
Градиентный спуск в логистической регрессии [объяснение для начинающих]
Опубликовано: 2021-01-08В этой статье мы обсудим очень популярный алгоритм градиентного спуска в логистической регрессии. Мы рассмотрим, что такое логистическая регрессия, затем постепенно перейдем к уравнению логистической регрессии, его функции стоимости и, наконец, алгоритму градиентного спуска.
Оглавление
Что такое логистическая регрессия?
Логистическая регрессия — это просто алгоритм классификации, используемый для прогнозирования дискретных категорий, таких как прогнозирование того, является ли почта «спамом» или «не спамом»; предсказание, является ли данная цифра «9» или «не 9» и т. д. Теперь, глядя на название, вы должны подумать, почему оно называется регрессией?
Причина в том, что идея логистической регрессии была разработана путем настройки нескольких элементов базового алгоритма линейной регрессии, используемого в задачах регрессии.
Логистическую регрессию также можно применять к задачам классификации с несколькими классами (более двух классов). Хотя рекомендуется использовать этот алгоритм только для задач бинарной классификации.
Сигмовидная функция
Проблемы классификации не являются проблемами линейной функции. Вывод ограничен определенными дискретными значениями, например, 0 и 1 для задачи бинарной классификации. Для линейной функции нет смысла предсказывать наши выходные значения как больше 1 или меньше 0. Поэтому нам нужна правильная функция для представления наших выходных значений.
Сигмовидная функция решает нашу проблему. Также известная как логистическая функция, это S-образная функция, отображающая любое число вещественных значений в интервал (0,1), что делает ее очень полезной для преобразования любой случайной функции в функцию, основанную на классификации. Сигмоидальная функция выглядит так:

Сигмовидная функция
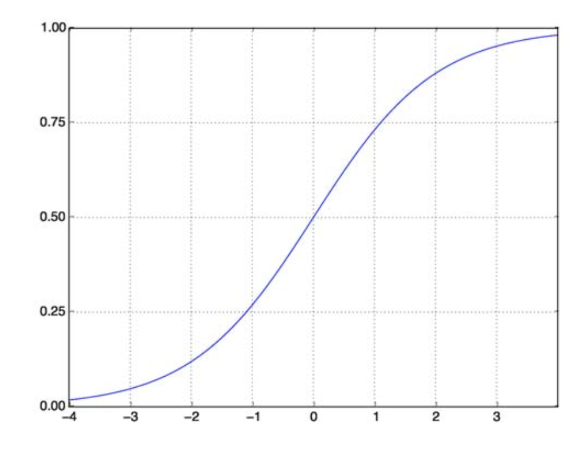
источник
Теперь математическая форма сигмовидной функции для параметризованного вектора и входного вектора X:
(z) = 11+exp(-z), где z = TX
(z) даст нам вероятность того, что выход равен 1. Как мы все знаем, значение вероятности колеблется от 0 до 1. Теперь это не тот результат, который нам нужен для нашей дискретной (только 0 и 1) задачи классификации. . Итак, теперь мы можем сравнить предсказанную вероятность с 0,5. Если вероятность > 0,5, мы имеем y=1. Точно так же, если вероятность <0,5, мы имеем y=0.
Функция стоимости
Теперь, когда у нас есть наши дискретные прогнозы, пришло время проверить, действительно ли наши прогнозы верны или нет. Для этого у нас есть функция стоимости. Функция стоимости — это просто сумма всех ошибок, сделанных в прогнозах по всему набору данных. Конечно, мы не можем использовать функцию стоимости, используемую в линейной регрессии. Итак, новая функция затрат для логистической регрессии:
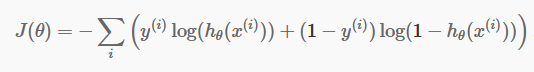 источник
источник
Не бойтесь уравнения. Это очень просто. Для каждой итерации i он вычисляет ошибку, которую мы сделали в нашем прогнозе, а затем суммирует все ошибки, чтобы определить нашу функцию стоимости J().
Два члена в скобках фактически относятся к двум случаям: y=0 и y=1. Когда y=0, первый член исчезает, и остается только второй член. Точно так же, когда y=1, второй член исчезает, и у нас остается только первый член.
Алгоритм градиентного спуска
Мы успешно рассчитали нашу функцию стоимости. Но нам нужно минимизировать потери, чтобы сделать хороший алгоритм прогнозирования. Для этого у нас есть алгоритм градиентного спуска.
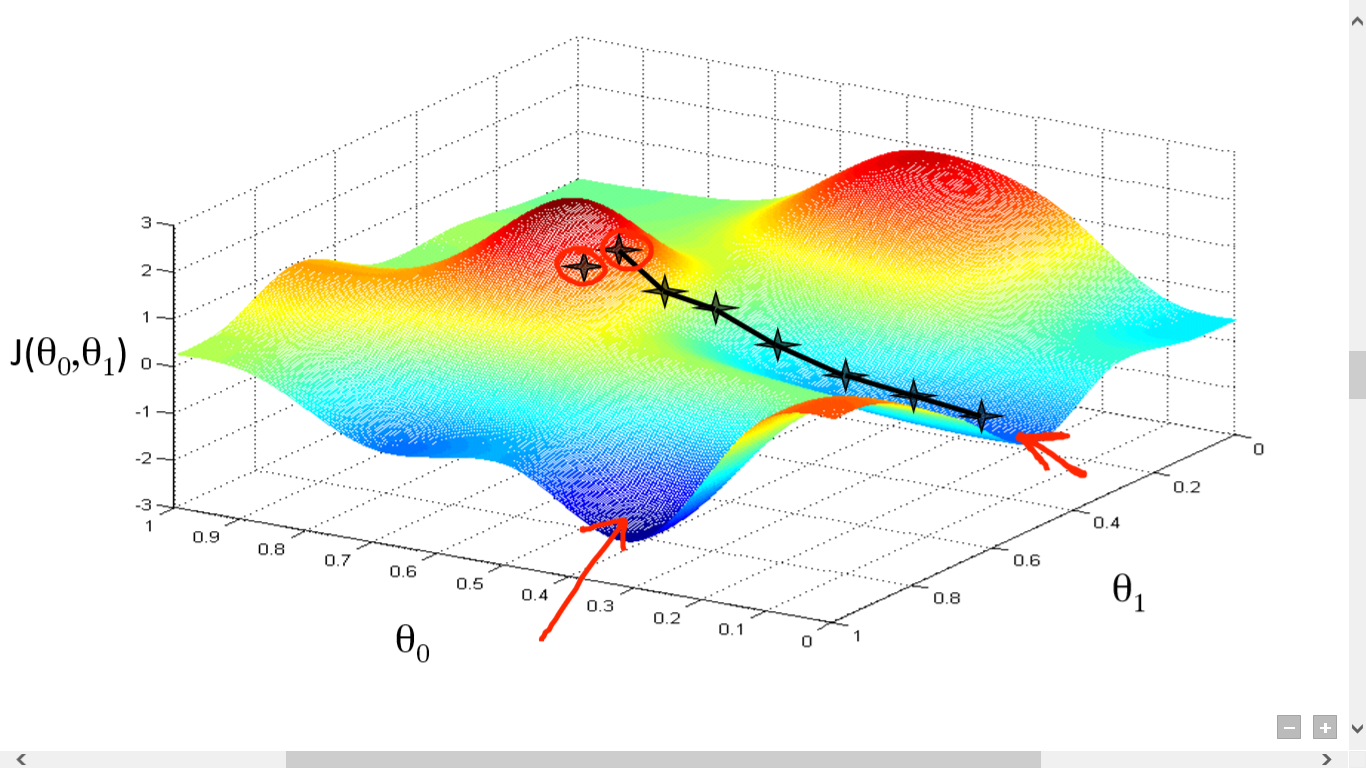 источник
источник
Здесь мы построили график между J() и . Наша цель — найти самую глубокую точку (глобальный минимум) этой функции. Теперь самая глубокая точка находится там, где J() минимален.
Чтобы найти самую глубокую точку, необходимы две вещи:
- Производная – найти направление следующего шага.
- (Скорость обучения) – величина следующего шага
Идея в том, что вы сначала выбираете любую случайную точку из функции. Затем вам нужно вычислить производную от J()wrt. Это укажет направление локального минимума. Теперь умножьте полученный градиент на скорость обучения. Скорость обучения не имеет фиксированного значения и должна решаться на основе проблем.
Теперь вам нужно вычесть результат, чтобы получить новый .
Это обновление должно выполняться одновременно для каждого (i) .
Повторяйте эти шаги, пока не достигнете локального или глобального минимума. Достигнув глобального минимума, вы добились наименьших возможных потерь в своем прогнозе.
Взять производные просто. Достаточно базовых математических вычислений, которые вы должны были сделать в старшей школе. Основная проблема связана со скоростью обучения ( ). Хорошая скорость обучения важна и часто трудна.
Если вы выберете очень маленькую скорость обучения, каждый шаг будет слишком маленьким, и, следовательно, вам потребуется много времени, чтобы достичь локального минимума.

Теперь, если вы склонны брать огромное значение скорости обучения, вы превысите минимум и больше никогда не сойдетесь. Не существует конкретного правила идеальной скорости обучения.
Вам нужно настроить его, чтобы подготовить лучшую модель.
Уравнение градиентного спуска:
Повторять до сходимости:
Таким образом, мы можем резюмировать алгоритм градиентного спуска следующим образом:
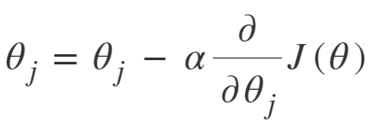
- Начните со случайного
- Цикл до сходимости:
- Вычислить градиент
- Обновлять
- Вернуть
Алгоритм стохастического градиентного спуска
Теперь алгоритм градиентного спуска является прекрасным алгоритмом для минимизации функции стоимости, особенно для небольших и средних данных. Но когда нам нужно иметь дело с большими наборами данных, алгоритм градиентного спуска оказывается медленным в вычислениях. Причина проста: необходимо вычислить градиент и обновить значения одновременно для каждого параметра, а также для каждого обучающего примера.
Так что подумайте обо всех этих расчетах! Он огромен, и поэтому возникла потребность в слегка модифицированном алгоритме градиентного спуска, а именно – алгоритме стохастического градиентного спуска (SGD).
Единственное отличие SGD от нормального градиентного спуска состоит в том, что в SGD мы не имеем дело со всем обучающим экземпляром за один раз. В SGD мы вычисляем градиент функции стоимости только для одного случайного примера на каждой итерации.
Теперь это значительно сокращает время, затрачиваемое на вычисления, особенно для больших наборов данных. Путь, выбранный SGD, очень случайный и шумный (хотя шумный путь может дать нам шанс достичь глобальных минимумов).
Но это нормально, так как нам не нужно беспокоиться о выбранном пути.
Нам нужно только достичь минимальных потерь в более быстрое время.
Таким образом, мы можем резюмировать алгоритм градиентного спуска следующим образом:
- Цикл до сходимости:
- Выберите одну точку данных ' i'
- Вычислить градиент по этой единственной точке
- Обновлять
- Вернуть
Алгоритм мини-пакетного градиентного спуска
Мини-пакетный градиентный спуск — еще одна небольшая модификация алгоритма градиентного спуска. Это нечто среднее между нормальным градиентным спуском и стохастическим градиентным спуском.
Мини-пакетный градиентный спуск просто берет меньшую партию всего набора данных, а затем минимизирует потери в нем.
Этот процесс более эффективен, чем два вышеупомянутых алгоритма градиентного спуска. Теперь размер партии может быть, конечно, любым, который вы хотите.
Но исследователи показали, что лучше держать его в пределах от 1 до 100, причем 32 — лучший размер партии.
Следовательно, размер партии = 32 используется по умолчанию в большинстве фреймворков.
- Цикл до сходимости:
- Выберите набор точек данных ' b '
- Вычислить градиент над этой партией
- Обновлять
- Вернуть
Заключение
Теперь у вас есть теоретическое понимание логистической регрессии. Вы научились математически представлять логистическую функцию. Вы знаете, как измерить прогнозируемую ошибку с помощью функции стоимости.
Вы также знаете, как можно минимизировать эту потерю, используя алгоритм градиентного спуска.
Наконец, вы знаете, какой вариант алгоритма градиентного спуска выбрать для своей задачи. upGrad предоставляет диплом PG в области машинного обучения и искусственного интеллекта и степень магистра наук в области машинного обучения и искусственного интеллекта , которые могут помочь вам построить карьеру. Эти курсы объяснят необходимость машинного обучения и дальнейшие шаги по сбору знаний в этой области, охватывающие различные концепции, от алгоритмов градиентного спуска до нейронных сетей.
Что такое алгоритм градиентного спуска?
Градиентный спуск — это алгоритм оптимизации для нахождения минимума функции. Предположим, вы хотите найти минимум функции f(x) между двумя точками (a, b) и (c, d) на графике y = f(x). Тогда градиентный спуск состоит из трех шагов: (1) выбрать точку посередине между двумя конечными точками, (2) вычислить градиент ∇f(x) (3) двигаться в направлении, противоположном градиенту, т. е. из (c, d) в (а, б). Об этом можно думать так: алгоритм определяет наклон функции в точке, а затем движется в направлении, противоположном наклону.
Что такое сигмовидная функция?
Сигмовидная функция или сигмовидная кривая — это тип математической функции, которая является нелинейной и очень похожа по форме на букву S (отсюда и название). Он используется в исследованиях операций, статистике и других дисциплинах для моделирования определенных форм реального роста. Он также используется в широком спектре приложений в компьютерных науках и технике, особенно в областях, связанных с нейронными сетями и искусственным интеллектом. Сигмовидные функции используются как часть входных данных для алгоритмов обучения с подкреплением, основанных на искусственных нейронных сетях.
Что такое алгоритм стохастического градиентного спуска?
Стохастический градиентный спуск — это один из популярных вариантов классического алгоритма градиентного спуска для поиска локальных минимумов функции. Алгоритм случайным образом выбирает направление, в котором функция будет двигаться дальше, чтобы минимизировать значение, и направление повторяется до тех пор, пока не будет достигнут локальный минимум. Цель состоит в том, чтобы при непрерывном повторении этого процесса алгоритм сходился к глобальному или локальному минимуму функции.