
HTTP/3: улучшения производительности (часть 2)
Опубликовано: 2022-03-10Добро пожаловать в эту серию статей о новом протоколе HTTP/3. В части 1 мы рассмотрели, зачем нам нужны HTTP/3 и лежащий в их основе протокол QUIC, и каковы их основные новые функции.
Во второй части мы подробно рассмотрим улучшения производительности , которые QUIC и HTTP/3 привносят в таблицу загрузки веб-страниц. Однако мы также будем несколько скептически относиться к тому, какое влияние мы можем ожидать от этих новых функций на практике.
Как мы увидим, QUIC и HTTP/3 действительно обладают большим потенциалом производительности в Интернете, но в основном для пользователей в медленных сетях . Если ваш средний посетитель находится в быстрой кабельной или сотовой сети, он, вероятно, не получит особой пользы от новых протоколов. Однако обратите внимание, что даже в странах и регионах с обычно быстрыми исходящими ссылками самые медленные от 1% до даже 10% вашей аудитории (так называемые 99 -й или 90-й процентили ) по-прежнему потенциально могут много выиграть. Это связано с тем, что HTTP/3 и QUIC в основном помогают справляться с несколько необычными, но потенциально серьезными проблемами, которые могут возникнуть в современном Интернете.
Эта часть немного более техническая , чем первая, хотя она выгружает большую часть действительно глубоких вещей во внешние источники, фокусируясь на объяснении того, почему эти вещи важны для среднего веб-разработчика.
- Часть 1: История HTTP/3 и основные понятия
Эта статья предназначена для людей, плохо знакомых с HTTP/3 и протоколами в целом, и в ней в основном обсуждаются основы. - Часть 2. Функции производительности HTTP/3
Этот более глубокий и технический. Люди, которые уже знают основы, могут начать здесь. - Часть 3. Практические варианты развертывания HTTP/3
В этой третьей статье серии объясняются проблемы, связанные с развертыванием и тестированием HTTP/3 самостоятельно. В нем подробно описывается, как и следует ли вам изменять свои веб-страницы и ресурсы.
Учебник по скорости
Обсуждение производительности и «скорости» может быстро стать сложным, потому что многие основные аспекты способствуют «медленной» загрузке веб-страницы. Поскольку здесь мы имеем дело с сетевыми протоколами, мы в основном рассмотрим сетевые аспекты, два из которых являются наиболее важными: задержка и пропускная способность.
Задержку можно грубо определить как время, необходимое для отправки пакета из точки А (скажем, клиента) в точку Б (сервер) . Физически она ограничена скоростью света или, практически, скоростью передачи сигналов по проводам или на открытом воздухе. Это означает, что задержка часто зависит от физического, реального расстояния между A и B.
На земле это означает, что типичные задержки концептуально малы, примерно от 10 до 200 миллисекунд. Однако это только один из способов: ответы на пакеты также должны возвращаться. Двустороннюю задержку часто называют временем приема-передачи (RTT) .
Из-за таких функций, как контроль перегрузки (см. ниже), нам часто требуется довольно много циклов для загрузки даже одного файла. Таким образом, даже небольшие задержки менее 50 миллисекунд могут привести к значительным задержкам. Это одна из основных причин существования сетей доставки контента (CDN): они размещают серверы физически ближе к конечному пользователю, чтобы максимально уменьшить задержку и, следовательно, задержку.
Таким образом, можно грубо сказать, что пропускная способность — это количество пакетов, которые могут быть отправлены одновременно . Это несколько сложнее объяснить, поскольку зависит от физических свойств среды (например, используемой частоты радиоволн), количества пользователей в сети, а также устройств, соединяющих между собой разные подсети (поскольку они обычно может обрабатывать только определенное количество пакетов в секунду).
Часто используемая метафора - это труба, по которой транспортируют воду. Длина канала — это задержка, а ширина канала — пропускная способность. Однако в Интернете у нас обычно есть длинный ряд соединенных каналов , некоторые из которых могут быть шире, чем другие (что приводит к так называемым узким местам в самых узких звеньях). Таким образом, сквозная пропускная способность между точками A и B часто ограничивается самыми медленными участками.
Хотя полное понимание этих концепций не требуется для остальной части этого поста, было бы неплохо иметь общее определение высокого уровня. Для получения дополнительной информации рекомендую ознакомиться с отличной главой Ильи Григорика о задержке и пропускной способности в его книге High Performance Browser Networking .
Контроль перегрузки
Одним из аспектов производительности является то, насколько эффективно транспортный протокол может использовать полную (физическую) полосу пропускания сети (т. е. примерное количество пакетов в секунду, которое может быть отправлено или получено). Это, в свою очередь, влияет на скорость загрузки ресурсов страницы. Некоторые утверждают, что QUIC делает это намного лучше, чем TCP, но это не так.
Вы знали?
TCP-соединение, например, не просто начинает отправлять данные с полной пропускной способностью, потому что это может привести к перегрузке (или перегрузке) сети. Это связано с тем, что, как мы уже говорили, каждое сетевое соединение имеет только определенный объем данных, которые он может (физически) обрабатывать каждую секунду. Дайте ему больше, и не останется другого выбора, кроме как отбросить лишние пакеты, что приведет к потере пакетов .
Как обсуждалось в части 1, для надежного протокола, такого как TCP, единственным способом восстановления после потери пакетов является повторная передача новой копии данных, что занимает один круговой путь. Особенно в сетях с высокой задержкой (скажем, с RTT более 50 миллисекунд) потеря пакетов может серьезно повлиять на производительность.
Другая проблема заключается в том, что мы заранее не знаем, какой будет максимальная пропускная способность . Часто это зависит от узкого места где-то в сквозном соединении, но мы не можем предсказать или знать, где оно будет. В Интернете также нет механизмов (пока) для передачи сигналов пропускной способности канала конечным точкам.
Кроме того, даже если бы мы знали доступную физическую пропускную способность, это не означало бы, что мы могли бы использовать всю ее самостоятельно. Обычно в сети одновременно активны несколько пользователей, каждому из которых требуется справедливая доля доступной пропускной способности.
Таким образом, соединение не знает заранее, какую пропускную способность оно может безопасно или справедливо использовать, и эта пропускная способность может меняться по мере того, как пользователи присоединяются к сети, покидают ее и используют ее. Чтобы решить эту проблему, TCP будет постоянно пытаться обнаружить доступную полосу пропускания с течением времени, используя механизм, называемый контролем перегрузки .
В начале соединения он отправляет всего несколько пакетов (на практике от 10 до 100 пакетов или от 14 до 140 КБ данных) и ожидает один круговой обход, пока получатель не отправит обратно подтверждения этих пакетов. Если они все подтверждены, это означает, что сеть может обрабатывать эту скорость отправки, и мы можем попытаться повторить процесс, но с большим количеством данных (на практике скорость отправки обычно удваивается с каждой итерацией).
Таким образом, скорость отправки продолжает расти до тех пор, пока некоторые пакеты не будут подтверждены (что указывает на потерю пакетов и перегрузку сети). Эту первую фазу обычно называют «медленным стартом». При обнаружении потери пакетов TCP снижает скорость отправки и (через некоторое время) снова начинает увеличивать скорость отправки, хотя и с (намного) меньшими приращениями. Эта логика «уменьшить, затем увеличить» повторяется для каждой потери пакета впоследствии. В конце концов, это означает, что TCP будет постоянно пытаться достичь своей идеальной справедливой доли полосы пропускания. Этот механизм показан на рисунке 1.
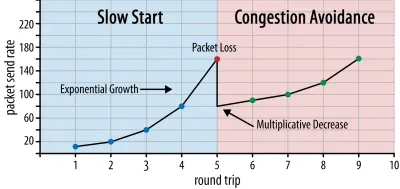
Это чрезвычайно упрощенное объяснение управления перегрузкой. На практике действуют многие другие факторы, такие как раздувание буфера, колебания RTT из-за перегрузки и тот факт, что несколько одновременных отправителей должны получать свою справедливую долю пропускной способности. Таким образом, существует множество различных алгоритмов управления перегрузкой, и многие из них все еще изобретаются сегодня, но ни один из них не работает оптимально во всех ситуациях.
Хотя управление перегрузкой TCP делает его надежным, это также означает, что для достижения оптимальной скорости отправки требуется некоторое время, в зависимости от RTT и фактической доступной полосы пропускания. При загрузке веб-страниц этот подход с медленным запуском также может повлиять на такие показатели, как первая содержательная отрисовка, поскольку лишь небольшой объем данных (от десятков до нескольких сотен КБ) может быть передан за первые несколько циклов передачи. (Возможно, вы слышали рекомендацию о том, чтобы критически важные данные не превышали 14 КБ.)
Таким образом, выбор более агрессивного подхода может привести к лучшим результатам в сетях с высокой пропускной способностью и высокой задержкой, особенно если вы не заботитесь о случайной потере пакетов. Здесь я снова увидел много неверных интерпретаций того, как работает QUIC.
Как обсуждалось в части 1, QUIC, теоретически, меньше страдает от потери пакетов (и связанной с этим блокировки заголовка строки (HOL)) потому, что он обрабатывает потерю пакетов в потоке байтов каждого ресурса независимо. Кроме того, QUIC работает по протоколу пользовательских дейтаграмм (UDP), который, в отличие от TCP, не имеет встроенной функции контроля перегрузки; это позволяет вам попробовать отправить с любой скоростью, которую вы хотите, и не передает повторно потерянные данные.
Это привело к многочисленным статьям, в которых утверждается, что QUIC также не использует управление перегрузкой, что вместо этого QUIC может начать отправлять данные с гораздо более высокой скоростью по UDP (полагаясь на удаление блокировки HOL для борьбы с потерей пакетов), вот почему QUIC намного быстрее, чем TCP.
На самом деле нет ничего более далекого от истины: в QUIC используются методы управления полосой пропускания, очень похожие на TCP . Он также начинается с более низкой скорости отправки и со временем увеличивается, используя подтверждения в качестве ключевого механизма для измерения пропускной способности сети. Это (среди прочих причин) связано с тем, что QUIC должен быть надежным, чтобы быть полезным для чего-то вроде HTTP, потому что он должен быть справедливым по отношению к другим соединениям QUIC (и TCP!) на самом деле хорошо помогает против потери пакетов (как мы увидим ниже).
Однако это не означает, что QUIC не может быть (немного) умнее в управлении пропускной способностью, чем TCP. В основном это связано с тем, что QUIC более гибок и легче развивается, чем TCP . Как мы уже говорили, алгоритмы управления перегрузкой сегодня все еще активно развиваются, и нам, вероятно, потребуется, например, настроить некоторые вещи, чтобы получить максимальную отдачу от 5G.
Однако TCP обычно реализуется в ядре операционной системы (ОС), безопасной и более ограниченной среде, которая для большинства ОС даже не является открытым исходным кодом. Таким образом, настройка логики перегрузки обычно выполняется только несколькими избранными разработчиками, и эволюция идет медленно.
Напротив, большинство реализаций QUIC в настоящее время выполняются в «пространстве пользователя» (где мы обычно запускаем нативные приложения) и имеют открытый исходный код, явно для поощрения экспериментов гораздо более широким кругом разработчиков (как уже показано, например, Facebook). ).
Еще одним конкретным примером является предложение о расширении частоты отложенных подтверждений для QUIC. Хотя по умолчанию QUIC отправляет подтверждение для каждых 2 полученных пакетов, это расширение позволяет конечным точкам вместо этого подтверждать, например, каждые 10 пакетов. Было показано, что это дает большие преимущества в скорости в спутниковых сетях и сетях с очень высокой пропускной способностью, поскольку снижаются накладные расходы на передачу пакетов подтверждения. Добавление такого расширения для TCP займет много времени, в то время как для QUIC его гораздо проще развернуть.
Таким образом, мы можем ожидать, что гибкость QUIC со временем приведет к большему количеству экспериментов и улучшению алгоритмов управления перегрузкой, которые, в свою очередь, также могут быть перенесены на TCP для его улучшения.
Вы знали?
Официальный документ QUIC Recovery RFC 9002 определяет использование алгоритма управления перегрузкой NewReno. Хотя этот подход является надежным, он также несколько устарел и больше не используется на практике. Итак, почему это в QUIC RFC? Первая причина заключается в том, что при запуске QUIC NewReno был самым последним алгоритмом управления перегрузкой, который сам был стандартизирован. Более продвинутые алгоритмы, такие как BBR и CUBIC, либо еще не стандартизированы, либо только недавно стали RFC.
Вторая причина заключается в том, что NewReno — относительно простая установка. Поскольку алгоритмы нуждаются в некоторых корректировках, чтобы справиться с отличиями QUIC от TCP, проще объяснить эти изменения на более простом алгоритме. Таким образом, RFC 9002 следует читать скорее как «как адаптировать алгоритм управления перегрузкой к QUIC», а не как «это то, что вы должны использовать для QUIC». Действительно, большинство реализаций QUIC на производственном уровне сделали собственные реализации как Cubic, так и BBR.
Стоит повторить, что алгоритмы управления перегрузкой не зависят от TCP или QUIC ; они могут использоваться любым протоколом, и есть надежда, что достижения в QUIC в конечном итоге найдут свое применение и в стеках TCP.
Вы знали?
Обратите внимание, что рядом с контролем перегрузки находится родственная концепция, называемая управлением потоком. Эти две функции часто путают в TCP, потому что они обе используют «окно TCP» , хотя на самом деле есть два окна: окно перегрузки и окно приема TCP. Управление потоком, однако, играет гораздо меньшую роль в интересующем нас случае загрузки веб-страницы, поэтому мы пропустим его здесь. Доступна более подробная информация.
Что все это значит?
QUIC по-прежнему связан законами физики и необходимостью быть вежливым с другими отправителями в Интернете. Это означает, что он не будет волшебным образом загружать ресурсы вашего веб-сайта намного быстрее, чем TCP. Однако гибкость QUIC означает, что экспериментировать с новыми алгоритмами управления перегрузкой станет проще, что должно улучшить ситуацию в будущем как для TCP, так и для QUIC.
Настройка соединения 0-RTT
Второй аспект производительности заключается в том, сколько циклов обмена требуется, прежде чем вы сможете отправлять полезные HTTP-данные (скажем, ресурсы страницы) по новому соединению. Некоторые утверждают, что QUIC на два-три раза быстрее, чем TCP + TLS, но мы увидим, что на самом деле это только один.
Вы знали?
Как мы говорили в части 1, соединение обычно выполняет одно (TCP) или два (TCP + TLS) рукопожатия, прежде чем можно будет обмениваться HTTP-запросами и ответами. Эти рукопожатия обмениваются исходными параметрами, которые должны быть известны как клиенту, так и серверу, например, для шифрования данных.
Как вы можете видеть на рисунке 2 ниже, для каждого отдельного рукопожатия требуется как минимум один круговой обмен (TCP + TLS 1.3, (b)) и иногда два (TLS 1.2 и более ранние версии (a)). Это неэффективно, потому что нам нужно как минимум два круговых обхода времени ожидания рукопожатия (накладные расходы), прежде чем мы сможем отправить наш первый HTTP-запрос, что означает ожидание по крайней мере трех круговых проходов для получения первых данных ответа HTTP (возвращающаяся красная стрелка). in. В медленных сетях это может означать накладные расходы от 100 до 200 миллисекунд.
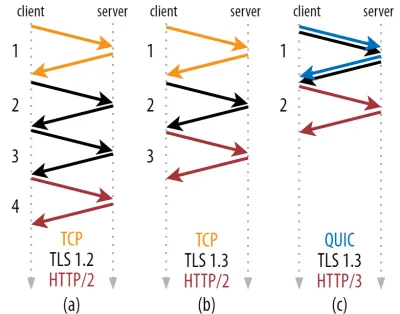
Вам может быть интересно, почему рукопожатие TCP + TLS нельзя просто объединить, чтобы выполнить одно и то же обращение туда и обратно. Хотя это концептуально возможно (QUIC делает именно это), изначально вещи не были спроектированы таким образом, потому что нам нужно иметь возможность использовать TCP с TLS и без него поверх. Иными словами, TCP просто не поддерживает отправку данных, отличных от TCP , во время рукопожатия. Были попытки добавить это с помощью расширения TCP Fast Open; однако, как обсуждалось в части 1, масштабное развертывание оказалось сложным.
К счастью, QUIC с самого начала разрабатывался с расчетом на TLS, поэтому он сочетает в себе как транспортные, так и криптографические рукопожатия в одном механизме. Это означает, что для завершения рукопожатия QUIC потребуется только один круговой обмен, что на один круговой путь меньше, чем для TCP + TLS 1.3 (см. рис. 2c выше).
Вы можете быть сбиты с толку, потому что вы, вероятно, читали, что QUIC на два или даже три пути туда и обратно быстрее, чем TCP, а не только на один. Это связано с тем, что в большинстве статей рассматривается только наихудший случай (TCP + TLS 1.2, (a)), не говоря уже о том, что современный TCP + TLS 1.3 также «только» использует два круговых пути ((b) редко показывается). Хотя увеличение скорости на одну поездку туда и обратно — это хорошо, вряд ли это удивительно. Особенно в быстрых сетях (скажем, RTT менее 50 мс) это будет едва заметно , хотя медленные сети и соединения с удаленными серверами принесут немного больше пользы.
Далее, вам может быть интересно, почему нам вообще нужно ждать рукопожатия. Почему мы не можем отправить HTTP-запрос в первом раунде? Это главным образом потому, что если бы мы это сделали, то первый запрос был бы отправлен незашифрованным , доступным для чтения любым перехватчиком в сети, что, очевидно, не очень хорошо для конфиденциальности и безопасности. Таким образом, нам нужно дождаться завершения криптографического рукопожатия, прежде чем отправлять первый HTTP-запрос. Или мы?
Вот где хитрый трюк используется на практике. Мы знаем, что пользователи часто повторно посещают веб-страницы в течение короткого времени после их первого посещения. Таким образом, мы можем использовать исходное зашифрованное соединение для загрузки второго соединения в будущем. Проще говоря, когда-то во время своего существования первое соединение используется для безопасной передачи новых криптографических параметров между клиентом и сервером. Затем эти параметры можно использовать для шифрования второго соединения с самого начала, не дожидаясь завершения полного рукопожатия TLS. Такой подход называется «возобновление сеанса» .
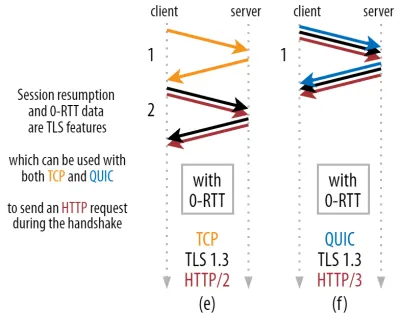
Это позволяет провести мощную оптимизацию: теперь мы можем безопасно отправлять наш первый HTTP-запрос вместе с рукопожатием QUIC/TLS, экономя еще один круговой путь ! Что касается TLS 1.3, это эффективно устраняет время ожидания рукопожатия TLS. Этот метод часто называют 0-RTT (хотя, конечно, для того, чтобы данные ответа HTTP начали поступать, по-прежнему требуется один круговой путь).
И возобновление сеанса, и 0-RTT — это, опять же, вещи, которые, как я часто видел, ошибочно объясняются как функции, специфичные для QUIC. На самом деле это функции TLS , которые в той или иной форме уже присутствовали в TLS 1.2, а теперь полностью реализованы в TLS 1.3.
Иными словами, как вы можете видеть на рисунке 3 ниже, мы можем получить преимущества производительности этих функций по сравнению с TCP (и, следовательно, также HTTP/2 и даже HTTP/1.1)! Мы видим, что даже с 0-RTT QUIC по-прежнему всего на один круговой обмен быстрее , чем оптимально функционирующий стек TCP + TLS 1.3. Утверждение, что QUIC на три круга быстрее, исходит из сравнения рисунка 2 (a) с рисунком 3 (f), что, как мы видели, не совсем справедливо.
Хуже всего то, что при использовании 0-RTT QUIC не может даже по-настоящему использовать полученный круговой путь из-за безопасности. Чтобы понять это, нам нужно понять одну из причин, по которой существует рукопожатие TCP. Во-первых, это позволяет клиенту убедиться, что сервер действительно доступен по заданному IP-адресу, прежде чем отправлять ему какие-либо данные более высокого уровня.
Во-вторых, что особенно важно, это позволяет серверу убедиться, что клиент, открывающий соединение, действительно является тем, кем и где он является, прежде чем отправлять ему данные. Если вы помните, как мы определяли соединение с 4-кортежами в части 1, вы знаете, что клиент в основном идентифицируется по его IP-адресу. И вот в чем проблема: IP-адреса можно подделать !
Предположим, злоумышленник запрашивает очень большой файл по HTTP через QUIC 0-RTT. Однако они подделывают свой IP-адрес, создавая впечатление, что запрос 0-RTT поступил с компьютера их жертвы. Это показано на рисунке 4 ниже. Сервер QUIC не может определить, был ли IP-адрес подделан, потому что это самые первые пакеты, которые он видит от этого клиента.

Если сервер затем просто начнет отправлять большой файл обратно на поддельный IP-адрес, это может привести к перегрузке пропускной способности сети жертвы (особенно если злоумышленник будет выполнять множество таких поддельных запросов параллельно). Обратите внимание, что ответ QUIC будет отброшен жертвой, потому что он не ожидает входящих данных, но это не имеет значения: их сети все еще нужно обрабатывать пакеты!
Это называется атакой с отражением или усилением, и это важный способ, с помощью которого хакеры выполняют распределенные атаки типа «отказ в обслуживании» (DDoS). Обратите внимание, что этого не происходит, когда используется 0-RTT через TCP + TLS, именно потому, что рукопожатие TCP должно быть завершено первым, прежде чем запрос 0-RTT даже будет отправлен вместе с рукопожатием TLS.
Таким образом, QUIC должен быть консервативен в ответах на запросы 0-RTT, ограничивая количество данных, которые он отправляет в ответ, до тех пор, пока клиент не будет проверен как настоящий клиент, а не жертва. Для QUIC этот объем данных установлен в три раза больше суммы, полученной от клиента.
Иными словами, QUIC имеет максимальный «фактор усиления», равный трем, что было определено как приемлемый компромисс между полезностью производительности и риском для безопасности (особенно по сравнению с некоторыми инцидентами, коэффициент усиления которых превышал 51 000 раз). Поскольку клиент обычно сначала отправляет только один-два пакета, ответ 0-RTT сервера QUIC будет ограничен размером от 4 до 6 КБ (включая другие накладные расходы QUIC и TLS!), что несколько меньше, чем впечатляет.
Кроме того, другие проблемы с безопасностью могут привести, например, к «атакам воспроизведения», которые ограничивают тип HTTP-запроса, который вы можете сделать. Например, Cloudflare разрешает только запросы HTTP GET без параметров запроса в 0-RTT. Это еще больше ограничивает полезность 0-RTT.
К счастью, у QUIC есть возможности сделать это немного лучше. Например, сервер может проверить, исходит ли 0-RTT от IP-адреса, с которым у него ранее было действительное соединение. Однако это работает только в том случае, если клиент остается в той же сети (что несколько ограничивает функцию переноса соединений QUIC). И даже если это сработает, ответ QUIC все равно будет ограничен логикой медленного старта контроллера перегрузки, которую мы обсуждали выше; таким образом, нет никакого дополнительного значительного увеличения скорости, кроме одной сохраненной поездки туда и обратно.
Вы знали?
Интересно отметить, что трехкратный предел усиления QUIC также учитывается для его нормального процесса рукопожатия без 0-RTT на рисунке 2c. Это может быть проблемой, если, например, сертификат TLS сервера слишком велик и не помещается в пределах 4–6 КБ. В этом случае его пришлось бы разделить, при этом второй фрагмент должен был бы ждать отправки второго кругового пути (после того, как приходят подтверждения первых нескольких пакетов, указывающие на то, что IP-адрес клиента не был подделан). В этом случае рукопожатие QUIC может по-прежнему совершать два круговых обхода , равных TCP + TLS! Вот почему для QUIC такие методы, как сжатие сертификатов, будут особенно важны.
Вы знали?
Возможно, некоторые расширенные настройки способны смягчить эти проблемы в достаточной степени, чтобы сделать 0-RTT более полезным. Например, сервер может помнить, какая пропускная способность была доступна клиенту в последний раз, когда он был замечен, что делает его менее ограниченным медленным запуском контроля перегрузки для повторного подключения (не поддельных) клиентов. Это было исследовано в академических кругах, и для этого даже предлагается расширение в QUIC. Несколько компаний уже делают подобные вещи для ускорения TCP.
Другим вариантом может быть отправка клиентами более одного или двух пакетов (например, отправка еще 7 пакетов с дополнением), поэтому трехкратное ограничение приводит к более интересному ответу размером от 12 до 14 КБ даже после переноса соединения. Я писал об этом в одной из своих статей.
Наконец, серверы QUIC (неправильно себя ведующие) могут также намеренно увеличить трехкратный лимит, если они считают, что это безопасно, или если их не волнуют потенциальные проблемы безопасности (в конце концов, никакой протокольной полиции не предотвращает это).
Что все это значит?
Более быстрая установка соединения QUIC с 0-RTT на самом деле является скорее микрооптимизацией, чем революционной новой функцией. По сравнению с современной настройкой TCP + TLS 1.3 это сэкономит максимум на одну передачу туда и обратно. Объем данных, которые фактически могут быть отправлены в ходе первого кругового пути, дополнительно ограничивается рядом соображений безопасности.
Таким образом, эта функция в основном будет работать, если ваши пользователи находятся в сетях с очень высокой задержкой (скажем, спутниковые сети с RTT более 200 миллисекунд), или если вы обычно не отправляете много данных. Некоторыми примерами последних являются сильно кэшированные веб-сайты, а также одностраничные приложения, которые периодически получают небольшие обновления через API и другие протоколы, такие как DNS-over-QUIC. Одна из причин, по которой Google получил очень хорошие результаты 0-RTT для QUIC, заключалась в том, что он протестировал его на своей уже сильно оптимизированной странице поиска, где ответы на запросы довольно малы.
В других случаях вы выиграете в лучшем случае всего несколько десятков миллисекунд , даже меньше, если вы уже используете CDN (что вам следует делать, если вы заботитесь о производительности!).
Миграция подключения
Третья функция повышения производительности делает QUIC быстрее при передаче между сетями, сохраняя существующие соединения нетронутыми . Хотя это действительно работает, этот тип изменения сети происходит не так часто, и соединениям все равно необходимо сбросить скорость отправки.
Как обсуждалось в части 1, идентификаторы соединений QUIC (CID) позволяют выполнять миграцию соединений при переключении сетей . Мы проиллюстрировали это на примере клиента, переходящего из сети Wi-Fi в сеть 4G во время загрузки большого файла. Для TCP эту загрузку, возможно, придется прервать, а для QUIC она может продолжиться.
Однако сначала подумайте, как часто на самом деле происходит такой сценарий. Вы можете подумать, что это также происходит при перемещении между точками доступа Wi-Fi внутри здания или между вышками сотовой связи в дороге. Однако в этих настройках (если они сделаны правильно) ваше устройство обычно сохраняет свой IP-адрес без изменений, потому что переход между беспроводными базовыми станциями выполняется на более низком уровне протокола. Таким образом, это происходит только тогда, когда вы перемещаетесь между совершенно разными сетями , что, я бы сказал, происходит не так уж часто.
Во-вторых, мы можем спросить, работает ли это также для других случаев использования, помимо загрузки больших файлов и видеоконференций в реальном времени и потоковой передачи. Если вы загружаете веб-страницу точно в момент переключения сетей, вам, возможно, придется повторно запросить некоторые из (более поздних) ресурсов.
Однако загрузка страницы обычно занимает порядка секунд, так что совпадение с сетевым коммутатором также не будет очень распространенным явлением. Кроме того, для случаев использования, когда это является насущной проблемой, обычно уже существуют другие меры по снижению риска . Например, серверы, предлагающие загрузку больших файлов, могут поддерживать запросы диапазона HTTP, чтобы разрешить возобновляемую загрузку.
Поскольку обычно существует некоторое время перекрытия между отключением сети 1 и доступностью сети 2, видеоприложения могут открывать несколько подключений (по одному на сеть), синхронизируя их до того, как старая сеть полностью исчезнет. Пользователь по-прежнему заметит этот переключатель, но он не отключит видеопоток полностью.
В-третьих, нет никакой гарантии, что новая сеть будет иметь такую же пропускную способность, как и старая. Таким образом, несмотря на то, что концептуальное соединение сохраняется, сервер QUIC не может просто продолжать отправлять данные на высоких скоростях. Вместо этого, чтобы избежать перегрузки новой сети, ей необходимо сбросить (или, по крайней мере, снизить) скорость отправки и начать снова в фазе медленного запуска контроллера перегрузки.
Поскольку эта начальная скорость отправки обычно слишком мала для реальной поддержки таких вещей, как потоковое видео, вы увидите некоторую потерю качества или сбои даже в QUIC. В некотором смысле миграция соединения больше направлена на предотвращение изменения контекста соединения и накладных расходов на сервере, чем на повышение производительности.
Вы знали?
Обратите внимание, что, как обсуждалось выше для 0-RTT, мы можем разработать некоторые продвинутые методы для улучшения миграции соединений. Например, мы можем снова попытаться вспомнить, какая пропускная способность была доступна в данной сети в прошлый раз, и попытаться быстрее увеличить этот уровень для новой миграции. Кроме того, мы могли бы не просто переключаться между сетями, но использовать обе одновременно. Эта концепция называется multipath , и мы обсудим ее более подробно ниже.
До сих пор мы в основном говорили об активной миграции соединений, когда пользователи перемещаются между разными сетями. Однако бывают и случаи пассивной миграции соединения, когда сама определенная сеть меняет параметры. Хорошим примером этого является повторная привязка преобразования сетевых адресов (NAT). Хотя полное обсуждение NAT выходит за рамки этой статьи, в основном это означает, что номера портов соединения могут измениться в любой момент времени без предупреждения. Это также происходит гораздо чаще для UDP, чем для TCP на большинстве маршрутизаторов.
Если это произойдет, QUIC CID не изменится, и в большинстве реализаций будет предполагаться, что пользователь все еще находится в той же физической сети, и поэтому не будут сбрасывать окно перегрузки или другие параметры. QUIC также включает в себя некоторые функции, такие как PING и индикаторы тайм-аута, чтобы предотвратить это, потому что это обычно происходит для соединений с длительным бездействием.
В части 1 мы обсуждали, что QUIC не просто использует один CID из соображений безопасности. Вместо этого он меняет CID при выполнении активной миграции. На практике все еще сложнее, поскольку и клиент, и сервер имеют отдельные списки CID (называемые исходным и целевым CID в QUIC RFC). Это показано на рисунке 5 ниже.
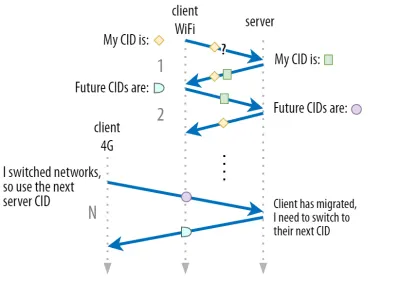
Это делается для того, чтобы каждая конечная точка могла выбирать свой собственный формат и содержимое CID , что, в свою очередь, имеет решающее значение для реализации расширенной логики маршрутизации и балансировки нагрузки. С миграцией соединения балансировщики нагрузки больше не могут просто смотреть на 4 кортежа, чтобы идентифицировать соединение и отправить его на правильный внутренний сервер. Однако, если бы все соединения QUIC использовали случайные CID, это значительно увеличило бы требования к памяти в балансировщике нагрузки, поскольку ему нужно было бы хранить сопоставления CID с внутренними серверами. Кроме того, это по-прежнему не будет работать при переносе соединения, поскольку CID меняются на новые случайные значения.
Таким образом, важно, чтобы внутренние серверы QUIC, развернутые за балансировщиком нагрузки, имели предсказуемый формат своих CID, чтобы балансировщик нагрузки мог получить правильный внутренний сервер из CID даже после миграции. Некоторые варианты для этого описаны в предложенном IETF документе. Чтобы все это стало возможным, серверы должны иметь возможность выбирать свой собственный CID, что было бы невозможно, если бы инициатор соединения (которым для QUIC всегда является клиент) выбирал CID. Вот почему в QUIC существует разделение CID клиента и сервера.

Что все это значит?
Таким образом, миграция соединения является ситуативной особенностью. Первоначальные тесты Google, например, показывают небольшой процент улучшений для его вариантов использования. Многие реализации QUIC еще не реализуют эту функцию. Даже те, которые это делают, обычно ограничиваются мобильными клиентами и приложениями, а не их настольными эквивалентами. Некоторые люди даже считают, что эта функция не нужна, потому что открытие нового соединения с 0-RTT в большинстве случаев должно иметь аналогичные характеристики производительности.
Тем не менее, в зависимости от вашего варианта использования или профиля пользователя, это может иметь большое влияние. Если ваш веб-сайт или приложение чаще всего используются в пути (скажем, Uber или Google Maps), вы, вероятно, получите больше преимуществ, чем если бы ваши пользователи обычно сидели за рабочим столом. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
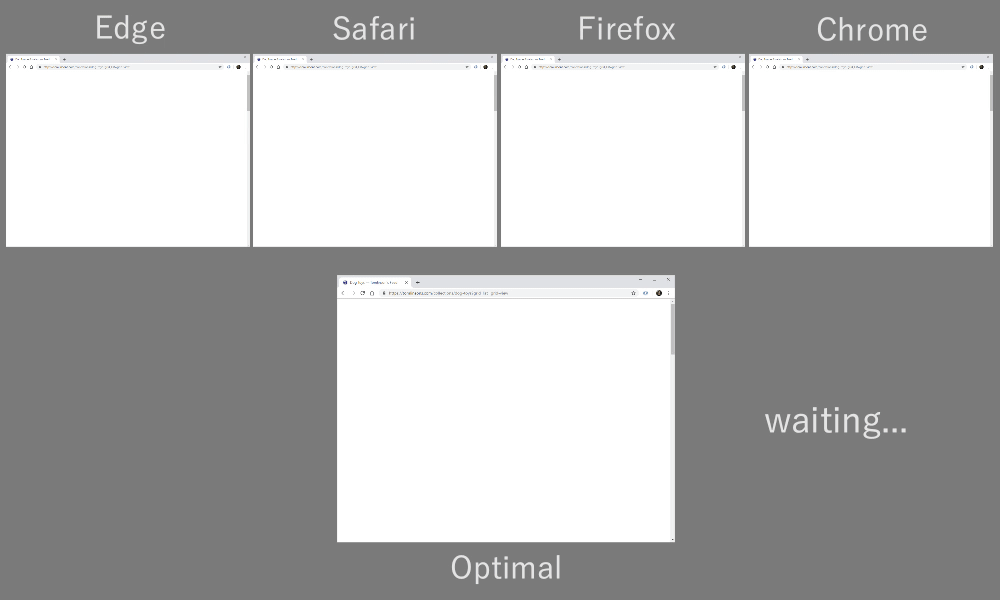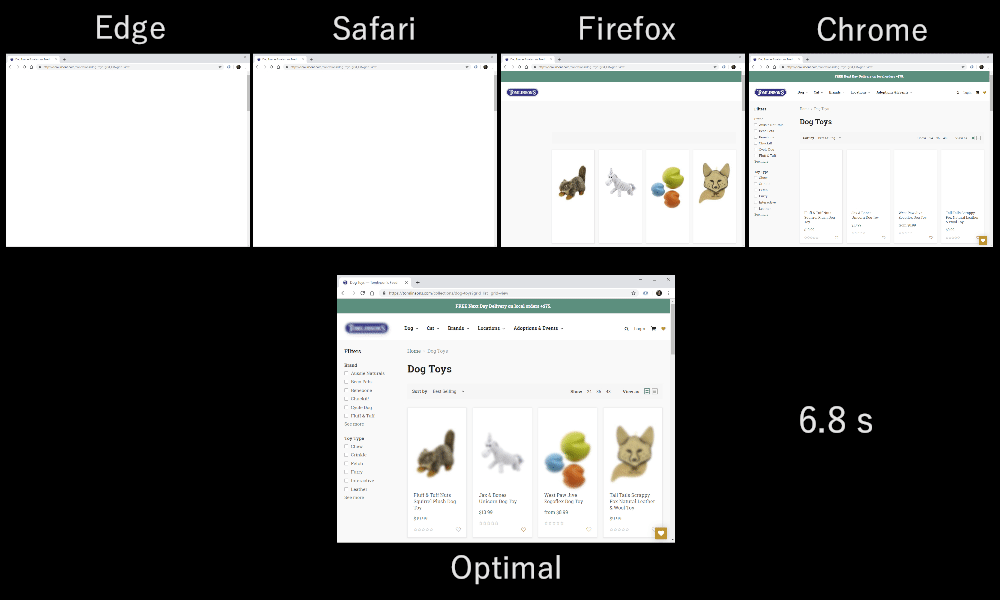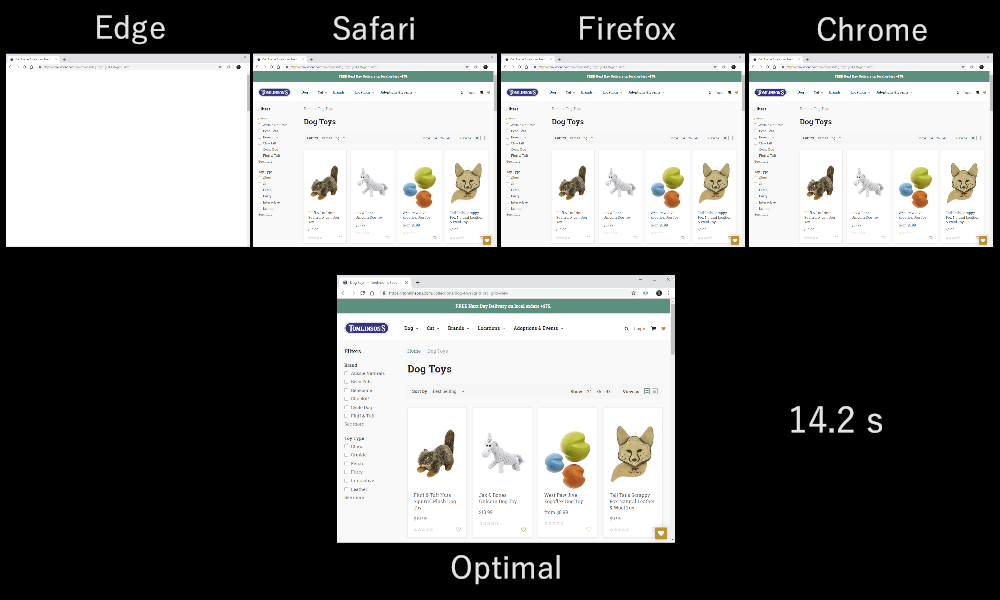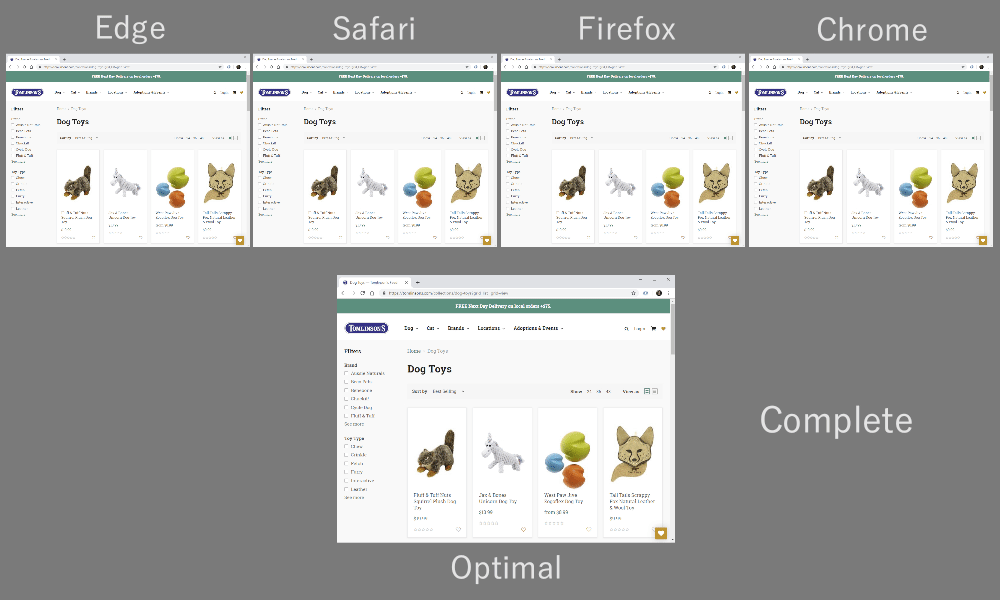
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
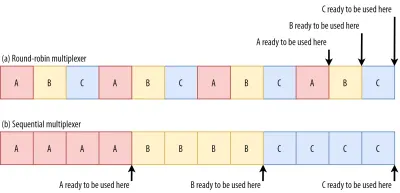
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
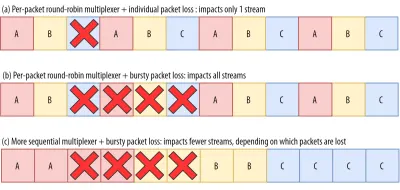
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Что все это значит?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
Производительность UDP и TLS
Пятый аспект производительности QUIC и HTTP/3 касается того, насколько эффективно и производительно они могут фактически создавать и отправлять пакеты по сети. Мы увидим, что QUIC, использующий UDP и тяжелое шифрование, может сделать его немного медленнее, чем TCP (но ситуация улучшается).
Во-первых, мы уже обсуждали, что использование UDP в QUIC больше связано с гибкостью и возможностью развертывания, чем с производительностью. Об этом еще больше свидетельствует тот факт, что до недавнего времени отправка пакетов QUIC по UDP обычно была намного медленнее, чем отправка пакетов TCP. Отчасти это связано с тем, где и как эти протоколы обычно реализуются (см. рис. 9 ниже).
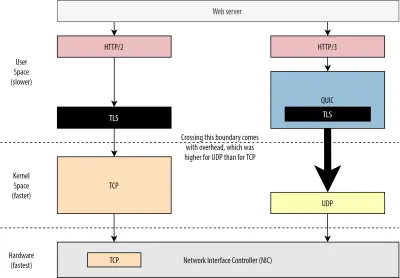
Как обсуждалось выше, TCP и UDP обычно реализуются непосредственно в быстром ядре ОС. Напротив, реализации TLS и QUIC в основном работают в более медленном пользовательском пространстве (обратите внимание, что это на самом деле не нужно для QUIC — в основном это делается, потому что он гораздо более гибкий). Это делает QUIC уже немного медленнее, чем TCP.
Кроме того, при отправке данных из нашего программного обеспечения пользовательского пространства (скажем, браузеров и веб-серверов) нам необходимо передать эти данные ядру ОС , которое затем использует TCP или UDP для фактической передачи их в сеть. Передача этих данных осуществляется с помощью API-интерфейсов ядра (системных вызовов), что влечет за собой определенные накладные расходы на каждый вызов API. Для TCP эти накладные расходы были намного ниже, чем для UDP.
В основном это связано с тем, что исторически TCP использовался намного чаще, чем UDP. Таким образом, со временем в реализации TCP и API ядра было добавлено множество оптимизаций, чтобы свести к минимуму накладные расходы на отправку и получение пакетов. Многие контроллеры сетевых интерфейсов (NIC) даже имеют встроенные функции аппаратной разгрузки для TCP. UDP, однако, повезло меньше, потому что его более ограниченное использование не оправдало вложений в дополнительные оптимизации. К счастью, за последние пять лет это изменилось, и с тех пор большинство операционных систем также добавили оптимизированные параметры для UDP .
Во-вторых, у QUIC много накладных расходов, потому что он шифрует каждый пакет по отдельности . Это медленнее, чем использование TLS через TCP, потому что вы можете шифровать пакеты порциями (примерно до 16 КБ или 11 пакетов за раз), что более эффективно. Это был сознательный компромисс, сделанный в QUIC, потому что массовое шифрование может привести к собственным формам блокировки HoL.
В отличие от первого пункта, где мы могли бы добавить дополнительные API, чтобы сделать UDP (и, следовательно, QUIC) быстрее, здесь у QUIC всегда будет неотъемлемый недостаток по сравнению с TCP + TLS. Однако на практике это также вполне управляемо, например, с помощью оптимизированных библиотек шифрования и умных методов, позволяющих массово шифровать заголовки пакетов QUIC.
В результате, хотя самые ранние версии QUIC от Google все еще были в два раза медленнее, чем TCP + TLS, с тех пор ситуация, безусловно, улучшилась. Например, в недавних тестах сильно оптимизированный стек Microsoft QUIC смог получить 7,85 Гбит/с по сравнению с 11,85 Гбит/с для TCP + TLS в той же системе (так что здесь QUIC примерно на 66% быстрее, чем TCP + TLS).
Это связано с недавними обновлениями Windows, которые сделали UDP быстрее (для полного сравнения пропускная способность UDP в этой системе составляла 19,5 Гбит/с). Самая оптимизированная версия стека Google QUIC в настоящее время примерно на 20% медленнее, чем TCP + TLS. Более ранние тесты Fastly на менее продвинутой системе и с некоторыми ухищрениями даже заявляли о равной производительности (около 450 Мбит/с), показывая, что в зависимости от варианта использования QUIC определенно может конкурировать с TCP.
Впрочем, даже если бы QUIC был в два раза медленнее, чем TCP+TLS, не все так плохо. Во-первых, обработка QUIC и TCP + TLS обычно не самая тяжелая вещь, происходящая на сервере, потому что другая логика (скажем, HTTP, кэширование, проксирование и т. д.) также должна выполняться. Таким образом, вам фактически не потребуется в два раза больше серверов для запуска QUIC (хотя немного неясно, какое влияние это окажет на реальный центр обработки данных, потому что ни одна из крупных компаний не опубликовала данные по этому вопросу).
Во-вторых, есть еще много возможностей для оптимизации реализаций QUIC в будущем. Например, со временем некоторые реализации QUIC (частично) перейдут к ядру ОС (как TCP) или обойдут его (некоторые уже делают это, например, MsQuic и Quant). Мы также можем ожидать, что аппаратное обеспечение, специфичное для QUIC, станет доступным.
Тем не менее, вероятно, будут некоторые варианты использования, для которых TCP + TLS останется предпочтительным вариантом. Например, Netflix указал, что, вероятно, не перейдет на QUIC в ближайшее время, поскольку вложил значительные средства в пользовательские настройки FreeBSD для потоковой передачи видео через TCP + TLS.
Точно так же Facebook заявил, что QUIC, вероятно, в основном будет использоваться между конечными пользователями и периферией CDN , но не между центрами обработки данных или между граничными узлами и исходными серверами из-за больших накладных расходов. В целом сценарии с очень высокой пропускной способностью, вероятно, по-прежнему будут отдавать предпочтение TCP + TLS, особенно в ближайшие несколько лет.
Вы знали?
Оптимизация сетевых стеков — это глубокая и техническая кроличья нора, из которой вышеизложенное лишь царапает поверхность (и упускает много нюансов). Если вы достаточно смелы или хотите знать, что означают такие термины, какGRO/GSO,SO_TXTIME, обход ядра иsendmmsg()иrecvmmsg(), я также могу порекомендовать несколько отличных статей по оптимизации QUIC от Cloudflare и Fastly. как подробное пошаговое руководство по коду от Microsoft и подробный доклад от Cisco. Наконец, инженер Google выступил с очень интересным докладом об оптимизации их реализации QUIC с течением времени.
Что все это значит?
Особое использование QUIC протоколов UDP и TLS исторически делало его намного медленнее, чем TCP + TLS. Однако со временем было внесено (и будет продолжаться) несколько улучшений, которые несколько закрыли этот пробел. Вы, вероятно, не заметите эти несоответствия в типичных случаях использования загрузки веб-страниц, но они могут доставить вам головную боль, если вы поддерживаете большие фермы серверов.
Возможности HTTP/3
До сих пор мы в основном говорили о новых функциях производительности в QUIC по сравнению с TCP. Однако как насчет HTTP/3 по сравнению с HTTP/2? Как обсуждалось в части 1, HTTP/3 на самом деле представляет собой HTTP/2-over-QUIC , и поэтому в новой версии не было представлено никаких серьезных новых функций. Это отличается от перехода с HTTP/1.1 на HTTP/2, который был намного больше и представил новые функции, такие как сжатие заголовков, приоритизация потоков и отправка на сервер. Все эти функции все еще находятся в HTTP/3, но есть некоторые важные отличия в том, как они реализованы под капотом.
В основном это связано с тем, как работает устранение блокировки HoL в QUIC. Как мы уже говорили, потеря в потоке B больше не означает, что потокам A и C придется ждать повторных передач B, как это было в TCP. Таким образом, если каждый из A, B и C отправил пакет QUIC в указанном порядке, их данные вполне могут быть доставлены (и обработаны) браузером как A, C, B! Иными словами, в отличие от TCP, QUIC больше не полностью упорядочен по разным потокам!
Это проблема для HTTP/2, который действительно полагался на строгий порядок TCP при разработке многих своих функций, которые используют специальные управляющие сообщения, перемежающиеся фрагментами данных. В QUIC эти управляющие сообщения могут поступать (и применяться) в любом порядке, потенциально даже заставляя функции действовать противоположно тому, что предполагалось! Технические детали, опять же, не нужны для этой статьи, но первая половина этой статьи должна дать вам представление о том, насколько это может быть невероятно сложно.
Таким образом, внутренняя механика и реализация функций должны были измениться для HTTP/3. Конкретным примером является сжатие заголовков HTTP , которое снижает нагрузку на повторяющиеся большие заголовки HTTP (например, файлы cookie и строки пользовательского агента). В HTTP/2 это было сделано с помощью настройки HPACK, а для HTTP/3 это было переработано в более сложный QPACK. Обе системы предоставляют одну и ту же функцию (например, сжатие заголовков), но совершенно по-разному. В блоге Litespeed можно найти отличное подробное техническое обсуждение и диаграммы по этой теме.
Нечто подобное верно и для функции приоритизации, которая управляет логикой потокового мультиплексирования и которую мы кратко обсуждали выше. В HTTP/2 это было реализовано с помощью сложной настройки «дерева зависимостей», которая явно пыталась смоделировать все ресурсы страницы и их взаимосвязи (дополнительная информация находится в докладе «Полное руководство по приоритизации ресурсов HTTP»). Использование этой системы непосредственно поверх QUIC привело бы к некоторым потенциально очень неправильным макетам дерева, потому что добавление каждого ресурса в дерево было бы отдельным управляющим сообщением.
Кроме того, этот подход оказался излишне сложным, что привело к множеству ошибок реализации и неэффективности, а также к низкому уровню производительности на многих серверах. Обе проблемы привели к тому, что система приоритизации для HTTP/3 была переработана гораздо проще. Эта более простая настройка делает некоторые сложные сценарии сложными или невозможными для реализации (например, проксирование трафика от нескольких клиентов по одному соединению), но по-прежнему позволяет использовать широкий спектр параметров для оптимизации загрузки веб-страниц.
Хотя, опять же, эти два подхода обеспечивают одну и ту же базовую функцию (управление мультиплексированием потока), есть надежда, что более простая настройка HTTP/3 уменьшит количество ошибок реализации.
Наконец, есть push сервера . Эта функция позволяет серверу отправлять HTTP-ответы, не дожидаясь явного запроса на них. Теоретически это может обеспечить отличный прирост производительности. Однако на практике оказалось, что его сложно правильно использовать и реализовать непоследовательно. В результате его, вероятно, даже уберут из Google Chrome.
Несмотря на все это, он по -прежнему определяется как функция HTTP/3 (хотя несколько реализаций поддерживают его). Хотя его внутренняя работа не изменилась так сильно, как предыдущие две функции, он также был адаптирован для работы с недетерминированным порядком QUIC. Однако, к сожалению, это мало поможет решить некоторые из его давних проблем.
Что все это значит?
Как мы уже говорили ранее, большая часть потенциала HTTP/3 исходит из лежащего в основе QUIC, а не самого HTTP/3. Хотя внутренняя реализация протокола сильно отличается от HTTP/2, его высокоуровневые характеристики производительности и то, как их можно и нужно использовать, остались прежними.
Будущие разработки, на которые стоит обратить внимание
В этой серии статей я регулярно подчеркивал, что более быстрая эволюция и более высокая гибкость являются ключевыми аспектами QUIC (и, соответственно, HTTP/3). Поэтому неудивительно, что люди уже работают над новыми расширениями и приложениями протоколов. Ниже перечислены основные из них, с которыми вы, вероятно, столкнетесь где-то в будущем:
Прямое исправление ошибок
Целью этого метода, опять же, является повышение устойчивости QUIC к потере пакетов . Он делает это, отправляя избыточные копии данных (хотя и искусно закодированные и сжатые, чтобы они не были такими большими). Затем, если пакет потерян, но поступили избыточные данные, повторная передача больше не требуется.
Первоначально это было частью Google QUIC (и одной из причин, по которой люди говорят, что QUIC хорош против потери пакетов), но оно не включено в стандартизированную версию QUIC 1, поскольку его влияние на производительность еще не доказано. Однако сейчас исследователи проводят с ним активные эксперименты, и вы можете им помочь, используя приложение PQUIC-FEC Download Experiments.Многолучевой QUIC
Ранее мы обсуждали миграцию подключения и то, как она может помочь при переходе, скажем, с Wi-Fi на сотовую связь. Однако не означает ли это, что мы можем одновременно использовать и Wi-Fi, и сотовую связь? Одновременное использование обеих сетей дало бы нам более доступную пропускную способность и повышенную надежность! Это основная концепция многолучевости.
Это, опять же, то, с чем Google экспериментировал, но это не вошло в QUIC версии 1 из-за присущей ему сложности. Однако с тех пор исследователи продемонстрировали его высокий потенциал, и он может быть включен в QUIC версии 2. Обратите внимание, что TCP multipath также существует, но потребовалось почти десятилетие, чтобы его можно было использовать на практике.Ненадежные данные через QUIC и HTTP/3
Как мы видели, QUIC — полностью надежный протокол. Однако, поскольку он работает по ненадежному протоколу UDP, мы можем добавить в QUIC функцию для отправки ненадежных данных. Это описано в предлагаемом расширении дейтаграммы. Вы, конечно, не захотите использовать это для отправки ресурсов веб-страницы, но это может быть удобно для таких вещей, как игры и потоковое видео в реальном времени. Таким образом, пользователи получат все преимущества UDP, но с шифрованием на уровне QUIC и (дополнительным) контролем перегрузки.Веб-транспорт
Браузеры не предоставляют TCP или UDP JavaScript напрямую, в основном из соображений безопасности. Вместо этого нам приходится полагаться на API-интерфейсы уровня HTTP, такие как Fetch, и несколько более гибкие протоколы WebSocket и WebRTC. Самый новый из этой серии опций называется WebTransport, который в основном позволяет вам использовать HTTP/3 (и, соответственно, QUIC) более низкоуровневым способом (хотя при необходимости он также может вернуться к TCP и HTTP/2). ).
Важно отметить, что он будет включать в себя возможность использовать ненадежные данные через HTTP/3 (см. предыдущий пункт), что должно упростить реализацию таких вещей, как игры, в браузере. Для обычных (JSON) вызовов API вы, конечно, по-прежнему будете использовать Fetch, который также будет автоматически использовать HTTP/3, когда это возможно. В настоящее время WebTransport все еще активно обсуждается, поэтому пока не ясно, как он будет выглядеть в конечном итоге. Из браузеров только Chromium в настоящее время работает над общедоступной реализацией концепции.Потоковое видео DASH и HLS
Для неживого видео (например, YouTube и Netflix) браузеры обычно используют протоколы Dynamic Adaptive Streaming over HTTP (DASH) или HTTP Live Streaming (HLS). Оба в основном означают, что вы кодируете свои видео в более мелкие фрагменты (от 2 до 10 секунд) и разные уровни качества (720p, 1080p, 4K и т. д.).
Во время выполнения браузер оценивает максимальное качество, которое может поддерживать ваша сеть (или наиболее оптимальное для данного варианта использования), и запрашивает соответствующие файлы с сервера по протоколу HTTP. Поскольку у браузера нет прямого доступа к стеку TCP (как это обычно реализовано в ядре), он иногда делает несколько ошибок в этих оценках или требуется некоторое время, чтобы отреагировать на изменение сетевых условий (что приводит к зависанию видео). .
Поскольку QUIC реализован как часть браузера, его можно немного улучшить, предоставив оценщикам потоковой передачи доступ к низкоуровневой информации протокола (такой как коэффициенты потерь, оценки пропускной способности и т. д.). Другие исследователи также экспериментировали со смешиванием надежных и ненадежных данных для потокового видео, и это дало многообещающие результаты.Протоколы, отличные от HTTP/3
Поскольку QUIC является транспортным протоколом общего назначения, мы можем ожидать, что многие протоколы прикладного уровня, которые теперь работают поверх TCP, также будут работать поверх QUIC. Некоторые незавершенные работы включают DNS-over-QUIC, SMB-over-QUIC и даже SSH-over-QUIC. Поскольку к этим протоколам обычно предъявляются совсем другие требования, чем к HTTP и загрузке веб-страницы, улучшения производительности QUIC, которые мы обсуждали, могут гораздо лучше работать для этих протоколов.
Что все это значит?
QUIC версии 1 — это только начало . Многие расширенные функции, ориентированные на производительность, с которыми ранее экспериментировал Google, не вошли в эту первую итерацию. Однако цель состоит в том, чтобы быстро развивать протокол, часто вводя новые расширения и функции. Таким образом, со временем QUIC (и HTTP/3) должен стать явно быстрее и гибче, чем TCP (и HTTP/2).
Заключение
Во второй части серии мы обсудили множество различных функций и аспектов производительности HTTP/3 и особенно QUIC. Мы видели, что, хотя большинство этих функций кажутся очень эффективными, на практике они могут не так много делать для среднего пользователя в рассматриваемом нами случае загрузки веб-страницы.
Например, мы видели, что использование UDP в QUIC не означает, что он может внезапно использовать большую пропускную способность, чем TCP, и не означает, что он может быстрее загружать ваши ресурсы. Часто восхваляемая функция 0-RTT на самом деле является микрооптимизацией, которая экономит вам один круговой путь, в котором вы можете отправить около 5 КБ (в худшем случае).
Удаление блокировки HoL не работает хорошо, если есть пакетная потеря пакетов или когда вы загружаете ресурсы, блокирующие рендеринг. Миграция соединений очень ситуативна, и HTTP/3 не имеет каких-либо важных новых функций, которые могли бы сделать его быстрее, чем HTTP/2.
Таким образом, вы можете ожидать, что я порекомендую вам просто пропустить HTTP/3 и QUIC. Зачем заморачиваться, да? Тем не менее, я определенно не буду делать ничего подобного! Несмотря на то, что эти новые протоколы могут не очень помочь пользователям в быстрых (городских) сетях, новые функции, безусловно, могут оказать большое влияние на мобильных пользователей и людей в медленных сетях.
Даже на западных рынках, таких как моя собственная Бельгия, где у нас обычно есть быстрые устройства и доступ к высокоскоростным сотовым сетям, эти ситуации могут затронуть от 1% до даже 10% вашей пользовательской базы, в зависимости от вашего продукта. Например, кто-то в поезде отчаянно пытается найти важную информацию на вашем веб-сайте, но ему приходится ждать 45 секунд, пока она загрузится. Я, конечно, знаю, что был в такой ситуации, желая, чтобы кто-то развернул QUIC, чтобы вытащить меня из нее.
Однако есть и другие страны и регионы, где дела обстоят еще хуже. Там средний пользователь может больше походить на самые медленные 10% в Бельгии, а самый медленный 1% может вообще никогда не увидеть загруженную страницу. Во многих частях мира веб-производительность является проблемой доступности и инклюзивности.
Вот почему мы никогда не должны просто тестировать наши страницы на собственном оборудовании (но также использовать такой сервис, как Webpagetest), а также почему вам обязательно следует развернуть QUIC и HTTP/3 . Особенно, если ваши пользователи часто находятся в пути или вряд ли будут иметь доступ к быстрым сотовым сетям, эти новые протоколы могут иметь большое значение, даже если вы не заметите многого на своем MacBook Pro с кабельным подключением. Для получения более подробной информации я настоятельно рекомендую пост Fastly по этому вопросу.
Если это вас не полностью убеждает, то учтите, что QUIC и HTTP/3 будут продолжать развиваться и становиться быстрее в ближайшие годы. Получение некоторого начального опыта работы с протоколами окупится в будущем, что позволит вам как можно скорее воспользоваться преимуществами новых функций. Кроме того, QUIC в фоновом режиме применяет передовые методы обеспечения безопасности и конфиденциальности, что приносит пользу всем пользователям во всем мире.
Наконец убедились? Затем перейдите к части 3 серии, чтобы прочитать о том, как вы можете использовать новые протоколы на практике.
- Часть 1: История HTTP/3 и основные понятия
Эта статья предназначена для людей, плохо знакомых с HTTP/3 и протоколами в целом, и в ней в основном обсуждаются основы. - Часть 2. Функции производительности HTTP/3
Этот более глубокий и технический. Люди, которые уже знают основы, могут начать здесь. - Часть 3. Практические варианты развертывания HTTP/3
В этой третьей статье серии объясняются проблемы, связанные с развертыванием и тестированием HTTP/3 самостоятельно. В нем подробно описывается, как и следует ли вам изменять свои веб-страницы и ресурсы.