
15 главных вопросов и ответов на собеседованиях по Hadoop в 2022 году
Опубликовано: 2021-01-09По мере того, как аналитика данных набирает обороты, резко возрос спрос на людей, умеющих работать с большими данными. Сегодня большие данные создают множество профилей вакансий, от аналитиков данных до специалистов по данным. Первое и главное, с чем вы должны иметь дело, — это Hadoop.
Независимо от того, какая должность/профиль работы, вы, вероятно, так или иначе будете работать с Hadoop. Таким образом, вы всегда можете ожидать, что интервьюеры зададут вам несколько вопросов Hadoop.
Чтобы узнать об этом и не только, давайте рассмотрим 15 лучших вопросов для интервью с Hadoop, которые можно ожидать на любом собеседовании, на котором вы сидите.
Что такое Хадуп? Каковы основные компоненты Hadoop?
Hadoop — это инфраструктура, оснащенная соответствующими инструментами и сервисами, необходимыми для обработки и хранения больших данных. Если быть точным, Hadoop — это «решение» всех проблем, связанных с большими данными. Кроме того, среда Hadoop также помогает организациям анализировать большие данные и принимать более эффективные бизнес-решения.
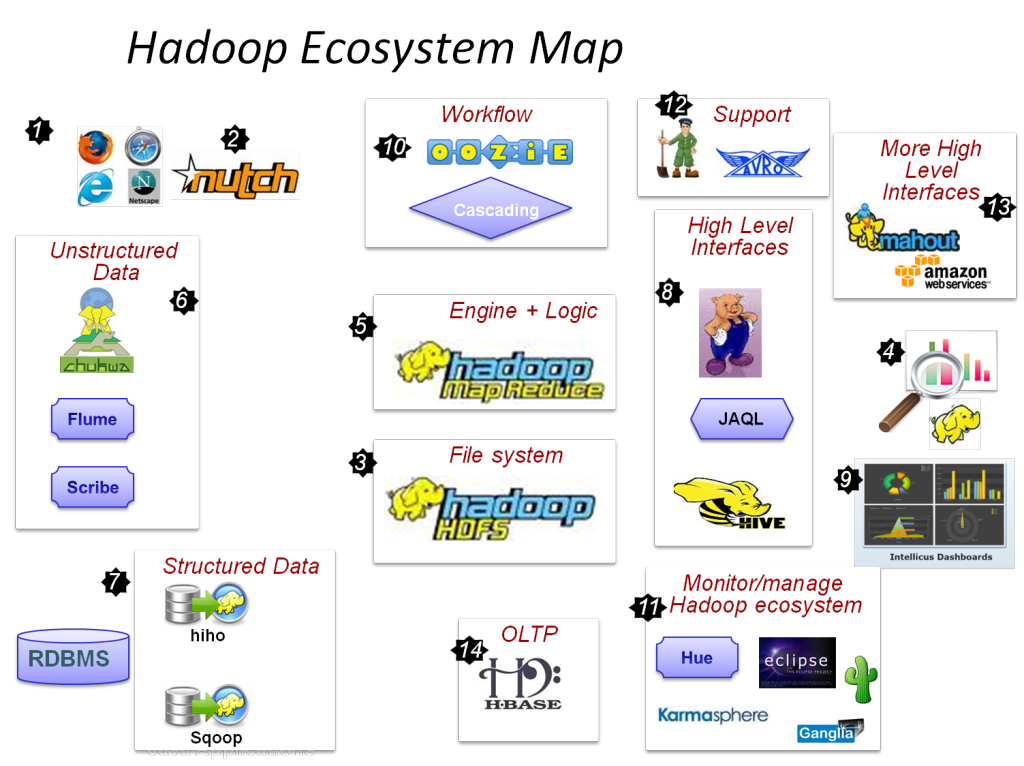
Основные компоненты Hadoop:
- HDFS
- Hadoop MapReduce
- Хадуп Общий
- ПРЯЖА
- PIG и HIVE — компоненты доступа к данным.
- HBase — для хранения данных
- Ambari, Oozie и ZooKeeper — компонент управления данными и мониторинга
- Thrift и Avro — компоненты сериализации данных
- Apache Flume, Sqoop, Chukwa — компоненты интеграции данных
- Apache Mahout и Drill — компоненты анализа данных
Каковы основные концепции платформы Hadoop?
Hadoop основан на двух основных концепциях. Они есть:
- HDFS: HDFS или распределенная файловая система Hadoop — это надежная файловая система на основе Java, используемая для хранения обширных наборов данных в блочном формате. Архитектура Master-Slave приводит его в действие.
- MapReduce: MapReduce — это структура программирования, которая помогает обрабатывать большие наборы данных. Эта функция далее разбита на две части: в то время как «карта» разделяет наборы данных на кортежи, «уменьшить» использует кортежи карты и создает комбинацию меньших фрагментов кортежей.
Назовите наиболее распространенные форматы ввода в Hadoop?
В Hadoop есть три распространенных формата ввода:
- Формат ввода текста: это формат ввода по умолчанию в Hadoop.
- Формат ввода файла последовательности: этот формат ввода используется для последовательного чтения файлов.
- Формат ввода значения ключа: этот формат используется для чтения текстовых файлов.
Что такое ПРЯЖА?
YARN — это сокращение от Yet Another Resource Negotiator. Это платформа обработки данных Hadoop, которая управляет ресурсами данных и создает среду для успешной обработки. 
Что такое «осведомленность о стойке»?
«Осведомленность о стойке» — это алгоритм, который NameNode использует для определения шаблона, в котором блоки данных и их реплики хранятся в кластере Hadoop. Это достигается с помощью определений стоек, которые уменьшают перегрузку между узлами данных, содержащимися в одной и той же стойке.

Что такое активные и пассивные узлы имен?
Система Hadoop высокой доступности обычно содержит два NameNode — Active NameNode и Passive NameNode.
NameNode, на котором работает кластер Hadoop, называется Active NameNode, а резервный NameNode, в котором хранятся данные Active NameNode, называется Passive NameNode.
Цель наличия двух NameNode состоит в том, что в случае сбоя Active NameNode пассивный NameNode может взять на себя инициативу. Таким образом, NameNode всегда работает в кластере, и система никогда не дает сбоев.
Какие существуют планировщики в среде Hadoop?
В среде Hadoop есть три разных планировщика:
- COSHH — COSHH помогает планировать решения, анализируя кластер и рабочую нагрузку в сочетании с неоднородностью.
- Планировщик FIFO — FIFO выстраивает задания в очередь в зависимости от времени их поступления, не используя неоднородность.
- Fair Sharing — Fair Sharing создает пул для отдельных пользователей, содержащий несколько карт, и сокращает слоты на ресурсе, который они могут использовать для выполнения определенных заданий.
Что такое спекулятивное исполнение?
Часто в среде Hadoop некоторые узлы могут работать медленнее остальных. Это имеет тенденцию ограничивать всю программу. Чтобы преодолеть это, Hadoop сначала обнаруживает или «предполагает», когда задача выполняется медленнее, чем обычно, а затем запускает эквивалентную резервную копию для этой задачи. Таким образом, в процессе главный узел выполняет обе задачи одновременно, и принимается та, которая выполняется первой, а другая уничтожается. Эта функция резервного копирования Hadoop известна как спекулятивное выполнение.

Назовите основные компоненты Apache HBase?
Apache HBase состоит из трех компонентов:
- Региональный сервер: после того, как таблица разделена на несколько регионов, кластеры этих регионов перенаправляются клиентам через региональный сервер.
- HMaster: это инструмент, который помогает управлять и координировать региональный сервер.
- ZooKeeper: ZooKeeper является координатором в распределенной среде HBase. Это помогает поддерживать состояние сервера внутри кластера посредством обмена данными в сеансах.
Что такое «чекпойнт»? В чем его польза?
Контрольные точки относятся к процедуре, с помощью которой FsImage и журнал редактирования объединяются для формирования нового FsImage. Таким образом, вместо воспроизведения журнала редактирования NameNode может напрямую загрузить окончательное состояние в памяти из FsImage. Вторичный NameNode отвечает за этот процесс.
Преимущество, которое предлагает Checkpointing, заключается в том, что оно минимизирует время запуска NameNode, тем самым делая весь процесс более эффективным.
Применение больших данных в поп-культуре
Как отлаживать код Hadoop?
Чтобы отладить код Hadoop, сначала вам нужно проверить список задач MapReduce, которые в данный момент выполняются. Затем вам нужно проверить, выполняются ли одновременно какие-либо потерянные задачи. Если это так, вам нужно найти расположение журналов Resource Manager, выполнив следующие простые действия:
Запустите «ps –ef | grep –I ResourceManager» и в отображаемом результате попытайтесь найти, есть ли ошибка, связанная с конкретным идентификатором задания.
Теперь определите рабочий узел, который использовался для выполнения задачи. Войдите на узел и запустите «ps –ef | grep — iNodeManager».
Наконец, внимательно изучите журнал Node Manager. Большинство ошибок генерируются из журналов уровня пользователя для каждого задания уменьшения карты.
Какова цель RecordReader в Hadoop?
Hadoop разбивает данные на блочные форматы. RecordReader помогает интегрировать эти блоки данных в единую удобочитаемую запись. Например, если входные данные разбиты на два блока –
1 ряд – добро пожаловать
Ряд 2 — UpGrad
RecordReader прочитает это как «Добро пожаловать в UpG rad».
В каких режимах может работать Hadoop?
Режимы, в которых может работать Hadoop:
- Автономный режим — это режим Hadoop по умолчанию, который используется для целей отладки. Он не поддерживает HDFS.
- Псевдораспределенный режим. Этот режим требует настройки файлов mapred-site.xml, core-site.xml и hdfs-site.xml. И главный, и подчиненный узел здесь одинаковы.
- Полностью распределенный режим. Полностью распределенный режим — это производственная стадия Hadoop, на которой данные распределяются между различными узлами в кластере Hadoop. Здесь главный и подчиненный узлы выделяются отдельно.
Назовите несколько практических применений Hadoop.
Вот несколько реальных примеров, когда Hadoop помогает:
- Управление уличным движением
- Обнаружение и предотвращение мошенничества
- Анализируйте данные о клиентах в режиме реального времени, чтобы улучшить обслуживание клиентов
- Доступ к неструктурированным медицинским данным от врачей, медицинских работников и т. д. для улучшения медицинских услуг.
Какие жизненно важные инструменты Hadoop могут повысить производительность больших данных?
Инструменты Hadoop, которые значительно повышают производительность больших данных:

• Улей
• HDFS
• HBase
• SQL
• NoSQL
• Узи
• Облака
• Авро
• Лоток
• Работник зоопарка
Инженеры по работе с большими данными: мифы против реальности
Заключение
Эти вопросы для собеседования с Hadoop должны вам очень помочь на следующем собеседовании. Хотя иногда интервьюеры имеют тенденцию искажать некоторые вопросы интервью Hadoop, это не должно быть проблемой для вас, если вы разобрались с основами.
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma в области разработки программного обеспечения со специализацией в области больших данных, которая предназначена для работающих профессионалов и включает более 7 тематических исследований и проектов, охватывает 14 языков и инструментов программирования, практические занятия. семинары, более 400 часов интенсивного обучения и помощь в трудоустройстве в ведущих фирмах.