
Front-End Performance 2021: планирование и показатели
Опубликовано: 2022-03-10Это руководство было любезно поддержано нашими друзьями из LogRocket, службы, которая сочетает в себе мониторинг производительности внешнего интерфейса , воспроизведение сеанса и аналитику продукта, чтобы помочь вам повысить качество обслуживания клиентов. LogRocket отслеживает ключевые показатели, в т.ч. DOM завершен, время до первого байта, задержка первого ввода, использование клиентского ЦП и памяти. Получите бесплатную пробную версию LogRocket сегодня.

Оглавление
- Подготовка: планирование и показатели
Культура производительности, Core Web Vitals, профили производительности, CrUX, Lighthouse, FID, TTI, CLS, устройства. - Постановка реалистичных целей
Бюджеты производительности, цели производительности, инфраструктура RAIL, бюджеты 170 КБ/30 КБ. - Определение среды
Выбор фреймворка, базовая стоимость производительности, Webpack, зависимости, CDN, архитектура интерфейса, CSR, SSR, CSR + SSR, статический рендеринг, предварительный рендеринг, шаблон PRPL. - Оптимизация активов
Brotli, AVIF, WebP, адаптивные изображения, AV1, адаптивная загрузка мультимедиа, сжатие видео, веб-шрифты, шрифты Google. - Оптимизация сборки
Модули JavaScript, паттерн модуль/номодуль, встряхивание дерева, разделение кода, подъем объема, Webpack, дифференциальное обслуживание, веб-воркер, WebAssembly, пакеты JavaScript, React, SPA, частичная гидратация, импорт при взаимодействии, третьи стороны, кеш. - Оптимизация доставки
Отложенная загрузка, наблюдатель пересечений, отложенный рендеринг и декодирование, критический CSS, потоковая передача, подсказки ресурсов, сдвиги макета, сервисный работник. - Сеть, HTTP/2, HTTP/3
Сшивание OCSP, сертификаты EV/DV, упаковка, IPv6, QUIC, HTTP/3. - Тестирование и мониторинг
Рабочий процесс аудита, прокси-браузеры, страница 404, запросы на согласие с файлами GDPR, CSS для диагностики производительности, специальные возможности. - Быстрые победы
- Все на одной странице
- Скачать контрольный список (PDF, Apple Pages, MS Word)
- Подпишитесь на нашу рассылку по электронной почте, чтобы не пропустить следующие руководства.
Подготовка: планирование и показатели
Микрооптимизация отлично подходит для поддержания производительности на правильном пути, но очень важно иметь в виду четко определенные цели — измеримые цели, которые будут влиять на любые решения, принимаемые на протяжении всего процесса. Есть несколько разных моделей, и те, что обсуждаются ниже, довольно самоуверенны — просто убедитесь, что вы установили свои собственные приоритеты на раннем этапе.
- Создайте культуру исполнения.
Во многих организациях фронтенд-разработчики точно знают, какие распространенные основные проблемы и какие стратегии следует использовать для их устранения. Однако до тех пор, пока не будет установленного одобрения культуры исполнения, каждое решение превратится в поле битвы между отделами, разбивая организацию на бункеры. Вам нужна поддержка заинтересованных сторон, а чтобы получить ее, вам необходимо создать тематическое исследование или доказательство концепции того, как скорость — особенно Core Web Vitals , которые мы подробно рассмотрим позже, — приносит пользу метрикам и ключевым показателям эффективности. ( KPI ), о которых они заботятся.Например, чтобы сделать производительность более ощутимой, вы можете выявить влияние на доход, показав корреляцию между коэффициентом конверсии и временем загрузки приложения, а также производительностью рендеринга. Или скорость сканирования поисковым роботом (PDF, стр. 27–50).
Без тесного взаимодействия между командами разработчиков/дизайнеров и бизнеса/маркетологов производительность не будет поддерживаться в долгосрочной перспективе. Изучите распространенные жалобы, поступающие в отдел обслуживания клиентов и отдел продаж, изучите аналитику на предмет высоких показателей отказов и падения конверсии. Узнайте, как повышение производительности может помочь решить некоторые из этих распространенных проблем. Скорректируйте аргумент в зависимости от группы заинтересованных сторон, с которой вы разговариваете.
Проводите эксперименты с производительностью и оценивайте результаты — как на мобильных устройствах, так и на компьютерах (например, с помощью Google Analytics). Это поможет вам создать индивидуальный кейс с реальными данными. Кроме того, использование данных тематических исследований и экспериментов, опубликованных в WPO Stats, поможет повысить чувствительность бизнеса к тому, почему производительность имеет значение и какое влияние она оказывает на пользовательский опыт и бизнес-показатели. Однако одного утверждения о том, что производительность имеет значение, недостаточно — вам также необходимо установить некоторые измеримые и отслеживаемые цели и соблюдать их с течением времени.
Как туда добраться? В своем выступлении на тему «Повышение производительности в долгосрочной перспективе» Эллисон Макнайт рассказывает о том, как она помогла создать культуру производительности на Etsy (слайды). Совсем недавно Тэмми Эвертс рассказала о привычках высокоэффективных команд как в малых, так и в крупных организациях.
Ведя эти разговоры в организациях, важно помнить, что точно так же, как UX — это спектр опыта, веб-производительность — это распределение. Как отметила Каролина Щур, «ожидание, что одно число сможет дать рейтинг, к которому можно стремиться, является ошибочным предположением». Следовательно, цели производительности должны быть детализированными, отслеживаемыми и осязаемыми.
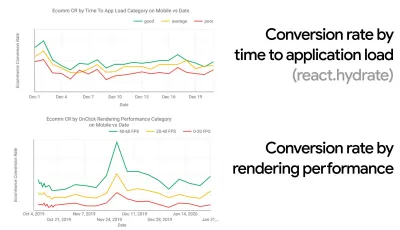
- Цель: быть как минимум на 20% быстрее своего самого быстрого конкурента.
Согласно психологическим исследованиям, если вы хотите, чтобы пользователи чувствовали, что ваш сайт работает быстрее, чем сайт вашего конкурента, вам нужно быть как минимум на 20% быстрее. Изучите своих основных конкурентов, соберите показатели их эффективности на мобильных устройствах и компьютерах и установите пороговые значения, которые помогут вам опередить их. Однако, чтобы получить точные результаты и цели, сначала обязательно получите полное представление об опыте ваших пользователей, изучив свою аналитику. Затем вы можете имитировать опыт 90-го процентиля для тестирования.Чтобы получить хорошее первое впечатление о том, как работают ваши конкуренты, вы можете использовать Chrome UX Report ( CrUX , готовый набор данных RUM, вводное видео Ильи Григорика и подробное руководство Рика Вискоми) или Treo, инструмент мониторинга RUM, который работает на основе отчета Chrome UX. Данные собираются от пользователей браузера Chrome, поэтому отчеты будут специфичными для Chrome, но они дадут вам довольно подробное распределение производительности, особенно баллов Core Web Vitals, среди широкого круга ваших посетителей. Обратите внимание, что новые наборы данных CrUX публикуются во второй вторник каждого месяца .
Кроме того, вы также можете использовать:
- Инструмент сравнения отчетов Chrome UX Эдди Османи,
- Карта показателей скорости (также предоставляет оценку влияния на доход),
- Сравнение тестов реального взаимодействия с пользователем или
- SiteSpeed CI (на основе синтетического тестирования).
Примечание . Если вы используете Page Speed Insights или Page Speed Insights API (нет, это не устарело!), вы можете получать данные о производительности CrUX для конкретных страниц, а не только сводные данные. Эти данные могут быть гораздо полезнее для определения целевых показателей эффективности для таких ресурсов, как «целевая страница» или «список продуктов». И если вы используете CI для тестирования бюджетов, вам нужно убедиться, что ваша тестируемая среда соответствует CrUX, если вы использовали CrUX для установки цели ( спасибо, Патрик Минан! ).
Если вам нужна помощь, чтобы показать причины приоритета скорости, или вы хотите визуализировать падение коэффициента конверсии или увеличение показателя отказов при более низкой производительности, или, возможно, вам нужно отстаивать решение RUM в вашей организации, Сергей. Чернышев создал UX Speed Calculator, инструмент с открытым исходным кодом, который помогает вам моделировать данные и визуализировать их, чтобы донести свою точку зрения.
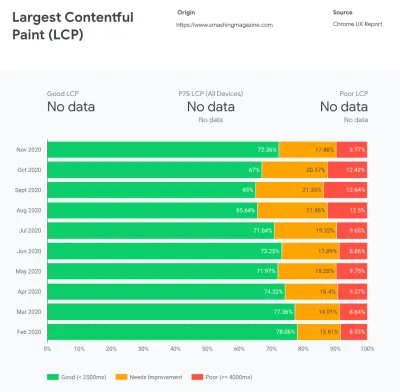
CrUX создает обзор распределения производительности с течением времени, используя трафик, полученный от пользователей Google Chrome. Вы можете создать свой собственный на Chrome UX Dashboard. (Большой превью) 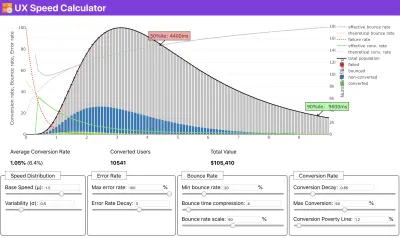
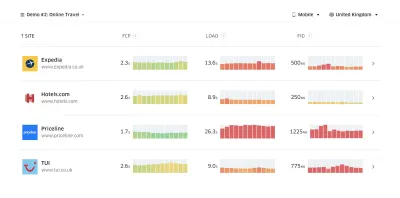
Как раз тогда, когда вам нужно обосновать эффективность, чтобы донести свою точку зрения: UX Speed Calculator визуализирует влияние производительности на показатель отказов, конверсию и общий доход — на основе реальных данных. (Большой превью) Иногда вы можете захотеть пойти немного глубже, объединив данные, поступающие от CrUX, с любыми другими данными, которые у вас уже есть, чтобы быстро определить, где лежат замедления, слепые зоны и неэффективность — для ваших конкурентов или для вашего проекта. В своей работе Гарри Робертс использовал электронную таблицу топографии скорости сайта, которую он использует для разбивки производительности по ключевым типам страниц и отслеживания того, как различаются ключевые показатели для них. Вы можете загрузить электронную таблицу в формате Google Sheets, Excel, документа OpenOffice или CSV.
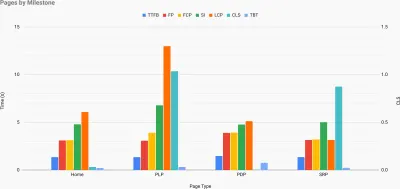
Топография скорости сайта с ключевыми показателями, представленными для ключевых страниц сайта. (Большой превью) И если вы хотите пройти весь путь, вы можете запустить аудит производительности Lighthouse на каждой странице сайта (через Lightouse Parade) с сохранением вывода в формате CSV. Это поможет вам определить, какие конкретные страницы (или типы страниц) ваших конкурентов работают хуже или лучше, и на чем вы могли бы сосредоточить свои усилия. (Для вашего собственного сайта, вероятно, лучше отправлять данные на конечную точку аналитики!).

С помощью Lighthouse Parade вы можете запустить аудит производительности Lighthouse на каждой странице сайта с сохранением результатов в формате CSV. (Большой превью) Соберите данные, настройте электронную таблицу, сократите 20% и настройте свои цели ( бюджеты производительности ) таким образом. Теперь у вас есть что-то измеримое для тестирования. Если вы держите в уме бюджет и пытаетесь отправить только минимальную полезную нагрузку, чтобы получить быстрое время до интерактивности, то вы на разумном пути.
Нужны ресурсы для начала?
- Эдди Османи написала очень подробный отчет о том, как начать бюджетирование по результатам, как количественно оценить влияние новых функций и с чего начать, если вы превысили бюджет.
- Руководство Лары Хоган о том, как подходить к дизайну с бюджетом производительности, может дать дизайнерам полезные подсказки.
- Гарри Робертс опубликовал руководство по настройке Google Sheet для отображения влияния сторонних скриптов на производительность с помощью Request Map,
- Калькулятор бюджета производительности Джонатана Филдинга, калькулятор производительности бюджета Кэти Хемпениус и Browser Calories могут помочь в составлении бюджета (спасибо Каролине Щур за советы).
- Во многих компаниях бюджеты по результатам должны быть не желательными, а скорее прагматичными, выступая в качестве удерживающего знака, позволяющего избежать скольжения за определенную точку. В этом случае вы можете выбрать худшую точку данных за последние две недели в качестве порога и взять ее оттуда. Бюджеты производительности, Pragmatically показывает вам стратегию для достижения этого.
- Кроме того, сделайте бюджет производительности и текущую производительность видимыми , настроив информационные панели с графиками, отображающими размеры сборок. Есть много инструментов, позволяющих вам добиться этого: панель инструментов SiteSpeed.io (с открытым исходным кодом), SpeedCurve и Caliber — лишь некоторые из них, и вы можете найти больше инструментов на perf.rocks.

Калории браузера помогают вам установить бюджет производительности и измерить, превышает ли страница эти цифры или нет. (Большой превью) После того, как у вас есть бюджет, включите его в процесс сборки с помощью Webpack Performance Hints и Bundlesize, Lighthouse CI, PWMetrics или Sitespeed CI, чтобы контролировать бюджеты по запросам на вытягивание и предоставлять историю оценок в PR-комментариях.
Чтобы представить бюджеты производительности всей команде, интегрируйте бюджеты производительности в Lighthouse через Lightwallet или используйте LHCI Action для быстрой интеграции Github Actions. А если вам нужно что-то нестандартное, вы можете использовать webpagetest-charts-api, API конечных точек для построения диаграмм на основе результатов WebPagetest.
Однако осведомленность о производительности не должна исходить только от бюджетов производительности. Как и в случае с Pinterest, вы можете создать собственное правило eslint , которое запрещает импорт из файлов и каталогов, которые, как известно, сильно зависимы и могут раздуть пакет. Настройте список «безопасных» пакетов, которыми можно поделиться со всей командой.
Кроме того, подумайте о важнейших задачах клиентов, которые наиболее выгодны для вашего бизнеса. Изучите, обсудите и определите приемлемые временные пороги для критических действий и установите метки времени пользователя «Готово к UX», одобренные всей организацией. Во многих случаях пути пользователей будут касаться работы многих различных отделов, поэтому согласование с точки зрения приемлемого времени поможет поддержать или предотвратить обсуждение производительности в будущем. Убедитесь, что дополнительные затраты на дополнительные ресурсы и функции видны и понятны.
Согласуйте усилия по повышению производительности с другими техническими инициативами, начиная от новых функций создаваемого продукта и заканчивая рефакторингом и выходом на новую глобальную аудиторию. Поэтому каждый раз, когда происходит разговор о дальнейшем развитии, производительность также является частью этого разговора. Гораздо проще достичь целей производительности, когда кодовая база свежая или только что подверглась рефакторингу.
Кроме того, как предложил Патрик Минан, стоит спланировать последовательность загрузки и компромиссы в процессе проектирования. Если вы заранее расставите приоритеты, какие части являются более важными, и определите порядок, в котором они должны появляться, вы также будете знать, что может быть отложено. В идеале этот порядок также будет отражать последовательность вашего импорта CSS и JavaScript, поэтому обрабатывать их в процессе сборки будет проще. Кроме того, подумайте, каким должен быть визуальный опыт в «промежуточных» состояниях во время загрузки страницы (например, когда веб-шрифты еще не загружены).
После того, как вы создали сильную культуру производительности в своей организации, стремитесь быть на 20% быстрее, чем вы были раньше, чтобы сохранять приоритеты в такт с течением времени ( спасибо, Гай Поджарный! ). Но учитывайте различные типы и поведение ваших клиентов (которое Тобиас Бальдауф называл каденцией и когортами), а также трафик ботов и эффекты сезонности.
Планирование, планирование, планирование. Может показаться заманчивым заняться быстрой оптимизацией «низко висящих плодов» на раннем этапе — и это может быть хорошей стратегией для быстрых побед — но будет очень сложно сохранить производительность приоритетом без планирования и настройки реалистичной компании. - индивидуальные цели производительности.
- Выбирайте правильные показатели.
Не все показатели одинаково важны. Изучите, какие метрики наиболее важны для вашего приложения: обычно они будут определяться тем, насколько быстро вы сможете начать рендеринг наиболее важных пикселей вашего интерфейса и насколько быстро вы сможете обеспечить реакцию ввода для этих отображаемых пикселов. Эти знания дадут вам наилучшую цель оптимизации для текущих усилий. В конце концов, опыт определяется не событиями загрузки или временем отклика сервера, а восприятием того, насколько быстрым кажется интерфейс.Что это значит? Вместо того, чтобы сосредотачиваться на полном времени загрузки страницы (например, с помощью таймингов onLoad и DOMContentLoaded ), расставьте приоритеты загрузки страницы, как их воспринимают ваши клиенты. Это означает, что нужно сосредоточиться на немного другом наборе показателей. На самом деле выбор правильной метрики — это процесс без явных победителей.
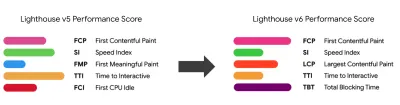
Основываясь на исследовании Тима Кадлека и заметках Маркоса Иглесиаса в его выступлении, традиционные метрики можно сгруппировать в несколько наборов. Обычно нам нужны все из них, чтобы получить полную картину производительности, и в вашем конкретном случае некоторые из них будут более важными, чем другие.
- Метрики, основанные на количестве, измеряют количество запросов, вес и оценку производительности. Хорошо подходит для подачи сигналов тревоги и отслеживания изменений с течением времени, но не очень хорошо для понимания взаимодействия с пользователем.
- Метрики Milestone используют состояния во время жизни процесса загрузки, например Time To First Byte и Time To Interactive . Хорошо подходит для описания пользовательского опыта и мониторинга, но не очень хорошо для понимания того, что происходит между вехами.
- Показатели рендеринга позволяют оценить скорость рендеринга контента (например, время начала рендеринга , индекс скорости ). Хорошо подходит для измерения и настройки производительности рендеринга, но не так хорош для измерения того, когда появляется важный контент и с ним можно взаимодействовать.
- Пользовательские метрики измеряют конкретное пользовательское событие для пользователя, например время до первого твита в Twitter и PinnerWaitTime в Pinterest. Хорошо для точного описания пользовательского опыта, но не очень хорошо для масштабирования метрик и сравнения с конкурентами.
Для полноты картины мы обычно ищем полезные метрики среди всех этих групп. Обычно наиболее конкретными и актуальными являются:
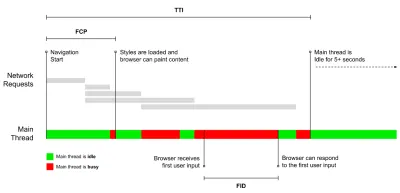
- Время до интерактивности (TTI)
Точка, в которой макет стабилизировался , основные веб-шрифты видны, а основной поток доступен достаточно для обработки пользовательского ввода — по сути, отметка времени, когда пользователь может взаимодействовать с пользовательским интерфейсом. Ключевые показатели для понимания того, сколько времени приходится ждать пользователю, чтобы пользоваться сайтом без задержек. Борис Шапира написал подробный пост о том, как надежно измерить TTI. - Первая задержка ввода (FID) , или реакция ввода
Время с момента, когда пользователь впервые взаимодействует с вашим сайтом, до момента, когда браузер фактически может реагировать на это взаимодействие. Очень хорошо дополняет TTI, поскольку описывает недостающую часть картины: что происходит, когда пользователь фактически взаимодействует с сайтом. Предназначен только как показатель RUM. В браузере есть библиотека JavaScript для измерения FID. - Самая большая содержательная краска (LCP)
Отмечает точку на временной шкале загрузки страницы, когда, вероятно, загрузился важный контент страницы. Предполагается, что наиболее важным элементом страницы является самый большой элемент, видимый в области просмотра пользователя. Если элементы отображаются как выше, так и ниже сгиба, релевантной считается только видимая часть. - Общее время блокировки ( TBT )
Метрика, которая помогает количественно оценить серьезность того, насколько неинтерактивной является страница, до того, как она станет надежно интерактивной (то есть основной поток был свободен от каких-либо задач, выполняющихся более 50 мс ( длительных задач ) в течение как минимум 5 с). Метрика измеряет общее количество времени между первой отрисовкой и временем до взаимодействия (TTI), когда основной поток был заблокирован на достаточно долгое время, чтобы предотвратить реакцию на ввод. Поэтому неудивительно, что низкий показатель TBT является хорошим показателем хорошей производительности. (спасибо, Артем, Фил) - Совокупный сдвиг макета ( CLS )
Метрика показывает, как часто пользователи сталкиваются с неожиданными изменениями макета ( перекомпоновки ) при доступе к сайту. Он исследует нестабильные элементы и их влияние на общий опыт. Чем ниже оценка, тем лучше. - Индекс скорости
Измеряет, насколько быстро содержимое страницы визуально заполняется; чем ниже оценка, тем лучше. Оценка индекса скорости рассчитывается на основе скорости визуального прогресса , но это всего лишь расчетное значение. Он также чувствителен к размеру области просмотра, поэтому вам необходимо определить диапазон конфигураций тестирования, которые соответствуют вашей целевой аудитории. Обратите внимание, что это становится менее важным, когда LCP становится более актуальной метрикой ( спасибо, Борис, Артем! ). - Затраченное процессорное время
Метрика, показывающая, как часто и как долго блокируется основной поток, работающий над отрисовкой, рендерингом, скриптингом и загрузкой. Высокое время ЦП является явным индикатором нестабильности , т. е. когда пользователь испытывает заметную задержку между своим действием и ответом. С помощью WebPageTest вы можете выбрать «Capture Dev Tools Timeline» на вкладке «Chrome», чтобы показать разбивку основного потока, когда он работает на любом устройстве с помощью WebPageTest. - Затраты ЦП на уровне компонентов
Так же, как и время, затраченное ЦП , эта метрика, предложенная Стояном Стефановым, исследует влияние JavaScript на ЦП . Идея состоит в том, чтобы использовать количество инструкций ЦП для каждого компонента, чтобы понять их влияние на общий опыт, изолированно. Может быть реализовано с помощью Puppeteer и Chrome. - FrustrationIndex
В то время как многие метрики, представленные выше, объясняют, когда происходит конкретное событие, FrustrationIndex Тима Вереке рассматривает разрывы между метриками, а не рассматривает их по отдельности. Он рассматривает ключевые вехи, воспринимаемые конечным пользователем, такие как «Заголовок виден», «Первое содержимое видно», «Визуально готово» и «Страница выглядит готово», и вычисляет оценку, указывающую уровень разочарования при загрузке страницы. Чем больше разрыв, тем больше вероятность, что пользователь разочаруется. Потенциально хороший KPI для пользовательского опыта. Тим опубликовал подробный пост о FrustrationIndex и о том, как он работает. - Влияние веса рекламы
Если доход вашего сайта зависит от рекламы, полезно отслеживать вес кода, связанного с рекламой. Сценарий Пэдди Ганти создает два URL-адреса (один обычный и один блокирующий рекламу), запрашивает создание сравнения видео через WebPageTest и сообщает о разнице. - Показатели отклонения
Как отмечают инженеры Википедии, данные о том, насколько велики различия в ваших результатах, могут сообщить вам, насколько надежны ваши инструменты и сколько внимания вы должны уделять отклонениям и отклонениям. Большая дисперсия является индикатором корректировок, необходимых в настройке. Это также помогает понять, трудно ли надежно измерить определенные страницы, например, из-за сторонних скриптов, вызывающих значительные различия. Также может быть хорошей идеей отслеживать версию браузера, чтобы понять скачки производительности при выпуске новой версии браузера. - Пользовательские показатели
Пользовательские метрики определяются вашими бизнес-потребностями и опытом клиентов. Это требует, чтобы вы определили важные пиксели, критические скрипты, необходимый CSS и соответствующие активы и измерили, насколько быстро они доставляются пользователю. Для этого вы можете отслеживать время рендеринга героев или использовать API производительности, отмечая определенные временные метки для важных для вашего бизнеса событий. Кроме того, вы можете собирать пользовательские метрики с помощью WebPagetest, выполняя произвольный JavaScript в конце теста.
Обратите внимание, что первая значимая краска (FMP) не отображается в приведенном выше обзоре. Раньше он давал представление о том, как быстро сервер выводит какие -либо данные. Длинный FMP обычно указывал на то, что JavaScript блокирует основной поток, но также может быть связан с внутренними/серверными проблемами. Однако в последнее время эта метрика устарела, поскольку примерно в 20% случаев она оказывается неточной. Он был эффективно заменен на LCP, который является более надежным и простым в использовании. Он больше не поддерживается в Lighthouse. Дважды проверьте последние ориентированные на пользователя показатели производительности и рекомендации, чтобы убедиться, что вы находитесь на безопасной странице ( спасибо, Патрик Минан ).

У Стива Содерса есть подробное объяснение многих из этих показателей. Важно отметить, что, хотя время до взаимодействия измеряется путем проведения автоматизированных аудитов в так называемой лабораторной среде , задержка первого ввода представляет фактическое взаимодействие с пользователем, при этом реальные пользователи испытывают заметное отставание. В общем, вероятно, было бы неплохо всегда измерять и отслеживать их оба.
В зависимости от контекста вашего приложения предпочтительные метрики могут различаться: например, для пользовательского интерфейса Netflix TV более важными являются скорость отклика при вводе клавиш, использование памяти и TTI, а для Википедии более важны первые/последние визуальные изменения и показатели затраченного процессорного времени.
Примечание . И FID, и TTI не учитывают поведение прокрутки; прокрутка может происходить независимо, так как она находится вне основного потока, поэтому для многих сайтов потребления контента эти показатели могут быть гораздо менее важными ( спасибо, Патрик! ).
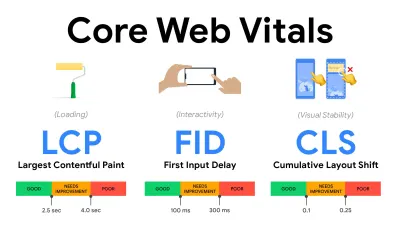
- Измеряйте и оптимизируйте Core Web Vitals .
Долгое время метрики производительности были чисто техническими, ориентируясь на инженерное представление о том, насколько быстро серверы отвечают и насколько быстро загружаются браузеры. Показатели менялись с годами — мы пытались найти способ зафиксировать фактическое взаимодействие с пользователем, а не тайминги сервера. В мае 2020 года Google анонсировала Core Web Vitals, набор новых показателей производительности, ориентированных на пользователя, каждый из которых представляет собой отдельный аспект взаимодействия с пользователем.Для каждого из них Google рекомендует диапазон приемлемых целей скорости. Чтобы пройти эту оценку, не менее 75 % всех просмотров страниц должны превышать диапазон «Хорошо ». Эти показатели быстро завоевали популярность, и, поскольку Core Web Vitals стали сигналами ранжирования для поиска Google в мае 2021 года ( обновление алгоритма ранжирования Page Experience ), многие компании обратили внимание на свои показатели эффективности.
Давайте разберем каждый из основных веб-показателей один за другим, а также полезные методы и инструменты для оптимизации вашего опыта с учетом этих показателей. (Стоит отметить, что вы получите более высокие баллы Core Web Vitals, если будете следовать общим советам из этой статьи.)
- Самая большая содержательная отрисовка ( LCP ) < 2,5 сек.
Измеряет загрузку страницы и сообщает о времени рендеринга самого большого изображения или текстового блока , видимого в области просмотра. Следовательно, на LCP влияет все, что откладывает рендеринг важной информации — будь то медленное время отклика сервера, блокировка CSS, работающий JavaScript (собственный или сторонний), загрузка веб-шрифтов, дорогостоящие операции рендеринга или рисования, ленивый загруженные изображения, каркасные экраны или рендеринг на стороне клиента.
Для удобства LCP должен выполняться в течение 2,5 с после первой загрузки страницы. Это означает, что нам нужно отобразить первую видимую часть страницы как можно раньше. Это потребует адаптированного критического CSS для каждого шаблона, оркестровки<head>-order и предварительной выборки критически важных ресурсов (мы рассмотрим их позже).Основной причиной низкой оценки LCP обычно являются изображения. Чтобы доставить LCP менее чем за 2,5 с на Fast 3G — размещенном на хорошо оптимизированном сервере, полностью статичном без рендеринга на стороне клиента и с изображением, поступающим из выделенной сети доставки изображений — это означает, что максимальный теоретический размер изображения составляет всего около 144 КБ . Вот почему так важны адаптивные изображения, а также ранняя предварительная загрузка важных изображений (с
preload).Небольшой совет : чтобы узнать, что считается LCP на странице, в DevTools вы можете навести указатель мыши на значок LCP в разделе «Время» на панели производительности ( спасибо, Тим Кадлек !).
- Задержка первого входа ( FID ) < 100 мс.
Измеряет скорость отклика пользовательского интерфейса, т. е . как долго браузер был занят другими задачами, прежде чем он смог отреагировать на дискретное событие пользовательского ввода, например касание или щелчок. Он предназначен для отслеживания задержек, возникающих из-за занятости основного потока, особенно во время загрузки страницы.
Цель состоит в том, чтобы оставаться в пределах 50–100 мс для каждого взаимодействия. Чтобы достичь этого, нам нужно идентифицировать длинные задачи (блокирует основной поток на> 50 мс) и разбить их, разбить код на несколько частей, сократить время выполнения JavaScript, оптимизировать выборку данных, отложить выполнение скриптов сторонних разработчиков. , переместите JavaScript в фоновый поток с помощью веб-воркеров и используйте прогрессивную гидратацию, чтобы снизить затраты на регидратацию в SPA.Небольшой совет : как правило, надежная стратегия для получения более высокой оценки FID заключается в том, чтобы свести к минимуму работу в основном потоке , разбивая большие пакеты на более мелкие и предоставляя то, что нужно пользователю, когда ему это нужно, чтобы взаимодействие с пользователем не задерживалось. . Подробнее об этом мы расскажем ниже.
- Совокупный сдвиг макета ( CLS ) <0,1.
Измеряет визуальную стабильность пользовательского интерфейса для обеспечения плавного и естественного взаимодействия, т. е. общую сумму всех индивидуальных оценок смещения макета для каждого неожиданного изменения макета, которое происходит в течение срока службы страницы. Индивидуальное смещение макета происходит каждый раз, когда элемент, который уже был виден, меняет свое положение на странице. Он оценивается в зависимости от размера контента и расстояния, на которое он был перемещен.
Таким образом, каждый раз, когда происходит изменение — например, когда запасные шрифты и веб-шрифты имеют разные метрики шрифта, или реклама, встраивание или iframe появляются с опозданием, или размеры изображения/видео не зарезервированы, или поздний CSS принудительно перекрашивает, или изменения вводятся поздний JavaScript — это влияет на оценку CLS. Рекомендуемое значение для хорошего опыта — CLS < 0,1.
Стоит отметить, что Core Web Vitals должны развиваться с течением времени с предсказуемым годовым циклом . В течение первого года обновления мы можем ожидать, что First Contentful Paint будет повышен до Core Web Vitals, снижен порог FID и улучшена поддержка одностраничных приложений. Мы также можем увидеть, как ответы на вводимые пользователем данные после нагрузки приобретают все больший вес, наряду с соображениями безопасности, конфиденциальности и доступности (!).
Что касается Core Web Vitals, существует множество полезных ресурсов и статей, на которые стоит обратить внимание:
- Web Vitals Leaderboard позволяет сравнивать свои результаты с конкурентами на мобильных устройствах, планшетах, настольных компьютерах, а также в сетях 3G и 4G.
- Core SERP Vitals, расширение Chrome, которое показывает Core Web Vitals из CrUX в результатах поиска Google.
- Генератор Layout Shift GIF, который визуализирует CLS с помощью простого GIF (также доступен из командной строки).
- web-vitals может собирать и отправлять Core Web Vitals в Google Analytics, Диспетчер тегов Google или любую другую конечную точку аналитики.
- Анализ Web Vitals с помощью WebPageTest, в котором Патрик Минан исследует, как WebPageTest предоставляет данные о Core Web Vitals.
- Оптимизация с помощью Core Web Vitals, 50-минутное видео с Эдди Османи, в котором он рассказывает, как улучшить Core Web Vitals на примере электронной коммерции.
- Cumulative Layout Shift in Practice и Cumulative Layout Shift in the Real World — подробные статьи Ника Янсмы, которые охватывают почти все, что касается CLS, и того, как она коррелирует с ключевыми показателями, такими как показатель отказов, время сеанса или клики Rage.
- What Forces Reflow, с обзором свойств или методов, при запросе/вызове в JavaScript, который заставит браузер синхронно вычислить стиль и макет.
- Триггеры CSS показывают, какие свойства CSS запускают Layout, Paint и Composite.
- Исправление нестабильности макета — это пошаговое руководство по использованию WebPageTest для выявления и устранения проблем нестабильности макета.
- Cumulative Layout Shift, The Layout Instability Metric, еще одно очень подробное руководство Бориса Шапира по CLS, как оно рассчитывается, как его измерять и как его оптимизировать.
- How To Improve Core Web Vitals — подробное руководство Саймона Херна по каждой метрике (включая другие Web Vitals, такие как FCP, TTI, TBT), когда они возникают и как они измеряются.
Итак, являются ли Core Web Vitals окончательными показателями ? Не совсем. Они действительно представлены в большинстве решений и платформ RUM, включая Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (уже в диафильме), Newrelic, Shopify, Next.js, во всех инструментах Google (PageSpeed Insights, Lighthouse + CI, Search консоли и др.) и многие другие.
Однако, как объясняет Кэти Силор-Миллер, некоторые из основных проблем с Core Web Vitals заключаются в отсутствии кросс-браузерной поддержки, мы на самом деле не измеряем полный жизненный цикл взаимодействия с пользователем, а также трудно сопоставить изменения в FID и CLS с бизнес-результатами.
Поскольку мы должны ожидать, что Core Web Vitals будет развиваться, кажется вполне разумным всегда комбинировать Web Vitals с вашими индивидуальными показателями, чтобы лучше понять, где вы находитесь с точки зрения производительности.
- Самая большая содержательная отрисовка ( LCP ) < 2,5 сек.
- Соберите данные об устройстве, представляющем вашу аудиторию.
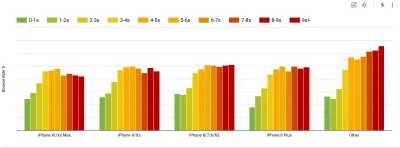
Чтобы собрать точные данные, нам нужно тщательно выбирать устройства для тестирования. В большинстве компаний это означает изучение аналитики и создание профилей пользователей на основе наиболее распространенных типов устройств. Однако зачастую аналитика сама по себе не дает полной картины. Значительная часть целевой аудитории может покинуть сайт (и не вернуться обратно) только потому, что их работа слишком медленная, и их устройства вряд ли будут отображаться как самые популярные устройства в аналитике по этой причине. Поэтому хорошей идеей может быть дополнительное исследование распространенных устройств в вашей целевой группе.По данным IDC, в 2020 году во всем мире 84,8% всех поставляемых мобильных телефонов являются устройствами Android. Средний потребитель обновляет свой телефон каждые 2 года, а в США цикл замены телефона составляет 33 месяца. В среднем самые продаваемые телефоны по всему миру будут стоить менее 200 долларов.
Таким образом, репрезентативным устройством является устройство Android, которому не менее 24 месяцев , стоимостью 200 долларов или меньше, работающее на медленном 3G, 400 мс RTT и 400 кбит / с, просто чтобы быть немного более пессимистичным. Конечно, это может сильно отличаться для вашей компании, но это достаточно близкое приближение к большинству клиентов. На самом деле, было бы неплохо изучить текущие бестселлеры Amazon для вашего целевого рынка. ( Спасибо Tim Kadlec, Henri Helvetica и Alex Russell за подсказки! ).
При создании нового сайта или приложения всегда сначала проверяйте текущие бестселлеры Amazon для вашего целевого рынка. (Большой превью) Какие тестовые устройства выбрать тогда? Те, которые хорошо вписываются в профиль, описанный выше. Это хороший вариант, чтобы выбрать немного более старый Moto G4/G5 Plus, устройство Samsung среднего класса (Galaxy A50, S8), хорошее устройство среднего уровня, такое как Nexus 5X, Xiaomi Mi A3 или Xiaomi Redmi Note. 7 и медленное устройство, такое как Alcatel 1X или Cubot X19, возможно, в открытой лаборатории устройств. Для тестирования на более медленных устройствах с терморегулированием вы также можете приобрести Nexus 4, который стоит всего около 100 долларов.
Кроме того, проверьте наборы микросхем, используемые в каждом устройстве, и не переоценивайте один набор микросхем : нескольких поколений Snapdragon и Apple, а также бюджетных Rockchip, Mediatek будет достаточно (спасибо, Патрик!) .
Если у вас нет устройства под рукой, эмулируйте мобильный опыт на настольном компьютере, протестировав сеть 3G с дросселированием (например, 300 мс RTT, 1,6 Мбит/с на вход, 0,8 Мбит/с) с дросселированием ЦП (замедление в 5 раз). Со временем переключитесь на обычный 3G, медленный 4G (например, 170 мс RTT, 9 Мбит/с входящий, 9 Мбит/с исходящий) и Wi-Fi. Чтобы сделать влияние на производительность более заметным, вы можете даже ввести 2G по вторникам или настроить регулируемую сеть 3G/4G в своем офисе для более быстрого тестирования.
Имейте в виду, что на мобильном устройстве следует ожидать замедления в 4–5 раз по сравнению с настольными компьютерами. Мобильные устройства имеют разные графические процессоры, процессоры, память и разные характеристики батареи. Вот почему важно иметь хороший профиль среднего устройства и всегда проводить тестирование на таком устройстве.
- Инструменты синтетического тестирования собирают лабораторные данные в воспроизводимой среде с предопределенными настройками устройства и сети (например, Lighthouse , Caliber , WebPageTest ) и
- Инструменты Real User Monitoring ( RUM ) постоянно оценивают взаимодействие пользователей и собирают полевые данные (например, SpeedCurve , New Relic — эти инструменты также обеспечивают синтетическое тестирование).
- используйте Lighthouse CI для отслеживания показателей Lighthouse с течением времени (это весьма впечатляет),
- запустите Lighthouse в GitHub Actions, чтобы получать отчет Lighthouse вместе с каждым PR,
- запустить аудит производительности Lighthouse на каждой странице сайта (через Lightouse Parade) с сохранением результатов в формате CSV,
- используйте калькулятор Lighthouse Scores Calculator и метрические веса Lighthouse, если вам нужно углубиться в детали.
- Lighthouse также доступен для Firefox, но внутри он использует API PageSpeed Insights и генерирует отчет на основе безголового пользовательского агента Chrome 79.

К счастью, есть много отличных вариантов, которые помогут вам автоматизировать сбор данных и измерить, как ваш сайт работает с течением времени в соответствии с этими показателями. Имейте в виду, что хорошая картина производительности охватывает набор показателей производительности, лабораторных данных и полевых данных:
Первый особенно полезен во время разработки , так как помогает выявлять, изолировать и устранять проблемы с производительностью во время работы над продуктом. Последнее полезно для долгосрочного обслуживания , поскольку оно поможет вам понять ваши узкие места в производительности, когда они происходят в реальном времени — когда пользователи фактически заходят на сайт.
Используя встроенные API-интерфейсы RUM, такие как Navigation Timing, Resource Timing, Paint Timing, Long Tasks и т. д., инструменты синтетического тестирования и RUM вместе дают полную картину производительности вашего приложения. Вы можете использовать Calibre, Treo, SpeedCurve, mPulse и Boomerang, Sitespeed.io, которые отлично подходят для мониторинга производительности. Кроме того, с заголовком Server Timing вы можете даже отслеживать производительность серверной и клиентской части в одном месте.
Примечание . Всегда безопаснее выбирать дроссели сетевого уровня, внешние по отношению к браузеру, поскольку, например, у DevTools есть проблемы с взаимодействием с HTTP/2 push из-за того, как он реализован ( спасибо, Йоав, Патрик !). Для Mac OS мы можем использовать Network Link Conditioner, для Windows — Windows Traffic Shaper, для Linux — netem, а для FreeBSD — dummynet.
Поскольку, скорее всего, вы будете проводить тестирование в Lighthouse, имейте в виду, что вы можете:
- Настройте «чистый» и «клиентский» профили для тестирования.
При выполнении тестов в инструментах пассивного мониторинга распространенной стратегией является отключение антивируса и фоновых задач ЦП, удаление фоновой передачи полосы пропускания и тестирование с чистым профилем пользователя без расширений браузера, чтобы избежать искажения результатов (в Firefox и в Chrome).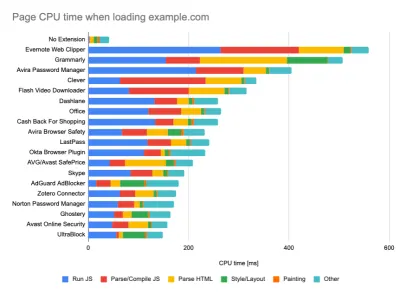
В отчете DebugBear указаны 20 самых медленных расширений, включая менеджеры паролей, блокировщики рекламы и популярные приложения, такие как Evernote и Grammarly. (Большой превью) Тем не менее, также рекомендуется изучить, какие расширения браузера часто используют ваши клиенты, а также протестировать их с помощью специальных профилей «клиентов» . На самом деле, некоторые расширения могут оказывать значительное влияние на производительность вашего приложения (отчет о производительности расширений Chrome за 2020 г.), и если ваши пользователи часто их используют, вы можете заранее учесть это. Следовательно, одни только «чистые» результаты профиля являются чрезмерно оптимистичными и могут быть разрушены в реальных сценариях.
- Поделитесь целями производительности с вашими коллегами.
Убедитесь, что цели эффективности знакомы каждому члену вашей команды, чтобы избежать недоразумений в будущем. Каждое решение — будь то дизайн, маркетинг или что-то промежуточное — влияет на производительность , а распределение ответственности и ответственности между всей командой упростит принятие решений, ориентированных на производительность, в дальнейшем. Сопоставьте проектные решения с бюджетом производительности и приоритетами, определенными на раннем этапе.
Оглавление
- Подготовка: планирование и показатели
- Постановка реалистичных целей
- Определение среды
- Оптимизация активов
- Оптимизация сборки
- Оптимизация доставки
- Сеть, HTTP/2, HTTP/3
- Тестирование и мониторинг
- Быстрые победы
- Все на одной странице
- Скачать контрольный список (PDF, Apple Pages, MS Word)
- Подпишитесь на нашу рассылку по электронной почте, чтобы не пропустить следующие руководства.