
Как выбрать метод выбора признаков для машинного обучения
Опубликовано: 2021-06-22Оглавление
Введение в выбор функций
Модель машинного обучения использует множество функций, из которых важны лишь некоторые из них. Точность модели снижается, если для обучения модели данных используются ненужные функции. Кроме того, увеличивается сложность модели и снижается способность к обобщению, что приводит к необъективной модели. Поговорка «иногда меньше, да лучше» хорошо сочетается с концепцией машинного обучения. С этой проблемой сталкиваются многие пользователи, когда им трудно определить набор соответствующих функций из своих данных и игнорировать все нерелевантные наборы функций. Менее важные функции называются так, что они не влияют на целевую переменную.
Поэтому одним из важных процессов является выбор признаков в машинном обучении . Цель состоит в том, чтобы выбрать наилучший набор функций для разработки модели машинного обучения. Выбор функций оказывает огромное влияние на производительность модели. Наряду с очисткой данных выбор признаков должен быть первым шагом в разработке модели.
Выбор функций в машинном обучении можно резюмировать как
- Автоматический или ручной выбор тех функций, которые в наибольшей степени влияют на прогнозируемую переменную или выходные данные.
- Наличие нерелевантных функций может привести к снижению точности модели, поскольку она будет учиться на нерелевантных функциях.
Преимущества выбора функций
- Уменьшает переоснащение данных: меньшее количество данных приводит к меньшей избыточности. Поэтому меньше шансов принять решение по шуму.
- Повышает точность модели: с меньшей вероятностью вводящих в заблуждение данных повышается точность модели.
- Время обучения сокращается: удаление нерелевантных функций снижает сложность алгоритма, поскольку присутствует только меньшее количество точек данных. Поэтому алгоритмы обучаются быстрее.
- Сложность модели снижается за счет лучшей интерпретации данных.
Контролируемый и неконтролируемый методы выбора признаков
Основная цель алгоритмов выбора признаков — выбрать набор лучших признаков для разработки модели. Методы выбора признаков в машинном обучении можно разделить на методы с учителем и без учителя.
- Метод с учителем: метод с учителем используется для выбора признаков из размеченных данных, а также используется для классификации соответствующих признаков. Следовательно, повышается эффективность построенных моделей.
- Неконтролируемый метод : этот метод выбора признаков используется для неразмеченных данных.
Список контролируемых методов
Контролируемые методы выбора признаков в машинном обучении можно разделить на

1. Методы обертки
Этот тип алгоритма выбора функций оценивает процесс выполнения функций на основе результатов алгоритма. Также известный как жадный алгоритм, он итеративно обучает алгоритм, используя подмножество признаков. Критерии остановки обычно определяются человеком, обучающим алгоритм. Добавление и удаление функций в модели происходит на основе предварительного обучения модели. В этой стратегии поиска может применяться любой тип алгоритма обучения. Модели более точны по сравнению с методами фильтрации.
Методы, используемые в методах Wrapper:
- Прямой выбор. Процесс прямого выбора — это итеративный процесс, в котором новые функции, улучшающие модель, добавляются после каждой итерации. Он начинается с пустого набора функций. Итерация продолжается и останавливается до тех пор, пока не будет добавлена функция, которая больше не улучшает производительность модели.
- Обратный выбор/исключение: процесс представляет собой итеративный процесс, который начинается со всех функций. После каждой итерации из набора исходных признаков удаляются признаки с наименьшей значимостью. Критерий остановки итерации — когда производительность модели не улучшается после удаления функции. Эти алгоритмы реализованы в пакете mlxtend.
- Двунаправленное исключение : оба метода прямого выбора и метода обратного исключения применяются одновременно в методе двунаправленного исключения для достижения одного уникального решения.
- Исчерпывающий выбор функций: он также известен как метод грубой силы для оценки подмножеств функций. Создается набор возможных подмножеств и алгоритм обучения строится для каждого подмножества. Выбирается то подмножество, модель которого дает наилучшую производительность.
- Рекурсивное исключение признаков (RFE): этот метод называется жадным, поскольку он выбирает признаки, рекурсивно рассматривая все меньший и меньший набор признаков. Начальный набор функций используется для обучения оценщика, а их важность определяется с помощью атрибута feature_importance_attribute. Затем следует удаление наименее важных функций, оставляя только необходимое количество функций. Алгоритмы реализованы в пакете scikit-learn.
Рис. 4. Пример кода, показывающий технику рекурсивного устранения признаков
2. Встроенные методы
Встроенные методы выбора признаков в машинном обучении имеют определенное преимущество перед методами фильтров и оболочек, поскольку включают взаимодействие признаков, а также поддерживают разумные вычислительные затраты. Методы, используемые во встроенных методах:
- Регуляризация: модель избегает переобучения данных, добавляя штраф к параметрам модели. Коэффициенты добавляются со штрафом, в результате чего некоторые коэффициенты становятся равными нулю. Поэтому те признаки, которые имеют нулевой коэффициент, удаляются из набора признаков. Подход к выбору признаков использует Лассо (регуляризация L1) и эластичные сети (регуляризация L1 и L2).
- SMLR (разреженная полиномиальная логистическая регрессия): алгоритм реализует разреженную регуляризацию с помощью ARD prior (автоматическое определение релевантности) для классической многонациональной логистической регрессии. Эта регуляризация оценивает важность каждой функции и отсекает измерения, которые бесполезны для прогноза. Реализация алгоритма выполнена в SMLR.
- ARD (регрессия с автоматическим определением релевантности): алгоритм смещает веса коэффициентов в сторону нуля и основан на регрессии байесовского хребта. Алгоритм может быть реализован в scikit-learn.
- Важность случайного леса: этот алгоритм выбора объектов представляет собой агрегацию определенного количества деревьев. Стратегии на основе дерева в этом алгоритме ранжируются на основе увеличения примеси узла или уменьшения примеси (примеси Джини). Конец деревьев состоит из узлов с наименьшим уменьшением примеси, а начало деревьев состоит из узлов с наибольшим уменьшением примеси. Следовательно, важные функции могут быть выбраны путем обрезки дерева ниже определенного узла.
3. Методы фильтрации
Методы применяются на этапах предварительной обработки. Эти методы довольно быстрые и недорогие и лучше всего работают при удалении повторяющихся, коррелирующих и избыточных признаков. Вместо применения каких-либо контролируемых методов обучения важность признаков оценивается на основе присущих им характеристик. Вычислительная стоимость алгоритма меньше по сравнению с методами-оболочками выбора признаков. Однако, если нет достаточного количества данных для получения статистической корреляции между функциями, результаты могут быть хуже, чем у методов-оболочек. Следовательно, алгоритмы используются для данных высокой размерности, что может привести к более высоким вычислительным затратам, если будут применяться методы-оболочки.

Методы, используемые в методах фильтра :
- Прирост информации: прирост информации означает, сколько информации получено от функций для определения целевого значения. Затем он измеряет снижение значений энтропии. Прирост информации каждого атрибута рассчитывается с учетом целевых значений для выбора признаков.
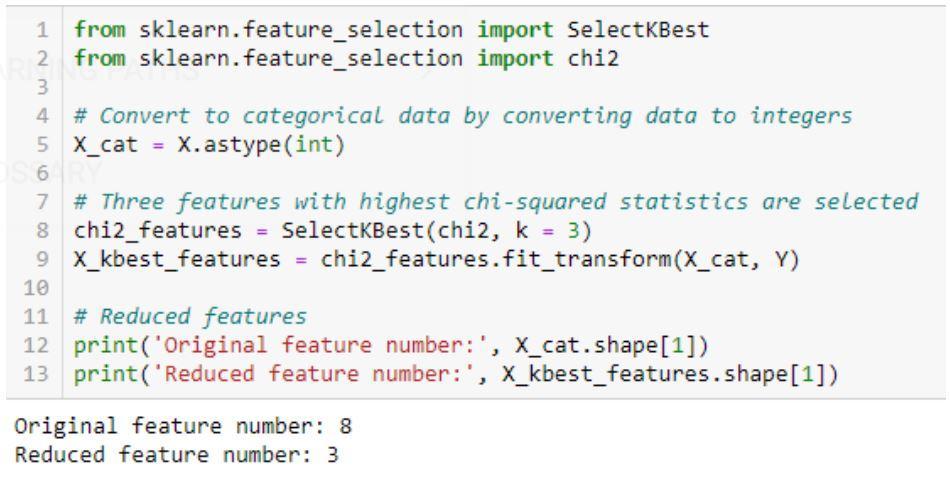
- Тест хи-квадрат: метод хи-квадрат (X 2 ) обычно используется для проверки взаимосвязи между двумя категориальными переменными. Тест используется для определения того, существует ли значительная разница между наблюдаемыми значениями различных атрибутов набора данных и его ожидаемым значением. Нулевая гипотеза утверждает, что между двумя переменными нет связи.
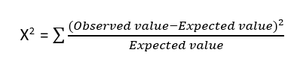
Источник
Формула для теста хи-квадрат
Реализация алгоритма хи-квадрат: sklearn, scipy
Пример кода для теста хи-квадрат
Источник
- CFS (выбор функций на основе корреляции): метод следует за « Реализация CFS (выбор признаков на основе корреляции): scikit-feature
Присоединяйтесь к онлайн- курсам по искусственному интеллекту и машинному обучению в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и программам повышения квалификации по машинному обучению и искусственному интеллекту, чтобы ускорить свою карьеру.
- FCBF (быстрый фильтр на основе корреляции): по сравнению с вышеупомянутыми методами Relief и CFS метод FCBF быстрее и эффективнее. Первоначально вычисление симметричной неопределенности выполняется для всех признаков. Затем с использованием этих критериев функции сортируются, а избыточные функции удаляются.
Симметричная неопределенность = прирост информации x | y разделить на сумму их энтропий. Реализация FCBF: skfeature
- Оценка Фишера: отношение Фишера (FIR) определяется как расстояние между средними значениями выборки для каждого класса по признаку, деленное на их дисперсии. Каждая функция выбирается независимо в соответствии с их оценками по критерию Фишера. Это приводит к неоптимальному набору функций. Чем выше показатель Фишера, тем лучше выбрана функция.
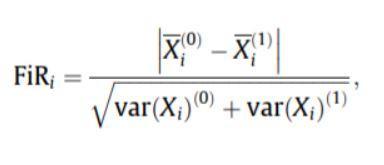
Источник
Формула для оценки Фишера
Реализация оценки Фишера: scikit-feature
Вывод кода, показывающего технику оценки Фишера
Источник
Коэффициент корреляции Пирсона: это мера количественной оценки связи между двумя непрерывными переменными. Значения коэффициента корреляции варьируются от -1 до 1, что определяет направление связи между переменными.
- Пороговое значение дисперсии: объекты, дисперсия которых не соответствует определенному пороговому значению, удаляются. С помощью этого метода удаляются признаки, имеющие нулевую дисперсию. Предполагается, что признаки с более высокой дисперсией, вероятно, содержат больше информации.
Рисунок 15: Пример кода, показывающий реализацию порога отклонения
- Средняя абсолютная разница (MAD): метод вычисляет среднюю абсолютную разницу
отличие от среднего значения.
Пример кода и его выходных данных, показывающих реализацию Mean Absolute Difference (MAD)
Источник
- Коэффициент дисперсии: Коэффициент дисперсии определяется как отношение среднего арифметического (AM) к среднему геометрическому (GM) для данного признака. Его значение колеблется от +1 до ∞, поскольку AM ≥ GM для данного признака.
Более высокий коэффициент дисперсии подразумевает более высокое значение Ri и, следовательно, более важную характеристику. И наоборот, когда Ri близко к 1, это указывает на низкую релевантность признака.
- Взаимная зависимость: метод используется для измерения взаимной зависимости между двумя переменными. Информация, полученная от одной переменной, может быть использована для получения информации о другой переменной.
- Лапласовская оценка: данные одного и того же класса часто близки друг к другу. Важность объекта можно оценить по его способности сохранять локальность. Вычисляется лапласианская оценка для каждой функции. Наименьшие значения определяют важные размеры. Реализация лапласианской оценки: scikit-feature.
Заключение
Выбор функций в процессе машинного обучения можно охарактеризовать как один из важных шагов на пути к разработке любой модели машинного обучения. Процесс алгоритма выбора признаков приводит к уменьшению размерности данных с удалением признаков, которые не имеют отношения или важны для рассматриваемой модели. Соответствующие функции могут ускорить время обучения моделей, что приведет к высокой производительности.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с программой Executive PG IIIT-B и upGrad по машинному обучению и искусственному интеллекту, которая предназначена для работающих профессионалов и предлагает более 450 часов интенсивного обучения, более 30 тематических исследований и заданий, IIIT -B статус выпускника, 5+ практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Чем метод фильтра отличается от метода-оболочки?
Метод оболочки помогает измерить, насколько полезны функции на основе производительности классификатора. Метод фильтрации, с другой стороны, оценивает внутренние качества функций, используя одномерную статистику, а не производительность перекрестной проверки, подразумевая, что они оценивают релевантность функций. В результате метод-оболочка более эффективен, поскольку оптимизирует производительность классификатора. Однако из-за повторяющихся процессов обучения и перекрестной проверки метод оболочки требует больших вычислительных ресурсов, чем метод фильтра.
Что такое последовательный выбор в машинном обучении?
Это своего рода последовательный выбор функций, хотя он намного дороже, чем выбор фильтра. Это метод жадного поиска, который итеративно выбирает функции на основе производительности классификатора, чтобы обнаружить идеальное подмножество функций. Он начинается с пустого подмножества функций и продолжает добавлять по одной функции в каждом раунде. Эта единственная функция выбирается из пула всех функций, которых нет в нашем подмножестве функций, и именно она обеспечивает наилучшую производительность классификатора в сочетании с другими.
Каковы ограничения использования метода фильтра для выбора признаков?
Подход с фильтром в вычислительном отношении менее затратен, чем методы выбора оболочек и встроенных признаков, но он имеет некоторые недостатки. В случае одномерных подходов эта стратегия часто игнорирует взаимозависимость признаков при выборе признаков и оценивает каждый признак независимо. По сравнению с двумя другими методами выбора функций это может иногда приводить к снижению производительности вычислений.