
Полное руководство по созданию масштабируемых парсеров с помощью Scrapy
Опубликовано: 2022-03-10Веб-скрапинг — это способ сбора данных с веб-сайтов без необходимости доступа к API или базе данных веб-сайта. Вам нужен только доступ к данным сайта — пока ваш браузер может получить доступ к данным, вы сможете их очистить.
На самом деле, большую часть времени вы можете просто просмотреть веб-сайт вручную и получить данные «вручную», используя копирование и вставку, но во многих случаях это потребует от вас многих часов ручной работы, что может в конечном итоге стоить вам намного больше, чем данные, особенно если вы наняли кого-то, кто сделает эту задачу за вас. Зачем нанимать кого-то, кто будет работать по 1–2 минуты на запрос, если можно заставить программу автоматически выполнять запрос каждые несколько секунд?
Например, предположим, что вы хотите составить список лауреатов премии «Оскар» за лучший фильм, а также указать их режиссера, исполнителей главных ролей, дату выхода и продолжительность. Используя Google, вы можете увидеть, что есть несколько сайтов, которые будут перечислять эти фильмы по названию и, возможно, с дополнительной информацией, но, как правило, вам придется переходить по ссылкам, чтобы получить всю необходимую информацию.
Очевидно, что было бы непрактично и трудоемко просматривать все ссылки с 1927 года по сегодняшний день и вручную пытаться найти информацию на каждой странице. При парсинге веб-страниц нам просто нужно найти веб-сайт со страницами, на которых есть вся эта информация, а затем указать нашей программе правильное направление с правильными инструкциями.
В этом уроке мы будем использовать Википедию в качестве нашего веб-сайта, поскольку она содержит всю необходимую нам информацию, а затем использовать Scrapy на Python в качестве инструмента для очистки нашей информации.
Несколько предостережений, прежде чем мы начнем:
Очистка данных включает в себя увеличение нагрузки на сервер для сайта, который вы очищаете, что означает более высокую стоимость для компаний, размещающих сайт, и более низкое качество работы для других пользователей этого сайта. Качество сервера, на котором запущен веб-сайт, объем данных, которые вы пытаетесь получить, и скорость, с которой вы отправляете запросы на сервер, будут влиять на влияние, которое вы оказываете на сервер. Имея это в виду, мы должны убедиться, что мы придерживаемся нескольких правил.
На большинстве сайтов в основном каталоге также есть файл robots.txt . Этот файл устанавливает правила, к которым сайты не должны иметь доступ парсерам. Страница «Положения и условия» веб-сайта обычно сообщает вам, какова их политика в отношении очистки данных. Например, на странице условий IMDB есть следующий пункт:
Роботы и анализ экрана. Вы не можете использовать интеллектуальный анализ данных, роботов, анализ экрана или аналогичные инструменты сбора и извлечения данных на этом сайте, кроме как с нашего явного письменного согласия, как указано ниже.
Прежде чем мы попытаемся получить данные веб-сайта, мы всегда должны проверять условия веб-сайта и robots.txt , чтобы убедиться, что мы получаем законные данные. При создании наших парсеров нам также необходимо убедиться, что мы не перегружаем сервер запросами, которые он не может обработать.
К счастью, многие веб-сайты осознают необходимость получения пользователями данных и делают эти данные доступными через API. Если они доступны, обычно гораздо проще получить данные через API, чем путем парсинга.
Википедия разрешает парсинг данных, если боты не работают «слишком быстро», как указано в их файле robots.txt . Они также предоставляют загружаемые наборы данных, чтобы люди могли обрабатывать данные на своих компьютерах. Если мы пойдем слишком быстро, серверы автоматически заблокируют наш IP, поэтому мы внедрим таймеры, чтобы не выходить за рамки их правил.
Начало работы, установка соответствующих библиотек с помощью Pip
Прежде всего, для начала давайте установим Scrapy.
Окна
Установите последнюю версию Python с https://www.python.org/downloads/windows/
Примечание. Пользователям Windows также потребуется Microsoft Visual C++ 14.0, который вы можете получить из «Инструментов сборки Microsoft Visual C++» здесь.
Вы также должны убедиться, что у вас установлена последняя версия pip.
В cmd.exe введите:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyЭто автоматически установит Scrapy и все зависимости.
линукс
Сначала вам нужно установить все зависимости:
В Терминале введите:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devПосле того, как все это установлено, просто введите:
pip install --upgrade pipЧтобы убедиться, что pip обновлен, а затем:
pip install scrapyИ все сделано.
Мак
Сначала вам нужно убедиться, что в вашей системе установлен c-компилятор. В Терминале введите:
xcode-select --installПосле этого установите хоумбрю с https://brew.sh/.
Обновите переменную PATH, чтобы доморощенные пакеты использовались перед системными:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcУстановите Python:
brew install pythonИ затем убедитесь, что все обновлено:
brew update; brew upgrade pythonПосле этого просто установите Scrapy с помощью pip:
pip install Scrapy > ## Обзор Scrapy, взаимосвязь частей, синтаксические анализаторы, пауки и т. д.Вы будете писать сценарий под названием «Паук» для запуска Scrapy, но не волнуйтесь, пауки Scrapy совсем не страшны, несмотря на свое имя. Единственное сходство пауков Scrapy и настоящих пауков заключается в том, что они любят ползать по паутине.
Внутри паука находится определяемый вами class , который сообщает Scrapy, что делать. Например, с чего начать сканирование, какие типы запросов оно делает, как переходить по ссылкам на страницах и как оно анализирует данные. Вы даже можете добавить пользовательские функции для обработки данных перед выводом обратно в файл.
Чтобы запустить нашего первого паука, нам нужно сначала создать проект Scrapy. Для этого введите это в командную строку:
scrapy startproject oscarsЭто создаст папку с вашим проектом.
Мы начнем с простого паука. Следующий код необходимо ввести в скрипт Python. Откройте новый скрипт Python в /oscars/spiders и назовите его oscars_spider.py
Мы импортируем Scrapy.
import scrapyЗатем мы начинаем определять наш класс Spider. Сначала мы устанавливаем имя, а затем домены, которые пауку разрешено очищать. Наконец, мы говорим пауку, с чего начать соскабливать.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']Далее нам нужна функция, которая будет собирать нужную нам информацию. Сейчас мы просто возьмем заголовок страницы. Мы используем CSS, чтобы найти тег, содержащий текст заголовка, а затем извлекаем его. Наконец, мы возвращаем информацию обратно в Scrapy для регистрации или записи в файл.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Теперь сохраните код в /oscars/spiders/oscars_spider.py
Чтобы запустить этого паука, просто перейдите в командную строку и введите:
scrapy crawl oscarsВы должны увидеть такой вывод:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Поздравляем, вы создали свой первый базовый парсер Scrapy!

Полный код:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataОчевидно, мы хотим, чтобы он делал немного больше, поэтому давайте посмотрим, как использовать Scrapy для анализа данных.
Во-первых, давайте познакомимся с оболочкой Scrapy. Оболочка Scrapy может помочь вам протестировать код, чтобы убедиться, что Scrapy захватывает нужные вам данные.
Чтобы получить доступ к оболочке, введите это в командную строку:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Это в основном откроет страницу, на которую вы ее направили, и позволит вам запускать отдельные строки кода. Например, вы можете просмотреть необработанный HTML-код страницы, введя:
print(response.text)Или откройте страницу в браузере по умолчанию, введя:
view(response)Наша цель здесь — найти код, содержащий нужную нам информацию. А пока давайте попробуем получить только названия фильмов.
Самый простой способ найти нужный нам код — открыть страницу в браузере и проверить код. В этом примере я использую Chrome DevTools. Просто щелкните правой кнопкой мыши название любого фильма и выберите «проверить»:
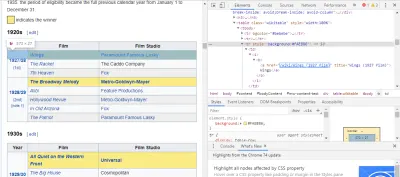
Как видите, у победителей Оскара желтый фон, а у номинантов — простой фон. Также есть ссылка на статью о названии фильма, а ссылки на фильмы заканчиваются на film) . Теперь, когда мы это знаем, мы можем использовать селектор CSS для получения данных. В оболочке Scrapy введите:
response.css(r"tr[] a[href*='film)']").extract()Как видите, теперь у вас есть список всех лауреатов премии «Оскар» за лучший фильм!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Возвращаясь к нашей главной цели, нам нужен список победителей Оскара за лучший фильм, а также их режиссера, актеров в главных ролях, дату выхода и продолжительность. Для этого нам нужно, чтобы Scrapy собирал данные с каждой из этих страниц фильмов.
Нам придется переписать несколько вещей и добавить новую функцию, но не волнуйтесь, это довольно просто.
Мы начнем с запуска скребка так же, как и раньше.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Но на этот раз меняются две вещи. Во-первых, мы будем импортировать time вместе со scrapy , потому что мы хотим создать таймер, чтобы ограничить скорость скрейпинга бота. Кроме того, когда мы анализируем страницы в первый раз, мы хотим получить только список ссылок на каждый заголовок, чтобы вместо этого мы могли получить информацию с этих страниц.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Здесь мы делаем цикл для поиска каждой ссылки на странице, которая заканчивается на film) с желтым фоном, а затем мы объединяем эти ссылки в список URL-адресов, которые мы отправляем в функцию parse_titles для дальнейшей передачи. Мы также добавили таймер, чтобы он запрашивал страницы только каждые 5 секунд. Помните, что мы можем использовать оболочку Scrapy для проверки наших полей response.css , чтобы убедиться, что мы получаем правильные данные!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data Настоящая работа выполняется в нашей функции parse_data , где мы создаем словарь с именем data и затем заполняем каждый ключ нужной нам информацией. Опять же, все эти селекторы были найдены с помощью Chrome DevTools, как показано ранее, а затем протестированы с помощью оболочки Scrapy.
Последняя строка возвращает словарь данных обратно в Scrapy для сохранения.
Полный код:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataИногда нам нужно использовать прокси-серверы, поскольку веб-сайты будут пытаться заблокировать наши попытки парсинга.
Для этого нам нужно всего лишь изменить несколько вещей. Используя наш пример, в нашем def parse() нам нужно изменить его на следующее:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqЭто направит запросы через ваш прокси-сервер.
Развертывание и ведение журнала, покажите, как на самом деле управлять пауком в производственной среде
Теперь пришло время запустить нашего паука. Чтобы Scrapy начал парсинг, а затем выводил его в CSV-файл, введите в командной строке следующее:
scrapy crawl oscars -o oscars.csvВы увидите большой вывод, и через пару минут он завершится, и у вас будет файл CSV, находящийся в папке вашего проекта.
Компиляция результатов. Покажите, как использовать результаты, скомпилированные на предыдущих шагах.
Когда вы откроете файл CSV, вы увидите всю нужную нам информацию (отсортированную по столбцам с заголовками). Это действительно так просто.
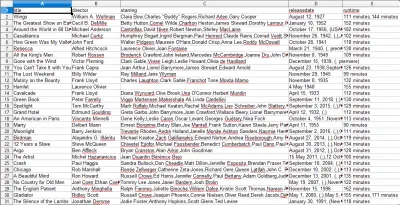
С помощью парсинга данных мы можем получить практически любой пользовательский набор данных, который нам нужен, если информация общедоступна. Что вы хотите делать с этими данными, зависит от вас. Этот навык чрезвычайно полезен для проведения маркетинговых исследований, обновления информации на веб-сайте и многого другого.
Довольно легко настроить собственный парсер для самостоятельного получения пользовательских наборов данных, однако всегда помните, что могут быть другие способы получения необходимых вам данных. Предприятия вкладывают большие средства в предоставление нужных вам данных, поэтому будет справедливо, если мы будем соблюдать их условия.
Дополнительные ресурсы для получения дополнительной информации о Scrapy и парсинге веб-страниц в целом
- Официальный сайт Scrapy
- Страница Scrapy на GitHub
- «10 лучших инструментов для очистки данных и инструментов веб-очистки», Scraper API
- «5 советов по парсингу веб-страниц без блокировки или внесения в черный список», Scraper API
- Parsel, библиотека Python для использования регулярных выражений для извлечения данных из HTML.