
Инструменты количественных данных для UX-дизайнеров
Опубликовано: 2022-03-10Многие UX-дизайнеры несколько боятся данных, считая, что они требуют глубоких знаний статистики и математики. Хотя это может быть верно для продвинутой науки о данных, это не верно для базового анализа данных исследования, необходимого большинству UX-дизайнеров. Поскольку мы живем в мире, который все больше зависит от данных, базовая грамотность в данных полезна практически для любого профессионала, а не только для дизайнеров UX.
Аарон Гитлин, дизайнер взаимодействия в Google, утверждает, что многие дизайнеры еще не ориентируются на данные:
«В то время как многие компании позиционируют себя как управляемые данными, большинство дизайнеров руководствуются интуицией, сотрудничеством и методами качественного исследования».
— Аарон Гитлин, «Стать дизайнером, осведомлённым о данных»
В этой статье я хотел бы дать UX-дизайнерам знания и инструменты для включения данных в свою повседневную жизнь.
Но сначала несколько концепций данных
В этой статье я расскажу о структурированных данных, то есть о данных, которые можно представить в виде таблицы со строками и столбцами. Неструктурированные данные, будучи предметом сами по себе, труднее анализировать, как указал Девин Пикелл (специалист по контент-маркетингу в G2 Crowd, пишущий о данных и аналитике) в своей статье «Структурированные и неструктурированные данные — в чем разница?». Если структурированные данные могут быть представлены в виде таблицы, основными понятиями являются:
Набор данных
Весь набор данных мы намерены проанализировать. Это может быть, например, таблица Excel. Другим популярным форматом хранения наборов данных является файл значений с разделителями-запятыми (CSV). Файлы CSV — это простые текстовые файлы, используемые для хранения табличной информации. Каждая строка CSV соответствует строке в таблице, и каждая строка CSV имеет значения, разделенные (естественно) запятыми, которые соответствуют ячейкам таблицы.
Точка данных
Одна строка из таблицы набора данных является точкой данных. Таким образом, набор данных представляет собой набор точек данных.
Переменная данных
Одно значение из строки точки данных представляет собой переменную данных — проще говоря, ячейку таблицы. У нас может быть два типа переменных данных: качественные переменные и количественные переменные. Качественные переменные (также известные как категориальные переменные) имеют дискретный набор значений, например color = red/green/blue . Количественные переменные имеют числовые значения, такие как height = 167 . Количественная переменная, в отличие от качественной, может принимать любые значения.
Создание нашего проекта данных
Теперь, когда мы знаем основы, пришло время запачкать руки и создать наш первый проект данных. Объем проекта заключается в анализе набора данных путем прохождения всего потока данных импорта, обработки и построения графиков данных. Сначала мы выберем наш набор данных, затем загрузим и установим инструменты для анализа данных.
Набор данных автомобилей
Для целей этой статьи я выбрал набор данных cars, потому что он прост и интуитивно понятен. Анализ данных просто подтвердит то, что мы уже знаем об автомобилях — и это нормально, поскольку мы сосредоточены на потоке данных и инструментах.
Мы можем загрузить набор данных о подержанных автомобилях с Kaggle, одного из крупнейших источников бесплатных наборов данных. Сначала вам нужно будет зарегистрироваться.
После загрузки файла откройте его и посмотрите. Это действительно большой CSV-файл, но вы должны уловить суть. Строка в этом файле будет выглядеть так:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3Как видите, эта точка данных имеет несколько переменных, разделенных запятыми. Поскольку теперь у нас есть набор данных, давайте немного поговорим об инструментах.
Инструменты торговли
Мы будем использовать язык R и RStudio для анализа набора данных. R — очень популярный и простой в изучении язык, которым пользуются не только специалисты по данным, но и люди, работающие на финансовых рынках, в медицине и многих других областях. RStudio — это среда, в которой разрабатываются проекты R, и есть бесплатная версия, которой более чем достаточно для наших нужд как дизайнеров UX.
Вполне вероятно, что некоторые UX-дизайнеры используют Excel для работы с данными. Если это относится к вам, попробуйте R — велика вероятность, что он вам понравится, поскольку его легко освоить, он более гибкий и мощный, чем Excel. Добавление R в ваш набор инструментов изменит ситуацию.
Установка инструментов
Во-первых, нам нужно скачать и установить R и RStudio. Сначала вы должны установить R, а затем RStudio. Процессы установки R и RStudio просты и понятны.
Настройка проекта
После завершения установки создайте папку проекта — я назвал ее used-cars-prj . В этой папке создайте подпапку с именем data , а затем скопируйте файл набора данных (скачанный с Kaggle) в эту папку и переименуйте его в used-cars.csv . Теперь вернитесь в папку нашего проекта ( used-cars-prj ) и создайте обычный текстовый файл с именем used-cars.r . У вас должна получиться такая же структура, как на скриншоте ниже.
Теперь у нас есть структура папок, мы можем открыть RStudio и создать новый проект R. Выберите «Новый проект…» в меню « Файл» и выберите второй вариант « Существующий каталог ». Затем выберите каталог проекта ( used-cars-prj ). Наконец, нажмите кнопку « Создать проект» , и все готово. Как только проект будет создан, откройте файл used-cars.r в RStudio — это файл, в который мы добавим весь наш код R.
Импорт данных
Мы добавим нашу первую строку в файл used-cars.r для чтения данных из файла used-cars.csv . Помните, что файлы CSV — это обычные текстовые файлы, используемые для хранения данных. Наша первая строка кода R будет выглядеть так:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Это может выглядеть немного пугающе, но на самом деле это не так — кстати, это самая сложная строчка во всей статье. Здесь у нас есть функция read.csv , которая принимает три параметра.
Первый параметр — это файл для чтения, в нашем случае used-cars.csv , который находится в папке данных . Второй параметр, stringsAsFactors=FALSE , задается для того, чтобы такие строки, как «BMW» или «Audi», не преобразовывались в факторы (жаргон R для категориальных данных) — как вы помните, качественные или категориальные переменные могут иметь только дискретные значения, такие как red/green/blue . Наконец, третий параметр, sep="," определяет вид разделителя, используемого для разделения значений в CSV-файле: запятая.
После чтения CSV-файла данные сохраняются в объекте фрейма данных cars . Фрейм данных — это двумерная структура данных (например, таблица Excel), которая очень полезна в R для управления данными. После введения линии и ее запуска для вас будет создан фрейм данных cars . Если вы посмотрите в верхний правый квадрант в RStudio, вы увидите фрейм данных cars в разделе Data на вкладке Environment . Если вы дважды щелкните на cars , в верхнем левом квадранте RStudio откроется новая вкладка, в которой будет представлен фрейм данных cars . Как и следовало ожидать, это похоже на таблицу Excel.
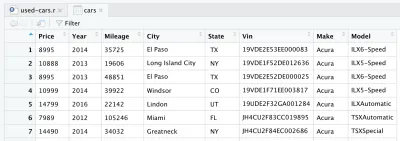
На самом деле это необработанные данные, которые мы скачали с Kaggle. Но поскольку мы хотим выполнить анализ данных, нам нужно сначала обработать наш набор данных.
Обработка данных
Под обработкой мы подразумеваем удаление, преобразование или добавление информации в наш набор данных, чтобы подготовиться к анализу, который мы хотим выполнить. У нас есть данные в объекте фрейма данных, поэтому теперь нам нужно установить библиотеку dplyr , мощную библиотеку для управления данными. Чтобы установить библиотеку в нашей среде R, нам нужно написать следующую строку в верхней части нашего файла R.
install.packages("dplyr")Затем, чтобы добавить библиотеку в наш текущий проект, мы будем использовать следующую строку:
library(dplyr) Как только библиотека dplyr добавлена в наш проект, мы можем начать обработку данных. У нас действительно большой набор данных, и нам нужны только данные, представляющие одного и того же производителя и модель автомобиля, чтобы сопоставить их с ценой. Мы будем использовать следующий код R, чтобы сохранить только данные, касающиеся BMW 3 серии, и удалить остальные. Конечно, вы можете выбрать любого другого производителя и модель из набора данных и ожидать, что у вас будут такие же характеристики данных.
cars <- cars %>% filter(Make == "BMW", Model == "3")Теперь у нас есть более управляемый набор данных, хотя он по-прежнему содержит более 11 000 точек данных, что соответствует нашей намеченной цели: анализировать распределение цен, возраста и пробега автомобилей, а также корреляции между ними. Для этого нам нужно оставить только столбцы «Цена», «Год» и «Пробег», а остальные удалить — это делается следующей строкой.
cars <- cars %>% select(Price, Year, Mileage)После удаления других столбцов наш фрейм данных будет выглядеть так:

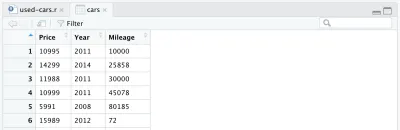
Есть еще одно изменение, которое мы хотим внести в наш набор данных: заменить год выпуска на возраст автомобиля. Мы можем добавить следующие две строки: первая для вычисления возраста, вторая для изменения имени столбца.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Наконец, наш полностью обработанный фрейм данных выглядит так:
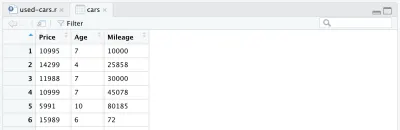
На этом этапе наш код R будет выглядеть следующим образом, и это все, что касается обработки данных. Теперь мы видим, насколько простым и мощным является язык R. Мы обработали первоначальный набор данных довольно резко, написав всего несколько строк кода.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Анализ данных
Наши данные теперь в правильной форме, поэтому мы можем перейти к построению графиков. Как уже упоминалось, мы сосредоточимся на двух аспектах: распределении отдельных переменных и корреляциях между ними. Переменное распределение помогает нам понять, что считается средней или высокой ценой на подержанный автомобиль — или процент автомобилей выше определенной цены. То же самое относится к возрасту и пробегу автомобилей. Корреляции, с другой стороны, помогают понять, как такие переменные, как возраст и пробег, связаны друг с другом.
При этом мы будем использовать два вида визуализации данных: гистограммы для распределения переменных и диаграммы рассеяния для корреляций.
Распределение цен
Построить гистограмму цен на автомобили на языке R очень просто:
hist(cars$Price)Небольшой совет: если вы находитесь в RStudio, вы можете запускать код построчно; например, в нашем случае вам нужно запустить только строку выше, чтобы отобразить гистограмму. Нет необходимости запускать весь код снова, так как вы уже запускали его один раз. Гистограмма должна выглядеть так:
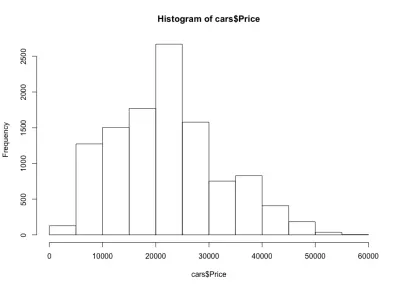
Если мы посмотрим на гистограмму, мы заметим колоколообразное распределение цен на автомобили, чего мы и ожидали. Большинство автомобилей попадают в средний диапазон, и по мере движения в каждую сторону их становится все меньше и меньше. Почти 80% автомобилей стоят от 10 000 до 30 000 долларов США, и у нас есть максимум более 2500 автомобилей от 20 000 до 25 000 долларов США. С левой стороны у нас, вероятно, около 150 автомобилей стоимостью менее 5000 долларов США, а с правой стороны еще меньше. Мы можем легко увидеть, насколько полезны такие графики для понимания данных.
Распределение по возрасту
Как и в случае с ценами на автомобили, мы будем использовать аналогичную линию для построения гистограммы возраста автомобилей.
hist(cars$Age)А вот и гистограмма:
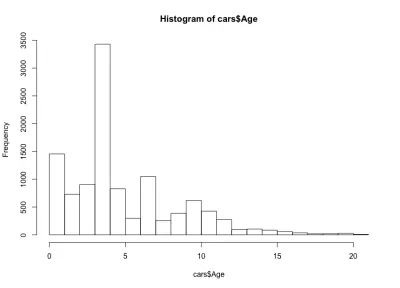
На этот раз гистограмма выглядит нелогично — вместо простого колокольчика здесь четыре колокола. В основном распределение имеет три локальных и один глобальный максимум, что неожиданно. Было бы интересно посмотреть, останется ли это странное распределение возраста автомобилей верным для другого производителя и модели автомобиля. Для целей этой статьи мы остановимся на наборе данных BMW 3 серии, но вы можете углубиться в данные, если вам интересно. Что касается нашего распределения по возрасту автомобилей, мы замечаем, что более 90% автомобилей моложе 10 лет, а более 80% — менее 7 лет. Также мы замечаем, что большинству автомобилей меньше 5 лет.
Распределение пробега
Теперь, что мы можем сказать о пробеге? Конечно, мы ожидаем получить ту же форму колокола, что и по цене. Вот код R и гистограмма:
hist(cars$Mileage) 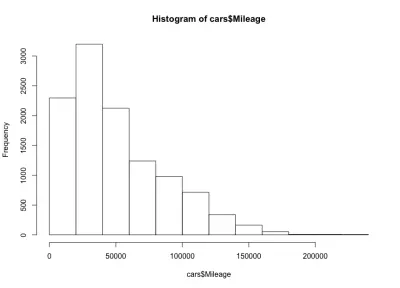
Здесь у нас форма колокола, скошенная влево, что означает, что на рынке больше автомобилей с меньшим пробегом. Мы также замечаем, что пробег большинства автомобилей составляет менее 60 000 миль, а у нас максимальный пробег составляет от 20 000 до 40 000 миль.
Корреляция возраста и цены
Что касается корреляции, давайте подробнее рассмотрим корреляцию цены и возраста автомобилей. Можно ожидать, что цена будет иметь отрицательную корреляцию с возрастом — по мере увеличения возраста автомобиля его цена будет снижаться. Мы будем использовать функцию plot R, чтобы отобразить корреляцию цена-возраст следующим образом:
plot(cars$Age, cars$Price)А сюжет выглядит так:
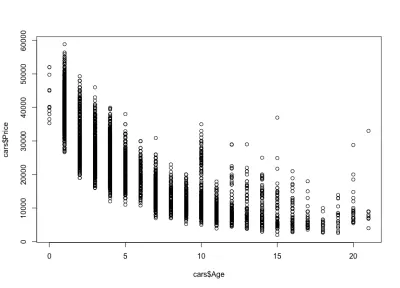
Мы замечаем, как с возрастом цены на автомобили снижаются: есть дорогие новые автомобили и более дешевые старые автомобили. Мы также можем увидеть интервал изменения цены для любого конкретного возраста, который уменьшается с возрастом автомобиля. Это изменение в значительной степени определяется пробегом, конфигурацией и общим состоянием автомобиля. Например, в случае 4-летнего автомобиля цена варьируется от 10 000 до 40 000 долларов США.
Корреляция пробега и возраста
Учитывая корреляцию между пробегом и возрастом, мы ожидаем, что пробег будет увеличиваться с возрастом, что означает положительную корреляцию. Вот код:
plot(cars$Mileage, cars$Age)А вот и сюжет:
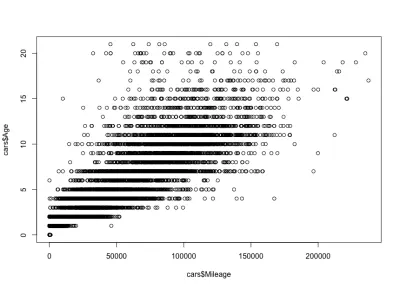
Как видите, возраст автомобиля и пробег положительно коррелированы, в отличие от цены и возраста автомобиля, которые имеют отрицательную корреляцию. У нас также есть ожидаемая вариация пробега для определенного возраста; то есть автомобили одного возраста имеют разный пробег. Например, пробег большинства 4-летних автомобилей составляет от 10 000 до 80 000 миль. Но есть и выбросы с большим пробегом.
Соотношение пробега и цены
Как и ожидалось, между пробегом автомобилей и ценой будет отрицательная корреляция, а это означает, что увеличение пробега снижает цену.
plot(cars$Mileage, cars$Price)А вот и сюжет:
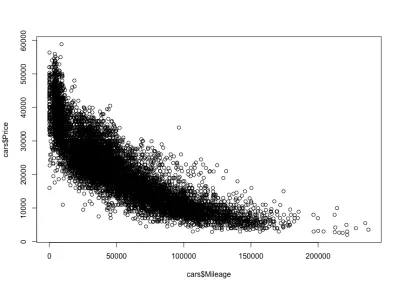
Как мы и ожидали, отрицательная корреляция. Мы также можем заметить диапазон брутто-цены от 3 000 до 50 000 долларов США и пробег от 0 до 150 000. Если мы внимательно посмотрим на форму распределения, то увидим, что цена снижается гораздо быстрее для автомобилей с меньшим пробегом, чем для автомобилей с большим пробегом. Есть машины с почти нулевым пробегом, где цена резко падает. Кроме того, при пробеге более 200 000 миль — из-за очень большого пробега — цена остается неизменной.
От чисел к визуализации данных
В этой статье мы использовали два типа визуализации: гистограммы для распределения данных и диаграммы рассеивания для корреляций данных. Гистограммы — это визуальные представления, которые принимают значения переменной данных (фактические числа ) и показывают, как они распределяются по диапазону. Мы использовали функцию R hist() для построения гистограммы.
Диаграммы рассеяния, с другой стороны, берут пары чисел и представляют их по двум осям. Диаграммы рассеяния используют функцию plot() и предоставляют два параметра: первую и вторую переменные данных корреляции, которую мы хотим исследовать. Таким образом, две функции R, hist() и plot() , помогают нам преобразовывать наборы чисел в осмысленные визуальные представления.
Заключение
Запачкав руки, пройдя через весь поток данных импорта, обработки и построения графиков, теперь все выглядит намного яснее. Вы можете применить один и тот же поток данных к любому блестящему новому набору данных, с которым вы столкнетесь. Например, в исследованиях пользователей вы можете построить график распределения времени по задачам или ошибкам, а также построить график корреляции времени по задачам и ошибкам.
Чтобы узнать больше о языке R, Quick-R — хорошее место для начала, но вы также можете рассмотреть R Bloggers. Для получения документации по пакетам R, таким как dplyr , вы можете посетить RDocumentation. Играть с данными может быть весело, но это также чрезвычайно полезно для любого UX-дизайнера в мире, управляемом данными. По мере того, как все больше данных собирается и используется для обоснования бизнес-решений, у дизайнеров появляется все больше шансов работать над визуализацией данных или продуктами данных, где важно понимание природы данных.