
Учебник по GraphQL: зачем нам новый вид API (часть 1)
Опубликовано: 2022-03-10В этой серии я хочу познакомить вас с GraphQL. К концу вы должны понять не только что это такое, но и его происхождение, его недостатки и основы того, как с ним работать. В этой первой статье, вместо того чтобы вдаваться в реализацию, я хочу рассказать, как и почему мы пришли к GraphQL (и подобным инструментам), изучив уроки, извлеченные из последних 60 лет разработки API, от RPC до наших дней. Ведь, как красочно описал Марк Твен, новых идей не бывает.
«Новой идеи не существует. Это невозможно. Мы просто берем множество старых идей и помещаем их в своего рода ментальный калейдоскоп».
- Марк Твен в «Собственной автобиографии Марка Твена: главы из The North American Review»
Но сначала я должен обратиться к слону в комнате. Новые вещи всегда интересны, но они также могут утомлять. Возможно, вы слышали о GraphQL и просто подумали про себя: «Почему…». В качестве альтернативы, возможно, вы подумали что-то вроде: «Почему меня волнует новая тенденция дизайна API? ОТДЫХ… в порядке». Это законные вопросы, поэтому позвольте мне объяснить, почему вы должны обратить на это внимание.
Введение
Преимущества использования новых инструментов для вашей команды должны быть сопоставлены с затратами. Есть много вещей, которые нужно измерить. Есть время, необходимое для обучения, время преобразования отнимает время на разработку функций, накладные расходы на поддержку двух систем. При таких высоких затратах любая новая технология должна быть намного лучше, быстрее или продуктивнее . Постепенные улучшения, хотя и захватывающие, просто не стоят вложений. Типы API, о которых я хочу рассказать, в частности GraphQL, на мой взгляд, являются огромным шагом вперед и приносят более чем достаточную выгоду, чтобы оправдать затраты.
Вместо того, чтобы сначала исследовать функции, полезно поместить их в контекст и понять, как они появились. Для этого я собираюсь начать с краткого обзора истории API.
RPC
Возможно, RPC был первым крупным шаблоном API, и его происхождение восходит к ранним вычислениям в середине 60-х годов. В то время компьютеры были все еще такими большими и дорогими, что понятие разработки приложений на основе API, как мы его себе представляем, было в основном чисто теоретическим. Ограничения, такие как пропускная способность/задержка, вычислительная мощность, общее время вычислений и физическая близость , заставляли инженеров думать с точки зрения распределенных систем , а не служб, предоставляющих данные. Начиная с ARPANET в 60-х и заканчивая серединой 90-х с такими вещами, как CORBA и Java RMI, большинство компьютеров взаимодействовали друг с другом с помощью удаленных вызовов процедур (RPC), которые представляют собой модель взаимодействия клиент-сервер, где клиент вызывает процедуру. (или метод) для выполнения на удаленном сервере.
В RPC есть много хороших вещей. Его основной принцип заключается в том, чтобы позволить разработчику обрабатывать код в удаленной среде, как если бы он был в локальной среде, хотя и намного медленнее и менее надежно, что создает преемственность в различных и несопоставимых системах. Как и многие вещи, появившиеся в ARPANET, он опередил свое время, поскольку мы все еще стремимся к такому типу непрерывности при работе с ненадежными и асинхронными действиями, такими как доступ к БД и вызовы внешних служб.
На протяжении десятилетий было проведено огромное количество исследований того, как позволить разработчикам встраивать подобное асинхронное поведение в типичный поток программы; если бы в то время были доступны такие вещи, как Promises, Futures и ScheduledTasks, возможно, наш ландшафт API выглядел бы иначе.
Еще одна замечательная особенность RPC заключается в том, что, поскольку он не ограничен структурой данных, для клиентов могут быть написаны узкоспециализированные методы, которые запрашивают и извлекают именно ту информацию, которая необходима, что может привести к минимальным издержкам сети и меньшей полезной нагрузке.
Однако есть вещи, которые усложняют RPC. Во-первых, непрерывность требует контекста . RPC по своей природе создает довольно сильную связь между локальными и удаленными системами — вы теряете границы между своим локальным и удаленным кодом. Для некоторых доменов это допустимо или даже предпочтительно, как в клиентских SDK, но для API, где клиентский код не совсем понятен, он может быть значительно менее гибким, чем что-то более ориентированное на данные.
Однако более важным является возможность распространения методов API . Теоретически служба RPC предоставляет небольшой продуманный API, способный справиться с любой задачей. На практике огромное количество внешних конечных точек может накапливаться без особой структуры. Требуется огромная дисциплина, чтобы предотвратить перекрытие API и дублирование с течением времени, когда члены команды приходят и уходят, а проекты меняются.
Это правда, что с помощью надлежащих инструментов и документации можно управлять изменениями, подобными тем, которые я упомянул, но в свое время написания программного обеспечения я столкнулся с несколькими службами автоматического документирования и дисциплины, так что для меня это что-то вроде красная сельдь.
МЫЛО
Следующим важным типом API стал SOAP, появившийся в конце 90-х годов в Microsoft Research. SOAP ( простой протокол доступа к объектам) — амбициозная спецификация протокола для обмена данными между приложениями на основе XML. Заявленная цель SOAP состояла в том, чтобы устранить некоторые практические недостатки RPC, в частности XML-RPC, путем создания хорошо структурированной основы для сложных веб-сервисов. По сути, это просто означало добавление в XML системы поведенческих типов. К сожалению, это создало больше препятствий, чем решило, о чем свидетельствует тот факт, что сегодня создается очень мало новых конечных точек SOAP.
«SOAP — это то, что большинство людей считают умеренным успехом».
— Дон Бокс
У SOAP было много хороших вещей, несмотря на его невыносимую многословность и ужасные имена. Принудительные контракты в WSDL и WADL (произносится как «wizdle» и «waddle») между клиентом и сервером гарантировали предсказуемые, типобезопасные результаты, а WSDL можно было использовать для создания документации или интеграции с IDE и другими инструментами.
Большим открытием SOAP в отношении эволюции API стало постепенное и, возможно, непреднамеренное введение более ориентированных на ресурсы вызовов. Конечные точки SOAP позволяют вам запрашивать данные с заранее определенной структурой, а не думать о методах, необходимых для генерации данных (при условии, что они написаны таким образом).
Наиболее существенным недостатком SOAP является то, что он слишком многословен; его почти невозможно использовать без большого количества инструментов . Вам нужны инструменты для написания тестов, инструменты для проверки ответов сервера и инструменты для анализа всех данных. Многие старые системы по-прежнему используют SOAP, но требования к инструментарию делают его слишком громоздким для большинства новых проектов, а количество байтов, необходимых для структуры XML, делает его плохим выбором для обслуживания мобильных устройств или распределенных систем.
Для получения дополнительной информации стоит прочитать спецификацию SOAP, а также удивительно интересную историю SOAP от Дона Бокса, одного из первых членов команды.
ОТДЫХ
Наконец, мы подошли к шаблону проектирования API: REST. ОТДЫХ, представленный Роем Филдингом в докторской диссертации в 2000 году, качнул маятник в совершенно другом направлении. REST во многих отношениях является антитезой SOAP, и, глядя на них рядом, вы чувствуете, что его диссертация была чем-то вроде гнева.
SOAP использует HTTP в качестве простого транспорта и строит свою структуру в теле запроса и ответа. REST, с другой стороны, выбрасывает контракты клиент-сервер, инструменты, XML и специальные заголовки, заменяя их семантикой HTTP, поскольку вместо этого структура выбирает использование глаголов HTTP, взаимодействующих с данными и URI, которые ссылаются на ресурс в некоторой иерархии. данные.
| МЫЛО | ОТДЫХ | |
|---|---|---|
| Глаголы HTTP | ПОЛУЧИТЬ, ПОСТАВИТЬ, ПОСТАВИТЬ, ИСПРАВИТЬ, УДАЛИТЬ | |
| Формат данных | XML | Все что пожелаете |
| Контракты клиент/сервер | Весь день каждый день! | Кому нужны эти |
| Система типов | В JavaScript есть неподписанный шорт, верно? | |
| URL-адреса | Описать операции | Именованные ресурсы |
REST полностью и явно меняет дизайн API с моделирования взаимодействий на простое моделирование данных предметной области. Будучи полностью ориентированным на ресурсы при работе с REST API, вам больше не нужно знать или заботиться о том, что требуется для извлечения определенного фрагмента данных; вам также не требуется знать что-либо о реализации серверных служб.

Мало того, что простота была благом для разработчиков, но, поскольку URL-адреса представляют собой стабильную информацию, ее легко кэшировать, ее отсутствие состояния упрощает горизонтальное масштабирование, а поскольку она моделирует данные, а не предвидит потребности потребителей, она может значительно уменьшить площадь поверхности API. .
REST великолепен, и его вездесущность является поразительным успехом, но, как и все решения, которые были до него, REST не лишен недостатков. Чтобы конкретно поговорить о некоторых его недостатках, давайте рассмотрим базовый пример. Давайте представим, что нам нужно создать целевую страницу блога, которая отображает список сообщений в блоге и имя их автора.
Давайте напишем код, который может получить данные домашней страницы из простого REST API. Мы начнем с нескольких функций, которые обертывают наши ресурсы.
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);Теперь давайте оркестровать!
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };Итак, наш код будет делать следующее:
- Получить все сообщения;
- Получить подробную информацию о каждом сообщении;
- Получить ресурс автора для каждого поста.
Приятно то, что об этом довольно легко рассуждать, хорошо организовано, и концептуальные границы каждого ресурса хорошо нарисованы. Облом здесь в том, что мы только что сделали восемь сетевых запросов, многие из которых выполняются последовательно.
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 Да, вы могли бы покритиковать этот пример, предположив, что API может иметь конечную точку /posts с разбивкой на страницы, но это щепетильность. Факт остается фактом: у вас часто есть набор вызовов API, которые зависят друг от друга для отображения полного приложения или страницы.
Разработка клиентов и серверов REST, безусловно, лучше, чем то, что было до этого, или, по крайней мере, более защищено от идиотов, но многое изменилось за два десятилетия после статьи Филдинга. В то время все компьютеры были из бежевого пластика; теперь они алюминиевые! А если серьезно, 2000 год был близок к пику расцвета персональных компьютеров. Каждый год скорость процессоров удваивалась, а сети становились все быстрее с невероятной скоростью. Проникновение Интернета на рынок составило около 45%, и ему некуда было двигаться, кроме роста.
Затем, примерно в 2008 году, мобильные вычисления стали мейнстримом. Что касается мобильных устройств, то мы буквально за одну ночь откатились на десятилетие вперед с точки зрения скорости/производительности. В 2017 году у нас почти 80% проникновения смартфонов в стране и более 50% в мире, и пришло время переосмыслить некоторые наши предположения о дизайне API.
Слабые стороны REST
Ниже представлен критический взгляд на REST с точки зрения разработчика клиентских приложений, в частности, работающего с мобильными устройствами. GraphQL и API-интерфейсы в стиле GraphQL не новы и не решают проблем, которые находятся за пределами понимания разработчиков REST. Наиболее значительным вкладом GraphQL является его способность решать эти проблемы систематически и с уровнем интеграции, недоступным где-либо еще. Другими словами, это решение «в комплекте с батареями».
Основные авторы REST, в том числе Филдинг, опубликовали в конце 2017 года статью («Размышления об архитектурном стиле REST» и «Принципиальный дизайн современной веб-архитектуры»), отражающую два десятилетия REST и множество шаблонов, которые он вдохновил. Она короткая и абсолютно достойна прочтения для всех, кто интересуется дизайном API.
С некоторым историческим контекстом и эталонным приложением давайте рассмотрим три основных слабости REST.
ОТДЫХ болтлив
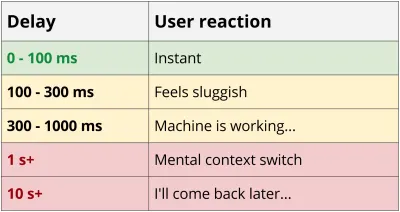
Службы REST имеют тенденцию быть, по крайней мере, несколько «болтливыми», поскольку между клиентом и сервером требуется несколько циклов обмена данными, чтобы получить достаточно данных для рендеринга приложения. Этот каскад запросов оказывает разрушительное воздействие на производительность, особенно на мобильных устройствах. Возвращаясь к примеру с блогом, даже в лучшем случае с новым телефоном и надежной сетью с подключением 4G вы потратили почти 0,5 с только на задержку до загрузки первого байта данных.
Задержка 4G 55 мс * 8 запросов = 440 мс накладных расходов
Еще одна проблема с сервисами чата заключается в том, что во многих случаях загрузка одного большого запроса занимает меньше времени, чем множество мелких. Снижение производительности небольших запросов происходит по многим причинам, включая медленный запуск TCP, отсутствие сжатия заголовков и эффективность gzip, и если вам это интересно, я настоятельно рекомендую прочитать книгу Ильи Григорика «Высокопроизводительные браузерные сети». В блоге MaxCDN также есть отличный обзор.
Технически эта проблема связана не с REST, а с HTTP, в частности с HTTP/1. HTTP/2 практически решает проблему болтливости независимо от стиля API и имеет широкую поддержку в таких клиентах, как браузеры и собственные SDK. К сожалению, развертывание на стороне API было медленным. Среди 10 000 лучших веб-сайтов внедрение составляет около 20% (и рост) по состоянию на конец 2017 года. Даже Node.js, к моему большому удивлению, получил поддержку HTTP/2 в выпуске 8.x. Если у вас есть возможность, пожалуйста, обновите свою инфраструктуру! А пока не будем останавливаться, так как это только одна часть уравнения.
Помимо HTTP, последняя часть того, почему болтливость имеет значение, связана с тем, как работают мобильные устройства и, в частности, их радиостанции. Короче говоря, работа радио — одна из самых ресурсоемких частей телефона, поэтому ОС отключает его при каждой возможности. Запуск радио не только разряжает батарею, но и увеличивает нагрузку на каждый запрос.
TMI (Перевыборка)
Следующая проблема со службами в стиле REST заключается в том, что они отправляют больше информации, чем необходимо. В нашем примере с блогом все, что нам нужно, это заголовок каждого сообщения и имя его автора, что составляет всего около 17% от того, что было возвращено. Это 6-кратная потеря для очень простой полезной нагрузки. В реальном API такие накладные расходы могут быть огромными. Например, сайты электронной коммерции часто представляют один продукт в виде тысяч строк JSON. Подобно проблеме болтливости, службы REST сегодня могут справиться с этим сценарием, используя «разреженные наборы полей» для условного включения или исключения частей данных. К сожалению, поддержка этого является неполной, неполной или проблематичной для сетевого кэширования.
Инструменты и самоанализ
И последнее, чего не хватает REST API, — это механизмов самоанализа. Без какого-либо контракта с информацией о типах возвращаемых данных или структуре конечной точки невозможно надежно генерировать документацию, создавать инструменты или взаимодействовать с данными. В REST можно работать, чтобы решить эту проблему в той или иной степени. Проекты, которые полностью реализуют OpenAPI, OData или JSON API, часто являются чистыми, четко определенными и, в разной степени, хорошо документированными, но такие серверные части встречаются редко. Даже Hypermedia, относительно низко висящий плод, несмотря на то, что его рекламировали на конференциях в течение десятилетий, до сих пор не часто работает хорошо, если вообще работает.
Заключение
Каждый из типов API несовершенен, но таков каждый паттерн. Это письмо не является суждением о феноменальном фундаменте, который заложили гиганты в области программного обеспечения, а является лишь трезвой оценкой каждого из этих шаблонов, примененных в их «чистом» виде с точки зрения разработчика клиента. Я надеюсь, что вместо того, чтобы перестать думать, что такие шаблоны, как REST или RPC, сломаны, вы можете подумать о том, как каждый из них пошел на компромиссы и области , на которых инженерная организация могла бы сосредоточить свои усилия для улучшения своих собственных API .
В следующей статье я буду изучать GraphQL и то, как он направлен на решение некоторых проблем, упомянутых выше. Инновация GraphQL и подобных инструментов заключается в уровне их интеграции, а не в их реализации. Пожалуйста, если вы или ваша команда не ищете API с включенными батареями, подумайте о том, чтобы изучить что-то вроде новой спецификации OpenAPI, которая может помочь создать более прочную основу уже сегодня!
Если вам понравилась эта статья (или если она вам не понравилась) и вы хотите оставить отзыв, найдите меня в Твиттере под ником @ebaerbaerbaer или на LinkedIn по адресу ericjbaer.