
Классификатор KNN для машинного обучения: все, что вам нужно знать
Опубликовано: 2021-09-28Помните время, когда искусственный интеллект (ИИ) был только концепцией, ограниченной научно-фантастическими романами и фильмами? Что ж, благодаря технологическому прогрессу, ИИ — это то, с чем мы живем каждый день. От Alexa и Siri, которые всегда готовы прийти на помощь, до OTT-платформ, «отбирающих» фильмы, которые мы хотели бы посмотреть, искусственный интеллект почти стал повесткой дня и уже готов сказать об этом в обозримом будущем.
Все это возможно благодаря передовым алгоритмам машинного обучения. Сегодня мы поговорим об одном таком полезном алгоритме машинного обучения, классификаторе K-NN.
Машинное обучение — это отрасль искусственного интеллекта и информатики, которая использует данные и алгоритмы для имитации человеческого понимания, постепенно повышая точность алгоритмов. Машинное обучение включает в себя алгоритмы обучения, позволяющие делать прогнозы или классификации, а также извлекать ключевые идеи, которые влияют на принятие стратегических решений в компаниях и приложениях.
Алгоритм KNN (k-ближайший сосед) — это фундаментальный алгоритм контролируемого машинного обучения, используемый для решения задач регрессии и классификации. Итак, давайте углубимся, чтобы узнать больше о K-NN Classifier.
Оглавление
Контролируемое и неконтролируемое машинное обучение
Контролируемое и неконтролируемое обучение — это два основных подхода к науке о данных, и уместно знать разницу, прежде чем мы углубимся в детали KNN.
Обучение с учителем — это подход к машинному обучению, который использует помеченные наборы данных, чтобы помочь прогнозировать результаты. Такие наборы данных предназначены для «контроля» или обучения алгоритмов прогнозированию результатов или точной классификации данных. Следовательно, помеченные входы и выходы позволяют модели обучаться с течением времени, повышая ее точность.

Обучение с учителем включает в себя два типа задач — классификацию и регрессию. В задачах классификации алгоритмы распределяют тестовые данные по дискретным категориям, например, отделяя кошек от собак.
Важным примером из реальной жизни может быть классификация писем со спамом в папку, отдельную от вашего почтового ящика. С другой стороны, регрессионный метод обучения с учителем обучает алгоритмы понимать взаимосвязь между независимыми и зависимыми переменными. Он использует различные точки данных для прогнозирования числовых значений, таких как прогноз дохода от продаж для бизнеса.
Неконтролируемое обучение , наоборот, использует алгоритмы машинного обучения для анализа и кластеризации неразмеченных наборов данных. Таким образом, нет необходимости в человеческом вмешательстве («без присмотра»), чтобы алгоритмы выявляли скрытые закономерности в данных.
Модели неконтролируемого обучения имеют три основных применения: ассоциация, кластеризация и уменьшение размерности. Однако мы не будем вдаваться в подробности, так как это выходит за рамки нашего обсуждения.
K-ближайший сосед (KNN)
K-ближайший сосед или алгоритм KNN — это алгоритм машинного обучения, основанный на модели обучения с учителем. Алгоритм K-NN работает, предполагая, что подобные вещи существуют близко друг к другу. Следовательно, алгоритм K-NN использует сходство признаков между новыми точками данных и точками в обучающем наборе (доступные случаи) для прогнозирования значений новых точек данных. По сути, алгоритм K-NN присваивает значение последней точке данных в зависимости от того, насколько она похожа на точки в обучающем наборе. Алгоритм K-NN находит применение как в задачах классификации, так и в задачах регрессии, но в основном используется для задач классификации.
Вот пример для понимания классификатора K-NN.

Источник
На изображении выше входным значением является существо, похожее как на кошку, так и на собаку. Однако мы хотим классифицировать его либо на кошку, либо на собаку. Итак, мы можем использовать алгоритм K-NN для этой классификации. Модель K-NN найдет сходство между новым набором данных (входные данные) и доступными изображениями кошек и собак (набор обучающих данных). Впоследствии модель поместит новую точку данных в категорию кошек или собак на основе наиболее схожих признаков.
Точно так же категория A (зеленые точки) и категория B (оранжевые точки) имеют приведенный выше графический пример. У нас также есть новая точка данных (синяя точка), которая попадает в любую из категорий. Мы можем решить эту проблему классификации с помощью алгоритма K-NN и определить новую категорию точек данных.
Определение свойств алгоритма K-NN
Следующие два свойства лучше всего определяют алгоритм K-NN:
- Это алгоритм ленивого обучения, потому что вместо немедленного обучения на обучающем наборе алгоритм K-NN сохраняет набор данных и обучается на основе набора данных во время классификации.
- K-NN также является непараметрическим алгоритмом , то есть он не делает никаких предположений о базовых данных.
Работа алгоритма K-NN
Теперь давайте рассмотрим следующие шаги, чтобы понять, как работает алгоритм K-NN.
Шаг 1: Загрузите обучающие и тестовые данные.
Шаг 2: Выберите ближайшие точки данных, то есть значение K.
Шаг 3: Рассчитайте расстояние K соседей (расстояние между каждой строкой обучающих данных и тестовых данных). Евклидов метод чаще всего используется для расчета расстояния.
Шаг 4: Возьмите K ближайших соседей на основе рассчитанного евклидова расстояния.
Шаг 5: Среди ближайших K соседей подсчитайте количество точек данных в каждой категории.
Шаг 6: Распределите новые точки данных по той категории, для которой количество соседей максимально.
Шаг 7: Конец. Теперь модель готова.
Присоединяйтесь к онлайн- курсам по искусственному интеллекту в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и продвинутым сертификационным программам в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
Выбор значения К
K является критическим параметром в алгоритме K-NN. Следовательно, нам нужно помнить о некоторых моментах, прежде чем мы примем решение о значении K.
Распространенным методом определения значения K является использование кривых ошибок . На изображении ниже показаны кривые ошибок для различных значений K для тестовых и обучающих данных.


Источник
В приведенном выше графическом примере ошибка поезда равна нулю при K = 1 в обучающих данных, потому что ближайшей соседней точкой является сама эта точка. Однако ошибка теста высока даже при низких значениях K. Это называется высокой дисперсией или переоснащением данных. Ошибка теста уменьшается по мере того, как мы увеличиваем значение К., но после определенного значения К мы видим, что ошибка теста снова увеличивается, что называется смещением или недостаточным соответствием. Таким образом, ошибка тестовых данных изначально высока из-за дисперсии, затем она снижается и стабилизируется, а при дальнейшем увеличении значения K ошибка тестов снова резко возрастает из-за смещения.
Поэтому значение K, при котором ошибка теста стабилизируется и является низкой, принимается за оптимальное значение K. Учитывая приведенную выше кривую ошибок, K=8 является оптимальным значением.
Пример для понимания работы алгоритма K-NN
Рассмотрим набор данных, который был построен следующим образом:

Источник
Скажем, есть новая точка данных (черная точка) в (60,60), которую мы должны отнести либо к фиолетовому, либо к красному классу. Мы будем использовать K=3, что означает, что новая точка данных найдет три ближайшие точки данных, две в красном классе и одну в фиолетовом классе.
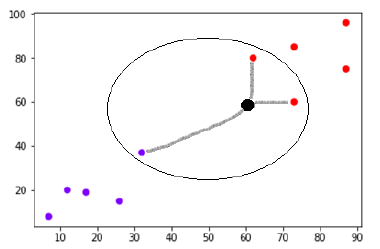
Источник
Ближайшие соседи определяются путем вычисления евклидова расстояния между двумя точками. Вот иллюстрация, показывающая, как выполняется расчет.

Источник
Теперь, поскольку два (из трех) ближайших соседей новой точки данных (черная точка) лежат в красном классе, новая точка данных также будет отнесена к красному классу.
Присоединяйтесь к онлайн-курсу по машинному обучению в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и программам повышения квалификации в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
K-NN как классификатор (реализация на Python)
Теперь, когда у нас есть упрощенное объяснение алгоритма K-NN, давайте рассмотрим реализацию алгоритма K-NN в Python. Мы сосредоточимся только на классификаторе K-NN.
Шаг 1: Импортируйте необходимые пакеты Python.

Источник
Шаг 2. Загрузите набор данных радужной оболочки глаза из репозитория машинного обучения UCI. Его веб-ссылка: «https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data» .
Шаг 3: Назначьте имена столбцов набору данных.

Источник
Шаг 4: Считайте набор данных в Pandas DataFrame.

Источник
Шаг 5: Предварительная обработка данных выполняется с использованием следующих строк скрипта.

Источник
Шаг 6: Разделите набор данных на тестовый и обучающий разделы. Приведенный ниже код разделит набор данных на 40% данных тестирования и 60% данных обучения.

Источник
Шаг 7: Масштабирование данных выполняется следующим образом:

Источник
Шаг 8: Обучите модель, используя класс KNeighborsClassifier sklearn.

Источник
Шаг 9: Сделайте прогноз, используя следующий скрипт:

Источник
Шаг 10: Распечатайте результаты.

Источник
Выход:

Источник
Что дальше? Зарегистрируйтесь в программе Advanced Certificate Program in Machine Learning от IIT Madras и upGrad.
Предположим, вы стремитесь стать квалифицированным специалистом по данным или специалистом по машинному обучению. В этом случае курс продвинутой сертификации по машинному обучению и облаку от IIT Madras и upGrad именно для вас!
12-месячная онлайн-программа специально разработана для работающих профессионалов, желающих освоить концепции машинного обучения, обработки больших данных, управления данными, хранения данных, облачных вычислений и развертывания моделей машинного обучения.
Вот некоторые основные моменты курса, чтобы дать вам лучшее представление о том, что предлагает программа:
- Всемирно признанный престижный сертификат IIT Madras
- 500+ часов обучения, 20+ тематических исследований и проектов, 25+ отраслевых менторских сессий, 8+ заданий по программированию
- Полный охват 7 языков программирования и инструментов
- 4 недели отраслевого краеугольного проекта
- Практические мастер-классы
- Оффлайн одноранговая сеть
Зарегистрируйтесь сегодня, чтобы узнать больше о программе!
Заключение
Со временем объем больших данных продолжает расти, а искусственный интеллект все больше вплетается в нашу жизнь. В результате резко растет спрос на специалистов по науке о данных, которые могут использовать возможности моделей машинного обучения для сбора информации и улучшения критически важных бизнес-процессов и нашего мира в целом. Без сомнения, область искусственного интеллекта и машинного обучения выглядит действительно многообещающе. С upGrad вы можете быть уверены, что ваша карьера в области машинного обучения и облачных вычислений будет успешной!
Почему K-NN хороший классификатор?
Основное преимущество K-NN перед другими алгоритмами машинного обучения заключается в том, что мы можем удобно использовать K-NN для многоклассовой классификации. Таким образом, K-NN — лучший алгоритм, если нам нужно классифицировать данные более чем по двум категориям или если данные содержат более двух меток. Кроме того, он идеально подходит для нелинейных данных и имеет относительно высокую точность.
Каково ограничение алгоритма K-NN?
Алгоритм K-NN работает, вычисляя расстояние между точками данных. Следовательно, совершенно очевидно, что это относительно более трудоемкий алгоритм, и в некоторых случаях для классификации потребуется больше времени. Поэтому лучше не использовать слишком много точек данных при использовании K-NN для мультиклассовой классификации. Другие ограничения включают большой объем памяти и чувствительность к ненужным функциям.
Каковы реальные приложения K-NN?
K-NN имеет несколько реальных вариантов использования в машинном обучении, таких как обнаружение рукописного ввода, распознавание речи, распознавание видео и распознавание изображений. В банковском деле K-NN используется для прогнозирования того, имеет ли человек право на получение ссуды, исходя из того, есть ли у него характеристики, аналогичные неплательщикам. В политике K-NN можно использовать для классификации потенциальных избирателей по разным классам, например, «будут голосовать за партию X» или «будут голосовать за партию Y» и т. д.