
Поддержание скорости Node.js: инструменты, методы и советы по созданию высокопроизводительных серверов Node.js
Опубликовано: 2022-03-10Если вы достаточно долго создавали что-либо с помощью Node.js, то вы, несомненно, сталкивались с неожиданными проблемами со скоростью. JavaScript — это событийный асинхронный язык. Это может затруднить рассуждения о производительности , как станет очевидным. Растущая популярность Node.js выявила потребность в инструментах, методах и мышлении, соответствующих ограничениям серверного JavaScript.
Когда дело доходит до производительности, то, что работает в браузере, не обязательно подходит для Node.js. Итак, как нам убедиться, что реализация Node.js работает быстро и соответствует цели? Давайте рассмотрим практический пример.
Инструменты
Node — очень универсальная платформа, но одним из основных приложений является создание сетевых процессов. Мы сосредоточимся на профилировании наиболее распространенных из них: веб-серверов HTTP.
Нам понадобится инструмент, который может взорвать сервер большим количеством запросов при измерении производительности. Например, мы можем использовать AutoCannon:
npm install -g autocannonДругие хорошие инструменты для тестирования HTTP включают Apache Bench (ab) и wrk2, но AutoCannon написан на Node, обеспечивает такое же (а иногда и большее) давление нагрузки и очень легко устанавливается в Windows, Linux и Mac OS X.
После того, как мы установили базовое измерение производительности, если мы решим, что наш процесс может быть быстрее, нам понадобится какой-то способ диагностировать проблемы с процессом. Отличным инструментом для диагностики различных проблем с производительностью является Node Clinic, который также можно установить с помощью npm:
npm install -g clinicЭто фактически устанавливает набор инструментов. Мы будем использовать Clinic Doctor и Clinic Flame (оболочку около 0x) по мере продвижения.
Примечание . Для этого практического примера нам понадобится Node 8.11.2 или выше.
Код
В нашем примере это простой сервер REST с одним ресурсом: большая полезная нагрузка JSON, представленная как маршрут GET в /seed/v1 . Сервер представляет собой папку app , состоящую из файла package.json (в зависимости от restify 7.1.0 ), файла index.js и файла util.js.
Файл index.js для нашего сервера выглядит так:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Этот сервер представляет распространенный случай обслуживания кэшированного клиентом динамического содержимого. Это достигается с помощью промежуточного программного обеспечения etagger , которое вычисляет заголовок ETag для последнего состояния содержимого.
Файл util.js содержит элементы реализации, которые обычно используются в таком сценарии, функцию для извлечения соответствующего контента из бэкэнда, промежуточное ПО etag и функцию временной метки, которая предоставляет временные метки поминутно:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }Ни в коем случае не воспринимайте этот код как пример передовой практики! В этом файле есть несколько запахов кода, но мы обнаружим их по мере измерения и профилирования приложения.
Чтобы получить полный исходный код для нашей отправной точки, медленный сервер можно найти здесь.
Профилирование
Для профилирования нам нужны два терминала, один для запуска приложения, а другой для его нагрузочного тестирования.
В одном терминале, в папке app , мы можем запустить:
node index.jsВ другом терминале мы можем профилировать это так:
autocannon -c100 localhost:3000/seed/v1Это откроет 100 одновременных подключений и будет бомбардировать сервер запросами в течение десяти секунд.
Результаты должны быть примерно https://localhost:3000/seed/v1 :
| Стат | Среднее | Стдев | Максимум |
|---|---|---|---|
| Задержка (мс) | 3086,81 | 1725,2 | 5554 |
| Треб/сек | 23.1 | 19.18 | 65 |
| Байт/сек | 237,98 КБ | 197,7 КБ | 688,13 КБ |
Результаты будут различаться в зависимости от машины. Однако, учитывая, что сервер Node.js «Hello World» легко может обрабатывать тридцать тысяч запросов в секунду на той машине, которая выдала эти результаты, 23 запроса в секунду со средней задержкой более 3 секунд — это удручающе.
Диагностика
Обнаружение проблемной области
Мы можем диагностировать приложение с помощью одной команды благодаря команде Clinic Doctor –on-port. В папке app запускаем:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsЭто создаст файл HTML, который автоматически откроется в нашем браузере после завершения профилирования.
Результаты должны выглядеть примерно так:
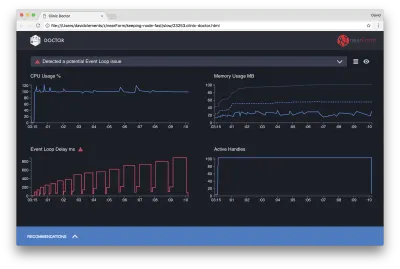
Доктор говорит нам, что, вероятно, у нас возникла проблема с циклом событий.
Наряду с сообщением в верхней части пользовательского интерфейса мы также видим, что диаграмма цикла событий окрашена в красный цвет и показывает постоянно увеличивающуюся задержку. Прежде чем мы углубимся в то, что это означает, давайте сначала разберемся, какое влияние диагностированная проблема оказывает на другие показатели.
Мы видим, что загрузка ЦП постоянно находится на уровне 100% или превышает его, поскольку процесс усердно работает над обработкой запросов, стоящих в очереди. Механизм JavaScript Node (V8) фактически использует в этом случае два ядра ЦП, потому что машина является многоядерной, а V8 использует два потока. Один для цикла событий, а другой для сборки мусора. Когда мы видим, что в некоторых случаях загрузка ЦП достигает 120%, процесс собирает объекты, связанные с обработанными запросами.
Мы видим, что это коррелирует на графике памяти. Сплошная линия на диаграмме «Память» — это показатель «Используемая куча». Каждый раз, когда происходит всплеск загрузки ЦП, мы видим падение строки Heap Used, показывая, что память освобождается.
На активные дескрипторы не влияет задержка цикла событий. Активный дескриптор — это объект, представляющий либо ввод-вывод (например, дескриптор сокета или файла), либо таймер (например, setInterval ). Мы поручили AutoCannon открыть 100 соединений ( -c100 ). Число активных дескрипторов постоянно равно 103. Остальные три — это дескрипторы для STDOUT, STDERR и дескриптор самого сервера.
Если мы щелкнем панель «Рекомендации» в нижней части экрана, мы должны увидеть что-то вроде следующего:
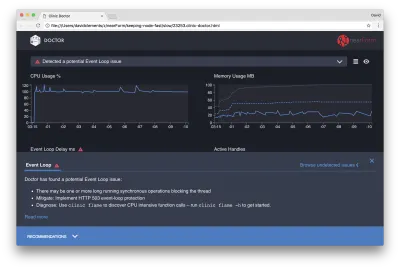
Краткосрочное смягчение
Анализ основных причин серьезных проблем с производительностью может занять некоторое время. В случае проекта, развернутого в реальном времени, стоит добавить защиту от перегрузки серверов или служб. Идея защиты от перегрузки состоит в том, чтобы отслеживать задержку цикла событий (среди прочего) и отвечать сообщением «503 Service Unreachable», если превышено пороговое значение. Это позволяет балансировщику нагрузки переключиться на другие экземпляры или, в худшем случае, означает, что пользователям придется обновляться. Модуль защиты от перегрузки может обеспечить это с минимальными накладными расходами для Express, Koa и Restify. Платформа Hapi имеет параметр конфигурации загрузки, обеспечивающий такую же защиту.
Понимание проблемной области
Как поясняется в кратком объяснении в Clinic Doctor, если цикл событий задерживается до уровня, который мы наблюдаем, очень вероятно, что одна или несколько функций «блокируют» цикл событий.
Для Node.js особенно важно распознавать эту основную характеристику JavaScript: асинхронные события не могут происходить до тех пор, пока текущий исполняемый код не завершится.
Вот почему setTimeout не может быть точным.
Например, попробуйте запустить в браузере DevTools или Node REPL следующее:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() Результирующее измерение времени никогда не будет равно 100 мс. Скорее всего, оно будет в диапазоне от 150 до 250 мс. setTimeout запланировал асинхронную операцию ( console.timeEnd ), но текущий выполняемый код еще не завершен; есть еще две строки. Выполняемый в данный момент код называется текущим «тиком». Чтобы тик завершился, Math.random нужно вызвать десять миллионов раз. Если это займет 100 мс, то общее время до разрешения тайм-аута будет 200 мс (плюс время, которое требуется функции setTimeout , чтобы поставить тайм-аут в очередь заранее, обычно пару миллисекунд).
В контексте на стороне сервера, если операция в текущем такте занимает много времени для завершения, запросы не могут быть обработаны, и выборка данных не может произойти, поскольку асинхронный код не будет выполняться до тех пор, пока не завершится текущий тик. Это означает, что вычислительно затратный код будет замедлять все взаимодействия с сервером. Поэтому рекомендуется разбивать ресурсоемкую работу на отдельные процессы и вызывать их с основного сервера, это позволит избежать случаев, когда на редко используемом, но дорогом маршруте замедляется производительность других часто используемых, но недорогих маршрутов.
На примере сервера есть код, который блокирует цикл обработки событий, поэтому следующим шагом будет поиск этого кода.
Анализ
Один из способов быстро выявить плохо работающий код — создать и проанализировать пламенный граф. Пламенный граф представляет вызовы функций как блоки, расположенные друг над другом — не во времени, а в совокупности. Причина, по которой он называется «диаграммой пламени», заключается в том, что он обычно использует цветовую схему от оранжевого до красного, где чем краснее блок, тем «горячее» функция, а это означает, что тем больше вероятность того, что она будет блокировать цикл событий. Сбор данных для флейм-графа осуществляется путем выборки ЦП — это означает, что делается моментальный снимок функции, которая выполняется в данный момент, и ее стека. Нагрев определяется процентом времени во время профилирования, в течение которого данная функция находится на вершине стека (например, функция, выполняемая в данный момент) для каждой выборки. Если это не последняя функция, которая когда-либо вызывалась в этом стеке, то, вероятно, она блокирует цикл обработки событий.
Давайте воспользуемся clinic flame для создания графа пламени примера приложения:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsРезультат должен открыться в нашем браузере примерно следующим образом:
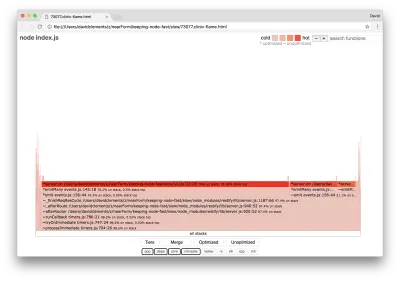
Ширина блока показывает, сколько времени он потратил на ЦП в целом. Можно наблюдать, что три основных стека занимают больше всего времени, и все они выделяют server.on как самую горячую функцию. По правде говоря, все три стека одинаковы. Они расходятся, потому что при профилировании оптимизированные и неоптимизированные функции рассматриваются как отдельные кадры вызовов. Функции с префиксом * оптимизируются движком JavaScript, а функции с префиксом ~ неоптимизированы. Если оптимизированное состояние для нас не важно, мы можем еще больше упростить график, нажав кнопку Merge. Это должно привести к представлению, подобному следующему:
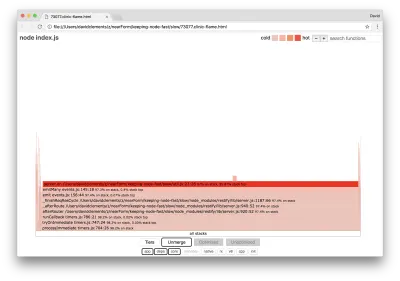
С самого начала мы можем сделать вывод, что код нарушения находится в файле util.js кода приложения.
Медленная функция также является обработчиком событий: функции, предшествующие этой функции, являются частью основного модуля events , а server.on — это резервное имя для анонимной функции, предоставляемой в качестве функции обработки событий. Мы также можем видеть, что этот код не находится в том же тике, что и код, который фактически обрабатывает запрос. Если бы это было так, в стеке были бы функции из основных модулей http , net и stream .
Такие основные функции можно найти, расширив другие, гораздо меньшие части графа пламени. Например, попробуйте использовать ввод поиска в правом верхнем углу пользовательского интерфейса для поиска по запросу send (название внутренних методов restify и http ). Он должен быть справа от графика (функции отсортированы по алфавиту):
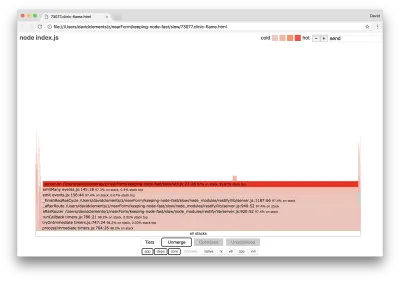
Обратите внимание, насколько малы все фактические блоки обработки HTTP.

Мы можем щелкнуть один из блоков, выделенных голубым, который расширится, чтобы показать такие функции, как writeHead и write в файле http_outgoing.js (часть основной http -библиотеки Node):
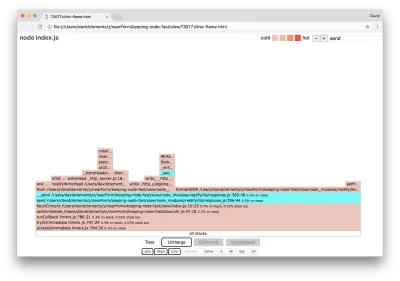
Мы можем щелкнуть все стопки , чтобы вернуться к основному виду.
Ключевым моментом здесь является то, что даже несмотря на то, что функция server.on не находится в том же тике, что и фактический код обработки запросов, она все же влияет на общую производительность сервера, задерживая выполнение в остальном производительного кода.
Отладка
Из флейм-графа мы знаем, что проблемная функция — это обработчик событий, переданный server.on в файле util.js.
Давайте взглянем:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) Хорошо известно, что криптография имеет тенденцию быть дорогой, как и сериализация ( JSON.stringify ), но почему они не отображаются на графике пламени? Эти операции есть в захваченных примерах, но они скрыты фильтром cpp . Если мы нажмем кнопку cpp , мы должны увидеть что-то вроде следующего:
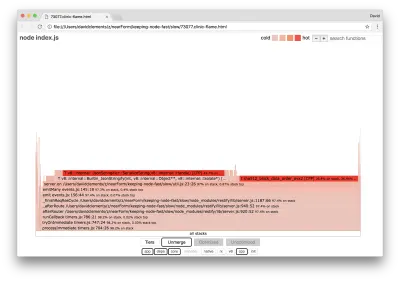
Внутренние инструкции V8, относящиеся как к сериализации, так и к криптографии, теперь отображаются как самые горячие стеки и занимают большую часть времени. Метод JSON.stringify напрямую вызывает код C++; вот почему мы не видим функцию JavaScript. В случае с криптографией такие функции, как createHash и update , находятся в данных, но они либо встроены (что означает, что они исчезают в объединенном представлении), либо слишком малы для отображения.
Как только мы начнем рассуждать о коде функции etagger , сразу станет ясно, что он плохо спроектирован. Почему мы берем экземпляр server из контекста функции? Происходит много хеширования, нужно ли все это? Также в реализации нет поддержки заголовка If-None-Match , что снизит часть нагрузки в некоторых реальных сценариях, поскольку клиенты будут делать только главный запрос для определения свежести.
Давайте на данный момент проигнорируем все эти моменты и подтвердим вывод о том, что фактическая работа, выполняемая в server.on , действительно является узким местом. Этого можно добиться, установив в коде server.on пустую функцию и сгенерировав новый пламенный граф.
Измените функцию etagger на следующее:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } Функция прослушивания событий, переданная server.on , теперь не работает.
Давайте снова запустим clinic flame :
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsЭто должно создать график пламени, подобный следующему:
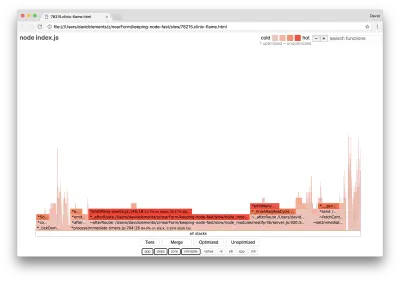
Это выглядит лучше, и мы должны были заметить увеличение количества запросов в секунду. Но почему код, генерирующий событие, такой горячий? Мы ожидаем, что в этот момент код обработки HTTP займет большую часть процессорного времени, в событии server.on вообще ничего не выполняется.
Этот тип узкого места вызван тем, что функция выполняется чаще, чем должна.
Подсказкой может быть следующий подозрительный код в верхней части util.js :
require('events').defaultMaxListeners = Infinity Удалим эту строку и запустим наш процесс с --trace-warnings :
node --trace-warnings index.jsЕсли мы профилируем AutoCannon в другом терминале, например:
autocannon -c100 localhost:3000/seed/v1Наш процесс выведет что-то похожее на:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node сообщает нам, что к объекту сервера прикрепляется множество событий. Это странно, потому что есть логическое значение, которое проверяет, было ли прикреплено событие, а затем возвращает ранний результат, по существу делая присоединениеAfterEvent неактивным после прикрепления первого события.
Давайте посмотрим на функцию attachAfterEvent :
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } Условная проверка неверна! Он проверяет, истинно ли attachAfterEvent вместо afterEventAttached . Это означает, что новое событие прикрепляется к экземпляру server при каждом запросе, а затем после каждого запроса запускаются все предыдущие прикрепленные события. Упс!
Оптимизация
Теперь, когда мы обнаружили проблемные области, давайте посмотрим, сможем ли мы сделать сервер быстрее.
Низко висящий фрукт
Давайте вернем обратно код прослушивателя server.on (вместо пустой функции) и будем использовать правильное логическое имя в условной проверке. Наша функция etagger выглядит следующим образом:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Теперь мы проверяем наше исправление, снова профилируя. Запустите сервер в одном терминале:
node index.jsЗатем профилируйте с помощью AutoCannon:
autocannon -c100 localhost:3000/seed/v1 Мы должны увидеть результаты где-то в диапазоне 200-кратного улучшения (выполнение 10-секундного теста @ https://localhost:3000/seed/v1 — 100 подключений):
| Стат | Среднее | Стдев | Максимум |
|---|---|---|---|
| Задержка (мс) | 19.47 | 4.29 | 103 |
| Треб/сек | 5011.11 | 506,2 | 5487 |
| Байт/сек | 51,8 МБ | 5,45 МБ | 58,72 МБ |
Важно сбалансировать потенциальное снижение стоимости сервера с затратами на разработку. Нам нужно определить в нашем собственном ситуационном контексте, как далеко нам нужно зайти в оптимизации проекта. В противном случае может быть слишком легко вложить 80% усилий в 20% повышения скорости. Оправдывают ли это ограничения проекта?
В некоторых сценариях может быть уместно добиться 200-кратного улучшения с помощью низко висящих фруктов и на этом закончить. В других случаях мы можем захотеть сделать нашу реализацию настолько быстрой, насколько это возможно. Это действительно зависит от приоритетов проекта.
Один из способов контролировать расход ресурсов — поставить цель. Например, улучшение в 10 раз или 4000 запросов в секунду. Основание этого на потребностях бизнеса имеет наибольший смысл. Например, если затраты на сервер на 100 % превышают бюджет, мы можем поставить цель двукратного улучшения.
Двигаясь дальше
Если мы создадим новый график пламени нашего сервера, мы должны увидеть что-то похожее на следующее:
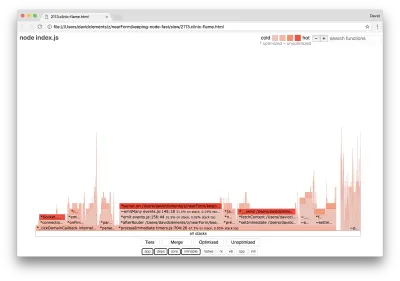
Прослушиватель событий по-прежнему является узким местом, он по-прежнему занимает треть процессорного времени при профилировании (ширина составляет примерно треть всего графа).
Какие дополнительные выгоды можно получить и стоит ли вносить изменения (наряду с связанными с ними разрушениями)?
С оптимизированной реализацией, которая, тем не менее, немного более ограничена, могут быть достигнуты следующие характеристики производительности (выполнение 10-секундного теста @ https://localhost:3000/seed/v1 — 10 подключений):
| Стат | Среднее | Стдев | Максимум |
|---|---|---|---|
| Задержка (мс) | 0,64 | 0,86 | 17 |
| Треб/сек | 8330,91 | 757,63 | 8991 |
| Байт/сек | 84,17 МБ | 7,64 МБ | 92,27 МБ |
Несмотря на то, что улучшение в 1,6 раза является значительным, в зависимости от ситуации можно утверждать, что усилия, изменения и нарушение кода, необходимые для создания этого улучшения, могут быть оправданы. Особенно по сравнению с 200-кратным улучшением исходной реализации за одно исправление ошибки.
Для достижения этого улучшения использовался тот же итеративный метод профилирования, создания пламенного графа, анализа, отладки и оптимизации, чтобы получить окончательный оптимизированный сервер, код для которого можно найти здесь.
Окончательные изменения для достижения 8000 запросов в секунду:
- Не создавайте объекты, а затем сериализуйте, создавайте строку JSON напрямую;
- Используйте что-то уникальное в контенте, чтобы определить его Etag, а не создавайте хэш;
- Не хешируйте URL-адрес, используйте его непосредственно в качестве ключа.
Эти изменения немного более сложны, немного более разрушительны для базы кода и делают промежуточное ПО etagger немного менее гибким, поскольку оно накладывает нагрузку на маршрут для предоставления значения Etag . Но на профилирующей машине это дает дополнительные 3000 запросов в секунду.
Давайте посмотрим на диаграмму пламени для этих последних улучшений:
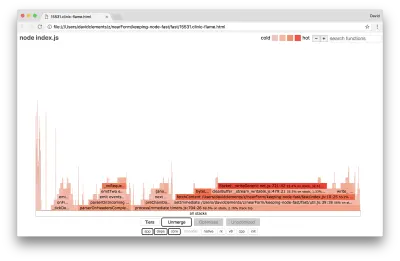
Самая горячая часть графика пламени — это часть ядра Node в net модуле. Это идеально.
Предотвращение проблем с производительностью
В завершение приведем несколько рекомендаций по предотвращению проблем с производительностью до их развертывания.
Использование инструментов производительности в качестве неофициальных контрольных точек во время разработки может отфильтровать ошибки производительности до того, как они попадут в рабочую среду. Рекомендуется сделать AutoCannon и Clinic (или их эквиваленты) частью повседневных инструментов разработки.
Приобретая фреймворк, узнайте, какова его политика в отношении производительности. Если платформа не отдает приоритет производительности, важно проверить, соответствует ли это инфраструктурным практикам и бизнес-целям. Например, компания Restify явно (начиная с выпуска версии 7) инвестировала средства в повышение производительности библиотеки. Однако, если низкая стоимость и высокая скорость являются абсолютным приоритетом, рассмотрите Fastify, который был измерен на 17% быстрее, чем участник Restify.
Остерегайтесь других вариантов выбора библиотек, которые могут иметь большое значение, особенно учитывайте ведение журнала. Когда разработчики устранят проблемы, они могут решить добавить дополнительные выходные данные журнала, чтобы помочь отладить связанные проблемы в будущем. Если используется неэффективный регистратор, это может со временем снизить производительность, как в басне о кипящей лягушке. Регистратор pino — это самый быстрый регистратор JSON с разделителями новой строки, доступный для Node.js.
Наконец, всегда помните, что цикл событий — это общий ресурс. Сервер Node.js в конечном итоге ограничен самой медленной логикой на самом горячем пути.