
Деревья в структуре данных: 8 типов деревьев, о которых должен знать каждый специалист по данным
Опубликовано: 2021-05-26Оглавление
Введение
В вычислительной области структуры данных относятся к шаблону расположения данных на диске, который обеспечивает удобное хранение и отображение. Они относятся к области науки о данных, которая, по прогнозам, станет прибыльным выбором карьеры в 2021 году. Основываясь на прогнозах на следующие несколько лет, крупномасштабные модели глубокого обучения и интеллектуальные устройства следующего поколения проложат будущее этот сектор.
Таким образом, получение знаний о структурах данных будет иметь важное значение для поиска подходящей карьеры в условиях технического прогресса. Согласно прогнозу Data Science Industry на 2021 год, в США и Индии будет занято около 50 000 специалистов по данным и 300 000 аналитиков данных в их более чем 2 50 000 фирмах. [1]
Структуры данных применяются для разработки путей распределения, управления и поиска информации. Структуры данных особенно необходимы для составления и повышения эффективности общих обрабатываемых данных. Они управляют данными, группируя и организуя их для эффективного обмена информацией.
Деревья в структурах данных
«Деревья» — это тип АТД (абстрактных типов данных), которые следуют иерархическому шаблону распределения данных. По сути, дерево представляет собой набор нескольких узлов, соединенных ребрами. Эти «деревья» образуют структуру данных, напоминающую дерево, где «корневой» узел ведет к «родительским» узлам, которые в конечном итоге ведут к «дочерним» узлам. Соединения выполняются линиями, известными как «ребра».
Узлы-листья являются конечными точками, от которых не исходят дальнейшие дочерние узлы. Деревья в структурах данных играют жизненно важную роль из-за нелинейного характера их расположения. Это обеспечивает более быстрое время отклика во время поиска, а также удобство на всех этапах проектирования.
Типы деревьев в структуре данных
Ниже подробно описаны различные типы деревьев в структурах данных :
1. Общее дерево
Обычное дерево характеризуется отсутствием какой-либо спецификации или ограничений на количество дочерних узлов, которые может иметь узел. Любое дерево с иерархической структурой может быть классифицировано как общее дерево. У узла может быть несколько потомков, и может быть любая комбинация ориентации дерева. Узлы могут быть любой степени от 0 до n.
Ниже приведен классический пример общего дерева в структуре данных, где «2» вверху является корневым узлом.
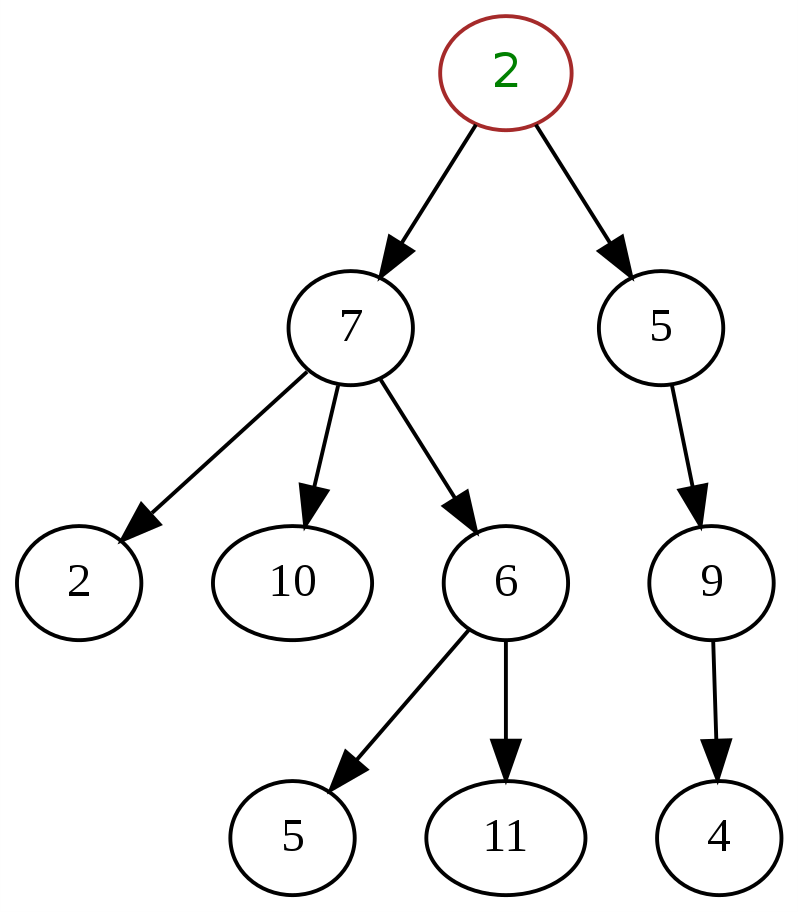
Источник
2. Бинарное дерево
Как определено словом «двоичный», что означает два числа, двоичное дерево состоит из узлов, которые могут иметь 2 дочерних узла. Любой узел в бинарном дереве может иметь максимум 0, 1 или 2 узла. Двоичные деревья в структурах данных являются высокофункциональными АТД и могут быть дополнительно подразделены на множество типов. Они в основном используются в структурах данных для двух целей:
- Для доступа к узлам и их маркировки, как это наблюдается в двоичных деревьях поиска.
- Для представления данных через раздвоенную структуру.
Ниже приведена базовая схема двоичного дерева в структуре данных:
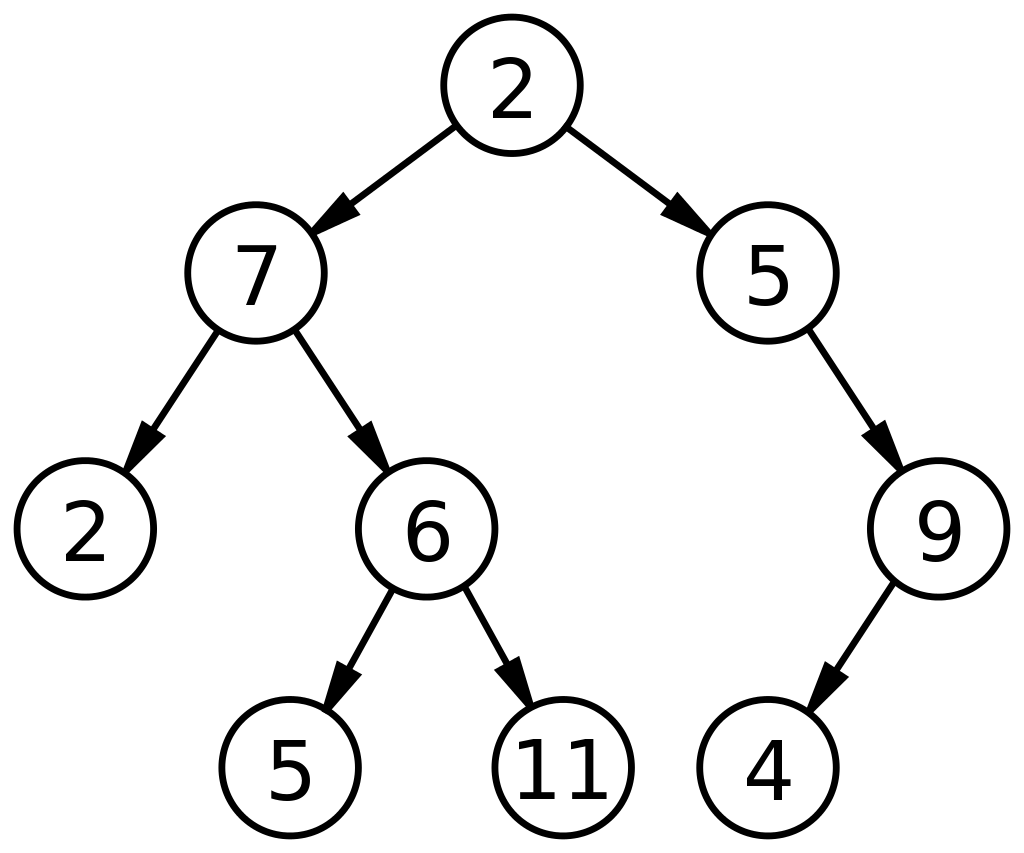
Источник
3. Бинарное дерево поиска
Двоичное дерево поиска (BST) — это уникальный подтип двоичных деревьев, организованный таким образом, чтобы облегчить более быстрый поиск/поиск или добавление/удаление данных. BST определяется представлением узлов на основе трех полей: данных, его левого дочернего элемента и его правого дочернего элемента. Определяющими факторами для BST являются:
- Каждый узел с левой стороны (левый дочерний узел) должен содержать значение, меньшее, чем его родительский узел.
- Каждый узел с правой стороны (правый дочерний узел) должен содержать значение, превышающее значение его родительского узла.
Такая компоновка сокращает время поиска до половины времени линейного поиска, как в массиве. Таким образом, бинарные деревья поиска в структурах данных широко применимы для поиска и сортировки по сравнению с другими АТД.
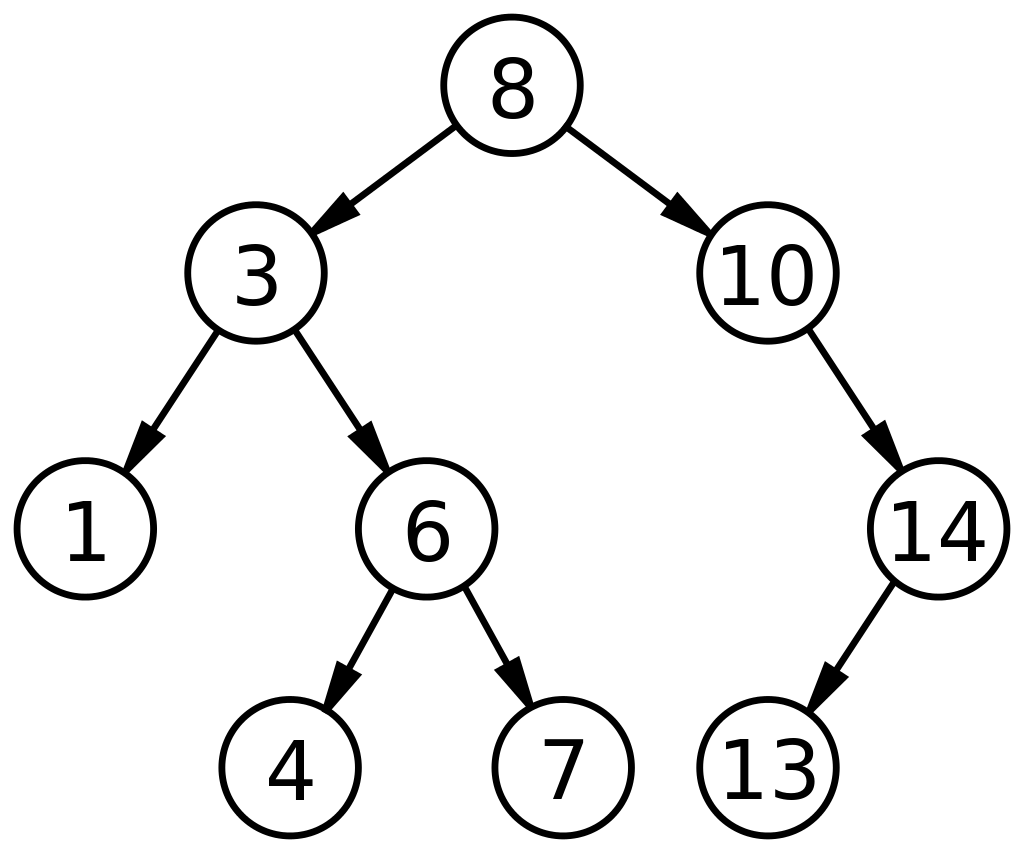
Источник
Несмотря на то, что и BT, и BST по сути являются деревьями в структурах данных , не смущайтесь из-за сходства их имен. Узнайте в деталях разницу между бинарным деревом и бинарным деревом поиска на upGrad.
4. Дерево АВЛ
Дерево AVL получило свое название от своих изобретателей: Адельсона-Вельского и Лэндиса. Дерево AVL характеризуется самобалансирующейся природой. Высота двух поддеревьев его корневых узлов ограничена значением менее двух. Когда разница высот превышает 1, дочерние узлы перебалансируются.
Деревья AVL сбалансированы по высоте, и эта перебалансировка происходит посредством одинарного или двойного вращения. Коэффициент балансировки — это разница между высотами левого поддерева и правого поддерева, и значения равны -1, 0 и 1.
5. Красное черное дерево
Этот тип напоминает деревья AVL, поскольку красно-черные деревья также сбалансированы по высоте. Их отличает то, что для балансировки требуется не более двух оборотов. Они содержат дополнительный бит, определяющий красный или черный цвет узла, что обеспечивает сбалансированность деревьев при удалении и вставке. Красно-черная цветовая кодировка тоже перекрашивается при изменениях, но почти без дополнительных затрат памяти.

6. Развернуть дерево
Другой подтип бинарного дерева поиска, развернутое дерево, обладает уникальным свойством выполнения операций вращения для корректировки последнего узла. Узел, к которому недавно обращались, упорядочивается как корневой узел путем выполнения поворота. Это сбалансированное дерево, но не сбалансированное по высоте.
Акт «расширения» выполняется после начального поиска в бинарном дереве, поскольку повороты дерева выполняются определенным образом. После каждой операции дерево поворачивается, чтобы сбалансироваться, и искомый элемент располагается вверху как корневой узел.
7. Треп
«Treaps» в структурах данных представляют собой комбинацию деревьев и куч. В BST значение левого дочернего узла должно быть меньше корневого узла, а значение правого дочернего узла должно быть выше. В структуре данных кучи корневой узел имеет наименьшее значение, а его дочерние узлы (левый и правый) имеют большее значение.
Таким образом, treap содержит значение в виде ключа (напоминающего BST) и приоритета (наподобие кучи). Узлы с наивысшим приоритетом вставляются первыми в двоичное дерево поиска таким образом, что числа приоритета являются независимыми случайными числами. Они поддерживают динамический набор упорядоченных ключей и позволяют выполнять бинарный поиск по своим ключам.
8. B-дерево
Как самобалансирующееся дерево в структурах данных, B-дерево сортирует данные, чтобы обеспечить поиск, последовательный доступ, удаление и вставку в логарифмическом масштабе. В отличие от бинарного дерева, B-дерево позволяет своим узлам иметь более двух дочерних элементов. Они совместимы с базами данных и файловыми системами, которые считывают и записывают большие блоки данных.
B-дерево в структурах данных используется для больших систем хранения, таких как диски. Все листья не несут никакой информации и находятся на одном уровне. Внутренние узлы B-дерева могут иметь переменный размер дочерних узлов, ограниченных диапазоном.
Это деревья в структурах данных , которые реализуются программистами, проектирующими поток данных. Изучение их уникальных характеристик и приложений необходимо для того, чтобы стать специалистом по данным. Еще один способ повысить свою квалификацию — попрактиковаться в различных проектах, требующих знаний о деревьях в структурах данных и других формах АТД.
Чтобы применить свои знания для проектов DS, по следующим ссылкам в блогах есть 13 интересных идей и тем для проектов по структурам данных для начинающих [2021] .
Заключение
Изучение таких понятий, как деревья в структуре данных, может быть сложным, и кандидатам в программирование требуется помощь экспертов для самообразования. Чтобы узнать больше о деревьях в структуре данных, ознакомьтесь с онлайн-курсами upGrad . Программа Executive PG в разработке программного обеспечения — специализация DevOps с DevOps от IIIT-B и upGrad может помочь вам построить карьеру программиста.
Поскольку владение структурами данных является неотъемлемой частью процесса кодирования, оно может помочь студенту стать опытным программистом и разработчиком программного обеспечения. Программисты и специалисты по данным обязательно будут востребованы в ближайшие десятилетия.
У нас есть 500 миллионов интернет-пользователей в Индии, которые генерируют и потребляют большие объемы данных, что требует найма тысяч специалистов по данным для удовлетворения спроса. [2] Этим специалистам по данным необходимо правильное образование и соответствующий технологический опыт, чтобы искать работу в этом секторе.
Программа Executive PG в разработке программного обеспечения — специализация в разработке полного стека , курируемая upGrad и IIIT-Bangalore, может помочь вам улучшить свой профиль и обеспечить лучшие возможности трудоустройства в качестве программиста.
- Дерево поиска — это структура данных, которая используется для поиска определенных ключей в наборе данных. Ключ каждого узла должен быть больше любых ключей в поддеревьях слева, но меньше ключей в поддеревьях справа, чтобы дерево действовало как дерево поиска. Иерархические данные, такие как структура папок, организационная структура и данные XML/HTML, должны храниться в виде деревьев. Идеальное бинарное дерево — это дерево, в котором каждый внутренний узел имеет два потомка, а каждый лист имеет одинаковую глубину или уровень. Карта предков (не инцестуозная) человека до определенной глубины является примером идеального бинарного дерева, поскольку у каждого человека есть ровно два биологических родителя (мать и отец).Какие деревья можно использовать для поиска?<br />
- Когда дерево достаточно сбалансировано, то есть листья на обоих концах имеют одинаковую глубину, деревья поиска имеют преимущество с точки зрения времени поиска. Существует множество структур данных дерева поиска, некоторые из которых дополнительно позволяют эффективно вставлять и удалять элементы, и эти действия должны затем сохранять баланс дерева.
- Ассоциативный массив часто реализуется с помощью деревьев поиска. Алгоритм дерева поиска находит место, используя ключ из пары ключ-значение, а затем приложение сохраняет полную пару ключ-значение в этом местоположении.
- Двоичные деревья поиска, B-деревья, (a,b)-деревья и троичные деревья поиска являются примерами деревьев поиска. Каковы основные области применения древовидной структуры данных?
1. Двоичное дерево поиска — это дерево, позволяющее быстро искать, вставлять и удалять отсортированные данные. Это также поможет вам найти ближайший к вам предмет.
2. Куча — это древовидная структура данных, которая использует массивы и используется для построения приоритетных очередей.
3. B-Tree и B+ Tree — это два типа деревьев индексации, используемых в базах данных.
4. Компиляторы используют синтаксическое дерево.
5. Дерево разбиения пространства, используемое для организации точек в K-мерном пространстве, известно как KD-дерево.
6. Trie — это структура данных, которая используется для построения словарей с префиксным поиском.
7. Дерево суффиксов используется для быстрого поиска шаблонов в фиксированном тексте.
8. В компьютерных сетях маршрутизаторы и мосты используют связующие деревья, а также деревья кратчайших путей соответственно. Что такое идеальное дерево?