
Стратегии для безголовых проектов со структурированными системами управления контентом
Опубликовано: 2022-03-10Это руководство, которое я хотел бы иметь последние пару лет при работе над проектами с безголовыми системами управления контентом (CMS). Я был разработчиком, консультантом по пользовательскому опыту и технологиям, менеджером проектов, информационным архитектором и автором. Различные шляпы заставили меня понять, что даже если у нас уже какое-то время есть так называемые «безголовые» CMS, все еще есть способ подумать, как их лучше всего использовать.
Сейчас мы находимся в том месте, где многие из нас полагаются на фреймворки JavaScript для работы с интерфейсом, используя системы дизайна, состоящие из компонентов и композиций, а не просто реализуя макеты плоских страниц. JAMstacks и изоморфные/универсальные приложения, которые работают как на сервере, так и на клиенте, пользуются большой популярностью. Последней частью головоломки является то, как мы управляем всем контентом.
Традиционные CMS добавляют API для обслуживания контента через сетевые запросы и формат JSON. Кроме того, появились «безголовые» CMS для обслуживания контента исключительно через API. Однако мой аргумент в этой статье заключается в том, что мы должны тратить меньше времени на разговоры о «безголовом» и больше о «структурированном контенте» . Потому что это основное качество этих систем. Эти системы влекут за собой множество последствий для нашего ремесла, и нам еще предстоит пройти долгий путь, чтобы определить хорошие модели того, как мы должны обращаться с этими технологиями.
Придя к технологическому консалтингу, имея опыт работы в гуманитарных науках, я многое узнал о том, как организовывать и работать с веб-проектами, использующими контент-ориентированный подход — как с более новыми API-интерфейсами, так и с традиционными CMS. Я пришел к пониманию того, как рано начать работу с живым контентом из CMS; это в междисциплинарной среде не только позволило выявить сложности на более ранней стадии, но и предоставило свободу выбора всем участникам, а также дало возможность задуматься о проблемах и возможностях технологий и дизайна в самом широком смысле.
Безголовый WordPress
Всем известно, что если сайт работает медленно, пользователи его покинут. Давайте подробнее рассмотрим основы создания несвязанного WordPress. Читать статью по теме →
В этой статье я предложу несколько всеобъемлющих стратегий с некоторыми конкретными примерами из реальной жизни о том, как думать о работе со структурированным контентом. На момент написания я только начал работать в SaaS-компании, которая предоставляет такой сервис управления контентом для размещения контента, доставляемого через API. Я буду ссылаться на него как из-за моего прошлого опыта работы с ним в проектах, в которых я участвовал в качестве консультанта, так и потому, что я думаю, что он точно иллюстрирует то, что я хочу сделать. Так что считайте это своего рода отказом от ответственности.
При этом я думал о написании этой статьи в течение нескольких лет и стремился сделать ее применимой к любой платформе, которую вы выберете. Итак, без лишних слов, давайте прыгнем на двадцать лет назад, чтобы лучше понять, где мы находимся сегодня.
Первые шаги в веб-стандартах
В начале 2000-х годов движение за веб-стандарты вдохновило поле изменить свои методы работы. Исходя из подхода «сначала макет», они обратили наше внимание на то, как контент на странице должен быть семантически размечен с помощью HTML: меню веб-сайта — это не <table> , это <nav> ; Заголовок — это не <b> , это <h1> . Это был значительный шаг к осмыслению различных ролей, которые играет веб-контент, чтобы помочь пользователям найти, идентифицировать и принять его.
Движение за веб-стандарты представило аргумент о том, что семантическая разметка улучшила доступность, что также улучшило его рейтинг в результатах поиска Google. Это также ознаменовало сдвиг в нашем отношении к веб-контенту . Ваш веб-сайт больше не был единственным местом, где был представлен ваш контент. Вы также должны были подумать о том, как ваши веб-страницы будут представлены в других визуальных контекстах, например, в результатах поиска или программах чтения с экрана. Позже этому способствовали социальные сети и встроенные предварительные просмотры общих ссылок. Мышление сместилось от того, как должно выглядеть содержание, к тому, что оно должно означать . Это также является ключом к работе со структурированным контентом.
С появлением карманных устройств, подключенных к Интернету, у Интернета внезапно появился серьезный конкурент среди приложений. Конкуренция, однако, была главным образом для глазных яблок конечного пользователя. Многим организациям по-прежнему необходимо распространять информацию о своих продуктах и услугах как в своих приложениях, так и в различных веб-сайтах. Параллельно развивалась сеть, а JavaScript и AJAX упростили подключение различных источников контента через API. Сегодня у нас есть GraphQL и инструменты, которые упрощают выборку контента и управление состоянием. И вот кусочки технологической головоломки начинают вставать на свои места.
«Создай один раз, опубликуй везде»
Хотя это в основном описывается как «технологический сдвиг», встраивание контента в полезные нагрузки JSON (путешествующие по каналам HTTP) оказывает огромное влияние на то, как мы думаем о цифровом контенте и окружающих рабочих процессах. В некотором смысле это уже произошло. Почти десять лет назад гость Национального общественного радио (NPR) Дэниел Джейкобсон написал в блоге на programmableweb.com об их подходе, кратко изложенном в аббревиатуре COPE, которая означает «Создай один раз, публикуй везде». В статье он представляет систему управления контентом, предоставляющую контент нескольким цифровым интерфейсам через API, а не через машину рендеринга HTML, как это делало большинство CMS в то время (и, возможно, сейчас).
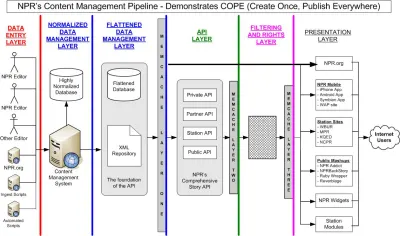
«Уровень управления данными» NPR COPE — это то, что стало бы понятием «безголовой CMS». На заре COPE это достигалось за счет структурирования контента в формате XML. Сегодня JSON стал доминирующим форматом данных для передачи данных через API, включая устройства Интернета вещей и другие системы за пределами Интернета. Если вы хотите обмениваться контентом с помощью чат-ботов, голосовых интерфейсов и даже программного обеспечения для визуального прототипирования, вы очень часто говорите о HTTP с акцентом JSON.
«Расчеканка» термина «безголовая CMS»
Согласно Google Trends, поисковые запросы «безголовая CMS» стали популярными только в 2015 году, то есть через шесть лет после публикации статьи COPE в NPR. Термин «безголовый» (по крайней мере, в отношении цифровых технологий, а не французской аристократии конца 18-го века) уже давно используется для обозначения систем, работающих без графического пользовательского интерфейса.
Примечание . Можно утверждать, что интерфейс командной строки действительно является «графическим», например, программное обеспечение на серверах или в тестовых средах (но давайте оставим это для другой статьи).
У меня двоякое мнение, называя эти новые CMS «безголовыми». С тем же успехом мы могли бы назвать их «полицефалами» — многоголовыми. Это Гидры и Цербеусы CMS. «Безголовые» также определяют эти системы по отсутствующим у них возможностям (т. е. механизму шаблонов для рендеринга веб-страниц), а не по их истинной силе: возможность структурировать контент без ограничений сети. При этом на сегодняшний день многие решения в этой категории также можно назвать «Почти безголовым Ником». Потому что интерфейс редактирования по-прежнему тесно связан с системой. Их «безголовость» возникает из-за отсутствия механизма шаблонов, то есть механизма, создающего разметку из контента.
Примечание . Я бы почти наверняка использовал CMS под названием «Mimsy-Porpington» (известную из вселенной Гарри Поттера).
Вместо этого они делают контент доступным через API, что дает вам больше гибкости в отношении того, как, что и где вы хотите отображать и использовать этот контент. Это делает их идеальными компаньонами для популярных интерфейсных фреймворков JavaScript, таких как React, Angular и Vue. И, несмотря на заявление о возможности доставки контента на «веб-сайты, в приложения и устройства», большинство из них по-прежнему ограничено тем, как работает веб-контент. Это наиболее заметно в том, как большинство обрабатывает форматированный текст — сохраняя его в виде HTML или Markdown.
Традиционные CMS также начали добавлять несколько общих API в дополнение к своим системам рендеринга шаблонов и называют это «несвязанным», чтобы отличиться от своих новых конкурентов. «Все это, а также API!»* — это утверждение. Некоторые из этих CMS также довольно независимы, когда дело доходит до моделирования контента. Например, Craft CMS почти не делает предположений о вашей модели контента при первой установке. Wordpress также движется к использованию API для доставки контента. Я подозреваю, что разрыв между старыми игроками в области CMS и новыми будет сокращаться по мере продвижения вперед.
Тем не менее, внедрение управления контентом в API (вместо средства визуализации HTML) является важным шагом к более сложным способам работы в эпоху, когда текст, изображения, видео и мультимедиа организации оцифровываются и доступны для внутренних и внешних пользователей и клиентов. Однако пришло время перейти от определения недостающих возможностей внешнего рендеринга к тому, что они действительно могут сделать для нас: предоставить нам способ работы со структурированным контентом . Итак, должны ли мы называть их «структурированными системами управления контентом»? Например: «Нет, Боб, это не обычная CMS. Это SCMS, поверьте мне, это будет важно».
Дело не в головах, а в структурированном контенте
Самое радикальное изменение, которое вносят системы управления структурированным содержимым (SCMS), — это отказ от упорядочивания содержимого в соответствии с иерархией страниц в пользу того, что вы можете свободно структурировать содержимое для любой цели, которую считаете подходящей. Отсутствие дублирования контента является явным преимуществом, поскольку повышает надежность и снижает административную нагрузку (вам не нужно справляться с дублированием контента по нескольким каналам). Другими словами: создай один раз, опубликуй везде . Если вам нужно всего лишь один раз обновить описание вашего продукта — в одной системе — и оно обновляется везде, где ваш продукт представлен пользователю, это явное преимущество.
Хотя поставщики SCMS часто используют фразу «ваш веб-сайт и приложение», чтобы оправдать разное понимание структуры страницы, вам не нужно переходить реку, чтобы извлечь выгоду из структурированной структуры контента. С ростом популярности фреймворков JavaScript все чаще и чаще создаются веб-сайты в виде композиции отдельных компонентов, которые могут быть «наполнены» различным контентом в зависимости от состояния и контекста. У вас может быть карточка продукта, которая появляется в разных контекстах вашего веб-приложения. Мы видим, что современная веб-разработка переходит от настройки документов и страниц к составлению компонентов в соответствии с сочетанием пользовательского ввода, алгоритмов и настроек.
Эти тенденции в том, как создаются дизайн-системы, и как нас поощряют работать в команде посредством процессов тестирования, обучения и итерации, делают область управления контентом готовой для некоторых новых способов мышления. Некоторые закономерности появились, но нам еще многое предстоит пройти. Поэтому, основываясь на своем опыте работы в командах и проектах, которые выдвигают контент на первый план и в настоящее время являются частью команды, которая создает для него сервис (и я призываю вас осознавать любые предубеждения здесь), я хочу выдвинуть некоторые стратегии, которые, как я считаю, могут быть полезными и создать темы для дальнейшего обсуждения.
1. Подход к контенту в мультидисциплинарных командах
Я считаю, что графический дизайнер может передать устаревшие, идеальные по пикселям страницы внешнему разработчику, в обязанности которого входило «внедрение» дизайна. Теперь мы создаем дизайн-системы, состоящие из более мелких компонентов, выложенных в композиции, которые поставляются с несколькими возможными состояниями из коробки. Чаще всего эти компоненты должны быть устойчивы к пользовательскому вводу, а это означает, что чем раньше вы введете живой контент в процесс, тем лучше. Ответственность разработчика внешнего интерфейса заключается не в том, чтобы воспроизводить видение графического дизайнера ; это маневрировать в сложном поле того, как браузеры отображают HTML, CSS и JavaScript, гарантируя, что пользовательские интерфейсы отзывчивы, доступны и производительны.
Работая консультантом по технологиям в Netlife (консалтинговая компания, специализирующаяся на пользовательском опыте), я увидел большие шаги в направлении сотрудничества между разработчиками, дизайнерами и исследователями пользователей. Несмотря на то, что наши контент-редакторы всегда были вовлечены в проект с самого начала, их вклад не влиял на рабочий процесс дизайна в основном из-за технических разногласий.
Узким местом часто была устаревшая CMS, которую мы не могли изменить, или то, что для создания структуры контента требовалось время, поскольку она зависела от макета дизайна. Это часто приводило к дублированию работы: мы делали HTML-прототип, часто основанный на контенте, разобранном из Markdown-файлов, который нужно было повторно реализовать в CMS-стеке, когда пользовательское тестирование было завершено, и все были идеально пиксельно довольны. . Часто это был дорогостоящий процесс, поскольку ограничения в CMS обнаруживались на поздних этапах процесса. Это также создает давление на все части, чтобы «сделать все правильно с первого раза», и оставляет меньше места для экспериментов, которые вы хотели бы иметь в дизайн-проекте.
Многопрофильная работа требует гибких систем
Переход на SCMS, в которой кодирование модели содержимого занимало минуты (где поля и API были готовы мгновенно), перевернул наш процесс с ног на голову — и в лучшую сторону. Я помню, как сидел с редактором контента нового u4.no в первые дни проекта. Рассказывая о том, как они работали и хотели бы работать со своим контентом. Довольно быстро мы перевели наши выводы в простые JavaScript-объекты, которые моментально трансформировались в среду редактирования в браузере. Выяснение полезных заголовков и описаний для заголовков. Мы говорили о том, что им нужны текстовые фрагменты, которые они могли бы повторно использовать на разных страницах и в разных контекстах, которые они внутри компании называли «самородками», которые мы затем создавали тут же.
Предоставление такого рода исследований на ранних этапах разработки проекта — когда редактор контента и разработчик разговаривают друг с другом, пока интерфейс создается у нас на глазах, — казалось мощным. Зная, что мы можем продолжить разработку внешнего интерфейса в React, пока она и ее коллеги приступят к работе с контентом. И не беспокоясь о том, чтобы загнать себя в угол, как мы часто делали с CMS, в которых структура была тесно связана с тем, как вам приходилось программировать ее интерфейсную часть.
Контент-система должна позволять экспериментировать и повторять
Помимо творческих проектов редизайна, система для структурированного контента также должна позволять вам продолжать улучшать, тестировать и повторять ваш контент как часть всей вашей системы дизайна. UX-дизайнеры должны иметь возможность быстро создавать прототипы с реальным контентом, используя такие инструменты, как Sketch или Framer X. Вы должны иметь возможность дополнять управление контентом количественными измерениями, будь то масштабы удобочитаемости или то, как контент работает там, где он используется.
Примечание . Я использовал термин «UX-дизайнеры» выше, несмотря на мнение, что мы все должны — так или иначе — иметь отношение к процессу создания хорошего пользовательского опыта. Мы все UX-дизайнеры в разных направлениях дизайна.
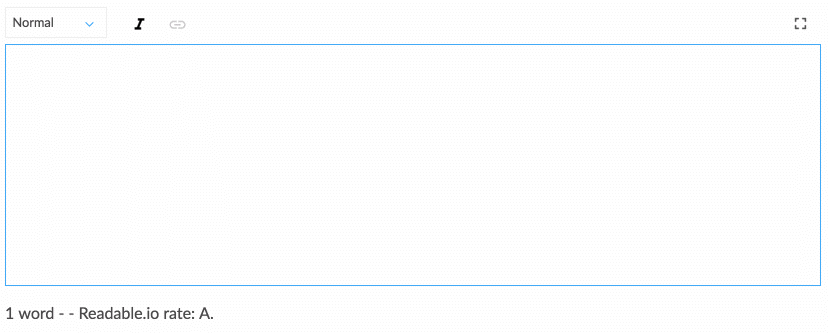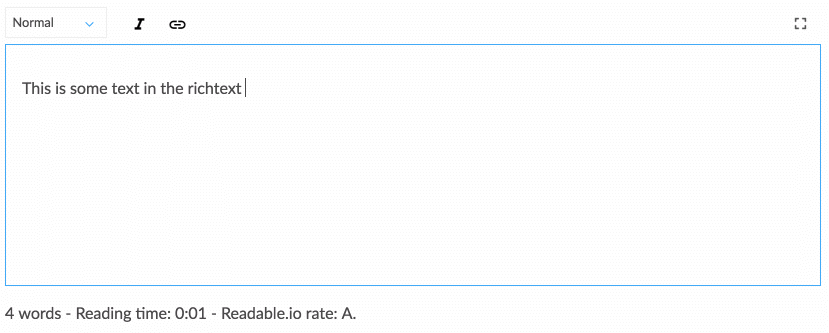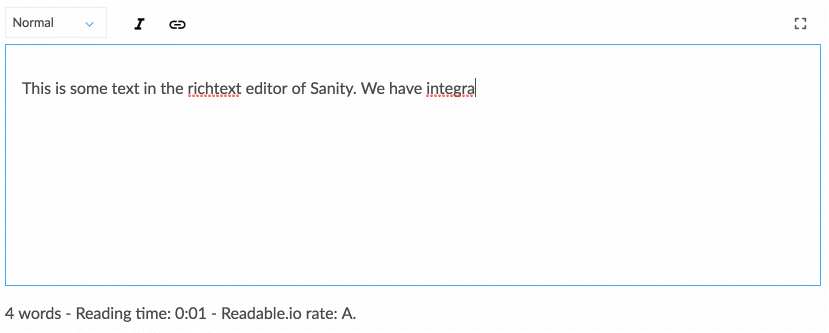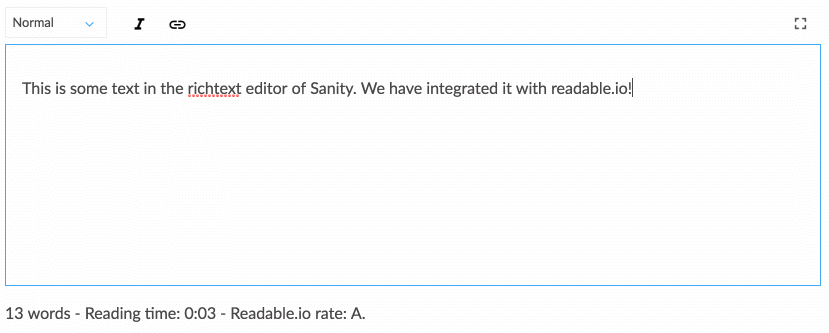
Работа со структурированным содержимым требует некоторого привыкания, если вы привыкли просто отображать содержимое WYSIWYG непосредственно на макете веб-страницы. Тем не менее, он поддается разговору, который больше соответствует тому, как движется область цифрового дизайна. Структурированный контент позволяет команде дизайнеров, разработчиков, редакторов контента, исследователей пользователей и менеджеров проектов совместно думать о том, как система должна работать, чтобы поддерживать потребности пользователей и стратегические цели. Это также требует, чтобы вы по-другому думали о структуре контента, что приводит нас к следующей стратегии.
2. Вам может не понадобиться иерархия
Одним из наиболее заметных изменений для многих является то, что системы структурированного контента ориентированы на коллекции и списки документов, а не на иерархии в виде папок, которые отражают структуру навигации по веб-сайту. Эти структуры перестают иметь смысл, как только часть контента будет использоваться в других контекстах — будь то чат-боты, печатные СМИ или другие веб-сайты. Традиционные CMS пытались смягчить это, позволяя повторно использовать блоки контента, но их по-прежнему необходимо размещать на макетах страниц, и их неудобно использовать через API.
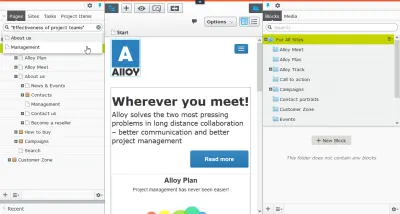
Каждой странице свое
Как указано в Базовой модели, когда одним из ваших основных рефералов является либо Google, либо публикация в социальных сетях, вы должны рассматривать каждую страницу как целевую. И если вы посмотрите на распределение просмотров страниц, вы заметите, что некоторые из ваших страниц более популярны, чем другие. Если вы не новостной веб-сайт, это, как правило, не новости, а те, которые позволяют пользователю достичь всего, чего он надеялся достичь на вашем веб-сайте. Они там, где на самом деле происходит бизнес.
Ваш цифровой контент должен служить пересечению ваших собственных стратегических целей и индивидуальных целей ваших пользователей. Когда цифровое агентство Bengler (предшественник sanity.io) создавало новый веб-сайт для oma.eu, они не структурировали контент после сложной иерархии страниц. Они создали типы контента, отражающие организационную повседневную реальность, т.е. после проектов , персон и публикаций . Фактически, веб-сайт OMA почти полностью плоский с точки зрения иерархии контента, а главная страница создается на основе сочетания алгоритмических и редакционных правил.

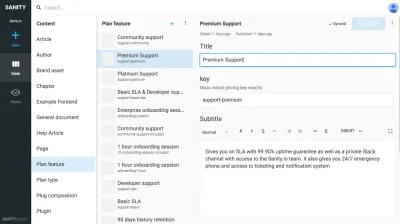
Итак, как это сделать? Я считаю, что сочетание размышлений о вашем контенте является отражением ментальной модели вашей организации и того, какой она должна быть, чтобы быть полезной для всего, для чего она нужна вашим пользователям.
Вот простой пример: при создании страницы сотрудников вам, вероятно, следует начать с типа контента под названием person . У человека может быть имя, контактная информация, изображение, различные организационные роли и краткая биография. Личный документ можно повторно использовать в списках контактов, подписях авторов статей, интерфейсах поддержки чата и создании значков доступа. Возможно, у вас уже есть внутренняя система, которая знает, кто эти люди, и поставляется с API? Отлично, тогда синхронизируйтесь с этим.
Не заблудитесь в онтологической кроличьей норе
Полезно вернуться к тому, как Google индексирует веб-страницы и как они пытаются индексировать информацию со всего мира. Вот почему они тратят время и усилия на связанные данные (RDFa, микроформат, JSON-LD). Если вы аннотируете свои веб-страницы элементами JSON-LD, вы будете более заметны в результатах поиска. Это также актуально, когда ваша информация должна быть произнесена голосовыми помощниками и отображена в пользовательском интерфейсе помощника. Если ваш контент уже структурирован и легко доступен через API, вам будет относительно легко реализовать его в этих микроформатах.
Я не уверен, что рекомендовал бы полностью использовать онтологии schema.org и различные ресурсы связанных данных, по крайней мере, не для редакторских целей. Вы можете быстро заблудиться в кроличьей норе, пытаясь создать идеальные платонические структуры, в которые все вписывается.
Newsflash : Никогда не будет, потому что мир — грязное место, и потому что люди думают о вещах по-разному.
Более важно структурировать ваш контент в системе, которая интуитивно понятна и поддается адаптации по мере изменения потребностей. Вот почему важно начать моделирование контента на ранней стадии процесса проектирования и разработки — вам нужно узнать, как его нужно использовать.
Абстрагируйтесь от реальности, а не от условностей CMS
Может возникнуть соблазн просто следовать любым соглашениям, которые поддерживает ваша CMS. Помните, как Wordpress выдает вам «Сообщения» и «Страницы», и вдруг все нужно вместить в эти поля? Форматированное текстовое поле WYSIWYG является гибким в том смысле, что оно позволяет вам вводить что угодно, но содержимое не будет структурировано и легко адаптируется — оно будет гибким только один раз. Но вам нужно с чего-то начать отображение модели контента. Я предлагаю начать с общения с людьми, то есть с авторами и читателями.
Как люди говорят о контенте внутри компании? Как люди называют разные вещи? Вы можете провести бесплатное упражнение по составлению списков — метод, используемый этнографами для картографирования народных таксономий. Например, вы можете спросить:
«Назовите различные типы контента в нашей организации».
Или, на более конкретном уровне:
«Можете ли вы назвать различные типы отчетов, которые есть в нашей организации?»
Смысл этого опроса в том, чтобы выявить интернализированные таксономии, которые несут люди, а не их мнения или чувства по поводу вещей (что-то, что часто имеет тенденцию мешать процессам проектирования). Вам не нужно спрашивать особенно много, прежде чем вы получите довольно исчерпывающий список, с которым вы можете работать. Вы, вероятно, обнаружите, что части вашего списка исходят из соглашений вашей текущей CMS (это полезно знать, если вы собираетесь что-то переделывать). Теперь вы должны поговорить со своим редактором и попытаться определить, для чего ему нужен контент.
Некоторые вопросы, которые вы можете задать, могут быть следующими:
- Вам нужно использовать этот контент более чем в одном месте? Где?
- Каковы различные отношения между типами контента?
- Где нам нужно, чтобы контент отображался сегодня и завтра?
- Каким образом нам нужно сортировать контент? Может ли порядок быть сделан алгоритмически, пользователем, или это должно быть сделано вручную?
- Существуют ли системы или базы данных в других системах, с которыми мы можем синхронизироваться, чтобы предотвратить дублирование?
- Где мы хотим, чтобы канонический контент жил? Должна ли SCMS быть источником для него или просто дополнять существующий контент, например, маркетинговый текст для продуктов, живущих в системе управления продуктами?
Это не означает, что вы должны выбросить традиционную информационную архитектуру вместе с теплой водой. По-прежнему имеет смысл иметь статьи в качестве типа контента, если статьи являются частью реальности контента вашей организации. Но, возможно, вам действительно не нужно абстрактное соглашение о категориях , потому что в этих статьях есть ссылки на тип услуг или продуктов в них. И это отношение позволяет запрашивать эти статьи в обстоятельствах, когда это имеет смысл, не требуя, чтобы кто-то имел «управление категориями статей» как часть их должностных инструкций.
Из-за статьи также трудно полностью отделить контент от уровня представления. Мы так привыкли думать о макете и стиле статьи, но в эпоху, когда вы должны размещать свой собственный контент на своем собственном домене, а затем синдицировать его на такие платформы, как medium.com, вы уже сдались. контроль над визуальным представлением. Это подводит нас к следующей стратегии.
3. Контексты презентации также являются типами контента
Будьте готовы к редизайну
Вы также хотите иметь возможность адаптировать и быстро изменять структуру навигации вашего веб-сайта без необходимости перестраивать всю архитектуру контента или бороться со строгим интерфейсом, похожим на папку. Вы также хотите иметь некоторую иерархию контента, потому что иногда это имеет смысл, а иногда становится глубже, чем два уровня, где большинство интерфейсов в отделе API-first CMS не могут предоставить большую помощь.
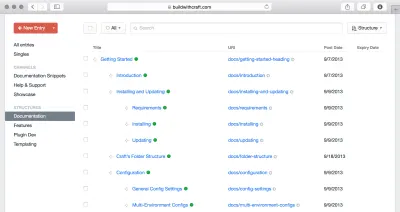
Интересно, что системы управления контентом для чат-ботов, как правило, используют аналогичные иерархические структуры для организации деревьев намерений и диалоговых потоков. Это говорит о том, что иерархии контента играют разные роли в разных каналах, но часто они предоставляют способы навигации по контенту. Подойти к этому можно с помощью типов для навигации, в которых вы можете упорядочивать содержимое по ссылкам, а также строить маршруты для веб-страниц, меню или пути для диалоговых интерфейсов.
Совет по отношениям
Ссылки (или отношения) — это то, что делает возможной систему для структурированного контента, и это действительно ядро всего, с чем мы имеем дело, когда дело доходит до контента в сети (в первую очередь, это причина, по которой это метафорически называется сетью ). Возможность создавать ссылки между битами контента — очень мощная вещь, но она также может быть дорогостоящей с точки зрения того, как серверные части могут записывать и извлекать такие данные. Таким образом, вам, возможно, придется думать по-другому, если у вас есть множество документов, поскольку масштаб редко предоставляется бесплатно.
Также стоит учитывать, что вам не всегда нужна явная ссылка для соединения данных; чаще всего это можно сделать по критерию, связанному с содержанием, например, «дайте мне всех людей и все здания в пределах этой геолокации». Здание и люди не должны иметь явную ссылку друг на друга, если это подразумевается в поле местоположения для обоих типов контента.
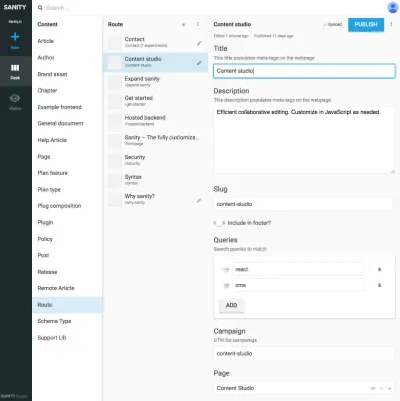
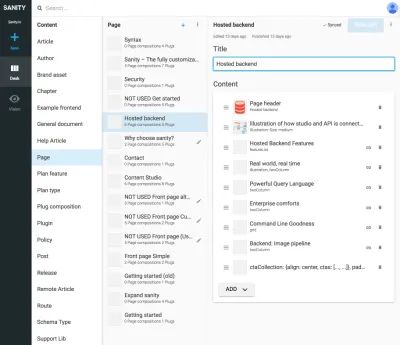
Ссылки между типами представления и другими типами контента полезны, когда вы не можете предоставить алгоритму уровня представления объединять данные. Может показаться немного громоздким явно отрисовывать эти типы презентаций и создавать композиции из упомянутого контента, но это решение проблемы, с которой вы часто столкнетесь в SCMS: трудно понять, где используется контент. Включив типы навигации, вы явно привяжете контент к презентации, но не только к одному. Это позволяет работать с навигационными структурами независимо от содержания, к которому они ведут.
Например, на скриншотах мы привязали Google Experiments к типу маршрутов , что позволяет добавлять несколько страниц , состоящих из ссылок на контент, а это значит, что мы можем запускать A/B-тесты практически без дублирования контента. Поскольку мы также получаем предупреждение, если пытаемся удалить содержимое, на которое ссылаются другие документы, такой способ структурирования не позволит нам удалить то, что не следует делать.
Отношения между типами контента — палка о двух концах. Это повышает устойчивость и является ключом к предотвращению дублирования. С другой стороны, вы можете легко порезаться, потому что вы делаете зависимости между контентом, что (если не сделать его прозрачным) может привести к непреднамеренным изменениям в каналах, где отображаются ваши данные. Например, было бы плохо, если бы мы могли без предупреждения удалить «страницу», используемую «маршрутом».
Это приводит нас к следующей стратегии, которая (разумеется!) частично не под силу обычному пользователю на сегодняшний день, поскольку она связана с тем, как устроены различные системы. Тем не менее, стоит подумать.
4. Не размещайте форматированный текст в углу
Форматированный текст — это больше, чем HTML
Я могу понять, почему HTML так распространен в цифровом контенте, но знаю, что он тоже откуда-то взялся; это подмножество SGML, обобщенного способа структурирования машиночитаемых документов. Как отмечает Клэр Л. Эванс в замечательной книге «Broad Band: невыразимая история женщин, создавших Интернет» (2018 г.), к моменту появления HTML уже существовало активное сообщество людей, которые думали о связанных документах. Предложение Тима Бернерса-Ли было намного проще, чем многие другие системы того времени, но, вероятно, именно поэтому оно прижилось и сделало — на данный момент — открытый, бесплатный Интернет возможным.
Когда вы находитесь в браузере во всемирной паутине, HTML великолепен. Если вы писатель, который хочет опубликовать что-то, что заканчивается простым HTML, Markdown отлично подходит. Если вы хотите, чтобы ваш форматированный текстовый контент легко интегрировался во что-то, кроме браузера, или популярную среду JavaScript, которая позволяет дополнять HTML с помощью JavaScript в сложных компонентах (да, мы говорим о React и Vue.js) , наличие HTML в ответах вашего API становится немного хлопотным, особенно если вам нужно его проанализировать.
Однако почти все это делают, даже новички в этом районе: я просмотрел всех поставщиков на headlesscms.org и просмотрел документацию, а также подписался на тех, кто не упомянул об этом. За двумя исключениями, все они сохраняли форматированный текст либо в формате HTML, либо в формате Markdown. Это нормально, если все, что вы делаете, это используете Jekyll для рендеринга веб-сайта или если вам нравится опасно использовать SetInnerHTML в React. Но что, если вы хотите повторно использовать свой контент в интерфейсах, которых нет в Интернете? Или если вам нужно больше контроля и функциональности в вашем текстовом редакторе? Или просто хотите, чтобы ваш форматированный текст было проще отображать в одной из популярных интерфейсных сред, и чтобы ваши компоненты заботились о разных частях вашего форматированного текстового контента? Что ж, вам придется либо найти умный способ разобрать эту уценку или HTML на то, что вам нужно, либо, что более удобно, просто хранить его более разумно в первую очередь.
Например, что, если вы хотите вывести форматированный текст в голосовой интерфейс? Мы знаем, что голосовые помощники становятся все более популярными. Самые популярные платформы для этих помощников имеют возможность получать текст для разговорного контента через API. Тогда вы хотите воспользоваться чем-то вроде языка разметки синтеза речи. Система переносимого текста использует более независимый подход к форматированному тексту, что позволяет адаптировать один и тот же контент для разных типов интерфейсов.
Рекомендуемая литература : Эксперименты с интерфейсом SpeechSynthesis
Переносимый текст как агностическая модель расширенного текста
Переносимый текст также полезен, когда вы в основном создаете контент для Интернета. Что, если вы хотите иметь возможность вкладывать и дополнять свой текст структурами данных, такими как сноска с форматированным текстом или встроенный редакционный комментарий? Или альтернативная фраза или формулировка для кейсов A/B-тестирования? Markdown и HTML быстро терпят неудачу, и вам придется полагаться на добавление чего-то вроде специальных тегов шорткода, как это решил Wordpress. С переносимым текстом у вас есть независимое представление структур контента без необходимости связываться с определенной реализацией. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you'll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn't widely adopted, but we're seeing movements towards it. The specification isn't very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn't just used for your organization's online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it's about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can't know prior to solving the problem whether the user tasks are best solved by making carousels ( newsflash: most probably not ), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile ( there's my coin for the swear jar ) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn't a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we've taken for granted for many years, but that's probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.