
Контрольный список производительности внешнего интерфейса на 2021 год (PDF, Apple Pages, MS Word)
Опубликовано: 2022-03-10Это руководство было любезно поддержано нашими друзьями из LogRocket, службы, которая сочетает в себе мониторинг производительности внешнего интерфейса , воспроизведение сеанса и аналитику продукта, чтобы помочь вам повысить качество обслуживания клиентов. LogRocket отслеживает ключевые показатели, в т.ч. DOM завершен, время до первого байта, задержка первого ввода, использование клиентского ЦП и памяти. Получите бесплатную пробную версию LogRocket сегодня.

Веб-производительность — хитрый зверь, не так ли? Как мы на самом деле узнаем, где мы находимся с точки зрения производительности и каковы именно наши узкие места в производительности? Это дорогой JavaScript, медленная доставка веб-шрифтов, тяжелые изображения или медленный рендеринг? Достаточно ли мы оптимизировали с помощью tree-shaking, подъема области действия, разделения кода и всех причудливых шаблонов загрузки с наблюдателем пересечений, прогрессивной гидратацией, клиентскими подсказками, HTTP/3, сервисными работниками и — о боже — пограничными работниками? И, самое главное, с чего мы вообще можем начать улучшать производительность и как нам создать культуру производительности в долгосрочной перспективе?
Раньше о производительности часто забывали . Часто отложенный до самого конца проекта, он сводился к минификации, конкатенации, оптимизации ресурсов и, возможно, нескольким тонким настройкам в файле config сервера. Сейчас, оглядываясь назад, кажется, что все очень сильно изменилось.
Производительность — это не просто техническая проблема: она влияет на все: от доступности до удобства использования и оптимизации для поисковых систем, и при внедрении ее в рабочий процесс дизайнерские решения должны основываться на их влиянии на производительность. Производительность необходимо постоянно измерять, отслеживать и улучшать , а растущая сложность Интернета создает новые проблемы, которые усложняют отслеживание показателей, поскольку данные будут значительно различаться в зависимости от устройства, браузера, протокола, типа сети и задержки ( CDN, интернет-провайдеры, кэши, прокси-серверы, брандмауэры, балансировщики нагрузки и серверы — все это играет роль в производительности).
Итак, если бы мы создали обзор всех вещей, которые мы должны иметь в виду при повышении производительности — с самого начала проекта до финальной версии веб-сайта — как бы это выглядело? Ниже вы найдете (надеюсь, беспристрастный и объективный) контрольный список производительности внешнего интерфейса на 2021 год — обновленный обзор проблем, которые вам, возможно, придется учитывать, чтобы обеспечить быстрое время отклика, плавное взаимодействие с пользователем и бесперебойную работу ваших сайтов. истощать пропускную способность пользователя.
Оглавление
- Все на отдельных страницах
- Подготовка: планирование и показатели
Культура производительности, Core Web Vitals, профили производительности, CrUX, Lighthouse, FID, TTI, CLS, устройства. - Постановка реалистичных целей
Бюджеты производительности, цели производительности, инфраструктура RAIL, бюджеты 170 КБ/30 КБ. - Определение среды
Выбор фреймворка, базовая стоимость производительности, Webpack, зависимости, CDN, архитектура интерфейса, CSR, SSR, CSR + SSR, статический рендеринг, предварительный рендеринг, шаблон PRPL. - Оптимизация активов
Brotli, AVIF, WebP, адаптивные изображения, AV1, адаптивная загрузка мультимедиа, сжатие видео, веб-шрифты, шрифты Google. - Оптимизация сборки
Модули JavaScript, паттерн модуль/номодуль, встряхивание дерева, разделение кода, подъем объема, Webpack, дифференциальное обслуживание, веб-воркер, WebAssembly, пакеты JavaScript, React, SPA, частичная гидратация, импорт при взаимодействии, третьи стороны, кеш. - Оптимизация доставки
Отложенная загрузка, наблюдатель пересечений, отложенный рендеринг и декодирование, критический CSS, потоковая передача, подсказки ресурсов, сдвиги макета, сервисный работник. - Сеть, HTTP/2, HTTP/3
Сшивание OCSP, сертификаты EV/DV, упаковка, IPv6, QUIC, HTTP/3. - Тестирование и мониторинг
Рабочий процесс аудита, прокси-браузеры, страница 404, запросы на согласие с файлами GDPR, CSS для диагностики производительности, специальные возможности. - Быстрые победы
- Скачать контрольный список (PDF, Apple Pages, MS Word)
- Поехали!
(Вы также можете просто загрузить контрольный список в формате PDF (166 КБ) или загрузить редактируемый файл Apple Pages (275 КБ) или файл .docx (151 КБ). Всем удачной оптимизации!)
Подготовка: планирование и показатели
Микрооптимизация отлично подходит для поддержания производительности на правильном пути, но очень важно иметь в виду четко определенные цели — измеримые цели, которые будут влиять на любые решения, принимаемые на протяжении всего процесса. Есть несколько разных моделей, и те, что обсуждаются ниже, довольно самоуверенны — просто убедитесь, что вы установили свои собственные приоритеты на раннем этапе.
- Создайте культуру исполнения.
Во многих организациях фронтенд-разработчики точно знают, какие распространенные основные проблемы и какие стратегии следует использовать для их устранения. Однако до тех пор, пока не будет установленного одобрения культуры исполнения, каждое решение превратится в поле битвы между отделами, разбивая организацию на бункеры. Вам нужна поддержка заинтересованных сторон, а чтобы получить ее, вам необходимо создать тематическое исследование или доказательство концепции того, как скорость — особенно Core Web Vitals , которые мы подробно рассмотрим позже, — приносит пользу метрикам и ключевым показателям эффективности. ( KPI ), о которых они заботятся.Например, чтобы сделать производительность более ощутимой, вы можете выявить влияние на доход, показав корреляцию между коэффициентом конверсии и временем загрузки приложения, а также производительностью рендеринга. Или скорость сканирования поисковым роботом (PDF, стр. 27–50).
Без тесного взаимодействия между командами разработчиков/дизайнеров и бизнеса/маркетологов производительность не будет поддерживаться в долгосрочной перспективе. Изучите распространенные жалобы, поступающие в отдел обслуживания клиентов и отдел продаж, изучите аналитику на предмет высоких показателей отказов и падения конверсии. Узнайте, как повышение производительности может помочь решить некоторые из этих распространенных проблем. Скорректируйте аргумент в зависимости от группы заинтересованных сторон, с которой вы разговариваете.
Проводите эксперименты с производительностью и оценивайте результаты — как на мобильных устройствах, так и на компьютерах (например, с помощью Google Analytics). Это поможет вам создать индивидуальный кейс с реальными данными. Кроме того, использование данных тематических исследований и экспериментов, опубликованных в WPO Stats, поможет повысить чувствительность бизнеса к тому, почему производительность имеет значение и какое влияние она оказывает на пользовательский опыт и бизнес-показатели. Однако одного утверждения о том, что производительность имеет значение, недостаточно — вам также необходимо установить некоторые измеримые и отслеживаемые цели и соблюдать их с течением времени.
Как туда добраться? В своем выступлении на тему «Повышение производительности в долгосрочной перспективе» Эллисон Макнайт рассказывает о том, как она помогла создать культуру производительности на Etsy (слайды). Совсем недавно Тэмми Эвертс рассказала о привычках высокоэффективных команд как в малых, так и в крупных организациях.
Ведя эти разговоры в организациях, важно помнить, что точно так же, как UX — это спектр опыта, веб-производительность — это распределение. Как отметила Каролина Щур, «ожидание, что одно число сможет дать рейтинг, к которому можно стремиться, является ошибочным предположением». Следовательно, цели производительности должны быть детализированными, отслеживаемыми и осязаемыми.
- Цель: быть как минимум на 20% быстрее своего самого быстрого конкурента.
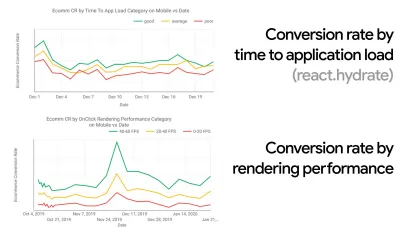
Согласно психологическим исследованиям, если вы хотите, чтобы пользователи чувствовали, что ваш сайт работает быстрее, чем сайт вашего конкурента, вам нужно быть как минимум на 20% быстрее. Изучите своих основных конкурентов, соберите показатели их эффективности на мобильных устройствах и компьютерах и установите пороговые значения, которые помогут вам опередить их. Однако, чтобы получить точные результаты и цели, сначала обязательно получите полное представление об опыте ваших пользователей, изучив свою аналитику. Затем вы можете имитировать опыт 90-го процентиля для тестирования.Чтобы получить хорошее первое впечатление о том, как работают ваши конкуренты, вы можете использовать Chrome UX Report ( CrUX , готовый набор данных RUM, вводное видео Ильи Григорика и подробное руководство Рика Вискоми) или Treo, инструмент мониторинга RUM, который работает на основе отчета Chrome UX. Данные собираются от пользователей браузера Chrome, поэтому отчеты будут специфичными для Chrome, но они дадут вам довольно подробное распределение производительности, особенно баллов Core Web Vitals, среди широкого круга ваших посетителей. Обратите внимание, что новые наборы данных CrUX публикуются во второй вторник каждого месяца .
Кроме того, вы также можете использовать:
- Инструмент сравнения отчетов Chrome UX Эдди Османи,
- Карта показателей скорости (также предоставляет оценку влияния на доход),
- Сравнение тестов реального взаимодействия с пользователем или
- SiteSpeed CI (на основе синтетического тестирования).
Примечание . Если вы используете Page Speed Insights или Page Speed Insights API (нет, это не устарело!), вы можете получать данные о производительности CrUX для конкретных страниц, а не только сводные данные. Эти данные могут быть гораздо полезнее для определения целевых показателей эффективности для таких ресурсов, как «целевая страница» или «список продуктов». И если вы используете CI для тестирования бюджетов, вам нужно убедиться, что ваша тестируемая среда соответствует CrUX, если вы использовали CrUX для установки цели ( спасибо, Патрик Минан! ).
Если вам нужна помощь, чтобы показать причины приоритета скорости, или вы хотите визуализировать падение коэффициента конверсии или увеличение показателя отказов при более низкой производительности, или, возможно, вам нужно отстаивать решение RUM в вашей организации, Сергей. Чернышев создал UX Speed Calculator, инструмент с открытым исходным кодом, который помогает вам моделировать данные и визуализировать их, чтобы донести свою точку зрения.
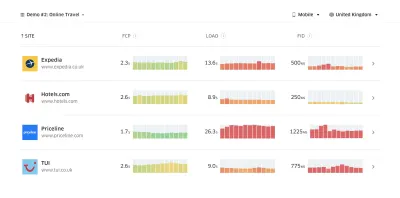
CrUX создает обзор распределения производительности с течением времени, используя трафик, полученный от пользователей Google Chrome. Вы можете создать свой собственный на Chrome UX Dashboard. (Большой превью) 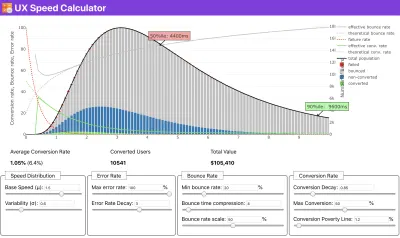
Как раз тогда, когда вам нужно обосновать эффективность, чтобы донести свою точку зрения: UX Speed Calculator визуализирует влияние производительности на показатель отказов, конверсию и общий доход — на основе реальных данных. (Большой превью) Иногда вы можете захотеть пойти немного глубже, объединив данные, поступающие от CrUX, с любыми другими данными, которые у вас уже есть, чтобы быстро определить, где лежат замедления, слепые зоны и неэффективность — для ваших конкурентов или для вашего проекта. В своей работе Гарри Робертс использовал электронную таблицу топографии скорости сайта, которую он использует для разбивки производительности по ключевым типам страниц и отслеживания того, как различаются ключевые показатели для них. Вы можете загрузить электронную таблицу в формате Google Sheets, Excel, документа OpenOffice или CSV.
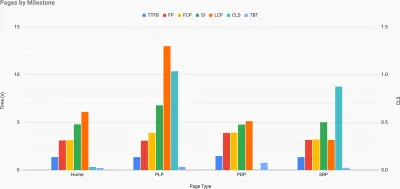
Топография скорости сайта с ключевыми показателями, представленными для ключевых страниц сайта. (Большой превью) И если вы хотите пройти весь путь, вы можете запустить аудит производительности Lighthouse на каждой странице сайта (через Lightouse Parade) с сохранением вывода в формате CSV. Это поможет вам определить, какие конкретные страницы (или типы страниц) ваших конкурентов работают хуже или лучше, и на чем вы могли бы сосредоточить свои усилия. (Для вашего собственного сайта, вероятно, лучше отправлять данные на конечную точку аналитики!).

С помощью Lighthouse Parade вы можете запустить аудит производительности Lighthouse на каждой странице сайта с сохранением результатов в формате CSV. (Большой превью) Соберите данные, настройте электронную таблицу, сократите 20% и настройте свои цели ( бюджеты производительности ) таким образом. Теперь у вас есть что-то измеримое для тестирования. Если вы держите в уме бюджет и пытаетесь отправить только минимальную полезную нагрузку, чтобы получить быстрое время до интерактивности, то вы на разумном пути.
Нужны ресурсы для начала?
- Эдди Османи написала очень подробный отчет о том, как начать бюджетирование по результатам, как количественно оценить влияние новых функций и с чего начать, если вы превысили бюджет.
- Руководство Лары Хоган о том, как подходить к дизайну с бюджетом производительности, может дать дизайнерам полезные подсказки.
- Гарри Робертс опубликовал руководство по настройке Google Sheet для отображения влияния сторонних скриптов на производительность с помощью Request Map,
- Калькулятор бюджета производительности Джонатана Филдинга, калькулятор производительности бюджета Кэти Хемпениус и Browser Calories могут помочь в составлении бюджета (спасибо Каролине Щур за советы).
- Во многих компаниях бюджеты по результатам должны быть не желательными, а скорее прагматичными, выступая в качестве удерживающего знака, позволяющего избежать скольжения за определенную точку. В этом случае вы можете выбрать худшую точку данных за последние две недели в качестве порога и взять ее оттуда. Бюджеты производительности, Pragmatically показывает вам стратегию для достижения этого.
- Кроме того, сделайте бюджет производительности и текущую производительность видимыми , настроив информационные панели с графиками, отображающими размеры сборок. Есть много инструментов, позволяющих вам добиться этого: панель инструментов SiteSpeed.io (с открытым исходным кодом), SpeedCurve и Caliber — лишь некоторые из них, и вы можете найти больше инструментов на perf.rocks.

Калории браузера помогают вам установить бюджет производительности и измерить, превышает ли страница эти цифры или нет. (Большой превью) После того, как у вас есть бюджет, включите его в процесс сборки с помощью Webpack Performance Hints и Bundlesize, Lighthouse CI, PWMetrics или Sitespeed CI, чтобы контролировать бюджеты по запросам на вытягивание и предоставлять историю оценок в PR-комментариях.
Чтобы представить бюджеты производительности всей команде, интегрируйте бюджеты производительности в Lighthouse через Lightwallet или используйте LHCI Action для быстрой интеграции Github Actions. А если вам нужно что-то нестандартное, вы можете использовать webpagetest-charts-api, API конечных точек для построения диаграмм на основе результатов WebPagetest.
Однако осведомленность о производительности не должна исходить только от бюджетов производительности. Как и в случае с Pinterest, вы можете создать собственное правило eslint , которое запрещает импорт из файлов и каталогов, которые, как известно, сильно зависимы и могут раздуть пакет. Настройте список «безопасных» пакетов, которыми можно поделиться со всей командой.
Кроме того, подумайте о важнейших задачах клиентов, которые наиболее выгодны для вашего бизнеса. Изучите, обсудите и определите приемлемые временные пороги для критических действий и установите метки времени пользователя «Готово к UX», одобренные всей организацией. Во многих случаях пути пользователей будут касаться работы многих различных отделов, поэтому согласование с точки зрения приемлемого времени поможет поддержать или предотвратить обсуждение производительности в будущем. Убедитесь, что дополнительные затраты на дополнительные ресурсы и функции видны и понятны.
Согласуйте усилия по повышению производительности с другими техническими инициативами, начиная от новых функций создаваемого продукта и заканчивая рефакторингом и выходом на новую глобальную аудиторию. Поэтому каждый раз, когда происходит разговор о дальнейшем развитии, производительность также является частью этого разговора. Гораздо проще достичь целей производительности, когда кодовая база свежая или только что подверглась рефакторингу.
Кроме того, как предложил Патрик Минан, стоит спланировать последовательность загрузки и компромиссы в процессе проектирования. Если вы заранее расставите приоритеты, какие части являются более важными, и определите порядок, в котором они должны появляться, вы также будете знать, что может быть отложено. В идеале этот порядок также будет отражать последовательность вашего импорта CSS и JavaScript, поэтому обрабатывать их в процессе сборки будет проще. Кроме того, подумайте, каким должен быть визуальный опыт в «промежуточных» состояниях во время загрузки страницы (например, когда веб-шрифты еще не загружены).
После того, как вы создали сильную культуру производительности в своей организации, стремитесь быть на 20% быстрее, чем вы были раньше, чтобы сохранять приоритеты в такт с течением времени ( спасибо, Гай Поджарный! ). Но учитывайте различные типы и поведение ваших клиентов (которое Тобиас Бальдауф называл каденцией и когортами), а также трафик ботов и эффекты сезонности.
Планирование, планирование, планирование. Может показаться заманчивым заняться быстрой оптимизацией «низко висящих плодов» на раннем этапе — и это может быть хорошей стратегией для быстрых побед — но будет очень сложно сохранить производительность приоритетом без планирования и настройки реалистичной компании. - индивидуальные цели производительности.
- Выбирайте правильные показатели.
Не все показатели одинаково важны. Изучите, какие метрики наиболее важны для вашего приложения: обычно они будут определяться тем, насколько быстро вы сможете начать рендеринг наиболее важных пикселей вашего интерфейса и насколько быстро вы сможете обеспечить реакцию ввода для этих отображаемых пикселов. Эти знания дадут вам наилучшую цель оптимизации для текущих усилий. В конце концов, опыт определяется не событиями загрузки или временем отклика сервера, а восприятием того, насколько быстрым кажется интерфейс.Что это значит? Вместо того, чтобы сосредотачиваться на полном времени загрузки страницы (например, с помощью таймингов onLoad и DOMContentLoaded ), расставьте приоритеты загрузки страницы, как их воспринимают ваши клиенты. Это означает, что нужно сосредоточиться на немного другом наборе показателей. На самом деле выбор правильной метрики — это процесс без явных победителей.
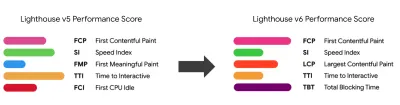
Основываясь на исследовании Тима Кадлека и заметках Маркоса Иглесиаса в его выступлении, традиционные метрики можно сгруппировать в несколько наборов. Обычно нам нужны все из них, чтобы получить полную картину производительности, и в вашем конкретном случае некоторые из них будут более важными, чем другие.
- Метрики, основанные на количестве, измеряют количество запросов, вес и оценку производительности. Хорошо подходит для подачи сигналов тревоги и отслеживания изменений с течением времени, но не очень хорошо для понимания взаимодействия с пользователем.
- Метрики Milestone используют состояния во время жизни процесса загрузки, например Time To First Byte и Time To Interactive . Хорошо подходит для описания пользовательского опыта и мониторинга, но не очень хорошо для понимания того, что происходит между вехами.
- Показатели рендеринга позволяют оценить скорость рендеринга контента (например, время начала рендеринга , индекс скорости ). Хорошо подходит для измерения и настройки производительности рендеринга, но не так хорош для измерения того, когда появляется важный контент и с ним можно взаимодействовать.
- Пользовательские метрики измеряют конкретное пользовательское событие для пользователя, например время до первого твита в Twitter и PinnerWaitTime в Pinterest. Хорошо для точного описания пользовательского опыта, но не очень хорошо для масштабирования метрик и сравнения с конкурентами.
Для полноты картины мы обычно ищем полезные метрики среди всех этих групп. Обычно наиболее конкретными и актуальными являются:
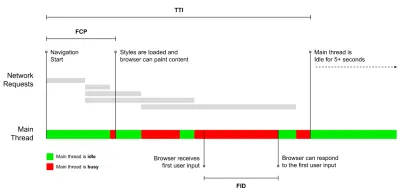
- Время до интерактивности (TTI)
Точка, в которой макет стабилизировался , основные веб-шрифты видны, а основной поток доступен достаточно для обработки пользовательского ввода — по сути, отметка времени, когда пользователь может взаимодействовать с пользовательским интерфейсом. Ключевые показатели для понимания того, сколько времени приходится ждать пользователю, чтобы пользоваться сайтом без задержек. Борис Шапира написал подробный пост о том, как надежно измерить TTI. - Первая задержка ввода (FID) , или реакция ввода
Время с момента, когда пользователь впервые взаимодействует с вашим сайтом, до момента, когда браузер фактически может реагировать на это взаимодействие. Очень хорошо дополняет TTI, поскольку описывает недостающую часть картины: что происходит, когда пользователь фактически взаимодействует с сайтом. Предназначен только как показатель RUM. В браузере есть библиотека JavaScript для измерения FID. - Самая большая содержательная краска (LCP)
Отмечает точку на временной шкале загрузки страницы, когда, вероятно, загрузился важный контент страницы. Предполагается, что наиболее важным элементом страницы является самый большой элемент, видимый в области просмотра пользователя. Если элементы отображаются как выше, так и ниже сгиба, релевантной считается только видимая часть. - Общее время блокировки ( TBT )
Метрика, которая помогает количественно оценить серьезность того, насколько неинтерактивной является страница, до того, как она станет надежно интерактивной (то есть основной поток был свободен от каких-либо задач, выполняющихся более 50 мс ( длительных задач ) в течение как минимум 5 с). Метрика измеряет общее количество времени между первой отрисовкой и временем до взаимодействия (TTI), когда основной поток был заблокирован на достаточно долгое время, чтобы предотвратить реакцию на ввод. Поэтому неудивительно, что низкий показатель TBT является хорошим показателем хорошей производительности. (спасибо, Артем, Фил) - Совокупный сдвиг макета ( CLS )
Метрика показывает, как часто пользователи сталкиваются с неожиданными изменениями макета ( перекомпоновки ) при доступе к сайту. Он исследует нестабильные элементы и их влияние на общий опыт. Чем ниже оценка, тем лучше. - Индекс скорости
Измеряет, насколько быстро содержимое страницы визуально заполняется; чем ниже оценка, тем лучше. Оценка индекса скорости рассчитывается на основе скорости визуального прогресса , но это всего лишь расчетное значение. Он также чувствителен к размеру области просмотра, поэтому вам необходимо определить диапазон конфигураций тестирования, которые соответствуют вашей целевой аудитории. Обратите внимание, что это становится менее важным, когда LCP становится более актуальной метрикой ( спасибо, Борис, Артем! ). - Затраченное процессорное время
Метрика, показывающая, как часто и как долго блокируется основной поток, работающий над отрисовкой, рендерингом, скриптингом и загрузкой. Высокое время ЦП является явным индикатором нестабильности , т. е. когда пользователь испытывает заметную задержку между своим действием и ответом. С помощью WebPageTest вы можете выбрать «Capture Dev Tools Timeline» на вкладке «Chrome», чтобы показать разбивку основного потока, когда он работает на любом устройстве с помощью WebPageTest. - Затраты ЦП на уровне компонентов
Так же, как и время, затраченное ЦП , эта метрика, предложенная Стояном Стефановым, исследует влияние JavaScript на ЦП . Идея состоит в том, чтобы использовать количество инструкций ЦП для каждого компонента, чтобы понять их влияние на общий опыт, изолированно. Может быть реализовано с помощью Puppeteer и Chrome. - FrustrationIndex
В то время как многие метрики, представленные выше, объясняют, когда происходит конкретное событие, FrustrationIndex Тима Вереке рассматривает разрывы между метриками, а не рассматривает их по отдельности. Он рассматривает ключевые вехи, воспринимаемые конечным пользователем, такие как «Заголовок виден», «Первое содержимое видно», «Визуально готово» и «Страница выглядит готово», и вычисляет оценку, указывающую уровень разочарования при загрузке страницы. Чем больше разрыв, тем больше вероятность, что пользователь разочаруется. Потенциально хороший KPI для пользовательского опыта. Тим опубликовал подробный пост о FrustrationIndex и о том, как он работает. - Влияние веса рекламы
Если доход вашего сайта зависит от рекламы, полезно отслеживать вес кода, связанного с рекламой. Сценарий Пэдди Ганти создает два URL-адреса (один обычный и один блокирующий рекламу), запрашивает создание сравнения видео через WebPageTest и сообщает о разнице. - Показатели отклонения
Как отмечают инженеры Википедии, данные о том, насколько велики различия в ваших результатах, могут сообщить вам, насколько надежны ваши инструменты и сколько внимания вы должны уделять отклонениям и отклонениям. Большая дисперсия является индикатором корректировок, необходимых в настройке. Это также помогает понять, трудно ли надежно измерить определенные страницы, например, из-за сторонних скриптов, вызывающих значительные различия. Также может быть хорошей идеей отслеживать версию браузера, чтобы понять скачки производительности при выпуске новой версии браузера. - Пользовательские показатели
Пользовательские метрики определяются вашими бизнес-потребностями и опытом клиентов. Это требует, чтобы вы определили важные пиксели, критические скрипты, необходимый CSS и соответствующие активы и измерили, насколько быстро они доставляются пользователю. Для этого вы можете отслеживать время рендеринга героев или использовать API производительности, отмечая определенные временные метки для важных для вашего бизнеса событий. Кроме того, вы можете собирать пользовательские метрики с помощью WebPagetest, выполняя произвольный JavaScript в конце теста.
Обратите внимание, что первая значимая краска (FMP) не отображается в приведенном выше обзоре. Раньше он давал представление о том, как быстро сервер выводит какие -либо данные. Длинный FMP обычно указывал на то, что JavaScript блокирует основной поток, но также может быть связан с внутренними/серверными проблемами. Однако в последнее время эта метрика устарела, поскольку примерно в 20% случаев она оказывается неточной. Он был эффективно заменен на LCP, который является более надежным и простым в использовании. Он больше не поддерживается в Lighthouse. Дважды проверьте последние ориентированные на пользователя показатели производительности и рекомендации, чтобы убедиться, что вы находитесь на безопасной странице ( спасибо, Патрик Минан ).
У Стива Содерса есть подробное объяснение многих из этих показателей. Важно отметить, что, хотя время до взаимодействия измеряется путем проведения автоматизированных аудитов в так называемой лабораторной среде , задержка первого ввода представляет фактическое взаимодействие с пользователем, при этом реальные пользователи испытывают заметное отставание. В общем, вероятно, было бы неплохо всегда измерять и отслеживать их оба.
В зависимости от контекста вашего приложения предпочтительные метрики могут различаться: например, для пользовательского интерфейса Netflix TV более важными являются скорость отклика при вводе клавиш, использование памяти и TTI, а для Википедии более важны первые/последние визуальные изменения и показатели затраченного процессорного времени.
Примечание . И FID, и TTI не учитывают поведение прокрутки; прокрутка может происходить независимо, так как она находится вне основного потока, поэтому для многих сайтов потребления контента эти показатели могут быть гораздо менее важными ( спасибо, Патрик! ).
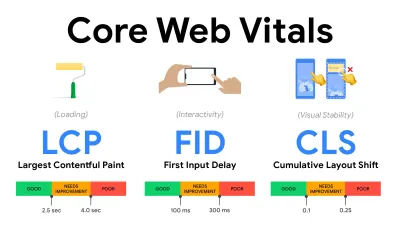
- Измеряйте и оптимизируйте Core Web Vitals .
Долгое время метрики производительности были чисто техническими, ориентируясь на инженерное представление о том, насколько быстро серверы отвечают и насколько быстро загружаются браузеры. Показатели менялись с годами — мы пытались найти способ зафиксировать фактическое взаимодействие с пользователем, а не тайминги сервера. В мае 2020 года Google анонсировала Core Web Vitals, набор новых показателей производительности, ориентированных на пользователя, каждый из которых представляет собой отдельный аспект взаимодействия с пользователем.Для каждого из них Google рекомендует диапазон приемлемых целей скорости. Чтобы пройти эту оценку, не менее 75 % всех просмотров страниц должны превышать диапазон «Хорошо ». Эти показатели быстро завоевали популярность, и, поскольку Core Web Vitals стали сигналами ранжирования для поиска Google в мае 2021 года ( обновление алгоритма ранжирования Page Experience ), многие компании обратили внимание на свои показатели эффективности.
Давайте разберем каждый из основных веб-показателей один за другим, а также полезные методы и инструменты для оптимизации вашего опыта с учетом этих показателей. (Стоит отметить, что вы получите более высокие баллы Core Web Vitals, если будете следовать общим советам из этой статьи.)
- Самая большая содержательная отрисовка ( LCP ) < 2,5 сек.
Измеряет загрузку страницы и сообщает о времени рендеринга самого большого изображения или текстового блока , видимого в области просмотра. Следовательно, на LCP влияет все, что откладывает рендеринг важной информации — будь то медленное время отклика сервера, блокировка CSS, работающий JavaScript (собственный или сторонний), загрузка веб-шрифтов, дорогостоящие операции рендеринга или рисования, ленивый загруженные изображения, каркасные экраны или рендеринг на стороне клиента.
Для удобства LCP должен выполняться в течение 2,5 с после первой загрузки страницы. Это означает, что нам нужно отобразить первую видимую часть страницы как можно раньше. Это потребует адаптированного критического CSS для каждого шаблона, оркестровки<head>-order и предварительной выборки критически важных ресурсов (мы рассмотрим их позже).Основной причиной низкой оценки LCP обычно являются изображения. Чтобы доставить LCP менее чем за 2,5 с на Fast 3G — размещенном на хорошо оптимизированном сервере, полностью статичном без рендеринга на стороне клиента и с изображением, поступающим из выделенной сети доставки изображений — это означает, что максимальный теоретический размер изображения составляет всего около 144 КБ . Вот почему так важны адаптивные изображения, а также ранняя предварительная загрузка важных изображений (с
preload).Небольшой совет : чтобы узнать, что считается LCP на странице, в DevTools вы можете навести указатель мыши на значок LCP в разделе «Время» на панели производительности ( спасибо, Тим Кадлек !).
- Задержка первого входа ( FID ) < 100 мс.
Измеряет скорость отклика пользовательского интерфейса, т. е . как долго браузер был занят другими задачами, прежде чем он смог отреагировать на дискретное событие пользовательского ввода, например касание или щелчок. Он предназначен для отслеживания задержек, возникающих из-за занятости основного потока, особенно во время загрузки страницы.
Цель состоит в том, чтобы оставаться в пределах 50–100 мс для каждого взаимодействия. Чтобы достичь этого, нам нужно идентифицировать длинные задачи (блокирует основной поток на> 50 мс) и разбить их, разбить код на несколько частей, сократить время выполнения JavaScript, оптимизировать выборку данных, отложить выполнение скриптов сторонних разработчиков. , переместите JavaScript в фоновый поток с помощью веб-воркеров и используйте прогрессивную гидратацию, чтобы снизить затраты на регидратацию в SPA.Небольшой совет : как правило, надежная стратегия для получения более высокой оценки FID заключается в том, чтобы свести к минимуму работу в основном потоке , разбивая большие пакеты на более мелкие и предоставляя то, что нужно пользователю, когда ему это нужно, чтобы взаимодействие с пользователем не задерживалось. . Подробнее об этом мы расскажем ниже.
- Совокупный сдвиг макета ( CLS ) <0,1.
Измеряет визуальную стабильность пользовательского интерфейса для обеспечения плавного и естественного взаимодействия, т. е. общую сумму всех индивидуальных оценок смещения макета для каждого неожиданного изменения макета, которое происходит в течение срока службы страницы. Индивидуальное смещение макета происходит каждый раз, когда элемент, который уже был виден, меняет свое положение на странице. Он оценивается в зависимости от размера контента и расстояния, на которое он был перемещен.
Таким образом, каждый раз, когда происходит изменение — например, когда запасные шрифты и веб-шрифты имеют разные метрики шрифта, или реклама, встраивание или iframe появляются с опозданием, или размеры изображения/видео не зарезервированы, или поздний CSS принудительно перекрашивает, или изменения вводятся поздний JavaScript — это влияет на оценку CLS. Рекомендуемое значение для хорошего опыта — CLS < 0,1.
Стоит отметить, что Core Web Vitals должны развиваться с течением времени с предсказуемым годовым циклом . В течение первого года обновления мы можем ожидать, что First Contentful Paint будет повышен до Core Web Vitals, снижен порог FID и улучшена поддержка одностраничных приложений. We might also see the responding to user inputs after load gaining more weight, along with security, privacy and accessibility (!) considerations.
Related to Core Web Vitals, there are plenty of useful resources and articles that are worth looking into:
- Web Vitals Leaderboard allows you to compare your scores against competition on mobile, tablet, desktop, and on 3G and 4G.
- Core SERP Vitals, a Chrome extension that shows the Core Web Vitals from CrUX in the Google Search Results.
- Layout Shift GIF Generator that visualizes CLS with a simple GIF (also available from the command line).
- web-vitals library can collect and send Core Web Vitals to Google Analytics, Google Tag Manager or any other analytics endpoint.
- Analyzing Web Vitals with WebPageTest, in which Patrick Meenan explores how WebPageTest exposes data about Core Web Vitals.
- Optimizing with Core Web Vitals, a 50-min video with Addy Osmani, in which he highlights how to improve Core Web Vitals in an eCommerce case-study.
- Cumulative Layout Shift in Practice and Cumulative Layout Shift in the Real World are comprehensive articles by Nic Jansma, which cover pretty much everything about CLS and how it correlates with key metrics such as Bounce Rate, Session Time or Rage Clicks.
- What Forces Reflow, with an overview of properties or methods, when requested/called in JavaScript, that will trigger the browser to synchronously calculate the style and layout.
- CSS Triggers shows which CSS properties trigger Layout, Paint and Composite.
- Fixing Layout Instability is a walkthrough of using WebPageTest to identify and fix layout instability issues.
- Cumulative Layout Shift, The Layout Instability Metric, another very detailed guide by Boris Schapira on CLS, how it's calcualted, how to measure and how to optimize for it.
- How To Improve Core Web Vitals, a detailed guide by Simon Hearne on each of the metrics (including other Web Vitals, such as FCP, TTI, TBT), when they occur and how they are measured.
So, are Core Web Vitals the ultimate metrics to follow ? Not quite. They are indeed exposed in most RUM solutions and platforms already, including Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in the filmstrip view already), Newrelic, Shopify, Next.js, all Google tools (PageSpeed Insights, Lighthouse + CI, Search Console etc.) and many others.
However, as Katie Sylor-Miller explains, some of the main problems with Core Web Vitals are the lack of cross-browser support, we don't really measure the full lifecycle of a user's experience, plus it's difficult to correlate changes in FID and CLS with business outcomes.
As we should be expecting Core Web Vitals to evolve, it seems only reasonable to always combine Web Vitals with your custom-tailored metrics to get a better understanding of where you stand in terms of performance.
- Самая большая содержательная отрисовка ( LCP ) < 2,5 сек.
- Gather data on a device representative of your audience.
To gather accurate data, we need to thoroughly choose devices to test on. In most companies, that means looking into analytics and creating user profiles based on most common device types. Yet often, analytics alone doesn't provide a complete picture. A significant portion of the target audience might be abandoning the site (and not returning back) just because their experience is too slow, and their devices are unlikely to show up as the most popular devices in analytics for that reason. So, additionally conducting research on common devices in your target group might be a good idea.Globally in 2020, according to the IDC, 84.8% of all shipped mobile phones are Android devices. An average consumer upgrades their phone every 2 years, and in the US phone replacement cycle is 33 months. Average bestselling phones around the world will cost under $200.
A representative device, then, is an Android device that is at least 24 months old , costing $200 or less, running on slow 3G, 400ms RTT and 400kbps transfer, just to be slightly more pessimistic. This might be very different for your company, of course, but that's a close enough approximation of a majority of customers out there. In fact, it might be a good idea to look into current Amazon Best Sellers for your target market. ( Thanks to Tim Kadlec, Henri Helvetica and Alex Russell for the pointers! ).
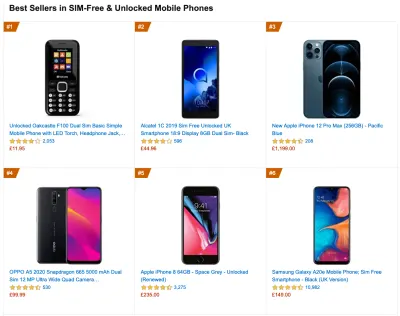
When building a new site or app, always check current Amazon Best Sellers for your target market first. (Большой превью) What test devices to choose then? The ones that fit well with the profile outlined above. It's a good option to choose a slightly older Moto G4/G5 Plus, a mid-range Samsung device (Galaxy A50, S8), a good middle-of-the-road device like a Nexus 5X, Xiaomi Mi A3 or Xiaomi Redmi Note 7 and a slow device like Alcatel 1X or Cubot X19, perhaps in an open device lab. For testing on slower thermal-throttled devices, you could also get a Nexus 4, which costs just around $100.
Also, check the chipsets used in each device and do not over-represent one chipset : a few generations of Snapdragon and Apple as well as low-end Rockchip, Mediatek would be enough (thanks, Patrick!) .
If you don't have a device at hand, emulate mobile experience on desktop by testing on a throttled 3G network (eg 300ms RTT, 1.6 Mbps down, 0.8 Mbps up) with a throttled CPU (5× slowdown). Eventually switch over to regular 3G, slow 4G (eg 170ms RTT, 9 Mbps down, 9Mbps up), and Wi-Fi. To make the performance impact more visible, you could even introduce 2G Tuesdays or set up a throttled 3G/4G network in your office for faster testing.
Keep in mind that on a mobile device, we should be expecting a 4×–5× slowdown compared to desktop machines. Mobile devices have different GPUs, CPU, memory and different battery characteristics. That's why it's important to have a good profile of an average device and always test on such a device.
- Synthetic testing tools collect lab data in a reproducible environment with predefined device and network settings (eg Lighthouse , Calibre , WebPageTest ) and
- Real User Monitoring ( RUM ) tools evaluate user interactions continuously and collect field data (eg SpeedCurve , New Relic — the tools provide synthetic testing, too).
- use Lighthouse CI to track Lighthouse scores over time (it's quite impressive),
- run Lighthouse in GitHub Actions to get a Lighthouse report alongside every PR,
- run a Lighthouse performance audit on every page of a site (via Lightouse Parade), with an output saved as CSV,
- use Lighthouse Scores Calculator and Lighthouse metric weights if you need to dive into more detail.
- Lighthouse is available for Firefox as well, but under the hood it uses the PageSpeed Insights API and generates a report based on a headless Chrome 79 User-Agent.

Luckily, there are many great options that help you automate the collection of data and measure how your website performs over time according to these metrics. Keep in mind that a good performance picture covers a set of performance metrics, lab data and field data:
The former is particularly useful during development as it will help you identify, isolate and fix performance issues while working on the product. The latter is useful for long-term maintenance as it will help you understand your performance bottlenecks as they are happening live — when users actually access the site.
By tapping into built-in RUM APIs such as Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., synthetic testing tools and RUM together provide a complete picture of performance in your application. You could use Calibre, Treo, SpeedCurve, mPulse and Boomerang, Sitespeed.io, which all are great options for performance monitoring. Furthermore, with Server Timing header, you could even monitor back-end and front-end performance all in one place.
Note : It's always a safer bet to choose network-level throttlers, external to the browser, as, for example, DevTools has issues interacting with HTTP/2 push, due to the way it's implemented ( thanks, Yoav, Patrick !). For Mac OS, we can use Network Link Conditioner, for Windows Windows Traffic Shaper, for Linux netem, and for FreeBSD dummynet.
As it's likely that you'll be testing in Lighthouse, keep in mind that you can:
- Set up "clean" and "customer" profiles for testing.
While running tests in passive monitoring tools, it's a common strategy to turn off anti-virus and background CPU tasks, remove background bandwidth transfers and test with a clean user profile without browser extensions to avoid skewed results (in Firefox, and in Chrome).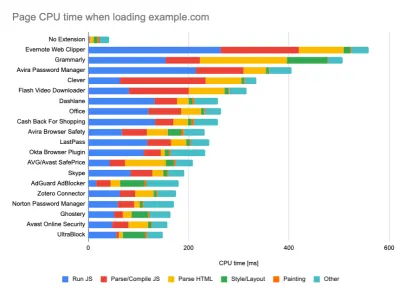
DebugBear's report highlights 20 slowest extensions, including password managers, ad-blockers and popular applications like Evernote and Grammarly. (Большой превью) However, it's also a good idea to study which browser extensions your customers use frequently, and test with dedicated "customer" profiles as well. In fact, some extensions might have a profound performance impact (2020 Chrome Extension Performance Report) on your application, and if your users use them a lot, you might want to account for it up front. Hence, "clean" profile results alone are overly optimistic and can be crushed in real-life scenarios.
- Поделитесь целями производительности с вашими коллегами.
Убедитесь, что цели эффективности знакомы каждому члену вашей команды, чтобы избежать недоразумений в будущем. Каждое решение — будь то дизайн, маркетинг или что-то промежуточное — влияет на производительность , а распределение ответственности и ответственности между всей командой упростит принятие решений, ориентированных на производительность, в дальнейшем. Сопоставьте проектные решения с бюджетом производительности и приоритетами, определенными на раннем этапе.
Постановка реалистичных целей
- Время отклика 100 миллисекунд, 60 кадров в секунду.
Чтобы взаимодействие было плавным, у интерфейса есть 100 мс для ответа на ввод пользователя. Еще немного, и пользователь воспринимает приложение как тормозящее. RAIL, модель производительности, ориентированная на пользователя, дает вам здоровые цели : чтобы обеспечить отклик <100 миллисекунд, страница должна возвращать управление обратно основному потоку не позднее, чем через каждые <50 миллисекунд. Расчетная задержка ввода сообщает нам, достигаем ли мы этого порога, и в идеале она должна быть ниже 50 мс. Для точек высокого давления, таких как анимация, лучше ничего не делать там, где вы можете, и абсолютный минимум там, где вы не можете.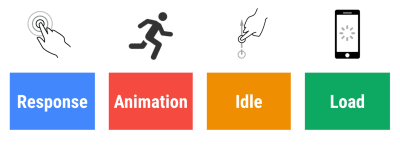
RAIL, ориентированная на пользователя модель производительности. Кроме того, каждый кадр анимации должен быть завершен менее чем за 16 миллисекунд, таким образом достигнув 60 кадров в секунду (1 секунда ÷ 60 = 16,6 миллисекунды) — желательно менее 10 миллисекунд. Поскольку браузеру нужно время, чтобы отобразить новый кадр на экране, ваш код должен завершить выполнение до достижения отметки в 16,6 миллисекунды. Мы начинаем вести разговоры о 120 кадрах в секунду (например, экраны iPad Pro работают на частоте 120 Гц), и Surma рассмотрела некоторые решения для повышения производительности рендеринга для 120 кадров в секунду, но, вероятно, это пока не наша цель.
Будьте пессимистичны в ожиданиях производительности, но будьте оптимистичны в дизайне интерфейса и разумно используйте время простоя (отметьте idlize, idle-until-urgent и response-idle). Очевидно, что эти цели относятся к производительности во время выполнения, а не к производительности при загрузке.
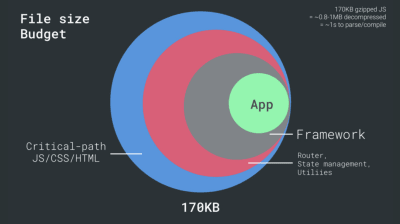
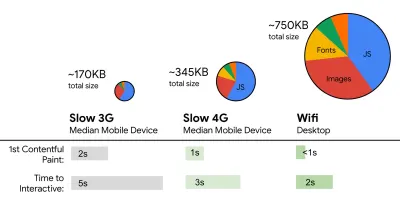
- FID < 100 мс, LCP < 2,5 с, TTI < 5 с в 3G, бюджет критического размера файла < 170 КБ (сжатый gzip).
Хотя это может быть очень сложно достичь, хорошей конечной целью будет время до взаимодействия менее 5 с, а для повторных посещений стремитесь к менее 2 с (достижимо только с сервисным работником). Стремитесь к наибольшей отрисовке содержимого менее чем за 2,5 с и минимизируйте общее время блокировки и кумулятивное смещение макета . Приемлемая задержка первого входа составляет менее 100–70 мс. Как упоминалось выше, мы рассматриваем в качестве базового уровня Android-телефон стоимостью 200 долларов (например, Moto G4) в медленной сети 3G, эмулируемой при RTT 400 мс и скорости передачи 400 кбит/с.У нас есть два основных ограничения, которые эффективно формируют разумную цель для быстрой доставки контента в Интернете. С одной стороны, у нас есть ограничения доставки по сети из-за медленного старта TCP. Первые 14 КБ HTML — 10 TCP-пакетов, каждый по 1460 байт, что составляет около 14,25 КБ, хотя это и не следует понимать буквально — это наиболее важный фрагмент полезной нагрузки и единственная часть бюджета, которая может быть доставлена за первую передачу туда и обратно ( это все, что вы получаете за 1 секунду при RTT 400 мс из-за времени пробуждения мобильных устройств).

С соединениями TCP мы начинаем с небольшого окна перегрузки и удваиваем его для каждого кругового пути. В самый первый цикл туда и обратно мы можем уместить 14 КБ. Источник: Высокопроизводительные браузерные сети Ильи Григорика. (Большой превью) ( Примечание : поскольку TCP, как правило, значительно недоиспользует сетевое подключение, Google разработал TCP узкое место и RRT ( BBR ), алгоритм управления потоком TCP с контролем задержки. Разработанный для современной сети, он реагирует на фактическую перегрузку, вместо потери пакетов, как это делает TCP, он значительно быстрее, с более высокой пропускной способностью и меньшей задержкой — и алгоритм работает по-другому ( спасибо, Виктор, Барри! )
С другой стороны, у нас есть аппаратные ограничения на память и процессор из-за времени парсинга и выполнения JavaScript (мы поговорим о них подробнее позже). Чтобы достичь целей, указанных в первом абзаце, мы должны учитывать критический бюджет размера файла для JavaScript. Мнения о том, каким должен быть этот бюджет, расходятся (и это сильно зависит от характера вашего проекта), но бюджет в 170 КБ JavaScript, уже сжатый gzip, потребует до 1 с для анализа и компиляции на телефоне среднего класса. Если предположить, что 170 КБ расширяются до 3-кратного размера при распаковке (0,7 МБ), это уже может быть похоронным звоном «приличного» пользовательского опыта на Moto G4 / G5 Plus.
Что касается веб-сайта Википедии, то в 2020 году во всем мире выполнение кода для пользователей Википедии ускорилось на 19%. Таким образом, если ваши годовые показатели веб-производительности остаются стабильными, это обычно предупреждающий знак, поскольку вы на самом деле регрессируете , поскольку среда продолжает улучшаться (подробности в сообщении в блоге Жиля Дюбюка).
Если вы хотите ориентироваться на растущие рынки, такие как Юго-Восточная Азия, Африка или Индия, вам придется изучить совсем другой набор ограничений. Эдди Османи охватывает основные ограничения функциональных телефонов, такие как небольшое количество недорогих высококачественных устройств, недоступность высококачественных сетей и дорогие мобильные данные, а также бюджет PRPL-30 и рекомендации по разработке для этих сред.
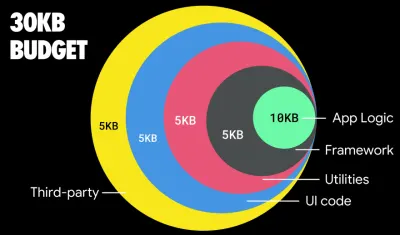
По словам Эдди Османи, рекомендуемый размер маршрутов с отложенной загрузкой также составляет менее 35 КБ. (Большой превью) 
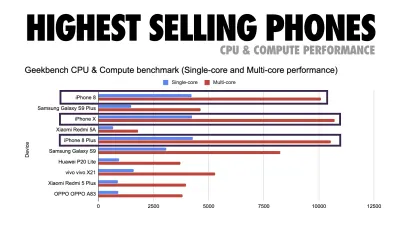
Эдди Османи предлагает бюджет производительности PRPL-30 (30 КБ в сжатом виде + исходный пакет в уменьшенном виде), если он нацелен на обычный телефон. (Большой превью) Фактически, Алекс Рассел из Google рекомендует ориентироваться на 130–170 КБ в сжатом виде в качестве разумной верхней границы. В реальных сценариях большинство продуктов даже близко не стоят: средний размер пакета сегодня составляет около 452 КБ, что на 53,6% больше, чем в начале 2015 года. На мобильном устройстве среднего класса это составляет 12–20 секунд для времени . -To-Interactive .
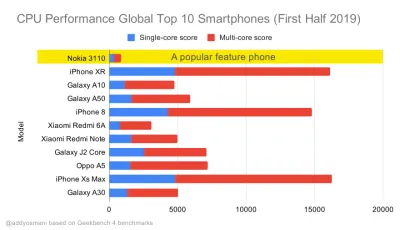
Тесты производительности ЦП Geekbench для самых продаваемых смартфонов в мире в 2019 году. JavaScript делает упор на одноядерную производительность (помните, что он по своей природе более однопоточен, чем остальная часть веб-платформы) и привязан к ЦП. Из статьи Эдди «Быстрая загрузка веб-страниц на многофункциональном телефоне за 20 долларов». (Большой превью) Мы также могли бы выйти за рамки бюджета размера пакета. Например, мы могли бы установить бюджеты производительности на основе активности основного потока браузера, т. е. времени отрисовки перед началом рендеринга или отследить загрузку процессора внешнего интерфейса. Такие инструменты, как Calibre, SpeedCurve и Bundlesize, помогут вам контролировать бюджет и могут быть интегрированы в процесс сборки.
Наконец, бюджет производительности, вероятно , не должен быть фиксированным значением . В зависимости от сетевого подключения бюджеты производительности должны адаптироваться, но полезная нагрузка при более медленном соединении гораздо более «дорогая», независимо от того, как они используются.
Примечание . Может показаться странным устанавливать такие жесткие бюджеты во времена широкого распространения HTTP/2, грядущих 5G и HTTP/3, быстро развивающихся мобильных телефонов и процветающих SPA. Тем не менее, они звучат разумно, когда мы имеем дело с непредсказуемым характером сети и оборудования, включая все, от перегруженных сетей до медленно развивающейся инфраструктуры, ограничений данных, прокси-браузеров, режима сохранения данных и скрытой платы за роуминг.
Определение среды
- Выберите и настройте инструменты сборки.
Не обращайте слишком много внимания на то, что в наши дни считается крутым. Придерживайтесь своей среды для сборки, будь то Grunt, Gulp, Webpack, Parcel или комбинация инструментов. Пока вы получаете нужные результаты и у вас нет проблем с поддержанием процесса сборки, у вас все в порядке.Среди инструментов сборки Rollup продолжает набирать обороты, как и Snowpack, но Webpack, кажется, является наиболее признанным, с буквально сотнями доступных плагинов для оптимизации размера ваших сборок. Следите за дорожной картой Webpack 2021.
Одной из наиболее примечательных стратегий, появившихся в последнее время, является дробное разбиение на фрагменты с помощью Webpack в Next.js и Gatsby для минимизации дублирования кода. По умолчанию модули, которые не являются общими в каждой точке входа, могут быть запрошены для маршрутов, которые их не используют. В конечном итоге это становится накладными расходами, поскольку загружается больше кода, чем необходимо. Благодаря гранулированному фрагментированию в Next.js мы можем использовать файл манифеста сборки на стороне сервера, чтобы определить, какие выходные фрагменты используются разными точками входа.
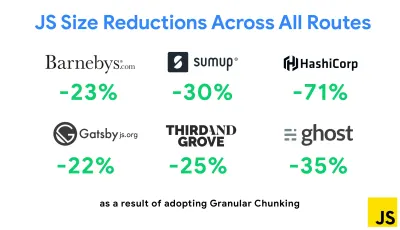
Чтобы уменьшить дублирование кода в проектах Webpack, мы можем использовать гранулированное разбиение, включенное в Next.js и Gatsby по умолчанию. Изображение предоставлено: Эдди Османи. (Большой превью) С помощью SplitChunksPlugin несколько разделенных фрагментов создаются в зависимости от ряда условий, чтобы предотвратить выборку дублированного кода по нескольким маршрутам. Это улучшает время загрузки страницы и кэширование во время навигации. Поставляется в Next.js 9.2 и в Gatsby v2.20.7.
Однако начать работу с Webpack может быть сложно. Итак, если вы хотите погрузиться в Webpack, есть несколько отличных ресурсов:
- Документация по Webpack — очевидно — является хорошей отправной точкой, как и Webpack — The Confusing Bits от Raja Rao и Annotated Webpack Config от Andrew Welch.
- У Шона Ларкина есть бесплатный курс по Webpack: The Core Concepts, а Джеффри Уэй выпустил фантастический бесплатный курс по Webpack для всех. Оба они являются отличным введением для погружения в Webpack.
- Webpack Fundamentals — это очень подробный 4-часовой курс с Шоном Ларкиным, выпущенный FrontendMasters.
- Примеры Webpack содержат сотни готовых к использованию конфигураций Webpack, классифицированных по темам и целям. Бонус: есть также конфигуратор конфигурации Webpack, который генерирует базовый файл конфигурации.
- awesome-webpack — это список полезных ресурсов, библиотек и инструментов Webpack, включая статьи, видео, курсы, книги и примеры для Angular, React и проектов, не зависящих от фреймворка.
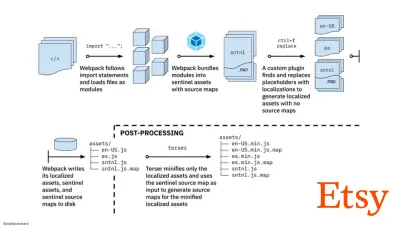
- Путь к быстрой сборке производственных активов с помощью Webpack — это тематическое исследование Etsy о том, как команда перешла от использования системы сборки JavaScript на основе RequireJS к использованию Webpack и как они оптимизировали свои сборки, управляя более чем 13 200 активами в среднем за 4 минуты .
- Советы по производительности Webpack — золотая ветка Ивана Акулова, содержащая множество советов, ориентированных на производительность, в том числе те, которые специально ориентированы на Webpack.
- awesome-webpack-perf — это золотой репозиторий GitHub с полезными инструментами и плагинами Webpack для повышения производительности. Также поддерживается Иваном Акуловым.
- Используйте прогрессивное улучшение по умолчанию.
Тем не менее, по прошествии стольких лет, сохранение прогрессивного улучшения в качестве руководящего принципа вашей интерфейсной архитектуры и развертывания является беспроигрышным вариантом. Сначала спроектируйте и создайте основной интерфейс, а затем улучшите его с помощью расширенных функций для совместимых браузеров, создавая устойчивые интерфейсы. Если ваш веб-сайт работает быстро на медленной машине с плохим экраном в плохом браузере в неоптимальной сети, то он будет работать быстрее только на быстрой машине с хорошим браузером в приличной сети.На самом деле, с адаптивным обслуживанием модулей мы, кажется, выводим прогрессивное улучшение на новый уровень, предоставляя «упрощенные» базовые возможности для недорогих устройств и добавляя более сложные функции для устройств высокого класса. Прогрессивное улучшение вряд ли исчезнет в ближайшее время.
- Выберите сильный базовый уровень производительности.
С таким количеством неизвестных факторов, влияющих на загрузку — сеть, тепловое регулирование, удаление кеша, сторонние сценарии, шаблоны блокировки синтаксического анализатора, дисковый ввод-вывод, задержка IPC, установленные расширения, антивирусное программное обеспечение и брандмауэры, фоновые задачи ЦП, ограничения оборудования и памяти, различия в кэшировании L2/L3, RTTS — JavaScript имеет самую большую стоимость опыта, рядом с веб-шрифтами, блокирующими рендеринг по умолчанию, и изображениями, часто потребляющими слишком много памяти. Поскольку узкие места в производительности переходят от сервера к клиенту, мы, как разработчики, должны рассмотреть все эти неизвестные гораздо подробнее.С бюджетом в 170 КБ, который уже содержит критический путь HTML/CSS/JavaScript, маршрутизатор, управление состоянием, утилиты, фреймворк и логику приложения, мы должны тщательно изучить стоимость передачи по сети, время синтаксического анализа/компиляции и стоимость времени выполнения. рамки по нашему выбору. К счастью, за последние несколько лет мы наблюдаем значительный прогресс в том, насколько быстро браузеры могут анализировать и компилировать скрипты. Тем не менее, выполнение JavaScript по-прежнему является основным узким местом, поэтому пристальное внимание к времени выполнения скрипта и сети может иметь большое значение.
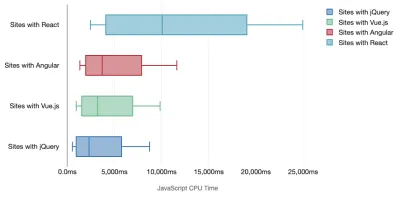
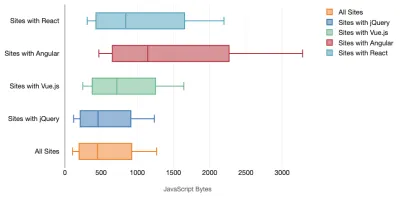
Тим Кадлек провел фантастическое исследование производительности современных фреймворков и резюмировал их в статье «Фреймворки JavaScript имеют свою цену». Мы часто говорим о влиянии автономных фреймворков, но, как отмечает Тим, на практике нередко используется несколько фреймворков . Возможно, это старая версия jQuery, которая постепенно переносится на современный фреймворк, а также несколько устаревших приложений, использующих более старую версию Angular. Поэтому более разумно изучить совокупную стоимость байтов JavaScript и время выполнения ЦП, которые могут легко сделать пользовательский опыт практически непригодным для использования даже на устройствах высокого класса.
Как правило, современные фреймворки не отдают приоритет менее мощным устройствам , поэтому производительность на телефоне и на настольном компьютере часто сильно различается. Согласно исследованиям, сайты с React или Angular тратят на ЦП больше времени, чем другие (что, конечно, не обязательно означает, что React требует больше ресурсов ЦП, чем Vue.js).
По словам Тима, очевидно одно: «если вы используете фреймворк для создания своего сайта, вы идете на компромисс с точки зрения начальной производительности — даже в лучшем из сценариев».
- Оцените фреймворки и зависимости.
Теперь не каждому проекту нужен фреймворк, и не каждая страница одностраничного приложения должна загружать фреймворк. В случае с Netflix «удаление React, нескольких библиотек и соответствующего кода приложения со стороны клиента уменьшило общий объем JavaScript более чем на 200 КБ, что привело к сокращению времени до интерактивности Netflix более чем на 50% для домашней страницы, на которой не выполнен вход. ." Затем команда использовала время, проведенное пользователями на целевой странице, для предварительной выборки React для последующих страниц, на которые, скорее всего, попадут пользователи (подробности читайте далее).Так что, если вы вообще удалите существующую структуру на критических страницах? С Gatsby вы можете проверить gatsby-plugin-no-javascript, который удаляет все файлы JavaScript, созданные Gatsby, из статических файлов HTML. В Vercel вы также можете разрешить отключение исполняемого JavaScript для определенных страниц (экспериментально).
После того, как фреймворк выбран, мы будем использовать его как минимум несколько лет, поэтому, если нам нужно его использовать, мы должны убедиться, что наш выбор обоснован и хорошо продуман — и это особенно касается ключевых показателей производительности, которые мы заботиться о.
Данные показывают, что по умолчанию фреймворки довольно дороги: 58,6% страниц React содержат более 1 МБ JavaScript, а 36% загрузок страниц Vue.js имеют первую отрисовку содержимого менее 1,5 с. Согласно исследованию Анкура Сетхи, «ваше приложение React никогда не будет загружаться быстрее, чем за 1,1 секунды на среднем телефоне в Индии, независимо от того, насколько вы его оптимизируете. Для загрузки вашего приложения Angular всегда требуется не менее 2,7 секунды». пользователям вашего приложения Vue нужно будет подождать не менее 1 секунды, прежде чем они смогут начать его использовать». Возможно, вы в любом случае не ориентируетесь на Индию как на основной рынок, но пользователи, заходящие на ваш сайт с неоптимальными сетевыми условиями, будут иметь сопоставимый опыт.
Конечно , можно делать SPA быстро, но они не быстры из коробки, поэтому нам нужно учитывать время и усилия, необходимые для их быстрого создания и поддержания . Вероятно, будет проще выбрать облегченную базовую стоимость производительности на раннем этапе.
Итак, как мы выбираем фреймворк ? Прежде чем выбирать вариант, рекомендуется учитывать как минимум общую стоимость размера + начальное время выполнения; легкие варианты, такие как Preact, Inferno, Vue, Svelte, Alpine или Polymer, могут отлично справиться с работой. Размер вашего базового плана будет определять ограничения для кода вашего приложения.
Как отмечает Себ Маркбейдж, хороший способ измерить начальные затраты для фреймворков — сначала отобразить представление, затем удалить его, а затем снова отрендерить, поскольку это может сказать вам, как масштабируется фреймворк. Первый рендер имеет тенденцию разогревать кучу лениво скомпилированного кода, что может принести пользу более крупному дереву при его масштабировании. Второй рендеринг в основном представляет собой эмуляцию того, как повторное использование кода на странице влияет на характеристики производительности по мере усложнения страницы.
Вы можете даже оценить своих кандидатов (или любую библиотеку JavaScript в целом) по 12-балльной системе оценки Саши Грейфа, изучив функции, доступность, стабильность, производительность, экосистему пакетов , сообщество, кривую обучения, документацию, инструменты, послужной список. , команда, совместимость, безопасность например.
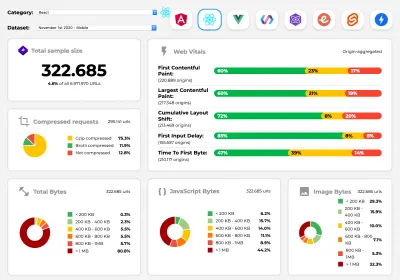
Perf Track отслеживает производительность платформы в любом масштабе. (Большой превью) Вы также можете полагаться на данные, собранные в Интернете за более длительный период времени. Например, Perf Track отслеживает производительность платформы в масштабе, показывая агрегированные по источнику баллы Core Web Vitals для веб-сайтов, созданных на Angular, React, Vue, Polymer, Preact, Ember, Svelte и AMP. Вы даже можете указать и сравнить веб-сайты, созданные с помощью Gatsby, Next.js или Create React App, а также веб-сайты, созданные с помощью Nuxt.js (Vue) или Sapper (Svelte).
Хорошей отправной точкой является выбор хорошего стека по умолчанию для вашего приложения. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI и PWA Starter Kit обеспечивают разумные значения по умолчанию для быстрой загрузки из коробки на среднее мобильное оборудование. Также ознакомьтесь с руководством по производительности для React и Angular, относящимся к фреймворку web.dev ( спасибо, Филипп! ).
И, возможно, вы могли бы применить немного более свежий подход к созданию одностраничных приложений в целом — Turbolinks, библиотеку JavaScript размером 15 КБ, которая использует HTML вместо JSON для отображения представлений. Поэтому, когда вы переходите по ссылке, Turbolinks автоматически извлекает страницу, заменяет ее
<body>и объединяет ее<head>, и все это без затрат на полную загрузку страницы. Вы можете проверить краткие подробности и полную документацию о стеке (Hotwire).
- Рендеринг на стороне клиента или рендеринг на стороне сервера? Обе!
Это довольно горячий разговор. Окончательным подходом было бы настроить своего рода прогрессивную загрузку: использовать рендеринг на стороне сервера, чтобы получить быструю первую контекстную отрисовку, но также включить минимально необходимый JavaScript, чтобы время до интерактивности оставалось близким к первой контентной отрисовке. Если JavaScript появляется слишком поздно после FCP, браузер блокирует основной поток при анализе, компиляции и выполнении поздно обнаруженного JavaScript, тем самым ограничивая интерактивность сайта или приложения.Чтобы этого избежать, всегда разбивайте выполнение функций на отдельные асинхронные задачи и по возможности используйте
requestIdleCallback. Рассмотрите ленивую загрузку частей пользовательского интерфейса с помощью поддержки динамическогоimport()WebPack, избегая затрат на загрузку, синтаксический анализ и компиляцию до тех пор, пока они действительно не понадобятся пользователям ( спасибо, Адди! ).Как упоминалось выше, время до интерактивности (TTI) сообщает нам время между навигацией и интерактивностью. В деталях метрика определяется путем просмотра первого пятисекундного окна после рендеринга начального контента, в котором ни одна задача JavaScript не занимает более 50 мс ( длительные задачи ). Если возникает задача более 50 мс, поиск пятисекундного окна начинается заново. В результате браузер сначала предположит, что он достиг Interactive , просто для того, чтобы переключиться на Frozen , чтобы в конечном итоге переключиться обратно на Interactive .
Как только мы достигли Interactive , мы можем — либо по требованию, либо, когда позволяет время — загружать второстепенные части приложения. К сожалению, как заметил Пол Льюис, фреймворки обычно не имеют простой концепции приоритета, которую можно было бы донести до разработчиков, и, следовательно, прогрессивную загрузку нелегко реализовать с большинством библиотек и фреймворков.
Тем не менее, мы добираемся туда. В наши дни есть несколько вариантов, которые мы можем изучить, и Хусейн Джирдех и Джейсон Миллер предоставили отличный обзор этих вариантов в своем докладе о рендеринге в Интернете и в статье Джейсона и Эдди о современных интерфейсных архитектурах. Обзор ниже основан на их звездной работе.
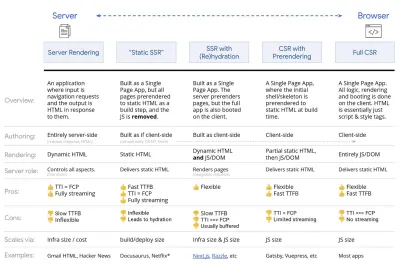
- Полный рендеринг на стороне сервера (SSR)
В классическом SSR, таком как WordPress, все запросы обрабатываются исключительно на сервере. Запрошенный контент возвращается в виде готовой HTML-страницы, и браузеры могут сразу ее отображать. Следовательно, SSR-приложения не могут использовать, например, DOM API. Разрыв между First Contentful Paint и Time to Interactive обычно невелик, и страница может отображаться сразу же, как HTML передается в браузер.Это позволяет избежать дополнительных циклов получения данных и шаблонов на клиенте, поскольку они обрабатываются до того, как браузер получит ответ. Тем не менее, мы получаем больше времени на обдумывание сервером и, следовательно, времени до первого байта, и мы не используем адаптивные и богатые функции современных приложений.
- Статическая визуализация
Мы создаем продукт как одностраничное приложение, но все страницы предварительно визуализируются в статический HTML с минимальным JavaScript в качестве шага сборки. Это означает, что при статическом рендеринге мы заранее создаем отдельные HTML-файлы для каждого возможного URL -адреса, что не многие приложения могут себе позволить. Но поскольку HTML-код для страницы не нужно генерировать на лету, мы можем добиться неизменно быстрого времени до первого байта. Таким образом, мы можем быстро отобразить целевую страницу, а затем выполнить предварительную выборку SPA-фреймворка для последующих страниц. Netflix применил этот подход, снизив загрузку и время до взаимодействия на 50%. - Рендеринг на стороне сервера с (ре)гидратацией (универсальный рендеринг, SSR + CSR)
Мы можем попытаться использовать лучшее из обоих подходов — SSR и CSR. С добавлением гидратации HTML-страница, возвращаемая с сервера, также содержит сценарий, который загружает полноценное клиентское приложение. В идеале добиться быстрой первой отрисовки содержимого (например, SSR), а затем продолжить рендеринг с (ре)гидратацией. К сожалению, это бывает редко. Чаще страница выглядит готовой, но не может реагировать на действия пользователя, вызывая гневные клики и отказы.С React мы можем использовать модуль
ReactDOMServerна сервере Node, таком как Express, а затем вызвать методrenderToStringдля отображения компонентов верхнего уровня в виде статической строки HTML.С Vue.js мы можем использовать vue-server-renderer для рендеринга экземпляра Vue в HTML с помощью
renderToString. В Angular мы можем использовать@nguniversalдля превращения клиентских запросов в HTML-страницы, полностью отображаемые сервером. Кроме того, с помощью Next.js (React) или Nuxt.js (Vue) можно получить полностью серверную визуализацию.У подхода есть свои минусы. В результате мы получаем полную гибкость клиентских приложений, обеспечивая при этом более быстрый рендеринг на стороне сервера, но в итоге мы получаем более длительный разрыв между First Contentful Paint и Time To Interactive и увеличенную задержку первого ввода. Регидратация стоит очень дорого, и обычно одной этой стратегии недостаточно, поскольку она сильно задерживает время до взаимодействия.
- Потоковая передача на стороне сервера с прогрессивной гидратацией (SSR + CSR)
Чтобы свести к минимуму разрыв между Time To Interactive и First Contentful Paint, мы обрабатываем несколько запросов одновременно и отправляем контент частями по мере его создания. Таким образом, нам не нужно ждать полной строки HTML, прежде чем отправлять содержимое в браузер, и, следовательно, улучшить время до первого байта.В React вместо
renderToString()мы можем использовать renderToNodeStream() для передачи ответа и отправки HTML по частям. В Vue мы можем использовать renderToStream(), который может передаваться по конвейеру и передаваться в потоковом режиме. С React Suspense мы также можем использовать асинхронный рендеринг для этой цели.На стороне клиента вместо загрузки всего приложения сразу мы загружаем компоненты постепенно . Разделы приложений сначала разбиваются на отдельные сценарии с разделением кода, а затем постепенно (в порядке наших приоритетов) гидратируются. Фактически, мы можем сначала гидратировать критически важные компоненты, а остальные можно гидратировать позже. Затем роль рендеринга на стороне клиента и на стороне сервера может быть определена по-разному для каждого компонента. Затем мы также можем отложить гидратацию некоторых компонентов до тех пор, пока они не появятся в поле зрения или потребуются для взаимодействия с пользователем, или пока браузер не будет бездействовать.
Для Vue Маркус Оберленер опубликовал руководство по сокращению времени до взаимодействия приложений SSR с помощью гидратации при взаимодействии с пользователем, а также vue-lazy-hydration, плагина ранней стадии, который включает гидратацию компонентов при видимости или конкретном взаимодействии с пользователем. Команда Angular работает над прогрессивным увлажнением с помощью Ivy Universal. Вы также можете реализовать частичную гидратацию с помощью Preact и Next.js.
- Трисоморфный рендеринг
Имея сервис-воркеров, мы можем использовать рендеринг потокового сервера для начальных/не-JS-навигаций, а затем заставлять сервис-воркер рендерить HTML для навигации после его установки. В этом случае сервисный работник выполняет предварительную визуализацию контента и включает навигацию в стиле SPA для визуализации новых представлений в том же сеансе. Хорошо работает, когда вы можете совместно использовать один и тот же код шаблонов и маршрутизации между сервером, клиентской страницей и работником службы.
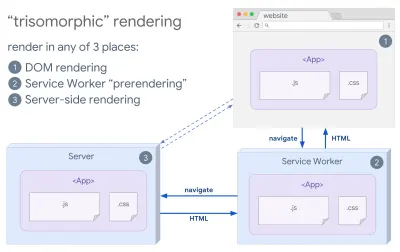
Трисоморфный рендеринг, с рендерингом одного и того же кода в любых 3-х местах: на сервере, в DOM или в сервис-воркере. (Источник изображения: Google Developers) (Большой предварительный просмотр) - CSR с предварительным рендерингом
Предварительный рендеринг похож на рендеринг на стороне сервера, но вместо динамического рендеринга страниц на сервере мы визуализируем приложение в статический HTML во время сборки. В то время как статические страницы полностью интерактивны без большого количества клиентского JavaScript, предварительный рендеринг работает по-другому . По сути, он фиксирует начальное состояние клиентского приложения в виде статического HTML во время сборки, в то время как с предварительным рендерингом приложение должно быть загружено на клиенте, чтобы страницы были интерактивными.С помощью Next.js мы можем использовать статический экспорт HTML, предварительно отрендерив приложение в статический HTML. В Gatsby, генераторе статических сайтов с открытым исходным кодом, использующем React, во время сборки используется метод
renderToStaticMarkupвместо методаrenderToString, при этом основной фрагмент JS предварительно загружается, а будущие маршруты предварительно выбираются без атрибутов DOM, которые не нужны для простых статических страниц.Для Vue мы можем использовать Vuepress для достижения той же цели. Вы также можете использовать prerender-loader с Webpack. Navi также обеспечивает статический рендеринг.
В результате улучшается время до первого байта и первая отрисовка по содержанию, и мы уменьшаем разрыв между временем до интерактивности и первой отрисовкой по содержанию. Мы не можем использовать этот подход, если ожидается, что контент сильно изменится. Кроме того, все URL-адреса должны быть известны заранее, чтобы сгенерировать все страницы. Таким образом, некоторые компоненты могут быть отрисованы с использованием предварительной отрисовки, но если нам нужно что-то динамическое, мы должны полагаться на приложение для получения содержимого.
- Полный рендеринг на стороне клиента (CSR)
Вся логика, рендеринг и загрузка выполняются на клиенте. Результатом обычно является огромный разрыв между Time To Interactive и First Contentful Paint. В результате приложения часто чувствуют себя вялыми , поскольку все приложение должно быть загружено на клиенте, чтобы отобразить что-либо.Поскольку у JavaScript есть издержки производительности, поскольку объем JavaScript растет вместе с приложением, агрессивное разделение кода и отсрочка JavaScript будут абсолютно необходимы для сдерживания влияния JavaScript. В таких случаях рендеринг на стороне сервера обычно будет лучшим подходом, если не требуется много интерактивности. Если это не вариант, рассмотрите возможность использования модели оболочки приложения.
В общем, SSR быстрее, чем CSR. Тем не менее, это довольно частая реализация для многих приложений.
Итак, на стороне клиента или на стороне сервера? В целом рекомендуется ограничить использование полностью клиентских фреймворков страницами, которые в них абсолютно необходимы. Для продвинутых приложений также не рекомендуется полагаться только на рендеринг на стороне сервера. И рендеринг на сервере, и рендеринг на клиенте — это катастрофа, если они сделаны плохо.
Независимо от того, склоняетесь ли вы к CSR или SSR, убедитесь, что вы рендерите важные пиксели как можно скорее и минимизируете разрыв между этим рендерингом и временем до интерактивности. Подумайте о предварительном рендеринге, если ваши страницы не сильно меняются, и по возможности отложите загрузку фреймворков. Потоковая передача HTML фрагментами с рендерингом на стороне сервера и внедрение прогрессивной гидратации для рендеринга на стороне клиента — и гидратация при видимости, взаимодействии или во время простоя, чтобы получить лучшее из обоих миров.
- Полный рендеринг на стороне сервера (SSR)

- Сколько мы можем обслуживать статически?
Независимо от того, работаете ли вы над большим приложением или небольшим сайтом, стоит подумать о том, какой контент можно обслуживать статически из CDN (т. е. стека JAM), а не генерировать динамически «на лету». Даже если у вас есть тысячи продуктов и сотни фильтров с множеством вариантов персонализации, вы все равно можете статически обслуживать важные целевые страницы и отделять эти страницы от выбранной вами структуры.Существует множество генераторов статических сайтов, и страницы, которые они генерируют, зачастую очень быстрые. The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
With JAMStack used on large sites these days, a new performance consideration appeared: the build time . In fact, building out even thousands of pages with every new deploy can take minutes, so it's promising to see incremental builds in Gatsby which improve build times by 60 times , with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
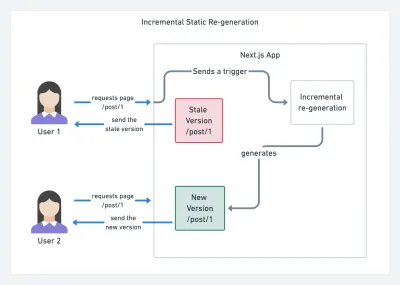
Incremental static regeneration with Next.js. (Image credit: Prisma.io) (Large preview) Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they've been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
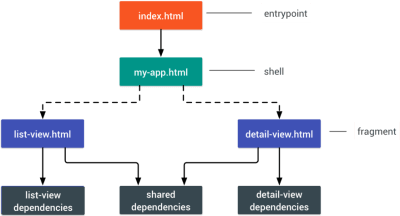
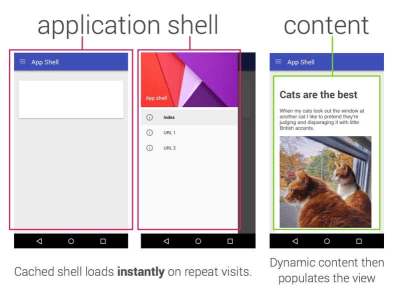
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you'll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
- Have you optimized the performance of your APIs?
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints . When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer ( REST ) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services .As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering . When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request , and the response will be exactly what is required, without over or under -fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
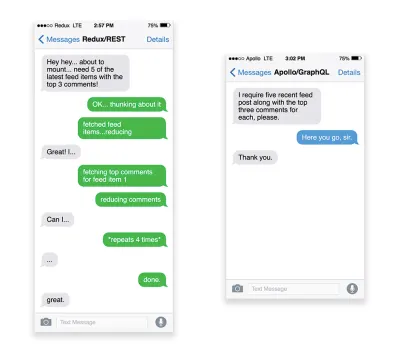
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google's AMP or Facebook's Instant Articles or Apple's Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance , so at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don't necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that's how it used to be. As AMP is no longer a requirement for Top Stories , publishers might be moving away from AMP to a traditional stack instead ( thanks, Barry! ).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!) .
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (eg image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN's edge (ie the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN , how to finetune it and all the little things to keep in mind when evaluating one. In general, it's a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note : based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization ( thanks, Barry! ).
CDNPerf measures query speed for CDNs by gathering and analyzing 300 million tests every day. (Большой превью) When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- Сравнение CDN, матрица сравнения CDN для Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai и многих других.
- CDN Perf измеряет скорость запросов для CDN, собирая и анализируя 300 миллионов тестов каждый день, причем все результаты основаны на данных RUM от пользователей со всего мира. Также проверьте сравнение производительности DNS и сравнение производительности облака.
- CDN Planet Guides предоставляет обзор CDN по конкретным темам, таким как Serve Stale, Purge, Origin Shield, Prefetch и Compression.
- Веб-альманах: принятие и использование CDN предоставляет информацию о ведущих поставщиках CDN, их управлении RTT и TLS, времени согласования TLS, внедрении HTTP/2 и многом другом. (К сожалению, данные только за 2019 год).
Оптимизация активов
- Используйте Brotli для сжатия простого текста.
В 2015 году Google представила Brotli, новый формат данных без потерь с открытым исходным кодом, который теперь поддерживается во всех современных браузерах. Библиотека Brotli с открытым исходным кодом, которая реализует кодировщик и декодер для Brotli, имеет 11 предопределенных уровней качества для кодировщика, при этом более высокий уровень качества требует больше ресурсов ЦП в обмен на лучшую степень сжатия. Более медленное сжатие в конечном итоге приведет к более высокой скорости сжатия, но тем не менее Brotli быстро распаковывает. Однако стоит отметить, что Brotli с уровнем сжатия 4 меньше и сжимает быстрее, чем Gzip.На практике Brotli оказывается намного эффективнее, чем Gzip. Мнения и опыт различаются, но если ваш сайт уже оптимизирован с помощью Gzip, вы можете ожидать, по крайней мере, однозначных улучшений и, в лучшем случае, двузначных улучшений в уменьшении размера и времени FCP. Вы также можете оценить экономию сжатия Brotli для вашего сайта.
Браузеры будут принимать Brotli, только если пользователь посещает веб-сайт через HTTPS. Brotli широко поддерживается, и многие CDN поддерживают его (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (в настоящее время только как сквозной), Cloudflare, CDN77), и вы можете включить Brotli даже на CDN, которые еще не поддерживают его. (с обслуживающим персоналом).
Загвоздка в том, что, поскольку сжатие всех ресурсов с помощью Brotli при высоком уровне сжатия обходится дорого, многие хостинг-провайдеры не могут использовать его в полном объеме только из-за огромных накладных расходов, которые он создает. На самом деле, на самом высоком уровне сжатия Brotli работает настолько медленно, что любое потенциальное увеличение размера файла может быть сведено на нет из-за времени, которое требуется серверу, чтобы начать отправку ответа, поскольку он ожидает динамического сжатия ресурса. (Но если у вас есть время во время сборки со статическим сжатием, конечно, предпочтительны более высокие настройки сжатия.)
Сравнение времени завершения различных методов сжатия. Неудивительно, что Brotli медленнее, чем gzip (на данный момент). (Большой превью) Хотя это может измениться. Формат файла Brotli включает встроенный статический словарь и, помимо того, что он содержит различные строки на нескольких языках, также поддерживает возможность применения нескольких преобразований к этим словам, что повышает его универсальность. В своем исследовании Феликс Ханау обнаружил способ улучшить сжатие на уровнях с 5 по 9, используя «более специализированное подмножество словаря, чем по умолчанию» и полагаясь на заголовок
Content-Type, чтобы указать компрессору, следует ли ему использовать словарь для HTML, JavaScript или CSS. Результатом было «незначительное влияние на производительность (на 1-3% больше ЦП по сравнению с 12% в обычном режиме) при сжатии веб-контента на высоких уровнях сжатия с использованием подхода с ограниченным использованием словаря».
Благодаря улучшенному словарному подходу мы можем быстрее сжимать активы на более высоких уровнях сжатия, при этом используя всего на 1–3 % больше ресурсов ЦП. Обычно уровень сжатия 6 по сравнению с 5 увеличивает загрузку ЦП до 12%. (Большой превью) Кроме того, благодаря исследованиям Елены Кириленко мы можем добиться быстрой и эффективной повторной компрессии Brotli , используя предыдущие артефакты сжатия. По словам Елены, «когда у нас есть ресурс, сжатый с помощью Brotli, и мы пытаемся сжимать динамический контент «на лету», когда контент напоминает контент, доступный нам заранее, мы можем добиться значительного улучшения времени сжатия. "
Как часто это бывает? Например, с доставкой подмножеств пакетов JavaScript (например, когда части кода уже кэшированы на клиенте или с динамическим пакетом, обслуживающим WebBundles). Или с динамическим HTML, основанным на заранее известных шаблонах, или с динамическим подмножеством шрифтов WOFF2 . По словам Елены, мы можем получить улучшение сжатия на 5,3% и улучшение скорости сжатия на 39% при удалении 10% контента, а также повышение скорости сжатия на 3,2% и ускорение сжатия на 26% при удалении 50% контента.
Сжатие Brotli становится лучше, поэтому, если вы можете обойти затраты на динамическое сжатие статических ресурсов, это определенно стоит затраченных усилий. Само собой разумеется, что Brotli можно использовать для любой полезной нагрузки открытого текста — HTML, CSS, SVG, JavaScript, JSON и так далее.
Примечание . По состоянию на начало 2021 года примерно 60 % HTTP-ответов доставляются без текстового сжатия, 30,82 % сжимаются с помощью Gzip и 9,1 % со сжатием с помощью Brotli (как на мобильных устройствах, так и на настольных компьютерах). Например, 23,4% страниц Angular не сжаты (через gzip или Brotli). Тем не менее, часто включение сжатия является одним из самых простых способов повысить производительность простым щелчком переключателя.
Стратегия? Предварительно сжимайте статические ресурсы с помощью Brotli+Gzip на самом высоком уровне и сжимайте (динамический) HTML на лету с помощью Brotli на уровне 4–6. Убедитесь, что сервер правильно обрабатывает согласование содержимого для Brotli или Gzip.
- Используем ли мы адаптивную загрузку мультимедиа и клиентские подсказки?
Это пришло из страны старых новостей, но это всегда хорошее напоминание об использовании адаптивных изображений сsrcset,sizesи элементом<picture>. Специально для сайтов с большим количеством носителей мы можем сделать еще один шаг вперед с адаптивной загрузкой мультимедиа (в этом примере React + Next.js), предоставляя легкий опыт для медленных сетей и устройств с малым объемом памяти и полный опыт для быстрой сети и высокой производительности. -устройства памяти. В контексте React мы можем добиться этого с помощью клиентских подсказок на сервере и реактивных адаптивных хуков на клиенте.Будущее адаптивных изображений может резко измениться с более широким внедрением клиентских подсказок. Подсказки клиента — это поля заголовка HTTP-запроса, например,
DPR,Viewport-Width,Width,Save-Data,Accept(для указания предпочтений формата изображения) и другие. Они должны информировать сервер об особенностях браузера пользователя, экрана, подключения и т. д.В результате сервер может решить, как заполнить макет изображениями подходящего размера , и обслуживать только эти изображения в нужных форматах. С помощью клиентских подсказок мы перемещаем выбор ресурсов из HTML-разметки в процесс согласования запроса и ответа между клиентом и сервером.
Используемый адаптивный носитель. Мы отправляем заполнитель с текстом пользователям, которые не в сети, изображение с низким разрешением — пользователям 2G, изображение с высоким разрешением — пользователям 3G и HD-видео — пользователям 4G. Через быструю загрузку веб-страниц на многофункциональном телефоне за 20 долларов. (Большой превью) Как заметил Илья Григорик, клиентские подсказки дополняют картину — они не являются альтернативой адаптивным изображениям. «Элемент
<picture>обеспечивает необходимое управление художественным оформлением в HTML-разметке. Подсказки клиента предоставляют аннотации к полученным запросам изображений, что позволяет автоматизировать выбор ресурсов. Service Worker предоставляет полные возможности управления запросами и ответами на клиенте».Сервисный работник может, например, добавить новые значения заголовков подсказок клиента к запросу, переписать URL-адрес и направить запрос изображения в CDN, адаптировать ответ на основе подключения и пользовательских предпочтений и т. д. Это верно не только для ресурсов изображений, но почти для всех других запросов.
Для клиентов, поддерживающих клиентские подсказки, можно было измерить 42% экономии байтов на изображениях и на 1 МБ+ меньше байтов для 70-го+ процентиля. На Smashing Magazine мы также смогли измерить улучшение на 19-32%. Клиентские подсказки поддерживаются в браузерах на основе Chromium, но в Firefox они все еще находятся на рассмотрении.
Однако если вы укажете как обычную разметку адаптивных изображений, так и
<meta>для клиентских подсказок, поддерживающий браузер оценит разметку адаптивных изображений и запросит соответствующий источник изображения, используя HTTP-заголовки клиентских подсказок. - Используем ли мы адаптивные изображения для фоновых изображений?
Мы обязательно должны! С помощьюimage-set, который теперь поддерживается в Safari 14 и в большинстве современных браузеров, кроме Firefox, мы также можем отображать адаптивные фоновые изображения:background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);По сути, мы можем условно обслуживать фоновые изображения с низким разрешением с дескриптором
1x, изображения с более высоким разрешением с дескриптором2xи даже изображение качества печати с дескриптором600dpi. Однако будьте осторожны: браузеры не предоставляют никакой специальной информации о фоновых изображениях вспомогательным технологиям, поэтому в идеале эти фотографии будут просто украшением. - Используем ли мы WebP?
Сжатие изображений часто считается быстрой победой, но на практике оно все еще используется недостаточно. Конечно, изображения не блокируют рендеринг, но они сильно влияют на плохие оценки LCP, и очень часто они слишком тяжелые и слишком большие для устройства, на котором они используются.Так что, по крайней мере, мы могли бы изучить использование формата WebP для наших изображений. Фактически, сага WebP близится к концу в прошлом году, когда Apple добавила поддержку WebP в Safari 14. Итак, после многих лет дискуссий и дебатов, на сегодняшний день WebP поддерживается во всех современных браузерах. Таким образом, мы можем обслуживать изображения WebP с элементом
<picture>и запасным вариантом JPEG, если это необходимо (см. фрагмент кода Андреаса Бовенса) или с помощью согласования содержимого (используя заголовкиAccept).Однако WebP не лишен недостатков . Несмотря на то, что размеры файла изображения WebP по сравнению с эквивалентными Guetzli и Zopfli, этот формат не поддерживает прогрессивный рендеринг, такой как JPEG, поэтому пользователи могут быстрее увидеть готовое изображение со старым добрым JPEG, хотя изображения WebP могут становиться быстрее через сеть. С JPEG мы можем обслуживать «достойный» пользовательский интерфейс с половиной или даже четвертью данных и загружать остальные позже, вместо того, чтобы иметь полупустое изображение, как в случае WebP.
Ваше решение будет зависеть от того, что вам нужно: с WebP вы уменьшите полезную нагрузку, а с JPEG вы улучшите воспринимаемую производительность. Вы можете узнать больше о WebP в выступлении Паскаля Массимино из Google.
Для преобразования в WebP вы можете использовать WebP Converter, cwebp или libwebp. У Айра Адеринокуна также есть очень подробное руководство по преобразованию изображений в WebP, как и у Джоша Комо в его статье о работе с современными форматами изображений.

Подробный рассказ о WebP: WebP Rewind от Паскаля Массимино. (Большой превью) Sketch изначально поддерживает WebP, а изображения WebP можно экспортировать из Photoshop с помощью подключаемого модуля WebP для Photoshop. Но возможны и другие варианты.
Если вы используете WordPress или Joomla, существуют расширения, которые помогут вам легко реализовать поддержку WebP, такие как Optimus и Cache Enabler для WordPress и собственное поддерживаемое расширение Joomla (через Коди Арсено). Вы также можете абстрагироваться от элемента
<picture>с помощью React, стилизованных компонентов или gatsby-image.Ах — бессовестная вилка! — Джереми Вагнер даже опубликовал потрясающую книгу о WebP, с которой вы, возможно, захотите ознакомиться, если вас интересует все, что связано с WebP.
- Используем ли мы AVIF?
Возможно, вы уже слышали важные новости: AVIF приземлился. Это новый формат изображения, полученный из ключевых кадров видео AV1. Это открытый, бесплатный формат, который поддерживает сжатие с потерями и без потерь, анимацию, альфа-канал с потерями и может обрабатывать четкие линии и сплошные цвета (что было проблемой с JPEG), обеспечивая при этом лучшие результаты в обоих случаях.На самом деле, по сравнению с WebP и JPEG, AVIF работает значительно лучше , обеспечивая экономию среднего размера файла до 50% при том же DSSIM ((не)подобие между двумя или более изображениями с использованием алгоритма, близкого к человеческому зрению). На самом деле, в своем подробном посте об оптимизации загрузки изображений Мальте Убл отмечает, что AVIF «очень последовательно превосходит JPEG в очень значительном смысле. потери из-за отсутствия поддержки прогрессивной загрузки».

Мы можем использовать AVIF в качестве прогрессивного расширения, предоставляя WebP, JPEG или PNG для старых браузеров. (Большое превью). См. обычный текстовый вид ниже. Как ни странно, AVIF может работать даже лучше, чем большие SVG, хотя, конечно, его не следует рассматривать как замену SVG. Это также один из первых форматов изображений, поддерживающих поддержку цвета HDR; предлагая более высокую яркость, глубину цвета и цветовую гамму. Единственным недостатком является то, что в настоящее время AVIF не поддерживает прогрессивное декодирование изображений (пока?) и, как и Brotli, кодирование с высокой степенью сжатия в настоящее время довольно медленное, хотя декодирование быстрое.
В настоящее время AVIF поддерживается в Chrome, Firefox и Opera, и ожидается, что поддержка в Safari появится в ближайшее время (поскольку Apple является членом группы, создавшей AV1).
Каков наилучший способ подачи изображений в наши дни ? Для иллюстраций и векторных изображений (сжатый) SVG, несомненно, лучший выбор. Для фотографий мы используем методы согласования контента с элементом
picture. Если AVIF поддерживается, мы отправляем изображение AVIF; если это не так, мы сначала возвращаемся к WebP, а если WebP также не поддерживается, мы переключаемся на JPEG или PNG в качестве резерва (при необходимости применяя условия@media):<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>Честно говоря, более вероятно, что мы будем использовать некоторые условия в элементе
picture:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>Вы можете пойти еще дальше, заменив анимированные изображения статическими изображениями для клиентов, которые соглашаются на меньшее движение с помощью
prefers-reduced-motion:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>За пару месяцев AVIF набрал обороты:
- Мы можем протестировать резервные варианты WebP/AVIF на панели Rendering в DevTools.
- Мы можем использовать Squoosh, AVIF.io и libavif для кодирования, декодирования, сжатия и преобразования файлов AVIF.
- Мы можем использовать компонент AVIF Preact Джейка Арчибальда, который декодирует AVIF-файл в воркере и отображает результат на холсте,
- Чтобы предоставить AVIF только поддерживающим браузерам, мы можем использовать плагин PostCSS вместе со скриптом 315B для использования AVIF в ваших объявлениях CSS.
- Мы можем постепенно предоставлять новые форматы изображений с помощью CSS и Cloudlare Workers, чтобы динамически изменять возвращаемый HTML-документ, выводя информацию из заголовка
accept, а затем добавляяwebp/avifи т. д. по мере необходимости. - AVIF уже доступен в Cloudinary (с ограничениями на использование), Cloudflare поддерживает AVIF при изменении размера изображения, и вы можете включить AVIF с пользовательскими заголовками AVIF в Netlify.
- Когда дело доходит до анимации, AVIF работает так же, как
<img src=mp4>в Safari, превосходя GIF и WebP в целом, но MP4 по-прежнему работает лучше. - В общем, для анимации AVC1 (h264) > HVC1 > WebP > AVIF > GIF, при условии, что браузеры на основе Chromium когда-либо будут поддерживать
<img src=mp4>. - Вы можете найти более подробную информацию об AVIF в AVIF for Next Generation Image Coding в докладе Адитьи Мавланкар из Netflix и в докладе Корнела Лесински из Cloudflare о формате изображения.
- Отличный справочник по всему AVIF: подробный пост Джейка Арчибальда на AVIF приземлился.
Так есть ли будущее в AVIF ? Джон Снейерс не согласен: AVIF работает на 60% хуже, чем JPEG XL, еще один бесплатный и открытый формат, разработанный Google и Cloudinary. На самом деле, JPEG XL, кажется, работает намного лучше по всем направлениям. Однако JPEG XL все еще находится на завершающей стадии стандартизации и еще не работает ни в одном браузере. (Не путать с JPEG-XR от Microsoft, исходящим из старого доброго Internet Explorer 9 раз).
- Правильно ли оптимизированы JPEG/PNG/SVG?
Когда вы работаете над целевой страницей, на которой очень важно, чтобы главное изображение загружалось молниеносно быстро, убедитесь, что файлы JPEG являются прогрессивными и сжаты с помощью mozJPEG (который сокращает время начального рендеринга за счет управления уровнями сканирования) или Guetzli, Google с открытым исходным кодом. кодировщик, ориентированный на производительность восприятия и использующий знания Zopfli и WebP. Единственный недостаток: медленное время обработки (минута процессора на мегапиксель).Для PNG мы можем использовать Pingo, а для SVG мы можем использовать SVGO или SVGOMG. И если вам нужно быстро просмотреть и скопировать или загрузить все ресурсы SVG с веб-сайта, svg-grabber может сделать это за вас.
Об этом говорится в каждой статье по оптимизации изображений, но всегда стоит упомянуть о чистоте и аккуратности векторных ресурсов. Обязательно очистите неиспользуемые активы, удалите ненужные метаданные и уменьшите количество точек пути в иллюстрации (и, следовательно, в коде SVG). ( Спасибо, Джереми! )
Однако есть и полезные онлайн-инструменты:
- Используйте Squoosh для сжатия, изменения размера и управления изображениями с оптимальным уровнем сжатия (с потерями или без потерь),
- Используйте Guetzli.it для сжатия и оптимизации изображений JPEG с помощью Guetzli, который хорошо работает с изображениями с четкими краями и сплошными цветами (но может быть немного медленнее)).
- Используйте Генератор контрольных точек адаптивного изображения или такой сервис, как Cloudinary или Imgix, для автоматизации оптимизации изображения. Кроме того, во многих случаях использование
srcsetиsizesдает значительные преимущества. - Чтобы проверить эффективность вашей адаптивной разметки, вы можете использовать images-heap, инструмент командной строки, который измеряет эффективность в зависимости от размера окна просмотра и соотношения пикселей устройства.
- Вы можете добавить автоматическое сжатие изображений в свои рабочие процессы GitHub, чтобы ни одно изображение не попадало в рабочую среду без сжатия. Экшен использует mozjpeg и libvips, которые работают с PNG и JPG.
- Чтобы оптимизировать внутреннюю память, вы можете использовать новый формат Dropbox Lepton для сжатия файлов JPEG без потерь в среднем на 22%.
- Используйте BlurHash, если вы хотите показать замещающее изображение заранее. BlurHash берет изображение и дает вам короткую строку (всего 20-30 символов!), которая представляет собой заполнитель для этого изображения. Строка достаточно короткая, чтобы ее можно было легко добавить как поле в объект JSON.
BlurHash — это крошечное компактное представление заполнителя для изображения. (Большой превью) Иногда оптимизация изображений сама по себе не помогает. Чтобы сократить время, необходимое для запуска рендеринга важного изображения, отложите загрузку менее важных изображений и отложите загрузку любых скриптов после того, как критические изображения уже отрендерены. Наиболее надежным способом является гибридная отложенная загрузка, когда мы используем нативную отложенную загрузку и отложенную загрузку, библиотеку, которая обнаруживает любые изменения видимости, вызванные взаимодействием с пользователем (с помощью IntersectionObserver, который мы рассмотрим позже). Кроме того:
- Рассмотрите возможность предварительной загрузки важных изображений, чтобы браузер не обнаружил их слишком поздно. Для фоновых изображений, если вы хотите быть еще более агрессивным, вы можете добавить изображение как обычное изображение с помощью
<img src>, а затем скрыть его с экрана. - Рассмотрите возможность замены изображений с помощью атрибута Sizes, указав различные размеры отображения изображения в зависимости от медиа-запросов, например, чтобы управлять
sizesдля замены источников в компоненте лупы. - Проверьте несоответствия загрузки изображений, чтобы предотвратить неожиданную загрузку изображений переднего плана и фона. Следите за изображениями, которые загружаются по умолчанию, но могут никогда не отображаться — например, в каруселях, аккордеонах и галереях изображений.
- Всегда устанавливайте
widthиheightизображений. Обратите внимание на свойствоaspect-ratioв CSS и атрибутintrinsicsizeразмера, который позволит нам устанавливать пропорции и размеры для изображений, чтобы браузер мог заранее зарезервировать заранее определенный слот макета, чтобы избежать скачков макета во время загрузки страницы.
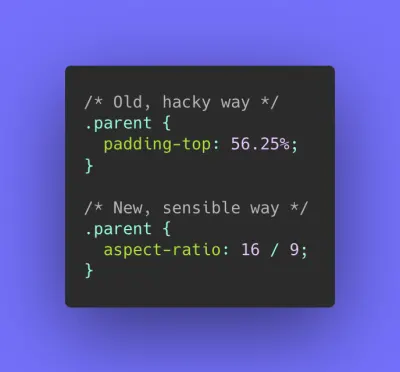
Должно быть, это всего лишь вопрос недель или месяцев, когда соотношение сторон появится в браузерах. В Safari Technical Preview 118 уже. В настоящее время за флагом в Firefox и Chrome. (Большой превью) Если вы чувствуете себя предприимчивым, вы можете обрезать и переупорядочивать потоки HTTP/2, используя Edge Workers, в основном фильтр в реальном времени, живущий в CDN, для более быстрой отправки изображений по сети. Пограничные рабочие используют потоки JavaScript, которые используют фрагменты, которыми вы можете управлять (по сути, это JavaScript, работающий на краю CDN, который может изменять потоковые ответы), поэтому вы можете контролировать доставку изображений.
С сервис-воркером уже слишком поздно, так как вы не можете контролировать то, что передается по сети, но он работает с пограничными работниками. Таким образом, вы можете использовать их поверх статических файлов JPEG, постепенно сохраняемых для конкретной целевой страницы.
Пример выходных данных с помощью images-heap, инструмента командной строки, который измеряет эффективность по размерам области просмотра и соотношению пикселей устройства. (Источник изображения) (Большой предварительный просмотр) Не достаточно хорош? Что ж, вы также можете улучшить воспринимаемую производительность для изображений с помощью метода множественных фоновых изображений. Имейте в виду, что игра с контрастом и размытие ненужных деталей (или удаление цветов) также могут уменьшить размер файла. Ах, вам нужно увеличить маленькое фото без потери качества? Рассмотрите возможность использования Letsenhance.io.
Эти оптимизации пока охватывают только основы. Эдди Османи опубликовала очень подробное руководство по Essential Image Optimization, в котором подробно рассказывается о сжатии изображений и управлении цветом. Например, вы можете размыть ненужные части изображения (применив к ним фильтр размытия по Гауссу), чтобы уменьшить размер файла, и в конечном итоге вы можете даже начать удалять цвета или превратить изображение в черно-белое, чтобы еще больше уменьшить размер. . Для фоновых изображений экспорт фотографий из Photoshop с качеством от 0 до 10% также может быть абсолютно приемлемым.
В Smashing Magazine мы используем постфикс
-optдля имен изображений — например,brotli-compression-opt.png; всякий раз, когда изображение содержит этот постфикс, все в команде знают, что изображение уже оптимизировано.Ах, и не используйте JPEG-XR в Интернете — «обработка декодирования JPEG-XR на стороне программного обеспечения на ЦП сводит на нет и даже перевешивает потенциально положительное влияние экономии размера байта, особенно в контексте SPA» (не чтобы перепутать с Cloudinary / Google JPEG XL).

- Правильно ли оптимизированы видео?
До сих пор мы рассматривали изображения, но избегали разговоров о старых добрых GIF-файлах. Несмотря на нашу любовь к GIF, пришло время отказаться от них навсегда (по крайней мере, в наших веб-сайтах и приложениях). Вместо того, чтобы загружать тяжелые анимированные GIF-файлы, которые влияют как на производительность рендеринга, так и на пропускную способность, рекомендуется переключиться либо на анимированный WebP (где GIF является запасным вариантом), либо полностью заменить их зацикленными видео HTML5.В отличие от изображений, браузеры не загружают предварительно содержимое
<video>, но видео HTML5, как правило, намного легче и меньше, чем GIF. Не вариант? Ну, по крайней мере, мы можем добавить сжатие с потерями к GIF с помощью Lossy GIF, gifsicle или giflossy.Тесты, проведенные Колином Бенделлом, показывают, что встроенные видео в тегах
imgв Safari Technology Preview отображаются по крайней мере в 20 раз быстрее и декодируются в 7 раз быстрее, чем эквивалент GIF, в дополнение к тому, что они имеют меньший размер файла. Однако он не поддерживается в других браузерах.В стране хороших новостей форматы видео стремительно развиваются на протяжении многих лет. Долгое время мы надеялись, что WebM станет форматом, который будет управлять ими всеми, а WebP (который, по сути, представляет собой одно неподвижное изображение внутри видеоконтейнера WebM) станет заменой устаревшим форматам изображений. Действительно, Safari теперь поддерживает WebP, но, несмотря на то, что WebP и WebM получили поддержку в наши дни, прорыва на самом деле не произошло.
Тем не менее, мы могли бы использовать WebM для большинства современных браузеров:
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>Но, возможно, мы могли бы вернуться к нему вообще. В 2018 году Альянс открытых медиа выпустил новый перспективный формат видео под названием AV1 . AV1 имеет сжатие, аналогичное кодеку H.265 (эволюция H.264), но в отличие от последнего, AV1 является бесплатным. Стоимость лицензии H.265 подтолкнула поставщиков браузеров к использованию вместо этого сравнительно производительного AV1: AV1 (точно так же, как H.265) сжимает в два раза лучше, чем WebM .

У AV1 есть хорошие шансы стать окончательным стандартом для видео в Интернете. (Изображение предоставлено Wikimedia.org) (Большой превью) На самом деле Apple в настоящее время использует формат HEIF и HEVC (H.265), и все фото и видео на последней версии iOS сохраняются в этих форматах, а не в JPEG. В то время как HEIF и HEVC (H.265) не доступны должным образом в Интернете (пока?), AV1 — и получает поддержку браузеров. Поэтому добавление источника
AV1в ваш<video>разумно, так как все поставщики браузеров, похоже, согласны с этим.На данный момент наиболее широко используемой и поддерживаемой кодировкой является H.264, обслуживаемая файлами MP4, поэтому перед подачей файла убедитесь, что ваши MP4-файлы обработаны многопроходным кодированием, размыты эффектом frei0r iirblur (если применимо) и Метаданные атома moov перемещаются в заголовок файла, в то время как ваш сервер принимает обслуживание байтов. Борис Шапира дает точные инструкции для FFmpeg по максимальной оптимизации видео. Конечно, предоставление формата WebM в качестве альтернативы тоже помогло бы.
Нужно ускорить рендеринг видео, но видеофайлы все еще слишком велики ? Например, когда у вас есть большое фоновое видео на целевой странице? Обычный метод заключается в том, чтобы сначала показать самый первый кадр в виде неподвижного изображения или отобразить сильно оптимизированный короткий зацикленный сегмент, который можно интерпретировать как часть видео, а затем, когда видео будет достаточно буферизовано, начать воспроизведение. собственно видео. Дуг Силларс написал подробное руководство по производительности фонового видео, которое может быть полезно в этом случае. ( Спасибо, Гай Поджарный! ).
Для приведенного выше сценария вы можете предоставить адаптивные изображения постеров . По умолчанию элементы
videoпозволяют использовать только одно изображение в качестве постера, что не всегда оптимально. Мы можем использовать Responsive Video Poster, библиотеку JavaScript, которая позволяет использовать разные изображения постеров для разных экранов, а также добавлять переходное наложение и полный контроль над стилем заполнителей видео.Исследование показывает, что качество видеопотока влияет на поведение зрителей. На самом деле зрители начинают отказываться от видео, если задержка запуска превышает примерно 2 секунды. После этого увеличение задержки на 1 секунду приводит к увеличению процента отказов примерно на 5,8%. Поэтому неудивительно, что среднее время начала видео составляет 12,8 с, при этом 40% видео имеют по крайней мере 1 остановку, а 20% - по крайней мере 2 секунды воспроизведения видео. На самом деле, зависания видео неизбежны в 3G, поскольку видео воспроизводится быстрее, чем сеть может предоставить контент.
Итак, каково решение? Обычно устройства с небольшим экраном не могут обрабатывать 720p и 1080p, которые мы обслуживаем на рабочем столе. По словам Дуга Силларса, мы можем либо создавать уменьшенные версии наших видео, либо использовать Javascript для определения источника для небольших экранов, чтобы обеспечить быстрое и плавное воспроизведение на этих устройствах. В качестве альтернативы мы можем использовать потоковое видео. Видеопотоки HLS будут доставлять на устройство видео соответствующего размера, что избавляет от необходимости создавать разные видео для разных экранов. Он также согласует скорость сети и адаптирует битрейт видео к скорости используемой вами сети.
Чтобы избежать потери полосы пропускания, мы могли добавить источник видео только для устройств, которые действительно могут хорошо воспроизводить видео. В качестве альтернативы мы можем вообще удалить
autoplayиз тегаvideoи использовать JavaScript для вставкиautoplayдля больших экранов. Кроме того, нам нужно добавитьpreload="none"кvideo, чтобы указать браузеру не загружать какие -либо видеофайлы, пока он действительно не понадобится:<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Затем мы можем настроить таргетинг на браузеры, которые действительно поддерживают AV1:
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Затем мы могли бы повторно добавить
autoplayвыше определенного порога (например, 1000 пикселей):/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>
Количество киосков по устройствам и скорости сети. У более быстрых устройств в более быстрых сетях практически нет зависаний. Согласно исследованию Дуга Силларса. (Большой превью) Производительность воспроизведения видео — это отдельная история, и если вы хотите погрузиться в нее подробнее, взгляните на другую серию статей Дуга Силларса «Текущее состояние видео и лучшие практики доставки видео», в которой подробно описаны показатели доставки видео. , предварительная загрузка видео, сжатие и потоковая передача. Наконец, вы можете проверить, насколько медленным или быстрым будет ваше потоковое видео с помощью Stream or Not.
- Оптимизирована ли доставка веб-шрифтов?
The first question that's worth asking is if we can get away with using UI system fonts in the first place — we just need to make sure to double check that they appear correctly on various platforms. If it's not the case, chances are high that the web fonts we are serving include glyphs and extra features and weights that aren't being used. We can ask our type foundry to subset web fonts or if we are using open-source fonts, subset them on our own with Glyphhanger or Fontsquirrel. We can even automate our entire workflow with Peter Muller's subfont, a command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into our pages.WOFF2 support is great, and we can use WOFF as fallback for browsers that don't support it — or perhaps legacy browsers could be served system fonts. There are many, many, many options for web font loading, and we can choose one of the strategies from Zach Leatherman's "Comprehensive Guide to Font-Loading Strategies," (code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with
preloadand "The Compromise" method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that "The Compromise" technique loads polyfill asynchronously only if font load events are not supported, so you don't need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.In general, it might be a good idea to use the
preloadresource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Withpreload, there is a puzzle of priorities, so consider injectingrel="preload"elements into the DOM just before the external blocking scripts. According to Andy Davies, "resources injected using a script are hidden from the browser until the script executes, and we can use this behaviour to delay when the browser discovers thepreloadhint." Otherwise, font loading will cost you in the first render time.
When everything is critical, nothing is critical. preload only one or a maximum of two fonts of each family. (Image credit: Zach Leatherman – slide 93) (Large preview) It's a good idea to be selective and choose files that matter most, eg the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less critical.
It has become quite common to use
local()value (which refers to a local font by name) when defining afont-familyin the@font-facerule:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }The idea is reasonable: some popular open-source fonts such as Open Sans are coming pre-installed with some drivers or apps, so if the font is available locally, the browser doesn't need to download the web font and can display the local font immediately. As Bram Stein noted, "though a local font matches the name of a web font, it most likely isn't the same font . Many web fonts differ from their "desktop" version. The text might be rendered differently, some characters may fall back to other fonts, OpenType features can be missing entirely, or the line height may be different."
Also, as typefaces evolve over time, the locally installed version might be very different from the web font, with characters looking very different. So, according to Bram, it's better to never mix locally installed fonts and web fonts in
@font-facerules. Google Fonts has followed suit by disablinglocal()on the CSS results for all users, other than Android requests for Roboto.Nobody likes waiting for the content to be displayed. With the
font-displayCSS descriptor, we can control the font loading behavior and enable content to be readable immediately (withfont-display: optional) or almost immediately (with a timeout of 3s, as long as the font gets successfully downloaded — withfont-display: swap). (Well, it's a bit more complicated than that.)However, if you want to minimize the impact of text reflows, we could use the Font Loading API (supported in all modern browsers). Specifically that means for every font, we'd creata a
FontFaceobject, then try to fetch them all, and only then apply them to the page. This way, we group all repaints by loading all fonts asynchronously, and then switch from fallback fonts to the web font exactly once. Take a look at Zach's explanation, starting at 32:15, and the code snippet):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));To initiate a very early fetch of the fonts with Font Loading API in use, Adrian Bece suggests to add a non-breaking space
nbsp;at the top of thebody, and hide it visually witharia-visibility: hiddenand a.hiddenclass:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>This goes along with CSS that has different font families declared for different states of loading, with the change triggered by Font Loading API once the fonts have successfully loaded:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }If you ever wondered why despite all your optimizations, Lighthouse still suggests to eliminate render-blocking resources (fonts), in the same article Adrian Bece provides a few techniques to make Lighthouse happy, along with a Gatsby Omni Font Loader, a performant asynchronous font loading and Flash Of Unstyled Text (FOUT) handling plugin for Gatsby.

Now, many of us might be using a CDN or a third-party host to load web fonts from. In general, it's always better to self-host all your static assets if you can, so consider using google-webfonts-helper, a hassle-free way to self-host Google Fonts. And if it's not possible, you can perhaps proxy the Google Font files through the page origin.
It's worth noting though that Google is doing quite a bit of work out of the box, so a server might need a bit of tweaking to avoid delays ( thanks, Barry! )
This is quite important especially as since Chrome v86 (released October 2020), cross-site resources like fonts can't be shared on the same CDN anymore — due to the partitioned browser cache. This behavior was a default in Safari for years.
But if it's not possible at all, there is a way to get to the fastest possible Google Fonts with Harry Roberts' snippet:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>Harry's strategy is to pre-emptively warm up the fonts' origin first. Then we initiate a high-priority, asynchronous fetch for the CSS file. Afterwards, we initiate a low-priority, asynchronous fetch that gets applied to the page only after it's arrived (with a print stylesheet trick). Finally, if JavaScript isn't supported, we fall back to the original method.
Ah, talking about Google Fonts: you can shave up to 90% of the size of Google Fonts requests by declaring only characters you need with
&text. Plus, the support for font-display was added recently to Google Fonts as well, so we can use it out of the box.Однако небольшое предостережение. Если вы используете
font-display: optional, использованиеpreloadможет быть неоптимальным, так как это вызовет ранний запрос веб-шрифта (вызывая перегрузку сети , если у вас есть другие ресурсы критического пути, которые необходимо извлечь). Используйтеpreconnectдля более быстрых запросов шрифтов из разных источников, но будьте осторожны сpreloadзагрузкой, так как предварительная загрузка шрифтов из другого источника вызовет конкуренцию в сети. Все эти приемы описаны в рецептах загрузки веб-шрифтов Зака.С другой стороны, может быть хорошей идеей отказаться от веб-шрифтов (или, по крайней мере, рендеринга второго этапа), если пользователь включил функцию «Уменьшение движения» в настройках специальных возможностей или выбрал режим экономии данных (см. заголовок «
Save-Data»). , или когда у пользователя медленное подключение (через Network Information API).Мы также можем использовать медиа-запрос
prefers-reduced-dataCSS, чтобы не определять объявления шрифтов, если пользователь выбрал режим сохранения данных (есть и другие варианты использования). Медиа-запрос в основном раскрывает, включен или выключен заголовок запросаSave-Dataиз HTTP-расширения Client Hint, чтобы разрешить использование с CSS. В настоящее время поддерживается только в Chrome и Edge.Метрики? Чтобы измерить производительность загрузки веб-шрифтов, рассмотрите метрику « Видимый весь текст » (момент, когда все шрифты загружены и весь контент отображается в веб-шрифтах), время до реального курсива, а также счетчик перекомпоновки веб-шрифтов после первого рендеринга. Очевидно, что чем ниже обе метрики, тем выше производительность.
А как насчет вариативных шрифтов , спросите вы? Важно отметить, что вариативные шрифты могут потребовать значительного внимания к производительности. Они дают нам гораздо более широкое дизайнерское пространство для выбора типографики, но это происходит за счет одного последовательного запроса, а не нескольких запросов отдельных файлов.
В то время как вариативные шрифты резко уменьшают общий объединенный размер файлов шрифтов, один запрос может быть медленным, блокируя отрисовку всего содержимого на странице. Таким образом, подмножество и разделение шрифта на наборы символов по-прежнему имеют значение. С хорошей стороны, однако, с переменным шрифтом мы получим ровно одно переформатирование по умолчанию, поэтому для группировки перерисовок не потребуется JavaScript.
Итак, что тогда может сделать пуленепробиваемую стратегию загрузки веб-шрифтов ? Подмножьте шрифты и подготовьте их к двухэтапному рендерингу, объявите их с помощью дескриптора
font-displayшрифтов, используйте API загрузки шрифтов для группировки перерисовок и сохранения шрифтов в постоянном кэше сервисного работника. При первом посещении введите предварительную загрузку скриптов непосредственно перед блокировкой внешних скриптов. При необходимости вы можете вернуться к Font Face Observer Брэма Штейна. А если вам интересно измерить производительность загрузки шрифтов, Андреас Маршке исследует отслеживание производительности с помощью Font API и UserTiming API.Наконец, не забудьте включить
unicode-range, чтобы разбить большой шрифт на более мелкие шрифты для конкретного языка, и использовать сопоставитель стиля шрифта Моники Динкулеску, чтобы свести к минимуму резкое изменение макета из-за несоответствия размеров между запасным и исходным шрифтами. веб-шрифты.В качестве альтернативы, чтобы эмулировать веб-шрифт для резервного шрифта, мы можем использовать дескрипторы @font-face для переопределения метрик шрифта (демонстрация, включена в Chrome 87). (Обратите внимание, что настройки сложны со сложными стеками шрифтов.)
Будущее выглядит светлым? С прогрессивным обогащением шрифта в конечном итоге мы сможем «загружать только необходимую часть шрифта на любой данной странице, а для последующих запросов на этот шрифт динамически« исправлять »исходную загрузку с дополнительными наборами глифов по мере необходимости на последующей странице. просмотров», как объясняет Джейсон Паменталь. Демо-версия Incremental Transfer уже доступна, и работа над ней продолжается.
Оптимизация сборки
- Определили ли мы наши приоритеты?
Это хорошая идея, чтобы знать, с чем вы имеете дело в первую очередь. Проведите инвентаризацию всех ваших ресурсов (JavaScript, изображения, шрифты, сторонние скрипты и «дорогие» модули на странице, такие как карусели, сложная инфографика и мультимедийный контент), и разбейте их на группы.Настройте электронную таблицу . Определите основные возможности для устаревших браузеров (т. е. полностью доступный основной контент), расширенные возможности для поддерживающих браузеров (т. е. расширенные, полные возможности) и дополнительные функции (ресурсы, которые не являются абсолютно необходимыми и могут загружаться отложенно, например веб-шрифты, ненужные стили, сценарии карусели, видеоплееры, виджеты социальных сетей, большие изображения). Несколько лет назад мы опубликовали статью «Улучшение производительности Smashing Magazine», в которой подробно описывается этот подход.
При оптимизации производительности нам необходимо учитывать наши приоритеты. Немедленно загрузите основные возможности , затем улучшения , а затем дополнительные функции .
- Используете ли вы нативные модули JavaScript в продакшене?
Помните старую добрую технику «перерезать горчицу», чтобы отправить базовый опыт в устаревшие браузеры и расширенный опыт в современные браузеры? Обновленный вариант метода может использовать ES2017+<script type="module">, также известный как шаблон module/nomodule (также представленный Джереми Вагнером как дифференциальное обслуживание ).Идея состоит в том, чтобы скомпилировать и обслуживать два отдельных пакета JavaScript : «обычная» сборка, та, что с Babel-преобразованиями и полифиллами, и обслуживать их только для устаревших браузеров, которым они действительно нужны, и еще один пакет (с той же функциональностью), который не имеет преобразований или полифиллы.
В результате мы помогаем уменьшить блокировку основного потока за счет уменьшения количества сценариев, которые должен обрабатывать браузер. Джереми Вагнер опубликовал исчерпывающую статью о дифференциальном обслуживании и о том, как настроить его в конвейере сборки, от настройки Babel до настроек, которые вам нужно будет внести в Webpack, а также о преимуществах выполнения всей этой работы.
Скрипты встроенных модулей JavaScript по умолчанию откладываются, поэтому, пока происходит синтаксический анализ HTML, браузер загружает основной модуль.

Нативные модули JavaScript по умолчанию откладываются. Почти все о нативных модулях JavaScript. (Большой превью) Тем не менее одно предупреждение: шаблон модуль/номодуль может иметь неприятные последствия для некоторых клиентов, поэтому вы можете рассмотреть обходной путь: менее рискованный шаблон дифференциального обслуживания Джереми, который, однако, обходит сканер предварительной загрузки, что может повлиять на производительность способами, которые не могли бы быть. предвидеть. ( спасибо, Джереми! )
На самом деле, Rollup поддерживает модули в качестве выходного формата, поэтому мы можем как объединять код, так и развертывать модули в рабочей среде. Parcel имеет поддержку модулей в Parcel 2. Для Webpack module-nomodule-plugin автоматизирует генерацию скриптов модуля/номодуля.
Примечание . Стоит отметить, что одного обнаружения функций недостаточно для принятия обоснованного решения о том, какую полезную нагрузку отправлять в этот браузер. Само по себе мы не можем вывести возможности устройства из версии браузера. Например, недорогие телефоны Android в развивающихся странах в основном работают под управлением Chrome и будут сокращать горчицу, несмотря на ограниченные возможности памяти и процессора.
В конце концов, используя заголовок Device Memory Client Hints, мы сможем более надежно нацеливаться на недорогие устройства. На момент написания заголовок поддерживается только в Blink (в основном он касается клиентских подсказок). Поскольку Device Memory также имеет JavaScript API, который доступен в Chrome, одним из вариантов может быть функция обнаружения на основе API и возврат к шаблону module/nomodule, если он не поддерживается ( спасибо, Йоав! ).
- Используете ли вы встряхивание дерева, подъем области видимости и разделение кода?
Tree-shaking — это способ очистить ваш процесс сборки, включив только тот код, который фактически используется в производстве, и исключив неиспользуемый импорт в Webpack. С Webpack и Rollup у нас также есть подъем области, который позволяет обоим инструментам определять, где цепочкуimportможно сгладить и преобразовать в одну встроенную функцию без ущерба для кода. С Webpack мы также можем использовать JSON Tree Shaking.Разделение кода — еще одна функция Webpack, которая разбивает вашу кодовую базу на «фрагменты», которые загружаются по запросу. Не весь код JavaScript нужно скачивать, парсить и компилировать сразу. Как только вы определите точки разделения в своем коде, Webpack может позаботиться о зависимостях и выходных файлах. Это позволяет вам сохранить первоначальную загрузку небольшой и запрашивать код по требованию, когда его запрашивает приложение. У Александра Кондрова есть фантастическое введение в разделение кода с помощью Webpack и React.
Рассмотрите возможность использования плагина preload-webpack-plugin, который принимает маршруты, разделенные кодом, а затем предлагает браузеру предварительно загрузить их с помощью
<link rel="preload">или<link rel="prefetch">. Встроенные директивы Webpack также дают некоторый контроль надpreload/prefetch. (Остерегайтесь проблем с расстановкой приоритетов.)Где определить точки разделения? Отслеживая, какие фрагменты CSS/JavaScript используются, а какие нет. Умар Ханса объясняет, как вы можете использовать покрытие кода от Devtools для достижения этой цели.
При работе с одностраничными приложениями нам нужно некоторое время для инициализации приложения, прежде чем мы сможем отобразить страницу. Для вашей настройки потребуется ваше индивидуальное решение, но вы можете следить за модулями и методами, чтобы ускорить начальное время рендеринга. Например, вот как отлаживать производительность React и устранять распространенные проблемы с производительностью React, а вот как повысить производительность в Angular. Как правило, большинство проблем с производительностью возникает при начальной загрузке приложения.
Итак, каков наилучший способ агрессивного, но не слишком агрессивного разделения кода? По словам Фила Уолтона, «в дополнение к разделению кода с помощью динамического импорта [мы могли бы] также использовать разделение кода на уровне пакета , где каждый импортированный модуль узла помещается в фрагмент на основе имени его пакета». Фил также предоставляет учебник о том, как его построить.
- Можем ли мы улучшить вывод Webpack?
Поскольку Webpack часто считается загадочным, существует множество подключаемых модулей Webpack, которые могут пригодиться для дальнейшего уменьшения производительности Webpack. Ниже приведены некоторые из наиболее неясных из них, которые могут потребовать немного больше внимания.Один из интересных исходит из ветки Ивана Акулова. Представьте, что у вас есть функция, которую вы вызываете один раз, сохраняете ее результат в переменной и затем не используете эту переменную. Tree-shaking удалит переменную, но не функцию, потому что она может использоваться иначе. Однако, если функция нигде не используется, вы можете удалить ее. Для этого добавьте к вызову функции
/*#__PURE__*/, который поддерживается Uglify и Terser — готово!
Чтобы удалить такую функцию, когда ее результат не используется, добавьте перед вызовом функции /*#__PURE__*/. Через Ивана Акулова.(Большое превью)Вот некоторые из других инструментов, которые рекомендует Иван:
- purgecss-webpack-plugin удаляет неиспользуемые классы, особенно если вы используете Bootstrap или Tailwind.
- Включить
optimization.splitChunks: 'all'с помощью плагина split-chunks. Это заставит веб-пакет автоматически разделить код ваших входных пакетов для лучшего кэширования. - Задайте для
optimization.runtimeChunk: true. Это переместит среду выполнения веб-пакета в отдельный фрагмент, а также улучшит кеширование. - google-fonts-webpack-plugin загружает файлы шрифтов, чтобы вы могли обслуживать их со своего сервера.
- workbox-webpack-plugin позволяет создать сервис-воркер с настройкой предварительного кэширования для всех ваших ресурсов веб-пакета. Кроме того, ознакомьтесь с пакетами Service Worker, исчерпывающим руководством по модулям, которые можно сразу применить. Или используйте preload-webpack-plugin для создания
preload/prefetchдля всех фрагментов JavaScript. - speed-measure-webpack-plugin измеряет скорость сборки вашего веб-пакета, предоставляя информацию о том, какие этапы процесса сборки занимают больше всего времени.
- дубликат-пакет-проверки-вебпак-плагин предупреждает, когда ваш пакет содержит несколько версий одного и того же пакета.
- Используйте изоляцию области действия и динамически сокращайте имена классов CSS во время компиляции.
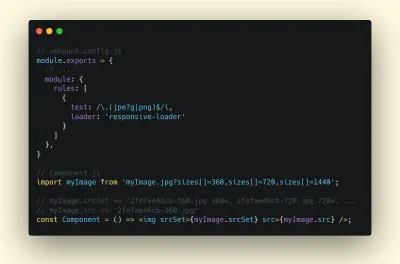
- Можно ли разгрузить JavaScript в Web Worker?
Чтобы уменьшить негативное влияние на Time-to-Interactive, может быть хорошей идеей рассмотреть возможность разгрузки тяжелого JavaScript в Web Worker.По мере роста кодовой базы будут появляться узкие места в производительности пользовательского интерфейса, что замедляет работу пользователя. Это потому, что операции DOM выполняются вместе с вашим JavaScript в основном потоке. С помощью веб-воркеров мы можем переместить эти дорогостоящие операции в фоновый процесс, работающий в другом потоке. Типичными вариантами использования веб-воркеров являются предварительная выборка данных и прогрессивные веб-приложения для загрузки и сохранения некоторых данных заранее, чтобы вы могли использовать их позже, когда это необходимо. И вы можете использовать Comlink для оптимизации связи между главной страницей и воркером. Еще есть над чем поработать, но мы к этому идем.
Есть несколько интересных тематических исследований, посвященных веб-воркерам, которые демонстрируют различные подходы к перемещению фреймворка и логики приложений в веб-воркеры. Вывод: в общем-то проблемы еще есть, но уже есть хорошие варианты использования ( спасибо, Иван Акулов! ).
Начиная с Chrome 80, появился новый режим для веб-работников с преимуществами производительности модулей JavaScript, который называется рабочими модулями. Мы можем изменить загрузку и выполнение скрипта, чтобы он соответствовал
script type="module", плюс мы также можем использовать динамический импорт для ленивой загрузки кода, не блокируя выполнение воркера.С чего начать? Вот несколько ресурсов, на которые стоит обратить внимание:
- Surma опубликовал отличное руководство о том, как запускать JavaScript вне основного потока браузера, а также о том, когда следует использовать Web Workers?
- Кроме того, проверьте разговор Сурма об архитектуре вне основного потока.
- В книге «В поисках гарантии отзывчивости» Шубхи Пэникер и Джейсон Миллер подробно рассказывается о том, как использовать веб-воркеры и когда их следует избегать.
- Как не мешать пользователям: меньше мусора с помощью Web Workers освещает полезные шаблоны для работы с Web Workers, эффективные способы взаимодействия между worker, выполнение сложной обработки данных вне основного потока, а также их тестирование и отладку.
- Workerize позволяет переместить модуль в Web Worker, автоматически отражая экспортированные функции как асинхронные прокси.
- Если вы используете Webpack, вы можете использовать workerize-loader. Кроме того, вы также можете использовать рабочий плагин.

Используйте веб-воркеры, когда код блокируется в течение длительного времени, но избегайте их, когда вы полагаетесь на DOM, обрабатываете входные ответы и требуете минимальной задержки. (через Адди Османи) (большой превью) Обратите внимание, что веб-воркеры не имеют доступа к DOM, потому что DOM не является «потокобезопасным», а код, который они выполняют, должен содержаться в отдельном файле.
- Можете ли вы разгрузить «горячие пути» для WebAssembly?
Мы могли бы переложить тяжелые вычислительные задачи на WebAssembly ( WASM ), формат двоичных инструкций, разработанный как переносимая цель для компиляции языков высокого уровня, таких как C/C++/Rust. Его браузерная поддержка замечательна, и в последнее время он стал жизнеспособным, поскольку вызовы функций между JavaScript и WASM становятся быстрее. Кроме того, он поддерживается даже в пограничном облаке Fastly.Конечно, WebAssembly не должен заменять JavaScript, но он может дополнить его в тех случаях, когда вы заметили перегрузку процессора. Для большинства веб-приложений больше подходит JavaScript, а WebAssembly лучше всего использовать для ресурсоемких веб-приложений , таких как игры.
Если вы хотите узнать больше о WebAssembly:
- Лин Кларк написал обширную серию статей для WebAssembly, а Милица Михайлия дает общий обзор того, как запускать нативный код в браузере, почему вы можете захотеть это сделать и что все это значит для JavaScript и будущего веб-разработки.
- Как мы использовали WebAssembly для ускорения работы нашего веб-приложения в 20 раз (пример из практики) освещает пример того, как медленные вычисления JavaScript были заменены скомпилированным WebAssembly, что привело к значительному повышению производительности.
- Патрик Хаманн говорил о растущей роли WebAssembly, и он развенчивает некоторые мифы о WebAssembly, исследует его проблемы, и сегодня мы можем использовать его практически в приложениях.
- Google Codelabs предлагает Введение в WebAssembly, 60-минутный курс, в котором вы узнаете, как взять нативный код — на C и скомпилировать его в WebAssembly, а затем вызвать его непосредственно из JavaScript.
- Алекс Данило рассказал о WebAssembly и о том, как он работает, в своем выступлении на Google I/O. Кроме того, Бенедек Гаджи поделился практическим примером WebAssembly, в частности, как команда использует его в качестве формата вывода своей кодовой базы C++ для iOS, Android и веб-сайта.
Все еще не знаете, когда использовать Web Workers, Web Assembly, потоки или, возможно, WebGL JavaScript API для доступа к GPU? Ускорение JavaScript — это краткое, но полезное руководство, объясняющее, когда что использовать и почему, а также с удобной блок-схемой и множеством полезных ресурсов.
- Предоставляем ли мы устаревший код только устаревшим браузерам?
Поскольку ES2017 замечательно поддерживается современными браузерами, мы можем использоватьbabelEsmPluginтолько для переноса функций ES2017+, которые не поддерживаются современными браузерами, на которые вы ориентируетесь.Хуссейн Джирде и Джейсон Миллер недавно опубликовали исчерпывающее руководство по транспиляции и обслуживанию современного и устаревшего JavaScript, подробно рассказывая о том, как заставить его работать с Webpack и Rollup, а также о необходимых инструментах. Вы также можете оценить, сколько JavaScript вы можете сократить на своем сайте или в наборах приложений.
Модули JavaScript поддерживаются во всех основных браузерах, поэтому используйте
script type="module", чтобы позволить браузерам с поддержкой модуля ES загружать файл, в то время как старые браузеры могли загружать устаревшие сборки соscript nomodule.В наши дни мы можем писать JavaScript на основе модулей, который изначально запускается в браузере, без транспиляторов или упаковщиков. Заголовок
<link rel="modulepreload">позволяет инициировать раннюю (и высокоприоритетную) загрузку скриптов модуля. По сути, это отличный способ помочь в максимальном использовании пропускной способности, сообщая браузеру о том, что ему нужно получить, чтобы он не застрял ни в чем во время этих длинных циклов. Кроме того, Джейк Арчибальд опубликовал подробную статью с подводными камнями и вещами, о которых следует помнить при работе с модулями ES, которые стоит прочитать.
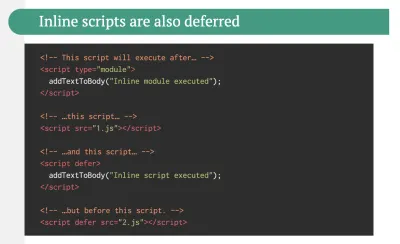
- Выявляйте и переписывайте устаревший код с помощью постепенного разделения .
Долгоживущие проекты имеют тенденцию собирать пыль и устаревший код. Пересмотрите свои зависимости и оцените, сколько времени потребуется на рефакторинг или переписывание устаревшего кода, который в последнее время вызывал проблемы. Конечно, это всегда большое мероприятие, но как только вы узнаете о влиянии устаревшего кода, вы можете начать с постепенного разделения.Во-первых, настройте метрики, которые отслеживают, остается ли соотношение вызовов устаревшего кода постоянным или снижается, а не растет. Публично отговаривайте команду от использования библиотеки и убедитесь, что ваш CI предупреждает разработчиков, если он используется в запросах на вытягивание. полифилы могут помочь перейти от устаревшего кода к переписанной кодовой базе, использующей стандартные функции браузера.
- Определите и удалите неиспользуемые CSS/JS .
Покрытие кода CSS и JavaScript в Chrome позволяет узнать, какой код был выполнен/применен, а какой нет. Вы можете начать запись покрытия, выполнить действия на странице, а затем изучить результаты покрытия кода. Как только вы обнаружите неиспользуемый код, найдите эти модули и выполните ленивую загрузку с помощьюimport()(см. весь поток). Затем повторите профиль покрытия и убедитесь, что теперь он отправляет меньше кода при начальной загрузке.Вы можете использовать Puppeteer для программного сбора покрытия кода. Chrome также позволяет экспортировать результаты покрытия кода. Как заметил Энди Дэвис, вам может понадобиться собрать данные о покрытии кода как для современных, так и для устаревших браузеров.
Есть много других вариантов использования и инструментов для Puppetter, которые могут потребовать немного больше внимания:
- Варианты использования Puppeteer, такие как, например, автоматическое визуальное сравнение или мониторинг неиспользуемого CSS при каждой сборке,
- Рецепты веб-производительности с Puppeteer,
- Полезные инструменты для записи и создания сценариев Pupeeteer и Playwright,
- Кроме того, вы даже можете записывать тесты прямо в DevTools,
- Всесторонний обзор Puppeteer от Нитая Нимана с примерами и вариантами использования.
Мы можем использовать Puppeteer Recorder и Puppeteer Sandbox для записи взаимодействия с браузером и создания сценариев Puppeteer и Playwright. (Большой превью) Кроме того, purgecss, UnCSS и Helium могут помочь вам удалить неиспользуемые стили из CSS. И если вы не уверены, что где-то используется подозрительный фрагмент кода, вы можете последовать совету Гарри Робертса: создайте прозрачный GIF размером 1×1px для определенного класса и поместите его в каталог
dead/, например,/assets/img/dead/comments.gif.После этого вы устанавливаете это конкретное изображение в качестве фона для соответствующего селектора в вашем CSS, сидите сложа руки и ждете несколько месяцев, если файл появится в ваших журналах. Если записей нет, значит, ни у кого этот устаревший компонент не отображался на экране: вы, вероятно, можете удалить его целиком.
Для отдела I-feel-adventure вы можете даже автоматизировать сбор неиспользуемых CSS через набор страниц, отслеживая DevTools с помощью DevTools.
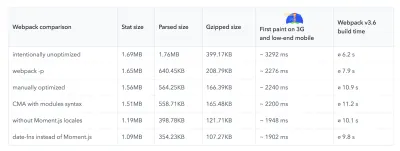
- Сократите размер ваших пакетов JavaScript.
Как заметила Эдди Османи, велика вероятность, что вы отправляете полные библиотеки JavaScript, когда вам нужна только часть, вместе с устаревшими полифиллами для браузеров, которым они не нужны, или просто дублируете код. Чтобы избежать накладных расходов, рассмотрите возможность использования оптимизации webpack-libs, которая удаляет неиспользуемые методы и полифиллы в процессе сборки.Проверяйте и просматривайте полифиллы , которые вы отправляете в устаревшие и современные браузеры, и относитесь к ним более стратегически. Взгляните на polyfill.io, службу, которая принимает запрос на набор функций браузера и возвращает только те полифиллы, которые необходимы запрашивающему браузеру.
Добавьте аудит пакетов в свой обычный рабочий процесс. Могут быть некоторые облегченные альтернативы тяжелым библиотекам, которые вы добавили много лет назад, например, Moment.js (сейчас снят с производства) можно заменить на:
- Собственный API интернационализации,
- Day.js со знакомым API Moment.js и шаблонами,
- дата-fns или
- Люксон.
- Вы также можете использовать Skypack Discover, который сочетает в себе проверенные людьми рекомендации пакетов с поиском, ориентированным на качество.
Исследование Бенедикта Ротша показало, что переход с Moment.js на date-fns может сократить примерно 300 мс для First Paint на 3G и недорогих мобильных телефонах.
Что касается аудита пакетов, Bundlephobia может помочь определить стоимость добавления пакета npm в ваш пакет. size-limit расширяет базовую проверку размера пакета, добавляя сведения о времени выполнения JavaScript. Вы даже можете интегрировать эти затраты с индивидуальным аудитом Lighthouse. Это касается и фреймворков. При удалении или обрезке Vue MDC Adapter (Material Components for Vue) стили уменьшаются со 194 КБ до 10 КБ.
Есть много дополнительных инструментов, которые помогут вам принять обоснованное решение о влиянии ваших зависимостей и жизнеспособных альтернатив:
- webpack-bundle-analyzer
- Обозреватель исходных карт
- Бандл Бадди
- связки фобия
- Анализ Webpack показывает, почему конкретный модуль включен в комплект.
- bundle-wizard также строит карту зависимостей для всей страницы.
- Плагин размера Webpack
- Стоимость импорта визуального кода
В качестве альтернативы отправке всего фреймворка вы можете обрезать свой фреймворк и скомпилировать его в необработанный пакет JavaScript , который не требует дополнительного кода. Это делает Svelte, как и плагин Rawact Babel, который транспилирует компоненты React.js в нативные операции DOM во время сборки. Почему? Ну, как объясняют сопровождающие, «react-dom включает в себя код для каждого возможного компонента/элемента HTML, который может быть отрисован, включая код для инкрементного рендеринга, планирования, обработки событий и т. д. Но есть приложения, которым не нужны все эти функции (на начальном этапе загрузка страницы). Для таких приложений может иметь смысл использовать собственные операции DOM для создания интерактивного пользовательского интерфейса».
- Используем ли мы частичную гидратацию?
Учитывая количество JavaScript, используемого в приложениях, нам нужно выяснить, как отправлять клиенту как можно меньше. Один из способов сделать это — и мы уже кратко рассмотрели его — частичное увлажнение. Идея довольно проста: вместо того, чтобы выполнять SSR и затем отправлять все приложение клиенту, клиенту будут отправляться только небольшие фрагменты JavaScript приложения, а затем обрабатываться. Мы можем думать об этом как о нескольких крошечных приложениях React с несколькими корнями рендеринга на статичном веб-сайте.В статье «Случай частичной гидратации (с Next и Preact)» Лукас Бомбах объясняет, как команда Welt.de, одного из новостных агентств в Германии, добилась лучших результатов при частичной гидратации. Вы также можете проверить репозиторий следующего сверхпроизводительного GitHub с пояснениями и фрагментами кода.
Также можно рассмотреть альтернативные варианты:
- частичное увлажнение Preact и Eleventy,
- прогрессивная гидратация в репозитории React GitHub,
- ленивая гидратация в Vue.js (репозиторий GitHub),
- Импорт шаблона взаимодействия для ленивой загрузки некритических ресурсов (например, компонентов, встраивания), когда пользователь взаимодействует с пользовательским интерфейсом, которому это необходимо.
Джейсон Миллер опубликовал рабочие демонстрации о том, как можно реализовать прогрессивную гидратацию с помощью React, так что вы можете сразу их использовать: демонстрация 1, демонстрация 2, демонстрация 3 (также доступны на GitHub). Кроме того, вы можете заглянуть в библиотеку react-prerendered-component.
Импорт при взаимодействии для собственного кода следует выполнять только в том случае, если вы не можете выполнить предварительную выборку ресурсов до взаимодействия. (Большой превью) - Оптимизировали ли мы стратегию для React/SPA?
Боретесь с производительностью в своем одностраничном приложении? Джереми Вагнер исследовал влияние производительности фреймворка на стороне клиента на различных устройствах, выделив некоторые последствия и рекомендации, о которых мы, возможно, хотели бы знать при их использовании.В результате вот стратегия SPA, которую Джереми предлагает использовать для платформы React (но она не должна существенно измениться для других платформ):
- Рефакторинг компонентов с состоянием как компонентов без состояния, когда это возможно.
- По возможности выполняйте предварительную визуализацию компонентов без состояния, чтобы свести к минимуму время отклика сервера. Рендерить только на сервере.
- Для компонентов с отслеживанием состояния с простой интерактивностью рассмотрите возможность предварительного рендеринга или серверного рендеринга этого компонента и замените его интерактивность независимыми от фреймворка обработчиками событий .
- Если вам необходимо гидратировать компоненты с отслеживанием состояния на клиенте, используйте ленивую гидратацию для видимости или взаимодействия.
- Для компонентов с ленивой гидратацией запланируйте их гидратацию во время простоя основного потока с помощью
requestIdleCallback.
Есть несколько других стратегий, которые вы, возможно, захотите применить или пересмотреть:
- Вопросы производительности для CSS-in-JS в приложениях React
- Уменьшите размер пакета Next.js, загружая полифиллы только при необходимости, используя динамический импорт и ленивую гидратацию.
- Секреты JavaScript: рассказ о React, оптимизации производительности и многопоточности, длинная серия из 7 статей, посвященная решению проблем пользовательского интерфейса с помощью React,
- Как измерить производительность React и как профилировать приложения React.
- Создание мобильной веб-анимации в React, фантастическое выступление Алекса Холачека, а также слайды и репозиторий GitHub ( спасибо за совет, Эдди! ).
- webpack-libs-optimizations — фантастическое репозиторий GitHub с множеством полезных оптимизаций, связанных с производительностью Webpack. Поддерживает Иван Акулов.
- Улучшения производительности React в Notion, руководство Ивана Акулова о том, как повысить производительность в React, с множеством полезных советов, которые сделают приложение примерно на 30% быстрее.
- Плагин React Refresh Webpack (экспериментальный) обеспечивает горячую перезагрузку, которая сохраняет состояние компонента, а также поддерживает хуки и функциональные компоненты.
- Остерегайтесь компонентов React Server с нулевым размером пакета — нового предлагаемого типа компонентов, который не повлияет на размер пакета. В настоящее время проект находится в разработке, но мы очень ценим любые отзывы сообщества (прекрасное объяснение от Софи Альперт).
- Используете ли вы прогнозную предварительную выборку для фрагментов JavaScript?
Мы могли бы использовать эвристику, чтобы решить, когда предварительно загружать куски JavaScript. Guess.js — это набор инструментов и библиотек, которые используют данные Google Analytics для определения того, какую страницу пользователь, скорее всего, посетит следующей с данной страницы. На основе шаблонов пользовательской навигации, собранных из Google Analytics или других источников, Guess.js строит модель машинного обучения для прогнозирования и предварительной выборки JavaScript, который потребуется на каждой последующей странице.Таким образом, каждый интерактивный элемент получает оценку вероятности вовлечения, и на основе этой оценки клиентский сценарий решает заблаговременно получить ресурс. Вы можете интегрировать эту технику в свое приложение Next.js, Angular и React, и есть плагин Webpack, который также автоматизирует процесс установки.
Очевидно, что вы можете подтолкнуть браузер к потреблению ненужных данных и предварительной выборке нежелательных страниц, поэтому рекомендуется быть достаточно консервативным в отношении количества предварительно выбранных запросов. Хорошим вариантом использования будет предварительная выборка сценариев проверки, необходимых при оформлении заказа, или спекулятивная предварительная выборка, когда критический призыв к действию появляется в области просмотра.
Нужно что-то менее сложное? DNStradamus выполняет предварительную выборку DNS для исходящих ссылок по мере их появления в окне просмотра. Quicklink, InstantClick и Instant.page — это небольшие библиотеки, которые автоматически выполняют предварительную выборку ссылок в области просмотра во время простоя, пытаясь ускорить загрузку навигации на следующей странице. Quicklink позволяет предварительно загружать маршруты React Router и Javascript; кроме того, он учитывает данные, поэтому он не выполняет предварительную выборку в 2G или если
Data-Saver. Так же, как и Instant.page, если режим настроен на использование предварительной выборки области просмотра (по умолчанию).Если вы хотите подробно изучить науку прогнозной предварительной выборки, у Дивьи Тагтачян есть отличный доклад «Искусство прогнозной предварительной выборки», в котором рассматриваются все варианты от начала до конца.
- Воспользуйтесь оптимизацией для вашего целевого движка JavaScript.
Изучите, какие движки JavaScript доминируют в вашей пользовательской базе, а затем изучите способы их оптимизации. Например, при оптимизации для V8, который используется в браузерах Blink, среде выполнения Node.js и Electron, используйте потоковую передачу скриптов для монолитных скриптов.Потоковая передача сценариев позволяет анализировать
asyncилиdefer scriptsв отдельном фоновом потоке после начала загрузки, поэтому в некоторых случаях время загрузки страницы сокращается до 10%. Practically, use<script defer>in the<head>, so that the browsers can discover the resource early and then parse it on the background thread.Caveat : Opera Mini doesn't support script deferment, so if you are developing for India or Africa,
deferwill be ignored, resulting in blocking rendering until the script has been evaluated (thanks Jeremy!) .You could also hook into V8's code caching as well, by splitting out libraries from code using them, or the other way around, merge libraries and their uses into a single script, group small files together and avoid inline scripts. Or perhaps even use v8-compile-cache.
When it comes to JavaScript in general, there are also some practices that are worth keeping in mind:
- Clean Code concepts for JavaScript, a large collection of patterns for writing readable, reusable, and refactorable code.
- You can Compress data from JavaScript with the CompressionStream API, eg to gzip before uploading data (Chrome 80+).
- Detached window memory leaks and Fixing memory leaks in web apps are detailed guides on how to find and fix tricky JavaScript memory leaks. Plus, you can use queryObjects(SomeConstructor) from the DevTools Console ( thanks, Mathias! ).
- Reexports are bad for loading and runtime performance, and avoiding them can help reduce the bundle size significantly.
- We can improve scroll performance with passive event listeners by setting a flag in the
optionsparameter. So browsers can scroll the page immediately, rather than after the listener has finished. (via Kayce Basques). - If you have any
scrollortouch*listeners, passpassive: trueto addEventListener. This tells the browser you're not planning to callevent.preventDefault()inside, so it can optimize the way it handles these events. (via Ivan Akulov) - We can achieve better JavaScript scheduling with isInputPending(), a new API that attempts to bridge the gap between loading and responsiveness with the concepts of interrupts for user inputs on the web, and allows for JavaScript to be able to check for input without yielding to the browser.
- You can also automatically remove an event listener after it has executed.
- Firefox's recently released Warp, a significant update to SpiderMonkey (shipped in Firefox 83), Baseline Interpreter and there are a few JIT Optimization Strategies available as well.
- Always prefer to self-host third-party assets.
Yet again, self-host your static assets by default. It's common to assume that if many sites use the same public CDN and the same version of a JavaScript library or a web font, then the visitors would land on our site with the scripts and fonts already cached in their browser, speeding up their experience considerably. However, it's very unlikely to happen.For security reasons, to avoid fingerprinting, browsers have been implementing partitioned caching that was introduced in Safari back in 2013, and in Chrome last year. So if two sites point to the exact same third-party resource URL, the code is downloaded once per domain , and the cache is "sandboxed" to that domain due to privacy implications ( thanks, David Calhoun! ). Hence, using a public CDN will not automatically lead to better performance.
Furthermore, it's worth noting that resources don't live in the browser's cache as long as we might expect, and first-party assets are more likely to stay in the cache than third-party assets. Therefore, self-hosting is usually more reliable and secure, and better for performance, too.
- Constrain the impact of third-party scripts.
With all performance optimizations in place, often we can't control third-party scripts coming from business requirements. Third-party-scripts metrics aren't influenced by end-user experience, so too often one single script ends up calling a long tail of obnoxious third-party scripts, hence ruining a dedicated performance effort. To contain and mitigate performance penalties that these scripts bring along, it's not enough to just defer their loading and execution and warm up connections via resource hints, iedns-prefetchorpreconnect.Currently 57% of all JavaScript code excution time is spent on third-party code. The median mobile site accesses 12 third-party domains , with a median of 37 different requests (or about 3 requests made to each third party).
Furthermore, these third-parties often invite fourth-party scripts to join in, ending up with a huge performance bottleneck, sometimes going as far as to the eigth-party scripts on a page. So regularly auditing your dependencies and tag managers can bring along costly surprises.
Another problem, as Yoav Weiss explained in his talk on third-party scripts, is that in many cases these scripts download resources that are dynamic. The resources change between page loads, so we don't necessarily know which hosts the resources will be downloaded from and what resources they would be.
Deferring, as shown above, might be just a start though as third-party scripts also steal bandwidth and CPU time from your app. We could be a bit more aggressive and load them only when our app has initialized.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }In a fantastic post on "Reducing the Site-Speed Impact of Third-Party Tags", Andy Davies explores a strategy of minimizing the footprint of third-parties — from identifying their costs towards reducing their impact.
According to Andy, there are two ways tags impact site-speed — they compete for network bandwidth and processing time on visitors' devices, and depending on how they're implemented, they can delay HTML parsing as well. So the first step is to identify the impact that third-parties have, by testing the site with and without scripts using WebPageTest. With Simon Hearne's Request Map, we can also visualize third-parties on a page along with details on their size, type and what triggered their load.
Preferably self-host and use a single hostname, but also use a request map to exposes fourth-party calls and detect when the scripts change. You can use Harry Roberts' approach for auditing third parties and produce spreadsheets like this one (also check Harry's auditing workflow).
Afterwards, we can explore lightweight alternatives to existing scripts and slowly replace duplicates and main culprits with lighter options. Perhaps some of the scripts could be replaced with their fallback tracking pixel instead of the full tag.

Loading YouTube with facades, eg lite-youtube-embed that's significantly smaller than an actual YouTube player. (Источник изображения) (Большой предварительный просмотр) If it's not viable, we can at least lazy load third-party resources with facades, ie a static element which looks similar to the actual embedded third-party, but is not functional and therefore much less taxing on the page load. The trick, then, is to load the actual embed only on interaction .
For example, we can use:
- lite-vimeo-embed for the Vimeo player,
- lite-vimeo for the Vimeo player,
- lite-youtube-embed for the YouTube player,
- react-live-chat-loader for a live chat (case study, and another case-study),
- lazyframe for iframes.
One of the reasons why tag managers are usually large in size is because of the many simultaneous experiments that are running at the same time, along with many user segments, page URLs, sites etc., so according to Andy, reducing them can reduce both the download size and the time it takes to execute the script in the browser.
And then there are anti-flicker snippets. Third-parties such as Google Optimize, Visual Web Optimizer (VWO) and others are unanimous in using them. These snippets are usually injected along with running A/B tests : to avoid flickering between the different test scenarios, they hide the
bodyof the document withopacity: 0, then adds a function that gets called after a few seconds to bring theopacityback. This often results in massive delays in rendering due to massive client-side execution costs.
With A/B testing in use, customers would often see flickering like this one. Anti-Flicker snippets prevent that, but they also cost in performance. Via Andy Davies. (Большой превью) Therefore keep track how often the anti-flicker timeout is triggered and reduce the timeout. Default blocks display of your page by up to 4s which will ruin conversion rates. According to Tim Kadlec, "Friends don't let friends do client side A/B testing". Server-side A/B testing on CDNs (eg Edge Computing, or Edge Slice Rerendering) is always a more performant option.
If you have to deal with almighty Google Tag Manager , Barry Pollard provides some guidelines to contain the impact of Google Tag Manager. Also, Christian Schaefer explores strategies for loading ads.
Будьте осторожны: некоторые сторонние виджеты скрывают себя от инструментов аудита, поэтому их может быть сложнее обнаружить и измерить. Чтобы провести стресс-тестирование третьих сторон, изучите сводные данные снизу вверх на странице профиля производительности в DevTools, проверьте, что произойдет, если запрос заблокирован или истекло время ожидания — для последнего вы можете использовать сервер
blackhole.webpagetest.orgBlackhole blackhole.webpagetest.org, который вы может указать определенные домены в вашем файлеhosts.Какие у нас тогда есть варианты? Рассмотрите возможность использования сервис-воркеров, ускорив загрузку ресурса с тайм -аутом, и если ресурс не ответил в течение определенного тайм-аута, верните пустой ответ, чтобы указать браузеру продолжить анализ страницы. Вы также можете регистрировать или блокировать сторонние запросы, которые не были успешными или не соответствуют определенным критериям. Если вы можете, загрузите сторонний скрипт со своего собственного сервера, а не с сервера поставщика, и лениво загрузите их.
Другой вариант — установить политику безопасности содержимого (CSP) , чтобы ограничить влияние сторонних сценариев, например запретить загрузку аудио или видео. Лучший вариант — встроить скрипты через
<iframe>, чтобы скрипты работали в контексте iframe и, следовательно, не имели доступа к DOM страницы и не могли запускать произвольный код в вашем домене. Интерактивные фреймы могут быть дополнительно ограничены с помощью атрибутаsandbox, поэтому вы можете отключить любую функциональность, которую может выполнять фреймворк, например, запретить выполнение сценариев, запретить оповещения, отправку форм, плагины, доступ к верхней навигации и т. д.Вы также можете держать третьих лиц под контролем с помощью анализа производительности в браузере с помощью политик функций, относительно новой функции, которая позволяет вам
включение или отключение определенных функций браузера на вашем сайте. (Кроме того, его также можно использовать, чтобы избежать слишком больших и неоптимизированных изображений, неразмерных медиафайлов, сценариев синхронизации и прочего). В настоящее время поддерживается в браузерах на основе Blink. /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'Поскольку многие сторонние скрипты работают в iframe, вам, вероятно, придется тщательно ограничивать их допуски. Песочница iframe — это всегда хорошая идея, и каждое из ограничений можно снять с помощью ряда
allowзначений атрибутаsandbox. Песочница поддерживается почти везде, поэтому ограничивайте сторонние скрипты до минимума того, что им разрешено делать.
ThirdPartyWeb.Today группирует все сторонние скрипты по категориям (аналитика, социальные сети, реклама, хостинг, менеджер тегов и т. д.) и визуализирует, сколько времени занимает выполнение скриптов объекта (в среднем). (Большой превью) Рассмотрите возможность использования Intersection Observer; это позволило бы размещать рекламу в iframe , при этом отправляя события или получая необходимую информацию из DOM (например, видимость рекламы). Следите за новыми политиками, такими как политика функций, ограничения на размер ресурсов и приоритет ЦП/пропускной способности, чтобы ограничить вредоносные веб-функции и сценарии, которые замедляют работу браузера, например синхронные сценарии, синхронные запросы XHR, document.write и устаревшие реализации.
Наконец, при выборе стороннего сервиса рассмотрите возможность проверки ThirdPartyWeb.Today Патрика Халса, сервиса, который группирует все сторонние скрипты по категориям (аналитика, социальные сети, реклама, хостинг, менеджер тегов и т. д.) и визуализирует, как долго скрипты объекта взять на выполнение (в среднем). Очевидно, что самые крупные объекты оказывают наихудшее влияние на производительность страниц, на которых они находятся. Просто пробежав страницу, вы получите представление о ожидаемой производительности.
Ах, и не забывайте об обычных подозреваемых: вместо сторонних виджетов для обмена мы можем использовать статические кнопки обмена в социальных сетях (например, SSBG) и статические ссылки на интерактивные карты вместо интерактивных карт.
- Правильно установите заголовки кэша HTTP.
Кэширование кажется такой очевидной вещью, но это может быть довольно сложно сделать правильно. Нам нужно перепроверить, чтоexpires,max-age,cache-controlи другие заголовки кэша HTTP были установлены правильно. Без надлежащих заголовков кеша HTTP браузеры автоматически установят их на 10% от времени, прошедшего с моментаlast-modified, что приведет к потенциальному недостаточному или избыточному кэшированию.В общем, ресурсы должны кэшироваться либо на очень короткое время (если они могут измениться), либо на неопределенное время (если они статичны) — вы можете просто изменить их версию в URL-адресе, когда это необходимо. Вы можете назвать это стратегией Cache-Forever, в которой мы могли бы передавать заголовки
Cache-ControlиExpiresв браузер, чтобы срок действия активов истекал только через год. Следовательно, браузер даже не будет запрашивать актив, если он есть в кеше.Исключение составляют ответы API (например,
/api/user). Чтобы предотвратить кеширование, мы можем использоватьprivate, no store, а неmax-age=0, no-store:Cache-Control: private, no-storeИспользуйте
Cache-control: immutable, чтобы избежать повторной проверки длинных явных сроков жизни кеша, когда пользователи нажимают кнопку перезагрузки. В случае перезагрузкиimmutableсохраняет HTTP-запросы и сокращает время загрузки динамического HTML, поскольку они больше не конкурируют с множеством ответов 304.Типичным примером, где мы хотим использовать
immutable, являются активы CSS/JavaScript с хешем в имени. Для них мы, вероятно, хотим кэшировать как можно дольше и гарантировать, что они никогда не будут повторно проверены:Cache-Control: max-age: 31556952, immutableСогласно исследованию Колина Бенделла,
immutableсокращает количество переадресаций 304 примерно на 50%, поскольку даже при использованииmax-ageклиенты все равно повторно проверяют и блокируют при обновлении. Он поддерживается в Firefox, Edge и Safari, и Chrome все еще обсуждает этот вопрос.Согласно Web Almanac, «его использование выросло до 3,5%, и оно широко используется в сторонних ответах Facebook и Google».

Cache-Control: Immutable уменьшает количество ошибок 304 примерно на 50 %, согласно исследованию Колина Бенделла в Cloudinary. (Большой превью) Вы помните старую добрую устаревшую версию? Когда мы указываем время кэширования в заголовке ответа
Cache-Control(напримерCache-Control: max-age=604800), после истечения срока действияmax-ageбраузер повторно извлекает запрошенный контент, что приводит к замедлению загрузки страницы. Этого замедления можно избежать с помощьюstale-while-revalidate; по сути, он определяет дополнительное окно времени, в течение которого кеш может использовать устаревший ресурс, пока он проверяет его асинхронно в фоновом режиме. Таким образом он «скрывает» латентность (как в сети, так и на сервере) от клиентов.В июне-июле 2019 года Chrome и Firefox запустили поддержку
stale-while-revalidateв заголовке HTTP Cache-Control, поэтому в результате это должно уменьшить последующие задержки загрузки страницы, поскольку устаревшие ресурсы больше не находятся на критическом пути. Результат: нулевой RTT для повторных просмотров.С осторожностью относитесь к заголовку вариации, особенно в отношении сетей CDN, и следите за вариантами представления HTTP, которые помогают избежать дополнительного кругового пути для проверки всякий раз, когда новый запрос немного (но не значительно) отличается от предыдущих запросов ( спасибо, Гай и Марк ! ).
Кроме того, дважды проверьте, что вы не отправляете ненужные заголовки (например
x-powered-by,pragma,x-ua-compatible,expires,X-XSS-Protectionи другие) и что вы включаете полезные заголовки безопасности и производительности (такие как какContent-Security-Policy,X-Content-Type-Optionsи другие). Наконец, не забывайте о снижении производительности запросов CORS в одностраничных приложениях.Примечание . Мы часто предполагаем, что кешированные ресурсы извлекаются мгновенно, но исследования показывают, что извлечение объекта из кеша может занять сотни миллисекунд. На самом деле, по словам Саймона Херна, «иногда сеть может быть быстрее, чем кеш, а извлечение ресурсов из кеша может быть дорогостоящим из-за большого количества кэшированных ресурсов (не размера файла) и устройств пользователя. Например: среднее извлечение из кеша Chrome OS удваивается с ~ 50 мс с 5 кэшированными ресурсами до ~ 100 мс с 25 ресурсами».
Кроме того, мы часто предполагаем, что размер пакета не является большой проблемой, и пользователи скачают его один раз, а затем будут использовать кешированную версию. В то же время, с CI/CD мы запускаем код в производство несколько раз в день, кеш каждый раз становится недействительным, поэтому кеширование имеет стратегическое значение.
Что касается кэширования, есть много ресурсов, которые стоит прочитать:
- Cache-Control for Civilians, подробное изучение всего кэширования с Гарри Робертсом.
- Учебник Heroku по заголовкам кэширования HTTP,
- Рекомендации по кэшированию, Джейк Арчибальд,
- Учебник по HTTP-кешированию Ильи Григорика,
- Сохраняйте актуальность с помощью функции «устаревшие при повторной проверке» от Джеффа Посника.
- CS Visualized: CORS Лидии Холли — отличное объяснение CORS, того, как он работает и как его понять.
- Говоря о CORS, вот небольшой обзор Политики одинакового происхождения от Эрика Портиса.
Оптимизация доставки
- Используем ли мы
deferдля асинхронной загрузки критического JavaScript?
Когда пользователь запрашивает страницу, браузер извлекает HTML и создает DOM, затем извлекает CSS и создает CSSOM, а затем создает дерево рендеринга, сопоставляя DOM и CSSOM. Если необходимо разрешить какой-либо JavaScript, браузер не начнет отображать страницу до тех пор, пока он не будет разрешен, что приведет к задержке отображения. Как разработчики, мы должны явно указать браузеру не ждать и начать рендеринг страницы. Для скриптов это можно сделать с помощью атрибутовdeferиasyncв HTML.На практике оказывается, что лучше использовать
deferвместоasync. Ах, какая опять разница ? По словам Стива Содерса, как только приходятasyncскрипты, они сразу же выполняются — как только скрипт готов. Если это происходит очень быстро, например, когда скрипт уже находится в кеше, он может фактически заблокировать анализатор HTML. Сdeferбраузер не выполняет скрипты до тех пор, пока не будет проанализирован HTML. Итак, если вам не нужно, чтобы JavaScript выполнялся перед началом рендеринга, лучше использоватьdefer. Кроме того, несколько асинхронных файлов будут выполняться в недетерминированном порядке.Стоит отметить, что существует несколько неправильных представлений об
asyncиdefer. Самое главное,asyncне означает, что код будет выполняться всякий раз, когда сценарий готов; это означает, что он будет запускаться всякий раз, когда сценарии будут готовы и будет выполнена вся предыдущая работа по синхронизации. По словам Гарри Робертса, «если вы поместитеasyncсценарий после сценариев синхронизации, вашasyncсценарий будет настолько же быстрым, как и ваш самый медленный сценарий синхронизации».Кроме того, не рекомендуется использовать одновременно
asyncиdefer. Современные браузеры поддерживают оба атрибута, но всякий раз, когда используются оба атрибута,asyncвсегда будет побеждать.Если вы хотите углубиться в детали, Милица Михайлия написала очень подробное руководство по ускоренному построению DOM, в котором подробно рассматриваются спекулятивный анализ, асинхронность и отложенное выполнение.
- Ленивая загрузка дорогих компонентов с IntersectionObserver и подсказками приоритета.
В общем, рекомендуется лениво загружать все дорогостоящие компоненты, такие как тяжелый JavaScript, видео, фреймы, виджеты и, возможно, изображения. Нативная отложенная загрузка уже доступна для изображений и фреймов с атрибутомloading(только Chromium). Под капотом этот атрибут откладывает загрузку ресурса до тех пор, пока он не достигнет расчетного расстояния от области просмотра.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Этот порог зависит от нескольких вещей, от типа загружаемого ресурса изображения до эффективного типа соединения. Но эксперименты, проведенные с использованием Chrome на Android, показывают, что в 4G 97,5% изображений ниже сгиба, загружаемых отложенно, были полностью загружены в течение 10 мс после того, как стали видимыми, поэтому это должно быть безопасно.
Мы также можем использовать атрибут
importance(highилиlow) для элемента<script>,<img>или<link>(только для Blink). На самом деле, это отличный способ снизить приоритет изображений в каруселях, а также изменить приоритет сценариев. Однако иногда нам может понадобиться немного более детальный контроль.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />Самый эффективный способ сделать несколько более сложную ленивую загрузку — использовать Intersection Observer API, который позволяет асинхронно отслеживать изменения в пересечении целевого элемента с элементом-предком или с окном просмотра документа верхнего уровня. По сути, вам нужно создать новый объект
IntersectionObserver, который получает функцию обратного вызова и набор параметров. Затем мы добавляем цель для наблюдения.Функция обратного вызова выполняется, когда цель становится видимой или невидимой, поэтому, когда она перехватывает область просмотра, вы можете начать выполнять некоторые действия до того, как элемент станет видимым. На самом деле, у нас есть детальный контроль над тем, когда должен вызываться обратный вызов наблюдателя, с
rootMargin(поле вокруг корня) иthreshold(одно число или массив чисел, которые указывают, на какой процент видимости цели мы нацелены).Алехандро Гарсия Англада опубликовал удобный учебник о том, как это реализовать на самом деле, Рахул Нанвани написал подробный пост о ленивой загрузке изображений переднего плана и фона, а Google Fundamentals также предоставил подробный учебник по ленивой загрузке изображений и видео с помощью Intersection Observer.
Помните художественные лонгриды с движущимися и липкими объектами? С помощью Intersection Observer также можно реализовать эффективное прокручивание.
Проверьте еще раз, что еще вы могли бы лениво загрузить. Даже ленивая загрузка строк перевода и эмодзи может помочь. Таким образом, Mobile Twitter удалось добиться ускорения выполнения JavaScript на 80 % благодаря новому конвейеру интернационализации.
Небольшое предостережение: стоит отметить, что отложенная загрузка должна быть скорее исключением, чем правилом. Вероятно, нецелесообразно лениво загружать все, что вы действительно хотите, чтобы люди увидели быстро, например, изображения страниц продукта, основные изображения или скрипт, необходимый для того, чтобы основная навигация стала интерактивной.

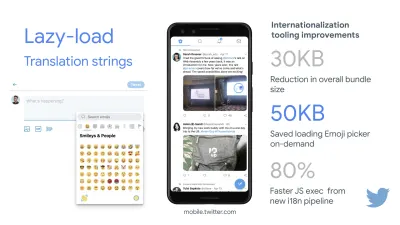
- Загружайте изображения постепенно.
Вы даже можете поднять ленивую загрузку на новый уровень, добавив прогрессивную загрузку изображений на свои страницы. Как и в Facebook, Pinterest, Medium и Wolt, вы можете сначала загрузить низкокачественные или даже размытые изображения, а затем, когда страница продолжает загружаться, заменить их полноценными версиями с помощью технологии BlurHash или LQIP (заполнители изображений низкого качества). техника.Мнения расходятся, улучшают ли эти методы взаимодействие с пользователем или нет, но они определенно сокращают время до первой отрисовки контента. Мы даже можем автоматизировать его, используя SQIP, который создает низкокачественную версию изображения в качестве заполнителя SVG, или заполнители Gradient Image Placeholders с линейными градиентами CSS.
Эти заполнители могут быть встроены в HTML, поскольку они естественным образом хорошо сжимаются методами сжатия текста. В своей статье Дин Хьюм описал, как эту технику можно реализовать с помощью Intersection Observer.
Отступать? Если браузер не поддерживает наблюдатель пересечений, мы все равно можем отложенно загрузить полифилл или сразу загрузить изображения. И для этого есть даже библиотека.
Хотите пофантазировать? Вы можете отслеживать свои изображения и использовать примитивные формы и края для создания легкого заполнителя SVG, сначала загрузить его, а затем перейти от векторного изображения заполнителя к (загруженному) растровому изображению.
- Вы откладываете рендеринг с помощью
content-visibility?
Для сложного макета с большим количеством блоков контента, изображений и видео декодирование данных и рендеринг пикселей может быть довольно дорогостоящей операцией, особенно на недорогих устройствах. С помощьюcontent-visibility: autoмы можем предложить браузеру пропустить макет дочерних элементов, пока контейнер находится за пределами области просмотра.Например, вы можете пропустить рендеринг нижнего колонтитула и поздних разделов при начальной загрузке:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Обратите внимание, что content-visibility: auto; ведет себя как переполнение: скрыто; , но вы можете исправить это, применив
padding-leftиpadding-rightвместо значения по умолчаниюmargin-left: auto;,margin-right: auto;и заявленная ширина. Заполнение в основном позволяет элементам переполнять блок содержимого и входить в блок заполнения, не выходя из модели блока в целом и не обрезаясь.Кроме того, имейте в виду, что вы можете ввести некоторые CLS, когда новый контент в конечном итоге будет отображаться, поэтому рекомендуется использовать
contain-intrinsic-sizeс заполнителем правильного размера ( спасибо, Уна! ).У Thijs Terluin есть гораздо больше подробностей об обоих свойствах и о том, как браузер вычисляет вложенный
contain-intrinsic-sizeсодержимого, Malte Ubl показывает, как вы можете его вычислить, а краткое пояснение Джейка и Сурма объясняет, как все это работает.И если вам нужно получить немного больше детализации, с помощью CSS Containment вы можете вручную пропустить макет, стиль и работу по рисованию для потомков узла DOM, если вам нужен только размер, выравнивание или вычисленные стили для других элементов — или элемент в настоящее время вне холста.


content-visibility: auto к фрагментированным областям контента дает 7-кратный прирост производительности рендеринга при начальной загрузке. (Большой превью)- Вы откладываете декодирование с помощью
decoding="async"?
Иногда контент появляется за кадром, но мы хотим быть уверены, что он доступен, когда он нужен клиентам — в идеале, ничего не блокируя на критическом пути, а декодируя и отображая асинхронно. Мы можем использоватьdecoding="async", чтобы дать браузеру разрешение на декодирование изображения вне основного потока, избегая воздействия на пользователя процессорного времени, используемого для декодирования изображения (через Malte Ubl):<img decoding="async" … />В качестве альтернативы, для закадровых изображений мы можем сначала отобразить заполнитель, а когда изображение находится в области просмотра, используя IntersectionObserver, инициировать сетевой вызов для загрузки изображения в фоновом режиме. Кроме того, мы можем отложить рендеринг до декодирования с помощью img.decode() или загрузить изображение, если API декодирования изображений недоступен.
Например, при рендеринге изображения мы можем использовать плавную анимацию. Кэти Хемпениус и Эдди Османи поделились своими мыслями в своем выступлении «Скорость в масштабе: советы и хитрости веб-производительности из окопов».
- Вы создаете и обслуживаете критический CSS?
Чтобы гарантировать, что браузеры начнут отображать вашу страницу как можно быстрее, стало обычной практикой собирать весь CSS, необходимый для начала отображения первой видимой части страницы (известный как «критический CSS» или «CSS верхней части страницы»). ") и включить его в<head>страницы, тем самым уменьшив круговые обращения. Из-за ограниченного размера пакетов, которыми обмениваются на этапе медленного старта, ваш бюджет на критический CSS составляет около 14 КБ.Если вы пойдете дальше этого, браузеру потребуются дополнительные обращения, чтобы получить больше стилей. CriticalCSS и Critical позволяют выводить критический CSS для каждого используемого вами шаблона. Однако, по нашему опыту, никакая автоматическая система не была лучше, чем ручной сбор критически важных CSS для каждого шаблона, и действительно, это подход, к которому мы недавно вернулись.
Затем вы можете встроить критический CSS и лениво загрузить остальные с помощью плагина critters Webpack. Если возможно, рассмотрите возможность использования подхода условного встраивания, используемого Filament Group, или преобразуйте встроенный код в статические ресурсы на лету.
Если вы в настоящее время загружаете свой полный CSS асинхронно с такими библиотеками, как loadCSS, в этом нет необходимости. С помощью
media="print"вы можете заставить браузер асинхронно извлекать CSS, но применять его к среде экрана после его загрузки. ( спасибо, Скотт! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />При сборе всех важных CSS-файлов для каждого шаблона обычно исследуют только верхнюю часть страницы. Тем не менее, для сложных макетов может быть хорошей идеей включить основу макета, чтобы избежать огромных затрат на пересчет и перерисовку, что в результате повредит вашей оценке Core Web Vitals.
Что делать, если пользователь получает URL-адрес, ведущий прямо в середину страницы, но CSS еще не загружен? В этом случае стало обычным скрывать некритическое содержимое, например, с помощью
opacity: 0;во встроенном CSS иopacity: 1в полном файле CSS и отображать его, когда CSS доступен. Однако у него есть серьезный недостаток , поскольку пользователи с медленным соединением могут никогда не прочитать содержимое страницы. Вот почему лучше всегда держать содержимое видимым, даже если оно может быть оформлено неправильно.Помещение критического CSS (и других важных ресурсов) в отдельный файл в корневом домене имеет преимущества, иногда даже больше, чем встраивание, благодаря кэшированию. Chrome спекулятивно открывает второе HTTP-соединение с корневым доменом при запросе страницы, что устраняет необходимость в TCP-соединении для получения этого CSS. Это означает, что вы можете создать набор важных -CSS-файлов (например, crypto -homepage.css , crypto-product-page.css и т. д.) и обслуживать их из своего корня без необходимости встраивания. ( спасибо, Филипп! )
Небольшое предостережение: при использовании HTTP/2 важные CSS-коды можно хранить в отдельном CSS-файле и доставлять через сервер, не раздувая HTML-код. Загвоздка в том, что отправка на сервер была проблематичной из-за множества подводных камней и условий гонки в разных браузерах. Он никогда не поддерживался последовательно и имел некоторые проблемы с кэшированием (см. слайд 114 презентации Hooman Beheshti и далее).
На самом деле эффект может быть отрицательным и привести к раздуванию сетевых буферов, препятствуя доставке подлинных кадров в документе. Поэтому неудивительно, что на данный момент Chrome планирует отказаться от поддержки Server Push.
- Поэкспериментируйте с перегруппировкой правил CSS.
Мы привыкли к критическому CSS, но есть несколько оптимизаций, которые могли бы выйти за рамки этого. Гарри Робертс провел замечательное исследование с довольно неожиданными результатами. Например, было бы неплохо разделить основной файл CSS на отдельные медиа-запросы. Таким образом, браузер будет извлекать критический CSS с высоким приоритетом, а все остальное с низким приоритетом — полностью вне критического пути.Кроме того, избегайте размещения
<link rel="stylesheet" />передasyncфрагментами. Если скрипты не зависят от таблиц стилей, рассмотрите возможность размещения блокирующих скриптов над блокирующими стилями. Если они это сделают, разделите этот JavaScript на две части и загрузите его по обе стороны от вашего CSS.Скотт Джел решил еще одну интересную проблему, кэшировав встроенный файл CSS с помощью сервис-воркера, — обычная проблема, знакомая тем, кто использует критически важный CSS. По сути, мы добавляем атрибут ID к элементу
style, чтобы его было легко найти с помощью JavaScript, затем небольшой фрагмент JavaScript находит этот CSS и использует Cache API для его сохранения в локальном кеше браузера (с типом содержимогоtext/css) для использования на последующих страницах. Чтобы избежать встраивания на последующих страницах и вместо этого ссылаться на кэшированные ресурсы извне, мы затем устанавливаем файл cookie при первом посещении сайта. Вуаля!Стоит отметить, что динамические стили тоже могут быть дорогими, но обычно только в тех случаях, когда вы полагаетесь на сотни одновременно отображаемых составных компонентов. Поэтому, если вы используете CSS-in-JS, убедитесь, что ваша библиотека CSS-in-JS оптимизирует выполнение, когда ваш CSS не зависит от темы или свойств, и не перекомпоновывайте стилизованные компоненты . Аггелос Арванитакис делится подробностями о затратах производительности на CSS-in-JS.
- Вы транслируете ответы?
Часто забываемые и игнорируемые потоки предоставляют интерфейс для чтения или записи асинхронных фрагментов данных, только часть которых может быть доступна в памяти в любой момент времени. По сути, они позволяют странице, отправившей первоначальный запрос, начать работу с ответом, как только станет доступен первый фрагмент данных, и используют синтаксические анализаторы, оптимизированные для потоковой передачи, для постепенного отображения контента.Мы могли бы создать один поток из нескольких источников. Например, вместо того, чтобы обслуживать пустую оболочку пользовательского интерфейса и позволять JavaScript заполнять ее, вы можете позволить сервис-воркеру создать поток, в котором оболочка поступает из кеша, а тело — из сети. Как заметил Джефф Посник, если ваше веб-приложение работает на базе CMS, которая отображает HTML-код на сервере путем сшивания частичных шаблонов, эта модель напрямую преобразуется в использование потоковых ответов, а логика шаблонов копируется в сервис-воркере, а не на вашем сервере. В статье Джейка Арчибальда «Год веб-потоков» рассказывается, как именно вы можете их построить. Прирост производительности весьма заметен.
Одним из важных преимуществ потоковой передачи всего HTML-ответа является то, что HTML-код, отображаемый во время начального запроса навигации, может в полной мере использовать преимущества потокового синтаксического анализатора HTML браузера. Фрагменты HTML, которые вставляются в документ после загрузки страницы (как это часто бывает с контентом, заполняемым с помощью JavaScript), не могут использовать преимущества этой оптимизации.
Поддержка браузера? По-прежнему достигается частичная поддержка в Chrome, Firefox, Safari и Edge с поддержкой API и Service Workers, которые поддерживаются во всех современных браузерах. И если вы снова чувствуете себя предприимчивым, вы можете проверить экспериментальную реализацию потоковых запросов, которая позволяет вам начать отправку запроса, продолжая генерировать тело. Доступно в Chrome 85.
- Подумайте о том, чтобы ваши компоненты знали о подключении.
Данные могут быть дорогими, и с ростом полезной нагрузки мы должны уважать пользователей, которые выбирают экономию данных при доступе к нашим сайтам или приложениям. Заголовок запроса подсказки клиента Save-Data позволяет нам настроить приложение и полезную нагрузку для пользователей с ограниченными затратами и производительностью.Фактически, вы можете переписать запросы для изображений с высоким DPI на изображения с низким DPI, удалить веб-шрифты, причудливые эффекты параллакса, миниатюры предварительного просмотра и бесконечную прокрутку, отключить автовоспроизведение видео, отправку сервером, уменьшить количество отображаемых элементов и понизить качество изображения или даже изменить способ доставки разметки. Тим Верике опубликовал очень подробную статью о стратегиях экономии данных, в которой представлено множество вариантов сохранения данных.
Кто использует
save-data, вам может быть интересно? У 18 % пользователей Android Chrome по всему миру включен упрощенный режим (с включенным параметром «Save-Data»), и, скорее всего, это число будет выше. Согласно исследованию Саймона Херна, самый высокий уровень подписки на более дешевых устройствах, но есть много исключений. Например: у пользователей в Канаде уровень отказа составляет более 34% (по сравнению с ~ 7% в США), а у пользователей последнего флагмана Samsung этот показатель составляет почти 18% во всем мире.При включенном режиме
Save-DataChrome Mobile обеспечивает оптимизированную работу, т. е. работу в Интернете через прокси с отложенными сценариями , принудительноеfont-display: swapи принудительная отложенная загрузка. Просто более разумно создавать опыт самостоятельно, а не полагаться на браузер для выполнения этих оптимизаций.Заголовок в настоящее время поддерживается только в Chromium, в версии Chrome для Android или через расширение Data Saver на настольном устройстве. Наконец, вы также можете использовать API сетевой информации для доставки дорогостоящих модулей JavaScript, изображений и видео с высоким разрешением в зависимости от типа сети. Network Information API и, в частности,
navigator.connection.effectiveType. EffectiveType используют значенияRTT,downlink,effectiveType(и некоторые другие), чтобы обеспечить представление соединения и данных, которые могут обрабатывать пользователи.В этом контексте Макс Бок говорит о компонентах, поддерживающих подключение, а Эдди Османи говорит об адаптивном обслуживании модулей. Например, с помощью React мы могли бы написать компонент, который будет отображаться по-разному для разных типов подключения. Как предположил Макс, компонент
<Media />в новостной статье может выводить:-
Offline: заполнитель сaltтекстом, -
2G/режимsave-data: изображение с низким разрешением, -
3Gна экране без Retina: изображение среднего разрешения, -
3Gна экранах Retina: изображение Retina в высоком разрешении, -
4G: HD-видео.
Дин Хьюм предлагает практическую реализацию аналогичной логики с помощью сервисного работника. Для видео мы могли бы отображать видеопостер по умолчанию, а затем отображать значок «Воспроизвести», а также оболочку видеоплеера, метаданные видео и т. д. при лучшем соединении. В качестве запасного варианта для неподдерживающих браузеров мы могли бы прослушивать событие
canplaythroughи использоватьPromise.race()для тайм-аута загрузки источника, если событиеcanplaythroughне срабатывает в течение 2 секунд.Если вы хотите погрузиться немного глубже, вот несколько ресурсов для начала:
- Эдди Османи показывает, как реализовать адаптивное обслуживание в React.
- React Adaptive Loading Hooks & Utilities предоставляет фрагменты кода для React,
- Нетанель Базель исследует компоненты с поддержкой подключения в Angular,
- Теодор Ворилас рассказывает, как работает обслуживание адаптивных компонентов с помощью API сетевой информации в Vue.
- Умар Ханса показывает, как выборочно загружать/выполнять дорогостоящий JavaScript.
-
- Рассмотрите возможность того, чтобы ваши компоненты учитывали память устройства.
Однако сетевое подключение дает нам только одну перспективу в контексте пользователя. Идя дальше, вы также можете динамически настраивать ресурсы в зависимости от доступной памяти устройства с помощью API памяти устройства.navigator.deviceMemoryreturns how much RAM the device has in gigabytes, rounded down to the nearest power of two. The API also features a Client Hints Header,Device-Memory, that reports the same value.Bonus : Umar Hansa shows how to defer expensive scripts with dynamic imports to change the experience based on device memory, network connectivity and hardware concurrency.
- Warm up the connection to speed up delivery.
Use resource hints to save time ondns-prefetch(which performs a DNS lookup in the background),preconnect(which asks the browser to start the connection handshake (DNS, TCP, TLS) in the background),prefetch(which asks the browser to request a resource) andpreload(which prefetches resources without executing them, among other things). Well supported in modern browsers, with support coming to Firefox soon.Remember
prerender? The resource hint used to prompt browser to build out the entire page in the background for next navigation. The implementations issues were quite problematic, ranging from a huge memory footprint and bandwidth usage to multiple registered analytics hits and ad impressions.Unsurprinsingly, it was deprecated, but the Chrome team has brought it back as NoState Prefetch mechanism. In fact, Chrome treats the
prerenderhint as a NoState Prefetch instead, so we can still use it today. As Katie Hempenius explains in that article, "like prerendering, NoState Prefetch fetches resources in advance ; but unlike prerendering, it does not execute JavaScript or render any part of the page in advance."NoState Prefetch only uses ~45MiB of memory and subresources that are fetched will be fetched with an
IDLENet Priority. Since Chrome 69, NoState Prefetch adds the header Purpose: Prefetch to all requests in order to make them distinguishable from normal browsing.Also, watch out for prerendering alternatives and portals, a new effort toward privacy-conscious prerendering, which will provide the inset
previewof the content for seamless navigations.Using resource hints is probably the easiest way to boost performance , and it works well indeed. When to use what? As Addy Osmani has explained, it's reasonable to preload resources that we know are very likely to be used on the current page and for future navigations across multiple navigation boundaries, eg Webpack bundles needed for pages the user hasn't visited yet.
Addy's article on "Loading Priorities in Chrome" shows how exactly Chrome interprets resource hints, so once you've decided which assets are critical for rendering, you can assign high priority to them. To see how your requests are prioritized, you can enable a "priority" column in the Chrome DevTools network request table (as well as Safari).
Most of the time these days, we'll be using at least
preconnectanddns-prefetch, and we'll be cautious with usingprefetch,preloadandprerender. Note that even withpreconnectanddns-prefetch, the browser has a limit on the number of hosts it will look up/connect to in parallel, so it's a safe bet to order them based on priority ( thanks Philip Tellis! ).Since fonts usually are important assets on a page, sometimes it's a good idea to request the browser to download critical fonts with
preload. However, double check if it actually helps performance as there is a puzzle of priorities when preloading fonts: aspreloadis seen as high importance, it can leapfrog even more critical resources like critical CSS. ( thanks, Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Since
<link rel="preload">accepts amediaattribute, you could choose to selectively download resources based on@mediaquery rules, as shown above.Furthermore, we can use
imagesrcsetandimagesizesattributes to preload late-discovered hero images faster, or any images that are loaded via JavaScript, eg movie posters:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>We can also preload the JSON as fetch , so it's discovered before JavaScript gets to request it:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>We could also load JavaScript dynamically, effectively for lazy execution of the script.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);A few gotchas to keep in mind:
preloadis good for moving the start download time of an asset closer to the initial request, but preloaded assets land in the memory cache which is tied to the page making the request.preloadplays well with the HTTP cache: a network request is never sent if the item is already there in the HTTP cache.Hence, it's useful for late-discovered resources, hero images loaded via
background-image, inlining critical CSS (or JavaScript) and pre-loading the rest of the CSS (or JavaScript).
Preload important images early; no need to wait on JavaScript to discover them. (Image credit: “Preload Late-Discovered Hero Images Faster” by Addy Osmani) (Large preview) A
preloadtag can initiate a preload only after the browser has received the HTML from the server and the lookahead parser has found thepreloadtag. Preloading via the HTTP header could be a bit faster since we don't to wait for the browser to parse the HTML to start the request (it's debated though).Early Hints will help even further, enabling preload to kick in even before the response headers for the HTML are sent (on the roadmap in Chromium, Firefox). Plus, Priority Hints will help us indicate loading priorities for scripts.
Beware : if you're using
preload,asmust be defined or nothing loads, plus preloaded fonts without thecrossoriginattribute will double fetch. If you're usingprefetch, beware of theAgeheader issues in Firefox.
- Use service workers for caching and network fallbacks.
No performance optimization over a network can be faster than a locally stored cache on a user's machine (there are exceptions though). If your website is running over HTTPS, we can cache static assets in a service worker cache and store offline fallbacks (or even offline pages) and retrieve them from the user's machine, rather than going to the network.As suggested by Phil Walton, with service workers, we can send smaller HTML payloads by programmatically generating our responses. A service worker can request just the bare minimum of data it needs from the server (eg an HTML content partial, a Markdown file, JSON data, etc.), and then it can programmatically transform that data into a full HTML document. So once a user visits a site and the service worker is installed, the user will never request a full HTML page again. The performance impact can be quite impressive.
Browser support? Service workers are widely supported and the fallback is the network anyway. Does it help boost performance ? Oh yes, it does. And it's getting better, eg with Background Fetch allowing background uploads/downloads via a service worker as well.
There are a number of use cases for a service worker. For example, you could implement "Save for offline" feature, handle broken images, introduce messaging between tabs or provide different caching strategies based on request types. In general, a common reliable strategy is to store the app shell in the service worker's cache along with a few critical pages, such as offline page, frontpage and anything else that might be important in your case.
There are a few gotchas to keep in mind though. With a service worker in place, we need to beware range requests in Safari (if you are using Workbox for a service worker it has a range request module). If you ever stumbled upon
DOMException: Quota exceeded.error in the browser console, then look into Gerardo's article When 7KB equals 7MB.Как пишет Джерардо: «Если вы создаете прогрессивное веб-приложение и сталкиваетесь с раздутым хранилищем кеша, когда ваш сервисный работник кэширует статические ресурсы, обслуживаемые из CDN, убедитесь, что для ресурсов из разных источников существует правильный заголовок ответа CORS, вы не кэшируете непрозрачные ответы. с вашим сервис-воркером вы непреднамеренно включаете ресурсы изображения из разных источников в режим CORS, добавляя атрибут
crossoriginк тегу<img>».Существует множество отличных ресурсов для начала работы с сервис-воркерами:
- Мышление сервисного работника, которое поможет вам понять, как сервисные работники работают за кулисами, и что нужно понимать при их создании.
- Крис Фердинанди (Chris Ferdinandi) опубликовал большую серию статей о сервис-воркерах, в которых объясняется, как создавать автономные приложения, и рассматриваются различные сценарии, от сохранения недавно просмотренных страниц в автономном режиме до установки даты истечения срока действия для элементов в кэше сервис-воркеров.
- Подводные камни сервис-воркеров и передовой опыт, а также несколько советов о сфере применения, отсрочке регистрации сервис-воркера и кэшировании сервис-воркера.
- Отличная серия статей Айра Адеринокуна «Сначала в автономном режиме» с Service Worker и стратегией предварительного кэширования оболочки приложения.
- Service Worker: Введение с практическими советами о том, как использовать Service Worker для многофункционального автономного взаимодействия, периодической фоновой синхронизации и push-уведомлений.
- Всегда стоит обратиться к старой доброй оффлайн-поваренной книге Джейка Арчибальда с рядом рецептов, как испечь собственного сервис-воркера.
- Workbox — это набор библиотек сервис-воркеров, созданных специально для создания прогрессивных веб-приложений.
- Запускаете ли вы рабочих серверов на CDN/Edge, например, для A/B-тестирования?
На данный момент мы уже привыкли запускать сервис-воркеры на клиенте, но с CDN, реализующими их на сервере, мы могли бы использовать их для настройки производительности и на периферии.Например, в A/B-тестах, когда HTML нужно менять содержимое для разных пользователей, мы могли бы использовать Service Workers на серверах CDN для обработки логики. Мы также могли бы транслировать переписывание HTML для ускорения работы сайтов, использующих Google Fonts.
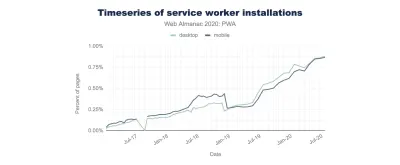
- Оптимизация производительности рендеринга.
Всякий раз, когда приложение тормозит, это сразу заметно. Поэтому нам нужно убедиться, что при прокрутке страницы или при анимации элемента нет задержек, и что вы постоянно набираете 60 кадров в секунду. Если это невозможно, то, по крайней мере, сделать количество кадров в секунду согласованным предпочтительнее, чем смешанный диапазон от 60 до 15. Используйте CSSwill-change, чтобы сообщить браузеру, какие элементы и свойства будут изменены.Всякий раз, когда вы испытываете, отлаживайте ненужные перерисовки в DevTools:
- Измеряйте производительность рендеринга во время выполнения. Ознакомьтесь с некоторыми полезными советами о том, как это понять.
- Для начала ознакомьтесь с бесплатным курсом Udacity Пола Льюиса по оптимизации рендеринга браузера и статьей Георгия Марчука «Отрисовка браузера и рекомендации по веб-производительности».
- Включите Paint Flashing в «Дополнительные инструменты → Рендеринг → Paint Flashing» в Firefox DevTools.
- В React DevTools установите флажок «Выделять обновления» и включите «Записывать, почему отображается каждый компонент».
- Вы также можете использовать Why Did You Render, чтобы при повторном рендеринге компонента вспышка уведомляла вас об изменении.
Вы используете макет Masonry? Имейте в виду, что очень скоро можно будет создать макет Masonry только с сеткой CSS.
Если вы хотите глубже погрузиться в тему, Нолан Лоусон поделился в своей статье приемами точного измерения производительности макета, а Джейсон Миллер также предложил альтернативные методы. У нас также есть небольшая статья Сергея Чикуёнка о том, как правильно сделать анимацию на GPU.

Браузеры могут дешево анимировать преобразование и непрозрачность. Триггеры CSS полезны для проверки того, запускает ли CSS повторные макеты или перекомпоновки. (Изображение предоставлено Адди Османи) (большой превью) Примечание : изменения в слоях, созданных с помощью графического процессора, являются наименее затратными, поэтому, если вы можете уйти, запустив только композитинг с помощью
opacityиtransform, вы будете на правильном пути. Анна Мигас также дала много практических советов в своем выступлении на тему «Отладка производительности рендеринга пользовательского интерфейса». А чтобы понять, как отладить производительность рисования в DevTools, посмотрите видео аудита производительности рисования Умара. - Оптимизировали ли вы воспринимаемую производительность?
Хотя последовательность того, как компоненты отображаются на странице, и стратегия того, как мы обслуживаем ресурсы для браузера, имеют значение, мы также не должны недооценивать роль воспринимаемой производительности. Концепция касается психологических аспектов ожидания, в основном удерживая клиентов занятыми или вовлеченными, пока что-то еще происходит. Вот где в игру вступают управление восприятием, опережающее начало, раннее завершение и управление толерантностью.Что все это значит? При загрузке активов мы можем стараться всегда быть на шаг впереди клиента, поэтому работа кажется быстрой, в то время как в фоновом режиме происходит довольно много. Чтобы поддерживать интерес клиента, мы можем тестировать скелетные экраны (демонстрация реализации) вместо загрузки индикаторов, добавлять переходы/анимацию и фактически обманывать UX, когда больше нечего оптимизировать.
В своем тематическом исследовании The Art of UI Skeletons Кумар Макмиллан делится некоторыми идеями и методами моделирования динамических списков, текста и конечного экрана, а также того, как учитывать скелетное мышление с помощью React.
Однако будьте осторожны: скелетные экраны следует протестировать перед развертыванием, поскольку некоторые тесты показали, что каркасные экраны могут работать хуже всего по всем показателям.
- Предотвращаете ли вы смену макета и перерисовку?
В области воспринимаемой производительности, вероятно, одним из наиболее разрушительных событий является смещение макета или перекомпоновка , вызванное масштабированием изображений и видео, веб-шрифтов, внедренной рекламы или поздно обнаруженными скриптами, которые заполняют компоненты реальным контентом. В результате покупатель может начать читать статью только для того, чтобы его прервал скачок макета над областью чтения. Опыт часто бывает резким и довольно дезориентирующим: и это, вероятно, случай загрузки приоритетов, которые необходимо пересмотреть.Сообщество разработало несколько методов и обходных путей, чтобы избежать перекомпоновки. Как правило, рекомендуется избегать вставки нового контента поверх существующего , если только это не происходит в ответ на действия пользователя. Всегда устанавливайте атрибуты ширины и высоты для изображений, чтобы современные браузеры выделяли поле и резервировали пространство по умолчанию (Firefox, Chrome).
Как для изображений, так и для видео мы можем использовать заполнитель SVG, чтобы зарезервировать поле отображения, в котором будет отображаться медиафайл. Это означает, что область будет зарезервирована должным образом, когда вам также потребуется сохранить ее соотношение сторон. Мы также можем использовать заполнители или резервные изображения для рекламы и динамического контента, а также предварительно выделять слоты макета.
Вместо отложенной загрузки изображений с помощью внешних скриптов рассмотрите возможность использования встроенной отложенной загрузки или гибридной отложенной загрузки, когда мы загружаем внешний скрипт только в том случае, если собственная отложенная загрузка не поддерживается.
Как упоминалось выше, всегда группируйте перерисовки веб-шрифтов и переходите от всех резервных шрифтов ко всем веб-шрифтам одновременно — просто убедитесь, что этот переход не слишком резкий, регулируя высоту строки и расстояние между шрифтами с помощью font-style-matcher. .
Чтобы переопределить метрики шрифта для резервного шрифта для эмуляции веб-шрифта, мы можем использовать дескрипторы @font-face для переопределения метрик шрифта (демонстрация, включена в Chrome 87). (Обратите внимание, что настройки сложны со сложными стеками шрифтов.)
Для поздних версий CSS мы можем убедиться, что важные для макета CSS встроены в заголовок каждого шаблона. Более того: для длинных страниц при добавлении вертикальной полосы прокрутки основной контент смещается на 16 пикселей влево. Чтобы отобразить полосу прокрутки раньше, мы можем добавить
overflow-y: scrollhtml, чтобы принудительно использовать полосу прокрутки при первой отрисовке. Последнее помогает, потому что полосы прокрутки могут вызвать нетривиальные сдвиги макета из-за перекомпоновки содержимого верхней части сгиба при изменении ширины. В основном это должно происходить на платформах с полосами прокрутки без наложения, такими как Windows. Но: ломаетposition: sticky, потому что эти элементы никогда не будут прокручиваться из контейнера.Если вы имеете дело с заголовками, которые становятся фиксированными или прилипают к верхней части страницы при прокрутке, зарезервируйте место для заголовка, когда он становится сосновым, например, с помощью элемента-заполнителя или
margin-topв содержимом. Исключением должны быть баннеры согласия на использование файлов cookie, которые не должны влиять на CLS, но иногда влияют: это зависит от реализации. В этой ветке Твиттера есть несколько интересных стратегий и выводов.Для компонента вкладки, который может включать различное количество текстов, вы можете предотвратить смену макета с помощью стеков сетки CSS. Помещая содержимое каждой вкладки в одну и ту же область сетки и скрывая одну из них за раз, мы можем гарантировать, что контейнер всегда будет занимать высоту большего элемента, поэтому не произойдет смещения макета.
Ну, и, конечно же, бесконечная прокрутка и «Загрузить еще» также могут вызвать сдвиг макета, если под списком есть контент (например, нижний колонтитул). Чтобы улучшить CLS, зарезервируйте достаточно места для содержимого, которое будет загружено до того, как пользователь прокрутит страницу до этой части страницы, удалите нижний колонтитул или любые элементы DOM внизу страницы, которые могут быть сдвинуты вниз при загрузке содержимого. выполнять предварительную выборку данных и изображений для контента, расположенного ниже сгиба, чтобы к моменту, когда пользователь прокручивает до конца, он уже был там. Вы также можете использовать библиотеки виртуализации списков, такие как react-window, для оптимизации длинных списков ( спасибо, Эдди Османи! ).
Чтобы убедиться, что влияние перекомпоновки ограничено, измерьте стабильность макета с помощью API нестабильности макета. С его помощью вы можете рассчитать показатель Cumulative Layout Shift ( CLS ) и включить его в качестве требования в свои тесты, чтобы всякий раз, когда появляется регрессия, вы могли отслеживать ее и исправлять.
Чтобы рассчитать оценку сдвига макета, браузер смотрит на размер области просмотра и перемещение нестабильных элементов в области просмотра между двумя визуализируемыми кадрами. В идеале оценка должна быть близка к
0. Существует отличное руководство Милицы Михайлии и Филипа Уолтона о том, что такое CLS и как его измерить. Это хорошая отправная точка для измерения и поддержания предполагаемой производительности и предотвращения сбоев, особенно для критически важных бизнес-задач.Небольшой совет : чтобы узнать, что вызвало изменение макета в DevTools, вы можете изучить изменения макета в разделе «Опыт» на панели «Производительность».
Бонус : если вы хотите уменьшить количество перекомпоновок и перерисовок, ознакомьтесь с руководством Чариса Теодулу по минимизации перекомпоновки/перераспределения макета DOM и списком Пола Айриша «Что заставляет разметку/перекомпоновку», а также с CSSTriggers.com, справочной таблицей свойств CSS, которые запускают разметку, рисование. и композитинга.
Сеть и HTTP/2
- Включено ли сшивание OCSP?
Включив сшивание OCSP на своем сервере, вы можете ускорить рукопожатия TLS. Протокол статуса онлайн-сертификатов (OCSP) был создан как альтернатива протоколу списка отзыва сертификатов (CRL). Оба протокола используются для проверки того, был ли отозван сертификат SSL.Однако протокол OCSP не требует, чтобы браузер тратил время на загрузку и последующий поиск в списке информации о сертификате, что сокращает время, необходимое для рукопожатия.
- Уменьшили ли вы влияние отзыва SSL-сертификата?
В своей статье «Стоимость сертификатов EV» Саймон Хирн дает отличный обзор распространенных сертификатов и влияние выбора сертификата на общую производительность.Как пишет Саймон, в мире HTTPS существует несколько типов уровней проверки сертификатов, используемых для защиты трафика:
- Проверка домена (DV) подтверждает, что инициатор запроса сертификата владеет доменом,
- Проверка организации (OV) подтверждает, что организация владеет доменом,
- Расширенная проверка (EV) подтверждает, что организация владеет доменом, с тщательной проверкой.
Важно отметить, что все эти сертификаты одинаковы с точки зрения технологии; они отличаются только информацией и свойствами, указанными в этих сертификатах.
Сертификаты EV дороги и требуют много времени , поскольку они требуют, чтобы человек просматривал сертификат и гарантировал его действительность. Сертификаты DV, с другой стороны, часто предоставляются бесплатно — например, Let's Encrypt — открытым автоматизированным центром сертификации, хорошо интегрированным со многими хостинг-провайдерами и CDN. Фактически, на момент написания статьи он поддерживает более 225 миллионов веб-сайтов (PDF), хотя он составляет только 2,69% страниц (открытых в Firefox).
Так в чем же тогда проблема? Проблема в том, что сертификаты EV не полностью поддерживают упомянутое выше сшивание OCSP . В то время как сшивание позволяет серверу проверить с центром сертификации, был ли сертификат отозван, а затем добавить («сшивать») эту информацию в сертификат, без сшивания всю работу должен выполнять клиент, что приводит к ненужным запросам во время согласования TLS. . При плохом соединении это может привести к заметным потерям производительности (1000 мс+).
Сертификаты EV не лучший выбор для веб-производительности, и они могут оказать гораздо большее влияние на производительность, чем сертификаты DV. Для оптимальной производительности Интернета всегда используйте сшитый DV-сертификат OCSP. Они также намного дешевле, чем сертификаты EV, и их проще приобрести. Ну, по крайней мере, пока не появится CRLite.
Сжатие имеет значение: 40–43 % несжатых цепочек сертификатов слишком велики, чтобы поместиться в одном потоке QUIC из 3 дейтаграмм UDP. (Изображение предоставлено:) Быстро) (Большой превью) Примечание . При использовании QUIC/HTTP/3 стоит отметить, что цепочка сертификатов TLS — это единственный контент переменного размера, который доминирует в подсчете байтов в рукопожатии QUIC. Размер варьируется от нескольких сотен байтов до более 10 КБ.
Таким образом, небольшие сертификаты TLS имеют большое значение для QUIC/HTTP/3, так как большие сертификаты вызовут несколько рукопожатий. Кроме того, нам нужно убедиться, что сертификаты сжаты, иначе цепочки сертификатов будут слишком большими, чтобы поместиться в одну сборку QUIC.
Вы можете найти более подробную информацию и указатели на проблему и решения на:
- Сертификаты EV делают Интернет медленным и ненадежным Аарон Питерс,
- Влияние отзыва SSL-сертификата на производительность сети, Мэтт Хоббс,
- Стоимость сертификатов EV Саймона Херна,
- Требует ли рукопожатие QUIC быстрого сжатия? Патрик Макманус.
- Вы уже приняли IPv6?
Поскольку у нас заканчивается пространство с IPv4, а основные мобильные сети быстро внедряют IPv6 (США почти достигли 50-процентного порога внедрения IPv6), рекомендуется обновить DNS до IPv6, чтобы оставаться пуленепробиваемым в будущем. Просто убедитесь, что в сети предоставляется поддержка двойного стека — это позволяет IPv6 и IPv4 работать одновременно друг с другом. В конце концов, IPv6 не поддерживает обратную совместимость. Кроме того, исследования показывают, что IPv6 сделал эти веб-сайты на 10–15% быстрее благодаря обнаружению соседей (NDP) и оптимизации маршрутов. - Убедитесь, что все активы работают через HTTP/2 (или HTTP/3).
Поскольку в последние несколько лет Google стремится к более безопасной сети HTTPS, переход на среду HTTP/2, безусловно, является хорошей инвестицией. На самом деле, согласно веб-альманаху, 64% всех запросов уже выполняются через HTTP/2.Важно понимать, что HTTP/2 не идеален и имеет проблемы с приоритизацией, но поддерживается очень хорошо; и, в большинстве случаев, вам лучше с ним.
Предостережение: HTTP/2 Server Push удаляется из Chrome, поэтому, если ваша реализация полагается на Server Push, возможно, вам придется вернуться к нему. Вместо этого мы могли бы рассмотреть ранние подсказки, которые уже интегрированы в качестве эксперимента в Fastly.
Если вы все еще работаете с HTTP, наиболее трудоемкой задачей будет сначала перейти на HTTPS, а затем настроить процесс сборки для поддержки мультиплексирования и распараллеливания HTTP/2. Внедрение HTTP/2 в Gov.uk — это фантастический пример того, как сделать именно это, попутно найдя путь через CORS, SRI и WPT. В оставшейся части этой статьи мы предполагаем, что вы либо переходите на HTTP/2, либо уже переключились на него.
- Правильно разверните HTTP/2.
Опять же, обслуживание ресурсов через HTTP/2 может выиграть от частичного пересмотра того, как вы обслуживали ресурсы до сих пор. Вам нужно будет найти тонкий баланс между упаковкой модулей и параллельной загрузкой множества небольших модулей. В конце концов, лучший запрос — это отсутствие запроса, однако цель состоит в том, чтобы найти баланс между быстрой первой доставкой ресурсов и кэшированием.С одной стороны, вы, возможно, захотите вообще избежать конкатенации ресурсов, вместо того, чтобы разбивать весь интерфейс на множество небольших модулей, сжимая их как часть процесса сборки и загружая их параллельно. Изменение в одном файле не потребует повторной загрузки всей таблицы стилей или JavaScript. Это также сводит к минимуму время синтаксического анализа и снижает нагрузку на отдельные страницы.
С другой стороны, упаковка по-прежнему имеет значение. При использовании большого количества небольших сценариев страдает общее сжатие и увеличивается стоимость извлечения объектов из кэша. Сжатие большого пакета выиграет от повторного использования словаря, в то время как небольшие отдельные пакеты этого не сделают. Есть стандартная работа по решению этой проблемы, но пока это далеко не так. Во-вторых, браузеры еще не оптимизированы для таких рабочих процессов. Например, Chrome будет запускать межпроцессное взаимодействие (IPC) линейно в зависимости от количества ресурсов, поэтому включение сотен ресурсов будет иметь затраты времени выполнения браузера.
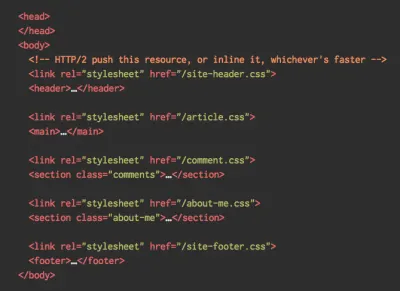
Чтобы достичь наилучших результатов с HTTP/2, рассмотрите возможность постепенной загрузки CSS, как предложил Джейк Арчибальд из Chrome. Тем не менее, вы можете попробовать загружать CSS постепенно. На самом деле встроенный CSS больше не блокирует рендеринг для Chrome. Но есть некоторые проблемы с расстановкой приоритетов, так что это не так просто, но с ними стоит поэкспериментировать.
Вы можете обойтись без объединения соединений HTTP/2, что позволяет вам использовать сегментирование домена, получая преимущества от HTTP/2, но добиться этого на практике сложно, и в целом это не считается хорошей практикой. Кроме того, HTTP/2 и целостность субресурсов не всегда ладят.
Что делать? Что ж, если вы используете HTTP/2, отправка примерно 6–10 пакетов кажется достойным компромиссом (и не так уж плохо для устаревших браузеров). Экспериментируйте и измеряйте, чтобы найти правильный баланс для вашего сайта.
- Отправляем ли мы все активы через одно соединение HTTP/2?
Одним из основных преимуществ HTTP/2 является то, что он позволяет нам отправлять активы по сети через одно соединение. Однако иногда мы могли сделать что-то не так — например, иметь проблему с CORS или неправильно настроить атрибутcrossorigin, поэтому браузер был вынужден открыть новое соединение.Чтобы проверить, используют ли все запросы одно соединение HTTP/2 или что-то неправильно настроено, включите столбец «Идентификатор соединения» в DevTools → Network. Например, здесь все запросы используют одно и то же соединение (286), кроме manifest.json, который открывает отдельное соединение (451).
- Поддерживают ли ваши серверы и CDN HTTP/2?
Разные серверы и CDN (по-прежнему) по-разному поддерживают HTTP/2. Используйте сравнение CDN, чтобы проверить свои варианты или быстро узнать, как работают ваши серверы и какие функции вы можете рассчитывать на поддержку.Проконсультируйтесь с невероятным исследованием Пэта Минана о приоритетах HTTP/2 (видео) и проверьте поддержку сервера для приоритизации HTTP/2. По словам Пэта, рекомендуется включить контроль перегрузки BBR и установить для
tcp_notsent_lowatзначение 16 КБ, чтобы приоритизация HTTP/2 надежно работала на ядрах Linux 4.9 и более поздних версиях ( спасибо, Йоав! ). Энди Дэвис провел аналогичное исследование для определения приоритетов HTTP/2 в браузерах, CDN и службах облачного хостинга.Находясь на нем, дважды проверьте, поддерживает ли ваше ядро TCP BBR, и включите его, если это возможно. В настоящее время он используется на Google Cloud Platform, Amazon Cloudfront, Linux (например, Ubuntu).
- Используется ли сжатие HPACK?
Если вы используете HTTP/2, убедитесь, что ваши серверы используют сжатие HPACK для заголовков ответа HTTP, чтобы уменьшить ненужные накладные расходы. Некоторые серверы HTTP/2 могут не полностью поддерживать спецификацию, например, HPACK. H2spec — отличный (хотя и очень технически подробный) инструмент для проверки этого. Алгоритм сжатия HPACK впечатляет, и он работает. - Убедитесь, что безопасность вашего сервера пуленепробиваема.
Все браузерные реализации HTTP/2 работают через TLS, поэтому вы, вероятно, захотите избежать предупреждений безопасности или неработающих элементов на вашей странице. Дважды проверьте правильность настройки заголовков безопасности, устраните известные уязвимости и проверьте настройку HTTPS.Кроме того, убедитесь, что все внешние подключаемые модули и сценарии отслеживания загружаются через HTTPS, что межсайтовые сценарии невозможны и что заголовки HTTP Strict Transport Security и заголовки Content Security Policy установлены правильно.
- Поддерживают ли ваши серверы и CDN HTTP/3?
Хотя HTTP/2 принес ряд значительных улучшений производительности в Интернете, он также оставил немало возможностей для улучшения — особенно блокировку начала строки в TCP, которая была заметна в медленной сети со значительной потерей пакетов. HTTP/3 решает эти проблемы навсегда (статья).Для решения проблем HTTP/2 IETF вместе с Google, Akamai и другими работает над новым протоколом, который недавно был стандартизирован как HTTP/3.
Робин Маркс очень хорошо объяснил HTTP/3, и следующее объяснение основано на его объяснении. По своей сути HTTP/3 очень похож на HTTP/2 с точки зрения функций, но внутри он работает совсем по-другому. HTTP/3 предоставляет ряд улучшений: более быстрые рукопожатия, лучшее шифрование, более надежные независимые потоки, лучшее шифрование и управление потоком. Заметным отличием является то, что HTTP/3 использует QUIC в качестве транспортного уровня, при этом пакеты QUIC инкапсулируются поверх диаграмм UDP, а не TCP.
QUIC полностью интегрирует TLS 1.3 в протокол, в то время как в TCP он находится поверх. В типичном стеке TCP у нас есть несколько накладных расходов, поскольку TCP и TLS должны выполнять свои собственные отдельные рукопожатия, но с QUIC оба они могут быть объединены и завершены всего за один цикл . Поскольку TLS 1.3 позволяет нам устанавливать ключи шифрования для последующего соединения, начиная со второго соединения, мы уже можем отправлять и получать данные прикладного уровня в первом круговом цикле, который называется «0-RTT».
Кроме того, алгоритм сжатия заголовков HTTP/2 был полностью переписан вместе с его системой приоритетов. Кроме того, QUIC поддерживает перенос соединения с Wi-Fi на сотовую сеть с помощью идентификаторов соединения в заголовке каждого пакета QUIC. Большинство реализаций выполняются в пространстве пользователя, а не в пространстве ядра (как это делается с TCP), поэтому следует ожидать, что протокол будет развиваться в будущем.
Будет ли все это иметь большое значение? Вероятно, да, особенно это влияет на время загрузки на мобильных устройствах, а также на то, как мы обслуживаем ресурсы для конечных пользователей. В то время как в HTTP/2 несколько запросов совместно используют соединение, в HTTP/3 запросы также используют соединение, но потоки независимы, поэтому отброшенный пакет больше не влияет на все запросы, а только на один поток.
Это означает, что хотя с одним большим пакетом JavaScript обработка ресурсов будет замедляться, когда один поток приостанавливается, влияние будет менее значительным, когда несколько файлов передаются параллельно (HTTP/3). Так что упаковка по-прежнему имеет значение .
Работа над HTTP/3 все еще продолжается. Chrome, Firefox и Safari уже имеют реализации. Некоторые CDN уже поддерживают QUIC и HTTP/3. В конце 2020 года Chrome начал развертывание HTTP/3 и IETF QUIC, и фактически все сервисы Google (Google Analytics, YouTube и т. д.) уже работают по протоколу HTTP/3. Веб-сервер LiteSpeed поддерживает HTTP/3, но ни Apache, ни nginx, ни IIS пока не поддерживают его, но, вероятно, в 2021 году это быстро изменится.
Вывод : если у вас есть возможность использовать HTTP/3 на сервере и в CDN, вероятно, это очень хорошая идея. Основное преимущество будет заключаться в одновременном получении нескольких объектов, особенно при соединениях с высокой задержкой. Мы еще не знаем наверняка, так как в этой области не проводилось много исследований, но первые результаты очень многообещающие.
Если вы хотите больше узнать о специфике и преимуществах протокола, вот несколько хороших отправных точек для проверки:
- Объяснение HTTP/3, совместная работа по документированию протоколов HTTP/3 и QUIC. Доступно на разных языках, а также в формате PDF.
- Повышение веб-производительности с помощью HTTP/3 с Дэниелом Стенбергом.
- Академическое руководство по QUIC с Робином Марксом знакомит с основными понятиями протоколов QUIC и HTTP/3, объясняет, как HTTP/3 обрабатывает блокировку заголовка строки и миграцию соединений, а также как HTTP/3 разработан, чтобы быть вечнозеленым (спасибо, Саймон !).
- Вы можете проверить, работает ли ваш сервер на HTTP/3 на HTTP3Check.net.
Тестирование и мониторинг
- Оптимизировали ли вы свой рабочий процесс аудита?
Это может показаться не таким уж большим делом, но наличие правильных настроек под рукой может сэкономить вам немало времени при тестировании. Рассмотрите возможность использования рабочего процесса Альфреда Тима Кадлека для WebPageTest для отправки теста в общедоступный экземпляр WebPageTest. На самом деле, в WebPageTest есть много неясных функций, поэтому найдите время, чтобы научиться читать диаграмму WebPageTest Waterfall View и как читать диаграмму WebPageTest Connection View, чтобы быстрее диагностировать и решать проблемы с производительностью.Вы также можете запустить WebPageTest из электронной таблицы Google и включить показатели доступности, производительности и SEO в свою настройку Travis с помощью Lighthouse CI или прямо в Webpack.
Взгляните на недавно выпущенный модульный инструмент AutoWebPerf, который позволяет автоматически собирать данные о производительности из нескольких источников. Например, мы можем провести ежедневный тест на ваших критически важных страницах, чтобы получить полевые данные из CrUX API и лабораторные данные из отчета Lighthouse из PageSpeed Insights.
И если вам нужно что-то быстро отладить, но ваш процесс сборки кажется удивительно медленным, имейте в виду, что «удаление пробелов и изменение символов составляет 95% уменьшения размера минимизированного кода для большинства JavaScript, а не сложные преобразования кода. Вы можете просто отключите сжатие, чтобы ускорить сборку Uglify в 3-4 раза».
- Вы тестировали в прокси-браузерах и устаревших браузерах?
Тестирования в Chrome и Firefox недостаточно. Посмотрите, как ваш сайт работает в прокси-браузерах и устаревших браузерах. UC Browser и Opera Mini, например, занимают значительную долю рынка в Азии (до 35% в Азии). Измерьте среднюю скорость Интернета в интересующих вас странах, чтобы избежать больших сюрпризов в будущем. Протестируйте с регулированием скорости сети и эмулируйте устройство с высоким разрешением. BrowserStack отлично подходит для тестирования на удаленных реальных устройствах, и дополните его хотя бы несколькими реальными устройствами в вашем офисе — оно того стоит.
- Вы проверяли производительность своих 404 страниц?
Обычно мы не думаем дважды, когда дело доходит до 404 страниц. В конце концов, когда клиент запрашивает страницу, которой нет на сервере, сервер ответит кодом состояния 404 и соответствующей страницей 404. Там не так уж много, не так ли?Важным аспектом ответов 404 является фактический размер тела ответа , отправляемого в браузер. Согласно исследованию 404 страниц, проведенному Мэттом Хоббсом, подавляющее большинство ответов 404 исходит от отсутствующих фавиконов, запросов на загрузку WordPress, неработающих запросов JavaScript, файлов манифеста, а также файлов CSS и шрифтов. Каждый раз, когда клиент запрашивает несуществующий актив, он получает ответ 404 — и часто этот ответ огромен.
Обязательно изучите и оптимизируйте стратегию кэширования для своих страниц 404. Наша цель — предоставлять HTML браузеру только тогда, когда он ожидает HTML-ответ, и возвращать небольшую полезную нагрузку с ошибкой для всех остальных ответов. По словам Мэтта, «если мы разместим CDN перед нашим источником, у нас будет возможность кэшировать ответ страницы 404 в CDN. Это полезно, потому что без этого попадание на страницу 404 может быть использовано как вектор атаки DoS, путем заставляя исходный сервер отвечать на каждый запрос 404 вместо того, чтобы позволить CDN отвечать кэшированной версией».
Ошибки 404 могут не только снизить производительность, но и снизить трафик, поэтому рекомендуется включить страницу ошибки 404 в набор тестирования Lighthouse и отслеживать ее оценку с течением времени.
- Проверяли ли вы эффективность своих запросов согласия GDPR?
Во времена GDPR и CCPA стало обычным делом полагаться на третьих лиц, чтобы предоставить клиентам из ЕС варианты выбора или отказа от отслеживания. Однако, как и в случае с любым другим сторонним скриптом, их производительность может иметь разрушительное влияние на общую производительность.Конечно, фактическое согласие, вероятно, изменит влияние сценариев на общую производительность, поэтому, как заметил Борис Шапира, мы могли бы изучить несколько различных профилей веб-производительности:
- В согласии было полностью отказано,
- В согласии частично отказано,
- Согласие было дано полностью.
- Пользователь не отреагировал на запрос согласия (или запрос был заблокирован блокировщиком контента),
Обычно запросы согласия на использование файлов cookie не должны влиять на CLS, но иногда они влияют, поэтому рассмотрите возможность использования бесплатных опций с открытым исходным кодом Osano или cookie-consent-box.
В общем, стоит изучить производительность всплывающих окон, так как вам нужно будет определить горизонтальное или вертикальное смещение события мыши и правильно расположить всплывающее окно относительно точки привязки. Ноам Розенталь делится знаниями команды Викимедиа в статье «Пример веб-производительности: предварительный просмотр страниц Википедии» (также доступен в виде видео и минут).
- Ведете ли вы CSS для диагностики производительности?
Хотя мы можем включить все виды проверок, чтобы гарантировать, что непроизводительный код будет развернут, часто бывает полезно получить быстрое представление о некоторых низко висящих плодах, которые можно легко решить. Для этого мы могли бы использовать великолепный CSS для диагностики производительности Тима Кадлека (вдохновленный фрагментом кода Гарри Робертса, который выделяет изображения с отложенной загрузкой, изображения без размера, изображения в устаревшем формате и синхронные сценарии.Например, вы можете захотеть убедиться, что никакие изображения над сгибом не загружаются лениво. Вы можете настроить фрагмент под свои нужды, например, выделить неиспользуемые веб-шрифты или определить шрифты значков. Отличный небольшой инструмент для обеспечения видимости ошибок во время отладки или просто для очень быстрого аудита текущего проекта.
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Have you tested the impact on accessibility?
When the browser starts to load a page, it builds a DOM, and if there is an assistive technology like a screen reader running, it also creates an accessibility tree. The screen reader then has to query the accessibility tree to retrieve the information and make it available to the user — sometimes by default, and sometimes on demand. And sometimes it takes time.When talking about fast Time to Interactive, usually we mean an indicator of how soon a user can interact with the page by clicking or tapping on links and buttons. The context is slightly different with screen readers. In that case, fast Time to Interactive means how much time passes by until the screen reader can announce navigation on a given page and a screen reader user can actually hit keyboard to interact.
Leonie Watson has given an eye-opening talk on accessibility performance and specifically the impact slow loading has on screen reader announcement delays. Screen readers are used to fast-paced announcements and quick navigation, and therefore might potentially be even less patient than sighted users.
Large pages and DOM manipulations with JavaScript will cause delays in screen reader announcements. A rather unexplored area that could use some attention and testing as screen readers are available on literally every platform (Jaws, NVDA, Voiceover, Narrator, Orca).
- Is continuous monitoring set up?
Having a private instance of WebPagetest is always beneficial for quick and unlimited tests. However, a continuous monitoring tool — like Sitespeed, Calibre and SpeedCurve — with automatic alerts will give you a more detailed picture of your performance. Set your own user-timing marks to measure and monitor business-specific metrics. Also, consider adding automated performance regression alerts to monitor changes over time.Look into using RUM-solutions to monitor changes in performance over time. For automated unit-test-alike load testing tools, you can use k6 with its scripting API. Also, look into SpeedTracker, Lighthouse and Calibre.
Быстрые победы
This list is quite comprehensive, and completing all of the optimizations might take quite a while. So, if you had just 1 hour to get significant improvements, what would you do? Let's boil it all down to 17 low-hanging fruits . Obviously, before you start and once you finish, measure results, including Largest Contentful Paint and Time To Interactive on a 3G and cable connection.
- Measure the real world experience and set appropriate goals. Aim to be at least 20% faster than your fastest competitor. Stay within Largest Contentful Paint < 2.5s, a First Input Delay < 100ms, Time to Interactive < 5s on slow 3G, for repeat visits, TTI < 2s. Optimize at least for First Contentful Paint and Time To Interactive.
- Optimize images with Squoosh, mozjpeg, guetzli, pingo and SVGOMG, and serve AVIF/WebP with an image CDN.
- Prepare critical CSS for your main templates, and inline them in the
<head>of each template. For CSS/JS, operate within a critical file size budget of max. 170KB gzipped (0.7MB decompressed). - Trim, optimize, defer and lazy-load scripts. Invest in the config of your bundler to remove redundancies and check lightweight alternatives.
- Always self-host your static assets and always prefer to self-host third-party assets. Limit the impact of third-party scripts. Use facades, load widgets on interaction and beware of anti-flicker snippets.
- Be selective when choosing a framework. For single-page-applications, identify critical pages and serve them statically, or at least prerender them, and use progressive hydration on component-level and import modules on interaction.
- Client-side rendering alone isn't a good choice for performance. Prerender if your pages don't change much, and defer the booting of frameworks if you can. If possible, use streaming server-side rendering.
- Serve legacy code only to legacy browsers with
<script type="module">and module/nomodule pattern. - Experiment with regrouping your CSS rules and test in-body CSS.
- Add resource hints to speed up delivery with faster
dns-lookup,preconnect,prefetch,preloadandprerender. - Subset web fonts and load them asynchronously, and utilize
font-displayin CSS for fast first rendering. - Check that HTTP cache headers and security headers are set properly.
- Enable Brotli compression on the server. (If that's not possible, at least make sure that Gzip compression is enabled.)
- Enable TCP BBR congestion as long as your server is running on the Linux kernel version 4.9+.
- Enable OCSP stapling and IPv6 if possible. Always serve an OCSP stapled DV certificate.
- Enable HPACK compression for HTTP/2 and move to HTTP/3 if it's available.
- Cache assets such as fonts, styles, JavaScript and images in a service worker cache.
Download The Checklist (PDF, Apple Pages)
With this checklist in mind, you should be prepared for any kind of front-end performance project. Feel free to download the print-ready PDF of the checklist as well as an editable Apple Pages document to customize the checklist for your needs:
- Download the checklist PDF (PDF, 166 KB)
- Download the checklist in Apple Pages (.pages, 275 KB)
- Download the checklist in MS Word (.docx, 151 KB)
If you need alternatives, you can also check the front-end checklist by Dan Rublic, the "Designer's Web Performance Checklist" by Jon Yablonski and the FrontendChecklist.
Поехали!
Some of the optimizations might be beyond the scope of your work or budget or might just be overkill given the legacy code you have to deal with. That's fine! Use this checklist as a general (and hopefully comprehensive) guide, and create your own list of issues that apply to your context. But most importantly, test and measure your own projects to identify issues before optimizing. Happy performance results in 2021, everyone!
A huge thanks to Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov and Rodney Rehm for reviewing this article, as well as our fantastic community which has shared techniques and lessons learned from its work in performance optimization for everybody to use. Вы действительно сокрушительны!