
Прогнозирование фондового рынка с помощью машинного обучения [пошаговая реализация]
Опубликовано: 2021-02-26Оглавление
Введение
Прогнозирование и анализ фондового рынка являются одними из самых сложных задач. Для этого есть несколько причин, таких как волатильность рынка и множество других зависимых и независимых факторов, влияющих на определение стоимости конкретной акции на рынке. Из-за этих факторов любому аналитику фондового рынка очень трудно предсказать рост и падение с высокой степенью точности.
Однако с появлением машинного обучения и его надежных алгоритмов последние разработки в области анализа рынка и прогнозирования фондового рынка начали включать такие методы для понимания данных фондового рынка.
Короче говоря, алгоритмы машинного обучения широко используются многими организациями для анализа и прогнозирования стоимости акций. В этой статье будет рассмотрена простая реализация анализа и прогнозирования стоимости акций популярного во всем мире розничного интернет-магазина с использованием нескольких алгоритмов машинного обучения в Python.
Постановка задачи
Прежде чем мы приступим к реализации программы для прогнозирования стоимости фондового рынка, давайте визуализируем данные, с которыми мы будем работать. Здесь мы будем анализировать стоимость акций Microsoft Corporation (MSFT) по данным автоматизированных котировок Национальной ассоциации дилеров по ценным бумагам (NASDAQ). Данные о стоимости акций будут представлены в виде файла с разделителями-запятыми (.csv), который можно открыть и просмотреть с помощью Excel или электронной таблицы.
Акции MSFT зарегистрированы в NASDAQ, и их стоимость обновляется в течение каждого рабочего дня фондового рынка. Обратите внимание, что рынок не позволяет торговать по субботам и воскресеньям; следовательно, существует разрыв между двумя датами. Для каждой даты отмечаются Начальная стоимость акции, Самая высокая и Самая низкая стоимость этой акции в те же дни, а также Цена закрытия в конце дня.
Скорректированная стоимость закрытия показывает стоимость акции после публикации дивидендов (слишком технический!). Кроме того, также приводится общий объем акций на рынке. С этими данными специалист по машинному обучению / специалисту по данным должен изучить данные и внедрить несколько алгоритмов, которые могут извлекать закономерности из истории акций корпорации Microsoft. данные.

Долгая кратковременная память
Чтобы разработать модель машинного обучения для прогнозирования цен на акции корпорации Microsoft, мы будем использовать метод долговременной кратковременной памяти (LSTM). Они используются для внесения небольших изменений в информацию путем умножения и добавления. По определению, долговременная память (LSTM) — это архитектура искусственной рекуррентной нейронной сети (RNN), используемая в глубоком обучении.
В отличие от стандартных нейронных сетей с прямой связью, LSTM имеет связи с обратной связью. Он может обрабатывать отдельные точки данных (например, изображения) и целые последовательности данных (например, речь или видео). Чтобы понять концепцию LSTM, давайте возьмем простой пример онлайн-отзыва клиента о мобильном телефоне.
Предположим, мы хотим купить мобильный телефон, мы обычно ссылаемся на интернет-обзоры сертифицированных пользователей. В зависимости от их мышления и информации мы решаем, хорош или плох мобильный телефон, а затем покупаем его. Продолжая читать обзоры, мы ищем такие ключевые слова, как «отлично», «хорошая камера», «лучший резервный аккумулятор» и многие другие термины, связанные с мобильным телефоном.
Мы склонны игнорировать общеупотребительные слова в английском языке, такие как «it», «give», «this» и т. д. Таким образом, когда мы решаем, покупать мобильный телефон или нет, мы запоминаем только эти ключевые слова, определенные выше. Скорее всего, мы забываем другие слова.
Точно так же работает алгоритм долговременной кратковременной памяти. Он запоминает только релевантную информацию и использует ее для прогнозирования, игнорируя нерелевантные данные. Таким образом, мы должны построить модель LSTM, которая по существу распознает только основные данные об этой акции и не учитывает ее выбросы.
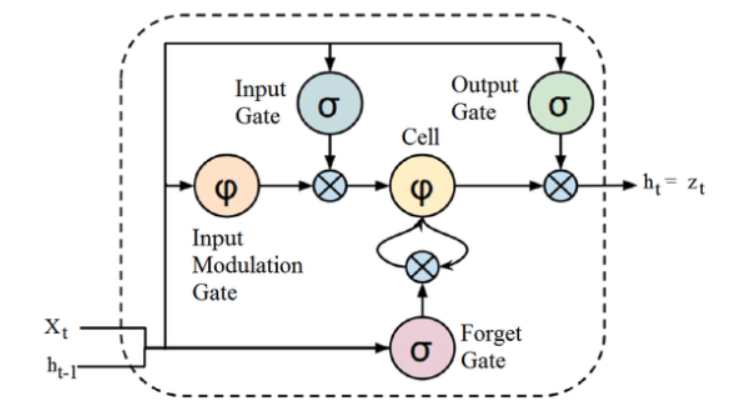
Источник
Хотя приведенная выше структура архитектуры LSTM поначалу может показаться интригующей, достаточно помнить, что LSTM — это расширенная версия рекуррентных нейронных сетей, которая сохраняет память для обработки последовательностей данных. Он может удалять или добавлять информацию о состоянии ячейки, тщательно регулируемую структурами, называемыми воротами.
Блок LSTM включает ячейку, входной вентиль, выходной вентиль и вентиль забывания. Клетка запоминает значения через произвольные промежутки времени, а трое ворот регулируют поток информации в ячейку и из нее.
Реализация программы
Мы перейдем к той части, где мы используем LSTM для прогнозирования стоимости акций с использованием машинного обучения в Python.
Шаг 1 – Импорт библиотек
Как мы все знаем, первым шагом является импорт библиотек, необходимых для предварительной обработки данных о запасах корпорации Microsoft, и других необходимых библиотек для построения и визуализации выходных данных модели LSTM. Для этого мы будем использовать библиотеку Keras в рамках фреймворка TensorFlow. Необходимые модули импортируются из библиотеки Keras по отдельности.
#Импорт библиотек
импортировать панд как PD
импортировать NumPy как np
%matplotlib встроенный
импортировать матплотлиб. pyplot как plt
импортировать matplotlib
из склеарна. Предварительная обработка импорта MinMaxScaler
из Кераса. импорт слоев LSTM, Dense, Dropout
из sklearn.model_selection импортировать TimeSeriesSplit
из sklearn.metrics импорта mean_squared_error, r2_score
импортировать матплотлиб. даты как мандаты
из склеарна. Предварительная обработка импорта MinMaxScaler
из sklearn импортировать linear_model
из Кераса. Импорт моделей Последовательный
из Кераса. Слои импортируют плотные
импортировать Керас. Бэкенд как K
из Кераса. Импорт обратных вызовов EarlyStopping
из Кераса. Оптимизаторы импортируют Адама
из Кераса. Импорт моделей load_model
из Кераса. Слои импортируют LSTM
из Кераса. utils.vis_utils импорта plot_model
Шаг 2. Получение визуализации данных
Используя библиотеку чтения данных Pandas, мы загрузим данные о запасах локальной системы в виде файла значений, разделенных запятыми (.csv), и сохраним их в кадре данных pandas. Наконец, мы также просмотрим данные.
#Получить набор данных
df = pd.read_csv("MicrosoftStockData.csv", na_values=['null'],index_col='Date',parse_dates=True, infer_datetime_format=True)
дф.голова()
Получите сертификацию ИИ онлайн в лучших университетах мира — магистерские программы, программы последипломного образования для руководителей и продвинутую сертификационную программу в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
Шаг 3. Распечатайте форму DataFrame и проверьте наличие нулевых значений.
На этом еще одном важном шаге мы сначала печатаем форму набора данных. Чтобы убедиться, что во фрейме данных нет нулевых значений, мы проверяем их. Наличие нулевых значений в наборе данных, как правило, вызывает проблемы во время обучения, поскольку они действуют как выбросы, вызывающие большие различия в процессе обучения.
# Распечатать форму Dataframe и проверить наличие нулевых значений
print("Форма кадра данных: ", df. shape)
print("Присутствует нулевое значение: ", df.IsNull().values.any())
>> Форма кадра данных: (7334, 6)
>> Присутствует нулевое значение: False
| Дата | Открыть | Высоко | Низкий | Закрывать | Корректировка Закрыть | Объем |
| 1990-01-02 | 0,605903 | 0,616319 | 0,598090 | 0,616319 | 0,447268 | 53033600 |
| 1990-01-03 | 0,621528 | 0,626736 | 0,614583 | 0,619792 | 0,449788 | 113772800 |
| 1990-01-04 | 0,619792 | 0,638889 | 0,616319 | 0,638021 | 0,463017 | 125740800 |
| 1990-01-05 | 0,635417 | 0,638889 | 0,621528 | 0,622396 | 0,451678 | 69564800 |
| 1990-01-08 | 0,621528 | 0,631944 | 0,614583 | 0,631944 | 0,458607 | 58982400 |
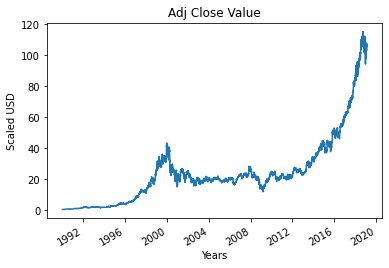
Шаг 4 – Построение истинного скорректированного значения закрытия
Окончательное выходное значение, которое должно быть предсказано с использованием модели машинного обучения, — это скорректированное значение закрытия. Это значение представляет собой стоимость акций на момент закрытия в конкретный день торгов на фондовом рынке.
#Нанесите на график значение True Adj Close
df['Adj Close'].plot()
Шаг 5 — Установка целевой переменной и выбор функций
На следующем шаге мы назначаем выходной столбец целевой переменной. В данном случае это скорректированная относительная стоимость акций Microsoft. Кроме того, мы также выбираем функции, которые действуют как независимая переменная для целевой переменной (зависимой переменной). Чтобы учесть цели обучения, мы выбираем четыре характеристики, а именно:

- Открыть
- Высоко
- Низкий
- Объем
#Установить целевую переменную
output_var = PD.DataFrame(df['Adj Close'])
#Выбор функций
функции = ['Открыть', 'Высокий', 'Низкий', 'Громкость']
Шаг 6 – Масштабирование
Чтобы уменьшить вычислительную стоимость данных в таблице, мы уменьшим значения запасов до значений от 0 до 1. Таким образом, все данные в больших числах будут уменьшены, что уменьшит использование памяти. Кроме того, мы можем получить большую точность за счет уменьшения масштаба, поскольку данные не разбросаны в огромных значениях. Это выполняется классом MinMaxScaler библиотеки sci-kit-learn.
#Масштабирование
масштабатор = MinMaxScaler()
feature_transform = scaler.fit_transform(df[features])
feature_transform = pd.DataFrame (столбцы = функции, данные = функция_преобразования, индекс = df.index)
feature_transform.head()
| Дата | Открыть | Высоко | Низкий | Объем |
| 1990-01-02 | 0,000129 | 0,000105 | 0,000129 | 0,064837 |
| 1990-01-03 | 0,000265 | 0,000195 | 0,000273 | 0,144673 |
| 1990-01-04 | 0,000249 | 0,000300 | 0,000288 | 0,160404 |
| 1990-01-05 | 0,000386 | 0,000300 | 0,000334 | 0,086566 |
| 1990-01-08 | 0,000265 | 0,000240 | 0,000273 | 0,072656 |
Как упоминалось выше, мы видим, что значения переменных признаков уменьшены до меньших значений по сравнению с реальными значениями, указанными выше.
Шаг 7 — Разделение на обучающий набор и тестовый набор.
Прежде чем вводить данные в обучающую модель, нам нужно разделить весь набор данных на обучающий и тестовый наборы. Модель машинного обучения LSTM будет обучаться на данных, представленных в обучающем наборе, и проверяться на тестовом наборе на точность и обратное распространение.
Для этого мы будем использовать класс TimeSeriesSplit библиотеки sci-kit-learn. Мы устанавливаем количество разбиений равным 10, что означает, что 10% данных будут использоваться в качестве тестового набора, а 90% данных будут использоваться для обучения модели LSTM. Преимущество использования этого разделения временных рядов заключается в том, что выборки данных разделенных временных рядов наблюдаются через фиксированные интервалы времени.
# Разделение на обучающий набор и тестовый набор
временной интервал = TimeSeriesSplit (n_splits = 10)
для train_index, test_index в timesplit.split(feature_transform):
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Шаг 8 — Обработка данных для LSTM
Как только обучающие и тестовые наборы будут готовы, мы можем передать данные в модель LSTM после ее создания. Перед этим нам нужно преобразовать данные обучающего и тестового набора в тип данных, который примет модель LSTM. Сначала мы преобразуем данные обучения и тестовые данные в массивы NumPy, а затем преобразуем их в формат (количество выборок, 1, количество функций), поскольку LSTM требует, чтобы данные подавались в 3D-форме. Как мы знаем, количество выборок в обучающей выборке составляет 90% от 7334, что составляет 6667, а количество признаков равно 4, обучающая выборка преобразуется в (6667, 1, 4). Точно так же изменяется и тестовый набор.
# Обработать данные для LSTM
поездX = np.массив (X_train)
testX = np.массив (X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
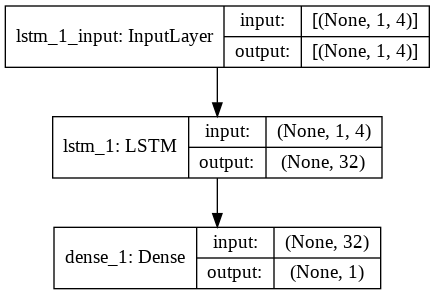
Шаг 9 — Построение модели LSTM
Наконец, мы подошли к этапу построения модели LSTM. Здесь мы создаем модель Sequential Keras с одним слоем LSTM. Слой LSTM состоит из 32 единиц, за ним следует один плотный слой из 1 нейрона.
Мы используем оптимизатор Адама и среднеквадратичную ошибку в качестве функции потерь для компиляции модели. Эти два являются наиболее предпочтительной комбинацией для модели LSTM. Кроме того, модель также построена и показана ниже.
#Построение модели LSTM
лстм = Последовательный()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), активация='relu', return_sequences=False))
lstm.add (плотный (1))
lstm.compile (потеря = 'mean_squared_error', оптимизатор = 'адам')
plot_model (lstm, show_shapes = Истина, show_layer_names = Истина)
Шаг 10 – Обучение модели
Наконец, мы обучаем модель LSTM, разработанную выше, на обучающих данных для 100 эпох с размером пакета 8, используя функцию подбора.
#Обучение модели
history = lstm.fit(X_train, y_train, epochs=100, batch_size=8, verbose=1, shuffle=False)
Эпоха 1/100
834/834 [===============================] – 3 с 2 мс/шаг – потери: 67,1211
Эпоха 2/100
834/834 [===============================] – 1 с 2 мс/шаг – потери: 70,4911
Эпоха 3/100
834/834 [==============================] – 1 с 2 мс/шаг – потери: 48,8155
Эпоха 4/100
834/834 [==============================] – 1 с 2 мс/шаг – потери: 21,5447
Эпоха 5/100
834/834 [==============================] – 1 с 2 мс/шаг – потери: 6,1709
Эпоха 6/100
834/834 [==============================] – 1 с 2 мс/шаг – потеря: 1,8726
Эпоха 7/100
834/834 [===============================] – 1 с 2 мс/шаг – потери: 0,9380
Эпоха 8/100
834/834 [==============================] – 2 с 2 мс/шаг – потери: 0,6566
Эпоха 9/100
834/834 [==============================] – 1 с 2 мс/шаг – потери: 0,5369
Эпоха 10/100
834/834 [===============================] – 2 с 2 мс/шаг – потери: 0,4761
.
.
.
.
Эпоха 95/100
834/834 [===============================] – 1 с 2 мс/шаг – потери: 0,4542
Эпоха 96/100
834/834 [===============================] – 2 с 2 мс/шаг – потери: 0,4553
Эпоха 97/100
834/834 [==============================] – 1 с 2 мс/шаг – потери: 0,4565
Эпоха 98/100
834/834 [==============================] – 1 с 2 мс/шаг – потери: 0,4576
Эпоха 99/100
834/834 [===============================] – 1 с 2 мс/шаг – потери: 0,4588
Эпоха 100/100
834/834 [==============================] – 1 с 2 мс/шаг – потери: 0,4599
Наконец, мы видим, что значение потерь экспоненциально уменьшалось с течением времени в процессе обучения из 100 эпох и достигло значения 0,4599.
Шаг 11 — Прогноз LSTM
Когда наша модель готова, пришло время использовать модель, обученную с использованием сети LSTM, на тестовом наборе и предсказать соседнюю стоимость закрытия акций Microsoft. Это выполняется с помощью простой функции прогнозирования построенной модели lstm.
#LSTM-прогноз
y_pred= lstm.predict(X_test)
Шаг 12 — Истинное и прогнозируемое значение Adj Close — LSTM
Наконец, поскольку мы предсказали значения тестового набора, мы можем построить график для сравнения истинных значений Adj Close и прогнозируемого значения Adj Close с помощью модели машинного обучения LSTM.
#True против прогнозируемого Adj Close Value - LSTM
plt.plot(y_test, метка='Истинное значение')
plt.plot(y_pred, метка='Значение LSTM')
plt.title («Прогноз LSTM»)
plt.xlabel('Шкала времени')
plt.ylabel('В пересчете на доллары США')
plt.legend()
plt.show()
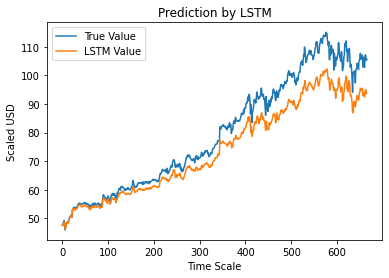
На приведенном выше графике показано, что некоторый шаблон обнаруживается очень простой одиночной сетевой моделью LSTM, построенной выше. Путем точной настройки нескольких параметров и добавления в модель дополнительных слоев LSTM мы можем добиться более точного представления стоимости акций любой данной компании.
Заключение
Если вам интересно узнать больше о примерах искусственного интеллекта и машинном обучении, ознакомьтесь с программой Executive PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, которая предназначена для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований. и задания, статус выпускника IIIT-B, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Можете ли вы предсказать фондовый рынок с помощью машинного обучения?
Сегодня у нас есть ряд индикаторов, помогающих прогнозировать рыночные тенденции. Тем не менее, чтобы найти наиболее точные индикаторы для фондового рынка, нам не нужно искать ничего, кроме мощного компьютера. Фондовый рынок — это открытая система, и его можно рассматривать как сложную сеть. Сеть состоит из отношений между акциями, компаниями, инвесторами и объемами торговли. Используя алгоритм интеллектуального анализа данных, такой как машина опорных векторов, вы можете применить математическую формулу для извлечения взаимосвязей между этими переменными. Фондовый рынок сейчас находится за пределами человеческих предсказаний.
Какой алгоритм лучше всего подходит для предсказания фондового рынка?
Для достижения наилучших результатов следует использовать линейную регрессию. Линейная регрессия — это статистический подход, который используется для определения взаимосвязи между двумя разными переменными. В этом примере переменными являются цена и время. В прогнозировании фондового рынка цена является независимой переменной, а время — зависимой переменной. Если можно определить линейную зависимость между этими двумя переменными, то можно точно предсказать стоимость акций в любой момент в будущем.
Является ли предсказание фондового рынка проблемой классификации или регрессии?
Прежде чем мы ответим, нам нужно понять, что означают прогнозы фондового рынка. Это проблема бинарной классификации или проблема регрессии? Предположим, мы хотим предсказать будущее акции, где будущее означает следующий день, неделю, месяц или год. Если прошлые результаты акции в какой-то момент времени являются входными данными, а будущие — выходными данными, то это проблема регрессии. Если прошлые результаты акций и будущие акции независимы, то это проблема классификации.