
Представляем API на основе компонентов
Опубликовано: 2022-03-10Эта статья была обновлена 31 января 2019 г. с учетом отзывов читателей. Автор добавил возможности пользовательских запросов в API на основе компонентов и описывает, как это работает .
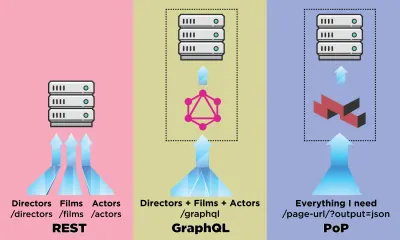
API — это канал связи для приложения для загрузки данных с сервера. В мире API REST был более устоявшейся методологией, но в последнее время его затмил GraphQL, который предлагает важные преимущества по сравнению с REST. В то время как REST требует нескольких HTTP-запросов для получения набора данных для отображения компонента, GraphQL может запрашивать и извлекать такие данные в одном запросе, и ответ будет именно таким, как требуется, без избыточной или недостаточной выборки данных, как это обычно происходит в ОТДЫХ.
В этой статье я опишу другой способ извлечения данных, который я разработал и назвал «PoP» (и открытый исходный код здесь), который расширяет идею получения данных для нескольких сущностей в одном запросе, представленном GraphQL, и принимает его шаг вперед, то есть в то время как REST извлекает данные для одного ресурса, а GraphQL извлекает данные для всех ресурсов в одном компоненте, API на основе компонентов может извлекать данные для всех ресурсов из всех компонентов на одной странице.
Использование API на основе компонентов имеет смысл, когда веб-сайт сам построен с использованием компонентов, т. е. когда веб-страница итеративно состоит из компонентов, обертывающих другие компоненты, пока в самом верху мы не получим один компонент, представляющий страницу. Например, веб-страница, показанная на изображении ниже, построена из компонентов, обведенных квадратами:
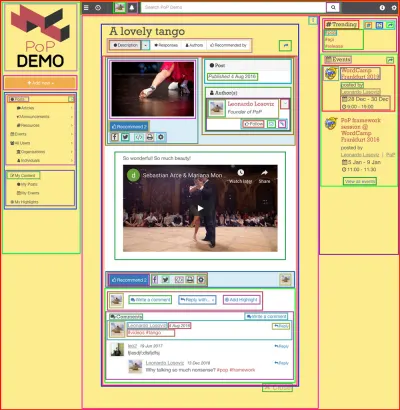
API на основе компонентов может сделать один запрос к серверу, запрашивая данные для всех ресурсов в каждом компоненте (а также для всех компонентов на странице), что достигается путем сохранения отношений между компонентами в сама структура API.
Среди прочего, эта структура предлагает следующие несколько преимуществ:
- Страница с большим количеством компонентов вызовет только один запрос вместо многих;
- Данные, совместно используемые компонентами, могут быть получены из БД только один раз и напечатаны в ответе только один раз;
- Это может значительно уменьшить — даже полностью устранить — потребность в хранилище данных.
Мы подробно рассмотрим их на протяжении всей статьи, но сначала давайте рассмотрим, что такое компоненты на самом деле и как мы можем создать сайт на основе таких компонентов, и, наконец, рассмотрим, как работает API на основе компонентов.
Рекомендуемая литература : Учебник по GraphQL: зачем нам нужен новый вид API
Создание сайта с помощью компонентов
Компонент — это просто набор фрагментов кода HTML, JavaScript и CSS, объединенных вместе для создания автономного объекта. Затем он может обернуть другие компоненты для создания более сложных структур, а также сам быть обернут другими компонентами. У компонента есть назначение, которое может варьироваться от чего-то очень простого (например, ссылка или кнопка) до чего-то очень сложного (например, карусель или загрузчик изображений с помощью перетаскивания). Компоненты наиболее полезны, когда они являются универсальными и позволяют настраивать их с помощью внедренных свойств (или «реквизитов»), чтобы они могли служить широкому спектру вариантов использования. В крайнем случае компонентом становится сам сайт.
Термин «компонент» часто используется для обозначения как функциональности, так и дизайна. Например, что касается функциональности, фреймворки JavaScript, такие как React или Vue, позволяют создавать компоненты на стороне клиента, которые могут самостоятельно отображать (например, после того, как API извлечет необходимые данные) и использовать реквизиты для установки значений конфигурации на их завернутые компоненты, обеспечивающие возможность повторного использования кода. Что касается дизайна, Bootstrap стандартизировал то, как веб-сайты выглядят и воспринимаются с помощью своей библиотеки внешних компонентов, и стало здоровой тенденцией для команд создавать дизайн-системы для обслуживания своих веб-сайтов, что позволяет различным членам команды (дизайнерам и разработчикам, а также маркетологи и продавцы), чтобы говорить на едином языке и выражать непротиворечивую идентичность.
Составление сайта на компоненты — это очень разумный способ сделать сайт более удобным в сопровождении. Сайты, использующие фреймворки JavaScript, такие как React и Vue, уже основаны на компонентах (по крайней мере, на стороне клиента). Использование библиотеки компонентов, такой как Bootstrap, не обязательно делает сайт основанным на компонентах (это может быть большой блок HTML), однако он включает в себя концепцию повторно используемых элементов для пользовательского интерфейса.
Если сайт представляет собой большой кусок HTML, то для того, чтобы разделить его на компоненты, мы должны разбить макет на серию повторяющихся шаблонов, для которых мы должны идентифицировать и каталогизировать разделы на странице на основе сходства их функциональных возможностей и стилей, а также разбить их. разделы на слои, максимально детализированные, пытаясь сфокусировать каждый слой на одной цели или действии, а также пытаясь сопоставить общие слои в разных разделах.
Примечание . «Атомарный дизайн» Брэда Фроста — отличная методология для выявления этих общих шаблонов и построения повторно используемой системы проектирования.
Следовательно, создание сайта из компонентов сродни игре с LEGO. Каждый компонент представляет собой либо атомарную функциональность, либо композицию других компонентов, либо их комбинацию.
Как показано ниже, базовый компонент (аватар) итеративно состоит из других компонентов, пока не будет получена веб-страница вверху:

Спецификация API на основе компонентов
Для разработанного мной API на основе компонентов компонент называется «модулем», поэтому в дальнейшем термины «компонент» и «модуль» используются взаимозаменяемо.
Взаимосвязь всех модулей, обертывающих друг друга, от самого верхнего модуля до самого последнего уровня, называется «иерархией компонентов». Это отношение может быть выражено через ассоциативный массив (массив ключ => свойство) на стороне сервера, в котором каждый модуль указывает свое имя в качестве атрибута ключа и его внутренние модули в modules свойств. Затем API просто кодирует этот массив как объект JSON для использования:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }Отношения между модулями определяются строго сверху вниз: модуль оборачивает другие модули и знает, кто они, но не знает — и ему все равно — какие модули оборачивают его.
Например, в приведенном выше коде JSON модуль module-level1 знает, что он является оболочкой для модулей module-level11 и module-level12 , и, транзитивно, он также знает, что он module-level121 ; но модуль module-level11 не заботится о том, кто его упаковывает, следовательно, не знает о module-level1 .
Имея структуру на основе компонентов, теперь мы можем добавлять фактическую информацию, требуемую каждым модулем, которая подразделяется на параметры (такие как значения конфигурации и другие свойства) и данные (такие как идентификаторы запрошенных объектов базы данных и другие свойства). , и размещены соответственно в записях modulesettings и moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } После этого API добавит данные объекта базы данных. Эта информация помещается не в каждый модуль, а в общий раздел, называемый databases , чтобы избежать дублирования информации, когда два или более разных модуля извлекают одни и те же объекты из базы данных.
Кроме того, API представляет данные объекта базы данных в реляционной манере, чтобы избежать дублирования информации, когда два или более разных объекта базы данных связаны с общим объектом (например, два сообщения одного автора). Другими словами, данные объекта базы данных нормализуются.
Рекомендуемая литература : Создание бессерверной контактной формы для вашего статического сайта
Структура представляет собой словарь, организованный сначала для каждого типа объекта, а затем для идентификатора объекта, из которого мы можем получить свойства объекта:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Этот объект JSON уже является ответом API на основе компонентов. Его формат сам по себе является спецификацией: пока сервер возвращает ответ JSON в требуемом формате, клиент может использовать API независимо от того, как он реализован. Следовательно, API может быть реализован на любом языке (что является одной из прелестей GraphQL: будучи спецификацией, а не фактической реализацией, он стал доступен на множестве языков).
Примечание . В следующей статье я опишу свою реализацию API на основе компонентов в PHP (который доступен в репозитории).
Пример ответа API
Например, приведенный ниже ответ API содержит иерархию компонентов с двумя модулями: page => post-feed , где модуль post-feed извлекает сообщения блога. Обратите внимание на следующее:
- Каждый модуль знает, какие запрошенные им объекты из свойства
dbobjectids(идентификаторы4и9для сообщений в блоге) - Каждый модуль знает тип объекта для своих запрошенных объектов из свойства
dbkeys(данные каждого сообщения находятся в разделеposts, а данные об авторе сообщения, соответствующие автору с идентификатором, указанным в свойствеauthorсообщения, находятся в разделеusers). - Поскольку данные объекта базы данных являются реляционными, свойство
authorсодержит идентификатор объекта автора, а не печатает данные автора напрямую.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Различия в получении данных из API на основе ресурсов, схем и компонентов
Давайте посмотрим, как API на основе компонентов, такой как PoP, сравнивается при извлечении данных с API на основе ресурсов, таким как REST, и с API на основе схемы, таким как GraphQL.
Допустим, на IMDB есть страница с двумя компонентами, которым необходимо получать данные: «Избранный режиссер» (показывает описание Джорджа Лукаса и список его фильмов) и «Фильмы, рекомендуемые для вас» (показывают такие фильмы, как «Звездные войны: Эпизод I» ). — «Скрытая угроза» и «Терминатор »). Это может выглядеть так:
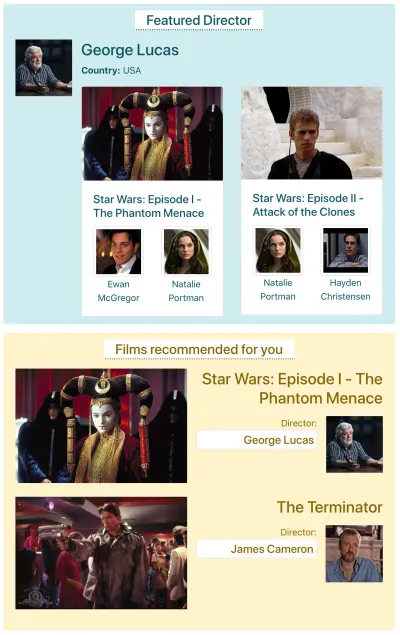
Давайте посмотрим, сколько запросов необходимо для получения данных через каждый метод API. Для этого примера компонент «Избранный режиссер» возвращает один результат («Джордж Лукас»), из которого он извлекает два фильма ( «Звездные войны: Эпизод I — Скрытая угроза» и «Звездные войны: Эпизод II — Атака клонов »), и на каждый фильм по два актера («Юэн МакГрегор» и «Натали Портман» для первого фильма и «Натали Портман» и «Хайден Кристенсен» для второго фильма). Компонент «Фильмы, рекомендованные для вас» выдает два результата ( «Звездные войны: Эпизод I — Скрытая угроза» и «Терминатор »), а затем выбирает их режиссеров («Джордж Лукас» и «Джеймс Кэмерон» соответственно).
Используя REST для рендеринга компонента featured-director , нам могут понадобиться следующие 7 запросов (это число может варьироваться в зависимости от того, сколько данных предоставляет каждая конечная точка, т. е. насколько реализована избыточная выборка):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL позволяет с помощью строго типизированных схем извлекать все необходимые данные одним запросом для каждого компонента. Запрос на получение данных через GraphQL для компонента featuredDirector выглядит так (после реализации соответствующей схемы):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }И выдает следующий ответ:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }И запрос компонента «Фильмы, рекомендуемые для вас» дает следующий ответ:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP выдает только один запрос на получение всех данных для всех компонентов на странице и нормализует результаты. Вызываемая конечная точка просто совпадает с URL-адресом, для которого нам нужно получить данные, просто добавив дополнительный параметр output=json , чтобы указать, что данные должны быть представлены в формате JSON, а не распечатываться в виде HTML:
GET - /url-of-the-page/?output=json Предполагая, что структура модуля имеет верхний модуль с именем page , содержащий модули featured-director и films-recommended-for-you , и у них также есть подмодули, например:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"Единственный возвращенный ответ JSON будет выглядеть так:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Давайте проанализируем, как эти три метода сравниваются друг с другом с точки зрения скорости и количества извлекаемых данных.
Скорость
Через REST необходимость получать 7 запросов только для рендеринга одного компонента может быть очень медленной, в основном при мобильных и шатких соединениях для передачи данных. Следовательно, переход с REST на GraphQL очень важен для скорости, потому что мы можем отобразить компонент всего одним запросом.
PoP, поскольку он может получать все данные для многих компонентов в одном запросе, будет быстрее для одновременного рендеринга многих компонентов; впрочем, скорее всего в этом нет необходимости. Отрисовка компонентов по порядку (как они отображаются на странице) уже является хорошей практикой, а для тех компонентов, которые появляются под сгибом, конечно, нет необходимости спешить с их визуализацией. Следовательно, и API на основе схемы, и API на основе компонентов уже довольно хороши и явно превосходят API на основе ресурсов.
Объем данных
При каждом запросе данные в ответе GraphQL могут дублироваться: актриса «Натали Портман» дважды извлекается в ответе от первого компонента, а при рассмотрении совместного вывода для двух компонентов мы также можем найти общие данные, такие как фильм Звёздные войны: Эпизод I — Скрытая угроза .
PoP, с другой стороны, нормализует данные базы данных и печатает их только один раз, однако несет накладные расходы на печать структуры модуля. Следовательно, в зависимости от того, содержит ли конкретный запрос дублированные данные или нет, API на основе схемы или API на основе компонентов будет иметь меньший размер.
В заключение, API на основе схемы, такой как GraphQL, и API на основе компонентов, такой как PoP, одинаково хороши с точки зрения производительности и превосходят API на основе ресурсов, такой как REST.
Рекомендуемая литература : Понимание и использование REST API .
Особые свойства API на основе компонентов
Если API на основе компонентов не обязательно лучше с точки зрения производительности, чем API на основе схемы, вам может быть интересно, чего я пытаюсь достичь с помощью этой статьи?
В этом разделе я попытаюсь убедить вас в том, что такой API обладает невероятным потенциалом, предоставляя несколько очень желательных функций, что делает его серьезным соперником в мире API. Ниже я описываю и демонстрирую каждую из его уникальных замечательных функций.
Данные, которые необходимо извлечь из базы данных, можно вывести из иерархии компонентов.
Когда модуль отображает свойство из объекта БД, модуль может не знать или не заботиться о том, что это за объект; все, что ему нужно, это определить, какие свойства загруженного объекта требуются.
Например, рассмотрим изображение ниже. Модуль загружает объект из базы данных (в данном случае отдельный пост), а затем его модули-потомки будут показывать определенные свойства объекта, такие как title и content :
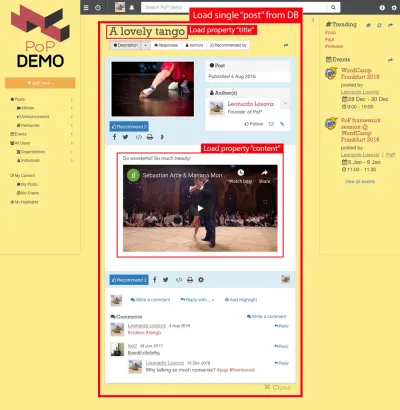
Следовательно, в иерархии компонентов модули «загрузки данных» будут отвечать за загрузку запрошенных объектов (в данном случае это модуль, загружающий один пост), а его дочерние модули будут определять, какие свойства объекта БД требуются ( title и content , в данном случае).
Извлечение всех необходимых свойств для объекта БД может быть выполнено автоматически путем обхода иерархии компонентов: начиная с модуля загрузки данных, мы итерируем все его модули-потомки вплоть до достижения нового модуля загрузки данных или до конца дерева; на каждом уровне мы получаем все необходимые свойства, а затем объединяем все свойства вместе и запрашиваем их из базы данных, все только один раз.
В приведенной ниже структуре модуль single-post извлекает результаты из БД (сообщение с идентификатором 37), а подмодули post-title и post-content определяют свойства, которые будут загружены для запрашиваемого объекта БД ( title и content соответственно); подмодули post-layout и fetch-next-post-button не требуют никаких полей данных.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"Выполняемый запрос вычисляется автоматически из иерархии компонентов и их обязательных полей данных, содержащих все свойства, необходимые для всех модулей и их подмодулей:
SELECT title, content FROM posts WHERE id = 37 Извлекая свойства для извлечения непосредственно из модулей, запрос будет автоматически обновляться при каждом изменении иерархии компонентов. Если, например, мы затем добавим подмодуль post-thumbnail , для которого требуется thumbnail поля данных:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Затем запрос автоматически обновляется для получения дополнительного свойства:
SELECT title, content, thumbnail FROM posts WHERE id = 37Поскольку мы установили, что данные объекта базы данных извлекаются реляционным способом, мы также можем применить эту стратегию к отношениям между самими объектами базы данных.
Рассмотрим изображение ниже: Начиная с типа объекта post и продвигаясь вниз по иерархии компонентов, нам нужно будет сместить тип объекта БД на user и comment , соответствующие автору сообщения и каждому из комментариев сообщения соответственно, а затем для каждого комментарий, он должен еще раз изменить тип объекта на user , соответствующего автору комментария.
Переход от объекта базы данных к реляционному объекту (возможно, изменение типа объекта, как в случае post => author переходит от post к user , или нет, как в случае author => последователи, переходящие от user к user ) — это то, что я называю «переключением доменов». ».
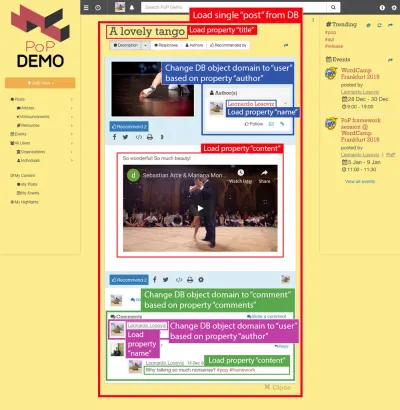
После переключения на новый домен с этого уровня иерархии компонентов вниз все необходимые свойства будут подчинены новому домену:
-
nameизвлекается из объектаuser(представляющего автора сообщения), -
contentизвлекается из объектаcomment(представляющего каждый комментарий к сообщению), -
nameизвлекается изuserобъекта (представляющего автора каждого комментария).
Обходя иерархию компонентов, API знает, когда он переключается на новый домен, и соответствующим образом обновляет запрос для получения реляционного объекта.
Например, если нам нужно показать данные от автора сообщения, стекирующий подмодуль post-author изменит домен на этом уровне с post на соответствующего user , и с этого уровня вниз объект БД, загруженный в контекст, переданный модулю, Пользователь. Затем подмодули user-name user-avatar в post-author будут загружать свойства name и avatar в объекте user :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"В результате получается следующий запрос:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idТаким образом, при соответствующей настройке каждого модуля нет необходимости писать запрос для получения данных для API на основе компонентов. Запрос автоматически создается из структуры самой иерархии компонентов, получая информацию о том, какие объекты должны быть загружены модулями загрузки данных, поля для извлечения для каждого загруженного объекта, определенные в каждом модуле-потомке, и переключение домена, определенное в каждом модуле-потомке.
Добавление, удаление, замена или изменение любого модуля автоматически обновит запрос. После выполнения запроса полученные данные будут именно такими, какие требуются — ни больше, ни меньше.
Наблюдение за данными и расчет дополнительных свойств
Начиная с модуля загрузки данных вниз по иерархии компонентов, любой модуль может наблюдать за возвращаемыми результатами и вычислять на их основе дополнительные элементы данных или значения feedback , которые помещаются в поле ввода moduledata .
Например, модуль fetch-next-post-button может добавить свойство, указывающее, есть ли еще результаты для извлечения или нет (на основе этого значения обратной связи, если результатов больше нет, кнопка будет отключена или скрыта):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }Неявное знание необходимых данных снижает сложность и делает концепцию «конечной точки» устаревшей
Как показано выше, API на основе компонентов может получать именно те данные, которые требуются, поскольку он имеет модель всех компонентов на сервере и поля данных, которые требуются для каждого компонента. Затем он может сделать знание необходимых полей данных неявным.

Преимущество заключается в том, что определение того, какие данные требуются компоненту, может быть обновлено только на стороне сервера, без необходимости повторного развертывания файлов JavaScript, а клиент может быть тупым, просто попросив сервер предоставить любые данные, которые ему нужны. , что снижает сложность клиентского приложения.
Кроме того, вызов API для получения данных для всех компонентов для определенного URL-адреса можно выполнить, просто запросив этот URL-адрес и добавив дополнительный параметр output=json , чтобы указать, что возвращаются данные API вместо печати страницы. Следовательно, URL-адрес становится собственной конечной точкой или, если рассматривать его по-другому, понятие «конечная точка» устаревает.
Получение подмножеств данных: данные могут быть получены для определенных модулей, найденных на любом уровне иерархии компонентов.
Что произойдет, если нам нужно получить данные не для всех модулей на странице, а просто данные для определенного модуля, начиная с любого уровня иерархии компонентов? Например, если модуль реализует бесконечную прокрутку, при прокрутке вниз мы должны получить только новые данные для этого модуля, а не для других модулей на странице.
Этого можно добиться путем фильтрации ветвей иерархии компонентов, которые будут включены в ответ, чтобы включить свойства только начиная с указанного модуля и игнорировать все выше этого уровня. В моей реализации (о которой я расскажу в следующей статье) фильтрация включается добавлением параметра modulefilter=modulepaths в URL, а выбранный модуль (или модули) указывается через параметр modulepaths[] , где «путь к модулю ” — это список модулей, начиная с самого верхнего модуля и заканчивая конкретным модулем (например module1 => module2 => module3 имеет путь к модулю [ module1 , module2 , module3 ] и передается как параметр URL-адреса как module1.module2.module3 ) .
Например, в иерархии компонентов под каждым модулем есть запись dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Затем запрос URL-адреса веб-страницы с добавлением параметров modulefilter=modulepaths и modulepaths[]=module1.module2.module5 приведет к следующему ответу:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] По сути, API начинает загружать данные, начиная с module1 => module2 => module5 . Вот почему module6 , который относится module5 , также приносит свои данные, а module3 и module4 - нет.
Кроме того, мы можем создавать настраиваемые фильтры модулей, чтобы включить в них заранее подготовленный набор модулей. Например, вызов страницы с modulefilter=userstate может напечатать только те модули, которые требуют пользовательского состояния для их отображения в клиенте, такие как модули module3 и module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] Информация о том, какие модули являются начальными, находится в разделе requestmeta под входом filteredmodules в виде массива путей к модулям:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Эта функция позволяет реализовать несложное одностраничное приложение, в котором фрейм сайта загружается по начальному запросу:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Но начиная с них мы можем добавлять параметр modulefilter=page ко всем запрошенным URL-адресам, отфильтровывая фрейм и выводя только содержимое страницы:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] Подобно фильтрам userstate , пользовательской информации и описанным выше page , мы можем реализовать любой пользовательский фильтр модулей и создать богатый пользовательский интерфейс.
Модуль — это собственный API
Как показано выше, мы можем фильтровать ответ API для получения данных, начиная с любого модуля. Как следствие, каждый модуль может взаимодействовать сам с собой от клиента к серверу, просто добавляя путь к своему модулю к URL-адресу веб-страницы, в которую он был включен.
Я надеюсь, вы извините мое чрезмерное волнение, но я действительно не могу в полной мере подчеркнуть, насколько замечательна эта функция. При создании компонента нам не нужно создавать API, чтобы идти вместе с ним для извлечения данных (REST, GraphQL или вообще что-то), потому что компонент уже может разговаривать сам с собой на сервере и загружать свои собственные data — полностью автономный и самообслуживающий .
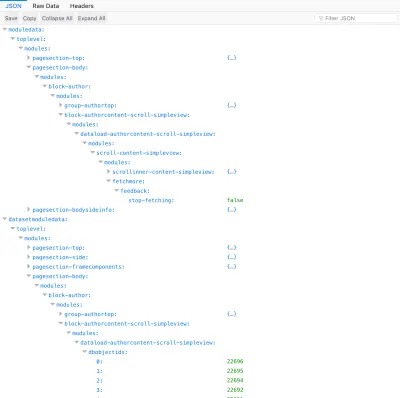
Каждый модуль загрузки данных экспортирует URL-адрес для взаимодействия с ним в разделе dataloadsource из раздела datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }Извлечение данных отделено от модулей и DRY
Чтобы показать, что выборка данных в API на основе компонентов сильно развязана и СУХАЯ (не повторяйте себя), мне сначала нужно показать, как в API на основе схемы, таком как GraphQL , она менее развязана и не СУХОЙ.
В GraphQL запрос на получение данных должен указывать поля данных для компонента, которые могут включать подкомпоненты, а они также могут включать подкомпоненты и так далее. Затем самый верхний компонент должен знать, какие данные требуются каждому из его подкомпонентов, чтобы получить эти данные.
Например, для рендеринга компонента <FeaturedDirector> могут потребоваться следующие подкомпоненты:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> В этом сценарии запрос GraphQL реализован на уровне <FeaturedDirector> . Затем, если подкомпонент <Film> обновляется, запрашивая заголовок через свойство filmTitle вместо title , запрос от компонента <FeaturedDirector> также необходимо будет обновить, чтобы отразить эту новую информацию (GraphQL имеет механизм управления версиями, который может обрабатывать с этой проблемой, но рано или поздно мы все равно должны обновить информацию). Это усложняет обслуживание, с которым может быть трудно справиться, если внутренние компоненты часто изменяются или производятся сторонними разработчиками. Следовательно, компоненты не полностью отделены друг от друга.
Точно так же мы можем захотеть напрямую отобразить компонент <Film> для какого-то конкретного фильма, для которого затем мы также должны реализовать запрос GraphQL на этом уровне, чтобы получить данные для фильма и его актеров, что добавляет избыточный код: части один и тот же запрос будет жить на разных уровнях структуры компонента. Так что GraphQL не СУХОЙ .
Поскольку API на основе компонентов уже знает, как его компоненты обволакивают друг друга в своей собственной структуре, этих проблем можно полностью избежать. Во-первых, клиент может просто запросить необходимые ему данные, какими бы они ни были; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
Однако в API на основе компонентов мы можем легко использовать отношения между модулями, уже описанными в API, для соединения модулей вместе. Хотя изначально у нас будет такой ответ:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }После добавления Instagram у нас будет обновленный ответ:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } И просто перебирая все значения в modulesettings["share-on-social-media"].modules , компонент <ShareOnSocialMedia> можно обновить, чтобы он отображал компонент <InstagramShare> без необходимости повторного развертывания какого-либо файла JavaScript. Следовательно, API поддерживает добавление и удаление модулей без ущерба для кода других модулей, достигая более высокой степени модульности.
Собственный клиентский кэш/хранилище данных
Полученные данные базы данных нормализованы в структуре словаря и стандартизированы таким образом, что, начиная со значения в dbobjectids , любой фрагмент данных в databases может быть доступен, просто следуя пути к нему, как указано в записях dbkeys , независимо от того, как он был структурирован. . Следовательно, логика организации данных уже встроена в сам API.
Мы можем извлечь выгоду из этой ситуации несколькими способами. Например, возвращенные данные для каждого запроса могут быть добавлены в кэш на стороне клиента, содержащий все данные, запрошенные пользователем на протяжении всего сеанса. Следовательно, можно избежать добавления в приложение внешнего хранилища данных, такого как Redux (я имею в виду обработку данных, а не другие функции, такие как Undo/Redo, совместную среду или отладку во времени).
Кроме того, структура на основе компонентов способствует кэшированию: иерархия компонентов зависит не от URL-адреса, а от того, какие компоненты необходимы в этом URL-адресе. Таким образом, два события в каталогах /events/1/ и /events/2/ будут иметь одну и ту же иерархию компонентов, и информация о том, какие модули требуются, может повторно использоваться в них. Как следствие, все свойства (кроме данных из базы данных) могут кэшироваться на клиенте после получения первого события и повторно использоваться с этого момента, так что необходимо извлекать только данные из базы данных для каждого последующего события и ничего больше.
Расширяемость и переназначение
Раздел databases API может быть расширен, что позволит разделить его информацию на настраиваемые подразделы. По умолчанию все данные объекта базы данных помещаются в запись primary , однако мы также можем создавать пользовательские записи, куда помещать определенные свойства объекта БД.
Например, если компонент «Фильмы, рекомендуемые для вас», описанный ранее, показывает список друзей вошедшего в систему пользователя, которые смотрели этот фильм, в свойстве friendsWhoWatchedFilm объекта БД film , потому что это значение будет меняться в зависимости от вошедшего в систему пользователя. user, то вместо этого мы сохраняем это свойство в userstate состояния пользователя, поэтому, когда пользователь выходит из системы, мы удаляем только эту ветку из кэшированной базы данных на клиенте, но все primary данные остаются:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }Кроме того, до определенного момента структура ответа API может быть изменена. В частности, результаты базы данных могут быть напечатаны в другой структуре данных, например, в виде массива вместо словаря по умолчанию.
Например, если тип объекта только один (например, films ), его можно отформатировать как массив, который будет передан непосредственно в компонент с опережением ввода:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Поддержка аспектно-ориентированного программирования
В дополнение к извлечению данных API на основе компонентов также может публиковать данные, например, для создания сообщения или добавления комментария, и выполнять любые операции, такие как вход или выход пользователя, отправка электронных писем, ведение журнала, аналитика и т. д. и так далее. Ограничений нет: любая функциональность, предоставляемая базовой CMS, может быть вызвана через модуль — на любом уровне.
В иерархию компонентов мы можем добавить любое количество модулей, и каждый модуль может выполнять свою собственную операцию. Следовательно, не все операции обязательно должны быть связаны с ожидаемым действием запроса, как при выполнении операции POST, PUT или DELETE в REST или отправке мутации в GraphQL, но могут быть добавлены для предоставления дополнительных функций, таких как отправка электронной почты. администратору, когда пользователь создает новый пост.
Таким образом, определяя иерархию компонентов через внедрение зависимостей или файлы конфигурации, можно сказать, что API поддерживает аспектно-ориентированное программирование, «парадигму программирования, которая направлена на повышение модульности за счет разделения сквозных задач».
Рекомендуемая литература : Защита вашего сайта с помощью политики функций
Повышенная безопасность
Имена модулей не обязательно фиксируются при печати в выводе, но могут быть сокращены, искажены, изменены случайным образом или (короче говоря) изменены любым образом. Хотя изначально предполагалось сократить вывод API (чтобы имена модулей carousel-featured-posts или drag-and-drop-user-images можно было сократить до базовой нотации 64, такой как a1 , a2 и т. д., для производственной среды ), эта функция позволяет часто менять имена модулей в ответе от API из соображений безопасности.
Например, имена входов по умолчанию именуются как соответствующие им модули; затем модули с именем username и password , которые должны отображаться в клиенте как <input type="text" name="{input_name}"> и <input type="password" name="{input_name}"> соответственно, могут быть установлены различные случайные значения для их входных имен (например, zwH8DSeG и QBG7m6EF сегодня, а c3oMLBjo и c46oVgN6 завтра), что затрудняет нацеливание на сайт спамерам и ботам.
Универсальность благодаря альтернативным моделям
Вложенность модулей позволяет перейти к другому модулю, чтобы добавить совместимость для определенного носителя или технологии или изменить некоторые стили или функциональные возможности, а затем вернуться к исходной ветви.
Например, предположим, что веб-страница имеет следующую структуру:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" В этом случае мы хотели бы, чтобы веб-сайт также работал для AMP, однако модули module2 , module4 и module5 с AMP. Мы можем разветвить эти модули на похожие, совместимые с AMP модули module2AMP , module4AMP и module5AMP , после чего мы продолжаем загружать исходную иерархию компонентов, поэтому тогда заменяются только эти три модуля (и ничего больше):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"Это позволяет довольно легко генерировать разные выходные данные из одной кодовой базы, добавляя ответвления только здесь и там по мере необходимости, и всегда ограничивая область действия и отдельные модули.
Время демонстрации
Код, реализующий API, описанный в этой статье, доступен в этом репозитории с открытым исходным кодом.
Я развернул PoP API по https://nextapi.getpop.org в демонстрационных целях. Веб-сайт работает на WordPress, поэтому постоянные URL-ссылки типичны для WordPress. Как отмечалось ранее, при добавлении к ним параметра output=json эти URL-адреса становятся их собственными конечными точками API.
Сайт поддерживается той же базой данных, что и демонстрационный веб-сайт PoP, поэтому визуализацию иерархии компонентов и полученных данных можно выполнить, запросив тот же URL-адрес на этом другом веб-сайте (например, посетив https://demo.getpop.org/u/leo/ ). https://demo.getpop.org/u/leo/ объясняет данные с https://nextapi.getpop.org/u/leo/?output=json ).
Ссылки ниже демонстрируют API для случаев, описанных ранее:
- Домашняя страница, отдельный пост, автор, список постов и список пользователей.
- Событие, фильтрация из определенного модуля.
- Тег, фильтрующий модули, которым требуется состояние пользователя, и фильтрующий, чтобы получить только страницу из одностраничного приложения.
- Массив местоположений для ввода в ввод.
- Альтернативные модели страницы «Кто мы?»: Обычная, Печатная, Встраиваемая.
- Изменение названий модулей: оригинальные vs искаженные.
- Фильтрация информации: только настройки модуля, данные модуля плюс данные базы данных.
Заключение
Хороший API — это ступенька к созданию надежных, простых в сопровождении и мощных приложений. В этой статье я описал концепции, лежащие в основе основанного на компонентах API, который, как мне кажется, является довольно хорошим API, и я надеюсь, что убедил и вас.
На данный момент разработка и реализация API включала в себя несколько итераций и заняла более пяти лет — и он еще не полностью готов. Тем не менее, он находится в довольно приличном состоянии, не готов к производству, а является стабильной альфой. В эти дни я все еще работаю над этим; работа над определением открытой спецификации, реализация дополнительных слоев (таких как рендеринг) и написание документации.
В следующей статье я опишу, как работает моя реализация API. До тех пор, если у вас есть какие-либо мысли по этому поводу — независимо от того, положительные они или отрицательные — я хотел бы прочитать ваши комментарии ниже.
Обновление (31 января): возможности пользовательских запросов
Ален Шлессер прокомментировал, что API, который нельзя запросить у клиента, бесполезен, возвращая нас к SOAP, поскольку он не может конкурировать ни с REST, ни с GraphQL. После его комментария несколько дней размышлений я должен был признать, что он прав. Однако вместо того, чтобы отмахиваться от API на основе компонентов как от благих намерений, но еще не доведенных до конца усилий, я сделал кое-что гораздо лучше: я реализовал для него возможность пользовательских запросов. И это работает как шарм!
В следующих ссылках данные для ресурса или набора ресурсов извлекаются, как обычно, через REST. Однако с помощью fields параметров мы также можем указать, какие конкретные данные следует извлекать для каждого ресурса, избегая избыточной или недостаточной выборки данных:
- Один пост и набор постов с добавлением параметров
fields=title,content,datetime - Пользователь и набор пользователей, добавляющих параметры
fields=name,username,description
Приведенные выше ссылки демонстрируют получение данных только для запрошенных ресурсов. А как насчет их отношений? Например, предположим, что мы хотим получить список сообщений с полями "title" и "content" , комментарии каждого сообщения с полями "content" и "date" и автора каждого комментария с полями "name" и "url" . Чтобы добиться этого в GraphQL, мы реализовали бы следующий запрос:
query { post { title content comments { content date author { name url } } } } Для реализации API на основе компонентов я перевел запрос в соответствующее ему выражение «точечный синтаксис», которое затем можно передать через fields параметров. При запросе ресурса «post» это значение:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url Или его можно упростить, используя | чтобы сгруппировать все поля, применяемые к одному и тому же ресурсу:
fields=title|content,comments.content|date,comments.author.name|urlПри выполнении этого запроса на одном посте мы получаем именно те данные, которые требуются для всех задействованных ресурсов:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Следовательно, мы можем запрашивать ресурсы в стиле REST и задавать запросы на основе схемы в стиле GraphQL, и мы получим именно то, что требуется, без избыточной или недостаточной выборки данных и нормализуя данные в базе данных, чтобы данные не дублировались. Предпочтительно, запрос может включать любое количество взаимосвязей, глубоко вложенных, и они разрешаются с линейным временем сложности: в худшем случае O(n+m), где n — количество узлов, которые переключают домен (в данном случае 2: comments и comments.author ), а m — количество полученных результатов (в данном случае 5: 1 сообщение + 2 комментария + 2 пользователя), а в среднем — O(n). (Это более эффективно, чем GraphQL, который имеет полиномиальное время сложности O(n^c) и страдает от увеличения времени выполнения по мере увеличения глубины уровня).
Наконец, этот API также может применять модификаторы при запросе данных, например, для фильтрации извлекаемых ресурсов, например, с помощью GraphQL. Для этого API просто размещается поверх приложения и может удобно использовать его функциональные возможности, поэтому нет необходимости изобретать велосипед. Например, добавление параметров filter=posts&searchfor=internet отфильтрует все сообщения, содержащие слово "internet" , из коллекции сообщений.
Реализация этой новой функции будет описана в следующей статье.