดถอยเชิงเส้นโดยใช้ Scikit [พร้อมตัวอย่าง]
เผยแพร่แล้ว: 2021-06-18โดยทั่วไปแล้วอัลกอริธึมการเรียนรู้ภายใต้การดูแลจะแบ่งออกเป็นสองประเภท: การถดถอยและการจำแนกประเภทด้วยการทำนายผลลัพธ์แบบต่อเนื่องและแบบไม่ต่อเนื่อง
บทความต่อไปนี้จะกล่าวถึงการถดถอยเชิงเส้นและการนำไปใช้โดยใช้หนึ่งในไลบรารีการเรียนรู้แมชชีนเลิร์นนิงยอดนิยมของ python นั่นคือไลบรารี Scikit-learn เครื่องมือสำหรับแมชชีนเลิร์นนิงและแบบจำลองทางสถิติมีอยู่ในไลบรารี python สำหรับการจำแนกประเภท การถดถอย การจัดกลุ่ม และการลดขนาด เขียนด้วยภาษาโปรแกรม python ไลบรารีนี้สร้างขึ้นจากไลบรารี python NumPy, SciPy และ Matplotlib
สารบัญ
การถดถอยเชิงเส้น
การถดถอยเชิงเส้นทำหน้าที่ถดถอยภายใต้วิธีการเรียนรู้แบบมีผู้ดูแล ตามตัวแปรอิสระ ค่าเป้าหมายจะถูกคาดการณ์ วิธีการนี้ส่วนใหญ่จะใช้สำหรับการคาดการณ์และระบุความสัมพันธ์ระหว่างตัวแปร
ในพีชคณิต คำว่าลิเนียริตี้หมายถึงความสัมพันธ์เชิงเส้นระหว่างตัวแปร เส้นตรงจะถูกอนุมานระหว่างตัวแปรในพื้นที่สองมิติ
หากเส้นคือการพล็อตระหว่างตัวแปรอิสระบนแกน X และตัวแปรตามบนแกน Y เส้นตรงจะเกิดขึ้นจากการถดถอยเชิงเส้นที่เหมาะสมกับจุดข้อมูลมากที่สุด
สมการของเส้นตรงอยู่ในรูปของ

Y = mx + b
โดยที่ b= สกัดกั้น
m= ความชันของเส้นตรง
ดังนั้นจากการถดถอยเชิงเส้น
- ค่าที่เหมาะสมที่สุดสำหรับการสกัดกั้นและความชันถูกกำหนดในสองมิติ
- ไม่มีการเปลี่ยนแปลงในตัวแปร x และ y เนื่องจากเป็นคุณลักษณะของข้อมูลและยังคงเหมือนเดิม
- เฉพาะค่าสกัดกั้นและความชันเท่านั้นที่สามารถควบคุมได้
- เส้นตรงหลายเส้นขึ้นอยู่กับค่าของความชันและการสกัดกั้น อาจมีเส้นตรงหลายเส้นโดยอาศัยอัลกอริธึมของการถดถอยเชิงเส้น หลายเส้นจะพอดีกับจุดข้อมูลและเส้นที่มีข้อผิดพลาดน้อยที่สุดจะถูกส่งกลับ
การถดถอยเชิงเส้นด้วย Python
สำหรับการนำการถดถอยเชิงเส้นไปใช้ใน python ให้ใช้แพ็คเกจที่เหมาะสมพร้อมกับฟังก์ชันและคลาสของมัน แพ็คเกจ NumPy ใน Python เป็นโอเพ่นซอร์สและอนุญาตให้ดำเนินการหลายอย่างผ่านอาร์เรย์ ทั้งอาร์เรย์เดี่ยวและหลายมิติ
ไลบรารี่อื่นที่ใช้กันอย่างแพร่หลายใน python คือ Scikit-learn ซึ่งใช้สำหรับปัญหาการเรียนรู้ของเครื่อง
Scikit-learN
ห้องสมุด Scikit-learn มีอัลกอริธึมสำหรับนักพัฒนาโดยอิงจากการเรียนรู้ทั้งแบบมีผู้สอนและแบบไม่มีผู้ดูแล ไลบรารีโอเพนซอร์สของ python ได้รับการออกแบบมาสำหรับงานการเรียนรู้ของเครื่อง
นักวิทยาศาสตร์ข้อมูลสามารถนำเข้าข้อมูล ประมวลผลล่วงหน้า วางแผน และทำนายข้อมูลผ่านการใช้ scikit-learn
David Cournapeau พัฒนา scikit-learn เป็นครั้งแรกในปี 2550 และห้องสมุดมีการเติบโตตั้งแต่หลายทศวรรษ
เครื่องมือที่จัดทำโดย scikit-learn คือ:
- การถดถอย: รวมการถดถอยโลจิสติกและการถดถอยเชิงเส้น
- การจัดประเภท: รวมวิธีการ K-Nearest Neighbors
- การเลือกรุ่น
- การจัดกลุ่ม: รวมทั้ง K-Means++ และ K-Means
- การประมวลผลล่วงหน้า
ข้อดีของห้องสมุดคือ:
- การเรียนรู้และการใช้งานห้องสมุดเป็นเรื่องง่าย
- เป็นห้องสมุดโอเพ่นซอร์สและฟรี
- ด้านการเรียนรู้ของเครื่องสามารถครอบคลุมได้รวมถึงการเรียนรู้เชิงลึก
- เป็นแพ็คเกจที่ทรงพลังและหลากหลาย
- ห้องสมุดมีเอกสารรายละเอียด
- หนึ่งในชุดเครื่องมือที่ใช้มากที่สุดสำหรับการเรียนรู้ของเครื่อง
นำเข้า scikit-learn
ต้องติดตั้ง scikit-learn ก่อนผ่าน pip หรือผ่าน conda
- ข้อกำหนด: python 3 รุ่น 64 บิตพร้อมไลบรารี NumPy และ Scipy ที่ติดตั้งไว้ นอกจากนี้ สำหรับการแสดงแผนภาพข้อมูล จำเป็นต้องใช้ matplotlib
คำสั่งการติดตั้ง: pip install -U scikit-learn
จากนั้นตรวจสอบว่าการติดตั้งเสร็จสมบูรณ์หรือไม่
การติดตั้ง Numpy, Scipy และ matplotlib
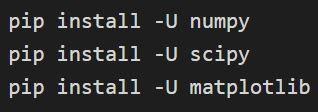
สามารถยืนยันการติดตั้งได้ทาง:
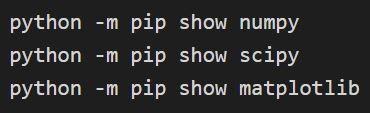
แหล่งที่มา
การถดถอยเชิงเส้นผ่าน Scikit-learn
การใช้การถดถอยเชิงเส้นผ่านแพ็คเกจ scikit-learn มีขั้นตอนดังต่อไปนี้
- ต้องนำเข้าแพ็คเกจและคลาสที่จำเป็น
- ข้อมูลจำเป็นสำหรับการทำงานและดำเนินการเปลี่ยนแปลงตามความเหมาะสม
- จะต้องสร้างแบบจำลองการถดถอยและติดตั้งข้อมูลที่มีอยู่
- ข้อมูลการปรับรุ่นจะต้องได้รับการตรวจสอบเพื่อวิเคราะห์ว่าแบบจำลองที่สร้างขึ้นนั้นน่าพอใจหรือไม่
- การคาดการณ์จะต้องทำผ่านแอปพลิเคชันของแบบจำลอง
แพ็กเกจ NumPy และคลาส LinearRegression จะถูกนำเข้าจาก sklearn.linear_model

แหล่งที่มา
ฟังก์ชันที่จำเป็นสำหรับ การถดถอยเชิงเส้นของ sklearn มีอยู่ทั้งหมดเพื่อนำการถดถอยเชิงเส้นไปใช้ในที่สุด คลาส sklearn.linear_model.LinearRegression ใช้สำหรับดำเนินการวิเคราะห์การถดถอย (ทั้งเชิงเส้นและพหุนาม) และดำเนินการคาดการณ์
สำหรับอัลกอริธึมการเรียนรู้ของเครื่องและ scikit เรียนรู้การถดถอยเชิงเส้น ต้องนำเข้าชุดข้อมูลก่อน สามตัวเลือกที่มีอยู่ใน Scikit-learn เพื่อรับข้อมูล:
- ชุดข้อมูล เช่น การจำแนกม่านตาหรือชุดการถดถอยราคาบ้านของบอสตัน
- สามารถดาวน์โหลดชุดข้อมูลของโลกแห่งความจริงจากอินเทอร์เน็ตได้โดยตรงผ่านฟังก์ชันที่กำหนดไว้ล่วงหน้าของ Scikit-learn
- สามารถสร้างชุดข้อมูลแบบสุ่มเพื่อจับคู่กับรูปแบบเฉพาะผ่านตัวสร้างข้อมูล Scikit-learn
ไม่ว่าจะเลือกตัวเลือกใด ชุดข้อมูลของโมดูลจะต้องถูกนำเข้า

นำเข้า sklearn.datasets เป็น datasets
1. ชุดการจำแนกไอริส
ไอริส = datasets.load_iris()
ม่านตาชุดข้อมูลถูกจัดเก็บเป็นฟิลด์ข้อมูลอาร์เรย์ 2 มิติ ของ n_samples * n_features การนำเข้าจะดำเนินการเป็นวัตถุของพจนานุกรม ประกอบด้วยข้อมูลที่จำเป็นทั้งหมดพร้อมกับข้อมูลเมตา
สามารถใช้ฟังก์ชัน DESCR รูปร่าง และ _names เพื่อรับคำอธิบายและการจัดรูปแบบของข้อมูล การพิมพ์ผลลัพธ์ของฟังก์ชันจะแสดงข้อมูลของชุดข้อมูลที่อาจจำเป็นขณะทำงานกับชุดข้อมูลไอริส
รหัสต่อไปนี้จะโหลดข้อมูลของชุดข้อมูลม่านตา
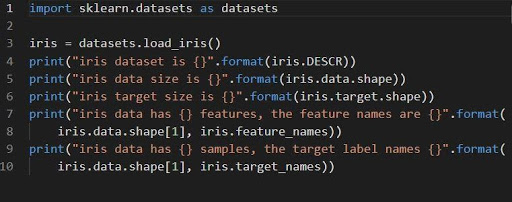
แหล่งที่มา
2. การสร้างข้อมูลการถดถอย
หากไม่มีข้อกำหนดสำหรับข้อมูลในตัว ก็สามารถสร้างข้อมูลผ่านการแจกจ่ายที่สามารถเลือกได้
การสร้างข้อมูลการถดถอยด้วยชุดคุณสมบัติข้อมูล 1 รายการและคุณสมบัติ 1 รายการ
X , Y = datasets.make_regression(n_features=1, n_informative=1)
ข้อมูลที่สร้างขึ้นจะถูกบันทึกในชุดข้อมูล 2 มิติที่มีอ็อบเจ็กต์ x และ y คุณสมบัติของข้อมูลที่สร้างขึ้นสามารถเปลี่ยนแปลงได้โดยการเปลี่ยนพารามิเตอร์ของฟังก์ชัน make_regression
ในตัวอย่างนี้ พารามิเตอร์ของ คุณลักษณะข้อมูล และ คุณลักษณะ จะเปลี่ยนจากค่าเริ่มต้น 10 เป็น 1
พารามิเตอร์อื่นๆ ที่พิจารณาคือ กลุ่มตัวอย่าง และ เป้าหมาย ที่มีการควบคุมจำนวนตัวแปรเป้าหมายและตัวแปรตัวอย่าง
- คุณลักษณะที่ให้ข้อมูลที่เป็นประโยชน์แก่อัลกอริธึมของ ML จะเรียกว่าคุณลักษณะที่ให้ข้อมูล ในขณะที่คุณลักษณะที่ไม่เป็นประโยชน์จะเรียกว่าคุณลักษณะที่ให้ข้อมูล
3. พล็อตข้อมูล
ข้อมูลถูกพล็อตโดยใช้ไลบรารี matplotlib ก่อนอื่น ต้องนำเข้า matplotlib
นำเข้า matplotlib.pyplot เป็น plt
กราฟด้านบนถูกพล็อตผ่าน matplotlib ผ่านโค้ด
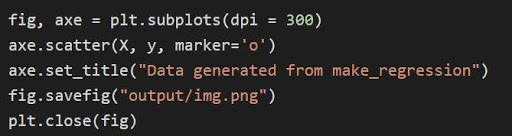
แหล่งที่มา
ในรหัสด้านบน:
- ตัวแปรทูเพิลถูกคลายแพ็กและบันทึกเป็นตัวแปรแยกกันในบรรทัดที่ 1 ของโค้ด ดังนั้น แอตทริบิวต์ที่แยกจากกันสามารถจัดการและบันทึกได้
- ชุดข้อมูล x, y ใช้เพื่อสร้างพล็อตแบบกระจายผ่านบรรทัดที่ 2 ด้วยความพร้อมใช้งานของพารามิเตอร์ตัวทำเครื่องหมายใน matplotlib ภาพจะได้รับการปรับปรุงโดยการทำเครื่องหมายจุดข้อมูลด้วยจุด (o)
- ชื่อเรื่องของพล็อตที่สร้างขึ้นถูกกำหนดผ่านบรรทัดที่ 3
- สามารถบันทึกรูปภาพเป็นไฟล์รูปภาพ .png จากนั้นรูปปัจจุบันจะปิดลง
พล็อตการถดถอยที่สร้างผ่านโค้ดด้านบนคือ
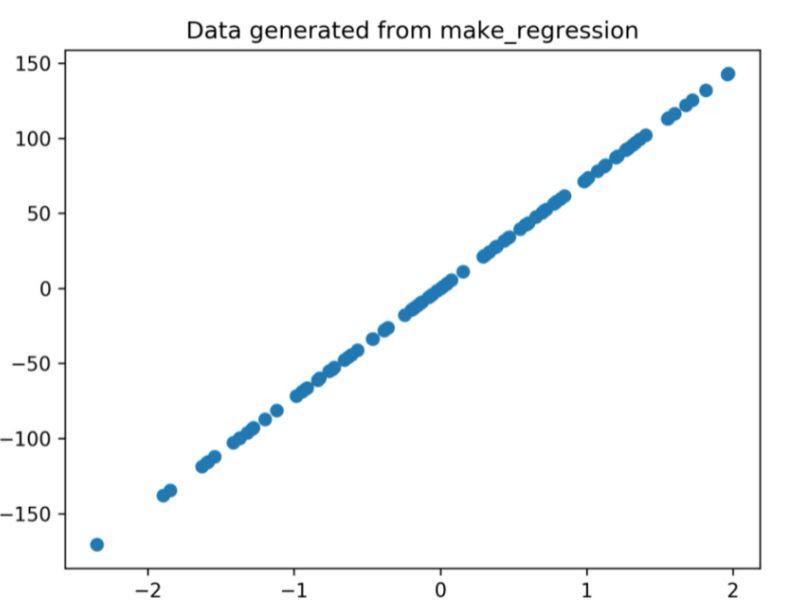
รูปที่ 1: พล็อตการถดถอยที่สร้างจากโค้ดด้านบน
4. การใช้อัลกอริทึมของการถดถอยเชิงเส้น
โดยใช้ข้อมูลตัวอย่างราคาบ้านในบอสตัน อัลกอริธึม ของ การถดถอยเชิงเส้น Scikit-learn ถูกนำมาใช้ในตัวอย่างต่อไปนี้ เช่นเดียวกับอัลกอริทึม ML อื่นๆ ชุดข้อมูลจะถูกนำเข้าและฝึกฝนโดยใช้ข้อมูลก่อนหน้า
ธุรกิจใช้วิธีถดถอยเชิงเส้น เนื่องจากเป็นรูปแบบการทำนายที่ทำนายความสัมพันธ์ระหว่างปริมาณตัวเลขและตัวแปรกับค่าเอาต์พุตโดยมีความหมายว่ามีค่าในความเป็นจริง
เมื่อมีบันทึกของข้อมูลก่อนหน้านี้ โมเดลนี้สามารถนำมาใช้ได้ดีที่สุด เนื่องจากสามารถคาดการณ์ผลลัพธ์ในอนาคตของสิ่งที่จะเกิดขึ้นในอนาคตได้หากมีรูปแบบที่ต่อเนื่องกัน
ในทางคณิตศาสตร์ ข้อมูลสามารถติดตั้งเพื่อลดผลรวมของสิ่งตกค้างทั้งหมดที่มีอยู่ระหว่างจุดข้อมูลและค่าที่คาดการณ์ไว้
ตัวอย่างต่อไปนี้แสดงการนำการ ถดถอยเชิงเส้นของ sklearn ไปใช้
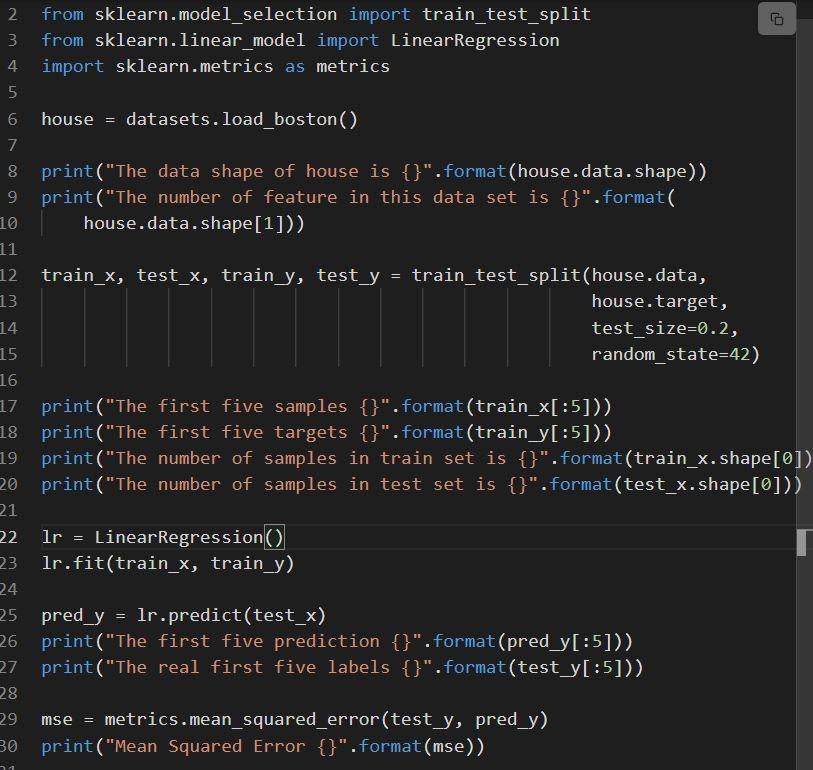
แหล่งที่มา
รหัสถูกอธิบายเป็น:
- บรรทัดที่ 6 โหลดชุดข้อมูลที่เรียกว่า load_boston
- ชุดข้อมูลแบ่งออกเป็นบรรทัดที่ 12 กล่าวคือ ชุดการฝึกที่มีข้อมูล 80% และชุดการทดสอบที่มีข้อมูล 20%
- การสร้างแบบจำลองการถดถอยเชิงเส้นที่บรรทัดที่ 23 แล้วฝึกที่
- ประสิทธิภาพของแบบจำลองได้รับการประเมินที่ผ้าลินิน 29 ผ่านการเรียก mean_squared_error
พ ล็อต การถดถอยเชิงเส้นของ sklearn แสดงไว้ด้านล่าง:
แบบจำลองการถดถอยเชิงเส้นของข้อมูลตัวอย่างราคาบ้านบอสตัน
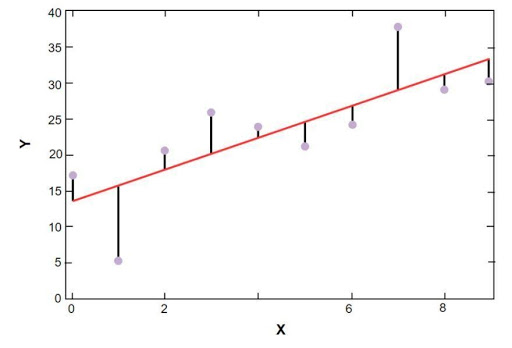
แหล่งที่มา
ในรูปด้านบน เส้นสีแดงแสดงแบบจำลองเชิงเส้นที่ได้รับการแก้ไขแล้วสำหรับข้อมูลตัวอย่างราคาบ้านในบอสตัน จุดสีน้ำเงินแสดงถึงข้อมูลเดิม และระยะห่างระหว่างเส้นสีแดงกับจุดสีน้ำเงินแสดงถึงผลรวมของส่วนที่เหลือ เป้าหมายของ แบบจำลอง การถดถอยเชิงเส้นแบบ scikit คือการลดผลรวมของเศษเหลือ
บทสรุป
บทความนี้กล่าวถึงการถดถอยเชิงเส้นและการนำไปใช้โดยใช้แพ็คเกจหลามโอเพ่นซอร์สที่เรียกว่า scikit-learn ถึงตอนนี้ คุณสามารถเข้าใจแนวคิดเกี่ยวกับวิธีการใช้การถดถอยเชิงเส้นผ่านแพ็คเกจนี้ การเรียนรู้วิธีใช้ห้องสมุดเพื่อการวิเคราะห์ข้อมูลของคุณเป็นเรื่องที่คุ้มค่า
หากคุณมีความสนใจในการสำรวจหัวข้อเพิ่มเติม เช่น การใช้แพ็คเกจหลามในการเรียนรู้ของเครื่องและปัญหาที่เกี่ยวข้องกับ AI คุณสามารถตรวจสอบหลักสูตร วิทยาศาสตรมหาบัณฑิตสาขาการเรียนรู้ของเครื่องและ AI ที่นำเสนอโดย upGrad หลักสูตรนี้มุ่งเป้าไปที่มืออาชีพระดับเริ่มต้นที่มีอายุระหว่าง 21 ถึง 45 ปี โดยมีเป้าหมายเพื่อฝึกอบรมนักเรียนในการเรียนรู้ของเครื่องผ่านการฝึกอบรมออนไลน์มากกว่า 650 ชั่วโมง กรณีศึกษามากกว่า 25 กรณี และการมอบหมายงาน ได้รับการรับรองจาก LJMU หลักสูตรนี้ให้คำแนะนำที่สมบูรณ์แบบและความช่วยเหลือในการจัดหางาน หากคุณมีคำถามหรือข้อสงสัย ฝากข้อความไว้ เรายินดีที่จะติดต่อคุณ