
Классификация изображений в CNN: все, что вам нужно знать
Опубликовано: 2021-02-25Оглавление
Введение
Просматривая ленту Facebook, задумывались ли вы когда-нибудь, как программное обеспечение Facebook автоматически помечает людей на групповой фотографии? За каждым интерактивным пользовательским интерфейсом Facebook, который вы видите, стоит сложный и надежный алгоритм, который используется для распознавания и маркировки каждой картинки, которую мы загружаем на платформу социальной сети. Каждой своей картинкой мы только помогаем повысить эффективность алгоритма. Да, классификация изображений — один из наиболее широко используемых алгоритмов, в которых мы видим применение искусственного интеллекта.
В последнее время сверточные нейронные сети (CNN) стали одним из самых сильных сторонников глубокого обучения. Одним из популярных приложений этих сверточных сетей является классификация изображений. В этом руководстве мы рассмотрим основы сверточных нейронных сетей, увидим различные слои, участвующие в построении модели CNN, и, наконец, визуализируем пример задачи классификации изображений.
Классификация изображений
Прежде чем мы углубимся в детали глубокого обучения и сверточных нейронных сетей, давайте разберемся с основами классификации изображений. В общем, классификация изображений определяется как задача, в которой мы даем изображение в качестве входных данных для модели, построенной с использованием определенного алгоритма, который выводит класс или вероятность класса, к которому принадлежит изображение. Этот процесс, в котором мы присваиваем изображению определенный класс, называется контролируемым обучением.
Существует огромная разница между тем, как мы видим изображение, и тем, как его видит машина (компьютер). Для нас мы можем визуализировать изображение и охарактеризовать его на основе цвета и размера. С другой стороны, машина видит только числа. Видимые числа называются пикселями.
Каждый пиксель имеет значение от 0 до 255. Следовательно, с этими числовыми данными машине требуются некоторые шаги предварительной обработки, чтобы получить определенные шаблоны или функции, которые отличают одно изображение от другого. Сверточные нейронные сети помогают нам создавать алгоритмы, способные извлекать определенный шаблон из изображений.
Что мы видим против того, что видит компьютер
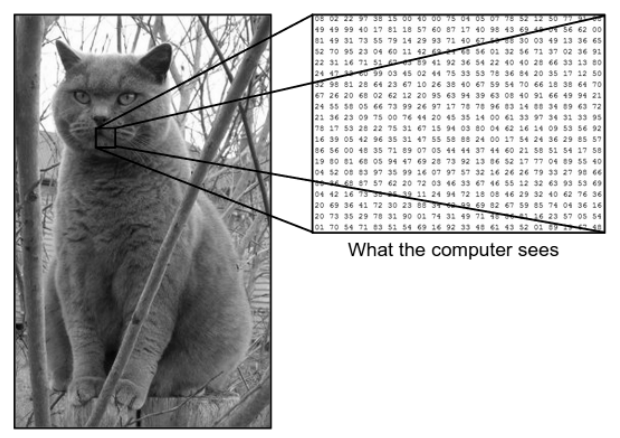 Источник - разница между компьютером и человеческим глазом
Источник - разница между компьютером и человеческим глазом

Глубокое обучение для классификации изображений
Теперь, когда мы поняли, что такое классификация изображений, давайте теперь посмотрим, как мы можем реализовать ее с помощью искусственного интеллекта. Для этого мы используем популярные методы Deep Learning. Глубокое обучение — это подмножество искусственного интеллекта, которое использует большие наборы данных изображений для распознавания и извлечения шаблонов из различных изображений, чтобы различать различные классы, присутствующие в наборе данных изображений.
Основная проблема, с которой сталкивается глубокое обучение, заключается в том, что для огромной базы данных требуется очень много времени и высокая вычислительная стоимость. Однако сверточные нейронные сети, которые являются типом алгоритма глубокого обучения, хорошо решают эту проблему.
Сверточные нейронные сети
В глубоком обучении сверточные нейронные сети представляют собой класс глубоких нейронных сетей, которые в основном используются в визуальных образах. Они представляют собой особую архитектуру искусственных нейронных сетей (ИНС), предложенную в 1998 году Яном ЛеКуном. Сверточные нейронные сети состоят из двух частей.
Первая часть состоит из сверточных слоев и объединенных слоев, в которых происходит основной процесс извлечения признаков. Во второй части слои Fully Connected и Dense выполняют несколько нелинейных преобразований извлеченных признаков и действуют как часть классификатора. Изучите CNN для классификации изображений.
Рассмотрим показанный выше пример изображения того, что видят человек и машина. Как видим, компьютер видит массив пикселей. Например, если размер изображения 500х500, то размер массива будет 500х500х3. Здесь 500 обозначает каждую высоту и ширину, 3 — канал RGB, где каждый цветовой канал представлен отдельным массивом. Интенсивность пикселей варьируется от 0 до 255.
Теперь для классификации изображений компьютер будет искать функции на базовом уровне. По нашему мнению, эти базовые черты кошки — это уши, нос и бакенбарды. В то время как для компьютера этими функциями базового уровня являются кривизны и границы. Таким образом, используя несколько разных слоев, таких как сверточные слои и объединяющие слои, компьютер извлекает из изображений функции базового уровня.
В модели сверточной нейронной сети существует несколько типов слоев, таких как:
- Входной слой
- Сверточный слой
- Объединение слоев
- Полностью подключенный слой
- Выходной слой
- Функции активации
Давайте кратко рассмотрим каждый из слоев, прежде чем мы перейдем к его применению в классификации изображений.
Входной слой
Из названия мы понимаем, что это слой, в котором входное изображение будет подаваться в модель CNN. В зависимости от наших требований мы можем изменить изображение до разных размеров, например (28,28,3)
Сверточный слой
Затем идет самый важный слой, который состоит из фильтра (также известного как ядро) с фиксированным размером. Математическая операция свертки выполняется между входным изображением и фильтром. Это этап, на котором из изображения извлекается большинство базовых функций, таких как острые края и кривые, поэтому этот слой также известен как слой извлечения функций.
Объединение слоев
После выполнения операции свертки мы выполняем операцию объединения. Это также известно как субдискретизация, при которой пространственный объем изображения уменьшается. Например, если мы выполним операцию объединения с шагом 2 на изображении размером 28×28, то размер изображения, уменьшенный до 14×14, уменьшится до половины исходного размера.
Полностью подключенный слой
Полносвязный слой (FC) размещается непосредственно перед выходом окончательной классификации модели CNN. Эти слои используются для выравнивания результатов перед классификацией. Он включает в себя несколько смещений, весов и нейронов. Присоединение слоя FC перед классификацией приводит к N-мерному вектору, где N — количество классов, из которых модель должна выбрать класс.
Выходной слой
Наконец, выходной слой состоит из метки, которая в основном кодируется с использованием метода горячего кодирования.
Функция активации
Эти функции активации являются ядром любой модели сверточной нейронной сети. Эти функции используются для определения выходных данных нейронной сети. Короче говоря, он определяет, должен ли конкретный нейрон быть активирован («запущен») или нет. Обычно это нелинейные функции, которые выполняются над входными сигналами. Этот преобразованный вывод затем отправляется в качестве входных данных для следующего слоя нейронов. Существует несколько функций активации, таких как Sigmoid, ReLU, Leaky ReLU, TanH и Softmax.
Базовая архитектура CNN
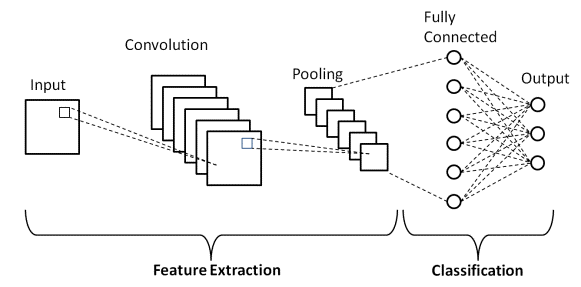
Источник : Базовая архитектура CNN.
Как было определено ранее, показанная выше диаграмма представляет собой базовую архитектуру модели сверточной нейронной сети. Теперь, когда мы знакомы с основами классификации изображений и CNN, давайте теперь погрузимся в их применение с проблемой реального времени. Узнайте больше об базовой архитектуре CNN.
Реализация сверточных нейронных сетей
Теперь, когда мы поняли основы классификации изображений и сверточных нейронных сетей, давайте визуализируем их реализацию в TensorFlow/Keras с кодированием Python. В этом мы построим простую модель сверточной нейронной сети с базовой архитектурой LeNet, обучим модель на обучающем наборе и тестовом наборе и, наконец, получим точность модели на данных тестового набора.
Набор проблем
В этой статье для построения и обучения модели сверточной нейронной сети мы будем использовать известный набор данных Fashion MNIST. MNIST расшифровывается как модифицированный национальный институт стандартов и технологий. Fashion-MNIST — это набор изображений статей Zalando, состоящий из обучающего набора из 60 000 примеров и тестового набора из 10 000 примеров. Каждый пример представляет собой изображение в градациях серого 28×28, связанное с меткой из 10 классов.

Каждому обучающему и тестовому примеру назначается одна из следующих меток:
0 – футболка/топ
1 — Брюки
2 – Пуловер
3 — Платье
4 — Пальто
5 — Сандалии
6 — Рубашка
7 – Кроссовки
8 – Сумка
9 – Ботильоны
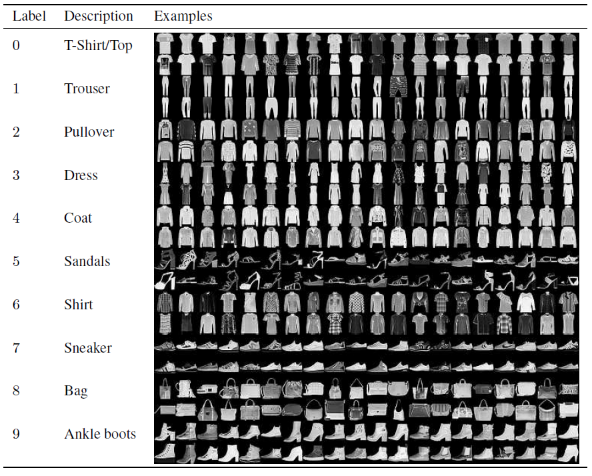
Источник : набор данных Fashion MNIST.
Код программы
Шаг 1 – Импорт библиотек
Первым шагом к построению любой модели глубокого обучения является импорт библиотек, необходимых для программы. В нашем примере, поскольку мы используем структуру TensorFlow, мы импортируем библиотеку Keras, а также другие важные библиотеки, такие как число для расчета и matplotlib для построения графиков.
#TensorFlow — импорт библиотек
импортировать numpy как np
импортировать matplotlib.pyplot как plt
%matplotlib встроенный
импортировать тензорный поток как tf
из тензорного импорта Keras
Шаг 2 — Получение и разделение набора данных
После того, как мы импортировали библиотеки, следующим шагом будет загрузка набора данных и разделение набора данных Fashion MNIST на соответствующие 60 000 обучающих и 10 000 тестовых данных. К счастью, keras предоставляет нам предопределенную функцию для импорта набора данных Fashion MNIST, и мы можем разделить их в следующей строке, используя простую строку кода, которая сама понимается.
#TensorFlow — получение и разделение набора данных
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
Шаг 3 – Визуализация данных
Поскольку набор данных загружается вместе с изображениями и соответствующими им метками, чтобы сделать их более понятными для пользователя, всегда рекомендуется просматривать данные, чтобы мы могли понять тип данных, с которыми мы имеем дело при построении сверточной нейронной сети. Сетевая модель соответственно. Здесь, с помощью этого простого блока кода, приведенного ниже, мы визуализируем первые 3 изображения набора обучающих данных, которые перемешиваются случайным образом.
#TensorFlow — визуализация данных
определение imshowTensorFlow (img):
plt.imshow(img, cmap='серый')
печать («Ярлык:», изображение [0])
imshowTensorFlow (train_images_tf [0])
Этикетка: 9 Этикетка: 0 Этикетка: 3
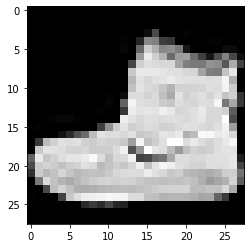


Приведенное выше изображение и его метки можно сверить с метками, которые указаны в деталях набора данных Fashion MNIST выше. Из этого мы делаем вывод, что наше изображение данных представляет собой изображение в градациях серого с высотой 28 пикселей и шириной 28 пикселей.
Следовательно, модель может быть построена с входным размером (28,28,1), где 1 означает изображение в градациях серого.
Шаг 4 – Построение модели
Как упоминалось выше, в этой статье мы будем строить простую свёрточную нейронную сеть с архитектурой LeNet. LeNet — это структура сверточной нейронной сети, предложенная Yann LeCun et al. в 1989 году. В общем, LeNet относится к LeNet-5 и представляет собой простую сверточную нейронную сеть.
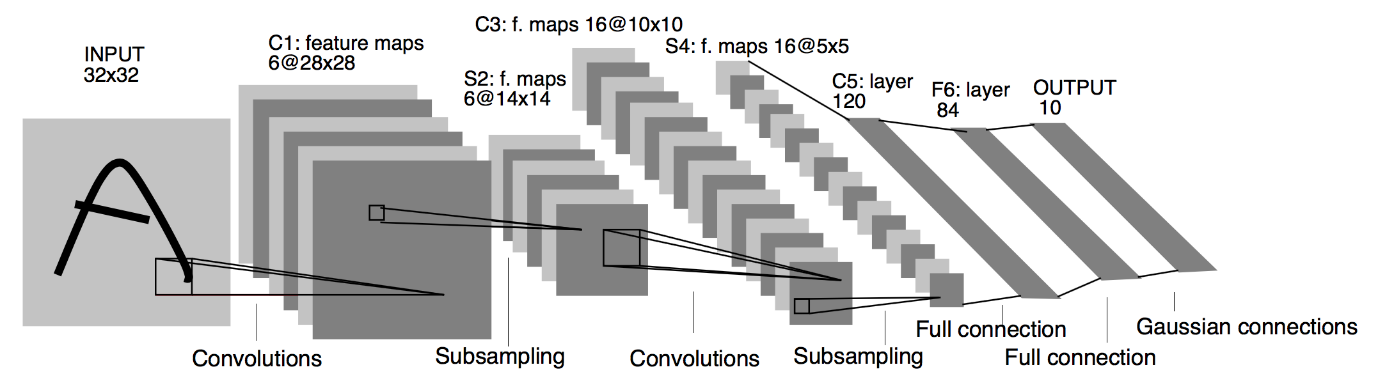
Источник : Архитектура LeNet
Из приведенной выше схемы архитектуры модели LeNet CNN видно, что существует 5 + 2 уровня. Первый и второй слои представляют собой сверточный слой, за которым следует объединяющий слой. Опять же, третий и четвертый слои состоят из сверточного слоя и слоя объединения. В результате этих операций размер входного изображения с 28х28 уменьшается до 7х7.
Пятый слой модели LeNet — это полносвязный слой, который сглаживает выходные данные предыдущего слоя. За которыми следуют два плотных слоя, последний выходной слой модели CNN состоит из функции активации Softmax с 10 единицами. Функция Softmax предсказывает вероятность класса для каждого из 10 классов набора данных Fashion MNIST.
#TensorFlow — построение модели
модель = keras.Sequential([
keras.layers.Conv2D (input_shape = (28,28,1), фильтры = 6, kernel_size = 5, шаги = 1, отступы = «то же самое», активация = tf.nn.relu),
keras.layers.AveragePooling2D (pool_size = 2, шаги = 2),
keras.layers.Conv2D (16, размер ядра = 5, шаги = 1, отступы = «то же самое», активация = tf.nn.relu),
keras.layers.AveragePooling2D (pool_size = 2, шаги = 2),
keras.layers.Flatten(),
keras.layers.Dense(120, активация=tf.nn.relu),
keras.layers.Dense(84, активация=tf.nn.relu),
keras.layers.Dense(10, активация=tf.nn.softmax)
])
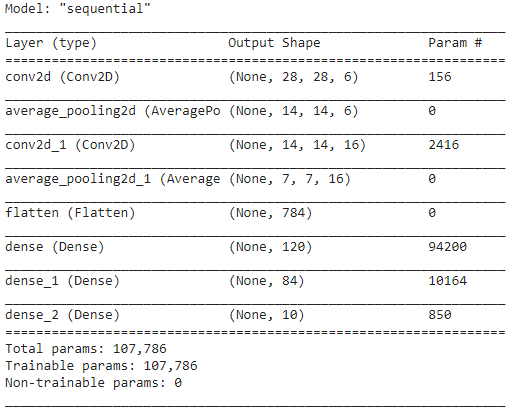
Шаг 5 – Резюме модели
Как только слои модели LeNet будут завершены, мы можем приступить к компиляции модели и просмотреть сводную версию разработанной модели CNN.
#TensorFlow — сводка модели
model.compile (потеря = keras.losses.categorical_crossentropy,
оптимизатор='адам',
метрики=['акк'])
модель.резюме()
При этом, поскольку конечный результат имеет более 2 классов (10 классов), мы используем категориальную кроссэнтропию в качестве функции потерь и оптимизатор Адама для нашей построенной модели. Краткое описание модели приведено ниже.
Шаг 6 – Обучение модели
Наконец, мы подошли к той части, где мы начинаем процесс обучения модели LeNet CNN. Во-первых, мы изменяем набор обучающих данных и нормализуем его до меньших значений, разделив на 255,0, чтобы снизить вычислительные затраты. Затем обучающие метки преобразуются из целочисленного вектора класса в бинарную матрицу класса. Например, метка 3 преобразуется в [0, 0, 0, 1, 0, 0, 0, 0, 0].
#TensorFlow — обучение модели
train_images_tensorflow = (train_images_tf / 255.0).reshape (train_images_tf.shape [0], 28, 28, 1)
test_images_tensorflow = (test_images_tf/255.0).reshape(test_images_tf.shape[0], 28, 28, 1)
train_labels_tensorflow = keras.utils.to_categorical (train_labels_tf)
test_labels_tensorflow = keras.utils.to_categorical (test_labels_tf)
H = model.fit (train_images_tensorflow, train_labels_tensorflow, эпохи = 30, batch_size = 32)
В конце обучения через 30 эпох мы получаем окончательную точность и потери обучения как,
Эпоха 30/30
1875/1875 [==============================] – 4 с 2 мс/шаг – потери: 0,0421 – акк: 0,9850
Точность обучения: 98,294997215271 %
Потери при обучении: 0,04584110900759697
Шаг 7 – Прогнозирование результатов
Наконец, когда мы закончим наш процесс обучения модели CNN, мы подгоним ту же модель к тестовому набору данных и предскажем точность 10 000 тестовых изображений.
#TensorFlow — сравнение результатов
прогнозы = model.predict (test_images_tensorflow)
правильно = 0
для i, pred в перечислении (прогнозы):
если np.argmax(pred) == test_labels_tf[i]:
правильно += 1
print('Проверка точности модели на {} тестовых изображениях: {}% с TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
Результат, который мы получаем,
Тестовая точность модели на 10000 тестовых изображений: 90,67% с TensorFlow
На этом мы подошли к концу программы по построению модели классификации изображений с помощью сверточных нейронных сетей.
Читайте также: Идеи проекта машинного обучения
Заключение
Таким образом, в этом руководстве по реализации классификации изображений в CNN мы поняли основные концепции, лежащие в основе классификации изображений, сверточных нейронных сетей, а также их реализацию на языке программирования Python с инфраструктурой TensorFlow.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, 5+ практических проектов и помощь в трудоустройстве в ведущих фирмах.
Какая модель CNN считается наиболее оптимальной для классификации изображений?
Лучшей моделью CNN для классификации изображений является VGG-16, что означает очень глубокие сверточные сети для крупномасштабного распознавания изображений. VGG, который был разработан как глубокая CNN, превосходит базовые показатели в широком диапазоне задач и наборов данных за пределами ImageNet. Отличительной особенностью модели является то, что при ее создании больше внимания уделялось включению отличных слоев свертки, а не добавлению большого количества гиперпараметров. Всего в ней 16 слоев, 5 блоков, и каждый блок имеет максимальный уровень объединения, что делает сеть довольно большой.
Каковы недостатки использования моделей CNN для классификации изображений?
Когда дело доходит до классификации изображений, модели CNN очень успешны. Однако у использования CNN есть несколько недостатков. Если идентифицируемое изображение наклонено или повернуто, у модели CNN возникают проблемы с точной идентификацией изображения. Когда CNN визуализирует изображения, нет внутренних представлений компонентов и их соединений часть-целое. Кроме того, если используемая модель CNN включает в себя множество сверточных слоев, процесс классификации займет много времени.
Почему использование модели CNN предпочтительнее, чем использование ANN для данных изображения в качестве входных данных?
Комбинируя фильтры или преобразования, CNN может изучить множество уровней представления признаков для каждого изображения, предоставленного в качестве входных данных. Переоснащение уменьшается, поскольку количество параметров, которые сеть должна изучить в CNN, значительно меньше, чем в многослойных нейронных сетях. При использовании ИНС нейронные сети могут изучать представление одного признака изображения, но в случае сложных изображений ИНС не сможет обеспечить улучшенную визуализацию или классификацию, поскольку она не может изучить пиксельные зависимости, существующие во входных изображениях.