
15 вопросов и ответов на интервью по машинному обучению на 2022 год
Опубликовано: 2021-01-08Вы тот, кто хочет сделать успешную карьеру в области машинного обучения? Если это так, отлично для вас!
Но сначала вы должны подготовиться к ледоколу — интервью ML.
Поскольку процесс подготовки к собеседованию может быть утомительным, мы решили вмешаться — вот список из 15 наиболее часто задаваемых вопросов на собеседованиях по машинному обучению!
- В чем разница между глубоким обучением и машинным обучением?
В то время как машинное обучение включает в себя применение и использование передовых алгоритмов для анализа данных, выявления скрытых шаблонов в данных и извлечения уроков из них и, наконец, применения полученных знаний для принятия обоснованных бизнес-решений. Что касается глубокого обучения, то это подмножество машинного обучения, которое включает использование искусственных нейронных сетей, которые черпают вдохновение из структуры нейронной сети человеческого мозга. Глубокое обучение широко используется для обнаружения признаков.
- Определить – точность и отзыв.
Точность или положительная прогностическая ценность измеряет или, точнее, прогнозирует количество истинных положительных результатов, заявленных моделью, по сравнению с количеством положительных результатов, которые она фактически заявляет.
Отзыв или истинный положительный показатель относится к количеству положительных результатов, заявленных моделью, по сравнению с фактическим количеством положительных результатов, присутствующих в данных.

Присоединяйтесь к онлайн- курсу по машинному обучению в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и программам повышения квалификации в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
- Объясните термины «смещение» и «дисперсия». '
В процессе обучения ожидаемая ошибка алгоритма обучения обычно классифицируется или разбивается на две части — смещение и дисперсию. В то время как «смещение» — это ситуация ошибки, вызванная использованием простых предположений в алгоритме обучения, «дисперсия» обозначает ошибку, вызванную сложностью этого алгоритма обучения при анализе данных. Смещение измеряет близость среднего классификатора, созданного алгоритмом обучения, к целевой функции, а дисперсия измеряет, насколько прогноз алгоритма обучения различается для разных наборов обучающих данных.
- Как работает кривая ROC?
Кривая ROC или кривая рабочих характеристик приемника представляет собой графическое представление вариации между истинно положительными показателями и ложноположительными показателями при различных пороговых значениях. Это фундаментальный инструмент для оценки диагностических тестов, который часто используется как представление компромисса между чувствительностью модели (истинные положительные результаты) и вероятностью срабатывания ложных сигналов тревоги (ложные положительные результаты).
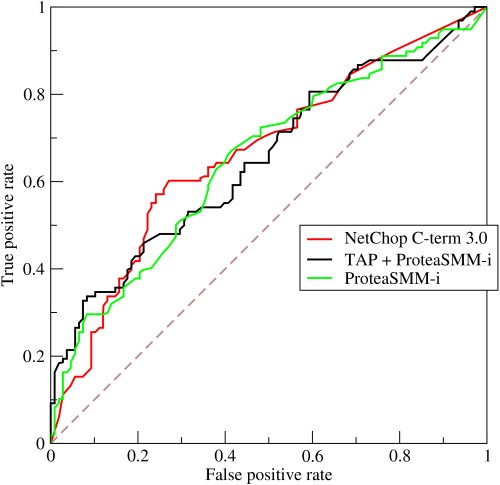
Источник
- Кривая показывает компромисс между чувствительностью и специфичностью: если чувствительность увеличивается, специфичность снижается.
- Если кривая больше граничит с левой осью и верхней частью пространства ROC, тест обычно более точен. Однако, если кривая приближается к 45-градусной диагонали пространства ROC, тест менее точен или надежен.
- Наклон касательной в точке отсечения указывает отношение правдоподобия (LR) для этого конкретного значения теста.
- Площадь под кривой измеряет точность теста.
- Объясните разницу между ошибками первого и второго рода?
Ошибка типа 1 — это ложноположительная ошибка, которая «утверждает», что инцидент произошел, хотя на самом деле ничего не произошло. Лучшим примером ложноположительной ошибки является ложная пожарная тревога — тревога начинает звонить, когда пожара нет. В отличие от этого, ошибка типа 2 является ложноотрицательной ошибкой, которая «утверждает», что ничего не произошло, когда что-то определенно произошло. Было бы ошибкой 2-го типа сказать беременной женщине, что она не носит ребенка.
- Почему Байеса называют «наивным Байесом»?
Наивный байесовский метод называют «наивным», потому что, хотя он имеет много практических применений, он основан на предположении, которое невозможно найти в реальных данных — все функции в наборе данных являются важными, независимыми и равными. В наивном байесовском подходе условная вероятность вычисляется как чистое произведение вероятностей отдельных компонентов, что подразумевает полную независимость признаков. К сожалению, это предположение никогда не может быть выполнено в реальном сценарии.
- Что означает термин «переоснащение»? Вы можете избежать этого? Если да, то как?
Обычно в процессе обучения модели подается большое количество данных. В ходе процесса данные начинают учиться даже на неточной информации и шуме, присутствующем в наборе выборочных данных. Это оказывает негативное влияние на производительность модели на новых данных, то есть модель не может точно классифицировать новые экземпляры/данные, кроме тех, которые входят в обучающий набор. Это известно как переоснащение.
Да, можно избежать переобучения. Вот как:
- Соберите больше данных (из разрозненных источников), чтобы обучить модель на разных образцах.
- Применяйте методы ансамбля (например, Random Forest), которые используют подход с пакетированием, чтобы свести к минимуму вариации в прогнозах путем сопоставления результатов нескольких деревьев решений для разных единиц набора данных.
- Обязательно используйте методы перекрестной проверки.
- Назовите два метода, используемых для калибровки в контролируемом обучении.
В контролируемом обучении используются два метода калибровки: калибровка Платта и изотоническая регрессия. Оба эти метода специально разработаны для бинарной классификации.
- Почему вы обрезаете дерево решений?
Деревья решений необходимо обрезать, чтобы избавиться от ветвей со слабыми предсказательными способностями. Это помогает свести к минимуму коэффициент сложности модели дерева решений и оптимизировать точность ее прогнозирования. Обрезку можно производить как сверху вниз, так и снизу вверх. Сокращение количества ошибок, сокращение затрат по сложности, сокращение сложности ошибок и сокращение числа ошибок с минимальным количеством ошибок — вот некоторые из наиболее часто используемых методов сокращения дерева решений.

- Что подразумевается под счетом F1?
Проще говоря, оценка F1 — это мера производительности модели — среднее значение точности и полноты модели, где результаты, близкие к 1, являются лучшими, а те, которые близки к 0, — худшими. Оценка F1 может использоваться в классификационных тестах, которые не придают значения истинным отрицательным результатам.
- Отличие Генеративного и Дискриминативного алгоритмов.
В то время как генеративный алгоритм изучает категории данных, дискриминационный алгоритм изучает различие между различными категориями данных. Когда дело доходит до задач классификации, дискриминационные модели обычно опережают генеративные модели.
- Что такое ансамблевое обучение?
Ensemble Learning использует комбинацию алгоритмов обучения для оптимизации прогностической эффективности моделей. В этом методе несколько моделей, таких как классификаторы или эксперты, стратегически генерируются и объединяются для предотвращения переобучения в моделях. Он в основном используется для улучшения прогнозирования, классификации, аппроксимации функций, производительности и т. д. модели.
- Определите «Трюк с ядром».
Метод Kernel Trick включает использование функций ядра, которые могут работать в многомерном и неявном пространстве признаков без необходимости явного вычисления координат точек в этом измерении. Функции ядра вычисляют внутренние продукты между изображениями всех пар данных, присутствующих в пространстве признаков. Эта процедура в вычислительном отношении дешевле по сравнению с явным вычислением координат и известна как трюк с ядром.
- Как следует обрабатывать отсутствующие или поврежденные данные в наборе данных?
Чтобы найти отсутствующие/поврежденные данные в наборе данных, вы должны либо удалить строки и столбцы, либо заменить их другими значениями. В библиотеке Pandas есть два отличных метода для поиска отсутствующих/поврежденных данных — isnull() и dropna(). Обе эти функции специально разработаны, чтобы помочь вам найти строки/столбцы данных с отсутствующими/поврежденными данными и удалить эти значения.
- Что такое хеш-таблица?
Хеш-таблица — это структура данных, которая создает ассоциативный массив, в котором ключ сопоставляется с определенными значениями с помощью хеш-функции. Хеш-таблицы в основном используются при индексировании баз данных.
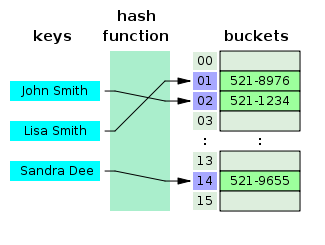
Источник
Этот список вопросов предназначен только для того, чтобы познакомить вас с основами машинного обучения, и, честно говоря, эти двадцать вопросов — всего лишь капля в море. Пока мы говорим, машинное обучение развивается, и, следовательно, со временем появятся новые концепции. Таким образом, ключ к успешному прохождению интервью по машинному обучению заключается в постоянном стремлении учиться и повышать квалификацию. Итак, приступайте к работе и исследуйте Интернет, читайте журналы, присоединяйтесь к онлайн-сообществам, посещайте конференции и семинары по машинному обучению — есть так много способов учиться.
Чтобы вступить в крупную организацию, сертификат от известного учреждения имеет важное значение. Ознакомьтесь с программой Executive PG IIIT-B в области машинного обучения и искусственного интеллекта и получите помощь в трудоустройстве от ведущих фирм, занимающихся машинным обучением и искусственным интеллектом.
Каковы ограничения ансамблевого обучения?
Ансамблевые подходы могут помочь в уменьшении дисперсии и разработке более надежных моделей. Однако у использования ансамблевых методов есть определенные недостатки, такие как отсутствие объяснимости и производительности. Кроме того, имейте в виду, что эффективность ансамблей обусловлена их способностью объединять несколько моделей, фокусирующихся на различных аспектах проблемы. Однако они имеют более длительный период прогноза, поскольку вам могут понадобиться прогнозы из сотен моделей. Даже если у них лучшие прогнозы, выигрыш в точности может не стоить того.
Сколько времени нужно, чтобы изучить машинное обучение?
Когда дело доходит до машинного обучения, сложные технологии, используемые для этого, могут легко напугать людей. Впрочем, разобраться в нем по крупицам несложно. Предыдущий опыт в статистике, высшей математике и т. д., несомненно, поможет вам быстро усвоить все концепции. Однако, поскольку образование и навыки у разных людей разные, одному человеку может понадобиться три недели, а другому может понадобиться год.
Как машинное обучение используется в нашей повседневной жизни?
Gmail классифицирует электронные письма как важные, сортируя их как основные, рекламные, социальные и обновляемые с помощью машинного обучения. Компании используют нейронные сети для обнаружения мошеннических транзакций на основе таких данных, как частота последних транзакций, сумма транзакции и тип продавца. Детекторы плагиата также используют машинное обучение. Когда дело доходит до машинного обучения, на его завершение уходит около шести месяцев.