
Что такое дерево решений в интеллектуальном анализе данных? Типы, реальные примеры и приложения
Опубликовано: 2021-06-15Оглавление
Введение в интеллектуальный анализ данных
Данные часто представлены в виде необработанных данных, которые необходимо эффективно обрабатывать для преобразования в полезную информацию. Прогнозирование результатов часто зависит от процесса поиска закономерностей, аномалий или корреляций в данных. Этот процесс получил название «обнаружение знаний в базах данных».
Только в 1990-х годах был придуман термин «интеллектуальный анализ данных». Интеллектуальный анализ данных был основан на трех дисциплинах: статистике, искусственном интеллекте и машинном обучении. Автоматизированный анализ данных превратил процесс анализа из утомительного в более быстрый подход. Интеллектуальный анализ данных позволяет пользователю
- Удалите все зашумленные и хаотичные данные
- Поймите соответствующие данные и используйте их для предсказания полезной информации.
- Ускоряется процесс прогнозирования обоснованных решений .
Интеллектуальный анализ данных можно также назвать процессом выявления скрытых шаблонов информации, требующих категоризации. Только тогда данные могут быть преобразованы в полезные данные. Полезные данные могут быть загружены в хранилище данных, алгоритмы интеллектуального анализа данных, анализ данных для принятия решений.
Дерево решений в интеллектуальном анализе данных
Тип метода интеллектуального анализа данных . Дерево решений в интеллектуальном анализе данных создает модель для классификации данных. Модели построены в виде древовидной структуры и, следовательно, относятся к контролируемой форме обучения. Помимо моделей классификации, деревья решений используются для построения регрессионных моделей для прогнозирования меток классов или значений, помогающих процессу принятия решений. Дерево решений может использовать как числовые, так и категориальные данные, такие как пол, возраст и т. д.
Структура дерева решений
Структура дерева решений состоит из корневого узла, ветвей и конечных узлов. Разветвленные узлы — это результаты дерева, а внутренние узлы представляют собой проверку атрибута. Листовые узлы представляют метку класса.
Работа с деревом решений
1. Дерево решений работает при обучении с учителем как для дискретных, так и для непрерывных переменных. Набор данных разбивается на подмножества на основе наиболее значимого атрибута набора данных. Идентификация атрибута и разделение осуществляется с помощью алгоритмов.
2. Структура дерева решений состоит из корневого узла, который является значимым узлом-предиктором. Процесс разделения происходит из узлов решений, которые являются подузлами дерева. Узлы, которые не разделяются дальше, называются листовыми или конечными узлами.
3. Набор данных делится на однородные и непересекающиеся области в соответствии с нисходящим подходом. Верхний слой обеспечивает наблюдения в одном месте, которое затем разбивается на ветви. Этот процесс называется «жадным подходом» из-за того, что он фокусируется только на текущем узле, а не на будущих узлах.
4. До тех пор, пока не будет достигнут критерий остановки, дерево решений будет продолжать работать.
5. При построении дерева решений возникает много шума и выбросов. Чтобы удалить эти выбросы и зашумленные данные, применяется метод «обрезки дерева». Следовательно, повышается точность модели.
6. Точность модели проверяется на тестовом наборе, состоящем из тестовых наборов и меток классов. Точная модель определяется на основе процентного соотношения кортежей и классов наборов тестов классификации по модели.
Рисунок 1 : Пример необрезанного и обрезанного дерева
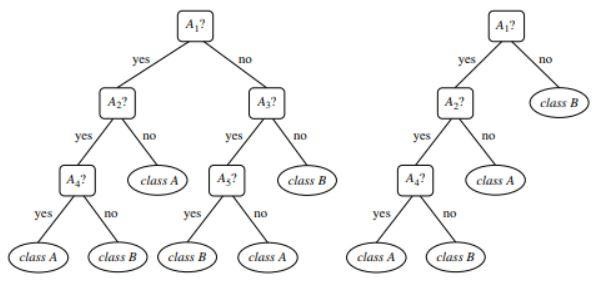
Источник
Типы дерева решений
Деревья решений приводят к разработке моделей классификации и регрессии на основе древовидной структуры. Данные разбиты на более мелкие подмножества. Результатом дерева решений является дерево с узлами решений и листовыми узлами. Ниже описаны два типа деревьев решений:
1. Классификация
Классификация включает построение моделей, описывающих важные метки классов. Они применяются в областях машинного обучения и распознавания образов. Деревья решений в машинном обучении с помощью моделей классификации приводят к обнаружению мошенничества, медицинской диагностике и т. Д. Двухэтапный процесс модели классификации включает:
- Обучение: строится классификационная модель на основе обучающих данных.
- Классификация: точность модели проверяется, а затем используется для классификации новых данных. Метки классов имеют форму дискретных значений, таких как «да» или «нет» и т. д.
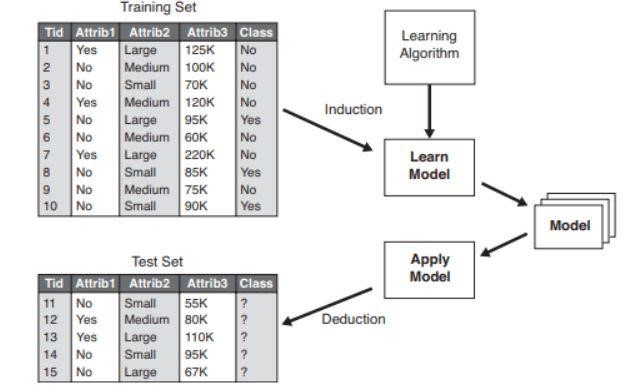
Рисунок 2 : Пример модели классификации .
Источник
2. Регрессия
Регрессионные модели используются для регрессионного анализа данных, т.е. предсказания числовых атрибутов. Их также называют непрерывными значениями. Таким образом, вместо того, чтобы предсказывать метки классов, регрессионная модель предсказывает непрерывные значения.
Список используемых алгоритмов
Алгоритм дерева решений, известный как «ID3», был разработан в 1980 году исследователем машин по имени Дж. Росс Куинлан. На смену этому алгоритму пришли другие алгоритмы, такие как C4.5, разработанный им. Оба алгоритма применяли жадный подход. Алгоритм C4.5 не использует поиск с возвратом, а деревья строятся рекурсивным методом «разделяй и властвуй» сверху вниз. Алгоритм использовал обучающий набор данных с метками классов, которые делятся на более мелкие подмножества по мере построения дерева.
- Изначально выбираются три параметра: список атрибутов, метод выбора атрибутов и раздел данных. Атрибуты обучающей выборки описаны в списке атрибутов.
- Метод выбора атрибута включает в себя метод выбора наилучшего атрибута для различения кортежей.
- Древовидная структура зависит от метода выбора атрибута.
- Построение дерева начинается с одного узла.
- Разделение кортежей происходит, когда в кортеже представлены разные метки классов. Это приведет к образованию ветвей дерева.
- Метод разделения определяет, какой атрибут следует выбрать для раздела данных. На основе этого метода ветки выращиваются из узла на основе результатов теста.
- Метод разделения и разделения выполняется рекурсивно, что в конечном итоге приводит к дереву решений для кортежей обучающего набора данных.
- Процесс формирования дерева продолжается до тех пор, пока оставшиеся кортежи не могут быть разделены дальше.
- Сложность алгоритма обозначается
п * |D| * журнал |D|
Где n — количество атрибутов в обучающем наборе данных D и |D| это количество кортежей.
Источник
Рисунок 3: Разделение дискретного значения
Списки алгоритмов, используемых в дереве решений:
ID3
Весь набор данных S рассматривается как корневой узел при формировании дерева решений. Затем выполняется итерация по каждому атрибуту и разбиение данных на фрагменты. Алгоритм проверяет и берет те атрибуты, которые не были взяты до итерации. Разделение данных в алгоритме ID3 требует много времени и не является идеальным алгоритмом, поскольку он переопределяет данные.
С4.5
Это расширенная форма алгоритма, поскольку данные классифицируются как выборки. В отличие от ID3, можно эффективно обрабатывать как непрерывные, так и дискретные значения. Присутствует метод обрезки, который удаляет нежелательные ветки.
КОРЗИНА
Алгоритм может выполнять задачи как классификации, так и регрессии. В отличие от ID3 и C4.5, точки принятия решений создаются с учетом индекса Джини. Для метода расщепления применяется жадный алгоритм, направленный на уменьшение функции стоимости. В задачах классификации индекс Джини используется в качестве функции стоимости для указания чистоты листовых узлов. В задачах регрессии сумма квадратов ошибок используется в качестве функции стоимости для поиска наилучшего прогноза.
ЧАЙД
Как следует из названия, это означает автоматический детектор взаимодействия хи-квадрата, процесс, работающий с любым типом переменных. Это могут быть номинальные, порядковые или непрерывные переменные. В деревьях регрессии используется F-тест, а в модели классификации используется критерий хи-квадрат.
МАРС
Это означает многомерные адаптивные регрессионные сплайны. Алгоритм специально реализован в задачах регрессии, где данные в основном нелинейны.

Жадное рекурсивное двоичное разделение
Метод бинарного расщепления приводит к двум ветвям. Разделение кортежей осуществляется с расчетом функции стоимости разделения. Выбирается наименьшее разделение затрат, и процесс рекурсивно выполняется для вычисления функции затрат других кортежей.
Дерево решений с реальным примером
Предсказать процесс приемлемости кредита на основе предоставленных данных.
Шаг 1: Загрузка данных
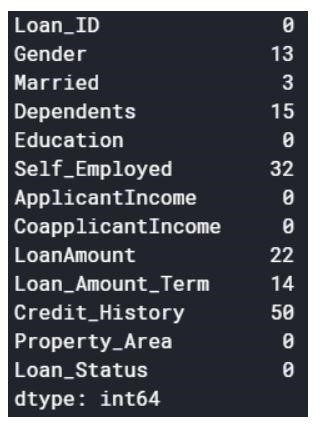
Нулевые значения могут быть удалены или заполнены некоторыми значениями. Форма исходного набора данных была (614,13), а новый набор данных после удаления нулевых значений — (480,13).
Шаг 2: посмотрите на набор данных.

Шаг 3: Разделение данных на обучающие и тестовые наборы.
Шаг 4: Соберите модель и установите набор поездов.

Перед визуализацией необходимо произвести некоторые расчеты.
Расчет 1: вычислить энтропию всего набора данных.

Расчет 2: Найдите энтропию и усиление для каждого столбца.
- Половая колонка
- Условие 1: набор данных со всеми мужчинами, а затем
р = 278, п = 116, р + п = 489
Энтропия (G = мужчина) = 0,87
- Условие 2: набор данных со всеми женщинами, а затем
р = 54, п = 32, р+п = 86
Энтропия (G = женщина) = 0,95
- Средняя информация в столбце пола

- Женатая колонка
- Условие 1: Женат = Да(1)
В этом разделении весь набор данных со статусом Женат да
р = 227, п = 84, р+п = 311
E (женат = да) = 0,84
- Условие 2: Женат = Нет(0)
В этом сплите весь набор данных со статусом Женат нет
р = 105, п = 64, р+п = 169
E (замужем = нет) = 0,957
- Средняя информация в столбце «Женаты»:
- Образовательная рубрика
- Условие 1: Образование = высшее(1)
р = 271, п = 112, р+п = 383
E (образование = высшее) = 0,87
- Условие 2: Образование = Не высшее (0)
р = 61, п = 36, р+п = 97
E (образование = не высшее) = 0,95
- Среднее значение столбца «Информация об образовании» = 0,886.
Усиление = 0,01
4) Колонка самозанятых
- Условие 1: Самозанятость = Да(1)
р = 43, п = 23, р+п = 66
E (самозанятые = да) = 0,93
- Условие 2: Самозанятость = Нет (0)
р = 289, п = 125, р+п = 414
E (самозанятые = нет) = 0,88
- Средняя информация в колонке «Самозанятые в сфере образования» = 0,886.
Усиление = 0,01
- Столбец Credit Score: столбец имеет значение 0 и 1.
- Условие 1: Кредитный рейтинг = 1
р = 325, п = 85, р+п = 410
E (Кредитный балл = 1) = 0,73
- Условие 2: Кредитный рейтинг = 0
р = 63, п = 7, р+п = 70
E(кредитный рейтинг = 0) = 0,46
- Средняя информация в столбце кредитного рейтинга = 0,69
Усиление = 0,2
Сравните все значения усиления

Кредитный рейтинг имеет самый высокий прирост. Следовательно, он будет использоваться в качестве корневого узла.
Шаг 5: Визуализируйте дерево решений

Рисунок 5: Дерево решений с критерием Джини
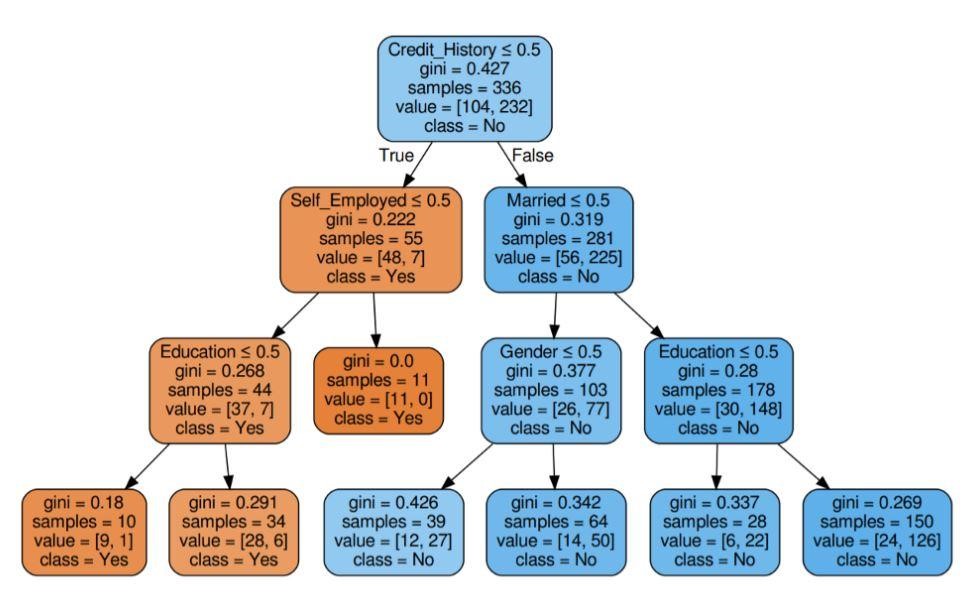 Источник
Источник
Рисунок 6: Дерево решений с энтропией критерия
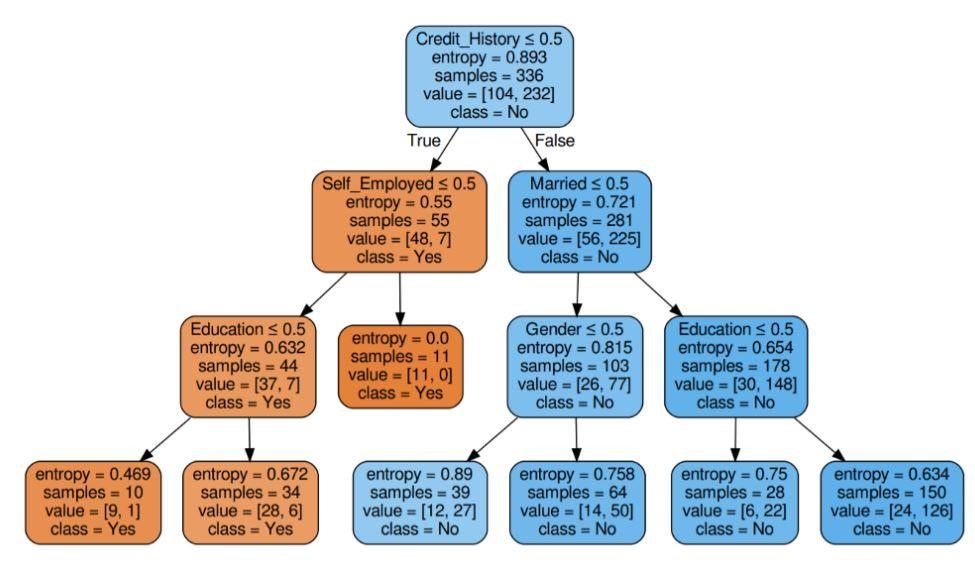
Источник
Шаг 6: Проверьте оценку модели
Набрана почти 80-процентная точность.
Список приложений
Деревья решений в основном используются информационными экспертами для проведения аналитических исследований. Их можно широко использовать в деловых целях для анализа или прогнозирования трудностей. Гибкость дерева решений позволяет использовать их в другой области:
1. Здравоохранение
Деревья решений позволяют прогнозировать, страдает ли пациент определенным заболеванием, с учетом возраста, веса, пола и т. д. Другие прогнозы включают определение эффекта лекарства с учетом таких факторов, как состав, период производства и т. д.
2. Банковский сектор
Деревья решений помогают предсказать, имеет ли человек право на получение кредита, учитывая его финансовое положение, зарплату, членов семьи и т. д. Они также могут выявлять мошенничество с кредитными картами, неуплату кредита и т. д.
3. Образовательные секторы
Отбор студента на основе его оценки успеваемости, посещаемости и т. д. может быть определен с помощью деревьев решений.
Список преимуществ
- Интерпретируемые результаты модели принятия решений могут быть представлены высшему руководству и заинтересованным сторонам.
- При построении модели дерева решений предварительная обработка данных, т.е. нормализация, масштабирование и т.п., не требуется.
- Оба типа данных — числовые и категориальные — могут обрабатываться деревом решений, которое демонстрирует более высокую эффективность использования по сравнению с другими алгоритмами.
- Отсутствие значения в данных не влияет на процесс дерева решений, что делает его гибким алгоритмом.
Что дальше?
Если вы заинтересованы в получении практического опыта в области интеллектуального анализа данных и обучении у экспертов в этой области, вы можете ознакомиться с программой upGrad Executive PG по науке о данных. Курс предназначен для любой возрастной группы в возрасте от 21 до 45 лет с минимальными критериями приемлемости 50% или эквивалентными проходными баллами при выпуске. Любые работающие профессионалы могут присоединиться к этой программе PG для руководителей, сертифицированной IIIT Bangalore.
Деревья решений в интеллектуальном анализе данных могут обрабатывать очень сложные данные. Все деревья решений имеют три жизненно важных узла или части. Давайте обсудим каждый из них ниже. Теперь, когда мы поняли, как работают деревья решений, давайте попробуем рассмотреть несколько преимуществ использования деревьев решений в интеллектуальном анализе данных.Что такое дерево решений в интеллектуальном анализе данных?
Дерево решений — это способ построения моделей в интеллектуальном анализе данных. Его можно понимать как перевернутое бинарное дерево. Он включает в себя корневой узел, несколько ветвей и конечные узлы в конце.
Каждый из внутренних узлов в дереве решений означает исследование атрибута. Каждый из разделов означает следствие этого конкретного исследования или исследования. И, наконец, каждый листовой узел представляет тег класса.
Основная цель построения дерева решений — создать идеал, который можно использовать для прогнозирования конкретного класса с помощью процедур суждения на основе предыдущих данных.
Мы начинаем с корневого узла, устанавливаем некоторые отношения с корневой переменной и делаем деления, которые согласуются с этими значениями. Основываясь на базовом выборе, мы переходим к последующим узлам. Какие важные узлы используются в деревьях решений?
Когда мы соединяем все эти узлы, мы получаем деления. Мы можем формировать деревья с различными сложностями, используя эти узлы и деления бесконечное количество раз. Каковы преимущества использования деревьев решений?
1. Когда мы сравниваем их с другими методами, деревья решений не требуют столько вычислений для обучения данных во время предварительной обработки.
2. Стабилизация информации не задействована в деревьях решений.
3. Также они даже не требуют масштабирования информации.
4. Даже если в наборе данных опущены некоторые значения, это не мешает построению деревьев.
5. Эти модели идентичны инстинктивно. Они также свободны от стресса для описания.