
Ненадежные тесты: избавление от живого кошмара в тестировании
Опубликовано: 2022-03-10Есть басня, о которой я много думаю в эти дни. Басню рассказали мне в детстве. Он называется «Мальчик, который кричал волком» Эзопа. Речь идет о мальчике, который пасет овец в своей деревне. Ему становится скучно, и он делает вид, что на стаю нападает волк, взывая к сельским жителям о помощи, но они с разочарованием понимают, что это ложная тревога, и оставляют мальчика в покое. Затем, когда на самом деле появляется волк и мальчик зовет на помощь, жители деревни считают, что это еще одна ложная тревога, и не приходят на помощь, и в конечном итоге волк съедает овец.
Мораль этой истории лучше всего резюмирует сам автор:
«Лжецу не поверят, даже если он говорит правду».
Волк нападает на овец, и мальчик взывает о помощи, но после многочисленных лжи ему уже никто не верит. Эту мораль можно применить и к тестированию: история Эзопа — прекрасная аллегория шаблона сопоставления, на который я наткнулся: ненадежные тесты, не дающие никакой ценности.
Front-end тестирование: зачем вообще заморачиваться?
Большую часть времени я трачу на фронтенд-тестирование. Поэтому вас не должно удивлять, что примеры кода в этой статье будут в основном взяты из интерфейсных тестов, с которыми я сталкивался в своей работе. Однако в большинстве случаев их можно легко перевести на другие языки и применить к другим фреймворкам. Так что, надеюсь, статья будет вам полезна — каким бы опытом вы ни обладали.
Стоит напомнить, что такое фронтенд-тестирование. По своей сути фронтенд-тестирование — это набор практик для тестирования пользовательского интерфейса веб-приложения, включая его функциональность.
Начав как инженер по обеспечению качества, я знаю боль бесконечного ручного тестирования по контрольному списку прямо перед выпуском. Таким образом, в дополнение к цели обеспечения того, чтобы приложение оставалось безошибочным во время последовательных обновлений, я стремился уменьшить рабочую нагрузку тестов , вызванную теми рутинными задачами, для которых вам на самом деле не нужен человек. Теперь, как разработчик, я считаю, что эта тема по-прежнему актуальна, особенно когда я пытаюсь напрямую помочь пользователям и коллегам. И, в частности, есть одна проблема с тестированием, которая вызывает у нас кошмары.
Наука ненадежных тестов
Ненадежный тест — это тест, который не может дать один и тот же результат каждый раз при выполнении одного и того же анализа. Сборка будет давать сбой только изредка: один раз она пройдет, другой раз не удастся, в следующий раз снова пройдет, без внесения каких-либо изменений в сборку.
Когда я вспоминаю свои кошмары с испытаниями, мне особенно вспоминается один случай. Это было в тесте пользовательского интерфейса. Мы создали поле со списком в пользовательском стиле (то есть выбираемый список с полем ввода):
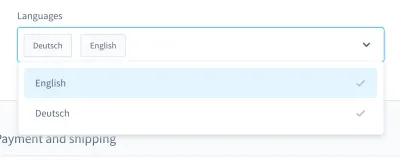
С помощью этого поля со списком вы можете искать продукт и выбирать один или несколько результатов. Много дней этот тест проходил нормально, но в какой-то момент все изменилось. В одной из примерно десяти сборок нашей системы непрерывной интеграции (CI) тест на поиск и выбор продукта в этом поле со списком не прошел.
Скриншот сбоя показывает, что список результатов не фильтруется, несмотря на то, что поиск был успешным:
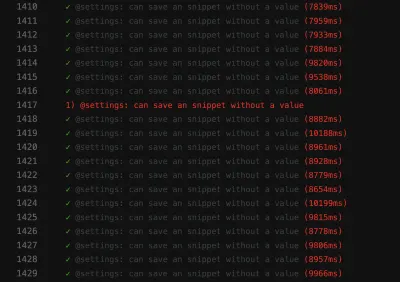
Ненадежный тест, подобный этому , может заблокировать конвейер непрерывного развертывания , из-за чего доставка функций будет медленнее, чем должна быть. Более того, ненадежный тест проблематичен, потому что он больше не является детерминированным, что делает его бесполезным. В конце концов, вы бы доверяли ему не больше, чем лжецу.
Кроме того, ненадежные тесты обходятся дорого в ремонте , на отладку часто требуются часы или даже дни. Несмотря на то, что сквозные тесты более склонны к нестабильности, я сталкивался с ними во всех видах тестов: модульных тестах, функциональных тестах, сквозных тестах и во всем, что между ними.
Еще одна существенная проблема ненадежных тестов — отношение, которое они вызывают у нас, разработчиков. Когда я начал заниматься автоматизацией тестирования, я часто слышал, как разработчики говорят следующее в ответ на неудачный тест:
«Ах, эта постройка. Ничего, просто забей еще раз. В конце концов, когда-нибудь это пройдет».
Это огромный красный флаг для меня . Это показывает мне, что ошибка в сборке не будет воспринята всерьез. Существует предположение, что ненадежный тест — это не настоящая ошибка, а «просто» ненадежный тест, не требующий внимания или даже отладки. Тест все равно потом пройдет снова, верно? Неа! Если такой коммит будет слит, в худшем случае мы получим новый flaky test в продукте.
Причины
Таким образом, ненадежные тесты проблематичны. Что нам с ними делать? Ну, если мы знаем проблему, мы можем разработать контрстратегию.
Я часто сталкиваюсь с причинами в повседневной жизни. Их можно найти в самих тестах . Тесты могут быть написаны неоптимально, содержат неверные предположения или содержат неверные методы. Однако не только это. Ненадежные тесты могут быть признаком чего-то гораздо худшего.
В следующих разделах мы рассмотрим наиболее распространенные из них, с которыми я столкнулся.
1. Причины на стороне теста
В идеальном мире начальное состояние вашего приложения должно быть безупречным и на 100% предсказуемым. На самом деле вы никогда не знаете, всегда ли идентификатор, который вы использовали в своем тесте, будет одним и тем же.
Давайте рассмотрим два примера одного сбоя с моей стороны. Ошибка номер один заключалась в использовании идентификатора в моих тестовых приборах:
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }Ошибка номер два заключалась в поиске уникального селектора для использования в тесте пользовательского интерфейса с мыслью: «Хорошо, этот идентификатор кажется уникальным. Я воспользуюсь этим».
<!-- This is a text field I took from a project I worked on --> <input type="text" />Однако, если бы я запустил тест на другой установке или позже на нескольких сборках в CI, эти тесты могли бы закончиться неудачно. Наше приложение будет генерировать идентификаторы заново, меняя их между сборками. Итак, первая возможная причина — жестко запрограммированные идентификаторы .
Вторая причина может возникнуть из-за случайно (или иным образом) сгенерированных демо-данных . Конечно, вы можете подумать, что этот «недостаток» оправдан — в конце концов, генерация данных случайна, — но подумайте об отладке этих данных. Бывает очень сложно понять, в самих тестах или в демонстрационных данных ошибка.
Далее следует проблема на стороне тестирования, с которой я много раз сталкивался: тесты с перекрестными зависимостями . Некоторые тесты могут не выполняться независимо или в случайном порядке, что создает проблемы. Кроме того, предыдущие тесты могли мешать последующим. Эти сценарии могут вызвать ненадежные тесты из-за появления побочных эффектов.
Однако не забывайте, что тесты — это оспаривание предположений . Что произойдет, если ваши предположения ошибочны с самого начала? Я часто сталкивался с этим, и мне больше всего нравились ошибочные представления о времени.
Одним из примеров является использование неточного времени ожидания, особенно в тестах пользовательского интерфейса, например, с использованием фиксированного времени ожидания . Следующая строка взята из теста Nightwatch.js.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);Еще одно неверное предположение относится к самому времени. Однажды я обнаружил, что ненадежный тест PHPUnit дает сбой только в наших ночных сборках. После некоторой отладки я обнаружил, что виновником был сдвиг во времени между вчера и сегодня. Еще один хороший пример — сбои из-за часовых поясов .
На этом ложные предположения не заканчиваются. У нас также могут быть неверные предположения о порядке данных . Представьте себе сетку или список, содержащий несколько записей с информацией, например список валют:
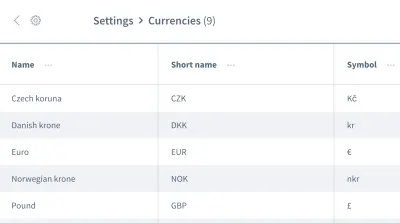
Мы хотим работать с информацией первой записи, валютой «Чешская крона». Можете ли вы быть уверены, что ваше приложение всегда будет размещать этот фрагмент данных в качестве первой записи при каждом выполнении вашего теста? Может ли быть так, что «евро» или другая валюта будет первой записью в некоторых случаях?
Не думайте, что ваши данные будут поступать в том порядке, в котором они вам нужны. Как и в случае с жестко заданными идентификаторами, порядок может меняться между сборками в зависимости от дизайна приложения.
2. Причины, связанные с окружающей средой
Следующая категория причин относится ко всему, что не относится к вашим тестам. В частности, мы говорим о среде, в которой выполняются тесты, зависимостях, связанных с CI и докером, за пределами ваших тестов — на все эти вещи вы едва ли можете повлиять, по крайней мере, в роли тестировщика.
Распространенной причиной на стороне среды является утечка ресурсов : часто это может быть приложение под нагрузкой, вызывающее различное время загрузки или неожиданное поведение. Большие тесты могут легко привести к утечкам, съедающим много памяти. Другой распространенной проблемой является отсутствие очистки .
Несовместимость между зависимостями вызывает у меня, в частности, кошмары. Когда я работал с Nightwatch.js для тестирования пользовательского интерфейса, произошел один кошмар. Nightwatch.js использует WebDriver, который, конечно же, зависит от Chrome. Когда Chrome поторопился с обновлением, возникла проблема с совместимостью: Chrome, WebDriver и сам Nightwatch.js больше не работали вместе, из-за чего наши сборки время от времени давали сбой.
Говоря о зависимостях : почетное упоминание касается любых проблем с npm, таких как отсутствующие разрешения или сбой npm. Я испытал все это, наблюдая за КИ.
Когда дело доходит до ошибок в тестах пользовательского интерфейса из-за проблем с окружающей средой, имейте в виду, что вам нужен весь стек приложений для их запуска. Чем больше вещей задействовано, тем больше вероятность ошибки . Таким образом, тесты JavaScript являются самыми сложными для стабилизации тестами в веб-разработке, поскольку они охватывают большой объем кода.
3. Причины, связанные с продуктом
И последнее, но не менее важное: мы действительно должны быть осторожны с этой третьей областью — областью с реальными ошибками. Я говорю о причинах шелушения на стороне продукта. Одним из самых известных примеров являются условия гонки в приложении. Когда это происходит, ошибку нужно исправлять в продукте, а не в тесте! Попытка исправить тест или среду в этом случае бесполезна.
Способы борьбы с шелушением
Мы выявили три причины шелушения. Мы можем построить нашу контр-стратегию на этом! Конечно, вы уже многого добились, если будете помнить о трех причинах, когда сталкиваетесь с ненадежными тестами. Вы уже будете знать, на что обращать внимание и как улучшить тесты. Однако в дополнение к этому есть некоторые стратегии, которые помогут нам разрабатывать, писать и отлаживать тесты, и мы рассмотрим их вместе в следующих разделах.
Сосредоточьтесь на своей команде
Ваша команда, пожалуй, самый важный фактор . В качестве первого шага признайте, что у вас есть проблема с ненадежными тестами. Получение приверженности всей команды имеет решающее значение! Затем, как команда, вам нужно решить, как бороться с ненадежными тестами.
За годы работы в сфере технологий я столкнулся с четырьмя стратегиями, используемыми командами для борьбы с ненадежностью:

- Ничего не делайте и примите ненадежный результат теста.
Конечно, эта стратегия вовсе не решение. Тест не принесет никакой пользы, потому что вы больше не можете ему доверять, даже если вы принимаете его ненадежность. Так что мы можем пропустить это довольно быстро. - Повторяйте тест, пока он не пройдет.
Эта стратегия была распространена в начале моей карьеры, что привело к реакции, о которой я упоминал ранее. Было некоторое согласие с повторными попытками тестов, пока они не прошли. Эта стратегия не требует отладки, но ленива. Помимо сокрытия симптомов проблемы, это еще больше замедлит ваш набор тестов, что сделает решение нежизнеспособным. Однако из этого правила могут быть некоторые исключения, о которых я объясню позже. - Удалите и забудьте о тесте.
Это говорит само за себя: просто удалите ненадежный тест, чтобы он больше не мешал вашему набору тестов. Конечно, это сэкономит вам деньги, потому что вам больше не нужно будет отлаживать и исправлять тест. Но это происходит за счет потери части тестового покрытия и потери потенциальных исправлений ошибок. Тест существует не просто так! Не стреляйте в мессенджера, удалив тест. - Карантин и исправить.
У меня был наибольший успех с этой стратегией. В этом случае мы бы временно пропустили тест, и набор тестов постоянно напоминал бы нам, что тест был пропущен. Чтобы убедиться, что исправление не будет упущено из виду, мы запланировали тикет на следующий спринт. Напоминания ботов также работают хорошо. Как только проблема, вызывающая нестабильность, будет устранена, мы снова интегрируем (т.е. не пропустим) тест. К сожалению, мы временно потеряем покрытие, но оно вернется с исправлением, так что это не займет много времени.
Эти стратегии помогают нам справляться с проблемами тестирования на уровне рабочего процесса, и я не единственный, кто столкнулся с ними. К аналогичному выводу в своей статье приходит Сэм Саффрон. Но в нашей повседневной работе они помогают нам в ограниченной степени. Итак, как мы поступим, когда перед нами встанет такая задача?
Держите тесты изолированными
При планировании тестовых случаев и структуры всегда изолируйте свои тесты от других тестов, чтобы их можно было запускать в независимом или произвольном порядке. Самый важный шаг — восстановить чистую установку между тестами . Кроме того, тестируйте только тот рабочий процесс, который вы хотите протестировать, и создавайте фиктивные данные только для самого теста. Еще одним преимуществом этого ярлыка является то, что он повышает производительность тестирования . Если вы будете следовать этим пунктам, никакие побочные эффекты от других тестов или остаточные данные не помешают.
Приведенный ниже пример взят из тестов пользовательского интерфейса платформы электронной коммерции и касается входа покупателя в витрину магазина. (Тест написан на JavaScript с использованием фреймворка Cypress.)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): Первый шаг — сброс приложения до чистой установки. Это делается в качестве первого шага в beforeEach жизненного цикла beforeEach, чтобы убедиться, что сброс выполняется каждый раз. После этого тестовые данные создаются специально для теста — для этого тестового примера клиент будет создан с помощью пользовательской команды. Впоследствии мы можем начать с одного рабочего процесса, который мы хотим протестировать: логин клиента.
Дальнейшая оптимизация структуры теста
Мы можем внести некоторые другие небольшие изменения, чтобы сделать нашу тестовую структуру более стабильной. Первый довольно прост: начните с небольших тестов. Как было сказано ранее, чем больше вы делаете в тесте, тем больше может пойти не так. Делайте тесты максимально простыми и избегайте большого количества логики в каждом из них.
Когда дело доходит до непредполагаемого порядка данных (например, при работе с порядком записей в списке при тестировании пользовательского интерфейса), мы можем разработать тест, который будет работать независимо от любого порядка. Чтобы вернуться к примеру сетки с информацией в ней, мы не будем использовать псевдоселекторы или другой CSS, сильно зависящий от порядка. Вместо селектора nth-child(3) мы могли бы использовать текст или другие вещи, для которых порядок не имеет значения. Например, мы могли бы использовать такое утверждение, как «Найди мне элемент с этой текстовой строкой в этой таблице».
Ждать! Повторные попытки тестирования иногда допустимы?
Повторные тесты — спорная тема, и это правильно. Я до сих пор считаю это анти-шаблоном, если тест повторяется вслепую до тех пор, пока он не будет успешным. Однако есть важное исключение: когда вы не можете контролировать ошибки, повторная попытка может быть последним средством (например, чтобы исключить ошибки из внешних зависимостей). В этом случае мы не можем повлиять на источник ошибки. Однако будьте особенно осторожны при этом: не закрывайте глаза на нестабильность при повторной попытке теста и используйте уведомления , чтобы напомнить вам, когда тест пропускается.
Следующий пример я использовал в нашем CI с GitLab. В других средах может быть другой синтаксис для достижения повторных попыток, но это должно дать вам представление:
test: script: rspec retry: max: 2 when: runner_system_failureВ этом примере мы настраиваем, сколько повторных попыток должно быть выполнено в случае сбоя задания. Что интересно, так это возможность повторной попытки в случае ошибки в системе раннера (например, ошибка установки задания). Мы решили повторить нашу работу, только если что-то в настройке докера не работает.
Обратите внимание, что это повторит всю работу при запуске. Если вы хотите повторить только ошибочный тест, вам нужно найти функцию в вашей тестовой среде для поддержки этого. Ниже приведен пример от Cypress, который поддерживает повтор одного теста, начиная с версии 5:
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Вы можете активировать повторные попытки в конфигурационном файле Cypress, cypress.json . Там вы можете определить количество повторных попыток в тестовом прогонщике и безголовом режиме.
Использование динамического времени ожидания
Этот момент важен для всех видов тестов, но особенно для тестирования пользовательского интерфейса. Я не могу не подчеркнуть: никогда не используйте фиксированное время ожидания — по крайней мере, без веской причины. Если вы это сделаете, подумайте о возможных последствиях. В лучшем случае вы выберете слишком долгое время ожидания, что сделает набор тестов медленнее, чем нужно. В худшем случае вы не будете ждать достаточно долго, поэтому тест не будет продолжен, потому что приложение еще не готово, что приведет к нестабильному сбою теста. По моему опыту, это самая распространенная причина нестабильных тестов.
Вместо этого используйте динамическое время ожидания. Есть много способов сделать это, но Cypress справляется с ними особенно хорошо.
Все команды Cypress имеют неявный метод ожидания: они уже проверяют, существует ли элемент, к которому применяется команда, в DOM в течение указанного времени, что указывает на возможность повторных попыток Cypress. Тем не менее, он только проверяет существование и ничего более. Поэтому я рекомендую пойти еще дальше — дождаться любых изменений в пользовательском интерфейсе вашего веб-сайта или приложения, которые также увидит реальный пользователь, например, изменений в самом пользовательском интерфейсе или в анимации.
В этом примере используется явное время ожидания для элемента с селектором .offcanvas . Тест будет продолжаться только в том случае, если элемент виден до указанного времени ожидания, которое вы можете настроить:
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); Еще одна полезная возможность Cypress для динамического ожидания — это его сетевые функции. Да, мы можем дождаться поступления запросов и результатов их ответов. Я использую этот вид ожидания особенно часто. В приведенном ниже примере мы определяем запрос для ожидания, используем команду wait для ожидания ответа и подтверждаем его код состояния:
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);Таким образом, мы можем ждать ровно столько, сколько нужно нашему приложению, что делает тесты более стабильными и менее подверженными нестабильности из-за утечек ресурсов или других проблем со средой.
Отладка ненадежных тестов
Теперь мы знаем, как предотвратить ненадежные тесты по дизайну. Но что, если вы уже имеете дело с ненадежным тестом? Как вы можете избавиться от него?
Когда я занимался отладкой, зацикливание ошибочного теста очень помогло мне выявить ненадежность. Например, если вы запускаете тест 50 раз, и каждый раз он проходит успешно, то вы можете быть более уверены, что тест стабилен — возможно, ваше исправление сработало. Если нет, вы, по крайней мере, можете получить больше информации о ненадежном тесте.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) Получить больше информации об этом ненадежном тесте особенно сложно в CI. Чтобы получить справку, посмотрите, может ли ваша среда тестирования получить дополнительную информацию о вашей сборке. Когда дело доходит до внешнего тестирования, вы обычно можете использовать console.log в своих тестах:
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Этот пример взят из модульного теста Jest, в котором я использую console.log для получения вывода HTML тестируемого компонента. Если вы используете эту возможность ведения журнала в средстве запуска тестов Cypress, вы даже можете проверить вывод в выбранных вами инструментах разработчика. Кроме того, когда дело доходит до Cypress в CI, вы можете проверить этот вывод в журнале вашего CI с помощью плагина.
Всегда смотрите на функции вашей тестовой среды, чтобы получить поддержку с ведением журнала. При тестировании пользовательского интерфейса большинство фреймворков предоставляют функции скриншотов — по крайней мере, в случае сбоя скриншот будет сделан автоматически. Некоторые фреймворки даже обеспечивают запись видео , что может очень помочь в понимании того, что происходит в вашем тесте.
Борьба с кошмарами неуравновешенности!
Важно постоянно выискивать ненадежные тесты, либо предотвращая их в первую очередь, либо отлаживая и исправляя их, как только они появляются. Нам нужно отнестись к ним серьезно, потому что они могут намекать на проблемы в вашем приложении.
Обнаружение красных флажков
Конечно, лучше всего предотвращать ненадежные тесты. Чтобы быстро резюмировать, вот несколько красных флажков:
- Тест большой и содержит много логики.
- Тест охватывает много кода (например, в тестах пользовательского интерфейса).
- Тест использует фиксированное время ожидания.
- Тест зависит от предыдущих тестов.
- Тест утверждает данные, которые не являются предсказуемыми на 100%, например, использование идентификаторов, времени или демонстрационных данных, особенно случайно сгенерированных.
Если вы будете помнить об указателях и стратегиях из этой статьи, вы сможете предотвратить ненадежные тесты до того, как они произойдут. И если они придут, вы будете знать, как их отлаживать и исправлять.
Эти шаги действительно помогли мне восстановить уверенность в нашем наборе тестов. На данный момент наш набор тестов кажется стабильным. В будущем могут возникнуть проблемы — нет ничего идеального на 100%. Эти знания и эти стратегии помогут мне справиться с ними. Таким образом, я буду уверен в своей способности бороться с этими странными кошмарами о тестах .
Надеюсь, мне удалось облегчить хотя бы часть вашей боли и беспокойства по поводу шелушения!
Дальнейшее чтение
Если вы хотите узнать больше по этой теме, вот несколько полезных ресурсов и статей, которые мне очень помогли:
- Статьи о «флейке», Cypress.io
- «Повторение ваших тестов на самом деле полезно (если ваш подход правильный)», Филип Хрик, Cypress.io
- «Нестабильность тестов: методы выявления и устранения нестабильных тестов», Джейсон Палмер, инженер по исследованиям и разработкам Spotify.
- «Ненадежные тесты в Google и как мы их устраняем», Джон Микко, блог тестирования Google.