
10 лучших команд Hadoop [с использованием]
Опубликовано: 2021-01-29В эту эпоху, когда объемы данных огромны, становится необходимо иметь с ними дело. Данные, поступающие от организаций с растущими клиентами, намного больше, чем может хранить любой традиционный инструмент управления данными. Это оставляет нас перед вопросом управления большими наборами данных, которые могут варьироваться от гигабайтов до петабайтов, без использования одного большого компьютера или традиционного инструмента управления данными.
Именно здесь в центре внимания находится инфраструктура Apache Hadoop. Прежде чем погрузиться в реализацию команд Hadoop, давайте кратко рассмотрим структуру Hadoop и ее важность.
Оглавление
Что такое Хадуп?
Hadoop обычно используется крупными бизнес-организациями для решения различных проблем, от ежедневного хранения больших ГБ (гигабайт) данных до вычислительных операций с данными.
Традиционно определяемый как программная среда с открытым исходным кодом, используемая для хранения данных и обработки приложений, Hadoop довольно сильно отличается от большинства традиционных инструментов управления данными. Он повышает вычислительную мощность и расширяет лимит хранения данных, добавляя несколько узлов в структуру, что делает ее высокомасштабируемой. Кроме того, ваши данные и процессы приложений защищены от различных аппаратных сбоев.
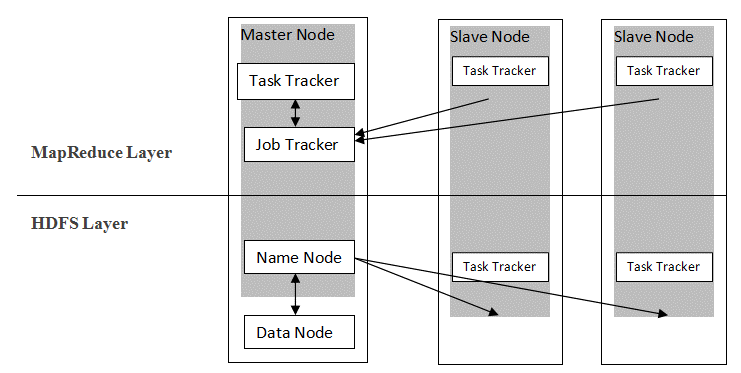
Hadoop использует архитектуру master-slave для распространения и хранения данных с использованием MapReduce и HDFS. Как показано на рисунке ниже, архитектура настроена определенным образом для выполнения операций управления данными с использованием четырех основных узлов, а именно Name, Data, Master и Slave. Основные компоненты Hadoop создаются непосредственно поверх платформы. Другие компоненты интегрируются непосредственно с сегментами.
 Источник
Источник

Команды Hadoop
Основные функции платформы Hadoop демонстрируют согласованный характер, и она становится более удобной для пользователя, когда дело доходит до управления большими данными с изучением команд Hadoop. Ниже приведены некоторые удобные команды Hadoop, которые позволяют выполнять различные операции, такие как управление и обработка файлов кластеров HDFS. Этот список команд часто требуется для достижения определенных результатов процесса.
1. Хадуп Тачз
hadoop fs -touchz /каталог/имя файла
Эта команда позволяет пользователю создать новый файл в кластере HDFS. «Каталог» в команде относится к имени каталога, в котором пользователь хочет создать новый файл, а «имя файла» означает имя нового файла, который будет создан после выполнения команды.
2. Тестовая команда Hadoop
hadoop fs -test -[defsz] <путь>
Эта конкретная команда выполняет цель проверки существования файла в кластере HDFS. Символы из «[defsz]» в команде должны быть изменены по мере необходимости. Вот краткое описание этих персонажей:
- d -> Проверяет, является ли это каталогом или нет
- e -> Проверяет, является ли это путем или нет
- f -> Проверяет, является ли это файлом или нет
- s -> Проверяет, является ли это пустым путем или нет
- r -> Проверяет наличие пути и разрешение на чтение
- w -> Проверяет наличие пути и разрешение на запись
- z -> Проверяет размер файла
3. Текстовая команда Hadoop
hadoop fs -text <источник>
Команда text особенно полезна для отображения выделенного zip-файла в текстовом формате. Он работает, обрабатывая исходные файлы и предоставляя их содержимое в формате простого декодированного текста.

4. Команда поиска Hadoop
hadoop fs -find <путь> … <выражение>
Эта команда обычно используется для поиска файлов в кластере HDFS. Он сканирует данное выражение в команде со всеми файлами в кластере и отображает файлы, соответствующие определенному выражению.
Читайте: Лучшие инструменты Hadoop
5. Команда Hadoop Getmerge
hadoop fs -getmerge <источник> <локальный>
Команда Getmerge позволяет объединить один или несколько файлов в указанном каталоге в кластере файловой системы HDFS. Он собирает файлы в один файл, расположенный в локальной файловой системе. «src» и «localdest» представляют значение источника-назначения и локального назначения.
6. Команда подсчета Hadoop
hadoop fs -count [параметры] <путь>
Как видно из названия, команда Hadoop count подсчитывает количество файлов и байтов в данном каталоге. Доступны различные параметры, которые изменяют вывод в соответствии с требованиями. Вот они:
- q -> квота показывает ограничение на общее количество имен и использование пространства
- u -> отображает только квоту и использование
- h -> дает размер файла
- v -> отображает заголовок
7. Команда Hadoop AppendToFile
hadoop fs -appendToFile <localsrc> <dest>
Это позволяет пользователю добавлять содержимое одного или нескольких файлов в один файл в указанном целевом файле в кластере файловой системы HDFS. При выполнении этой команды указанные исходные файлы добавляются в целевой источник в соответствии с именем файла, указанным в команде.
8. Команда Hadoop ls
hadoop fs -ls /путь
Команда ls в Hadoop показывает список файлов/содержимого в указанном каталоге, т. е. пути. При добавлении «R» перед /path в выводе будут отображаться сведения о содержимом, такие как имена, размер, владелец и т. д., для каждого файла, указанного в данном каталоге.
9. Команда Hadoop mkdir
hadoop fs -mkdir /путь/имя_каталога
Уникальной особенностью этой команды является создание каталога в кластере файловой системы HDFS, если каталог не существует. Кроме того, если указанный каталог присутствует, то в выходном сообщении будет отображаться ошибка, указывающая на существование каталога.
10. Команда Hadoop chmod
hadoop fs -chmod [-R] <режим> <путь>
Эта команда используется, когда есть необходимость изменить права доступа к тому или иному файлу. При подаче команды chmod изменяется разрешение указанного файла. Однако важно помнить, что разрешение будет изменено, когда владелец файла выполнит эту команду.
Читайте также: Учебное пособие по Impala Hadoop
Заключение
Начиная с важной проблемы хранения данных, с которой сталкиваются крупные организации в современном мире, в этой статье обсуждалось решение для ограниченного хранения данных с помощью Hadoop и его влияние на выполнение операций управления данными с помощью команд Hadoop. Для новичков в Hadoop описан обзор фреймворка вместе с его компонентами и архитектурой.

Прочитав эту статью, можно легко быть уверенным в своих знаниях в аспекте фреймворка Hadoop и его прикладных команд. Эксклюзивная сертификация PG в области больших данных от upGrad: upGrad предлагает отраслевую 7,5-месячную программу сертификации PG в области больших данных, в рамках которой вы будете организовывать, анализировать и интерпретировать большие данные с помощью IIIT-Bangalore.
Разработанный специально для работающих профессионалов, он поможет студентам получить практические знания и будет способствовать их вхождению в роли больших данных.
Основные моменты программы:
- Изучение соответствующих языков и инструментов
- Изучение передовых концепций распределенного программирования, платформ больших данных, баз данных, алгоритмов и веб-майнинга
- Аккредитованный сертификат от IIIT Bangalore
- Помощь в трудоустройстве, чтобы попасть в топ-МНК
- Наставничество 1:1 для отслеживания вашего прогресса и помощи на каждом этапе
- Работа над живыми проектами и заданиями
Требования : математика/программная инженерия/статистика/аналитика.
Ознакомьтесь с другими нашими курсами по программной инженерии на upGrad.