
Градиентный спуск в машинном обучении: как это работает?
Опубликовано: 2021-01-28Оглавление
Введение
Одной из наиболее важных частей машинного обучения является оптимизация его алгоритмов. Почти все алгоритмы машинного обучения имеют в своей основе алгоритм оптимизации, который выступает в качестве ядра алгоритма. Как мы все знаем, оптимизация является конечной целью любого алгоритма, даже при работе с реальными событиями или при работе с технологическим продуктом на рынке.
В настоящее время существует множество алгоритмов оптимизации, которые используются в нескольких приложениях, таких как распознавание лиц, беспилотные автомобили, анализ рынка и т. д. Точно так же в машинном обучении такие алгоритмы оптимизации играют важную роль. Одним из таких широко используемых алгоритмов оптимизации является алгоритм градиентного спуска, который мы рассмотрим в этой статье.
Что такое градиентный спуск?
В машинном обучении алгоритм градиентного спуска является одним из наиболее часто используемых алгоритмов, и все же он ошеломляет большинство новичков. С математической точки зрения градиентный спуск — это итеративный алгоритм оптимизации первого порядка, который используется для нахождения локального минимума дифференцируемой функции. Проще говоря, этот алгоритм градиентного спуска используется для нахождения значений параметров функции (или коэффициентов), которые используются для минимизации функции стоимости как можно ниже. Функция стоимости используется для количественной оценки ошибки между прогнозируемыми значениями и реальными значениями построенной модели машинного обучения.
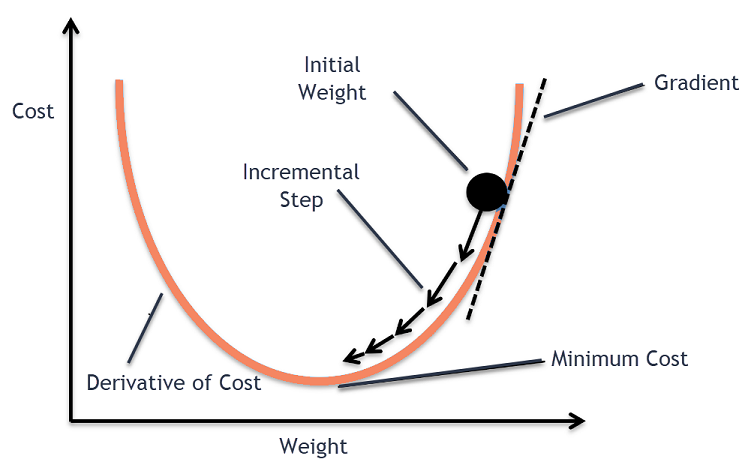
Интуиция градиентного спуска
Представьте себе большую миску, в которой вы обычно храните фрукты или едите хлопья. Эта чаша будет функцией стоимости (f).
Теперь произвольной координатой на любом участке поверхности чаши будут текущие значения коэффициентов функции стоимости. Дно чаши — это наилучший набор коэффициентов и минимум функции.
Здесь цель состоит в том, чтобы вычислить различные значения коэффициентов на каждой итерации, оценить стоимость и выбрать коэффициенты, которые имеют лучшее значение функции стоимости (более низкое значение). На нескольких итерациях будет обнаружено, что дно чаши имеет лучшие коэффициенты для минимизации функции стоимости.

Таким образом, алгоритм градиентного спуска работает с минимальными затратами.
Присоединяйтесь к онлайн- курсу по машинному обучению в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и программам повышения квалификации в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
Процедура градиентного спуска
Этот процесс градиентного спуска начинается с первоначального присвоения значений коэффициентам функции стоимости. Это может быть либо значение, близкое к 0, либо небольшое случайное значение.
коэффициент = 0,0
Затем стоимость коэффициентов получается путем применения ее к функции стоимости и расчета стоимости.
стоимость = f (коэффициент)
Затем вычисляется производная функции стоимости. Эта производная функции стоимости получается с помощью математической концепции дифференциального исчисления. Он дает нам наклон функции в данной точке, где вычисляется ее производная. Этот наклон необходим, чтобы знать, в каком направлении должен быть перемещен коэффициент на следующей итерации, чтобы получить более низкое значение стоимости. Это делается путем наблюдения за знаком вычисленной производной.
дельта = производная (стоимость)
Как только мы узнаем, какое направление идет вниз от рассчитанной производной, нам нужно обновить значения коэффициентов. Для этого используется параметр, известный как параметр обучения, альфа (α). Это используется для контроля степени изменения коэффициентов при каждом обновлении.
коэффициент = коэффициент – (альфа * дельта)
Источник
Таким образом, этот процесс повторяется до тех пор, пока стоимость коэффициентов не станет равной 0,0 или достаточно близкой к нулю. Это процедура для алгоритма градиентного спуска.
Типы алгоритмов градиентного спуска
В наше время существует три основных типа градиентного спуска, которые используются в современных алгоритмах машинного обучения и глубокого обучения. Основное различие между каждым из этих трех типов заключается в его вычислительной стоимости и эффективности. В зависимости от объема используемых данных, временной сложности и точности различают следующие три типа.
- Пакетный градиентный спуск
- Стохастический градиентный спуск
- Мини-пакетный градиентный спуск
Пакетный градиентный спуск
Это первая и базовая версия алгоритмов градиентного спуска, в которой весь набор данных используется сразу для вычисления функции стоимости и ее градиента. Поскольку весь набор данных используется за один раз для одного обновления, расчет градиента в этом типе может быть очень медленным и невозможен с теми наборами данных, для которых недостаточно памяти устройства.
Таким образом, этот алгоритм пакетного градиентного спуска используется только для небольших наборов данных, и когда количество обучающих примеров велико, пакетный градиентный спуск не является предпочтительным. Вместо этого используются алгоритмы Stochastic и Mini Batch Gradient Descent.
Стохастический градиентный спуск
Это еще один тип алгоритма градиентного спуска, в котором за итерацию обрабатывается только один обучающий пример. При этом первым шагом является рандомизация всего набора обучающих данных. Затем для обновления коэффициентов используется только один обучающий пример. Это отличается от пакетного градиентного спуска, в котором параметры (коэффициенты) обновляются только после оценки всех обучающих примеров.

Стохастический градиентный спуск (SGD) имеет то преимущество, что этот тип частого обновления дает подробную информацию о скорости улучшения. Однако в некоторых случаях это может оказаться дорогостоящим с вычислительной точки зрения, поскольку обрабатывается только один пример на каждой итерации, что может привести к очень большому количеству итераций.
Мини-пакетный градиентный спуск
Это недавно разработанный алгоритм, который быстрее, чем алгоритмы пакетного и стохастического градиентного спуска. Он наиболее предпочтителен, так как представляет собой комбинацию обоих ранее упомянутых алгоритмов. При этом он разделяет обучающий набор на несколько мини-пакетов и выполняет обновление для каждого из этих пакетов после вычисления градиента этого пакета (как в SGD).
Обычно размер пакета варьируется от 30 до 500, но фиксированного размера нет, поскольку они различаются для разных приложений. Следовательно, даже если имеется огромный набор обучающих данных, этот алгоритм обрабатывает его мини-пакетами «b». Таким образом, он подходит для больших наборов данных с меньшим количеством итераций.
Если «m» — это количество обучающих примеров, то если b == m, то мини-пакетный градиентный спуск будет аналогичен алгоритму пакетного градиентного спуска.
Варианты градиентного спуска в машинном обучении
На этой основе для градиентного спуска было разработано несколько других алгоритмов. Некоторые из них приведены ниже.
Ванильный градиентный спуск
Это одна из самых простых форм техники градиентного спуска. Название ваниль означает чистый или без каких-либо примесей. При этом предпринимаются небольшие шаги в направлении минимумов путем вычисления градиента функции стоимости. Подобно вышеупомянутому алгоритму, правило обновления задается следующим образом:
коэффициент = коэффициент – (альфа * дельта)
Градиентный спуск с импульсом
В этом случае алгоритм таков, что мы знаем предыдущие шаги, прежде чем делать следующий шаг. Это делается путем введения нового термина, который является продуктом предыдущего обновления и константы, известной как импульс. При этом правило обновления веса задается следующим образом:
обновление = альфа * дельта
скорость = предыдущее_обновление * импульс
коэффициент = коэффициент + скорость – обновление
АДАГРАД
Термин ADAGRAD расшифровывается как Adaptive Gradient Algorithm. Как следует из названия, он использует адаптивную технику для обновления весов. Этот алгоритм больше подходит для разреженных данных. Эта оптимизация изменяет скорость обучения в зависимости от частоты обновления параметров во время обучения. Например, параметры с более высокими градиентами имеют более медленную скорость обучения, чтобы мы не превышали минимальное значение. Точно так же более низкие градиенты имеют более высокую скорость обучения, чтобы обучаться быстрее.
АДАМ
Еще один алгоритм адаптивной оптимизации, уходящий своими корнями в алгоритм градиентного спуска, — это ADAM, что означает адаптивную оценку момента. Это комбинация алгоритмов ADAGRAD и SGD с алгоритмами Momentum. Он построен на основе алгоритма ADAGRAD и построен с другой стороны. Проще говоря, АДАМ = АДАГРАД + Импульс.
Таким образом, существует несколько других вариантов алгоритмов градиентного спуска, которые были разработаны и разрабатываются в мире, такие как AMSGrad, ADAMax.
Заключение
В этой статье мы рассмотрели алгоритм одного из наиболее часто используемых алгоритмов оптимизации в машинном обучении, алгоритмов градиентного спуска, а также его типы и варианты, которые были разработаны.
upGrad предлагает программу Executive PG в области машинного обучения и искусственного интеллекта и степень магистра наук в области машинного обучения и искусственного интеллекта , которые могут помочь вам построить карьеру. Эти курсы объяснят необходимость машинного обучения и дальнейшие шаги по сбору знаний в этой области, охватывающие различные концепции, начиная от градиентного спуска и машинного обучения.
Где алгоритм градиентного спуска может внести максимальный вклад?
Оптимизация в рамках любого алгоритма машинного обучения зависит от чистоты алгоритма. Алгоритм градиентного спуска помогает минимизировать ошибки функции стоимости и улучшить параметры алгоритма. Хотя алгоритм градиентного спуска широко используется в машинном обучении и глубоком обучении, его эффективность может определяться количеством данных, предпочтительным количеством итераций и точностью, а также количеством доступного времени. Для небольших наборов данных оптимальным является пакетный градиентный спуск. Стохастический градиентный спуск (SGD) оказывается более эффективным для подробных и более обширных наборов данных. Напротив, Mini Batch Gradient Descent используется для более быстрой оптимизации.
Какие проблемы возникают при градиентном спуске?
Градиентный спуск предпочтительнее для оптимизации моделей машинного обучения для снижения функции затрат. Однако у него есть и свои недостатки. Предположим, что градиент уменьшен из-за минимальных выходных функций слоев модели. В этом случае итерации будут не такими эффективными, поскольку модель не будет полностью переобучаться, обновляя свои веса и смещения. Иногда градиент ошибок накапливает множество весов и смещений, чтобы поддерживать актуальность итераций. Однако этот градиент становится слишком большим для управления и называется взрывным градиентом. Необходимо учитывать требования к инфраструктуре, баланс скорости обучения, импульс.
Всегда ли градиентный спуск сходится?
Сходимость — это когда алгоритм градиентного спуска успешно минимизирует свою функцию стоимости до оптимального уровня. Алгоритм градиентного спуска пытается минимизировать функцию стоимости с помощью параметров алгоритма. Однако он может приземлиться в любой из оптимальных точек и не обязательно в той, которая имеет глобальную или локальную точку оптимума. Одной из причин отсутствия оптимальной сходимости является размер шага. Более значительный размер шага приводит к большему количеству колебаний и может отклоняться от глобального оптимума. Следовательно, градиентный спуск не всегда может сходиться к лучшему признаку, но он все равно достигает ближайшей точки признака.