
Как реализовать классификацию в машинном обучении?
Опубликовано: 2021-03-12Применение машинного обучения в различных областях за последние несколько лет увеличилось как на дрожжах, и оно продолжает расти. Одна из самых популярных задач модели машинного обучения — распознавать объекты и разделять их на назначенные им классы.
Это метод классификации, который является одним из самых популярных приложений машинного обучения. Классификация используется для разделения огромного количества данных на набор дискретных значений, которые могут быть двоичными, такими как 0/1, Да/Нет, или мультиклассовыми, такими как животные, автомобили, птицы и т. д.
В следующей статье мы поймем концепцию классификации в машинном обучении, типы задействованных данных и увидим некоторые из самых популярных алгоритмов классификации, используемых в машинном обучении для классификации нескольких данных.
Оглавление
Что такое контролируемое обучение?
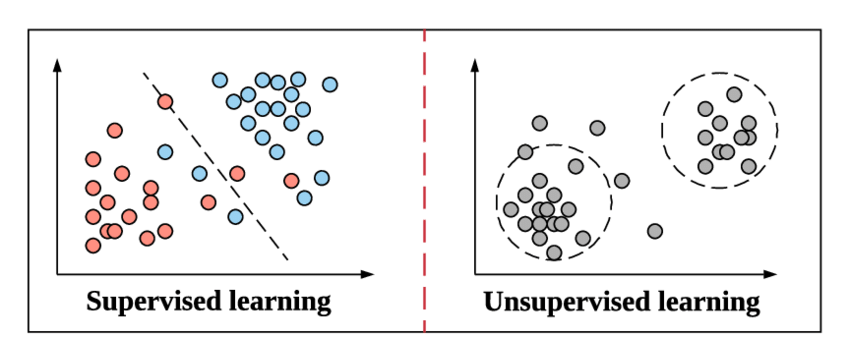
Поскольку мы готовимся погрузиться в концепцию классификации и ее типов, давайте быстро освежим в памяти то, что подразумевается под контролируемым обучением и чем оно отличается от другого метода неконтролируемого обучения в машинном обучении.
Давайте разберемся в этом на простом примере из нашего урока физики в старшей школе. Предположим, есть простая задача, связанная с новым методом. Если нам представят вопрос, который мы должны решить, используя один и тот же метод, разве мы все не обратимся к примеру задачи с одним и тем же методом и не попытаемся решить ее? Как только мы будем уверены в этом методе, нам не нужно обращаться к нему снова и продолжать решать его.
Источник

Это то же самое, как контролируемое обучение работает в машинном обучении. Оно учится на примере. Чтобы сделать это еще более простым, в контролируемом обучении все данные подаются с соответствующими метками, и, следовательно, в процессе обучения модель машинного обучения сравнивает свои выходные данные для конкретных данных с истинным выводом тех же данных и пытается минимизировать ошибку между прогнозируемым и реальным значением метки.
Алгоритмы классификации, которые мы рассмотрим в этой статье, следуют этому методу контролируемого обучения, например, обнаружению спама и распознаванию объектов.
Неконтролируемое обучение — это шаг выше, на котором данные не передаются со своими метками. Ответственность и эффективность модели машинного обучения заключается в том, чтобы извлекать шаблоны из данных и давать результат. Алгоритмы кластеризации следуют этому неконтролируемому методу обучения.
Что такое Классификация?
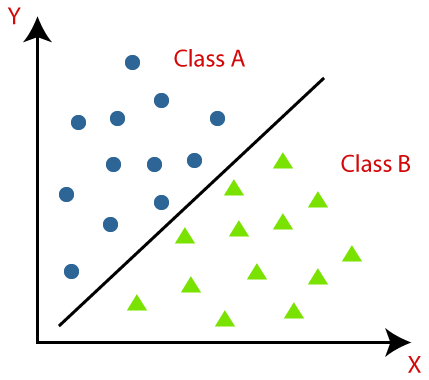
Классификация определяется как распознавание, понимание и группировка объектов или данных в заранее заданные классы. Классифицируя данные перед процессом обучения модели машинного обучения, мы можем использовать различные алгоритмы классификации для классификации данных по нескольким классам. В отличие от регрессии, проблема классификации возникает, когда выходной переменной является категория, такая как «Да» или «Нет», или «Болезнь», или «Болезнь отсутствует».
В большинстве задач машинного обучения после загрузки набора данных в программу перед обучением набор данных разбивается на обучающий набор и тестовый набор с фиксированным соотношением (обычно 70% обучающий набор и 30% тестовый набор). Этот процесс разделения позволяет модели выполнять обратное распространение, в котором она пытается исправить свою ошибку прогнозируемого значения по сравнению с истинным значением с помощью нескольких математических приближений.
Точно так же, прежде чем мы начнем классификацию, создается набор обучающих данных. Алгоритм классификации проходит обучение на нем при тестировании на тестовом наборе данных с каждой итерацией, известной как эпоха.
Источник
Одним из наиболее распространенных приложений алгоритмов классификации является фильтрация электронных писем на предмет того, являются ли они «спамом» или «не спамом». Короче говоря, мы можем определить классификацию в машинном обучении как форму «распознавания образов», в которой эти алгоритмы, применяемые к обучающим данным, используются для извлечения из данных нескольких шаблонов (таких как похожие слова или числовые последовательности, настроения и т. д.). .).
Классификация — это процесс классификации заданного набора данных по классам; это может быть выполнено как со структурированными, так и с неструктурированными данными. Он начинается с предсказания класса заданных точек данных. Эти классы также называются выходными переменными, целевыми метками и т. д. Некоторые алгоритмы имеют встроенные математические функции для аппроксимации функции отображения из переменных точек входных данных в выходной целевой класс. Основная цель классификации — определить, к какому классу/категории попадут новые данные.
Типы алгоритмов классификации в машинном обучении
В зависимости от типа данных, к которым применяются алгоритмы классификации, существует две широкие категории алгоритмов: линейные и нелинейные модели.
Линейные модели
- Логистическая регрессия
- Методы опорных векторов (SVM)
Нелинейные модели
- Классификация K-ближайших соседей (KNN)
- Ядро SVM
- Наивная байесовская классификация
- Классификация дерева решений
- Случайная классификация леса
В этой статье мы кратко рассмотрим концепцию каждого из упомянутых выше алгоритмов.
Оценка модели классификации в машинном обучении
Прежде чем мы перейдем к упомянутым выше концепциям этих алгоритмов, мы должны понять, как мы можем оценить нашу модель машинного обучения, построенную на основе этих алгоритмов. Важно оценить точность нашей модели как на обучающем наборе, так и на тестовом наборе.
Перекрестная энтропийная потеря или потеря журнала
Это первый тип функции потерь, который мы будем использовать при оценке производительности классификатора, чьи выходные данные находятся в диапазоне от 0 до 1. Это в основном используется для моделей двоичной классификации. Формула Log Loss определяется следующим образом:
Log Loss = -((1 – y) * log(1 – yhat) + y * log(yhat))
Где это прогнозируемое значение, а y - реальное значение.
Матрица путаницы
Матрица путаницы — это матрица NXN, где N — количество прогнозируемых классов. Матрица путаницы предоставляет нам матрицу/таблицу в качестве выходных данных и описывает производительность модели. Он состоит из результатов прогнозов в виде матрицы, из которой мы можем получить несколько показателей производительности для оценки модели классификации. Он имеет форму,
| Фактический положительный | Фактический отрицательный | |
| Прогнозируемый положительный | Истинный положительный | Ложно положительный |
| Прогнозируемый отрицательный | Ложноотрицательный | Правда отрицательный |
Ниже приведены некоторые показатели производительности, которые можно получить из приведенной выше таблицы.
1.Точность – доля от общего количества правильных прогнозов.
2. Положительная прогностическая ценность или точность — доля правильно идентифицированных положительных случаев.
3. Отрицательная прогностическая ценность — доля правильно идентифицированных отрицательных случаев.
4. Чувствительность или отзыв — доля фактических положительных случаев, которые были правильно идентифицированы.
5. Специфичность – доля фактических отрицательных случаев, которые были правильно идентифицированы.
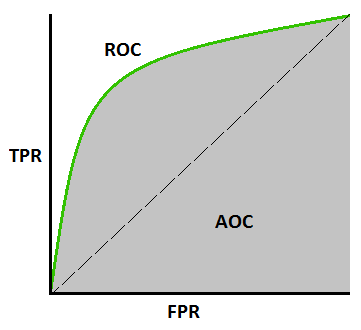
Кривая AUC-ROC –
Это еще одна важная метрика кривой, которая оценивает любую модель машинного обучения. Кривая ROC обозначает кривую рабочих характеристик приемника, а AUC обозначает площадь под кривой. Кривая ROC построена с TPR и FPR, где TPR (истинно положительный показатель) на оси Y и FPR (ложноположительный показатель) на оси X. Он показывает эффективность модели классификации при различных пороговых значениях.
Источник
1. Логистическая регрессия
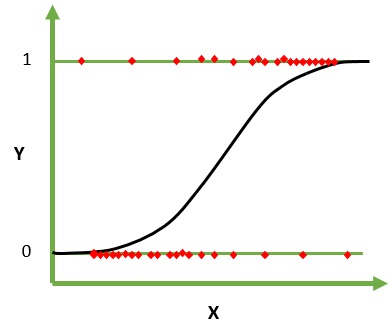
Логистическая регрессия — это алгоритм машинного обучения для классификации. В этом алгоритме вероятности, описывающие возможные результаты одного испытания, моделируются с использованием логистической функции. Предполагается, что входные переменные являются числовыми и имеют распределение по Гауссу (гауссовая кривая).
Логистическая функция, также называемая сигмовидной функцией, первоначально использовалась статистиками для описания роста населения в экологии. Сигмовидная функция — это математическая функция, используемая для сопоставления прогнозируемых значений с вероятностями. Логистическая регрессия имеет S-образную кривую и может принимать значения от 0 до 1, но никогда точно в этих пределах.

Источник
Логистическая регрессия в основном используется для прогнозирования бинарного результата, такого как Да/Нет и Пройдено/Не пройдено. Независимые переменные могут быть категориальными или числовыми, но зависимая переменная всегда категорична. Формула для логистической регрессии дается,
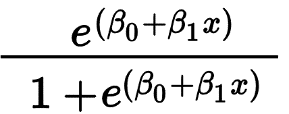
Где e представляет S-образную кривую, которая имеет значения от 0 до 1.
2. Машины опорных векторов
Машина опорных векторов (SVM) использует алгоритмы для обучения и классификации данных в пределах степеней полярности, доводя их до уровня, выходящего за пределы предсказания X/Y. В SVM линия, используемая для разделения классов, называется гиперплоскостью. Точки данных по обе стороны от гиперплоскости, ближайшие к гиперплоскости, называются опорными векторами, используемыми для построения граничной линии.
Эта машина опорных векторов в классификации представляет данные обучения в виде точек данных в пространстве, в котором многие категории разделены на категории гиперплоскости. Когда появляется новая точка, она классифицируется путем предсказания, к какой категории они относятся и принадлежат к определенному пространству.
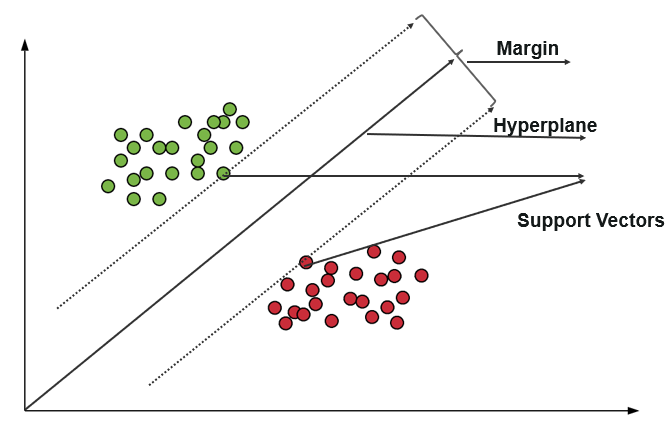
Источник
Основная цель машины опорных векторов — максимизировать разницу между двумя опорными векторами.
Присоединяйтесь к онлайн- курсу машинного обучения в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и продвинутой сертификационной программе в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
3. Классификация K-ближайших соседей (KNN)
Классификация KNN — один из самых простых алгоритмов классификации, но он широко используется из-за его высокой эффективности и простоты использования. В этом методе весь набор данных изначально хранится в машине. Затем выбирается значение –k, которое представляет количество соседей. Таким образом, когда новая точка данных добавляется в набор данных, она получает большинство голосов метки класса k ближайших соседей для этой новой точки данных. При этом голосовании новая точка данных добавляется к этому конкретному классу с наибольшим числом голосов.
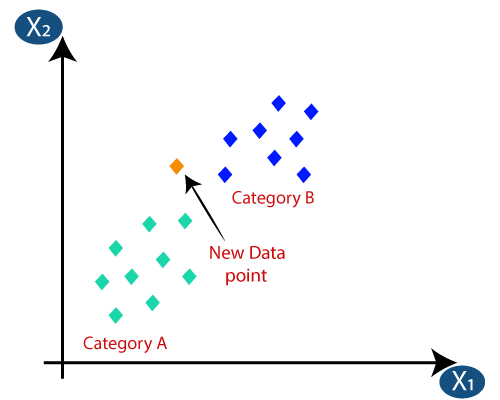
Источник
4. Ядро SVM
Как упоминалось выше, линейная машина опорных векторов может применяться только к линейным данным в природе. Однако все данные в мире не являются линейно разделимыми. Следовательно, нам нужно разработать машину опорных векторов для учета данных, которые также нелинейно разделимы. А вот и трюк с ядром, также известный как Kernel Support Vector Machine или Kernel SVM.
В Kernel SVM мы выбираем ядро, такое как RBF или Gaussian Kernel. Все точки данных сопоставляются с более высоким измерением, где они становятся линейно разделимыми. Таким образом, мы можем создать границу принятия решений между различными классами набора данных.
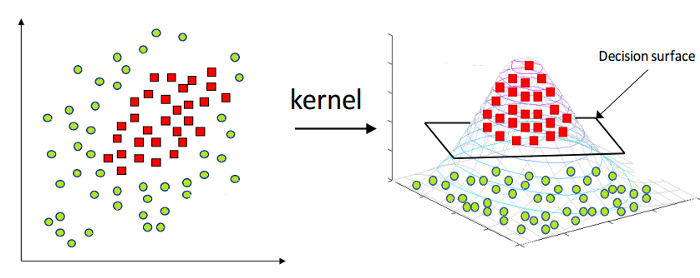
Источник
Следовательно, таким образом, используя базовые концепции машин опорных векторов, мы можем разработать Kernel SVM для нелинейных вычислений.
5. Наивная байесовская классификация
Наивная байесовская классификация имеет свои корни, принадлежащие теореме Байеса, предполагающей, что все независимые переменные (признаки) набора данных независимы. Они одинаково важны для предсказания результата. Это допущение теоремы Байеса дало название «Наивный». Он используется для различных задач, таких как фильтрация спама и другие области классификации текста. Наивный Байес вычисляет вероятность того, принадлежит ли точка данных определенной категории или нет.
Формула наивной байесовской классификации дается следующим образом:
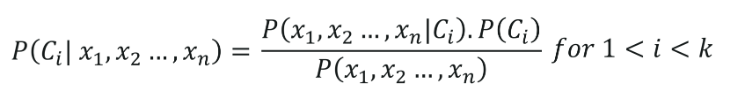
6. Классификация дерева решений
Дерево решений — это контролируемый алгоритм обучения, который идеально подходит для задач классификации, поскольку может упорядочивать классы на определенном уровне. Он работает в виде блок-схемы, где он разделяет точки данных на каждом уровне. Окончательная структура выглядит как дерево с узлами и листьями.

Источник
Узел решения будет иметь две или более ветвей, а лист представляет собой классификацию или решение. В приведенном выше примере дерева решений путем задания нескольких вопросов создается блок-схема, которая помогает нам решить простую проблему прогнозирования, выходить на рынок или нет.
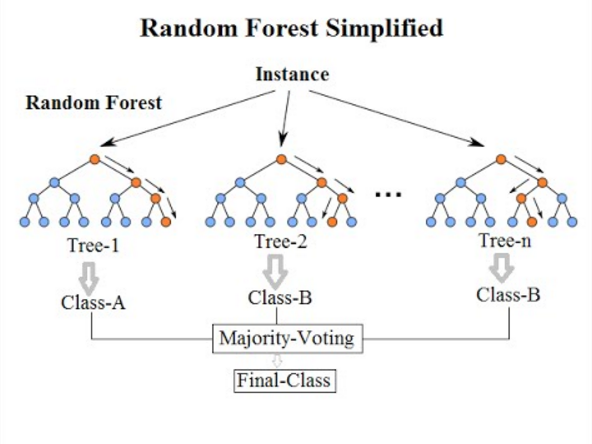
7. Классификация случайного леса
Переходя к последнему алгоритму классификации в этом списке, случайный лес является лишь расширением алгоритма дерева решений. Случайный лес — это ансамблевый метод обучения с несколькими деревьями решений. Он работает так же, как и деревья решений.
Источник
Алгоритм случайного леса является усовершенствованием существующего алгоритма дерева решений, который страдает от серьезной проблемы « переобучения ». Он также считается более быстрым и точным по сравнению с алгоритмом дерева решений.
Читайте также: Идеи и темы проекта машинного обучения
Заключение
Таким образом, в этой статье о методах машинного обучения для классификации мы поняли основы классификации и контролируемого обучения, типов и показателей оценки моделей классификации и, наконец, краткое изложение всех наиболее часто используемых моделей машинного обучения.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с программой Executive PG IIIT-B и upGrad по машинному обучению и искусственному интеллекту , которая предназначена для работающих профессионалов и предлагает более 450 часов интенсивного обучения, более 30 тематических исследований и заданий, IIIT -B статус выпускника, 5+ практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Q1. Какие алгоритмы чаще всего используются в машинном обучении?
В машинном обучении используется множество различных алгоритмов, которые можно разделить на три основных типа: алгоритмы обучения с учителем, алгоритмы обучения без учителя и алгоритмы обучения с подкреплением. Теперь, чтобы сузить и назвать некоторые из наиболее часто используемых алгоритмов, следует упомянуть линейную регрессию, логистическую регрессию, SVM, деревья решений, алгоритм случайного леса, kNN, наивную байесовскую теорию, K-средние, уменьшение размерности, и алгоритмы повышения градиента. Алгоритмы XGBoost, GBM, LightGBM и CatBoost заслуживают особого упоминания в алгоритмах повышения градиента. Эти алгоритмы могут применяться для решения практически любых проблем с данными.
Q2. Что такое классификация и регрессия в машинном обучении?
Алгоритмы классификации и регрессии широко используются в машинном обучении. Однако между ними есть много различий, которые в конечном итоге определяют их использование или назначение. Основное отличие состоит в том, что в то время как алгоритмы классификации используются для классификации или прогнозирования дискретных значений, таких как мужчина-женщина или правда-ложь, алгоритмы регрессии используются для прогнозирования недискретных, непрерывных значений, таких как зарплата, возраст, цена и т. д. Деревья решений, Случайный лес, Kernel SVM и логистическая регрессия являются одними из наиболее распространенных алгоритмов классификации, а простая и множественная линейная регрессия, регрессия опорных векторов, полиномиальная регрессия и регрессия дерева решений являются одними из самых популярных алгоритмов регрессии, используемых в машинном обучении.
Q3. Каковы предпосылки для обучения машинному обучению?
Чтобы начать с машинного обучения, вам не нужно быть опытным математиком или опытным программистом. Однако, учитывая обширность области, она может показаться пугающей, когда вы только собираетесь начать свое путешествие по машинному обучению. В таких случаях знание предварительных условий может помочь вам в плавном старте. Предварительные требования — это, по сути, основные навыки, которые необходимо приобрести для понимания концепций машинного обучения. Итак, прежде всего, убедитесь, что вы научились кодировать с помощью Python. Кроме того, дополнительным преимуществом будет базовое понимание статистики и математики, особенно линейной алгебры и многомерного исчисления.