
Смешение материального и нематериального: проектирование мультимодальных интерфейсов с помощью Adobe XD
Опубликовано: 2022-03-10(Эта статья любезно спонсируется Adobe.) Пользовательские интерфейсы развиваются. Голосовые интерфейсы бросают вызов многолетнему доминированию графических пользовательских интерфейсов и быстро становятся обычной частью нашей повседневной жизни. Значительный прогресс в области автоматического распознавания речи (APS) и обработки естественного языка (NLP) вместе с внушительной потребительской базой (миллионы мобильных устройств со встроенными голосовыми помощниками) повлияли на быстрое развитие и внедрение голосового интерфейса.
Продукты, использующие голос в качестве основного интерфейса, становятся все более популярными. Только в США 47,3 миллиона взрослых имеют доступ к умным колонкам (это пятая часть взрослого населения США), и это число растет. Но у голосовых интерфейсов большое будущее не только в личном и домашнем использовании. Когда люди привыкнут к голосовым интерфейсам, они будут ожидать их и в бизнес-контексте. Только представьте, что скоро вы сможете активировать проектор в конференц-зале, сказав что-то вроде «Покажи мою презентацию».
Очевидно, что общение человека с машиной быстро расширяется, охватывая как письменное, так и устное взаимодействие. Но означает ли это, что будущие интерфейсы будут только голосовыми? Несмотря на некоторые научно-фантастические изображения, голос не заменит полностью графические пользовательские интерфейсы. Вместо этого у нас будет синергия голоса, изображения и жестов в новом формате интерфейса: мультимодальный интерфейс с голосовой поддержкой.
В этой статье мы:
- изучить концепцию голосового интерфейса и рассмотреть различные типы голосовых интерфейсов;
- выяснить, почему голосовые мультимодальные пользовательские интерфейсы будут предпочтительным для пользователей;
- узнайте, как создать мультимодальный пользовательский интерфейс с помощью Adobe XD.
Состояние голосовых пользовательских интерфейсов (VUI)
Прежде чем углубляться в детали голосовых пользовательских интерфейсов, мы должны определить, что такое голосовой ввод. Голосовой ввод — это взаимодействие человека с компьютером, при котором пользователь произносит команды, а не пишет их. Прелесть голосового ввода в том, что это более естественное взаимодействие для людей — пользователи не ограничены определенным синтаксисом при взаимодействии с системой; они могут структурировать свой ввод разными способами, точно так же, как в человеческом разговоре.
Голосовые пользовательские интерфейсы приносят своим пользователям следующие преимущества:
- Меньшая стоимость взаимодействия
Хотя использование голосового интерфейса связано с затратами на взаимодействие, эти затраты (теоретически) меньше, чем затраты на изучение нового графического интерфейса. - Управление без помощи рук
VUI отлично подходят, когда руки пользователей заняты — например, во время вождения, приготовления пищи или занятий спортом. - Скорость
Голос отличный, когда задавать вопрос быстрее, чем набирать его и читать результаты. Например, при использовании голоса в автомобиле быстрее сказать место навигационной системе, чем вводить его на сенсорном экране. - Эмоции и личность
Даже когда мы слышим голос, но не видим изображения говорящего, мы можем представить его себе в голове. Это дает возможность улучшить взаимодействие с пользователем. - Доступность
Пользователи с нарушениями зрения и пользователи с нарушениями подвижности могут использовать голос для взаимодействия с системой.
Три типа голосовых интерфейсов
В зависимости от того, как используется голос, это может быть один из следующих типов интерфейсов.
Голосовые агенты в устройствах первого экрана
Apple Siri и Google Assistant — яркие примеры голосовых агентов. Для таких систем голос больше похож на расширение существующего графического интерфейса. Во многих случаях агент действует как первый шаг на пути пользователя: пользователь запускает голосового агента и отдает команду голосом, в то время как все остальные взаимодействия выполняются с помощью сенсорного экрана. Например, когда вы задаете Siri вопрос, она предоставляет ответы в формате списка, и вам нужно взаимодействовать с этим списком. В результате пользовательский опыт становится фрагментированным — мы используем голос, чтобы инициировать взаимодействие, а затем переходим к прикосновениям, чтобы продолжить его.
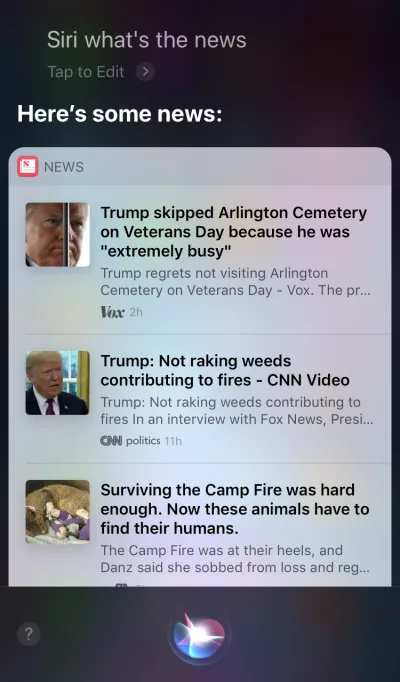
Голосовые устройства
Эти устройства не имеют визуальных дисплеев; пользователи полагаются на звук как для ввода, так и для вывода. Умные колонки Amazon Echo и Google Home являются яркими примерами продуктов в этой категории. Отсутствие визуального дисплея является существенным ограничением способности устройства передавать информацию и параметры пользователю. В результате большинство людей используют эти устройства для выполнения простых задач, таких как воспроизведение музыки и получение ответов на простые вопросы.

Голосовые устройства
В системах с приоритетом голоса устройство принимает пользовательский ввод в основном с помощью голосовых команд, но также имеет встроенный экранный дисплей. Это означает, что голос является основным пользовательским интерфейсом, но не единственным. Старая поговорка «Картинка стоит тысячи слов» по-прежнему применима к современным голосовым системам. Человеческий мозг обладает невероятными возможностями обработки изображений — мы можем понимать сложную информацию быстрее, когда видим ее визуально. По сравнению с голосовыми устройствами голосовые устройства позволяют пользователям получать доступ к большему объему информации и значительно облегчают многие задачи.
Amazon Echo Show — яркий пример устройства, использующего голосовую систему. Визуальная информация постепенно встраивается в целостную систему — экран не загружен иконками приложений; скорее, система побуждает пользователей пробовать разные голосовые команды (предлагая словесные команды, такие как «Попробуй, Алекса, покажи мне погоду в 17:00»). Экран даже упрощает выполнение обычных задач, таких как проверка рецепта во время приготовления — пользователям не нужно внимательно слушать и держать всю информацию в голове; когда им нужна информация, они просто смотрят на экран.

Представляем мультимодальные интерфейсы
Когда дело доходит до использования голоса в дизайне пользовательского интерфейса, не думайте, что голос можно использовать отдельно. Такие устройства, как Amazon Echo Show, имеют экран, но используют голос в качестве основного метода ввода, что обеспечивает более целостный пользовательский опыт. Это первый шаг к новому поколению пользовательских интерфейсов: мультимодальным интерфейсам.
Мультимодальный интерфейс — это интерфейс, который сочетает в себе голосовые, сенсорные, звуковые и визуальные эффекты различных типов в едином цельном пользовательском интерфейсе. Amazon Echo Show — отличный пример устройства, которое в полной мере использует мультимодальный интерфейс с голосовой поддержкой. Когда пользователи взаимодействуют с Show, они отправляют запросы точно так же, как если бы они использовали только голосовое устройство; однако ответ, который они получат, скорее всего, будет мультимодальным, содержащим как голосовые, так и визуальные ответы.
Мультимодальные продукты более сложны, чем продукты, которые полагаются только на визуальные эффекты или только на голос. Зачем кому-то вообще создавать мультимодальный интерфейс? Чтобы ответить на этот вопрос, нам нужно сделать шаг назад и посмотреть, как люди воспринимают окружающую их среду. У людей есть пять чувств, и комбинация наших чувств, работающих вместе, определяет то, как мы воспринимаем вещи. Например, наши чувства работают вместе, когда мы слушаем музыку на живом концерте. Уберите одно чувство (например, слух), и опыт приобретет совершенно другой контекст.

Слишком долго мы думали о пользовательском опыте исключительно как о визуальном или жестовом дизайне. Пришло время изменить это мышление. Мультимодальный дизайн — это способ обдумать и спроектировать опыт, который объединяет наши сенсорные способности.
Мультимодальные интерфейсы кажутся более человечным способом общения пользователя и машины. Они открывают новые возможности для более глубокого взаимодействия. И сегодня гораздо проще проектировать мультимодальные интерфейсы, потому что технические ограничения, которые в прошлом ограничивали взаимодействие с продуктами, стираются.
Разница между графическим интерфейсом и мультимодальным интерфейсом
Ключевое отличие здесь заключается в том, что мультимодальные интерфейсы, такие как Amazon Echo Show, синхронизируют голосовой и визуальный интерфейсы. В результате, когда мы разрабатываем опыт, голос и визуальные эффекты больше не являются независимыми частями; они являются неотъемлемой частью опыта, который предоставляет система.
Визуальный и голосовой канал: когда использовать каждый из них
Важно думать о голосе и визуальных эффектах как о каналах ввода и вывода. Каждый канал имеет свои сильные и слабые стороны.
Начнем с визуальных эффектов. Понятно, что некоторую информацию легче понять, когда мы ее видим, а не когда слышим. Визуальные эффекты работают лучше, когда вам нужно предоставить:
- длинные списки опций (чтение длинного списка займет много времени и будет трудным для понимания);
- информация с большим объемом данных (например, диаграммы и графики);
- информация о продукте (например, товары в интернет-магазинах; скорее всего, вы захотите увидеть товар перед покупкой) и сравнение товаров (как и в случае с длинным списком вариантов, будет сложно предоставить всю информацию только голосом) .
Однако для получения некоторой информации мы можем легко полагаться на вербальное общение. Голос может подойти в следующих случаях:
- пользовательские команды (голос — эффективный способ ввода, позволяющий пользователям быстро отдавать команды системе и миновать сложные навигационные меню);
- простые инструкции для пользователя (например, обычная проверка рецепта);
- предупреждения и уведомления (например, звуковое предупреждение в сочетании с голосовыми уведомлениями во время вождения).
Хотя это несколько типичных случаев сочетания визуальных и голосовых эффектов, важно знать, что мы не можем отделить их друг от друга. Мы можем создать лучший пользовательский опыт только тогда, когда и голос, и визуальные эффекты работают вместе. Например, предположим, что мы хотим купить новую пару обуви. Мы могли бы использовать голос, чтобы запросить у системы: «Покажи мне обувь New Balance». Система обработает ваш запрос и визуально предоставит информацию о продукте (чтобы нам было проще сравнивать обувь).
Что нужно знать для разработки мультимодальных интерфейсов с поддержкой голоса
Голос — одна из самых захватывающих задач для UX-дизайнеров. Несмотря на новизну, фундаментальные правила проектирования мультимодального интерфейса с поддержкой голоса такие же, как те, которые мы используем для создания визуального дизайна. Дизайнеры должны заботиться о своих пользователях. Они должны стремиться уменьшить трения для пользователей, решая их проблемы эффективными способами, и отдавать приоритет ясности, чтобы сделать выбор пользователя понятным.
Но есть и уникальные принципы проектирования мультимодальных интерфейсов.
Убедитесь, что вы решаете правильную проблему
Дизайн должен решать проблемы. Но очень важно решать правильные проблемы; в противном случае вы могли бы потратить много времени на создание опыта, который не представляет особой ценности для пользователей. Таким образом, убедитесь, что вы сосредоточены на решении правильной проблемы. Голосовые взаимодействия должны быть понятны пользователю; у пользователей должна быть веская причина использовать голос вместо других методов взаимодействия (таких как щелчок или постукивание). Вот почему, когда вы создаете новый продукт — даже до начала проектирования — важно провести исследование пользователей и определить, улучшит ли голос UX.
Начните с создания карты пути пользователя. Проанализируйте карту путешествия и найдите места, где включение голоса в качестве канала принесет пользу UX.
- Найдите места на пути, где пользователи могут столкнуться с трудностями и разочарованием. Снизит ли трение использование голоса?
- Подумайте о контексте пользователя. Подойдет ли голос для определенного контекста?
- Подумайте о том, что уникально возможно с помощью голоса. Помните об уникальных преимуществах использования голоса, таких как взаимодействие без помощи рук и без глаз. Может ли голос повысить ценность опыта?
Создавайте диалоговые потоки
В идеале разрабатываемые вами интерфейсы не должны требовать затрат на взаимодействие: пользователи должны иметь возможность удовлетворять свои потребности, не тратя дополнительное время на изучение того, как взаимодействовать с системой. Это происходит только тогда, когда голосовое взаимодействие напоминает реальный разговор, а не системный диалог, завернутый в формат голосовых команд. Фундаментальное правило хорошего пользовательского интерфейса простое: компьютеры должны подстраиваться под людей, а не наоборот.
Люди редко ведут плоские, линейные разговоры (разговоры, которые длятся всего один ход). Вот почему, чтобы взаимодействие с системой было похоже на живой разговор, дизайнеры должны сосредоточиться на создании диалоговых потоков. Каждый диалоговый поток состоит из диалогов — путей, которые происходят между системой и пользователем. Каждый диалог будет включать подсказки системы и возможные ответы пользователя.
Диалоговый поток может быть представлен в виде блок-схемы. Каждый поток должен фокусироваться на одном конкретном варианте использования (например, установка будильника с помощью системы). Для большинства диалогов в потоке жизненно важно учитывать пути ошибок, когда что-то идет не так.
Каждая голосовая команда пользователя состоит из трех ключевых элементов: намерения, высказывания и слота.
- Намерение — это цель взаимодействия пользователя с системой с поддержкой голоса.
Намерение — это просто причудливый способ определить цель, стоящую за набором слов. Каждое взаимодействие с системой приносит пользователю некоторую пользу. Будь то информация или действие, утилита находится в намерении. Понимание намерений пользователя является важной частью голосовых интерфейсов. Когда мы разрабатываем VUI, мы не всегда точно знаем, каково намерение пользователя, но мы можем угадать его с высокой точностью. - Высказывание — это то, как пользователь формулирует свой запрос.
Обычно у пользователей есть несколько способов сформулировать голосовую команду. Например, мы можем установить будильник, сказав: «Поставь будильник на 8 утра», или «Будильник завтра в 8 утра», или даже «Мне нужно проснуться в 8 утра». Дизайнеры должны учитывать все возможные варианты высказывания. - Слоты — это переменные, которые пользователи используют в команде. Иногда пользователям необходимо предоставить дополнительную информацию в запросе. В нашем примере с будильником «8 утра» — это слот.
Не вкладывайте слова в уста пользователя
Люди умеют говорить. Не пытайтесь научить их командам. Избегайте таких фраз, как «Чтобы отправить встречу, вам нужно сказать «Календарь, встречи, создать новую встречу»». Если вам нужно объяснить команды, вам нужно пересмотреть способ проектирования системы. Всегда стремитесь к общению на естественном языке и старайтесь приспособиться к различным стилям речи).
Стремитесь к последовательности
Вам нужно добиться согласованности в языке и голосе в разных контекстах. Последовательность поможет построить знакомство во взаимодействиях.
Всегда оставляйте отзыв
Видимость состояния системы — один из фундаментальных принципов хорошего дизайна графического интерфейса. Система должна всегда информировать пользователей о том, что происходит, посредством соответствующей обратной связи в разумные сроки. То же правило применяется к дизайну VUI.
- Сообщите пользователю, что система слушает.
Показывать визуальные индикаторы, когда устройство прослушивает или обрабатывает запрос пользователя. Без обратной связи пользователь может только догадываться, делает ли система что-то. Вот почему даже голосовые устройства, такие как Amazon Echo и Google Home, дают нам приятную визуальную обратную связь (мигающие огни), когда они слушают или ищут ответ. - Предоставьте разговорные маркеры.
Диалоговые маркеры сообщают пользователю, на каком этапе разговора он находится. - Подтвердите, когда задача будет выполнена.
Например, когда пользователи просят голосовую систему умного дома «Выключить свет в гараже», система должна сообщить пользователю, что команда была успешно выполнена. Без подтверждения пользователям нужно будет зайти в гараж и проверить свет. Это противоречит цели системы умного дома, которая состоит в том, чтобы облегчить жизнь пользователя.
Избегайте длинных предложений
При разработке системы с голосовой поддержкой подумайте о том, как вы предоставляете информацию пользователям. Относительно легко перегрузить пользователей слишком большим количеством информации, когда вы используете длинные предложения. Во-первых, пользователи не могут удерживать много информации в своей кратковременной памяти, поэтому они могут легко забыть какую-то важную информацию. Кроме того, звук — это медленный носитель — большинство людей могут читать гораздо быстрее, чем слушать.
Уважайте время вашего пользователя; не зачитывайте длинные аудиомонологи. Когда вы разрабатываете ответ, чем меньше слов вы используете, тем лучше. Но помните, что вам все равно нужно предоставить пользователю достаточно информации для выполнения своей задачи. Таким образом, если вы не можете обобщить ответ в нескольких словах, вместо этого отобразите его на экране.

Предоставьте следующие шаги последовательно
Пользователи могут быть перегружены не только длинными предложениями, но и их количеством вариантов одновременно. Крайне важно разбить процесс взаимодействия с голосовой системой на небольшие кусочки. Ограничьте количество вариантов выбора, которые есть у пользователя в любой момент, и убедитесь, что он знает, что делать в любой момент.
При проектировании сложной голосовой системы с большим количеством функций вы можете использовать метод постепенного раскрытия информации: представляйте только те параметры или информацию, которые необходимы для выполнения задачи.
Имейте сильную стратегию обработки ошибок
Конечно, система должна в первую очередь предотвращать возникновение ошибок. Но независимо от того, насколько хороша ваша голосовая система, вы всегда должны проектировать сценарий, в котором система не понимает пользователя. Ваша ответственность заключается в разработке для таких случаев.
Вот несколько практических советов по созданию стратегии:
- Не обвиняйте пользователя.
В разговоре ошибок нет. Старайтесь избегать ответов типа «Ваш ответ неверен». - Обеспечьте потоки восстановления после ошибок.
Обеспечьте возможность перехода назад и вперед в разговоре или даже выхода из системы без потери важной информации. Сохраняйте состояние пользователя в путешествии, чтобы он мог повторно взаимодействовать с системой с того места, на котором остановился. - Позвольте пользователям воспроизводить информацию.
Предоставьте возможность заставить систему повторять вопрос или ответ. Это может быть полезно для сложных вопросов или ответов, когда пользователю будет сложно зафиксировать всю информацию в своей рабочей памяти. - Предоставьте стоп-формулировку.
В некоторых случаях пользователь не будет заинтересован в том, чтобы слушать вариант, и захочет, чтобы система перестала говорить об этом. Стоп-формулировка должна помочь им сделать именно это. - Обращайтесь с неожиданными высказываниями изящно.
Сколько бы вы ни инвестировали в разработку системы, будут ситуации, когда система не понимает пользователя. Жизненно важно обращаться с такими случаями изящно. Не бойтесь позволить системе признать непонимание. Система должна сообщать о том, что она поняла, и предоставлять полезные подсказки. - Используйте аналитику, чтобы улучшить свою стратегию ошибок.
Аналитика может помочь вам выявить неправильные повороты и неверные толкования.
Следите за контекстом
Убедитесь, что система понимает контекст ввода пользователя. Например, когда кто-то говорит, что хочет забронировать рейс в Сан-Франциско на следующей неделе, он может ссылаться на «это» или «город» во время разговора. Система должна помнить сказанное и уметь сопоставлять это с вновь полученной информацией.
Узнайте о своих пользователях, чтобы создать более эффективные взаимодействия
Система с поддержкой голоса становится более сложной, когда она использует дополнительную информацию (например, контекст пользователя или прошлое поведение), чтобы понять, чего хочет пользователь. Этот метод называется интеллектуальной интерпретацией, и он требует, чтобы система активно изучала пользователя и могла соответствующим образом корректировать его поведение. Эти знания помогут системе дать ответы даже на сложные вопросы, например, «Какой подарок купить жене на день рождения?»
Придайте своему VUI индивидуальность
Каждая голосовая система оказывает эмоциональное воздействие на пользователя, планируете вы это или нет. Люди ассоциируют голос с людьми, а не с машинами. Согласно исследованию Speak Easy Global Edition, 74% постоянных пользователей голосовых технологий ожидают, что бренды будут использовать уникальные голоса и личности для своих голосовых продуктов. Можно развить эмпатию через личность и достичь более высокого уровня вовлеченности пользователей.
Постарайтесь отразить свой уникальный бренд и индивидуальность в голосе и тоне, который вы представляете. Создайте образ своего голосового агента и полагайтесь на этот образ при создании диалогов.
Завоевать доверие
Когда пользователи не доверяют системе, у них нет мотивации ее использовать. Вот почему построение доверия является требованием к дизайну продукта. Два фактора оказывают существенное влияние на уровень доверия: возможности системы и действительный результат.
Укрепление доверия начинается с установления пользовательских ожиданий. Традиционные графические интерфейсы содержат множество визуальных деталей, помогающих пользователю понять, на что способна система. Благодаря голосовой системе у дизайнеров меньше инструментов, на которые можно положиться. Тем не менее, жизненно важно сделать систему естественной для обнаружения; пользователь должен понимать, что возможно в системе, а что нет. Вот почему система с голосовой поддержкой может потребовать регистрации пользователя, когда она говорит о том, что система может делать или что она знает. При разработке онбординга постарайтесь предложить содержательные примеры, чтобы люди знали, что он может делать (примеры работают лучше, чем инструкции).
Когда дело доходит до достоверных результатов, люди знают, что голосовые системы несовершенны. Когда система предоставляет ответ, некоторые пользователи могут усомниться в правильности ответа. это происходит потому, что пользователи не имеют никакой информации о том, правильно ли был понят их запрос или какой алгоритм был использован для поиска ответа. Чтобы предотвратить проблемы с доверием, используйте экран для подтверждающих доказательств — отобразите исходный запрос на экране — и предоставьте некоторую ключевую информацию об алгоритме. Например, когда пользователь спрашивает: «Покажи мне пять лучших фильмов 2018 года», система может сказать: «Вот пять лучших фильмов 2018 года по кассовым сборам в США».
Не игнорируйте безопасность и конфиденциальность данных
В отличие от мобильных устройств, которые принадлежат человеку, голосовые устройства, как правило, принадлежат определенному месту, например кухне. И обычно в одном и том же месте находится более одного человека. Только представьте, что кто-то другой может взаимодействовать с системой, которая имеет доступ ко всем вашим личным данным. Некоторые системы VUI, такие как Amazon Alexa, Google Assistant и Apple Siri, могут распознавать отдельные голоса, что повышает уровень безопасности системы. Тем не менее, это не гарантирует, что система сможет распознавать пользователей по их уникальной голосовой подписи в 100% случаев.
Распознавание голоса постоянно совершенствуется, и в ближайшем будущем будет трудно или почти невозможно имитировать голос. Однако в текущих реалиях жизненно важно обеспечить дополнительный уровень аутентификации, чтобы убедить пользователя в безопасности его данных. Если вы разрабатываете приложение, которое работает с конфиденциальными данными, такими как информация о состоянии здоровья или банковские реквизиты, вы можете включить дополнительный этап проверки подлинности, например пароль, отпечаток пальца или распознавание лица.
Проведите юзабилити-тестирование
Юзабилити-тестирование является обязательным требованием для любой системы. Тестируйте заранее, тестируйте чаще — это должно быть фундаментальным правилом вашего процесса проектирования. Соберите данные исследования пользователей на ранней стадии и повторите свои проекты. Но тестирование мультимодальных интерфейсов имеет свою специфику. Вот два этапа, которые следует учитывать:
- Фаза идеи
Протестируйте образцы диалогов. Потренируйтесь читать примеры диалогов вслух. Когда у вас есть несколько диалоговых потоков, запишите обе стороны разговора (высказывания пользователя и ответы системы) и прослушайте запись, чтобы понять, звучат ли они естественно. - Ранние этапы разработки продукта (тестирование с прототипами lo-fi)
Тестирование Wizard of Oz хорошо подходит для тестирования диалоговых интерфейсов. Тестирование «Волшебник страны Оз» — это тип тестирования, в котором участник взаимодействует с системой, которая, по его мнению, управляется компьютером, но на самом деле управляется человеком. Участник теста формулирует запрос, а на другом конце отвечает реальный человек. Этот метод получил свое название от книги Фрэнка Баума «Чудесный волшебник страны Оз ». В книге обычный человек прячется за занавеской, притворяясь могущественным волшебником. Этот тест позволяет вам наметить все возможные сценарии взаимодействия и, как следствие, создать более естественные взаимодействия. Say Wizard — отличный инструмент, который поможет вам запустить тест голосового интерфейса Wizard of Oz на macOS. - Более поздние этапы разработки продукта (тестирование прототипов Hi-Fi)
При тестировании удобства использования графических пользовательских интерфейсов мы часто просим пользователей говорить вслух, когда они взаимодействуют с системой. Для системы с поддержкой голоса это не всегда возможно, потому что система будет слушать это повествование. Таким образом, может быть лучше наблюдать за взаимодействием пользователя с системой, чем просить его говорить вслух.
Как создать мультимодальный интерфейс с помощью Adobe XD
Теперь, когда у вас есть четкое представление о том, что такое мультимодальный интерфейс и какие правила следует помнить при его разработке, мы можем обсудить, как сделать прототип мультимодального интерфейса.
Прототипирование является фундаментальной частью процесса проектирования. Возможность воплотить идею в жизнь и поделиться ею с другими чрезвычайно важна. До сих пор у дизайнеров, которые хотели включить голос в прототипирование, было мало инструментов, на которые они могли положиться, самым мощным из которых была блок-схема. Чтобы представить, как пользователь будет взаимодействовать с системой, требовалось много воображения от того, кто смотрел на блок-схему. Благодаря Adobe XD дизайнеры теперь имеют доступ к голосовой среде и могут использовать ее в своих прототипах. XD легко объединяет экранное и голосовое прототипирование в одном приложении.
Новый опыт, тот же процесс
Несмотря на то, что голос — это совершенно другой носитель, чем визуальный, процесс прототипирования голоса в Adobe XD почти такой же, как прототипирование графического интерфейса. Команда Adobe XD интегрирует голос таким образом, чтобы любой дизайнер чувствовал себя естественным и интуитивно понятным. Дизайнеры могут использовать голосовые триггеры и воспроизведение речи для взаимодействия с прототипами:
- Голосовые триггеры начинают взаимодействие, когда пользователь произносит определенное слово или фразу (высказывание).
- Воспроизведение речи дает дизайнерам доступ к механизму преобразования текста в речь. XD будет произносить слова и предложения, определенные дизайнером. Воспроизведение речи можно использовать для самых разных целей. Например, это может действовать как подтверждение (чтобы успокоить пользователей) или как руководство (чтобы пользователи знали, что делать дальше).
Самое замечательное в XD то, что он не заставляет вас изучать сложности каждой голосовой платформы.
Достаточно слов — давайте посмотрим, как это работает в действии. Для всех примеров, которые вы увидите ниже, я использовал монтажные области, созданные с помощью набора пользовательского интерфейса Adobe XD для Amazon Alexa (это ссылка для загрузки набора). Комплект содержит все стили и компоненты, необходимые для создания возможностей для Amazon Alexa.
Предположим, у нас есть следующие артборды:
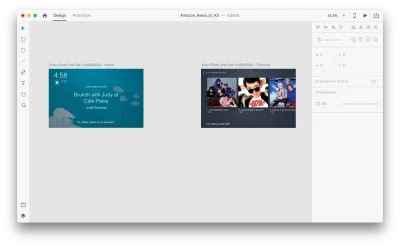
Давайте перейдем в режим прототипирования, чтобы добавить некоторые голосовые взаимодействия. Начнем с голосовых триггеров. Наряду с такими триггерами, как нажатие и перетаскивание, мы теперь можем использовать голос в качестве триггера. Мы можем использовать любые слои для голосовых триггеров, если у них есть дескриптор, ведущий к другой монтажной области. Соединим артборды вместе.
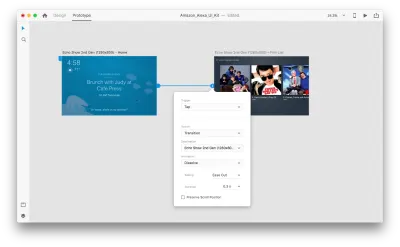
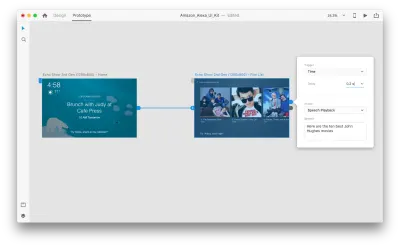
Как только мы это сделаем, мы найдем новую опцию «Голос» в разделе «Триггер». Когда мы выбираем эту опцию, мы видим поле «Команда», которое мы можем использовать для ввода высказывания — это то, что XD на самом деле будет прослушивать. Пользователям нужно будет произнести эту команду, чтобы активировать триггер.
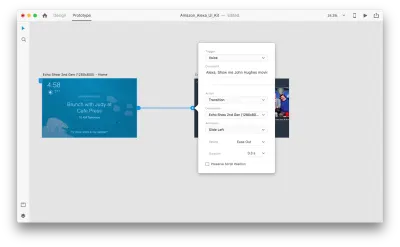
Это все! Мы определили наше первое голосовое взаимодействие. Теперь пользователи могут что-то сказать, и прототип на это отреагирует. Но мы можем сделать это взаимодействие намного более мощным, добавив воспроизведение речи. Как я упоминал ранее, воспроизведение речи позволяет системе произнести несколько слов.
Выберите всю вторую монтажную область и нажмите на синюю ручку. Выберите триггер «Время» с задержкой и установите его на 0,2 с. Под действием вы найдете «Воспроизведение речи». Мы будем записывать то, что говорит нам виртуальный помощник.
Мы готовы протестировать наш прототип. Выберите первую монтажную область и нажмите кнопку воспроизведения в правом верхнем углу, чтобы открыть окно предварительного просмотра. При взаимодействии с голосовым прототипированием убедитесь, что ваш микрофон включен. Затем удерживайте пробел, чтобы произнести голосовую команду. Этот ввод запускает следующее действие в прототипе.
Используйте автоматическую анимацию, чтобы сделать опыт более динамичным
Анимация дает много преимуществ для дизайна пользовательского интерфейса. Он служит четким функциональным целям, таким как:
- передача пространственных отношений между объектами (откуда взялся объект? связаны ли эти объекты?);
- коммуникативная аффордансность (Что я могу сделать дальше?)
Но функциональные цели — не единственные преимущества анимации; анимация также делает опыт более живым и динамичным. Вот почему анимация пользовательского интерфейса должна быть естественной частью мультимодальных интерфейсов.
Благодаря функции «Автоанимация», доступной в Adobe XD, становится намного проще создавать прототипы с иммерсивными анимированными переходами. Adobe XD сделает всю тяжелую работу за вас, поэтому вам не нужно об этом беспокоиться. Все, что вам нужно сделать, чтобы создать анимированный переход между двумя монтажными областями, — это просто продублировать монтажную область, изменить свойства объекта в клоне (такие свойства, как размер, положение и поворот) и применить действие «Автоанимация». XD автоматически анимирует различия в свойствах каждой монтажной области.
Давайте посмотрим, как это работает в нашем дизайне. Предположим, у нас есть существующий список покупок в Amazon Echo Show, и мы хотим добавить в список новый объект с помощью голоса. Дублируйте следующий артборд:
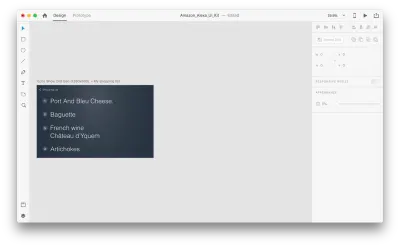
Давайте внесем некоторые изменения в макет: Добавьте новый объект. Мы не ограничены здесь, поэтому мы можем легко изменить любые свойства, такие как атрибуты текста, цвет, непрозрачность, положение объекта — в основном, любые изменения, которые мы делаем, XD будет анимировать между ними.
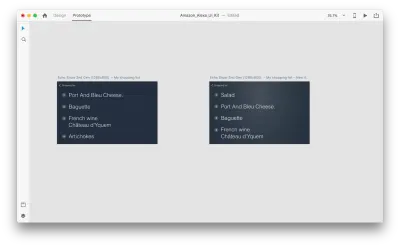
Когда вы соединяете две монтажные области вместе в режиме прототипа с помощью Auto-Animate в «Действии», XD автоматически анимирует различия в свойствах между каждой монтажной областью.
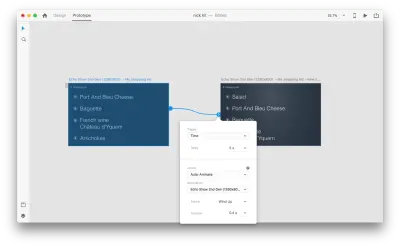
А вот как взаимодействие будет выглядеть для пользователей:

Один важный момент, который требует упоминания: сохраняйте имена всех слоев одинаковыми; в противном случае Adobe XD не сможет применить автоматическую анимацию.
Заключение
Мы находимся на заре революции пользовательского интерфейса. Интерфейсы нового поколения — мультимодальные интерфейсы — не только дадут пользователям больше возможностей, но и изменят способ взаимодействия пользователей с системами. We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. You can start today.
Эта статья является частью серии UX-дизайна, спонсируемой Adobe. Инструмент Adobe XD создан для быстрого и плавного процесса проектирования UX, поскольку он позволяет быстрее переходить от идеи к прототипу. Дизайн, прототип и публикация — все в одном приложении. Вы можете ознакомиться с другими вдохновляющими проектами, созданными с помощью Adobe XD, на Behance, а также подписаться на информационный бюллетень Adobe Experience Design, чтобы быть в курсе последних тенденций и идей для дизайна UX/UI.