
Что такое машинное обучение с помощью Java? Как это реализовать?
Опубликовано: 2021-03-10Оглавление
Что такое машинное обучение?
Машинное обучение — это часть искусственного интеллекта, которая учится на доступных данных, примерах и опыте, чтобы имитировать поведение и интеллект человека. Программа, созданная с использованием машинного обучения, может самостоятельно строить логику без необходимости написания кода человеком вручную.
Все началось с теста Тьюринга в начале 1950-х годов, когда Алан Тернинг пришел к выводу, что для того, чтобы компьютер обладал настоящим интеллектом, он должен манипулировать человеком или убеждать его в том, что он тоже человек. Машинное обучение — относительно старая концепция, но только сегодня эта развивающаяся область может быть реализована, поскольку теперь компьютеры могут обрабатывать сложные алгоритмы. Алгоритмы машинного обучения эволюционировали за последнее десятилетие и теперь включают в себя сложные вычислительные навыки, что, в свою очередь, привело к расширению их возможностей имитации.
Приложения машинного обучения также росли с угрожающей скоростью. От здравоохранения, финансов, аналитики и образования до производства, маркетинга и государственных операций — в каждой отрасли наблюдается значительный рост качества и эффективности после внедрения технологий машинного обучения. Во всем мире произошли широкомасштабные качественные улучшения, что привело к росту спроса на специалистов по машинному обучению.
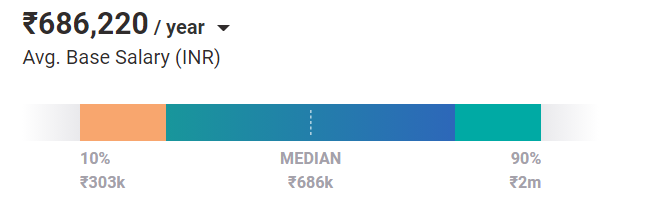
В среднем сегодня зарплата инженеров по машинному обучению составляет 686 220 фунтов стерлингов в год. И это касается позиции начального уровня. Обладая опытом и навыками, они могут зарабатывать до 2 млн фунтов стерлингов в год в Индии.
Типы алгоритмов машинного обучения
Алгоритмы машинного обучения бывают трех типов:
1. Контролируемое обучение . В этом типе обучения наборы данных для обучения помогают алгоритму делать точные прогнозы или аналитические решения. Он использует знания из прошлых обучающих наборов данных для обработки новых данных. Вот несколько примеров моделей машинного обучения с учителем:

- Линейная регрессия
- Логистическая регрессия
- Древо решений
2. Обучение без учителя . В этом типе обучения модель машинного обучения учится на немаркированных фрагментах информации. Он использует кластеризацию данных, группируя объекты или понимая взаимосвязь между ними, или используя их статистические свойства для проведения анализа. Примеры алгоритмов обучения без учителя:
- Кластеризация K-средних
- Иерархическая кластеризация
3. Обучение с подкреплением . Этот процесс основан на пробах. Это обучение путем взаимодействия с пространством или окружающей средой. Алгоритм RL учится на своем прошлом опыте, взаимодействуя с окружающей средой и определяя наилучший план действий.
Как реализовать машинное обучение с помощью Java?
Java входит в число лучших языков программирования, используемых для реализации алгоритмов машинного обучения. Большинство его библиотек имеют открытый исходный код, обеспечивая обширную поддержку документации, простоту обслуживания, конкурентоспособность и удобочитаемость.
В зависимости от популярности, вот 10 лучших библиотек машинного обучения, используемых для реализации машинного обучения в Java.
1. АДАМС
Расширенная система интеллектуального анализа данных и машинного обучения или ADAMS предназначена для создания новых и гибких систем рабочих процессов и управления сложными процессами в реальном мире. ADAMS использует древовидную архитектуру для управления потоком данных вместо ручного ввода-вывода.
Это устраняет необходимость в явных соединениях. Он основан на принципе «меньше значит больше» и выполняет поиск, визуализацию и визуализацию на основе данных. ADAMS отлично справляется с обработкой данных, потоковой передачей данных, управлением базами данных, созданием сценариев и документацией.
2. JavaML
JavaML предлагает множество алгоритмов машинного обучения и интеллектуального анализа данных, написанных для Java для поддержки инженеров-программистов, программистов, специалистов по данным и исследователей. У каждого алгоритма есть общий интерфейс, который прост в использовании и имеет обширную документацию, несмотря на отсутствие графического интерфейса.
Он довольно прост и понятен в реализации по сравнению с другими алгоритмами кластеризации. Его основные функции включают манипулирование данными, документирование, управление базами данных, классификацию данных, кластеризацию, выбор функций и так далее.
Присоединяйтесь к онлайн- курсу по машинному обучению в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и программам повышения квалификации в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
3. ВЕКА
Weka также является библиотекой машинного обучения с открытым исходным кодом, написанной для Java, которая поддерживает глубокое обучение. Он предоставляет набор алгоритмов машинного обучения и находит широкое применение в интеллектуальном анализе данных, подготовке данных, кластеризации данных, визуализации данных и регрессии, среди других операций с данными.
Пример: мы продемонстрируем это на небольшом наборе данных по диабету.
Шаг 1 : Загрузите данные с помощью Weka
| импортировать weka.core.Instances; импортировать weka.core.converters.ConverterUtils.DataSource; общественный класс Основной { public static void main(String[] args) выдает Exception { // Указание источника данных Источник данных Источник данных = новый Источник данных («data.arff»); // Загрузка набора данных Экземпляры dataInstances = dataSource.getDataSet(); // Отображение количества экземпляров log.info("Количество загруженных экземпляров: " + dataInstances.numInstances()); log.info («данные:» + dataInstances.toString()); } } |
Шаг 2: Набор данных содержит 768 экземпляров. Нам нужно получить доступ к количеству атрибутов, т.е. 9.
| log.info("Количество атрибутов (признаков) в наборе данных: " + dataInstances.numAttributes()); |
Шаг 3 : Нам нужно определить целевой столбец, прежде чем мы построим модель и найдем количество классов.
| // Определение индекса метки dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Получение количества log.info("Количество классов: " + dataInstances.numClasses()); |
Шаг 4 : Теперь мы построим модель, используя простой древовидный классификатор J48.
| // Создание классификатора дерева решений J48 treeClassifier = новый J48(); treeClassifier.setOptions (новая строка [] { "-U"}); treeClassifier.buildClassifier (экземпляры данных); |
В приведенном выше коде показано, как создать необработанное дерево, состоящее из экземпляров данных, необходимых для обучения модели. Как только древовидная структура напечатана после обучения модели, мы можем определить, как правила были построены внутри.
| Плас <= 127 | масса <= 26,4 | | preg <= 7: test_negative (117.0/1.0) | | прег > 7 | | | масса <= 0: проверено_положительно (2.0) | | | масса > 0: test_negative (13.0) | масса > 26,4 | | возраст <= 28: test_negative (180,0/22,0) | | возраст > 28 | | | plas <= 99: проверено_отрицательно (55,0/10,0) | | | Плас > 99 | | | | педи <= 0,56: тест_отрицательный (84,0/34,0) | | | | педи > 0,56 | | | | | прег <= 6 | | | | | | возраст <= 30: test_positive (4.0) | | | | | | возраст > 30 | | | | | | | возраст <= 34: test_negative (7,0/1,0) | | | | | | | возраст > 34 | | | | | | | | масса <= 33,1: проверено_положительно (6,0) | | | | | | | | масса > 33,1: тест_отрицательный (4,0/1,0) | | | | | preg > 6: проверено_положительно (13.0) Плас > 127 | масса <= 29,9 | | plas <= 145: test_negative (41,0/6,0) | | Плас > 145 | | | возраст <= 25: test_negative (4.0) | | | возраст > 25 | | | | возраст <= 61 | | | | | масса <= 27,1: проверено_положительно (12,0/1,0) | | | | | масса > 27,1 | | | | | | прес <= 82 | | | | | | | педи <= 0,396: проверено_положительно (8,0/1,0)  | | | | | | | педи > 0,396: проверено_отрицательно (3,0) | | | | | | предварительно > 82: проверено_отрицательно (4.0) | | | | возраст > 61: проверено_отрицательно (4.0) | масса > 29,9 | | Плас <= 157 | | | pres <= 61: test_positive (15.0/1.0) | | | дав > 61 | | | | возраст <= 30: test_negative (40,0/13,0) | | | | возраст > 30: проверено_положительно (60,0/17,0) | | plas > 157: проверено_положительно (92,0/12,0) Количество листьев: 22 Размер дерева : 43 |
4. Апач Махаут
Mahaut — это набор алгоритмов, помогающих реализовать машинное обучение с использованием Java. Это масштабируемая структура линейной алгебры, с помощью которой разработчики могут выполнять математические и статистические анализы. Обычно его используют специалисты по данным, инженеры-исследователи и специалисты по аналитике для создания корпоративных приложений. Его масштабируемость и гибкость позволяют пользователям быстро и легко внедрять кластеризацию данных, системы рекомендаций и создавать эффективные приложения для машинного обучения.
5. Глубокое обучение4j
Deeplearning4j — это библиотека программирования, написанная на Java и предлагающая обширную поддержку глубокого обучения. Это платформа с открытым исходным кодом, которая сочетает в себе глубокие нейронные сети и глубокое обучение с подкреплением для обслуживания бизнес-операций. Он совместим со Scala, Kotlin, Apache Spark, Hadoop и другими языками JVM и средами обработки больших данных.
Обычно он используется для обнаружения закономерностей и эмоций в голосе, речи и письменном тексте. Он служит инструментом «сделай сам», который может обнаруживать расхождения в транзакциях и выполнять несколько задач. Это коммерческая распределенная библиотека с подробной документацией по API из-за ее открытого исходного кода.
Вот пример того, как вы можете реализовать машинное обучение с помощью Deeplearning4j.
Пример . Используя Deeplearning4j, мы построим модель сверточной нейронной сети (CNN) для классификации рукописных цифр с помощью библиотеки MNIST.
Шаг 1 : Загрузите набор данных, чтобы отобразить его размер.
| DataSetIterator MNISTTrain = новый MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = новый MnistDataSetIterator(batchSize,false,seed); |
Шаг 2. Убедитесь, что набор данных дает нам десять уникальных меток.
| log.info («Общее количество меток, найденных в обучающем наборе данных» + MNISTTrain.totalOutcomes()); log.info("Общее количество меток, найденных в тестовом наборе данных" + MNISTTest.totalOutcomes()); |
Шаг 3 : Теперь мы настроим архитектуру модели, используя два слоя свертки вместе со сглаженным слоем для отображения вывода.
В Deeplearning4j есть опции, которые позволяют инициализировать весовую схему.
| // Построение модели CNN MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) // случайное начальное число .l2(0.0005) // регуляризация .weightInit(WeightInit.XAVIER) // инициализация схемы весов .updater(new Adam(1e-3)) // Настройка алгоритма оптимизации .список() .layer(новый ConvolutionLayer.Builder(5, 5) //Установка шага, размера ядра и функции активации. .nIn(nChannels) .шаг(1,1) .nВыход(20) .activation(Активация.IDENTITY) .строить()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // понижающая дискретизация свертки .kernelSize(2,2) .шаг(2,2) .строить()) .layer(новый ConvolutionLayer.Builder(5, 5) // Установка шага, размера ядра и функции активации. .шаг(1,1) .nВыход(50) .activation(Активация.IDENTITY) .строить()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // понижающая дискретизация свертки .kernelSize(2,2) .шаг(2,2) .строить()) .layer(новый DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(новый OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(выходное число) .activation(Активация.SOFTMAX) .строить()) // конечный выходной слой 28×28 с глубиной 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .строить(); |
Шаг 4 : После того, как мы настроили архитектуру, мы инициализируем режим и набор обучающих данных и начнем обучение модели.
| Модель MultiLayerNetwork = новая MultiLayerNetwork (conf); // инициализируем веса модели. модель.инит(); log.info("Шаг 2: начать обучение модели"); // Устанавливаем прослушиватель каждые 10 итераций и оцениваем набор тестов в каждую эпоху model.setListeners(новый ScoreIterationListener(10), новый EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Обучение модели model.fit(MNISTTrain, nEpochs); |
Когда начнется обучение модели, у вас будет матрица путаницы точности классификации.
Вот точность модели после десяти периодов обучения:
| =========================Матрица путаницы======================= == 0 1 2 3 4 5 6 7 8 9 ————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ЭЛКИ
Среда для разработки KDD-приложений, поддерживаемая индексной структурой или ELKI, представляет собой набор встроенных алгоритмов и программ, используемых для интеллектуального анализа данных. Написанная на Java, это библиотека с открытым исходным кодом, которая включает в себя алгоритмы с широкими возможностями настройки параметров. Обычно его используют ученые-исследователи и студенты, чтобы получить представление о наборах данных. Как следует из названия, он предоставляет среду для разработки сложных программ интеллектуального анализа данных и баз данных с использованием индексной структуры.
7. ЯСАТ
Инструмент статистического анализа Java или JSAT — это библиотека GPL3, которая использует объектно-ориентированную структуру, чтобы помочь пользователям реализовать машинное обучение с помощью Java. Обычно он используется в целях самообразования студентами и разработчиками. По сравнению с другими библиотеками реализации ИИ, JSAT имеет наибольшее количество алгоритмов машинного обучения и является самым быстрым среди всех фреймворков. Отсутствие внешних зависимостей делает его очень гибким и эффективным, а также обеспечивает высокую производительность.
8. Платформа машинного обучения Encog
Encog написан на Java и C# и содержит библиотеки, помогающие реализовать алгоритмы машинного обучения. Он используется для построения генетических алгоритмов, байесовских сетей, статистических моделей, таких как скрытая модель Маркова, и многого другого.
9. Молоток
Машинное обучение для Language Toolkit или Mallet используется в обработке естественного языка (NLP). Как и большинство других платформ реализации ML, Mallet также поддерживает моделирование данных, кластеризацию данных, обработку документов, классификацию документов и т. д.
10. Искра MLlib
Spark MLlib используется предприятиями для повышения эффективности и масштабируемости управления рабочими процессами. Он обрабатывает большие объемы данных и поддерживает сильно загруженные алгоритмы машинного обучения.
Оформить заказ: идеи проекта машинного обучения
Заключение
Это подводит нас к концу статьи. Для получения дополнительной информации о концепциях машинного обучения свяжитесь с ведущими преподавателями IIIT в Бангалоре и Ливерпульском университете Джона Мурса в рамках программы upGrad Master of Science in Machine Learning & AI.
Почему мы должны использовать Java вместе с машинным обучением?
Специалистам по машинному обучению будет проще взаимодействовать с текущими репозиториями кода, если они выберут Java в качестве языка программирования для своих проектов. Это предпочтительный язык машинного обучения из-за таких функций, как простота использования, пакетные услуги, лучшее взаимодействие с пользователем, быстрая отладка и графическая иллюстрация данных. Java позволяет разработчикам машинного обучения легко масштабировать свои системы, что делает его отличным выбором для создания больших и сложных приложений машинного обучения с нуля. Виртуальная машина Java (JVM) поддерживает ряд интегрированных сред разработки (IDE), которые позволяют машинному обучению быстро разрабатывать новые инструменты.
Легко ли выучить Java?
Поскольку Java является языком высокого уровня, его легко понять. Как учащемуся, вам не нужно будет вдаваться в подробности, поскольку это хорошо структурированный объектно-ориентированный язык, который достаточно прост для новичков. Поскольку существует множество процедур, которые выполняются автоматически, вы можете быстро их освоить. Вам не нужно вдаваться в подробности о том, как там все работает. Java — это независимый от платформы язык программирования. Это позволяет программисту создать мобильное приложение, которое можно использовать на любом устройстве. Это предпочтительный язык Интернета вещей, а также лучший инструмент для разработки приложений корпоративного уровня.
Что такое ADAMS и чем он полезен для машинного обучения?
Расширенная система интеллектуального анализа данных и машинного обучения (ADAMS) — это механизм рабочих процессов под лицензией GPLv3, предназначенный для быстрого создания управляемых данными реактивных рабочих процессов и управления ими, которые можно легко включить в бизнес-процессы. Механизм рабочего процесса, работающий по принципу «лучше меньше, да лучше», лежит в основе ADAMS. ADAMS использует древовидную структуру вместо того, чтобы позволять пользователю размещать операторов (или действующих лиц на жаргоне ADAMS) на холсте, а затем вручную связывать входы и выходы. Никаких явных подключений не требуется, потому что эта структура и субъекты управления определяют, как данные передаются в процессе. Внутреннее представление объектов и вложенность подоператоров в обработчики операторов приводят к древовидной структуре. ADAMS предоставляет разнообразный набор агентов для поиска, обработки, анализа и отображения данных.