
Создание сервиса Pub/Sub собственными силами с использованием Node.js и Redis
Опубликовано: 2022-03-10Современный мир работает в режиме реального времени. Будь то торговля акциями или заказ еды, потребители сегодня ожидают немедленных результатов. Точно так же мы все ожидаем получать информацию немедленно — будь то новости или спорт. Другими словами, Зеро — это новый герой.
Это относится и к разработчикам программного обеспечения — возможно, одним из самых нетерпеливых людей! Прежде чем погрузиться в историю BrowserStack, с моей стороны было бы упущением не рассказать немного о Pub/Sub. Те из вас, кто знаком с основами, могут пропустить следующие два абзаца.
Сегодня многие приложения полагаются на передачу данных в реальном времени. Давайте рассмотрим пример: социальные сети. Подобные Facebook и Twitter генерируют релевантные каналы , а вы (через их приложение) просматриваете их и шпионите за своими друзьями. Они достигают этого с помощью функции обмена сообщениями, в которой, если пользователь генерирует данные, они будут опубликованы для других для использования в мгновение ока. Любые значительные задержки и пользователи будут жаловаться, использование упадет, а если оно сохранится, произойдет массовое производство. Ставки высоки, как и ожидания пользователей. Так как же такие сервисы, как WhatsApp, Facebook, TD Ameritrade, Wall Street Journal и GrubHub, поддерживают передачу больших объемов данных в режиме реального времени?
Все они используют схожую программную архитектуру на высоком уровне, называемую моделью «публикация-подписка», обычно называемую Pub/Sub.
«В архитектуре программного обеспечения публикация-подписка — это шаблон обмена сообщениями, в котором отправители сообщений, называемые издателями, не программируют сообщения для отправки напрямую конкретным получателям, называемым подписчиками, а вместо этого классифицируют опубликованные сообщения по классам, не зная, какие подписчики, если любой, может быть. Точно так же подписчики проявляют интерес к одному или нескольким классам и получают только те сообщения, которые представляют интерес, не зная, какие издатели существуют, если таковые имеются».
— Википедия
Скучно по определению? Вернемся к нашей истории.
В BrowserStack все наши продукты поддерживают (так или иначе) программное обеспечение с существенным компонентом зависимости в реальном времени — будь то журналы автоматизированных тестов, свежеиспеченные снимки экрана браузера или мобильная потоковая передача со скоростью 15 кадров в секунду.
В таких случаях, если одно сообщение теряется, клиент может потерять информацию, необходимую для предотвращения ошибки . Поэтому нам нужно было масштабироваться для различных требований к размеру данных. Например, при использовании служб регистрации устройств в определенный момент времени в одном сообщении может быть создано 50 МБ данных. Такие размеры могут привести к сбою браузера. Не говоря уже о том, что в будущем системе BrowserStack потребуется масштабирование для дополнительных продуктов.
Поскольку размер данных для каждого сообщения варьируется от нескольких байтов до 100 МБ, нам требовалось масштабируемое решение, которое могло бы поддерживать множество сценариев. Другими словами, мы искали меч, который мог бы разрезать все торты. В этой статье я расскажу о том, почему, как и о результатах создания нашего сервиса Pub/Sub собственными силами.
Через призму реальной проблемы BrowserStack вы получите более глубокое понимание требований и процесса создания собственного Pub/Sub .
Наша потребность в сервисе Pub/Sub
BrowserStack содержит около 100 миллионов сообщений, каждое из которых имеет размер примерно от 2 байт до 100+ МБ. Они передаются по всему миру в любой момент, все с разной скоростью Интернета.
Наши продукты BrowserStack Automate являются крупнейшими генераторами этих сообщений по размеру сообщений. Оба имеют информационные панели в реальном времени, отображающие все запросы и ответы для каждой команды пользовательского теста. Итак, если кто-то запускает тест со 100 запросами, где средний размер запроса-ответа составляет 10 байт, это передает 1 × 100 × 10 = 1000 байт.
Теперь давайте рассмотрим общую картину, поскольку, конечно же, мы не проводим только один тест в день. Ежедневно с помощью BrowserStack выполняется более 850 000 тестов BrowserStack Automate и App Automate. И да, в среднем мы получаем около 235 запросов-ответов за тест. Поскольку пользователи могут делать скриншоты или запрашивать исходники страниц в Selenium, наш средний размер запроса-ответа составляет примерно 220 байт.
Итак, вернемся к нашему калькулятору:
850 000×235×220 = 43 945 000 000 байт (приблизительно) или всего 43,945 ГБ в день
Теперь поговорим о BrowserStack Live и App Live. Конечно, у нас есть Automate как наш победитель в форме размера данных. Тем не менее, продукты Live лидируют по количеству переданных сообщений. Для каждого живого теста каждую минуту передается около 20 сообщений. Мы проводим около 100 000 живых тестов, каждый из которых в среднем занимает около 12 минут, что означает:
100 000×12×20 = 24 000 000 сообщений в день
Теперь самое замечательное: мы создаем, запускаем и поддерживаем приложение для этого под названием pusher с 6 экземплярами t1.micro ec2. Стоимость работы службы? Около 70 долларов в месяц .
Выбор построить против покупки
Перво-наперво: как стартапу, как и большинству других, мы всегда были рады создавать что-то собственными силами. Но мы все же оценили несколько сервисов. Основные требования, которые у нас были:
- Надежность и стабильность,
- Высокая производительность и
- Экономическая эффективность.
Давайте опустим критерии экономической эффективности, так как я не могу вспомнить какие-либо внешние услуги, которые стоят менее 70 долларов в месяц (напишите мне в Твиттере, если знаете такую!). Так что наш ответ там очевиден.
Что касается надежности и стабильности, мы нашли компании, которые предоставляли Pub/Sub как услугу с SLA 99,9+% безотказной работы, но к ним прилагалось много условий. Проблема не так проста, как вы думаете, особенно если учесть огромные просторы открытого Интернета, лежащие между системой и клиентом. Любой, кто знаком с инфраструктурой Интернета, знает, что стабильное соединение является самой большой проблемой. Кроме того, объем отправляемых данных зависит от трафика. Например, конвейер данных, который в течение одной минуты находится на нуле, может разорваться в течение следующей. Сервисы, обеспечивающие достаточную надежность в такие пиковые моменты, встречаются редко (Google и Amazon).
Производительность для нашего проекта означает получение и отправку данных на все прослушивающие узлы почти с нулевой задержкой . В BrowserStack мы используем облачные сервисы (AWS) вместе с совместным хостингом. Однако наши издатели и/или подписчики могут быть размещены где угодно. Например, это может включать сервер приложений AWS, генерирующий столь необходимые данные журнала, или терминалы (машины, к которым пользователи могут безопасно подключаться для тестирования). Возвращаясь снова к открытой проблеме Интернета, если бы мы хотели снизить риск, мы должны были бы убедиться, что наша Pub/Sub использовала лучшие хост-сервисы и AWS.
Еще одним важным требованием была возможность передачи всех типов данных (байты, текст, странные медиаданные и т. д.). Учитывая все вышесказанное, не имело смысла полагаться на стороннее решение для поддержки наших продуктов. В свою очередь, мы решили возродить дух стартапа, засучив рукава, чтобы написать собственное решение.

Создание нашего решения
Pub/Sub по замыслу означает, что будет издатель, генерирующий и отправляющий данные, и подписчик, принимающий и обрабатывающий их. Это похоже на радио: радиоканал транслирует (публикует) контент везде в пределах диапазона. Как подписчик, вы можете решить, настроиться ли на этот канал и слушать (или вообще выключить радио).
В отличие от аналогии с радио, где данные бесплатны для всех и каждый может решить настроиться, в нашем цифровом сценарии нам нужна аутентификация, что означает, что данные, сгенерированные издателем, могут быть только для одного конкретного клиента или подписчика.
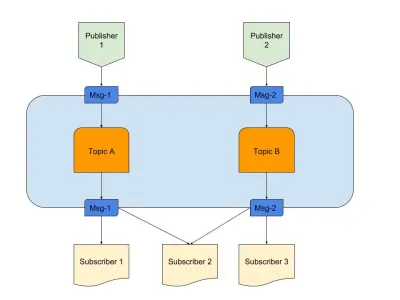
Выше приведена диаграмма, представляющая пример хорошего Pub/Sub с:
- Издатели
Здесь у нас есть два издателя, генерирующие сообщения на основе заранее определенной логики. В нашей радио-аналогии это наши радио-жокеи, создающие контент. - Темы
Здесь их два, что означает наличие двух типов данных. Можно сказать, что это наши радиоканалы 1 и 2. - Подписчики
У нас есть три, каждая из которых считывает данные по определенной теме. Следует отметить, что подписчик 2 читает из нескольких тем. В нашей аналогии с радио это люди, которые настроены на радиоканал.
Начнем разбираться с необходимыми требованиями к сервису.
- Событийный компонент
Это срабатывает только тогда, когда есть что-то, что можно сбить. - Временное хранилище
Это сохраняет данные в течение короткого промежутка времени, поэтому, если подписчик работает медленно, у него все еще есть окно для их использования. - Уменьшение задержки
Соединение двух объектов по сети с минимальными переходами и расстоянием.
Мы выбрали стек технологий, отвечающий вышеуказанным требованиям:
- Node.js
Почему бы и нет? В случае событий нам не понадобилась бы тяжелая обработка данных, к тому же ее легко внедрить. - Редис
Отлично поддерживает кратковременные данные. Он имеет все возможности для запуска, обновления и автоматического истечения срока действия. Это также снижает нагрузку на приложение.
Node.js для подключения к бизнес-логике
Node.js — почти идеальный язык, когда дело доходит до написания кода, включающего ввод-вывод и события. В нашей конкретной заданной проблеме было и то, и другое, что делало этот вариант наиболее практичным для наших нужд.
Конечно, другие языки, такие как Java, могли бы быть более оптимизированными, или такой язык, как Python, предлагает масштабируемость. Однако стоимость начала работы с этими языками настолько высока, что разработчик может закончить писать код на Node за то же время.
Честно говоря, если бы у сервиса была возможность добавить более сложные функции, мы могли бы посмотреть на другие языки или готовый стек. Но вот это брак, заключенный на небесах. Вот наш package.json :
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }Проще говоря, мы верим в минимализм, особенно когда дело касается написания кода. С другой стороны, мы могли бы использовать такие библиотеки, как Express, для написания расширяемого кода для этого проекта. Однако наши инстинкты стартапа решили пропустить это и сохранить для следующего проекта. Дополнительные инструменты, которые мы использовали:
- иоредис
Это одна из наиболее поддерживаемых библиотек для подключения Redis к Node.js, используемая такими компаниями, как Alibaba. - socket.io
Лучшая библиотека для удобного подключения и отката с помощью WebSocket и HTTP.
Redis для временного хранилища
Redis как масштабируемый сервис очень надежен и легко настраивается. Кроме того, для Redis существует множество надежных поставщиков управляемых услуг, включая AWS. Даже если вы не хотите использовать провайдера, с Redis легко начать работу.
Разберем настраиваемую часть. Мы начали с обычной конфигурации master-slave, но Redis также поставляется с режимами кластера или дозорного. Каждый режим имеет свои преимущества.
Если бы мы могли каким-то образом обмениваться данными, кластер Redis был бы лучшим выбором. Но если бы мы делились данными с помощью какой-либо эвристики, у нас было бы меньше гибкости, поскольку эвристика должна следовать через . Меньше правил, больше контроля — это хорошо для жизни!
Redis Sentinel лучше всего подходит для нас, поскольку поиск данных выполняется только на одном узле, который подключается в определенный момент времени, а данные не сегментируются. Это также означает, что даже если несколько узлов потеряны, данные по-прежнему распределяются и присутствуют на других узлах. Так у вас больше HA и меньше шансов проиграть. Конечно, это убрало преимущества кластера, но наш вариант использования отличается.
Архитектура на высоте 30000 футов
На приведенной ниже диаграмме показано очень общее представление о том, как работают наши информационные панели Automate и App Automate. Помните систему реального времени, которую мы использовали в предыдущем разделе?
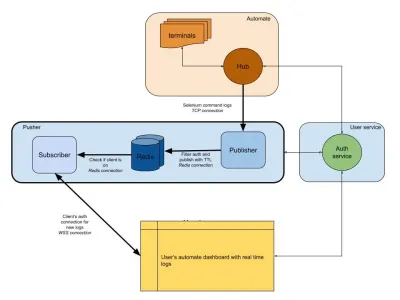
На нашей диаграмме наш основной рабочий процесс выделен более толстыми границами. Раздел «Автоматизация» состоит из:
- Терминалы
Состоит из нетронутых версий Windows, OSX, Android или iOS, которые вы получаете при тестировании на BrowserStack. - Центр
Точка контакта для всех ваших тестов Selenium и Appium с BrowserStack.
Раздел «пользовательская служба» здесь является нашим привратником, гарантируя, что данные отправляются и сохраняются для нужного человека. Это также наш хранитель безопасности. Раздел «толкатель» включает в себя суть того, что мы обсуждали в этой статье. Он состоит из обычных подозреваемых, в том числе:
- Редис
Наше временное хранилище для сообщений, где в нашем случае временно хранятся автоматические журналы. - Издатель
По сути, это объект, который получает данные из концентратора. Все ваши ответы на запросы перехватываются этим компонентом, который пишет в Redis сsession_idв качестве канала. - Подписчик
Это считывает данные из Redis, сгенерированные дляsession_id. Это также веб-сервер для клиентов, которые подключаются через WebSocket (или HTTP) для получения данных, а затем отправляют их аутентифицированным клиентам.
Наконец, у нас есть раздел браузера пользователя, представляющий аутентифицированное соединение WebSocket для обеспечения отправки журналов session_id . Это позволяет внешнему JS анализировать и украшать его для пользователей.
Как и в случае со службой журналов, у нас есть pusher, который используется для других интеграций продуктов. Вместо session_id мы используем другую форму идентификатора для представления этого канала. Это все работает из толкателя!
Заключение (TLDR)
Мы добились значительных успехов в создании Pub/Sub. Подводя итог, почему мы построили его собственными силами:
- Лучше масштабируется для наших нужд;
- Дешевле, чем аутсорсинговые услуги;
- Полный контроль над общей архитектурой.
Не говоря уже о том, что JS идеально подходит для такого сценария. Цикл событий и огромное количество операций ввода-вывода — вот что нужно для решения проблемы! JavaScript — это магия одного псевдопотока.
События и Redis как система упрощают работу разработчиков, поскольку вы можете получать данные из одного источника и передавать их в другой через Redis. Итак, мы построили его.
Если использование подходит для вашей системы, я рекомендую сделать то же самое!