
Понимание дженериков TypeScript
Опубликовано: 2022-03-10В этой статье мы изучим концепцию Generics в TypeScript и рассмотрим, как можно использовать Generics для написания модульного, несвязанного и многократно используемого кода. Попутно мы кратко обсудим, как они вписываются в лучшие шаблоны тестирования, подходы к обработке ошибок и разделение доступа к домену и данным.
Реальный пример
Я хочу войти в мир дженериков, не объясняя, что они из себя представляют, а предоставляя интуитивно понятный пример того, почему они полезны. Предположим, вам поручили создать многофункциональный динамический список. Вы можете назвать это массивом, ArrayList , List , std::vector или как-то еще, в зависимости от вашего языкового фона. Возможно, эта структура данных также должна иметь встроенные или сменные буферные системы (например, возможность вставки циклического буфера). Это будет оболочка вокруг обычного массива JavaScript, чтобы мы могли работать с нашей структурой вместо простых массивов.
Непосредственная проблема, с которой вы столкнетесь, связана с ограничениями, налагаемыми системой типов. На данный момент вы не можете принять любой тип, который вы хотите, в функцию или метод в хорошем чистом виде (мы вернемся к этому утверждению позже).
Единственное очевидное решение — реплицировать нашу структуру данных для всех типов:
const intList = IntegerList.create(); intList.add(4); const stringList = StringList.create(); stringList.add('hello'); const userList = UserList.create(); userList.add(new User('Jamie')); .create() здесь может показаться произвольным, и действительно, new SomethingList() был бы более простым, но позже вы поймете, почему мы используем этот статический фабричный метод. Внутри метод create вызывает конструктор.
Это ужасно. У нас есть много логики в этой структуре коллекции, и мы явно дублируем ее для поддержки различных вариантов использования, полностью нарушая при этом принцип DRY. Когда мы решим изменить нашу реализацию, нам придется вручную распространить/отразить эти изменения во всех структурах и типах, которые мы поддерживаем, включая пользовательские типы, как в последнем примере выше. Предположим, что сама структура коллекции состоит из 100 строк — было бы кошмаром поддерживать несколько разных реализаций, единственная разница между которыми — это типы.
Немедленное решение, которое может прийти на ум, особенно если у вас есть мышление ООП, — это рассмотреть корневой «супертип», если хотите. В C#, например, существует тип по имени object , а object — это псевдоним класса System.Object . В системе типов C# все типы, предопределенные или определяемые пользователем, а также ссылочные или значимые типы, прямо или косвенно наследуются от System.Object . Это означает, что любое значение может быть присвоено переменной типа object (не залезая в стек/кучу и семантику упаковки/распаковки).
В этом случае наша проблема кажется решенной. Мы можем просто использовать any тип, и это позволит нам хранить в нашей коллекции все, что мы захотим, без необходимости дублировать структуру, и это действительно так:
const intList = AnyList.create(); intList.add(4); const stringList = AnyList.create(); stringList.add('hello'); const userList = AnyList.create(); userList.add(new User('Jamie')); Давайте посмотрим на фактическую реализацию нашего списка, используя any :
class AnyList { private values: any[] = []; private constructor (values: any[]) { this.values = values; // Some more construction work. } public add(value: any): void { this.values.push(value); } public where(predicate: (value: any) => boolean): AnyList { return AnyList.from(this.values.filter(predicate)); } public select(selector: (value: any) => any): AnyList { return AnyList.from(this.values.map(selector)); } public toArray(): any[] { return this.values; } public static from(values: any[]): AnyList { // Perhaps we perform some logic here. // ... return new AnyList(values); } public static create(values?: any[]): AnyList { return new AnyList(values ?? []); } // Other collection functions. // ... }Все методы относительно просты, но мы начнем с конструктора. Его видимость является частной, так как мы предполагаем, что наш список сложный, и мы хотим запретить произвольное построение. Мы также можем захотеть выполнить логику до построения, поэтому по этим причинам и для сохранения чистоты конструктора мы делегируем эти задачи статическим фабричным/вспомогательным методам, что считается хорошей практикой.
Предоставляются статические методы from и create . Метод from принимает массив значений, выполняет пользовательскую логику, а затем использует их для построения списка. Статический метод create принимает необязательный массив значений на тот случай, если мы хотим заполнить наш список начальными данными. «Нулевой оператор объединения» ( ?? ) используется для создания списка с пустым массивом в случае, если он не указан. Если левая часть операнда равна null или undefined , мы вернемся к правой стороне, так как в этом случае values является необязательным и, следовательно, может быть undefined . Вы можете узнать больше о нулевом объединении на соответствующей странице документации TypeScript.
Я также добавил метод select и where . Эти методы просто обертывают map и filter JavaScript соответственно. select позволяет нам проецировать массив элементов в новую форму на основе предоставленной функции выбора, а where позволяет нам отфильтровывать определенные элементы на основе предоставленной функции предиката. Метод toArray просто преобразует список в массив, возвращая ссылку на массив, которую мы храним внутри.
Наконец, предположим, что класс User содержит метод getName , который возвращает имя, а также принимает имя в качестве первого и единственного аргумента конструктора.
Примечание. Некоторые читатели узнаютWhereиSelectиз C# LINQ, но имейте в виду, что я пытаюсь сделать это простым, поэтому меня не беспокоит лень или отложенное выполнение. Это оптимизации, которые можно и нужно делать в реальной жизни.
Кроме того, в качестве интересной заметки я хочу обсудить значение слова «предикат». В дискретной математике и логике высказываний у нас есть понятие «предложение». Предложение — это некоторое утверждение, которое можно считать истинным или ложным, например, «четыре делится на два». «Предикат» — это предложение, которое содержит одну или несколько переменных, поэтому истинность предложения зависит от истинности этих переменных. Вы можете думать об этом как о функции, такой какP(x) = x is divisible by two, поскольку нам нужно знать значениеx, чтобы определить, является ли утверждение истинным или ложным. Вы можете узнать больше о логике предикатов здесь.
Есть несколько проблем, которые могут возникнуть при использовании any . Компилятор TypeScript ничего не знает об элементах внутри списка/внутреннего массива, поэтому он не предоставит никакой помощи внутри where или select или при добавлении элементов:
// Providing seed data. const userList = AnyList.create([new User('Jamie')]); // This is fine and expected. userList.add(new User('Tom')); userList.add(new User('Alice')); // This is an acceptable input to the TS Compiler, // but it's not what we want. We'll definitely // be surprised later to find strings in a list // of users. userList.add('Hello, World!'); // Also acceptable. We have a large tuple // at this point rather than a homogeneous array. userList.add(0); // This compiles just fine despite the spelling mistake (extra 's'): // The type of `users` is any. const users = userList.where(user => user.getNames() === 'Jamie'); // Property `ssn` doesn't even exist on a `user`, yet it compiles. users.toArray()[0].ssn = '000000000'; // `usersWithId` is, again, just `any`. const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Oops, it's "id" not "ID", but TS doesn't help us. // We compile just fine. console.log(usersWithId.toArray()[0].ID); Поскольку TypeScript знает только, что тип всех элементов массива — any , он не может помочь нам во время компиляции с несуществующими свойствами или функцией getNames , которая даже не существует, поэтому этот код приведет к множеству неожиданных ошибок во время выполнения. .
Честно говоря, все начинает выглядеть довольно мрачно. Мы пытались реализовать нашу структуру данных для каждого конкретного типа, который мы хотели поддерживать, но быстро поняли, что это никоим образом не поддается сопровождению. Затем мы подумали, что достигнем чего-то, используя any , что аналогично зависимости от корневого супертипа в цепочке наследования, из которой происходят все типы, но мы пришли к выводу, что с этим методом мы теряем безопасность типов. Каково же решение?
Оказывается, в начале статьи я наврал (вроде):
«На данный момент вы не можете принять любой тип, который вы хотите, в функцию или метод в хорошем чистом виде».
Вы на самом деле можете, и вот тут-то и появляются дженерики. Заметьте, я сказал «сейчас», потому что я предполагал, что мы не знали о дженериках на тот момент в статье.
Я начну с демонстрации полной реализации нашей структуры List с помощью Generics, а затем мы сделаем шаг назад, обсудим, что они собой представляют на самом деле, и более формально определим их синтаксис. Я назвал его TypedList , чтобы отличать его от нашего предыдущего AnyList :
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. }Попробуем еще раз совершить те же ошибки, что и раньше:
// Here's the magic. `TypedList` will operate on objects // of type `User` due to the `<User>` syntax. const userList = TypedList.create<User>([new User('Jamie')]); // The compiler expects this. userList.add(new User('Tom')); userList.add(new User('Alice')); // Argument of type '0' is not assignable to parameter // of type 'User'. ts(2345) userList.add(0); // Property 'getNames' does not exist on type 'User'. // Did you mean 'getName'? ts(2551) // Note: TypeScript infers the type of `users` to be // `TypedList<User>` const users = userList.where(user => user.getNames() === 'Jamie'); // Property 'ssn' does not exist on type 'User'. ts(2339) users.toArray()[0].ssn = '000000000'; // TypeScript infers `usersWithId` to be of type // `TypedList<`{ id: string, name: string }> const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Property 'ID' does not exist on type '{ id: string; name: string; }'. // Did you mean 'id'? ts(2551) console.log(usersWithId.toArray()[0].ID)Как видите, компилятор TypeScript активно помогает нам с безопасностью типов. Все эти комментарии являются ошибками, которые я получаю от компилятора при попытке скомпилировать этот код. Обобщения позволили нам указать тип, с которым мы хотим разрешить работать нашему списку, и исходя из этого, TypeScript может указать типы всего, вплоть до свойств отдельных объектов в массиве.
Типы, которые мы предоставляем, могут быть настолько простыми или сложными, насколько мы хотим. Здесь вы видите, что мы можем передавать как примитивы, так и сложные интерфейсы. Мы также можем передавать другие массивы, классы или что-то еще:
const numberList = TypedList.create<number>(); numberList.add(4); const stringList = TypedList.create<string>(); stringList.add('Hello, World'); // Example of a complex type interface IAircraft { apuStatus: ApuStatus; inboardOneRPM: number; altimeter: number; tcasAlert: boolean; pushBackAndStart(): Promise<void>; ilsCaptureGlidescope(): boolean; getFuelStats(): IFuelStats; getTCASHistory(): ITCASHistory; } const aircraftList = TypedList.create<IAircraft>(); aircraftList.add(/* ... */); // Aggregate and generate report: const stats = aircraftList.select(a => ({ ...a.getFuelStats(), ...a.getTCASHistory() })); Необычное использование T и U , а также <T> и <U> в реализации TypedList<T> — это примеры универсальных шаблонов в действии. Выполнив нашу директиву о построении структуры коллекции, безопасной для типов, мы пока оставим этот пример и вернемся к нему, как только поймем, что такое дженерики, как они работают и каков их синтаксис. Когда я изучаю новую концепцию, мне всегда нравится начинать со сложного примера ее использования, чтобы, когда я приступаю к изучению основ, я мог установить связи между основными темами и существующим примером, который у меня есть. голова.
Что такое дженерики?
Простой способ понять обобщения — рассматривать их как относительно аналогичные заполнителям или переменным, но для типов. Это не означает, что вы можете выполнять те же операции с заполнителем универсального типа, что и с переменной, но переменную универсального типа можно рассматривать как некоторый заполнитель, представляющий конкретный тип, который будет использоваться в будущем. То есть использование Generics — это метод написания программ с точки зрения типов, которые должны быть указаны в более поздний момент времени. Причина, по которой это полезно, заключается в том, что это позволяет нам создавать структуры данных, которые можно повторно использовать для различных типов, с которыми они работают (или которые не зависят от типа).
Это не самое лучшее из объяснений, поэтому, выражаясь более простыми словами, как мы видели, в программировании часто требуется построить структуру функции/класса/данных, которая будет работать с определенным типом, но одинаково часто такая структура данных должна работать с множеством различных типов. Если бы мы застряли в ситуации, когда нам нужно было бы статически объявить конкретный тип, с которым будет работать структура данных, в то время, когда мы проектируем структуру данных (во время компиляции), мы бы очень быстро обнаружили, что нам нужно перестроить эти структуры почти точно таким же образом для каждого типа, который мы хотим поддерживать, как мы видели в примерах выше.
Обобщения помогают нам решить эту проблему, позволяя нам отложить требование для конкретного типа до тех пор, пока он не станет известен.
Дженерики в TypeScript
Теперь у нас есть довольно органичное представление о том, почему дженерики полезны, и мы видели несколько сложный пример их использования на практике. Для большинства реализация TypedList<T> , вероятно, уже имеет большой смысл, особенно если вы пришли из языка со статической типизацией, но я помню, как мне было трудно понять концепцию, когда я только учился, поэтому я хочу постройте этот пример, начав с простых функций. Общеизвестно, что концепции, связанные с абстракцией в программном обеспечении, трудно усвоить, поэтому, если понятие универсальных шаблонов еще не совсем прижилось, это совершенно нормально, и, надеюсь, к концу этой статьи эта идея будет, по крайней мере, несколько интуитивной.
Чтобы понять этот пример, давайте начнем с простых функций. Мы начнем с «Функции идентификации», которую любят использовать в большинстве статей, включая саму документацию по TypeScript.
«Функция идентичности» в математике — это функция, которая напрямую сопоставляет свои входные данные с выходными, например, f(x) = x . Что вы вкладываете, то и получаете. Мы можем представить это в JavaScript как:
function identity(input) { return input; }Или, более кратко:
const identity = input => input; Попытка перенести это на TypeScript возвращает те же проблемы с системой типов, которые мы видели раньше. Решения заключаются в наборе с any , что, как мы знаем, редко бывает хорошей идеей, дублированием/перегрузкой функции для каждого типа (разбивает DRY) или использованием дженериков.
С последним вариантом мы можем представить функцию следующим образом:
// ES5 Function function identity<T>(input: T): T { return input; } // Arrow Function const identity = <T>(input: T): T => input; console.log(identity<number>(5)); // 5 console.log(identity<string>('hello')); // hello Синтаксис <T> здесь объявляет эту функцию универсальной. Точно так же, как функция позволяет нам передать произвольный входной параметр в свой список аргументов, с универсальной функцией мы также можем передать параметр произвольного типа.
Часть <T> сигнатуры identity<T>(input: T): T и <T>(input: T): T в обоих случаях объявляет, что рассматриваемая функция примет один параметр универсального типа с именем T . Точно так же, как переменные могут иметь любое имя, так же могут быть и наши общие заполнители, но принято использовать заглавную букву «Т» («Т» для «Типа») и двигаться вниз по алфавиту по мере необходимости. Помните, что T — это тип, поэтому мы также заявляем, что примем один аргумент функции input имени с типом T и что наша функция вернет тип T Это все, что говорит подпись. Попробуйте представить T = string в своей голове — замените все T на string в этих подписях. Видишь, ничего такого волшебного не происходит? Видите, насколько это похоже на нестандартный способ использования функций каждый день?
Помните, что вы уже знаете о TypeScript и сигнатурах функций. Все, что мы говорим, это то, что T — это произвольный тип, который пользователь предоставляет при вызове функции, точно так же, как input — это произвольное значение, которое пользователь предоставляет при вызове функции. В этом случае input должен быть любым, что имеет этот тип T , когда функция вызывается в будущем .
Затем, в «будущем», в двух операторах журнала мы «передаем» конкретный тип, который мы хотим использовать, точно так же, как мы делаем переменную. Обратите внимание на переключатель в формулировке здесь — в начальной форме <T> signature при объявлении нашей функции она является универсальной, то есть работает с универсальными типами или типами, которые будут указаны позже. Это потому, что мы не знаем, какой тип захочет использовать вызывающая сторона, когда мы на самом деле напишем функцию. Но когда вызывающий объект вызывает функцию, он/она точно знает, с каким типом (типами) он хочет работать, в данном случае это string и number .
Вы можете представить себе идею объявления функции журнала таким образом в сторонней библиотеке — автор библиотеки понятия не имеет, какие типы захотят использовать разработчики, использующие библиотеку, поэтому они делают функцию универсальной, по существу откладывая необходимость для конкретных типов, пока они фактически не известны.
Я хочу подчеркнуть, что вы должны думать об этом процессе так же, как и о передаче переменной в функцию, чтобы получить более интуитивное понимание. Все, что мы сейчас делаем, — это также передаем тип.
В тот момент, когда мы вызвали функцию с number параметром, исходная подпись во всех смыслах и целях могла рассматриваться как identity(input: number): number . И в том месте, где мы вызвали функцию со string параметром, опять же, исходная подпись могла бы быть такой же, как identity(input: string): string . Вы можете себе представить, что при выполнении вызова каждый универсальный T заменяется конкретным типом, который вы предоставляете в этот момент.
Изучение общего синтаксиса
Существуют разные синтаксис и семантика для указания дженериков в контексте функций ES5, функций стрелок, псевдонимов типов, интерфейсов и классов. Мы рассмотрим эти различия в этом разделе.
Изучение общего синтаксиса — функции
Вы уже видели несколько примеров универсальных функций, но важно отметить, что универсальная функция может принимать более одного параметра универсального типа, как и переменные. Вы можете запросить один, два, три или сколько угодно типов, разделенных запятыми (опять же, как входные аргументы).
Эта функция принимает три типа ввода и случайным образом возвращает один из них:
function randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } // Calling the function. // `value` has type `string | number | IAircraft` const value = randomValue< string, number, IAircraft >( myString, myNumber, myAircraft );Вы также можете видеть, что синтаксис немного отличается в зависимости от того, используем ли мы функцию ES5 или функцию стрелки, но обе объявляют параметры типа в подписи:
const randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } Имейте в виду, что на типы не накладывается «ограничение уникальности» — вы можете передать любую комбинацию, которую пожелаете, например, две string s и number . Кроме того, точно так же, как входные аргументы находятся «в области действия» тела функции, так же как и параметры универсального типа. Первый пример демонстрирует, что у нас есть полный доступ к T , U и V из тела функции, и мы использовали их для объявления локальной тройки.
Вы можете себе представить, что эти дженерики работают в определенном «контексте» или в течение определенного «времени жизни», и это зависит от того, где они объявлены. Обобщения для функций находятся в области действия сигнатуры и тела функции (и замыканий, созданных вложенными функциями), в то время как обобщения, объявленные в классе, интерфейсе или псевдониме типа, находятся в области действия для всех членов класса, интерфейса или псевдонима типа.
Понятие дженериков для функций не ограничивается «свободными функциями» или «плавающими функциями» (функциями, не привязанными к объекту или классу, термин C++), но они также могут использоваться в функциях, присоединенных к другим структурам.
Мы можем поместить это randomValue в класс и назвать его точно так же:
class Utils { public randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // ... } // Or, as an arrow function: public randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // ... } }Мы также можем поместить определение в интерфейс:
interface IUtils { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }Или внутри псевдонима типа:
type Utils = { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }Как и раньше, эти параметры универсального типа находятся «в области действия» для этой конкретной функции — они не относятся к классу, интерфейсу или псевдониму типа. Они существуют только в пределах конкретной функции, на которой они указаны. Чтобы общий тип был общим для всех членов структуры, вы должны аннотировать само имя структуры, как мы увидим ниже.
Изучение общего синтаксиса — псевдонимы типов
С псевдонимами типов общий синтаксис используется для имени псевдонима.
Например, некоторая функция «действия», которая принимает значение, возможно, изменяет это значение, но возвращает void, может быть записана так:
type Action<T> = (val: T) => void;Примечание . Это должно быть знакомо разработчикам C#, которые понимают делегат Action<T>.
Или можно объявить функцию обратного вызова, которая принимает как ошибку, так и значение:
type CallbackFunction<T> = (err: Error, data: T) => void; const usersApi = { get(uri: string, cb: CallbackFunction<User>) { /// ... } }С нашими знаниями об универсальных функциях мы могли бы пойти дальше и сделать функцию объекта API универсальной:
type CallbackFunction<T> = (err: Error, data: T) => void; const api = { // `T` is available for use within this function. get<T>(uri: string, cb: CallbackFunction<T>) { /// ... } } Теперь мы говорим, что функция get принимает какой-то параметр универсального типа, и что бы это ни было, CallbackFunction получает его. По сути, мы «передали» T , который входит в get , как T для CallbackFunction . Возможно, это будет иметь больше смысла, если мы изменим имена:
type CallbackFunction<TData> = (err: Error, data: TData) => void; const api = { get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } } Префикс параметров типа с T — это просто соглашение, точно так же, как интерфейсы с префиксом I или переменные-члены с _ . Здесь вы можете видеть, что CallbackFunction принимает некоторый тип ( TData ), который представляет полезные данные, доступные для функции, в то время как get принимает параметр типа, который представляет тип/форму данных HTTP-ответа ( TResponse ). HTTP-клиент ( api ), подобно Axios, использует любой TResponse в качестве TData для CallbackFunction . Это позволяет вызывающей стороне API выбирать тип данных, которые они будут получать от API (предположим, где-то еще в конвейере у нас есть промежуточное ПО, которое анализирует JSON в DTO).
Если бы мы хотели пойти немного дальше, мы могли бы изменить параметры универсального типа в CallbackFunction , чтобы также принимать пользовательский тип ошибки:
type CallbackFunction<TData, TError> = (err: TError, data: TData) => void;И точно так же, как вы можете сделать аргументы функции необязательными, вы можете сделать это и с параметрами типа. В случае, если пользователь не укажет тип ошибки, мы установим его в конструктор ошибок по умолчанию:
type CallbackFunction<TData, TError = Error> = (err: TError, data: TData) => void;Теперь мы можем указать тип функции обратного вызова несколькими способами:
const apiOne = { // `Error` is used by default for `CallbackFunction`. get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } }; apiOne.get<string>('uri', (err: Error, data: string) => { // ... }); const apiTwo = { // Override the default and use `HttpError` instead. get<TResponse>(uri: string, cb: CallbackFunction<TResponse, HttpError>) { // ... } }; apiTwo.get<string>('uri', (err: HttpError, data: string) => { // ... });Эта идея параметров по умолчанию приемлема для функций, классов, интерфейсов и т. д. Она не ограничивается только псевдонимами типов. Во всех примерах, которые мы видели до сих пор, мы могли присвоить любому параметру типа значение по умолчанию. Псевдонимы типов, как и функции, могут принимать любое количество параметров универсального типа.
Изучение общего синтаксиса — интерфейсы
Как вы видели, параметр универсального типа может быть предоставлен функции в интерфейсе:
interface IUselessFunctions { // Not generic printHelloWorld(); // Generic identity<T>(t: T): T; } В этом случае T существует только для функции identity в качестве ее входного и возвращаемого типа.
Мы также можем сделать параметр типа доступным для всех членов интерфейса, точно так же, как с классами и псевдонимами типов, указав, что сам интерфейс принимает универсальный тип. Мы поговорим о шаблоне репозитория чуть позже, когда будем обсуждать более сложные варианты использования дженериков, так что ничего страшного, если вы никогда о нем не слышали. Шаблон репозитория позволяет нам абстрагироваться от нашего хранилища данных, чтобы сделать бизнес-логику независимой от постоянства. Если вы хотите создать общий интерфейс репозитория, работающий с неизвестными типами сущностей, мы могли бы ввести его следующим образом:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; removeById(id: string): Promise<void>; }Примечание . Существует много разных мнений по поводу репозиториев, от определения Мартина Фаулера до определения DDD Aggregate. Я просто пытаюсь показать вариант использования дженериков, поэтому меня не слишком заботит полная корректность реализации. Определенно есть что сказать по поводу отказа от использования универсальных репозиториев, но мы поговорим об этом позже.
Как вы можете видеть здесь, IRepository — это интерфейс, который содержит методы для хранения и извлечения данных. Он работает с некоторым параметром универсального типа с именем T , и T используется в качестве входных данных для add и updateById , а также результата разрешения обещания findById .
Имейте в виду, что существует очень большая разница между принятием параметра универсального типа в имени интерфейса и разрешением каждой функции принимать параметр универсального типа. Первое, как мы сделали здесь, гарантирует, что каждая функция в интерфейсе работает с одним и тем же типом T То есть для IRepository<User> каждый метод, использующий T в интерфейсе, теперь работает с объектами User . С последним методом каждой функции будет разрешено работать с любым типом, который она хочет. Было бы очень странно иметь возможность только добавлять User в репозиторий, но иметь возможность, например, получать Policies или Orders обратно, что является потенциальной ситуацией, в которой мы оказались бы, если бы мы не могли обеспечить, чтобы тип был един для всех методов.
Данный интерфейс может содержать не только общий тип, но и типы, уникальные для его членов. Например, если бы мы хотели имитировать массив, мы могли бы ввести такой интерфейс:
interface IArray<T> { forEach(func: (elem: T, index: number) => void): this; map<U>(func: (elem: T, index: number) => U): IArray<U>; } В этом случае и forEach , и map имеют доступ к T по имени интерфейса. Как уже говорилось, вы можете себе представить, что T находится в области действия для всех членов интерфейса. Несмотря на это, ничто не мешает отдельным функциям также принимать собственные параметры типа. Функция map делает это с U . Теперь map имеет доступ как к T , так и к U Нам пришлось назвать параметр другой буквой, например U , потому что T уже занято, и нам не нужна коллизия имен. Как и его название, map «сопоставляет» элементы типа T внутри массива с новыми элементами типа U Он отображает T s в U s. Возвращаемое значение этой функции — это сам интерфейс, теперь работающий с новым типом U , так что мы можем несколько имитировать свободный синтаксис JavaScript для массивов.
Мы вскоре увидим пример мощи обобщений и интерфейсов, когда будем реализовывать шаблон репозитория и обсуждать внедрение зависимостей. Опять же, мы можем принять столько общих параметров, а также выбрать один или несколько параметров по умолчанию, расположенных в конце интерфейса.
Изучение общего синтаксиса — классы
Точно так же, как мы можем передать параметр универсального типа псевдониму типа, функции или интерфейсу, мы также можем передать один или несколько параметров классу. После этого этот параметр типа будет доступен для всех членов этого класса, а также для расширенных базовых классов или реализованных интерфейсов.
Давайте создадим еще один класс коллекции, но немного проще, чем TypedList выше, чтобы мы могли увидеть взаимодействие между универсальными типами, интерфейсами и членами. Чуть позже мы увидим пример передачи типа базовому классу и наследования интерфейса.
Наша коллекция будет просто поддерживать базовые функции CRUD в дополнение к map и методу forEach .
class Collection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): Collection<U> { return new Collection<U>(this.elements.map(func)); } } const stringCollection = new Collection<string>(); stringCollection.add('Hello, World!'); const numberCollection = new Collection<number>(); numberCollection.add(3.14159); const aircraftCollection = new Collection<IAircraft>(); aircraftCollection.add(myAircraft); Давайте обсудим, что здесь происходит. Класс Collection принимает один параметр универсального типа с именем T . Этот тип становится доступным для всех членов класса. Мы используем его для определения частного массива типа T[] , который мы также могли бы обозначить в форме Array<T> (Снова см. Generics для обычного ввода массива TS). Кроме того, большинство функций-членов каким-то образом используют этот T , например, контролируя добавляемые и удаляемые типы или проверяя, содержит ли коллекция элемент.
Наконец, как мы уже видели, для метода map требуется собственный параметр универсального типа. We need to define in the signature of map that some type T is mapped to some type U through a callback function, thus we need a U . That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named U , and that'd be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can't do is have another function that accepts a generic parameter named T , for that'd conflict with the T from the class signature.

You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with string s, number s, and IAircraft s.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we'll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let's define it:
interface ICollection<T> { add(t: T): void; contains(t: T): boolean; remove(t: T): void; forEach(func: (elem: T, index: number) => void): void; map<U>(func: (elem: T, index: number) => U): ICollection<U>; }Now, let's suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.
class InMemoryCollection<T> implements ICollection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): ICollection<U> { return new InMemoryCollection<U>(this.elements.map(func)); } } The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don't know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type T , and whatever it is, it's immediately passed to the interface, and the interface methods are implemented using that type.
Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the // tutorial. const userCollection: ICollection<User> = new InMemoryCollection<User>(); function manageUsers(userCollection: ICollection<User>) { userCollection.add(new User()); } With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection<T> (for example) with InMemoryCollection<T> instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
At this point, we should have worked up to the point where we can understand that first TypedList<T> example. Here it is again:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. } The class itself accepts a generic type parameter named T , and all members of the class are provided access to it. The instance method select and the two static methods from and create , which are factories, accept their own generic type parameter named U .
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[] . When it calls the list's constructor with new , it passes that type U as the generic parameter to TypedList . This creates a new list where the type of every element is U . It is exactly the same as how we could call the constructor of our collection class earlier with new Collection<SomeType>() . The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I've stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass { private constructor (t: number) {} public static create(u: number) { return new MyClass(u); } } const myClass = MyClass.create(2.17); This is very similar to what is happening with the more-involved example, the difference being that we're working on generic type parameters, not variables. Here, 2.17 becomes the u in create , which ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass<T> { private constructor () {} public static create<U>() { return new MyClass<U>(); } } const myClass = MyClass.create<number>(); The U passed to create is ultimately passed in as the T for MyClass<T> . When calling create , we provided number as U , thus now U = number . We put that U (which, again, is just number ) into the T for MyClass<T> , so that MyClass<T> effectively becomes MyClass<number> . The benefit of generics is that we're opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U . It uses that type U , just like create , to construct a new instance of the TypedList class, now passing in that type U for T .
The where instance method performs a filtering operation based upon a predicate function. There's no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript's array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don't satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type T , which is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T . The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we'll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we've used generics, we've explicitly defined the type we're operating on. It's important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number :
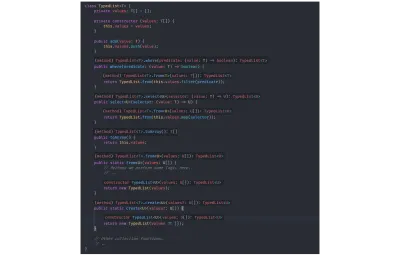
// `value` is inferred as type `number`. const value = identity(getRandomNumber()); Чтобы продемонстрировать вывод типов, я ранее удалил все технически ненужные аннотации типов из нашей структуры TypedList , и вы можете видеть на рисунках ниже, что TSC по-прежнему правильно выводит все типы:
TypedList без лишних объявлений типов:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T) { this.values.push(value); } public where(predicate: (value: T) => boolean) { return TypedList.from(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U) { return TypedList.from(this.values.map(selector)); } public toArray() { return this.values; } public static from<U>(values: U[]) { // Perhaps we perform some logic here. // ... return new TypedList(values); } public static create<U>(values?: U[]) { return new TypedList(values ?? []); } // Other collection functions. // .. } Основываясь на значениях, возвращаемых функцией, и на основе входных типов, переданных from конструктора, TSC понимает всю информацию о типах. На изображении ниже я склеил вместе несколько изображений, которые показывают расширение языка Visual Studio Code TypeScript (и, следовательно, компилятор), выводящее все типы:
Общие ограничения
Иногда мы хотим наложить ограничение на универсальный тип. Возможно, мы не можем поддерживать все существующие типы, но мы можем поддерживать их подмножество. Допустим, мы хотим создать функцию, которая возвращает длину некоторой коллекции. Как видно выше, у нас может быть много разных типов массивов/коллекций, от Array JavaScript по умолчанию до наших пользовательских. Как сообщить нашей функции, что к некоторому универсальному типу привязано свойство length ? Точно так же, как ограничить конкретные типы, которые мы передаем в функцию, теми, которые содержат нужные нам данные? Например, такой пример, как этот, не будет работать:
function getLength<T>(collection: T): number { // Error. TS does not know that a type T contains a `length` property. return collection.length; }Ответ заключается в использовании общих ограничений. Мы можем определить интерфейс, описывающий нужные нам свойства:
interface IHasLength { length: number; }Теперь, определяя нашу универсальную функцию, мы можем ограничить универсальный тип тем, который расширяет этот интерфейс:
function getLength<T extends IHasLength>(collection: T): number { // Restricting `collection` to be a type that contains // everything within the `IHasLength` interface. return collection.length; }Реальные примеры
В следующих двух разделах мы обсудим несколько реальных примеров универсальных шаблонов, которые создают более элегантный и понятный код. Мы видели много тривиальных примеров, но я хочу обсудить некоторые подходы к обработке ошибок, шаблонам доступа к данным и внешнему интерфейсу состояния/реквизитов React.
Реальные примеры — подходы к обработке ошибок
JavaScript содержит первоклассный механизм обработки ошибок, как и большинство языков программирования — try / catch . Несмотря на это, я не очень в восторге от того, как он выглядит при использовании. Это не значит, что я не использую этот механизм, но я стараюсь скрывать его, насколько это возможно. Абстрагируясь от try / catch , я также могу повторно использовать логику обработки ошибок в операциях с высокой вероятностью неудачи.
Предположим, мы создаем некоторый уровень доступа к данным. Это уровень приложения, в котором реализована логика сохраняемости для работы с методом хранения данных. Если мы выполняем операции с базой данных и если эта база данных используется в сети, могут возникнуть определенные ошибки, характерные для БД, и временные исключения. Одной из причин наличия выделенного уровня доступа к данным является абстрагирование базы данных от бизнес-логики. Из-за этого у нас не может быть таких ошибок, специфичных для БД, которые выбрасываются вверх по стеку и из этого уровня. Сначала нам нужно их обернуть.
Давайте посмотрим на типичную реализацию, которая будет использовать try / catch :
async function queryUser(userID: string): Promise<User> { try { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Переключение на true — это просто метод, позволяющий использовать операторы switch case для моей логики проверки ошибок, в отличие от необходимости объявлять цепочку if/else if — трюк, который я впервые услышал от @Jeffijoe.
Если у нас есть несколько таких функций, мы должны реплицировать эту логику переноса ошибок, что является очень плохой практикой. Это выглядит неплохо для одной функции, но для многих это будет кошмар. Чтобы абстрагироваться от этой логики, мы можем обернуть ее в пользовательскую функцию обработки ошибок, которая будет передавать результат, но перехватывать и оборачивать любые ошибки, если они возникнут:
async function withErrorHandling<T>( dalOperation: () => Promise<T> ): Promise<T> { try { // This unwraps the promise and returns the type `T`. return await dalOperation(); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Чтобы убедиться, что это имеет смысл, у нас есть функция withErrorHandling , которая принимает некоторый параметр универсального типа T Этот T представляет собой тип значения успешного разрешения обещания, которое мы ожидаем вернуть из функции обратного вызова dalOperation . Обычно, поскольку мы просто возвращаем результат, возвращаемый асинхронной функцией dalOperation , нам не нужно await его, поскольку это заключало бы функцию во второе постороннее обещание, и мы могли бы оставить await вызывающему коду. В этом случае нам нужно поймать любые ошибки, поэтому требуется await .
Теперь мы можем использовать эту функцию, чтобы обернуть наши операции DAL из более ранних:
async function queryUser(userID: string) { return withErrorHandling<User>(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); }); }И вот мы идем. У нас есть типобезопасная и безошибочная функция пользовательского запроса.
Кроме того, как вы видели ранее, если у компилятора TypeScript достаточно информации для неявного вывода типов, вам не нужно передавать их явно. В этом случае TSC знает, что возвращаемый функцией результат является общим типом. Таким образом, если бы mapper.toDomain(user) возвращал тип User , вам вообще не нужно было бы передавать этот тип:
async function queryUser(userID: string) { return withErrorHandling(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(user); }); } Еще один подход к обработке ошибок, который мне нравится, — это использование монадических типов. Либо Монада является алгебраическим типом данных формы Either<T, U> , где T может представлять тип ошибки, а U может представлять тип отказа. Использование монадических типов напоминает функциональное программирование, и главное преимущество заключается в том, что ошибки становятся безопасными для типов — обычная сигнатура функции ничего не сообщает вызывающей стороне API о том, какие ошибки может выдать эта функция. Предположим, мы выдаем ошибку NotFound изнутри queryUser . Подпись queryUser(userID: string): Promise<User> ничего нам об этом не говорит. Но такая подпись, как queryUser(userID: string): Promise<Either<NotFound, User>> абсолютно подходит. Я не буду объяснять в этой статье, как работают такие монады, как монада «Либо», потому что они могут быть довольно сложными, и есть множество методов, которые они должны считать монадическими, например, отображение/связывание. Если вы хотите узнать о них больше, я бы порекомендовал два доклада Скотта Влашина NDC, здесь и здесь, а также доклад Дэниела Чамбера здесь. Этот сайт, а также эти сообщения в блоге тоже могут быть полезны.
Реальные примеры — шаблон репозитория
Давайте рассмотрим еще один вариант использования, в котором универсальные шаблоны могут быть полезны. Большинство серверных систем должны каким-то образом взаимодействовать с базой данных — это может быть реляционная база данных, такая как PostgreSQL, база данных документов, такая как MongoDB, или, возможно, даже графовая база данных, такая как Neo4j.
Поскольку, как разработчики, мы должны стремиться к слабосвязанным и высокосвязным проектам, было бы справедливым аргументом рассмотреть возможные последствия миграции систем баз данных. Также было бы справедливо учитывать, что разные потребности в доступе к данным могут предпочитать разные подходы к доступу к данным (это немного начинает проникать в CQRS, что является шаблоном для разделения операций чтения и записи. См. сообщение Мартина Фаулера и список MSDN, если хотите Книги «Внедрение предметно-ориентированного проектирования» Вона Вернона и «Шаблоны, принципы и практики предметно-ориентированного проектирования» Скотта Миллета также хорошо читаются). Мы также должны рассмотреть автоматизированное тестирование. В большинстве руководств, объясняющих создание серверных систем с помощью Node.js, код доступа к данным смешивается с бизнес-логикой и маршрутизацией. То есть они, как правило, используют MongoDB с ODM Mongoose, используя подход Active Record и не имея четкого разделения задач. Такие методы не одобряются в больших приложениях; в тот момент, когда вы решите, что хотите перенести одну систему баз данных на другую, или в тот момент, когда вы поймете, что предпочитаете другой подход к доступу к данным, вы должны вырвать этот старый код доступа к данным, заменить его новым кодом, и надеюсь, вы не внесли никаких ошибок в маршрутизацию и бизнес-логику.
Конечно, вы можете возразить, что модульные и интеграционные тесты предотвратят регрессию, но если эти тесты окажутся связанными и зависимыми от деталей реализации, от которых они не должны зависеть, они тоже, скорее всего, сломаются в процессе.
Распространенным подходом к решению этой проблемы является шаблон репозитория. В нем говорится, что для вызова кода мы должны позволить нашему уровню доступа к данным имитировать простую коллекцию объектов или доменных сущностей в памяти. Таким образом, мы можем позволить бизнесу управлять дизайном, а не базой данных (моделью данных). Для больших приложений становится полезным архитектурный шаблон под названием Domain-Driven Design. Репозитории в шаблоне репозитория — это компоненты, чаще всего классы, которые инкапсулируют и содержат всю логику для доступа к источникам данных. Благодаря этому мы можем централизовать код доступа к данным на одном уровне, что упрощает его тестирование и повторное использование. Кроме того, мы можем поместить слой сопоставления между ними, что позволит нам сопоставить модели предметной области, не зависящие от базы данных, с серией сопоставлений таблиц один к одному. Каждая функция, доступная в репозитории, может дополнительно использовать другой метод доступа к данным, если вы того пожелаете.
Существует множество различных подходов и семантики к репозиториям, единицам работы, транзакциям базы данных между таблицами и т. д. Поскольку это статья о универсальных шаблонах, я не хочу слишком углубляться в суть, поэтому я приведу здесь простой пример, но важно отметить, что разные приложения имеют разные потребности. Например, репозиторий для агрегатов DDD будет сильно отличаться от того, что мы делаем здесь. То, как я изображаю реализации репозитория здесь, отличается от того, как я реализую их в реальных проектах, потому что в них много недостающей функциональности и используются менее желательные архитектурные приемы.
Предположим, у нас есть Users и Tasks в качестве моделей предметной области. Это могут быть просто POTO — обычные объекты TypeScript. В них нет встроенной базы данных, поэтому вы не будете вызывать User.save() , например, как при использовании Mongoose. Используя шаблон репозитория, мы можем сохранить пользователя или удалить задачу из нашей бизнес-логики следующим образом:
// Querying the DB for a User by their ID. const user: User = await userRepository.findById(userID); // Deleting a Task by its ID. await taskRepository.deleteById(taskID); // Deleting a Task by its owner's ID. await taskRepository.deleteByUserId(userID);Очевидно, вы можете видеть, как вся беспорядочная и временная логика доступа к данным скрыта за этим фасадом/абстракцией репозитория, что делает бизнес-логику независимой от проблем сохранения.
Начнем с создания нескольких простых моделей предметной области. Это модели, с которыми будет взаимодействовать код приложения. Здесь они анемичны, но придерживаются собственной логики для удовлетворения бизнес-инвариантов в реальном мире, то есть они не будут простыми пакетами данных.
interface IHasIdentity { id: string; } class User implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _username: string ) {} public get id() { return this._id; } public get username() { return this._username; } } class Task implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _title: string ) {} public get id() { return this._id; } public get title() { return this._title; } } Вскоре вы поймете, почему мы извлекаем информацию о вводе идентификатора в интерфейс. Этот метод определения моделей предметной области и передачи всего через конструктор не такой, как я бы сделал в реальном мире. Кроме того, полагаться на абстрактный класс модели предметной области было бы предпочтительнее, чем на интерфейс, чтобы получить реализацию id бесплатно.
Для репозитория, поскольку в этом случае мы ожидаем, что многие из одних и тех же механизмов сохраняемости будут общими для разных моделей предметной области, мы можем абстрагировать наши методы репозитория в общий интерфейс:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; deleteById(id: string): Promise<void>; existsById(id: string): Promise<boolean>; }Мы могли бы пойти дальше и создать универсальный репозиторий, чтобы уменьшить дублирование. Для краткости я не буду делать этого здесь, и я должен отметить, что интерфейсы Generic Repository, такие как этот и Generic Repositories, как правило, не одобряются, потому что у вас могут быть определенные сущности, которые доступны только для чтения или записи. -только, или которые не могут быть удалены, или подобные. Это зависит от приложения. Кроме того, у нас нет понятия «единицы работы», чтобы разделить транзакцию между таблицами, функцию, которую я бы реализовал в реальном мире, но, опять же, поскольку это небольшая демонстрация, я не хочу получить слишком технические.
Начнем с реализации нашего UserRepository . Я определю интерфейс IUserRepository , который содержит методы, специфичные для пользователей, что позволит вызывающему коду зависеть от этой абстракции, когда мы внедряем зависимости в конкретные реализации:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository implements IUserRepository { // There are 6 methods to implement here all using the // concrete type of `User` - Five from IRepository<User> // and the one above. }Репозиторий задач будет похож, но будет содержать разные методы, которые приложение сочтет нужным.
Здесь мы определяем интерфейс, который расширяет общий, поэтому нам нужно передать конкретный тип, над которым мы работаем. Как видно из обоих интерфейсов, у нас есть понятие, что мы отправляем эти модели предметной области POTO и получаем их. Вызывающий код понятия не имеет, каков лежащий в основе механизм сохраняемости, и в этом суть.
Следующее соображение, которое следует учитывать, заключается в том, что в зависимости от выбранного нами метода доступа к данным нам придется обрабатывать ошибки, связанные с базой данных. Например, мы могли бы разместить Mongoose или Knex Query Builder за этим репозиторием, и в этом случае нам придется обрабатывать эти конкретные ошибки — мы не хотим, чтобы они всплывали в бизнес-логику, поскольку это нарушит разделение задач. и ввести большую степень связи.
Давайте определим базовый репозиторий для методов доступа к данным, которые мы хотим использовать, которые могут обрабатывать ошибки для нас:
class BaseKnexRepository { // A constructor. /** * Wraps a likely to fail database operation within a function that handles errors by catching * them and wrapping them in a domain-safe error. * * @param dalOp The operation to perform upon the database. */ public async withErrorHandling<T>(dalOp: () => Promise<T>) { try { return await dalOp(); } catch (e) { // Use a proper logger: console.error(e); // Handle errors properly here. } } }Теперь мы можем расширить этот базовый класс в репозитории и получить доступ к этому общему методу:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository extends BaseKnexRepository implements IUserRepository { private readonly dbContext: Knex | Knex.Transaction; public constructor (private knexInstance: Knex | Knex.Transaction) { super(); this.dbContext = knexInstance; } // Example `findById` implementation: public async findById(id: string): Promise<User> { return this.withErrorHandling<User>(async () => { const dbUser = await this.dbContext<DbUser>() .select() .where({ user_id: id }) .first(); // Maps type DbUser to User return mapper.toDomain(dbUser); }); } // There are 5 methods to implement here all using the // concrete type of `User`. } Обратите внимание, что наша функция извлекает DbUser из базы данных и сопоставляет его с моделью домена User , прежде чем вернуть его. Это шаблон Data Mapper, и он имеет решающее значение для поддержания разделения задач. DbUser — это однозначное сопоставление с таблицей базы данных — это модель данных, с которой работает репозиторий — и, таким образом, сильно зависит от используемой технологии хранения данных. По этой причине DbUser s никогда не покинет репозиторий и перед возвратом будет сопоставлен с моделью домена User . Я не показывал реализацию DbUser , но это мог быть просто класс или интерфейс.
До сих пор, используя шаблон репозитория на базе Generics, нам удавалось абстрагироваться от проблем доступа к данным в небольшие блоки, а также обеспечивать безопасность типов и возможность повторного использования.
Наконец, для целей модульного и интеграционного тестирования допустим, что мы сохраним реализацию репозитория в памяти, чтобы в тестовой среде мы могли внедрить этот репозиторий и выполнять утверждения на основе состояния на диске, а не имитировать с помощью насмешливая структура. Этот метод заставляет все полагаться на общедоступные интерфейсы, а не позволяет связывать тесты с деталями реализации. Поскольку единственное различие между каждым репозиторием заключается в методах, которые они выбирают для добавления в интерфейс ISomethingRepository , мы можем создать общий репозиторий в памяти и расширить его в реализациях, специфичных для типа:
class InMemoryRepository<T extends IHasIdentity> implements IRepository<T> { protected entities: T[] = []; public findById(id: string): Promise<T> { const entityOrNone = this.entities.find(entity => entity.id === id); return entityOrNone ? Promise.resolve(entityOrNone) : Promise.reject(new NotFound()); } // Implement the rest of the IRepository<T> methods here. } Цель этого базового класса — выполнить всю логику для обработки хранилища в памяти, чтобы нам не приходилось дублировать его в тестовых репозиториях в памяти. Из-за таких методов, как findById , этот репозиторий должен понимать, что объекты содержат поле id , поэтому необходимо общее ограничение для интерфейса IHasIdentity . Мы видели этот интерфейс раньше — это то, что реализовано в наших предметных моделях.
Таким образом, когда дело доходит до создания пользовательского репозитория или репозитория задач в памяти, мы можем просто расширить этот класс и автоматически реализовать большинство методов:
class InMemoryUserRepository extends InMemoryRepository<User> { public async existsByUsername(username: string): Promise<boolean> { const userOrNone = this.entities.find(entity => entity.username === username); return Boolean(userOrNone); // or, return !!userOrNone; } // And that's it here. InMemoryRepository implements the rest. } Здесь нашему InMemoryRepository необходимо знать, что сущности имеют такие поля, как id и username , поэтому мы передаем User в качестве общего параметра. User уже реализует IHasIdentity , поэтому универсальное ограничение выполнено, и мы также указываем, что у нас также есть свойство username .
Теперь, когда мы хотим использовать эти репозитории из уровня бизнес-логики, это довольно просто:
class UserService { public constructor ( private readonly userRepository: IUserRepository, private readonly emailService: IEmailService ) {} public async createUser(dto: ICreateUserDTO) { // Validate the DTO: // ... // Create a User Domain Model from the DTO const user = userFactory(dto); // Persist the Entity await this.userRepository.add(user); // Send a welcome email await this.emailService.sendWelcomeEmail(user); } } (Обратите внимание, что в реальном приложении мы, вероятно, переместили бы вызов emailService в очередь заданий, чтобы не увеличивать задержку запроса и в надежде, что при сбоях можно будет выполнять идемпотентные повторные попытки (не то чтобы отправка электронной почты особенно идемпотент в первую очередь). Кроме того, передача всего объекта пользователя службе также сомнительна. Другая проблема, которую следует отметить, заключается в том, что мы можем оказаться в положении, когда сервер падает после сохранения пользователя, но до того, как электронная почта Для предотвращения этого существуют шаблоны смягчения последствий, но с точки зрения прагматизма вмешательство человека с надлежащим ведением журнала, вероятно, будет работать очень хорошо).
И вот мы идем — используя шаблон репозитория с мощью универсальных шаблонов, мы полностью отделили наш DAL от нашего BLL и сумели взаимодействовать с нашим репозиторием безопасным для типов способом. Мы также разработали способ быстрого создания одинаково типобезопасных репозиториев в памяти для целей модульного и интеграционного тестирования, что позволяет проводить настоящие тесты черного ящика и тесты, не зависящие от реализации. Все это было бы невозможно без универсальных типов.
В качестве отказа от ответственности хочу еще раз отметить, что в этой реализации Repository многого не хватает. Я хотел, чтобы пример был простым, поскольку основное внимание уделяется использованию дженериков, поэтому я не занимался дублированием и не беспокоился о транзакциях. Достойные реализации репозитория потребуют отдельной статьи, чтобы объяснить их полностью и правильно, а детали реализации меняются в зависимости от того, используете ли вы N-уровневую архитектуру или DDD. Это означает, что если вы хотите использовать шаблон репозитория, вы не должны смотреть на мою реализацию здесь как на лучшую практику.
Реальные примеры — React State и реквизиты
Состояние, ссылка и остальные хуки для функциональных компонентов React также являются общими. Если у меня есть интерфейс, содержащий свойства для Task , и я хочу хранить их коллекцию в компоненте React, я мог бы сделать это следующим образом:
import React, { useState } from 'react'; export const MyComponent: React.FC = () => { // An empty array of tasks as the initial state: const [tasks, setTasks] = useState<Task[]>([]); // A counter: // Notice, type of `number` is inferred automatically. const [counter, setCounter] = useState(0); return ( <div> <h3>Counter Value: {counter}</h3> <ul> { tasks.map(task => ( <li key={task.id}> <TaskItem {...task} /> </li> )) } </ul> </div> ); }; Кроме того, если мы хотим передать ряд реквизитов в нашу функцию, мы можем использовать общий React.FC<T> и получить доступ к props :
import React from 'react'; interface IProps { id: string; title: string; description: string; } export const TaskItem: React.FC<IProps> = (props) => { return ( <div> <h3>{props.title}</h3> <p>{props.description}</p> </div> ); }; Компилятор TS автоматически определяет тип props как IProps .
Заключение
В этой статье мы видели множество различных примеров обобщений и вариантов их использования, от простых коллекций до подходов к обработке ошибок, изоляции уровня доступа к данным и так далее. Проще говоря, обобщения позволяют нам создавать структуры данных без необходимости знать конкретное время, в течение которого они будут работать во время компиляции. Надеюсь, это поможет немного раскрыть тему, сделать понятие дженериков немного более интуитивным и показать их истинную силу.