
Учебник по GraphQL: эволюция дизайна API (часть 2)
Опубликовано: 2022-03-10В части 1 мы рассмотрели, как API развивались за последние несколько десятилетий и как каждый из них уступал место другому. Мы также говорили о некоторых конкретных недостатках использования REST для разработки мобильных клиентов. В этой статье я хочу посмотреть, куда, по-видимому, движется дизайн API для мобильных клиентов, с особым акцентом на GraphQL.
Конечно, есть много людей, компаний и проектов, которые годами пытались устранить недостатки REST: HAL, Swagger/OpenAPI, OData JSON API и десятки других небольших или внутренних проектов стремились навести порядок в REST. мир REST без спецификаций. Вместо того, чтобы принимать мир таким, какой он есть, и предлагать постепенные улучшения или пытаться собрать достаточно разрозненных частей, чтобы превратить REST в то, что мне нужно, я хотел бы провести мысленный эксперимент. Учитывая понимание методов, которые работали и не работали в прошлом, я хотел бы использовать сегодняшние ограничения и наши гораздо более выразительные языки, чтобы попытаться набросать API, который нам нужен. Давайте отталкиваться от опыта разработчика, а не от реализации вперед (я смотрю на ваш SQL).
Минимальный HTTP-трафик
Мы знаем, что стоимость каждого сетевого запроса (HTTP/1) высока по целому ряду параметров, от задержки до времени автономной работы. В идеале клиентам нашего нового API потребуется способ запрашивать все данные, которые им нужны, за минимально возможное количество циклов.
Минимальная полезная нагрузка
Мы также знаем, что средний клиент ограничен в ресурсах, в пропускной способности, ЦП и памяти, поэтому наша цель должна состоять в том, чтобы отправлять только ту информацию, которая нужна нашему клиенту. Для этого нам, вероятно, понадобится способ, с помощью которого клиент может запрашивать определенные фрагменты данных.
Человек читаемый
Из дней SOAP мы узнали, что с API непросто взаимодействовать, люди будут гримасничать при его упоминании. Команды инженеров хотят использовать те же инструменты, на которые мы полагались годами, такие как curl , wget и Charles , а также вкладку сети в наших браузерах.
Богатый инструментарий
Еще одна вещь, которую мы узнали из XML-RPC и SOAP, заключается в том, что контракты клиент/сервер и системы типов, в частности, удивительно полезны. Если это вообще возможно, любой новый API будет иметь легкость формата, такого как JSON или YAML, с возможностью самоанализа более структурированных и типобезопасных контрактов.
Сохранение локального мышления
За прошедшие годы мы пришли к соглашению о некоторых руководящих принципах организации больших кодовых баз, основным из которых является «разделение задач». К сожалению, для большинства проектов это имеет тенденцию ломаться в виде уровня централизованного доступа к данным. Если возможно, разные части приложения должны иметь возможность управлять собственными потребностями в данных наряду с другими функциями.
Поскольку мы разрабатываем ориентированный на клиента API, давайте начнем с того, как может выглядеть получение данных в таком API. Если мы знаем, что нам нужно сделать как можно меньше обходов и что нам нужно иметь возможность отфильтровывать поля, которые нам не нужны, нам нужен способ как для обхода больших наборов данных, так и для запроса только тех их частей, которые нам нужны. полезно для нас. Язык запросов, кажется, хорошо подходит здесь.
Нам не нужно задавать вопросы о наших данных так же, как вы делаете это с базой данных, поэтому императивный язык, такой как SQL, кажется неподходящим инструментом. На самом деле, наша основная цель состоит в том, чтобы обойти уже существующие отношения и ограничить поля, которые мы должны быть в состоянии сделать с помощью чего-то относительно простого и декларативного. В отрасли достаточно хорошо зарекомендовали себя JSON для недвоичных данных, поэтому давайте начнем с JSON-подобного языка декларативных запросов. Мы должны уметь описывать нужные нам данные, и сервер должен возвращать JSON, содержащий эти поля.

Декларативный язык запросов удовлетворяет требованиям как минимальной полезной нагрузки, так и минимального HTTP-трафика, но у него есть еще одно преимущество, которое поможет нам в решении других задач проектирования. Многими декларативными языками, запросами и прочими, можно эффективно манипулировать, как если бы они были данными. Если мы будем тщательно проектировать, наш язык запросов позволит разработчикам разбивать большие запросы на части и рекомбинировать их любым способом, который имеет смысл для их проекта. Использование такого языка запросов помогло бы нам двигаться к нашей конечной цели — сохранению локального мышления.
Есть много интересных вещей, которые вы можете сделать, когда ваши запросы станут «данными». Например, вы можете перехватывать все запросы и группировать их аналогично тому, как виртуальный DOM пакетно обновляет DOM, вы также можете использовать компилятор для извлечения небольших запросов во время сборки для предварительного кэширования данных или вы можете создать сложную систему кэширования. как Кэш Аполлона.
Последний пункт в списке пожеланий API — инструменты. Мы уже получаем некоторые из них, используя язык запросов, но настоящая сила приходит, когда вы соединяете его с системой типов. С простой типизированной схемой на сервере есть почти бесконечные возможности для богатого инструментария. Запросы могут быть статически проанализированы и проверены на соответствие контракту, интеграция с IDE может предоставлять подсказки или автоматическое завершение, компиляторы могут выполнять оптимизацию запросов во время сборки, или несколько схем могут быть сшиты вместе для формирования непрерывной поверхности API.

Разработка API, сочетающего язык запросов и систему типов, может показаться грандиозным предложением, но люди годами экспериментировали с этим в различных формах. XML-RPC продвигал типизированные ответы в середине 90-х, а его преемник, SOAP, доминировал в течение многих лет! Совсем недавно появились такие вещи, как абстракция MongoDB от Meteor, Horizon от RethinkDB (RIP), удивительный Falcor от Netflix, который они использовали для Netflix.com в течение многих лет, и, наконец, GraphQL от Facebook. В оставшейся части этого эссе я сосредоточусь на GraphQL, поскольку, хотя другие проекты, такие как Falcor, делают аналогичные вещи, мнение сообщества, похоже, в подавляющем большинстве поддерживает его.
Что такое GraphQL?
Во-первых, я должен сказать, что я немного солгал. API, который мы создали выше, был GraphQL. GraphQL — это просто система типов для ваших данных, язык запросов для их обхода — остальное — просто детали. В GraphQL вы описываете свои данные как граф взаимосвязей, и ваш клиент запрашивает именно то подмножество данных, которое ему нужно. Много говорят и пишут обо всех невероятных вещах, которые делает GraphQL, но основные концепции очень управляемы и несложны.
Чтобы сделать эти концепции более конкретными и помочь проиллюстрировать, как GraphQL пытается решить некоторые из проблем, описанных в части 1, в оставшейся части этого поста будет построен API GraphQL, который может привести в действие блог в части 1 этой серии. Прежде чем перейти к коду, следует помнить несколько вещей о GraphQL.
GraphQL — это спецификация (а не реализация)
GraphQL — это только спецификация. Он определяет систему типов вместе с простым языком запросов, вот и все. Первое, что из этого выпадает, это то, что GraphQL никак не привязан к конкретному языку. Существует более двух десятков реализаций для всего, от Haskell до C++, из которых JavaScript — только одна. Вскоре после объявления спецификации Facebook выпустил эталонную реализацию на JavaScript, но, поскольку они не используют ее внутри компании, реализации на таких языках, как Go и Clojure, могут быть еще лучше или быстрее.
В спецификации GraphQL не упоминаются клиенты или данные
Если вы прочитаете спецификацию, то заметите, что две вещи явно отсутствуют. Во-первых, помимо языка запросов, нет упоминания об интеграции клиентов. Такие инструменты, как Apollo, Relay, Loka и им подобные, возможны благодаря дизайну GraphQL, но они никоим образом не являются его частью и не требуются для его использования. Во-вторых, нет упоминания о каком-либо конкретном уровне данных. Один и тот же сервер GraphQL может и часто извлекает данные из разнородного набора источников. Он может запрашивать кешированные данные у Redis, выполнять поиск адреса из USPS API и вызывать микросервисы на основе protobuff, и клиент никогда не заметит разницы.
Прогрессивное раскрытие сложности
GraphQL для многих оказался на редком пересечении мощности и простоты. Он проделывает фантастическую работу, делая простые вещи простыми, а сложные возможными. Чтобы запустить сервер и обслуживать типизированные данные по HTTP, достаточно написать всего несколько строк кода практически на любом языке, который вы только можете себе представить.
Например, сервер GraphQL может обернуть существующий REST API, а его клиенты могут получать данные с помощью обычных запросов GET так же, как вы взаимодействовали бы с другими службами. Вы можете увидеть демо здесь. Или, если проекту требуется более сложный набор инструментов, можно использовать GraphQL для выполнения таких действий, как проверка подлинности на уровне поля, подписка на публикации/подписки или предварительно скомпилированные/кешированные запросы.
Пример приложения
Цель этого примера — продемонстрировать мощь и простоту GraphQL примерно в 70 строках JavaScript, а не писать подробное руководство. Я не буду вдаваться в подробности о синтаксисе и семантике, но весь код здесь работоспособен, а в конце статьи есть ссылка на загружаемую версию проекта. Если, пройдя через это, вы захотите копнуть немного глубже, в моем блоге есть коллекция ресурсов, которые помогут вам создавать более крупные и надежные сервисы.
Для демонстрации я буду использовать JavaScript, но шаги очень похожи на любом языке. Давайте начнем с некоторых примеров данных, используя удивительный Mocky.io.
Авторы
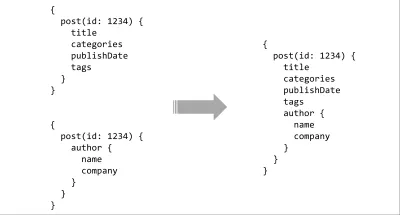
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }Сообщения
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] Первый шаг — создать новый проект с промежуточным ПО express и express-graphql .
bash npm init -y && npm install --save graphql express express-graphql И создать файл index.js с экспресс-сервером.

const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Чтобы начать работу с GraphQL, мы можем начать с моделирования данных в REST API. В новый файл с именем schema.js добавьте следующее:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); Приведенный выше код сопоставляет типы ответов JSON нашего API с типами GraphQL. GraphQLObjectType соответствует Object JavaScript, GraphQLString соответствует строке String и так далее. Один особый тип, на который следует обратить внимание, — это GraphQLSchema в последних нескольких строках. GraphQLSchema — это экспорт GraphQL на корневом уровне — отправная точка для запросов по графу. В этом базовом примере мы только определяем query ; здесь вы должны определить мутации (записи) и подписки.
Далее мы собираемся добавить схему на наш экспресс-сервер в файле index.js . Для этого мы добавим промежуточное ПО express-graphql и передадим ему схему.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); На данный момент, хотя мы не возвращаем никаких данных, у нас есть работающий сервер GraphQL, который предоставляет свою схему клиентам. Чтобы упростить запуск приложения, мы также добавим стартовый скрипт в package.json .
"scripts": { "start": "nodemon index.js" }, Запустив проект и перейдя по адресу https://localhost:5000/, должен появиться обозреватель данных под названием GraphiQL. GraphiQL будет загружаться по умолчанию, если для заголовка HTTP Accept не установлено значение application/json . Вызов этого же URL-адреса с помощью fetch или cURL с использованием application/json вернет результат JSON. Не стесняйтесь поиграть со встроенной документацией и написать запрос.

Единственное, что осталось сделать для завершения сервера, — это связать базовые данные со схемой. Для этого нам нужно определить функции resolve . В GraphQL запрос выполняется сверху вниз, вызывая функцию resolve при обходе дерева. Например, для следующего запроса:
query homepage { posts { title } } GraphQL сначала вызовет posts.resolve(parentData) , а затем posts.title.resolve(parentData) . Давайте начнем с определения распознавателя в нашем списке сообщений в блоге.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); Я использую здесь пакет isomorphic-fetch для выполнения HTTP-запроса, так как он прекрасно демонстрирует, как вернуть обещание из преобразователя, но вы можете использовать все, что захотите. Эта функция вернет массив сообщений типа Blog. Функция разрешения по умолчанию для реализации GraphQL на JavaScript — parentData.<fieldName> . Например, распознаватель по умолчанию для поля имени автора будет следующим:
rawAuthorObject => rawAuthorObject.nameЭтот единственный переопределяющий преобразователь должен предоставлять данные для всего почтового объекта. Нам все еще нужно определить преобразователь для автора, но если вы запустите запрос для получения данных, необходимых для домашней страницы, вы должны увидеть, что он работает.
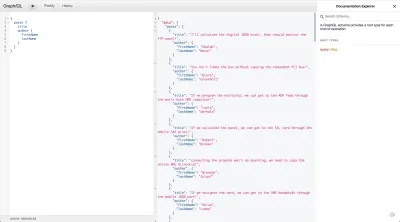
Поскольку атрибут author в нашем API сообщений — это просто идентификатор автора, когда GraphQL ищет объект, определяющий имя и компанию, и находит строку, он просто возвращает null . Чтобы связать Автора, нам нужно изменить нашу схему Post, чтобы она выглядела следующим образом:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });Теперь у нас есть полностью работающий сервер GraphQL, обертывающий REST API. Полный исходный код можно загрузить по этой ссылке на Github или запустить с этой панели запуска GraphQL.
Вам могут быть интересны инструменты, которые вам понадобятся для использования конечной точки GraphQL, подобной этой. Есть много вариантов, таких как Relay и Apollo, но для начала я думаю, что лучше всего использовать простой подход. Если вы много играли с GraphiQL, вы могли заметить, что у него длинный URL. Этот URL-адрес является просто версией вашего запроса в кодировке URI. Чтобы построить запрос GraphQL в JavaScript, вы можете сделать что-то вроде этого:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Или, если хотите, вы можете скопировать и вставить URL-адрес прямо из GraphiQL следующим образом:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageПоскольку у нас есть конечная точка GraphQL и способ ее использования, мы можем сравнить ее с нашим RESTish API. Код, который нам нужно было написать для извлечения наших данных с помощью RESTish API, выглядел так:
Использование RESTish API
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };Использование API GraphQL
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Таким образом, мы использовали GraphQL для:
- Сократите девять запросов (список сообщений, четыре сообщения в блоге и автора каждого сообщения).
- Сократите объем отправляемых данных на значительный процент.
- Используйте невероятные инструменты разработчика для создания наших запросов.
- Напишите намного более чистый код в нашем клиенте.
Недостатки в GraphQL
Хотя я считаю, что ажиотаж оправдан, серебряной пули не существует, и каким бы прекрасным ни был GraphQL, он не лишен недостатков.
Целостность данных
GraphQL иногда кажется инструментом, специально созданным для хороших данных. Часто он лучше всего работает как своего рода шлюз, объединяющий разрозненные сервисы или сильно нормализованные таблицы. Если данные, которые возвращаются из потребляемых вами сервисов, беспорядочны и неструктурированы, добавление конвейера преобразования данных под GraphQL может стать настоящей проблемой. Областью действия функции разрешения GraphQL являются только ее собственные данные и данные ее дочерних элементов. Если задаче оркестровки требуется доступ к данным родственного элемента или родителя в дереве, это может быть особенно сложно.
Комплексная обработка ошибок
Запрос GraphQL может запускать произвольное количество запросов, и каждый запрос может обращаться к произвольному количеству сервисов. Если какая-либо часть запроса не выполняется, а не весь запрос, GraphQL по умолчанию возвращает частичные данные. Частичные данные, вероятно, являются правильным выбором с технической точки зрения, и они могут быть невероятно полезными и эффективными. Недостатком является то, что обработка ошибок уже не так проста, как проверка кода состояния HTTP. Это поведение можно отключить, но чаще всего клиенты сталкиваются с более сложными случаями ошибок.
Кэширование
Хотя часто рекомендуется использовать статические запросы GraphQL, для таких организаций, как Github, которые разрешают произвольные запросы, сетевое кэширование с помощью стандартных инструментов, таких как Varnish или Fastly, больше не будет возможным.
Высокая стоимость процессора
Разбор, проверка и проверка типа запроса — это процесс, связанный с процессором, который может привести к проблемам с производительностью в однопоточных языках, таких как JavaScript.
Это проблема только для оценки запроса во время выполнения.
Заключительные мысли
Функции GraphQL не являются революцией — некоторые из них существуют уже почти 30 лет. Что делает GraphQL мощным, так это то, что уровень полировки, интеграции и простоты использования делают его чем-то большим, чем сумма его частей.
Многое из того, что делает GraphQL, может быть достигнуто с помощью усилий и дисциплины с использованием REST или RPC, но GraphQL предлагает современные API для огромного количества проектов, у которых может не быть времени, ресурсов или инструментов, чтобы сделать это самостоятельно. Верно и то, что GraphQL не панацея, но его недостатки, как правило, незначительны и хорошо понятны. Как человек, который построил достаточно сложный сервер GraphQL, я могу легко сказать, что преимущества легко перевешивают затраты.
Это эссе почти полностью посвящено тому, почему существует GraphQL и проблемам, которые он решает. Если это пробудило в вас интерес к изучению его семантики и тому, как его использовать, я призываю вас учиться любым удобным для вас способом, будь то блоги, YouTube или просто чтение источника (особенно хорошо How To GraphQL).
Если вам понравилась эта статья (или если она вам не понравилась) и вы хотите оставить отзыв, найдите меня в Твиттере под ником @ebaerbaerbaer или на LinkedIn по адресу ericjbaer.