
Мысли о уценке
Опубликовано: 2022-03-10Уценка является второй натурой для многих из нас. Оглядываясь назад, я помню, как начал печатать в Markdown вскоре после того, как Джон Грубер выпустил свой первый синтаксический анализатор на основе Perl в 2004 году после совместной работы над языком с Аароном Шварцем.
Синтаксис Markdown предназначен для одной цели: его можно использовать в качестве формата для написания в Интернете.
— Джон Грубер
Это было почти 20 лет назад — ура! То, что начиналось как более удобный для писателя и читателя синтаксис HTML, стало излюбленным способом написания и хранения технических текстов для программистов и технически подкованных людей.
Markdown — это символ культуры разработчиков и текстовых редакторов. Но с момента его появления изменился и мир цифрового контента. Хотя Markdown по-прежнему хорош для некоторых вещей, я не думаю, что он больше должен быть популярным для контента.
Для этого есть две основные причины:
- Markdown не был разработан для удовлетворения сегодняшних потребностей в контенте.
- Markdown сдерживает редакционный опыт.
Конечно, на эту позицию повлияла работа на платформе структурированного контента. В Sanity.io мы проводим большую часть наших дней, думая о том, как контент в виде данных раскрывает большую ценность, и мы тратим много времени на глубокие размышления о работе редактора и о том, как сэкономить время людей и сделать работу с цифровым контентом восхитительной. . Итак, в игре есть скин, но я надеюсь, что смогу изобразить это, даже если я буду выступать против Markdown как основного формата для контента, я все еще глубоко ценю его значение, применение и наследие.
До моей нынешней работы я работал консультантом по технологиям в агентстве, где нам приходилось буквально бороться с CMS, которые блокировали контент нашего клиента, встраивая его в презентации и сложные модели данных (да, даже с открытым исходным кодом). Я наблюдал, как люди борются с синтаксисом Markdown и теряют мотивацию в своей работе в качестве редакторов и создателей контента. Мы потратили часы (и деньги клиента) на создание пользовательских средств визуализации тегов, которые никогда не использовались, потому что у людей нет времени или мотивации использовать синтаксис. Даже я, когда был очень мотивирован, отказался от участия в документации с открытым исходным кодом, потому что реализация Markdown на основе компонентов создавала слишком много трений.
Но я также вижу и другую сторону медали. Markdown поставляется с впечатляющей экосистемой, и с точки зрения разработчика существует элегантная простота текстовых файлов и простой для анализа синтаксис для людей, которые привыкли читать код. Однажды я потратил несколько дней на создание впечатляющего MultiMarkdown -> LaTeX -> real-time-PDF-preview-pipeline в Sublime Text для моего академического письма. И вполне логично, что файл README.md можно открыть и отредактировать в редакторе кода и красиво отобразить на GitHub. Нет никаких сомнений в том, что Markdown в некоторых случаях приносит удобство разработчикам.
Именно поэтому я хочу построить свой совет против Markdown, оглядываясь назад на то, почему он был введен в первую очередь, и просматривая некоторые основные разработки контента в Интернете. Я подозреваю, что для многих из нас Markdown — это то, что мы просто принимаем как должное как «вещь, которая существует». Но все технологии имеют историю и являются продуктом человеческого взаимодействия. Это важно помнить, когда вы, читатель, разрабатываете технологию для использования другими.
Вкусы и характеристики
Markdown был разработан, чтобы облегчить веб-писателям работу со статьями в эпоху, когда веб-публикации требовали написания HTML. Таким образом, целью было упростить взаимодействие с форматированием текста в HTML. Это был не первый упрощенный синтаксис на планете, но именно он за последние годы получил наибольшее распространение. Сегодня использование Markdown вышло далеко за рамки его конструктивного замысла, чтобы быть более простым способом чтения и записи HTML, чтобы стать подходом к разметке простого текста во множестве различных контекстов. Конечно, технологии и идеи могут развиваться сверх своего предназначения, но напряженность в сегодняшнем использовании Markdown можно проследить до этого происхождения и ограничений, наложенных на его дизайн.
Для тех, кто не знаком с синтаксисом, возьмите следующий HTML-контент:
<p>The <a href=”https://daringfireball.net/projects/markdown/syntax#philosophy”>Markdown syntax</a> is designed to be <em>easy-to-read</em> and <em>easy-to.write</em>.</p>С помощью Markdown вы можете выразить то же форматирование, что и:
The [Markdown syntax](https://daringfireball.net/projects/markdown/syntax#philosophy) is designed to be _easy-to-read_ and _easy-to-write_.Это похоже на закон природы, что внедрение технологий сопровождается необходимостью развиваться и добавлять к ним новые функции. Растущая популярность Markdown означала, что люди хотели адаптировать его для своих случаев использования. Они хотели больше функций, таких как поддержка сносок и таблиц. Первоначальная реализация исходила из самоуверенной позиции, которая в то время была разумной для того, что было замыслом дизайна:
Для любой разметки, на которую не распространяется синтаксис Markdown, вы просто используете сам HTML. Нет необходимости предварять его или разделять, чтобы указать, что вы переключаетесь с Markdown на HTML; вы просто используете теги.
— Джон Грубер
Другими словами, если вам нужна таблица, используйте <table></table> . Вы обнаружите, что это все еще относится к исходной реализации. Один из духовных преемников Markdown, MDX, взял тот же принцип, но расширил его до JSX, языка шаблонов на основе JS.
От уценки к уценке?
Может показаться, что привлекательность Markdown для многих заключалась не столько в его привязке к HTML, сколько в эргономике открытого текста и простом синтаксисе форматирования. Некоторые создатели контента хотели использовать Markdown не только для простых статей в Интернете. Такие реализации, как MultiMarkdown, открыли возможности для академических писателей, которые хотели использовать простые текстовые файлы, но нуждались в дополнительных функциях. Вскоре у вас будет ряд приложений для написания, которые принимают синтаксис Markdown, не обязательно превращая его в HTML или даже используя синтаксис markdown в качестве формата хранения.
Во многих приложениях вы найдете редакторы с ограниченным набором параметров форматирования, а некоторые из них более «вдохновлены» исходным синтаксисом. На самом деле, один из отзывов, которые я получил по черновику этой статьи, заключался в том, что к настоящему времени «уценка» должна быть в нижнем регистре, поскольку она стала настолько распространенной, и чтобы она отличалась от исходной реализации. Потому что то, что мы называем уценкой, также стало очень разнообразным.
CommonMark: попытка приручить Markdown
Как и мороженое, Markdown бывает разных вкусов, некоторые из которых более популярны, чем другие. Когда люди начали разветвлять исходную реализацию и добавлять в нее функции, произошли две вещи:
- Стало более непредсказуемо, что вы, как писатель, можете и не можете делать с Markdown.
- Разработчики программного обеспечения должны были принимать решения о том, какую реализацию принять для своего программного обеспечения. Первоначальная реализация также содержала некоторые несоответствия, которые создавали трудности для людей, которые хотели использовать ее программно.
Это положило начало разговорам о формализации Markdown в собственно спецификации. Что-то, чему Грубер сопротивлялся и до сих пор сопротивляется, что интересно, потому что он понял, что люди хотят использовать Markdown для разных целей, и «Ни один синтаксис не удовлетворит всех». Это интересная позиция, учитывая, что Markdown переводится в HTML, который является спецификацией, которая развивается для удовлетворения различных потребностей.
Несмотря на то, что первоначальная реализация Markdown подпадает под действие «BSD-подобной» лицензии, она также гласит: «Ни название Markdown, ни имена его участников не могут использоваться для поддержки или продвижения продуктов, созданных на основе этого программного обеспечения, без специального предварительного письменного разрешения. ” Мы можем с уверенностью предположить, что большинство продуктов, которые используют «Markdown» как часть своих маркетинговых материалов, не получили этого письменного разрешения.
Самая успешная попытка включить Markdown в общую спецификацию — это то, что сегодня известно как CommonMark. Его возглавили Джефф Этвуд (известный как соучредитель Stack Overflow и Discourse) и Джон Макфарлейн (профессор философии в Беркли, стоящий за Babelmark и pandoc). Первоначально они запустили его как «Standard Markdown», но изменили его на «CommonMark» после критики со стороны Грубера. Чья позиция была последовательной, цель Markdown — стать простым авторским синтаксисом, который транслируется в HTML:
@davewiner И это недостаток CommonMark. Они хотят упростить жизнь программистам в качестве основной цели. Они упускают суть.
— Джон Грубер (@gruber) 8 сентября 2014 г.
Я думаю, что это также стало точкой отсчета, когда Markdown стал общественным достоянием. Несмотря на то, что CommonMark не маркируется как «Markdown» (согласно лицензированию), эта спецификация распознается и называется «markdown». Сегодня вы найдете CommonMark в качестве базовой реализации для таких программ, как Discourse, GitHub, GitLab, Reddit, Qt, Stack Overflow и Swift. Такие проекты, как unified.js , объединяют синтаксисы, переводя их в абстрактные синтаксические деревья, также полагаются на CommonMark для поддержки уценки.
CommonMark в значительной степени унифицировал реализацию уценки и во многих отношениях упростил для программистов интеграцию поддержки уценки в программное обеспечение. Но это не принесло такой же унификации в то, как пишется и используется уценка. Возьмите GitHub Flavored Markdown (GFM). Он основан на CommonMark, но дополнен дополнительными функциями (такими как таблицы, списки задач и зачеркивание). Reddit описывает свою «уценку Reddit Flavored Markdown» как «разновидность GFM» и вводит такие функции, как синтаксис для разметки спойлеров. Я думаю, мы можем с уверенностью заключить, что и группа, стоящая за CommonMark, и Грубер были правы: это, безусловно, помогает с общими спецификациями, но да, люди хотят использовать Markdown для разных конкретных вещей.
Markdown как ярлык форматирования
Грубер сопротивлялся формализации Markdown в общую спецификацию, потому что он полагал, что это сделает его не столько инструментом для писателей, сколько инструментом для программистов. Мы уже видели, что даже при широком внедрении спецификации мы не получаем автоматически синтаксис, который предсказуемо работает одинаково в разных контекстах. И спецификации вроде CommonMark, несмотря на свою популярность, также имеют ограниченный успех. Очевидным примером является реализация уценки Slack (называемая mrkdown ), которая переводит *this* в сильный/полужирный, а не в выделение/курсив, и не поддерживает синтаксис [link](https://slack.com) , но использует <link|https://slack.com> вместо этого <link|https://slack.com> .
Вы также обнаружите, что вы можете использовать синтаксис, подобный Markdown, для инициализации форматирования в редакторах форматированного текста в таких программах, как Notion, Dropbox Paper, Craft и, в некоторой степени, в Google Docs (например, asterisk + space в новой строке преобразуются в маркированный список). Что поддерживается и что переведено на что варьируется. Таким образом, вы не обязательно можете использовать свою мышечную память в этих приложениях. Для некоторых людей это нормально, и они могут адаптироваться. Для других это вырезка из бумаги, которая не позволяет им использовать эти функции. Что задает вопрос, для кого был разработан Markdown и кто его пользователи сегодня?
Кем должны быть пользователи Markdown?
Мы видели, как уценка существует в противоречии между различными вариантами использования, аудиториями и представлениями о том, кем являются ее пользователи. То, что начиналось как язык разметки специально для веб-писателей, владеющих HTML, стало любимым для разработчиков.
В 2014 году веб-райтеры начали отказываться от перемещения файлов через парсеры на Perl и FTP. Системы управления контентом (CMS), такие как WordPress, Drupal и Moveable Type (которые, как мне кажется, до сих пор использует Грубер), неуклонно становились популярными инструментами для веб-публикаций. Они предлагали такие возможности, как редакторы форматированного текста, которые веб-писатели могли использовать в своих браузерах.
Эти редакторы форматированного текста по-прежнему предполагали HTML и Markdown в качестве основного синтаксиса форматированного текста, но они убрали часть когнитивных издержек, добавив кнопки для вставки этого синтаксиса в редактор. И все чаще писатели не были и не должны были разбираться в HTML. Бьюсь об заклад, если вы занимались веб-разработкой с помощью CMS в 2010-х годах, вам, вероятно, приходилось иметь дело с «мусорным HTML», который появлялся через эти редакторы, когда люди вставляли прямо из Word.
Сегодня я утверждаю, что основными пользователями Markdown являются разработчики и люди, интересующиеся кодом. Это не совпадение, что Slack сделал WYSIWYG режимом ввода по умолчанию, когда их программное обеспечение стало использоваться большим количеством людей за пределами технических отделов. И тот факт, что это было настолько спорным решением, что его пришлось вернуть в качестве опции, показывает, насколько глубока любовь к уценке в сообществе разработчиков. Slack не особо приветствовали попытки сделать его проще и доступнее для всех. И в этом суть дела.
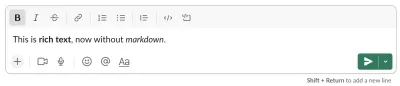
Идеология уценки
Тот факт, что уценка стала лингва-франка стилем письма, и то, что обслуживает большинство фреймворков веб-сайтов, также является основной причиной, по которой я был немного пугливым в отношении публикации этого. Об этом часто говорят как о неотъемлемом и неоспоримом благе. Markdown стал отличительной чертой дружественности к разработчикам. Умные и опытные люди потратили много времени на то, чтобы включить уценку во всех контекстах. Таким образом, вызов его гегемонии наверняка кого-то раздражает. Но, надеюсь, это может породить плодотворную дискуссию о вещах, которые часто считаются само собой разумеющимися.
У меня сложилось впечатление, что удобство для разработчиков, с которым люди относятся к Markdown, в основном связано с тремя факторами:
- Удобная абстракция простого текстового файла.
- Существует экосистема инструментов.
- Вы можете держать свой контент близко к рабочему процессу разработки.
Я не говорю, что эти позиции неверны, но я предполагаю, что они сопровождаются компромиссами и некоторыми необоснованными предположениями.
Простая ментальная модель простого текстового файла
Базы данных удивительные вещи. Но они также заслужили репутацию сложных и недоступных для разработчиков интерфейса. Я знаю много замечательных разработчиков, которые избегают внутреннего кода и баз данных, потому что они представляют сложность, на которую они не хотят тратить время. Даже с WordPress, который делает многое из коробки, чтобы вам не приходилось иметь дело с его базой данных после установки, это было накладно для запуска и запуска.
Обычные текстовые файлы, однако, более осязаемы, и о них довольно просто рассуждать (если вы привыкли к управлению файлами). Особенно по сравнению с системой, которая разбивает ваш контент на несколько таблиц в реляционной базе данных с некоторой проприетарной структурой. Для ограниченных случаев использования, таких как сообщения в блогах с простым форматированным текстом с изображениями и ссылками, уценка выполнит свою работу. Вы можете скопировать файл и вставить его в папку или проверить в git. Контент кажется вашим из-за осязаемости файлов. Даже если они размещены на GitHub, который является коммерческим программным обеспечением как услугой, принадлежащим Microsoft, и, таким образом, подпадает под действие их условий обслуживания.
В эпоху, когда вам фактически приходилось раскручивать локальную базу данных, чтобы запустить локальную разработку и иметь дело с ее синхронизацией с удаленной, привлекательность простых текстовых файлов понятна. Но эта эпоха в значительной степени ушла с появлением бэкэндов как сервиса. Такие сервисы и инструменты, как Fauna, Firestore, Hasura, Prisma, PlanetScale и Sanity's Content Lake, вкладывают значительные средства в опыт разработчиков. Даже работа с традиционными базами данных по местному развитию стала менее сложной задачей по сравнению с тем, что было всего 10 лет назад.
Если подумать, меньше ли вы владеете своим контентом, если он размещен в базе данных? И разве с появлением инструментов SaaS опыт работы с базами данных не стал значительно проще? И справедливо ли говорить, что проприетарная технология базы данных препятствует переносимости вашего контента? Сегодня вы можете запустить то, что по сути является базой данных Postgres, без навыков системного администратора, создать свои таблицы и столбцы, поместить в них свой контент и в любой момент экспортировать его в виде дампа .sql .
Переносимость контента в большей степени зависит от того, как вы его структурируете . Возьмите WordPress, он полностью с открытым исходным кодом, вы можете разместить свою собственную БД. Он даже имеет стандартизированный формат экспорта в XML. Но любой, кто пытался отказаться от зрелой установки WordPress, знает, как мало это помогает, если вы пытаетесь уйти от WordPress.
Обширная экосистема… Для разработчиков
Мы уже коснулись обширной экосистемы уценки. Если вы посмотрите на современные фреймворки веб-сайтов, то увидите, что большинство из них предполагают уценку как основной формат контента, а некоторые — как единственный формат. Например, Hugo, генератор статических сайтов, используемый Smashing Magazine, по-прежнему требует файлов уценки для публикации с разбивкой на страницы. Это означает, что если Smashing Magazine хочет использовать CMS для хранения статей, он должен взаимодействовать с файлами уценки или конвертировать весь контент в файлы уценки. Если вы посмотрите документацию для Next.js, Nuxt.js, VuePress, Gatsby.js и т. д., уценка будет занимать видное место. Это также синтаксис по умолчанию для файлов README на GitHub, который также использует его для форматирования в примечаниях и комментариях к запросам на вытягивание.
Есть несколько почетных упоминаний об инициативах по доведению эргономики уценки до масс. Netlify CMS и TinaCMS (духовный потомок Forestry) предоставят вам пользовательские интерфейсы, в которых синтаксис уценки в основном абстрагирован для редакторов. Обычно вы обнаружите, что редакторы на основе уценки в CMS предоставляют вам функции предварительного просмотра форматирования. Некоторые редакторы, такие как Notion, позволяют вставлять синтаксис уценки и переводят его в собственное форматирование. Но я думаю, можно с уверенностью сказать, что энергия, затраченная на инновации для уценки, не благоприятствовала людям, которые не пишут ее синтаксис. Это не просочилось вверх по стеку, так сказать.
Рабочие процессы контента или рабочие процессы разработчиков?
Для разработчика, который ведет свой блог, использование файлов уценки снижает некоторые накладные расходы на его запуск и запуск, поскольку фреймворки часто поставляются со встроенным синтаксическим анализом или обычно предлагают его как часть начального кода. И не на что дополнительно подписываться. Вы можете использовать git для фиксации этих файлов вместе с вашим кодом. Если вам удобно работать с git diffs, у вас даже будет контроль версий, как вы привыкли к программированию. Другими словами, поскольку файлы уценки представляют собой обычный текст, их можно интегрировать в рабочий процесс вашего разработчика.

Но помимо этого, опыт разработчика вскоре становится более сложным. И в конечном итоге вы ставите под угрозу пользовательский опыт вашей команды как создателей контента, а наш собственный опыт разработчиков застревает на уценке для решения проблем, которые выходят далеко за рамки его замысла.
Да, может быть, было бы здорово, если бы ваша команда по контенту использовала git и проверяла свои изменения, но в то же время, является ли это наилучшим использованием их времени? Вы действительно хотите, чтобы ваши редакторы столкнулись с конфликтами слияния или как перебазировать ветки? Git достаточно сложен для разработчиков, которые используют его каждый день. И действительно ли эта установка представляет собой лучший рабочий процесс для людей, которые в основном работают с контентом? Разве это не тот случай, когда опыт разработчика важнее опыта редактора, и разве это не затраты, время и усилия, которые можно было бы потратить на то, чтобы сделать что-то лучше для пользователей?
Поскольку ожидания и потребности, связанные с контентом и средами редактирования, изменились, я не думаю, что уценка сделает это за нас. Я не понимаю, как некоторые из эргономики разработчиков в конечном итоге отдают предпочтение не-разработчикам, и я думаю, что даже для разработчиков уценка сдерживает создание собственного контента и потребности. Потому что контент в сети значительно изменился с начала 2000-х годов.
От абзацев к блокам
У Markdown всегда была возможность отказаться от HTML, если вам нужны более сложные вещи. Это хорошо работало, когда автор был также веб-мастером или, по крайней мере, знал HTML. Это также хорошо работало, потому что веб-сайты обычно состояли в основном из HTML и CSS. Вы создавали веб-сайты в основном путем создания целых макетов страниц. Вы можете преобразовать Markdown в разметку HTML и поместить ее рядом с файлом style.css . Конечно, в 2000-х у нас тоже были CMS и генераторы статических сайтов, но в основном они работали одинаково, вставляя HTML-контент внутрь шаблонов без передачи «реквизита» между компонентами.
Но большинство из нас больше не создают HTML, как в старые времена. Контент в Интернете превратился из статей с простым форматированием расширенного текста в составные мультимедийные и специализированные компоненты, часто с интерактивностью пользователя (что является причудливым способом сказать «подписка на рассылку новостей с призывом к действию»).
От статей к приложениям
В начале 2010-х Web 2.0 переживал период своего расцвета, и компании, занимающиеся разработкой программного обеспечения как услуги, начали использовать Интернет для приложений с большим объемом данных. HTML, CSS и JavaScript все чаще использовались для создания интерактивных пользовательских интерфейсов. Twitter Bootstrap с открытым исходным кодом, их фреймворк для создания более согласованных и устойчивых пользовательских интерфейсов. Это привело к тому, что мы можем назвать «компонентизацией» веб-дизайна. Это коренным образом изменило то, как мы строим для Интернета.
Различные фреймворки CSS, появившиеся в ту эпоху (например, Bootstrap и Foundation), как правило, использовали стандартизированные имена классов и предполагали определенные структуры HTML, чтобы упростить создание отказоустойчивых и отзывчивых пользовательских интерфейсов. Благодаря философии веб-дизайна Atomic Design и соглашениям об именах классов, таким как Block-Element-Modifier (BEM), по умолчанию вместо макета страницы сначала рассматривались страницы как набор повторяющихся и совместимых элементов дизайна.
Какой бы контент у вас ни был внутри уценки, он несовместим с этим. Если только вы не спустились в кроличью нору, вставив парсеры уценки и настроив их для вывода желаемого синтаксиса (подробнее об этом позже). Неудивительно, что Markdown был разработан, чтобы быть простыми текстовыми статьями с нативными HTML-элементами, на которые вы могли бы ориентироваться с помощью таблицы стилей.
Это все еще проблема для людей, которые используют Markdown для размещения контента на своих сайтах.
Встраиваемая сеть
Но что-то случилось и с нашим контентом. Мы не только смогли найти его за пределами семантических HTML-тегов <article> , но и стали содержать больше… вещей. Большая часть нашего контента переместилась из наших ЖЖ и блогов в социальные сети: Facebook, Twitter, tumblr, YouTube. Чтобы вернуть фрагменты контента в наши статьи, нам нужно было иметь возможность их встраивать. Соглашение HTML начало использовать <iframe> для передачи видеоплеера с YouTube или даже для вставки окна твита между вашими абзацами текста. Некоторые системы начали абстрагировать это в виде «коротких кодов», чаще всего скобок, содержащих какое-то ключевое слово, чтобы определить, какой блок контента он должен представлять, и некоторые атрибуты «ключ-значение». Например, dev.to включил синтаксис языка шаблонов, который будет вставлен в их редактор Markdown:
{% youtube dQw4w9WgXcQ %}Конечно, для этого необходимо использовать настраиваемый парсер Markdown и иметь специальную логику, чтобы убедиться, что правильный HTML был вставлен, когда синтаксис был преобразован в HTML. И ваши создатели контента должны будут запомнить эти коды (если только не было какой-то панели инструментов для их автоматической вставки). И если скобка будет удалена или испорчена, это может привести к поломке сайта.
Но как насчет MDX?
Попыткой удовлетворить потребность в блочном контенте является MDX, представленный под слоганом «Markdown для эры компонентов». MDX позволяет использовать язык шаблонов JSX, а также JavaScript с чересстрочной разверткой в синтаксисе уценки. В сообществе много впечатляющих разработок вокруг MDX, включая Unified.js , который специализируется на разборе различных синтаксисов в абстрактные синтаксические деревья (AST), чтобы сделать их более доступными для программного использования. Обратите внимание, что стандартизация уценки упростила бы работу разработчиков Unified.js и ее пользователей, потому что нужно учитывать меньше крайних случаев.
MDX, безусловно, позволяет разработчикам лучше интегрировать компоненты в Markdown. Но это не улучшает работу редактора, потому что добавляет много когнитивных издержек при создании и редактировании контента:
import {Chart} from './snowfall.js' export const year = 2018 # Last year's snowfall In {year}, the snowfall was above average. It was followed by a warm spring which caused flood conditions in many of the nearby rivers. <Chart year={year} color="#fcb32c" />Объем предполагаемых знаний только для этого простого примера значителен. Вам нужно знать о модулях ES6, переменных JavaScript, синтаксисе шаблонов JSX и о том, как использовать реквизиты, шестнадцатеричные коды и типы данных, а также знать, какие компоненты вы можете использовать и как их использовать. И вам нужно набирать его правильно и в среде, которая дает вам какую-то обратную связь. Я не сомневаюсь, что помимо MDX появятся более доступные инструменты разработки, это похоже на решение чего-то, что не должно быть проблемой в первую очередь.
Если вы не очень усердны в том, как вы составляете и называете свои компоненты MDX, это также связывает ваш контент с конкретной презентацией. Просто возьмите приведенный выше пример с главной страницы MDX. Вы найдете жестко закодированный шестнадцатеричный цвет для диаграммы. Когда вы изменяете дизайн своего сайта, этот цвет может быть несовместим с вашей новой системой дизайна. Конечно, ничто не мешает вам абстрагироваться от этого и использовать свойство color=”primary” , но в инструменте также нет ничего, что подталкивало бы вас к таким мудрым решениям.
Встраивание конкретных аспектов презентации в ваш контент все чаще становится проблемой и чем-то, что будет мешать адаптации, повторению и быстрому перемещению вашего контента. Он блокирует его гораздо более тонкими способами, чем наличие контента в базе данных. Вы рискуете оказаться в том же месте, что и устаревшая установка WordPress с плагинами. Трудно разделять структуру и представление.
Спрос на структурированный контент
С более сложными сайтами и переходами пользователей мы также видим необходимость представления одних и тех же фрагментов контента на всем веб-сайте. Если вы используете сайт электронной коммерции, вы хотите встроить информацию о продукте во многих местах за пределами одной страницы продукта. Если вы запускаете современный маркетинговый сайт, вы хотите иметь возможность делиться одной и той же копией в нескольких персонализированных представлениях.
Чтобы сделать это эффективно и надежно, вам необходимо адаптировать структурированный контент. Это означает, что ваш контент должен быть встроен в метаданные и разбит на части таким образом, чтобы можно было анализировать намерения. Если разработчик просто видит «страницу» с «контентом», ему очень сложно разместить нужные вещи в нужных местах. Если они смогут получить доступ ко всем «описаниям продуктов» с помощью API или запроса, все станет проще.
С уценкой вы ограничены выражением таксономий и структурированного контента либо в какой-то организации папок (что затрудняет размещение одного и того же фрагмента контента в нескольких таксономиях), либо вам нужно дополнить синтаксис чем-то еще.
Jekyll, ранний генератор статических сайтов (SSG), созданный для файлов уценки, представил «Front Matter» как способ добавления метаданных к сообщениям с использованием YAML (простой формат «ключ-значение», в котором для создания области используются пробелы) между тремя тире вверху. файла. Итак, теперь у вас будет два синтаксиса для работы. YAML также имеет репутацию озорного (особенно если вы из Норвегии). Тем не менее, другие SSG приняли это соглашение, а также CMS на основе git, которые используют уценку в качестве формата своего контента.
Когда вам нужно добавить дополнительный синтаксис в ваши простые файлы, чтобы получить некоторые возможности структурированного контента, вы можете начать задаваться вопросом, действительно ли это того стоит. И для кого формат, а кого он исключает.
Если подумать, многое из того, что мы делаем в Интернете, — это не только потребление контента, но и его создание! В настоящее время я пишу эту длинную статью в продвинутом текстовом процессоре в своем браузере.
Растет ожидание, что вы также сможете создавать блочный контент в современных приложениях для работы с контентом. Люди начали привыкать к восхитительному пользовательскому интерфейсу, который работает и выглядит красиво, и где от вас не ожидается изучения специального синтаксиса. Medium популяризировал представление о том, что вы можете создавать восхитительный и интуитивно понятный контент в Интернете. И, говоря о «понятии», популярное приложение для заметок полностью заблокировало контент и позволяет пользователям смешивать максимум из широкого спектра различных типов. Большинство этих блоков выходит за рамки уценки и нативных элементов HTML.
Примечательно, что Notion, описывая свой процесс, чтобы сделать свой контент доступным через свой долгожданный API, указывает на выбор формата своего контента, что:
Документы из одного редактора Markdown часто анализируются и отображаются по-разному в другом приложении. Несоответствие, как правило, управляемо для простых документов, но это большая проблема для богатой библиотеки блоков и встроенных параметров форматирования Notion, многие из которых просто не поддерживаются ни в одной широко используемой реализации Markdown.
Notion использует формат на основе JSON, который позволяет им представлять структурированные данные. Их аргумент заключается в том, что это упрощает и делает более предсказуемым взаимодействие для разработчиков, которые хотят создать собственное представление блочного содержимого, которое выходит из API-интерфейсов Notion.
Если не уценка, то что?
Я подозреваю, что известность Markdown сдерживает инновации и прогресс цифрового контента. Итак, когда я утверждаю, что мы должны прекратить выбирать его в качестве основного способа хранения контента, трудно дать прямой ответ, что должно его заменить. Однако мы знаем, чего следует ожидать от современных форматов контента и инструментов разработки.
Давайте инвестировать в доступный авторский опыт
Использование уценки требует изучения синтаксиса, а часто и нескольких синтаксисов и специальных тегов, чтобы соответствовать современным ожиданиям. Сегодня это кажется совершенно ненужным ожиданием для большинства людей. Я бы хотел, чтобы мы могли направить больше энергии на создание доступных и восхитительных редакционных материалов, создающих современные переносимые форматы контента.
Несмотря на то, что общеизвестно сложно создавать отличные редакторы блочного контента, есть несколько жизнеспособных вариантов, которые можно расширить и настроить для вашего случая использования (например, Slate.js, Quill.js или Prosemirror). Опять же, инвестирование в сообщества вокруг этих инструментов также может способствовать их дальнейшему развитию.
Все чаще люди ожидают, что инструменты для разработки будут доступными, работающими в режиме реального времени и поддерживающими совместную работу. Почему в 2021 году нужно нажимать кнопку сохранения в Интернете? Почему нельзя внести изменения в документ, не рискуя состоянием гонки, потому что ваш коллега случайно открыл документ на вкладке? Стоит ли ожидать, что авторам придется иметь дело с конфликтами слияния? И разве мы не должны упростить создателям контента работу со структурированным контентом с визуальными возможностями, которые имеют смысл?
Чтобы быть немного полемичным: инновации последнего десятилетия в реактивных средах JavaScript и компонентах пользовательского интерфейса идеально подходят для создания потрясающих инструментов разработки. Вместо того, чтобы использовать их для преобразования Markdown в HTML и в абстрактное синтаксическое дерево, чтобы затем интегрировать его в язык шаблонов JavaScript, который выводит HTML.
Содержимое блока должно соответствовать спецификации
Я не упомянул WYSIWYG-редакторы для HTML. Потому что они неправильные. Современные редакторы блочного содержимого предпочтительно должны взаимодействовать с указанным форматом. Вышеупомянутые редакторы, по крайней мере, имеют разумную внутреннюю модель документа, которую можно преобразовать во что-то более портативное. If you look at the content management system landscape, you start to see various JSON-based block content formats emerge. Some of them are still tied to HTML assumptions or overly concerned with character positions. And none of them aren't really offered as a generic specification.
At Sanity.io, we decided early that the block content format should never assume HTML as neither input nor output, and that we could use algorithms to synchronize text strings. More importantly, was it that block content and rich text should be deeply typed and queryable. The result was the open specification Portable Text. Its structure not only makes it flexible enough to accommodate custom data structures as blocks and inline spans; it's also fully queryable with open-source query languages like GROQ.
Portable Text isn't design to be written or be easily readable in its raw form; it's designed to be produced by an user interface, manipulated by code, and to be serialized and rendered where ever it needs to go. For example, you can use it to express content for voice assistants.
{ "style": "normal", "_type": "block", "children": [ { "_type": "span", "marks": ["a-key", "emphasis"], "text": "some text" } ], "markDefs": [ { "_key": "a-key", "_type": "markType", "extraData": "some data" } ] }An interesting side-effect of turning block content into structured data is exactly that: It becomes data! And data can be queried and processed. That can be highly useful and practical, and it lets you ask your content repository questions that would be otherwise harder and more errorprone in formats like Markdown.
For example, if I for some reason wanted to know what programming languages we've covered in examples on Sanity's blog, that's within reach with a short query. You can imagine how trivial it is to build specialized tools and views on top of this that can be helpful for content editors:
distinct( *["code" in body[]._type] .body[_type == "code"] .language ) // output [ "text", "javascript", "json", "html", "markdown", "sh", "groq", "jsx", "bash", "css", "typescript", "tsx", "scss" ]Example: Get a distinct list of all programming languages that you have code blocks of.
Portable Text is also serializable, meaning that you can recursively loop through it, and make an API that exposes its nodes in callback functions mapped to block types, marked-up spans, and so on. We have spent the last years learning a lot about how it works and how it can be improved, and plan to take it to 1.0 in the near future. The next step is to offer an editor experience outside of Sanity Studio. As we have learned from Markdown, the design intent is important.
Of course, whatever the alternative to markdown is, it doesn't need to be Portable Text, but it needs to be portable text. And it needs to share a lot of its characteristics. There have been a couple of other JSON-based block content format popping up the last few years, but a lot of them seem to bring with them a lot of “HTMLism.” The convenience is understandable, since a lot of content still ends up on the web serialized into HTML, but the convenience limits the portability and the potential for reuse.
You can disregard my short pitch for something we made at Sanity, as long as you embrace the idea of structured content and formats that let you move between systems in a fundamental manner. For example, a goal for Portable Text will be improved compatibility with Unified.js, so it's easier to travel between formats.
Embracing The Legacy Of Markdown
Уценка со всеми ее разновидностями, интерпретациями и форками никуда не денется. I suspect that plain text files will always have a place in developers' note apps, blogs, docs, and digital gardens. As a writer who has used markdown for almost two decades, I've become accustomed to “markdown shortcuts” that are available in many rich text editors and am frequently stumped from Google Docs' lack of markdownisms. But I'm not sure if the next generation of content creators and even developers will be as bought in on markdown, and nor should they have to be.
I also think that markdown captured a culture of savvy tinkerers who love text, markup, and automation. I'd love to see that creative energy expand and move into collectively figuring out how we can make better and more accessible block content editors, and building out an ecosystem around specifications that can express block content that's agnostic to HTML. Structured data formats for block content might not have the same plain text ergonomics, but they are highly “tinkerable” and open for a lot of creativity of expression and authoring.
If you are a developer, product owner, or a decision-maker, I really want you to be circumspect of how you want to store and format your content going forward. If you're going for markdown, at least consider the following trade-offs:
Markdown is not great for the developer experience in modern stacks :
- It can be a hassle to parse and validate, even with great tooling.
- Even if you adopt CommonMark, you aren't guaranteed compatibility with tooling or people's expectations.
- It's not great for structured content, YAML frontmatter only takes you so far.
Markdown is not great for editorial experience :
- Most content creators don't want to learn syntax, their time is better spent on other things.
- Most markdown systems are brittle, especially when people get syntax wrong (which they will).
- It's hard to accommodate great collaborative user experiences for block content on top of markdown.
Markdown is not great in block content age , and shouldn't be forced into it. Block content needs to:
- Be untangled from HTMLisms and presentation agnostic.
- Accommodate structured content, so it can be easily used wherever it needs to be used.
- Have stable specification(s), so it's possible to build on.
- Support real-time collaborative systems.
What's common for people like me who challenge the prevalence of markdown, and those who are really into the simple way of expressing text formating is an appreciation of how we transcribe intent into code. That's where I think we can all meet. But I do think it's time to look at the landscape and the emerging content formats that try to encompass modern needs, and ask how we can make sure that we build something that truly caters to editorial experience, and that can speak to developer experience as well.
I want to express my gratitude to Titus Wormer (@wooorm) for his insightful feedback on my first draft of this post, and for the great work he and the Unified.js team have done for the web community.