
Обмен данными между несколькими серверами через AWS S3
Опубликовано: 2022-03-10При предоставлении некоторых функций для обработки файла, загруженного пользователем, файл должен быть доступен для процесса на протяжении всего выполнения. Простая операция загрузки и сохранения не вызывает проблем. Однако, если, кроме того, с файлом необходимо манипулировать перед сохранением, а приложение работает на нескольких серверах за балансировщиком нагрузки, то нам необходимо убедиться, что файл доступен для любого сервера, на котором запущен процесс в каждый момент времени.
Например, многоэтапная функция «Загрузить аватар пользователя» может потребовать, чтобы пользователь загрузил аватар на шаге 1, обрезал его на шаге 2 и, наконец, сохранил на шаге 3. После загрузки файла на сервер на шаге 1, файл должен быть доступен любому серверу, обрабатывающему запрос для шагов 2 и 3, которые могут совпадать или не совпадать с запросом для шага 1.
Наивным подходом было бы копирование загруженного файла на шаге 1 на все остальные серверы, чтобы файл был доступен на всех из них. Однако такой подход не только чрезвычайно сложен, но и невыполним: например, если сайт работает на сотнях серверов из нескольких регионов, то его невозможно реализовать.
Возможное решение — включить «закрепленные сеансы» в балансировщике нагрузки, который всегда будет назначать один и тот же сервер для данного сеанса. Затем шаги 1, 2 и 3 будут обрабатываться одним и тем же сервером, а файл, загруженный на этот сервер на шаге 1, все еще будет там для шагов 2 и 3. Однако закрепленные сеансы не являются полностью надежными: если между шагами 1 и 2 этот сервер вышел из строя, тогда балансировщику нагрузки придется назначить другой сервер, нарушив функциональность и взаимодействие с пользователем. Аналогичным образом, постоянное назначение одного и того же сервера для сеанса может при определенных обстоятельствах привести к увеличению времени отклика перегруженного сервера.
Более правильное решение — хранить копию файла в репозитории, доступном для всех серверов. Затем, после загрузки файла на сервер на шаге 1, этот сервер загрузит его в репозиторий (или, как вариант, файл может быть загружен в репозиторий напрямую с клиента, минуя сервер); сервер, обрабатывающий шаг 2, загрузит файл из репозитория, обработает его и снова загрузит туда; и, наконец, сервер, обрабатывающий шаг 3, загрузит его из репозитория и сохранит.
В этой статье я опишу это последнее решение, основанное на приложении WordPress, хранящем файлы в Amazon Web Services (AWS) Simple Storage Service (S3) (решение для хранения облачных объектов для хранения и извлечения данных), работающем через AWS SDK.
Примечание 1. Для простой функции, такой как обрезка аватаров, другим решением может быть полный обход сервера и реализация ее непосредственно в облаке с помощью функций Lambda. Но поскольку в этой статье речь пойдет о подключении приложения, работающего на сервере, с AWS S3, мы не рассматриваем это решение.
Примечание 2. Чтобы использовать AWS S3 (или любой другой сервис AWS), нам потребуется учетная запись пользователя. Amazon предлагает здесь бесплатный уровень на 1 год, чего достаточно для экспериментов с их услугами.
Примечание 3. Существуют сторонние плагины для загрузки файлов из WordPress в S3. Одним из таких плагинов является WP Media Offload (облегченная версия доступна здесь), который предоставляет замечательную функцию: он легко передает файлы, загруженные в медиатеку, в корзину S3, что позволяет отделить содержимое сайта (например, все, что находится под /wp-content/uploads) из кода приложения. Разделив содержимое и код, мы можем развернуть наше приложение WordPress с помощью Git (в противном случае мы не сможем, поскольку загружаемый пользователем контент не размещается в репозитории Git) и разместить приложение на нескольких серверах (в противном случае каждый сервер должен будет поддерживать копия всего загруженного пользователем контента.)
Создание ведра
При создании корзины необходимо учитывать имя корзины: имя каждой корзины должно быть глобально уникальным в сети AWS, поэтому, даже если мы хотели бы назвать нашу корзину чем-то простым, например «аватары», это имя уже может быть занято. , тогда мы можем выбрать что-то более характерное, например, «аватары-название-моей-компании».
Нам также нужно будет выбрать регион, в котором базируется корзина (регион — это физическое местоположение, в котором расположен центр обработки данных, с местоположениями по всему миру).
Регион должен быть таким же, где развернуто наше приложение, чтобы доступ к S3 во время выполнения процесса был быстрым. В противном случае пользователю, возможно, придется ждать дополнительные секунды перед загрузкой/загрузкой изображения в/из удаленного места.
Примечание. Имеет смысл использовать S3 в качестве решения для хранения облачных объектов, только если мы также используем сервис Amazon для виртуальных серверов в облаке, EC2, для запуска приложения. Если вместо этого мы полагаемся на какую-либо другую компанию для размещения приложения, такую как Microsoft Azure или DigitalOcean, то нам также следует использовать их службы облачного хранения объектов. В противном случае наш сайт будет страдать от накладных расходов из-за передачи данных между сетями разных компаний.
На скриншотах ниже мы увидим, как создать корзину, куда загружать аватары пользователей для обрезки. Сначала мы переходим к панели инструментов S3 и нажимаем «Создать корзину»:
Затем вводим название корзины (в данном случае «аватарки-разбивальщики») и выбираем регион («ЕС (Франкфурт)»):
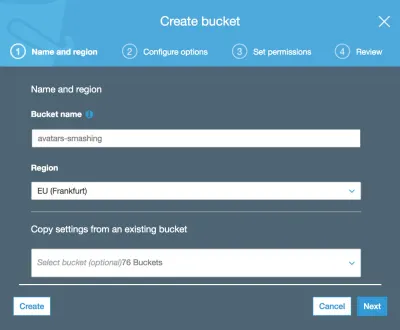
Обязательными являются только имя корзины и регион. Для следующих шагов мы можем сохранить параметры по умолчанию, поэтому мы нажимаем «Далее», пока, наконец, не нажмем «Создать ведро», и при этом у нас будет созданное ведро.
Настройка разрешений пользователя
При подключении к AWS через SDK нам потребуется ввести учетные данные пользователя (пара идентификатора ключа доступа и секретного ключа доступа), чтобы подтвердить, что у нас есть доступ к запрошенным службам и объектам. Разрешения пользователя могут быть очень общими (роль «администратор» может делать все) или очень детализированными, просто предоставляя разрешение на определенные необходимые операции и ничего больше.
Как правило, чем конкретнее наши предоставленные разрешения, тем лучше, чтобы избежать проблем с безопасностью . При создании нового пользователя нам нужно будет создать политику, которая представляет собой простой документ JSON, в котором перечислены разрешения, которые должны быть предоставлены пользователю. В нашем случае наши пользовательские разрешения будут предоставлять доступ к S3, для ведра «аватарки-разбивания», для операций «Положить» (для загрузки объекта), «Получить» (для загрузки объекта) и «Список» ( для перечисления всех объектов в корзине), что приводит к следующей политике:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::avatars-smashing", "arn:aws:s3:::avatars-smashing/*" ] } ] }На скриншотах ниже мы видим, как добавить права пользователя. Мы должны перейти на панель управления идентификацией и доступом (IAM):
На панели инструментов мы нажимаем «Пользователи» и сразу после этого «Добавить пользователя». На странице «Добавить пользователя» мы выбираем имя пользователя («кроп-аватары») и отмечаем «Программный доступ» в качестве типа доступа, который предоставит идентификатор ключа доступа и секретный ключ доступа для подключения через SDK:
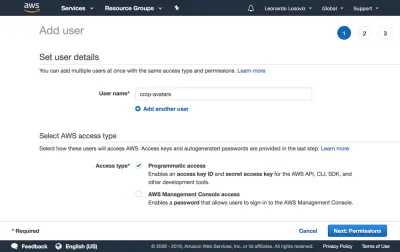
Затем мы нажимаем кнопку «Далее: Разрешения», нажимаем «Прикрепить существующие политики напрямую» и нажимаем «Создать политику». Откроется новая вкладка в браузере со страницей «Создать политику». Мы нажимаем на вкладку JSON и вводим код JSON для политики, определенной выше:
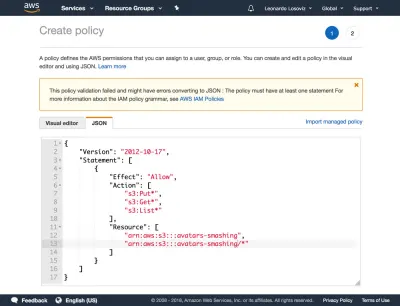
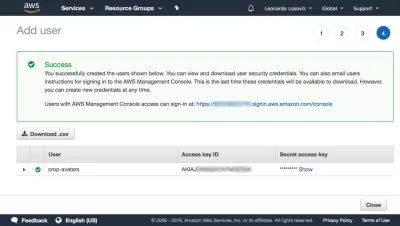
Затем мы нажимаем «Обзор политики», даем ей имя («CropAvatars») и, наконец, нажимаем «Создать политику». Создав политику, мы переключаемся обратно на предыдущую вкладку, выбираем политику CropAvatars (нам может потребоваться обновить список политик, чтобы увидеть ее), нажимаем «Далее: обзор» и, наконец, «Создать пользователя». После того, как это будет сделано, мы можем, наконец, загрузить идентификатор ключа доступа и секретный ключ доступа (обратите внимание, что эти учетные данные доступны для этого уникального момента; если мы не скопируем или не загрузим их сейчас, нам придется создать новую пару ):

Подключение к AWS через SDK
SDK доступен на множестве языков. Для приложения WordPress нам требуется SDK для PHP, который можно скачать здесь, а инструкции по его установке — здесь.
Как только мы создадим корзину, подготовим учетные данные пользователя и установим SDK, мы можем начать загрузку файлов в S3.
Загрузка и скачивание файлов
Для удобства мы определяем учетные данные пользователя и регион как константы в файле wp-config.php:
define ('AWS_ACCESS_KEY_ID', '...'); // Your access key id define ('AWS_SECRET_ACCESS_KEY', '...'); // Your secret access key define ('AWS_REGION', 'eu-central-1'); // Region where the bucket is located. This is the region id for "EU (Frankfurt)" В нашем случае мы реализуем функционал обрезки аватаров, для чего аватары будут храниться в ведре «аватарки-крушители». Однако в нашем приложении у нас может быть несколько других сегментов для других функций, требующих выполнения тех же операций загрузки, скачивания и вывода файлов. Следовательно, мы реализуем общие методы в абстрактном классе AWS_S3 и получаем входные данные, такие как имя корзины, определенное с помощью функции get_bucket , в реализующих дочерних классах.
// Load the SDK and import the AWS objects require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\Exception\AwsException; // Definition of an abstract class abstract class AWS_S3 { protected function get_bucket() { // The bucket name will be implemented by the child class return ''; } } Класс S3Client предоставляет API для взаимодействия с S3. Мы создаем его экземпляр только при необходимости (через ленивую инициализацию) и сохраняем ссылку на него в $this->s3Client , чтобы продолжать использовать тот же экземпляр:
abstract class AWS_S3 { // Continued from above... protected $s3Client; protected function get_s3_client() { // Lazy initialization if (!$this->s3Client) { // Create an S3Client. Provide the credentials and region as defined through constants in wp-config.php $this->s3Client = new S3Client([ 'version' => '2006-03-01', 'region' => AWS_REGION, 'credentials' => [ 'key' => AWS_ACCESS_KEY_ID, 'secret' => AWS_SECRET_ACCESS_KEY, ], ]); } return $this->s3Client; } } Когда мы имеем дело с $file в нашем приложении, эта переменная содержит абсолютный путь к файлу на диске (например, /var/app/current/wp-content/uploads/users/654/leo.jpg ), но при загрузке файл на S3, мы не должны хранить объект по тому же пути. В частности, мы должны удалить начальный бит, относящийся к системной информации ( /var/app/current ) из соображений безопасности, и, при желании, мы можем удалить бит /wp-content (поскольку все файлы хранятся в этой папке, это избыточная информация). ), сохраняя только относительный путь к файлу ( /uploads/users/654/leo.jpg ). Для удобства этого можно добиться, удалив все после WP_CONTENT_DIR из абсолютного пути. Функции get_file и get_file_relative_path ниже переключаются между абсолютным и относительным путями к файлам:
abstract class AWS_S3 { // Continued from above... function get_file_relative_path($file) { return substr($file, strlen(WP_CONTENT_DIR)); } function get_file($file_relative_path) { return WP_CONTENT_DIR.$file_relative_path; } }При загрузке объекта в S3 мы можем установить, кому предоставлен доступ к объекту, и тип доступа, сделанный с помощью разрешений списка управления доступом (ACL). Наиболее распространенные варианты — оставить файл закрытым (ACL => «частный») и сделать его доступным для чтения в Интернете (ACL => «общедоступное чтение»). Поскольку нам нужно будет запросить файл напрямую из S3, чтобы показать его пользователю, нам нужен ACL => «public-read»:
abstract class AWS_S3 { // Continued from above... protected function get_acl() { return 'public-read'; } }Наконец, мы реализуем методы для загрузки объекта и загрузки объекта из корзины S3:
abstract class AWS_S3 { // Continued from above... function upload($file) { $s3Client = $this->get_s3_client(); // Upload a file object to S3 $s3Client->putObject([ 'ACL' => $this->get_acl(), 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SourceFile' => $file, ]); } function download($file) { $s3Client = $this->get_s3_client(); // Download a file object from S3 $s3Client->getObject([ 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SaveAs' => $file, ]); } }Затем в реализующем дочернем классе мы определяем имя корзины:
class AvatarCropper_AWS_S3 extends AWS_S3 { protected function get_bucket() { return 'avatars-smashing'; } } Наконец, мы просто создаем экземпляр класса для загрузки аватаров на S3 или загрузки с него. Кроме того, при переходе с шагов 1 на 2 и со 2 на 3 нам необходимо сообщить значение $file . Мы можем сделать это, отправив поле «file_relative_path» со значением относительного пути $file через операцию POST (мы не передаем абсолютный путь из соображений безопасности: нет необходимости включать «/var/www/current ” информация для просмотра посторонними):
// Step 1: after the file was uploaded to the server, upload it to S3. Here, $file is known $avatarcropper = new AvatarCropper_AWS_S3(); $avatarcropper->upload($file); // Get the file path, and send it to the next step in the POST $file_relative_path = $avatarcropper->get_file_relative_path($file); // ... // -------------------------------------------------- // Step 2: get the $file from the request and download it, manipulate it, and upload it again $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_POST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Do manipulation of the file // ... // Upload the file again to S3 $avatarcropper->upload($file); // -------------------------------------------------- // Step 3: get the $file from the request and download it, and then save it $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_REQUEST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Save it, whatever that means // ...Отображение файла непосредственно из S3
Если мы хотим отобразить промежуточное состояние файла после обработки на шаге 2 (например, аватар пользователя после обрезки), то мы должны ссылаться на файл непосредственно из S3; URL-адрес не может указывать на файл на сервере, поскольку, опять же, мы не знаем, какой сервер будет обрабатывать этот запрос.
Ниже мы добавляем функцию get_file_url($file) , которая получает URL-адрес этого файла в S3. При использовании этой функции убедитесь, что ACL загруженных файлов является общедоступным, иначе он не будет доступен пользователю.
abstract class AWS_S3 { // Continue from above... protected function get_bucket_url() { $region = $this->get_region(); // North Virginia region is simply "s3", the others require the region explicitly $prefix = $region == 'us-east-1' ? 's3' : 's3-'.$region; // Use the same scheme as the current request $scheme = is_ssl() ? 'https' : 'http'; // Using the bucket name in path scheme return $scheme.'://'.$prefix.'.amazonaws.com/'.$this->get_bucket(); } function get_file_url($file) { return $this->get_bucket_url().$this->get_file_relative_path($file); } }Затем мы можем просто получить URL-адрес файла на S3 и распечатать изображение:
printf( "<img src='%s'>", $avatarcropper->get_file_url($file) );Список файлов
Если в нашем приложении мы хотим разрешить пользователю просматривать все ранее загруженные аватары, мы можем это сделать. Для этого мы вводим функцию get_file_urls , которая выводит URL-адреса всех файлов, хранящихся по определенному пути (в терминах S3 это называется префиксом):
abstract class AWS_S3 { // Continue from above... function get_file_urls($prefix) { $s3Client = $this->get_s3_client(); $result = $s3Client->listObjects(array( 'Bucket' => $this->get_bucket(), 'Prefix' => $prefix )); $file_urls = array(); if(isset($result['Contents']) && count($result['Contents']) > 0 ) { foreach ($result['Contents'] as $obj) { // Check that Key is a full file path and not just a "directory" if ($obj['Key'] != $prefix) { $file_urls[] = $this->get_bucket_url().$obj['Key']; } } } return $file_urls; } }Затем, если мы храним каждый аватар по пути «/users/${user_id}/», передав этот префикс, мы получим список всех файлов:
$user_id = get_current_user_id(); $prefix = "/users/${user_id}/"; foreach ($avatarcropper->get_file_urls($prefix) as $file_url) { printf( "<img src='%s'>", $file_url ); }Заключение
В этой статье мы рассмотрели, как использовать облачное хранилище объектов в качестве общего репозитория для хранения файлов приложения, развернутого на нескольких серверах. Для решения мы сосредоточились на AWS S3 и продолжили показывать шаги, необходимые для интеграции в приложение: создание корзины, настройка разрешений пользователя, а также загрузка и установка SDK. Наконец, мы объяснили, как избежать подводных камней безопасности в приложении, и увидели примеры кода, демонстрирующие, как выполнять самые основные операции на S3: загрузку, загрузку и просмотр файлов, для каждой из которых требуется всего несколько строк кода. Простота решения показывает, что интегрировать облачные сервисы в приложение несложно, и это также может быть выполнено разработчиками, не имеющими большого опыта работы с облаком.