
Как мой веб-сайт на основе API помогает мне путешествовать по миру
Опубликовано: 2022-03-10(Это спонсируемый пост.) Недавно я решил восстановить свой личный веб-сайт, потому что ему было шесть лет, и он выглядел, мягко говоря, немного «устаревшим». Цель состояла в том, чтобы включить некоторую информацию о себе, область блога, список моих недавних побочных проектов и предстоящих событий.
Поскольку я время от времени работаю с клиентами, я не хотел иметь дело с одной вещью — с базами данных ! Раньше я создавал сайты на WordPress для всех, кто этого хотел. Часть программирования обычно доставляла мне удовольствие, но релизы, перемещение баз данных в разные среды и фактическая публикация всегда раздражали. Дешевые хостинг-провайдеры предлагают только плохие веб-интерфейсы для настройки баз данных MySQL, а FTP-доступ для загрузки файлов всегда был худшей частью. Я не хотел иметь дело с этим для моего личного веб-сайта.
Итак, требования, которые у меня были для редизайна, были:
- Современный стек технологий, основанный на JavaScript и фронтенд-технологиях.
- Решение для управления контентом, позволяющее редактировать контент из любого места.
- Хороший сайт с быстрыми результатами.
В этой статье я хочу показать вам, что я создал и как мой веб-сайт неожиданно стал моим ежедневным спутником.
Определение модели контента
Публикация вещей в сети кажется легкой. Выберите систему управления контентом (CMS), которая предоставляет WYSIWYG -редактор (« Что видишь , то и получаешь » ) для каждой необходимой страницы, и все редакторы могут легко управлять контентом. Вот так, верно?
После создания нескольких клиентских веб-сайтов, от небольших кафе до растущих стартапов, я понял, что святой WYSIWYG-редактор не всегда является серебряной пулей, которую мы все ищем. Эти интерфейсы призваны упростить создание веб-сайтов, но вот в чем суть:
Создание веб-сайтов — это непросто
Чтобы создавать и редактировать содержимое веб-сайта, не ломая его постоянно, вы должны хорошо знать HTML и хотя бы немного разбираться в CSS. Это не то, что вы можете ожидать от своих редакторов.
Я видел ужасные сложные макеты, созданные с помощью WYSIWYG-редакторов, и я не могу перечислить все ситуации, когда все разваливается из-за того, что система слишком хрупкая. Эти ситуации приводят к ссорам и дискомфорту, когда все стороны обвиняют друг друга в том, что было неизбежным. Я всегда старался избегать подобных ситуаций и создавать комфортную и стабильную среду для редакторов, чтобы избежать гневных электронных писем, кричащих: «Помогите! Все сломано».
Структурированный контент избавит вас от некоторых проблем
Я довольно быстро понял, что люди редко что-то ломают, когда я разбиваю весь необходимый контент веб-сайта на несколько кусков, каждый из которых связан друг с другом, не думая о каком-либо представлении. В WordPress этого можно добиться с помощью пользовательских типов записей. Каждый настраиваемый тип записи может включать в себя несколько свойств с собственным удобным для понимания текстовым полем. Я полностью похоронил концепцию мышления на страницах .
Моя работа заключалась в том, чтобы соединить части контента и построить веб-страницы из этих блоков контента. Это означало, что редакторы могли делать лишь небольшие визуальные изменения на своих веб-сайтах. Они отвечали за содержание и только за содержание. Визуальные изменения пришлось делать мне — не все могли стилизовать сайт, и мы могли избежать хрупкого окружения. Эта концепция казалась отличным компромиссом и обычно была хорошо принята.
Позже я обнаружил, что занимаюсь определением модели контента. Рэйчел Ловингер в своей превосходной статье «Моделирование контента: главный навык» определяет модель контента следующим образом:
«Модель контента документирует все различные типы контента, который у вас будет для данного проекта. Он содержит подробные определения элементов каждого типа контента и их отношения друг к другу».
Начало с моделирования контента сработало для большинства клиентов, за исключением одного.
«Стефан, я не определяю схему вашей базы данных!»
Идея этого единственного проекта заключалась в том, чтобы создать массивный веб-сайт, который должен создавать много органического трафика, предоставляя тонны контента — во всех вариантах, отображаемых на нескольких разных страницах и в разных местах. Я организовал встречу, чтобы обсудить нашу стратегию подхода к этому проекту.
Я хотел определить все страницы и модели контента, которые должны быть включены. Неважно, какой крошечный виджет или какую боковую панель имел в виду клиент, я хотел, чтобы это было четко определено. Моя цель состояла в том, чтобы создать прочную структуру контента, которая позволила бы предоставить простой в использовании интерфейс для редакторов и предоставить повторно используемые данные для их отображения в любом мыслимом формате.
Как оказалось, идея этого проекта была не очень ясна, и я не мог получить ответы на все свои вопросы. Руководитель проекта не понимал, что начинать надо с правильного моделирования контента (а не с дизайна и разработки). Для него это была просто тонна страниц. Дублированный контент и огромные текстовые области для добавления огромного количества текста не казались проблемой. По его мнению, вопросы, которые у меня были о структуре, носили технический характер, и они не должны были о них беспокоиться. Короче говоря, я не делал проект.
Важно то, что моделирование контента не связано с базами данных.
Речь идет о том, чтобы сделать ваш контент доступным и ориентированным на будущее. Если вы не сможете определить потребности в своем контенте на старте проекта, будет очень сложно, если вообще возможно, повторно использовать его позже.
Правильное моделирование контента является ключом к настоящим и будущим веб-сайтам.
Contentful: безголовая CMS
Было ясно, что я также хочу следовать хорошему моделированию контента для своего сайта. Однако была еще одна вещь. Я не хотел иметь дело со слоем хранения для создания моего нового веб-сайта, поэтому я решил использовать Contentful, безголовую CMS, над которой (полный отказ от ответственности!) я сейчас работаю. «Безголовый» означает, что этот сервис предлагает веб-интерфейс для управления контентом в облаке и предоставляет API, который возвращает мне мои данные в формате JSON. Выбор этой CMS помог мне сразу же начать продуктивно работать, так как через несколько минут у меня был доступен API, и мне не пришлось заниматься какой-либо настройкой инфраструктуры. Contentful также предоставляет бесплатный план, который идеально подходит для небольших проектов, таких как мой личный веб-сайт.
Пример запроса для получения всех сообщений в блоге выглядит следующим образом:
<a href="https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post">https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post</a>А ответ, в сокращенном варианте, выглядит так:
{ "sys": { "type": "Array" }, "total": 7, "skip": 0, "limit": 100, "items": [ { "sys": { "space": {...}, "id": "455OEfg1KUskygWUiKwmkc", "type": "Entry", "createdAt": "2016-07-29T11:53:52.596Z", "updatedAt": "2016-11-09T21:07:19.118Z", "revision": 12, "contentType": {...}, "locale": "en-US" }, "fields": { "title": "How to React to Changing Environments Using matchMedia", "excerpt": "...", "slug": "how-to-react-to-changing-environments-using-match-media", "author": [...], "body": "...", "date": "2014-12-26T00:00+02:00", "comments": true, "externalUrl": "https://4waisenkinder.de/blog/2014/12/26/handle-environment-changes-via-window-dot-matchmedia/" }, {...}, {...}, {...}, {...}, {...}, {...} ] } }Отличительной чертой Contentful является то, что он отлично подходит для моделирования контента, что мне и требовалось. Используя предоставленный веб-интерфейс, я могу быстро определить все необходимые элементы контента. Определение конкретной модели контента в Contentful называется типом контента. Здесь важно отметить возможность моделировать отношения между элементами контента. Например, я могу легко связать автора с сообщением в блоге. Это может привести к структурированным деревьям данных, которые идеально подходят для повторного использования в различных случаях.
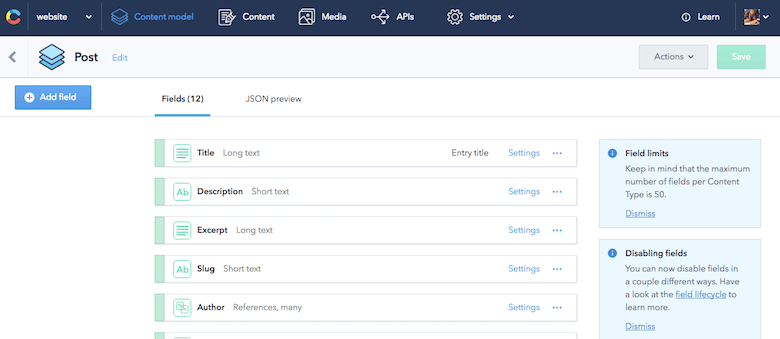
Итак, я настроил свою модель контента, не думая о каких-либо страницах, которые я, возможно, захочу создать в будущем.
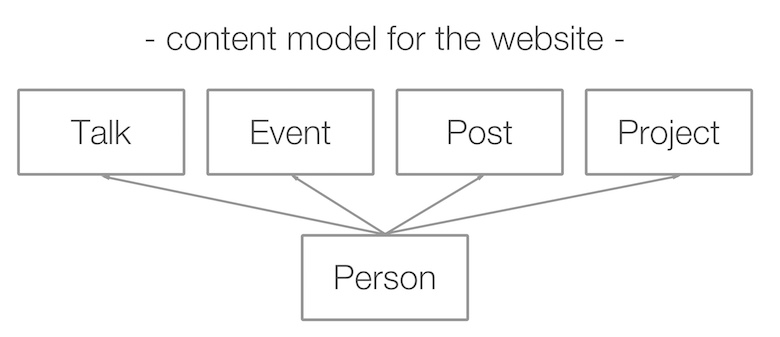
Следующим шагом было выяснить, что я хочу делать с этими данными. Я спросил у знакомого дизайнера, и он придумал индексную страницу сайта со следующей структурой.
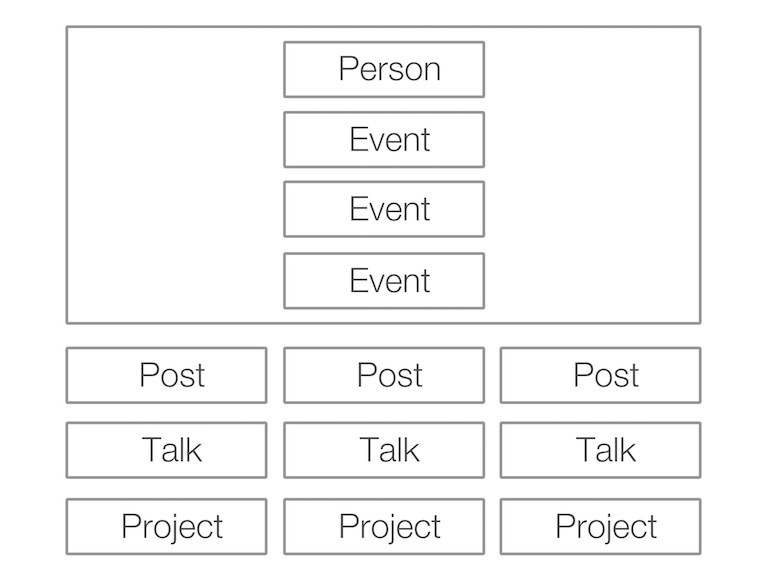
Рендеринг HTML-страниц с помощью Node.js
Теперь самое сложное. Пока мне не приходилось иметь дело с хранилищем и базами данных, что было для меня большим достижением. Итак, как я могу создать свой веб-сайт, если у меня есть только доступный API?
Первым моим подходом был подход «сделай сам». Я начал писать простой скрипт Node.js, который извлекал данные и отображал из них некоторый HTML.
Предварительный рендеринг всех HTML-файлов удовлетворил одно из моих основных требований. Статический HTML можно обслуживать очень быстро.
Итак, давайте посмотрим на сценарий, который я использовал.
'use strict'; const contentful = require('contentful'); const template = require('lodash.template'); const fs = require('fs'); // create contentful client with particular credentials const client = contentful.createClient({ space: 'your_space_id', accessToken: 'your_token' }); // cache templates to not read // them over and over again const TEMPLATES = { index : template(fs.readFileSync(`${__dirname}/templates/index.html`)) }; // fetch all the data Promise.all([ // get posts client.getEntries({content_type: 'content_type_post_id'}), // get events client.getEntries({content_type: 'content_type_event_id'}), // get projects client.getEntries({content_type: 'content_type_project_id'}), // get talk client.getEntries({content_type: 'content_type_talk_id'}), // get specific person client.getEntries({'sys.id': 'person_id'}) ]) .then(([posts, events, projects, talks, persons]) => { const renderedHTML = TEMPLATES.index({ posts, events, projects, talks, person : persons.items[0] }) fs.writeFileSync(`${__dirname}/build/index.html`, renderedHTML); console.log('Rendered HTML'); }) .catch(console.error); <!doctype html> <html lang="en"> <head> <!-- ... --> </head> <body> <!-- ... --> <h2>Posts</h2> <ul> <% posts.items.forEach( function( talk ) { %> <li><%- talk.fields.title %> <% }) %> </ul> <!-- ... --> </body> </html>Это сработало нормально. Я мог создать желаемый веб-сайт совершенно гибким способом, принимая все решения о файловой структуре и функциональности. Рендеринг разных типов страниц с совершенно разными наборами данных вообще не проблема. Каждый, кто боролся против правил и структуры существующей CMS, которая поставляется с HTML-рендерингом, знает, что полная свобода может быть отличной вещью. Особенно, когда модель данных со временем становится более сложной, включая множество отношений — гибкость окупается.
В этом сценарии Node.js создается клиент Contentful SDK, и все данные извлекаются с помощью клиентского метода getEntries . Все предоставляемые методы клиента управляются промисами, что позволяет легко избежать глубоко вложенных обратных вызовов. Для создания шаблонов я решил использовать шаблонизатор lodash. Наконец, для чтения и записи файлов Node.js предлагает собственный модуль fs , который затем используется для чтения шаблонов и записи отображаемого HTML.
Однако у этого подхода был один недостаток; это было очень просто. Даже когда этот метод был полностью гибким, это было похоже на изобретение велосипеда. То, что я создавал, было в основном генератором статических сайтов, и их уже существует множество. Пришло время начать все сначала.
Переход к реальному генератору статических сайтов
Известные генераторы статических сайтов, например, Jekyll или Middleman, обычно имеют дело с файлами Markdown, которые будут преобразованы в HTML. Редакторы работают с ними, а веб-сайт создается с помощью команды CLI. Однако этот подход не соответствовал одному из моих первоначальных требований. Я хотел иметь возможность редактировать сайт, где бы я ни находился, не полагаясь на файлы, хранящиеся на моем личном компьютере.
Моей первой идеей было визуализировать эти файлы Markdown с помощью API. Хотя это сработало бы, это казалось неправильным. Рендеринг файлов Markdown для последующего преобразования в HTML все еще был двумя шагами, которые не давали больших преимуществ по сравнению с моим первоначальным решением.

К счастью, существуют интеграции Contentful, например, для Metalsmith и Middleman. Я выбрал Metalsmith для этого проекта, так как он написан на Node.js, и я не хотел привносить зависимость от Ruby.
Metalsmith преобразует файлы из исходной папки и отображает их в папке назначения. Эти файлы не обязательно должны быть файлами Markdown. Вы также можете использовать его для транспиляции Sass или оптимизации ваших изображений. Нет никаких ограничений, и это действительно гибко.
Используя интеграцию Contentful, я смог определить некоторые исходные файлы, которые были взяты в качестве файлов конфигурации, а затем мог получить все необходимое из API.
--- title: Blog contentful: content_type: content_type_id entry_filename_pattern: ${ fields.slug } entry_template: article.html order: '-fields.date' filter: include: 5 layout: blog.html description: >- Recent articles by Stefan Judis. --- В этом примере конфигурации отображается область сообщения блога с родительским файлом blog.html , включая ответ на запрос API, а также несколько дочерних страниц с использованием шаблона article.html . Имена файлов для дочерних страниц определяются через entry_filename_pattern .
Как видите, с помощью чего-то подобного я могу легко создавать свои страницы. Эта настройка отлично работала, чтобы все страницы зависели от API.
Подключите сервис к вашему проекту
Единственной недостающей частью было подключение сайта к службе CMS и повторная визуализация при редактировании любого контента. Решение этой проблемы — вебхуки, с которыми вы, возможно, уже знакомы, если используете такие сервисы, как GitHub.
Веб-перехватчики — это запросы, сделанные программным обеспечением в качестве службы к ранее определенной конечной точке, которые уведомляют вас о том, что что-то произошло. GitHub, например, может отправлять вам ответные сообщения, когда кто-то открывает запрос на извлечение в одном из ваших репозиториев. Что касается управления контентом, мы можем применить здесь тот же принцип. Всякий раз, когда что-то происходит с контентом, пингуйте конечную точку и заставляйте определенную среду реагировать на это. В нашем случае это будет означать повторную визуализацию HTML с помощью metalsmith.
Чтобы принимать вебхуки, я также использовал решение JavaScript. Мой выбор хостинг-провайдера (Uberspace) позволяет установить Node.js и использовать JavaScript на стороне сервера.
const http = require('http'); const exec = require('child_process').exec; const server = http.createServer((req, res) => { res.setHeader('Content-Type', 'text/plain'); // check for secret header // to not open up this endpoint for everybody if (req.headers.secret === 'YOUR_SECRET') { res.end('ok'); // wait for the CDN to // invalidate the data setTimeout(() => { // execute command exec('npm start', { cwd: __dirname }, (error) => { if (error) { return console.log(error); } console.log('Rebuilt success'); }); }, 1000 * 120 ); } else { res.end('Not allowed'); } }); console.log('Started server at 8000'); server.listen(8000); Этот сценарий запускает простой HTTP-сервер на порту 8000. Он проверяет входящие запросы на наличие правильного заголовка, чтобы убедиться, что это веб-перехватчик от Contentful. Если запрос подтверждается как веб-перехватчик, выполняется предопределенная команда npm start для повторного рендеринга всех HTML-страниц. Вы можете задаться вопросом, почему существует тайм-аут. Это необходимо для временной приостановки действий до тех пор, пока данные в облаке не станут недействительными, поскольку сохраненные данные обслуживаются из CDN.
В зависимости от вашей среды этот HTTP-сервер может быть недоступен в Интернете. Мой сайт обслуживается с помощью сервера Apache, поэтому мне нужно было добавить внутреннее правило перезаписи, чтобы сделать работающий сервер node доступным для Интернета.
# add node endpoint to enable webhooks RewriteRule ^rerender/(.*) https://localhost:8000/$1 [P]API-First и структурированные данные: лучшие друзья навсегда
На данный момент я мог управлять всеми своими данными в облаке, и мой веб-сайт реагировал соответствующим образом после изменений.
Повторение повсюду
Нахождение в дороге — важная часть моей жизни, поэтому мне необходимо было иметь информацию, такую как местонахождение данного места или отель, который я забронировал, прямо у меня под рукой — обычно хранящийся в электронной таблице Google. Теперь информация была разбросана по электронной таблице, нескольким электронным письмам, моему календарю, а также на моем веб-сайте.
Я должен был признать, что я создал много дублирования данных в своем ежедневном потоке.
Момент структурированных данных
Я мечтал о едином источнике правды, (желательно на моем телефоне), чтобы быстро видеть, какие события приближаются, а также получать дополнительную информацию об отелях и площадках. События, перечисленные на моем веб-сайте, на данный момент не содержат всей информации, но добавить новые поля к типу контента в Contentful очень просто. Итак, я добавил нужные поля в тип контента «Событие».
Размещение этой информации в CMS моего веб-сайта никогда не входило в мои намерения, поскольку она не должна отображаться в Интернете, но доступ к ней через API заставил меня понять, что теперь я могу делать с этими данными совершенно другие вещи.
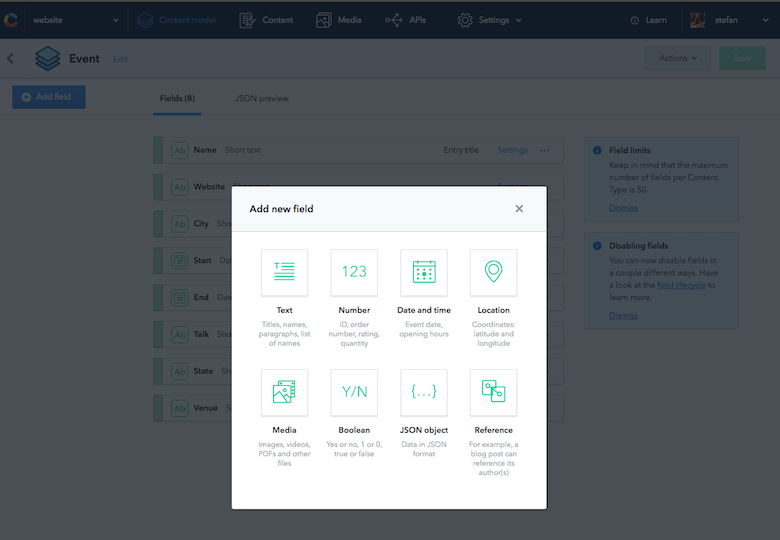
Создание нативного приложения с помощью JavaScript
Создание приложений для мобильных устройств является актуальной темой уже много лет, и существует несколько подходов к этому. Прогрессивные веб-приложения (PWA) — особенно горячая тема в наши дни. Используя Service Workers и манифест веб-приложения, можно создавать полноценные интерфейсы, подобные приложениям, начиная от значка на главном экране и заканчивая управляемым поведением в автономном режиме с использованием веб-технологий.
Стоит отметить один недостаток. Прогрессивные веб-приложения находятся на подъеме, но еще не полностью. Сервисные работники, например, сегодня не поддерживаются в Safari и пока «находятся на рассмотрении» со стороны Apple. Это было для меня препятствием, так как я хотел иметь автономное приложение и для iPhone.
Поэтому я искал альтернативы. Мой друг очень увлекался NativeScript и постоянно рассказывал мне об этой довольно новой технологии. NativeScript — это фреймворк с открытым исходным кодом для создания действительно нативных мобильных приложений с помощью JavaScript, поэтому я решил попробовать его.
Знакомство с NativeScript
Настройка NativeScript занимает некоторое время, потому что вам нужно установить множество вещей для разработки для нативных мобильных сред. Вы будете руководствоваться процессом установки при первой установке инструмента командной строки NativeScript с помощью npm install nativescript -g .
Затем вы можете использовать команды создания шаблонов для настройки новых проектов: tns create MyNewApp
Однако это не то, что я сделал. Я просматривал документацию и наткнулся на пример приложения для управления продуктами, созданного на NativeScript. Поэтому я взял это приложение, копался в коде и шаг за шагом модифицировал его, подгоняя под свои нужды.
Я не хочу погружаться слишком глубоко в процесс, но составление списка поиска со всей необходимой мне информацией не заняло много времени.
NativeScript очень хорошо работает вместе с Angular 2, который я не хотел пробовать на этот раз, так как открытие самого NativeScript казалось достаточно большим. В NativeScript вы должны написать «Просмотры». Каждое представление состоит из XML-файла, определяющего базовый макет, а также дополнительных JavaScript и CSS. Все они определены в одной папке для каждого вида.
Отображение простого списка может быть достигнуто с помощью шаблона XML, подобного этому:
<!-- call JavaScript function when ready --> <Page loaded="loaded"> <ActionBar title="All Travels" /> <!-- make it scrollable when going too big --> <ScrollView> <!-- iterate over the entries in context --> <ListView items="{{ entries }}"> <ListView.itemTemplate> <Label text="{{ fields.name }}" textWrap="true" class="headline"/> </ListView.itemTemplate> </ListView> </ScrollView> </Page> Первое, что здесь происходит, — это определение элемента страницы. Внутри этой страницы я определил ActionBar , чтобы придать ей классический вид Android, а также правильный заголовок. Создание вещей для нативной среды иногда может быть немного сложным. Например, чтобы добиться рабочего поведения прокрутки, вы должны использовать «ScrollView». Последнее, что нужно сделать, это просто перебрать мои события с помощью ListView . В целом, это было довольно просто!
Но откуда берутся эти записи, которые используются в представлении? Оказывается, для этого можно использовать объект общего контекста. Читая XML для представления, вы, возможно, уже заметили, что страница имеет loaded атрибутов load. Устанавливая этот атрибут, я сообщаю представлению о вызове определенной функции JavaScript при загрузке страницы.
Эта функция JavaScript определена в соответствующем файле JS. Его можно сделать доступным, просто экспортировав его с помощью exports.something . Чтобы добавить привязку данных, все, что нам нужно сделать, это установить новый Observable в свойство страницы bindingContext . Наблюдаемые объекты в NativeScript генерируют события propertyChange , которые необходимы для реагирования на изменения данных внутри представления, но вам не нужно об этом беспокоиться, так как это работает из коробки.
const context = new Observable({ entries: null}); const fetchModule = require('fetch'); // export loaded to be called from // List.xml when everything is loaded exports.loaded = (args) => { const page = args.object; page.bindingContext = context; fetchModule.fetch( `https://cdn.contentful.com/spaces/${config.space}/entries?access_token=${config.cda.token}&content_type=event&order=fields.start`, { method: "GET", headers: { 'Content-Type': 'application/json' } } ) .then(response => response.json()) .then(response => context.set('entries', response.items)); } Последнее, что нужно сделать, это получить данные и установить их в контексте. Это можно сделать с помощью модуля fetch NativeScript. Здесь вы можете увидеть результат.
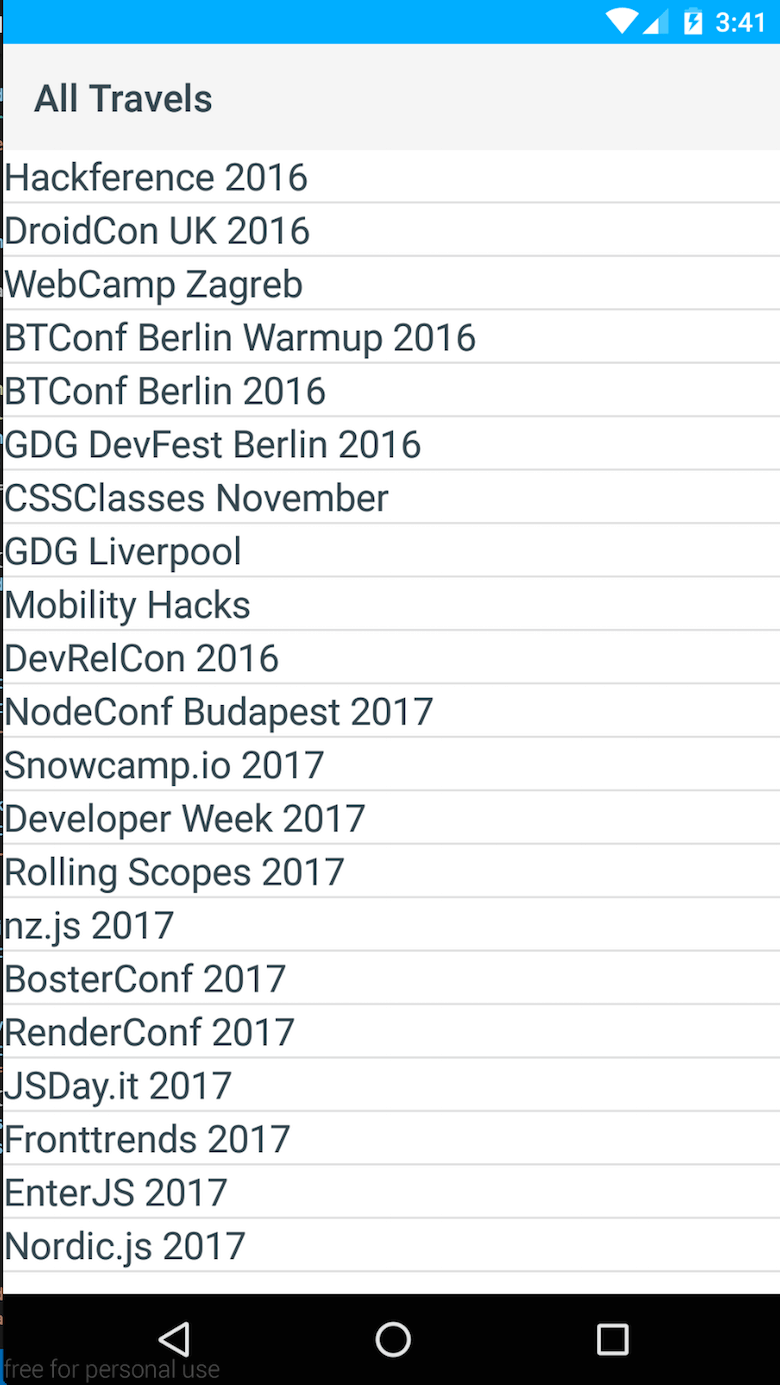
Итак, как видите, создать простой список с помощью NativeScript не так уж и сложно. Позже я расширил приложение другим представлением, а также дополнительными функциями, чтобы открывать заданные адреса в Картах Google и веб-представлениях для просмотра веб-сайтов событий.
Здесь следует отметить одну вещь: NativeScript все еще довольно новый, а это означает, что плагины, найденные в npm, обычно не имеют большого количества загрузок или звезд на GitHub. Сначала это меня раздражало, но я использовал несколько нативных компонентов (nativescript-floatingactionbutton, nativescript-advanced-webview и nativescript-pulltorefresh), которые помогли мне получить нативный опыт, и все работало отлично.
Вы можете увидеть улучшенный результат здесь:
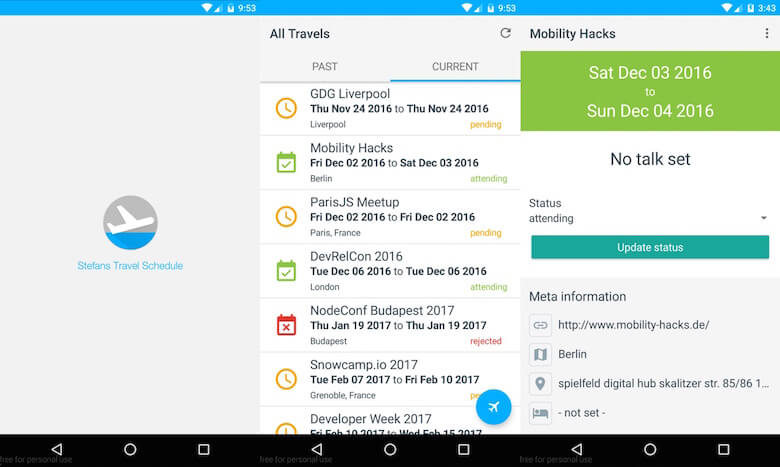
Чем больше функций я добавлял в это приложение, тем больше оно мне нравилось и тем больше я им пользовался. Самое приятное то, что я мог избавиться от дублирования данных, управляя всеми данными в одном месте, и при этом быть достаточно гибким, чтобы отображать их для различных вариантов использования.
Страницы — это вчерашний день: да здравствует структурированный контент!
Создание этого приложения еще раз показало мне, что принцип наличия данных в формате страницы ушел в прошлое. Мы не знаем, куда пойдут наши данные — мы должны быть готовы к неограниченному количеству вариантов использования.
Оглядываясь назад, я достиг:
- Наличие системы управления контентом в облаке
- Не нужно иметь дело с обслуживанием базы данных
- Полный стек технологий JavaScript
- Наличие эффективного статического веб-сайта
- Наличие приложения для Android для доступа к моему контенту всегда и везде
И самая важная часть:
Структурированный и доступный контент помог мне улучшить мою повседневную жизнь.
Этот вариант использования может показаться вам тривиальным прямо сейчас, но когда вы думаете о продуктах, которые вы создаете каждый день, всегда есть больше вариантов использования вашего контента на разных платформах. Сегодня мы согласны с тем, что мобильные устройства, наконец, вытесняют настольные компьютеры старой школы, но такие платформы, как автомобили, часы и даже холодильники, уже ждут своего внимания. Я даже не могу думать о вариантах использования, которые придут.
Итак, давайте постараемся быть готовыми и поместить структурированный контент в середину, потому что, в конце концов, речь идет не о схемах базы данных, а о построении на будущее.
Дальнейшее чтение на SmashingMag:
- Парсинг веб-страниц с помощью Node.js
- Плавание с Sails.js: фреймворк в стиле MVC для Node.js
- 40 иконок для путешествий, которые украсят ваш дизайн
- Подробное введение в Webpack