
Преобразование изображения в текст с помощью React и Tesseract.js (OCR)
Опубликовано: 2022-03-10Данные — это основа любого программного приложения, потому что основная цель приложения — решать человеческие проблемы. Для решения человеческих проблем необходимо иметь некоторую информацию о них.
Такая информация представляется в виде данных, особенно посредством вычислений. В Интернете данные в основном собираются в виде текстов, изображений, видео и многого другого. Иногда изображения содержат важные тексты, которые предназначены для обработки для достижения определенной цели. Эти изображения в основном обрабатывались вручную, потому что не было возможности обработать их программно.
Невозможность извлекать текст из изображений была ограничением обработки данных, с которым я столкнулся на собственном опыте в своей прошлой компании. Нам нужно было обработать отсканированные подарочные карты, и нам пришлось делать это вручную, так как мы не могли извлечь текст из изображений.
В компании был отдел под названием «Операции», который отвечал за ручное подтверждение подарочных карт и зачисление средств на счета пользователей. Хотя у нас был веб-сайт, через который пользователи связывались с нами, обработка подарочных карт осуществлялась вручную за кулисами.
В то время наш веб-сайт был создан в основном с использованием PHP (Laravel) для серверной части и JavaScript (jQuery и Vue) для внешнего интерфейса. Наш технический стек был достаточно хорош для работы с Tesseract.js при условии, что руководство считало проблему важной.
Я был готов решить проблему, но не было необходимости решать проблему с точки зрения бизнеса или руководства. Покинув компанию, я решил провести небольшое исследование и попытаться найти возможные решения. В конце концов, я открыл для себя OCR.
Что такое ОКР?
OCR расшифровывается как «Оптическое распознавание символов» или «Оптическое считывание символов». Он используется для извлечения текстов из изображений.
Эволюцию OCR можно проследить до нескольких изобретений, но Optophone, «Gismo», планшетный CCD-сканер, Newton MesssagePad и Tesseract являются основными изобретениями, которые выводят распознавание символов на новый уровень полезности.
Итак, зачем использовать OCR? Итак, оптическое распознавание символов решает множество проблем, одна из которых побудила меня написать эту статью. Я понял, что возможность извлекать текст из изображения обеспечивает множество возможностей, таких как:
- Регулирование
Каждая организация должна регулировать деятельность пользователей по тем или иным причинам. Регулирование может использоваться для защиты прав пользователей и защиты их от угроз или мошенничества.
Извлечение текстов из изображения позволяет организации обрабатывать текстовую информацию на изображении для регулирования, особенно когда изображения предоставляются некоторыми пользователями.
Например, регулирование количества текстов на изображениях, используемых для рекламы, как в Facebook, может быть достигнуто с помощью OCR. Кроме того, оптическое распознавание символов также позволяет скрывать конфиденциальный контент в Твиттере. - Возможность поиска
Поиск является одним из наиболее распространенных видов деятельности, особенно в Интернете. Алгоритмы поиска в основном основаны на манипулировании текстами. Благодаря оптическому распознаванию символов можно распознавать символы на изображениях и использовать их для предоставления пользователям релевантных изображений. Короче говоря, изображения и видео теперь доступны для поиска с помощью OCR. - Доступность
Наличие текста на изображениях всегда было проблемой для доступности, и это правило заключается в том, чтобы на изображении было мало текста. С помощью OCR программы чтения с экрана могут иметь доступ к текстам на изображениях, чтобы предоставить своим пользователям необходимый опыт. - Автоматизация обработки данных Обработка данных в основном автоматизирована для масштабирования. Наличие текстов на изображениях является ограничением для обработки данных, поскольку тексты можно обрабатывать только вручную. Оптическое распознавание символов (OCR) позволяет программно извлекать тексты из изображений, тем самым обеспечивая автоматизацию обработки данных, особенно когда речь идет об обработке текстов на изображениях.
- Оцифровка печатных материалов
Все становится цифровым, и еще много документов предстоит оцифровать. Чеки, сертификаты и другие физические документы теперь можно оцифровывать с помощью оптического распознавания символов.
Выяснение всех вышеперечисленных способов применения углубило мои интересы, поэтому я решил пойти дальше, задав вопрос:
«Как я могу использовать OCR в Интернете, особенно в приложении React?»
Этот вопрос привел меня к Tesseract.js.
Что такое Tesseract.js?
Tesseract.js — это библиотека JavaScript, которая компилирует исходный Tesseract из C в JavaScript WebAssembly, тем самым делая распознавание текста доступным в браузере. Движок Tesseract.js изначально был написан на ASM.js, а позже был портирован на WebAssembly, но ASM.js по-прежнему служит резервной копией в некоторых случаях, когда WebAssembly не поддерживается.
Как указано на сайте Tesseract.js, он поддерживает более 100 языков , автоматическую ориентацию текста и определение скрипта, простой интерфейс для чтения абзацев, слов и ограничивающих символов символов.
Tesseract — это механизм оптического распознавания символов для различных операционных систем. Это бесплатное программное обеспечение, выпущенное под лицензией Apache. Hewlett-Packard разработала Tesseract как проприетарное программное обеспечение в 1980-х годах. Он был выпущен с открытым исходным кодом в 2005 году, а его разработка спонсируется Google с 2006 года.
Последняя версия Tesseract, версия 4, была выпущена в октябре 2018 года и содержит новый механизм распознавания текста, который использует систему нейронных сетей на основе долговременной кратковременной памяти (LSTM) и предназначен для получения более точных результатов.
Понимание API Tesseract
Чтобы действительно понять, как работает Tesseract, нам нужно разобрать некоторые его API и их компоненты. Согласно документации Tesseract.js, есть два способа его использования. Ниже приведен первый подход и его разбивка:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } Метод recognize принимает изображение в качестве первого аргумента, язык (которого может быть несколько) в качестве второго аргумента и { logger: m => console.log(me) } в качестве последнего аргумента. Tesseract поддерживает следующие форматы изображений: jpg, png, bmp и pbm, которые могут быть предоставлены только в виде элементов (img, видео или холст), файлового объекта ( <input> ), объекта blob, пути или URL-адреса изображения и изображения в кодировке base64. . (Читайте здесь для получения дополнительной информации обо всех форматах изображений, которые может обрабатывать Tesseract.)
Язык предоставляется в виде строки, такой как eng . Знак + можно использовать для объединения нескольких языков, как в eng+chi_tra . Аргумент языка используется для определения обученных языковых данных, которые будут использоваться при обработке изображений.
Примечание . Здесь вы найдете все доступные языки и их коды.
{ logger: m => console.log(m) } очень полезен для получения информации о ходе обработки изображения. Свойство logger принимает функцию, которая будет вызываться несколько раз, когда Tesseract обрабатывает изображение. Параметром функции регистратора должен быть объект со workerId , jobId , status и progress :
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress — это число от 0 до 1, выраженное в процентах, чтобы показать ход процесса распознавания изображений.
Tesseract автоматически генерирует объект в качестве параметра функции регистратора, но его также можно указать вручную. В процессе распознавания свойства объекта logger обновляются каждый раз при вызове функции . Таким образом, его можно использовать для отображения индикатора выполнения преобразования, изменения какой-либо части приложения или для достижения любого желаемого результата.
result в приведенном выше коде является результатом процесса распознавания изображения. Каждое из свойств result имеет свойство bbox как координаты x/y их ограничивающей рамки.
Вот свойства объекта result , их значения или использование:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: Весь распознанный текст в виде строки. -
lines: Массив каждой распознанной строки за строкой текста. -
words: Массив всех распознанных слов. -
symbols: Массив каждого из распознанных символов. -
paragraphs: Массив каждого распознанного абзаца. Мы собираемся обсудить «уверенность» позже в этой статье.
Tesseract также может использоваться более императивно, например:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Этот подход связан с первым подходом, но с другими реализациями.
createWorker(options) создает рабочий веб-процесс или дочерний процесс узла, который создает рабочий процесс Tesseract. Работник помогает настроить механизм распознавания текста Tesseract. Метод load() загружает базовые сценарии Tesseract, loadLanguage() загружает любой предоставленный ему язык в виде строки, initialize() проверяет, что Tesseract полностью готов к использованию, а затем метод распознавания используется для обработки предоставленного изображения. Метод terminate() останавливает рабочий процесс и очищает все.
Примечание . Дополнительные сведения см. в документации по Tesseract API.
Теперь нам нужно что-то создать, чтобы действительно увидеть, насколько эффективен Tesseract.js.
Что мы собираемся строить?
Мы собираемся создать экстрактор PIN-кода подарочной карты, потому что извлечение PIN-кода из подарочной карты было проблемой, которая в первую очередь привела к этому писательскому приключению.
Мы создадим простое приложение, которое извлекает ПИН-код из отсканированной подарочной карты . Поскольку я намеревался создать простой экстрактор булавок для подарочных карт, я расскажу вам о некоторых проблемах, с которыми я столкнулся на этом пути, решениях, которые я предоставил, и моем выводе, основанном на моем опыте.
- Перейти к исходному коду →
Ниже приведено изображение, которое мы собираемся использовать для тестирования, поскольку оно обладает некоторыми реалистичными свойствами, которые возможны в реальном мире.

Извлечем AQUX-QWMB6L-R6JAU с карты. Итак, приступим.
Установка React и Tesseract
Перед установкой React и Tesseract.js нужно обратить внимание на вопрос, зачем использовать React с Tesseract? На практике мы можем использовать Tesseract с ванильным JavaScript, любыми библиотеками JavaScript или фреймворками, такими как React, Vue и Angular.
Использование React в этом случае является личным предпочтением. Изначально я хотел использовать Vue, но решил использовать React, потому что я больше знаком с React, чем с Vue.
Теперь продолжим установку.
Чтобы установить React с помощью create-react-app, вам нужно запустить следующий код:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsили
npm install tesseract.jsЯ решил использовать пряжу для установки Tesseract.js, потому что мне не удалось установить Tesseract с npm, но пряжа справилась со своей задачей без стресса. Вы можете использовать npm, но я рекомендую установить Tesseract с пряжей, исходя из моего опыта.
Теперь давайте запустим наш сервер разработки, запустив код ниже:
yarn startили
npm startПосле запуска yarn start или npm start ваш браузер по умолчанию должен открыть веб-страницу, как показано ниже:

Вы также можете перейти на localhost:3000 в браузере, если страница не запускается автоматически.
Что дальше после установки React и Tesseract.js?
Настройка формы загрузки
В этом случае мы настроим домашнюю страницу (App.js), которую мы только что просматривали в браузере, чтобы она содержала нужную нам форму:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App Часть вышеприведенного кода, которая требует нашего внимания, — это функция handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } В этой функции URL.createObjectURL берет выбранный файл через event.target.files[0] и создает ссылочный URL-адрес, который можно использовать с тегами HTML, такими как img, аудио и видео. Мы использовали setImagePath , чтобы добавить URL-адрес в состояние. Теперь к URL-адресу можно получить доступ с помощью imagePath .
<img src={imagePath} className="App-logo" alt="image"/> Мы устанавливаем для атрибута src изображения значение {imagePath} , чтобы просмотреть его в браузере перед обработкой.
Преобразование выбранных изображений в текст
Поскольку мы получили путь к выбранному изображению, мы можем передать путь к изображению в Tesseract.js, чтобы извлечь из него тексты.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppМы добавляем функцию «handleClick» в «App.js», и она содержит API Tesseract.js, который получает путь к выбранному изображению. Tesseract.js принимает «imagePath», «язык», «объект настройки».
Кнопка ниже добавлена в форму для вызова «handClick», который запускает преобразование изображения в текст при каждом нажатии кнопки.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Когда обработка прошла успешно, мы получаем доступ как к «достоверности», так и к «тексту» из результата. Затем мы добавляем «текст» в состояние с помощью «setText (текст)».
Добавляя к <p> {text} </p> , мы отображаем извлеченный текст.
Очевидно, что «текст» извлекается из изображения, но что такое уверенность?
Уверенность показывает, насколько точна конверсия. Уровень достоверности находится в диапазоне от 1 до 100. 1 означает наихудшее значение, а 100 — наилучшее с точки зрения точности. Его также можно использовать для определения того, следует ли считать извлеченный текст точным или нет.
Тогда возникает вопрос, какие факторы могут повлиять на показатель достоверности или точность всего преобразования? В основном на него влияют три основных фактора: качество и характер используемого документа, качество скана, созданного из документа, и возможности обработки движка Tesseract.
Теперь давайте добавим приведенный ниже код в «App.css», чтобы немного придать стилю приложению.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Вот результат моего первого теста :
Результат в Firefox
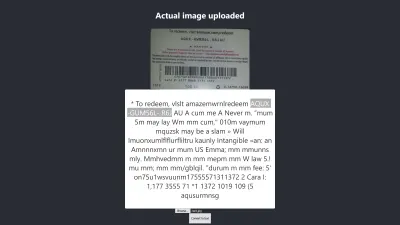
Уровень достоверности приведенного выше результата равен 64. Стоит отметить, что изображение подарочной карты имеет темный цвет, и это определенно влияет на результат, который мы получаем.

Если вы внимательно посмотрите на изображение выше, вы увидите, что пин-код от карты почти точен в извлеченном тексте. Это не точно, потому что подарочная карта не совсем ясна.
О, подождите! Как это будет выглядеть в Chrome?
Результат в Chrome
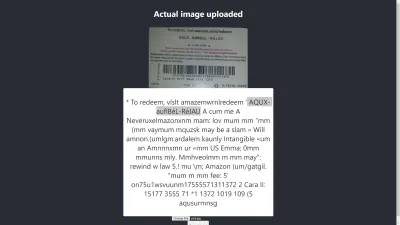
Ах! Результат еще хуже в Chrome. Но почему результат в Chrome отличается от Mozilla Firefox? Разные браузеры по-разному обрабатывают изображения и их цветовые профили. Это означает, что изображение может отображаться по-разному в зависимости от браузера . Предоставление Tesseract предварительно обработанных image.data может привести к разным результатам в разных браузерах, поскольку в Tesseract передаются разные image.data в зависимости от используемого браузера. Предварительная обработка изображения, как мы увидим далее в этой статье, поможет добиться стабильного результата.
Нам нужно быть более точными, чтобы мы могли быть уверены, что получаем или предоставляем правильную информацию. Так что мы должны пойти немного дальше.
Давайте попробуем еще, чтобы увидеть, сможем ли мы достичь цели в конце.
Тестирование на точность
На преобразование изображения в текст с помощью Tesseract.js влияет множество факторов. Большинство из этих факторов связаны с характером изображения, которое мы хотим обработать, а остальные зависят от того, как движок Tesseract обрабатывает преобразование.
Внутри Tesseract предварительно обрабатывает изображения перед фактическим преобразованием OCR, но это не всегда дает точные результаты.
В качестве решения мы можем предварительно обработать изображения для достижения точных преобразований. Мы можем бинаризировать, инвертировать, расширять, выравнивать или масштабировать изображение, чтобы предварительно обработать его для Tesseract.js.
Предварительная обработка изображений — это большая работа или обширная область сама по себе. К счастью, P5.js предоставляет все методы предварительной обработки изображений, которые мы хотим использовать. Вместо того, чтобы изобретать велосипед или использовать всю библиотеку только потому, что мы хотим использовать крошечную ее часть, я скопировал те, которые нам нужны. Все методы предварительной обработки изображений включены в preprocess.js.
Что такое бинаризация?
Бинаризация — это преобразование пикселей изображения в черный или белый цвет. Мы хотим бинаризировать предыдущую подарочную карту, чтобы проверить, будет ли точность лучше или нет.
Раньше мы извлекали некоторые тексты из подарочной карты, но целевой PIN-код был не таким точным, как хотелось бы. Поэтому необходимо найти другой способ получить точный результат.
Теперь мы хотим преобразовать подарочную карту в бинарную форму, т. е. преобразовать ее пиксели в черно-белые, чтобы увидеть, можно ли достичь более высокого уровня точности или нет.
Приведенные ниже функции будут использоваться для бинаризации и включены в отдельный файл с именем preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageЧто делает приведенный выше код?
Мы представляем холст для хранения данных изображения для применения некоторых фильтров, для предварительной обработки изображения перед передачей его в Tesseract для преобразования.
Первая функция preprocessImage находится в файле preprocess.js и подготавливает холст к использованию, получая его пиксели. Функция thresholdFilter бинаризирует изображение, преобразовывая его пиксели либо в черный, либо в белый цвет .
Давайте вызовем preprocessImage , чтобы узнать, может ли текст, извлеченный из предыдущей подарочной карты, быть более точным.
К тому времени, когда мы обновим App.js, он должен выглядеть следующим образом:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppВо-первых, мы должны импортировать «preprocessImage» из «preprocess.js» с помощью кода ниже:
import preprocessImage from './preprocess'; Затем мы добавляем тег холста в форму. Мы устанавливаем атрибут ref тегов canvas и img на { canvasRef } и { imageRef } соответственно. Ссылки используются для доступа к холсту и изображению из компонента приложения. Мы получаем как холст, так и изображение с помощью «useRef», как в:
const canvasRef = useRef(null); const imageRef = useRef(null);В этой части кода мы объединяем изображение с холстом, поскольку мы можем предварительно обработать холст только в JavaScript. Затем мы конвертируем его в URL-адрес данных с «jpeg» в качестве формата изображения.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");«dataUrl» передается Tesseract как изображение для обработки.
Теперь давайте проверим, будет ли извлеченный текст более точным.
Тест №2

На изображении выше показан результат в Firefox. Очевидно, что темная часть изображения была изменена на белую, но предварительная обработка изображения не приводит к более точному результату. Это еще хуже.
В первом преобразовании есть только два неправильных символа , а в этом — четыре неправильных символа. Я даже пытался изменить пороговый уровень, но безрезультатно. Мы не получаем лучшего результата не потому, что бинаризация плохая, а потому, что бинаризация изображения не исправляет природу изображения способом, подходящим для движка Tesseract.
Давайте проверим, как это выглядит в Chrome:

Получаем тот же результат.
После получения худшего результата путем бинаризации изображения необходимо проверить другие методы предварительной обработки изображения, чтобы увидеть, можем ли мы решить проблему или нет. Итак, мы собираемся попробовать расширение, инверсию и размытие.
Давайте просто возьмем код для каждого из методов из P5.js, который используется в этой статье. Мы добавим методы обработки изображений в preprocess.js и будем использовать их один за другим. Перед их использованием необходимо понять каждый из методов предварительной обработки изображений, которые мы хотим использовать, поэтому мы собираемся обсудить их в первую очередь.
Что такое дилатация?
Расширение — это добавление пикселей к границам объектов на изображении, чтобы сделать его шире, больше или более открытым. Техника «расширения» используется для предварительной обработки наших изображений, чтобы увеличить яркость объектов на изображениях. Нам нужна функция для расширения изображений с помощью JavaScript, поэтому фрагмент кода для расширения изображения добавлен в preprocess.js.
Что такое размытие?
Размытие — это сглаживание цветов изображения за счет снижения его резкости. Иногда на изображениях появляются небольшие точки/пятна. Чтобы удалить эти пятна, мы можем размыть изображения. Фрагмент кода для размытия изображения включен в preprocess.js.
Что такое инверсия?
Инверсия — это преобразование светлых участков изображения в темные, а темных — в светлые. Например, если изображение имеет черный фон и белый передний план, мы можем инвертировать его так, чтобы его фон был белым, а передний план — черным. Мы также добавили фрагмент кода для инвертирования изображения в preprocess.js.
После добавления dilate , invertColors и blurARGB в «preprocess.js» теперь мы можем использовать их для предварительной обработки изображений. Чтобы их использовать, нам нужно обновить исходную функцию «preprocessImage» в preprocess.js:
preprocessImage(...) теперь выглядит так:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } В приведенном выше preprocessImage мы применяем к изображению четыре метода предварительной обработки: blurARGB() для удаления точек на изображении, dilate() для увеличения яркости изображения, invertColors() для переключения цвета переднего плана и фона изображения и thresholdFilter() . thresholdFilter() , чтобы преобразовать изображение в черно-белое, что больше подходит для преобразования Tesseract.
thresholdFilter() принимает image.data и level в качестве параметров. level используется для установки того, насколько белым или черным должно быть изображение. Мы определили уровень thresholdFilter фильтра и радиус blurRGB методом проб и ошибок, поскольку не уверены, насколько белым, темным или гладким должно быть изображение, чтобы Tesseract давал отличный результат.
Тест №3
Вот новый результат после применения четырех техник:

Изображение выше представляет результат, который мы получаем как в Chrome, так и в Firefox.
Ой! Исход ужасный.
Вместо того, чтобы использовать все четыре метода, почему бы нам просто не использовать два из них одновременно?
Да! Мы можем просто использовать invertColors и thresholdFilter , чтобы преобразовать изображение в черно-белое и поменять местами передний план и фон изображения. Но откуда нам знать, что и какие приемы комбинировать? Мы знаем, что комбинировать, исходя из характера изображения, которое мы хотим предварительно обработать.
Например, цифровое изображение должно быть преобразовано в черно-белое, а изображение с пятнами должно быть размыто, чтобы удалить точки/пятна. Что действительно важно, так это понять, для чего используется каждый из методов.
Чтобы использовать invertColors и thresholdFilter , нам нужно закомментировать как blurARGB , так и dilate в preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Тест №4
А теперь новый результат:

Результат все равно хуже, чем без предварительной обработки. После настройки каждого из методов для этого конкретного изображения и некоторых других изображений я пришел к выводу, что изображения с разным характером требуют разных методов предварительной обработки.
Короче говоря, использование Tesseract.js без предварительной обработки изображения дало лучший результат для подарочной карты выше. Все остальные эксперименты с предварительной обработкой изображений дали менее точные результаты.
Проблема
Первоначально я хотел извлечь ПИН-код из любой подарочной карты Amazon, но не смог этого сделать, потому что нет смысла сопоставлять несовместимый ПИН-код, чтобы получить согласованный результат. Хотя можно обработать изображение для получения точного PIN-кода, такая предварительная обработка будет несовместимой к тому времени, когда будет использоваться другое изображение другой природы.
Лучший результат
Изображение ниже демонстрирует наилучший результат, полученный в ходе экспериментов.
Тест №5

Тексты на изображении и извлеченные полностью совпадают. Преобразование имеет 100% точность. Я попытался воспроизвести результат, но смог воспроизвести его только при использовании изображений с похожей природой.
Наблюдение и уроки
- Некоторые изображения, не прошедшие предварительную обработку, могут давать разные результаты в разных браузерах . Это утверждение очевидно в первом тесте. Результат в Firefox отличается от результата в Chrome. Однако предварительная обработка изображений помогает добиться стабильного результата в других тестах.
- Черный цвет на белом фоне, как правило, дает управляемые результаты. Изображение ниже — пример точного результата без какой-либо предварительной обработки . Я также смог получить тот же уровень точности, предварительно обработав изображение, но мне потребовалось много настроек, которые были ненужными.
Преобразование является 100% точным.
- Текст с большим размером шрифта имеет тенденцию быть более точным.
- Шрифты с изогнутыми краями могут сбить с толку Tesseract. Наилучший результат, который я получил, был достигнут, когда я использовал Arial (шрифт).
- OCR в настоящее время недостаточно хорош для автоматического преобразования изображения в текст, особенно когда требуется уровень точности более 80%. Однако его можно использовать, чтобы сделать ручную обработку текстов на изображениях менее напряженной , извлекая тексты для ручной коррекции.
- OCR в настоящее время недостаточно хорош, чтобы передавать полезную информацию программам чтения с экрана для обеспечения доступности . Предоставление неточной информации программе чтения с экрана может легко ввести пользователей в заблуждение или отвлечь их.
- OCR очень перспективен, поскольку нейронные сети позволяют учиться и совершенствоваться. Благодаря глубокому обучению в ближайшем будущем OCR изменит правила игры .
- Принятие решений с уверенностью. Оценка достоверности может использоваться для принятия решений, которые могут сильно повлиять на наши приложения. Оценка достоверности может использоваться для определения того, следует ли принять или отклонить результат. Из своего опыта и экспериментов я понял, что любой показатель достоверности ниже 90 не очень полезен. Если мне нужно извлечь из текста только несколько булавок, я ожидаю, что показатель достоверности будет находиться в диапазоне от 75 до 100, а все, что ниже 75, будет отклонено .
В случае, если я имею дело с текстами без необходимости извлечения какой-либо его части, я определенно приму оценку достоверности от 90 до 100, но отклоню любую оценку ниже этой. Например, ожидается точность 90 и выше, если я хочу оцифровать такие документы, как чеки, исторический черновик или всякий раз, когда необходима точная копия. Но оценка от 75 до 90 приемлема, когда точная копия не важна, например, для получения PIN-кода с подарочной карты. Короче говоря, оценка достоверности помогает принимать решения , влияющие на наши приложения.
Заключение
Учитывая ограничения обработки данных, вызванные текстами на изображениях, и связанные с этим недостатки, оптическое распознавание символов (OCR) является полезной технологией. Хотя OCR имеет свои ограничения, оно очень перспективно из-за использования нейронных сетей.
Со временем OCR преодолеет большинство своих ограничений с помощью глубокого обучения, но до этого подходы, описанные в этой статье, можно использовать для извлечения текста из изображений, по крайней мере, чтобы уменьшить трудности и потери, связанные с ручным обработки — особенно с точки зрения бизнеса.
Теперь ваша очередь попробовать OCR для извлечения текста из изображений. Удачи!
Дальнейшее чтение
- P5.js
- Предварительная обработка в OCR
- Улучшение качества продукции
- Использование JavaScript для предварительной обработки изображений для OCR
- OCR в браузере с Tesseract.js
- Краткая история оптического распознавания символов
- Будущее OCR — это глубокое обучение
- Хронология оптического распознавания символов