
Ускоренная загрузка изображений благодаря встроенному предварительному просмотру изображений
Опубликовано: 2022-03-10Предварительный просмотр изображения низкого качества (LQIP) и вариант SQIP на основе SVG являются двумя основными методами отложенной загрузки изображений. Что общего у обоих, так это то, что вы сначала создаете низкокачественное изображение для предварительного просмотра. Это будет отображаться размытым, а затем заменено исходным изображением. Что, если бы вы могли предоставить посетителю веб-сайта изображение для предварительного просмотра без необходимости загрузки дополнительных данных?
Файлы JPEG, для которых в основном используется ленивая загрузка, согласно спецификации имеют возможность хранить содержащиеся в них данные таким образом, что сначала отображается грубое, а затем подробное содержимое изображения. Вместо того, чтобы во время загрузки изображение строилось сверху вниз (базовый режим), можно очень быстро отображать размытое изображение, которое постепенно становится все четче и четче (прогрессивный режим).


В дополнение к лучшему пользовательскому опыту, обеспечиваемому более быстрым отображением, прогрессивные JPEG-файлы обычно также меньше, чем их аналоги с базовым кодированием. По словам Стояна Стефанова из команды разработчиков Yahoo, для файлов размером более 10 КБ существует 94-процентная вероятность уменьшения изображения при использовании прогрессивного режима.
Если ваш веб-сайт состоит из множества файлов JPEG, вы заметите, что даже прогрессивные файлы JPEG загружаются один за другим. Это связано с тем, что современные браузеры допускают только шесть одновременных подключений к домену. Таким образом, одни только прогрессивные JPEG-файлы не являются решением, позволяющим пользователю получить максимально быстрое представление о странице. В худшем случае браузер полностью загрузит изображение, прежде чем начнет загружать следующее.
Идея, представленная здесь, состоит в том, чтобы теперь загружать с сервера столько байтов прогрессивного JPEG, чтобы вы могли быстро получить представление о содержимом изображения. Позже, в определенное нами время (например, когда все изображения для предварительного просмотра в текущем окне просмотра будут загружены), остальная часть изображения должна быть загружена без повторного запроса части, уже запрошенной для предварительного просмотра.

К сожалению, вы не можете указать тегу img в атрибуте, какая часть изображения должна быть загружена в какое время. Однако с Ajax это возможно при условии, что сервер, доставляющий изображение, поддерживает HTTP Range Requests.
Используя запросы диапазона HTTP, клиент может сообщить серверу в заголовке запроса HTTP, какие байты запрошенного файла должны содержаться в ответе HTTP. Эта функция, поддерживаемая всеми крупными серверами (Apache, IIS, nginx), в основном используется для воспроизведения видео. Если пользователь переходит к концу видео, было бы не очень эффективно загружать все видео до того, как пользователь, наконец, увидит желаемую часть. Таким образом, сервер запрашивает только видеоданные во время, запрошенное пользователем, чтобы пользователь мог просмотреть видео как можно быстрее.
Теперь мы сталкиваемся со следующими тремя проблемами:
- Создание прогрессивного JPEG
- Определите смещение в байтах, до которого первый запрос диапазона HTTP должен загрузить изображение предварительного просмотра
- Создание внешнего кода JavaScript
1. Создание прогрессивного JPEG
Прогрессивный JPEG состоит из нескольких так называемых сегментов сканирования, каждый из которых содержит часть конечного изображения. Первое сканирование показывает изображение только очень приблизительно, в то время как последующие в файле добавляют все более и более подробную информацию к уже загруженным данным и, наконец, формируют окончательный вид.
То, как именно выглядят отдельные сканы, определяется программой, которая генерирует файлы JPEG. В программах командной строки, таких как cjpeg из проекта mozjpeg, вы даже можете определить, какие данные содержат эти сканы. Однако для этого требуются более глубокие знания, которые выходят за рамки данной статьи. Для этого я хотел бы сослаться на свою статью «Наконец-то понять JPG», которая учит основам сжатия JPEG. Точные параметры, которые необходимо передать программе в сценарии сканирования, объясняются в файле wizard.txt проекта mozjpeg. На мой взгляд, параметры сценария сканирования (семь сканирований), используемые mozjpeg по умолчанию, являются хорошим компромиссом между быстрой прогрессивной структурой и размером файла и поэтому могут быть приняты.
Чтобы преобразовать наш исходный JPEG в прогрессивный JPEG, мы используем jpegtran из проекта mozjpeg. Это инструмент для внесения изменений без потерь в существующий JPEG. Предварительно скомпилированные сборки для Windows и Linux доступны здесь: https://mozjpeg.codelove.de/binaries.html. Если вы предпочитаете перестраховаться из соображений безопасности, лучше построить их самостоятельно.
Теперь из командной строки мы создаем наш прогрессивный JPEG:
$ jpegtran input.jpg > progressive.jpgТот факт, что мы хотим создать прогрессивный JPEG, предполагается jpegtran и не требует явного указания. Данные изображения не будут изменены никоим образом. Меняется только расположение данных изображения в файле.
Метаданные, не относящиеся к внешнему виду изображения (такие как данные Exif, IPTC или XMP), в идеале должны быть удалены из JPEG, поскольку соответствующие сегменты могут быть прочитаны декодерами метаданных только в том случае, если они предшествуют содержимому изображения. Поскольку по этой причине мы не можем переместить их за данные изображения в файле, они уже будут доставлены с изображением предварительного просмотра и соответствующим образом увеличены в первом запросе. С помощью программы командной строки exiftool вы можете легко удалить эти метаданные:
$ exiftool -all= progressive.jpgЕсли вы не хотите использовать инструмент командной строки, вы также можете использовать онлайн-сервис сжатия Compress-or-die.com для создания прогрессивного JPEG без метаданных.
2. Определите смещение в байтах, до которого первый HTTP-запрос диапазона должен загрузить изображение для предварительного просмотра.
Файл JPEG разделен на разные сегменты, каждый из которых содержит разные компоненты (данные изображения, метаданные, такие как IPTC, Exif и XMP, встроенные цветовые профили, таблицы квантования и т. д.). Каждый из этих сегментов начинается с маркера, представленного шестнадцатеричным байтом FF . За ним следует байт, указывающий тип сегмента. Например, D8 завершает маркер до маркера SOI FF D8 (Start Of Image), с которого начинается каждый файл JPEG.
Каждое начало сканирования отмечается маркером SOS (Start Of Scan, шестнадцатеричное FF DA ). Поскольку данные за маркером SOS закодированы энтропийно (JPEG использует кодирование Хаффмана), существует еще один сегмент с таблицами Хаффмана (DHT, шестнадцатеричный FF C4 ), необходимый для декодирования перед сегментом SOS. Таким образом, интересующая нас область в прогрессивном файле JPEG состоит из чередующихся таблиц Хаффмана/сегментов данных сканирования. Таким образом, если мы хотим отобразить первое очень грубое сканирование изображения, мы должны запросить у сервера все байты до второго вхождения сегмента DHT (шестнадцатеричный FF C4 ).
В PHP мы можем использовать следующий код для чтения количества байтов, необходимых для всех сканирований, в массив:
<?php $img = "progressive.jpg"; $jpgdata = file_get_contents($img); $positions = []; $offset = 0; while ($pos = strpos($jpgdata, "\xFF\xC4", $offset)) { $positions[] = $pos+2; $offset = $pos+2; }Мы должны добавить значение два к найденной позиции, потому что браузер отображает последнюю строку изображения предварительного просмотра только тогда, когда он встречает новый маркер (который, как только что упоминалось, состоит из двух байтов).
Поскольку нас интересует первое изображение предварительного просмотра в этом примере, мы находим правильную позицию в $positions[1] , до которой мы должны запросить файл через запрос диапазона HTTP. Чтобы запросить изображение с лучшим разрешением, мы могли бы использовать более позднюю позицию в массиве, например, $positions[3] .

3. Создание внешнего кода JavaScript
Прежде всего, мы определяем тег img , которому мы присваиваем только что оцененную позицию байта:
<img data-src="progressive.jpg" data-bytes="<?= $positions[1] ?>"> Как это часто бывает с библиотеками отложенной загрузки, мы не определяем атрибут src напрямую, чтобы браузер не начал сразу запрашивать изображение с сервера при разборе HTML-кода.
С помощью следующего кода JavaScript мы теперь загружаем изображение для предварительного просмотра:
var $img = document.querySelector("img[data-src]"); var URL = window.URL || window.webkitURL; var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ $img.src_part = this.response; $img.src = URL.createObjectURL(this.response); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes=0-" + $img.getAttribute('data-bytes')); xhr.responseType = 'blob'; xhr.send(); Этот код создает запрос Ajax, который сообщает серверу в заголовке диапазона HTTP вернуть файл с начала в позицию, указанную в data-bytes ... и не более того. Если сервер понимает HTTP Range Requests, он возвращает двоичные данные изображения в ответе HTTP-206 (HTTP 206 = Partial Content) в виде большого двоичного объекта, из которого мы можем сгенерировать внутренний URL-адрес браузера с помощью createObjectURL . Мы используем этот URL как src для нашего тега img . Таким образом, мы загрузили наше изображение для предварительного просмотра.
Мы храним блоб дополнительно у DOM-объекта в свойстве src_part , потому что эти данные нам понадобятся сразу.
Во вкладке network консоли разработчика можно проверить, что мы загрузили не полный образ, а только небольшую часть. Кроме того, загрузка URL-адреса большого двоичного объекта должна отображаться с размером 0 байт.
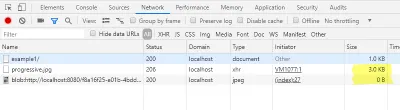
Поскольку мы уже загружаем заголовок JPEG исходного файла, изображение предварительного просмотра имеет правильный размер. Таким образом, в зависимости от приложения мы можем опустить высоту и ширину тега img .
Альтернатива: встроенная загрузка изображения для предварительного просмотра
Из соображений производительности также можно передавать данные изображения предварительного просмотра в виде URI данных непосредственно в исходный код HTML. Это избавляет нас от накладных расходов на передачу заголовков HTTP, но кодировка base64 увеличивает объем данных изображения на треть. Это относительно, если вы доставляете код HTML с кодировкой содержимого, такой как gzip или brotli , но вы все равно должны использовать URI данных для небольших изображений предварительного просмотра.
Гораздо важнее тот факт, что изображения для предварительного просмотра доступны сразу и нет заметной задержки для пользователя при построении страницы.
Прежде всего, мы должны создать URI данных, который затем используем в теге img как src . Для этого мы создаем URI данных через PHP, при этом этот код основан на только что созданном коде, определяющем байтовые смещения маркеров SOS:
<?php … $fp = fopen($img, 'r'); $data_uri = 'data:image/jpeg;base64,'. base64_encode(fread($fp, $positions[1])); fclose($fp); Созданный URI данных теперь напрямую вставляется в тег img как src :
<img src="<?= $data_uri ?>" data-src="progressive.jpg" alt="">Конечно, код JavaScript также должен быть адаптирован:
<script> var $img = document.querySelector("img[data-src]"); var binary = atob($img.src.slice(23)); var n = binary.length; var view = new Uint8Array(n); while(n--) { view[n] = binary.charCodeAt(n); } $img.src_part = new Blob([view], { type: 'image/jpeg' }); $img.setAttribute('data-bytes', $img.src_part.size - 1); </script> Вместо того, чтобы запрашивать данные через Ajax-запрос, где мы сразу получили бы большой двоичный объект, в этом случае мы должны сами создать большой двоичный объект из URI данных. Для этого мы освобождаем data-URI от той части, которая не содержит данных изображения: data:image/jpeg;base64 . Мы декодируем оставшиеся данные в кодировке base64 с помощью команды atob . Чтобы создать большой двоичный объект из теперь двоичных строковых данных, мы должны передать данные в массив Uint8, что гарантирует, что данные не будут обрабатываться как текст в кодировке UTF-8. Теперь из этого массива мы можем создать двоичный BLOB-объект с данными изображения предварительного просмотра.
Чтобы нам не пришлось адаптировать следующий код для этой встроенной версии, мы добавляем атрибут data-bytes в тег img , который в предыдущем примере содержит смещение в байтах, с которого должна быть загружена вторая часть изображения. .
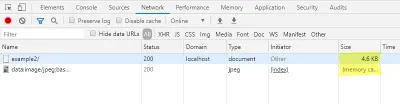
Во вкладке network консоли разработчика здесь же можно проверить, что загрузка изображения превью не генерирует дополнительный запрос, при этом размер файла HTML-страницы увеличился.
Загрузка финального изображения
На втором этапе мы загружаем остальную часть файла изображения через две секунды, например:
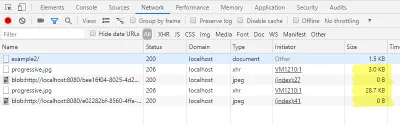
setTimeout(function(){ var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ var blob = new Blob([$img.src_part, this.response], { type: 'image/jpeg'} ); $img.src = URL.createObjectURL(blob); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes="+ (parseInt($img.getAttribute('data-bytes'), 10)+1) +'-'); xhr.responseType = 'blob'; xhr.send(); }, 2000); В заголовке Range на этот раз мы указываем, что хотим запросить изображение от конечной позиции изображения предварительного просмотра до конца файла. Ответ на первый запрос хранится в свойстве src_part объекта DOM. Мы используем ответы от обоих запросов для создания нового большого двоичного объекта для каждого new Blob() , который содержит данные всего изображения. URL-адрес большого двоичного объекта, сгенерированный из этого, снова используется как src объекта DOM. Теперь изображение полностью загружено.
Также теперь мы можем снова проверить загруженные размеры на вкладке сети консоли разработчика.
Прототип
По следующему URL-адресу я предоставил прототип, где вы можете поэкспериментировать с различными параметрами: https://embedded-image-preview.cerdmann.com/prototype/
Репозиторий GitHub для прототипа можно найти здесь: https://github.com/McSodbrenner/embedded-image-preview.
Соображения в конце
Используя представленную здесь технологию Embedded Image Preview (EIP), мы можем загружать качественно разные изображения для предварительного просмотра из прогрессивных JPEG с помощью запросов Ajax и HTTP Range. Данные этих изображений для предварительного просмотра не удаляются, а повторно используются для отображения всего изображения.
Кроме того, не нужно создавать изображения для предварительного просмотра. На стороне сервера необходимо определить и сохранить только смещение в байтах, на котором заканчивается изображение предварительного просмотра. В системе CMS должна быть возможность сохранить этот номер как атрибут изображения и учитывать его при выводе в теге img . Возможен даже рабочий процесс, который дополняет имя файла изображения смещением, например, progress-8343.jpg , чтобы не сохранять смещение отдельно от файла изображения. Это смещение может быть извлечено кодом JavaScript.
Поскольку данные изображения предварительного просмотра используются повторно, этот метод может быть лучшей альтернативой обычному подходу загрузки изображения предварительного просмотра, а затем WebP (и предоставления резервного варианта JPEG для браузеров, не поддерживающих WebP). Изображение для предварительного просмотра часто уничтожает преимущества хранилища WebP, который не поддерживает прогрессивный режим.
В настоящее время изображения предварительного просмотра в обычном LQIP имеют более низкое качество, поскольку предполагается, что для загрузки данных предварительного просмотра требуется дополнительная пропускная способность. Как Робин Осборн уже дал понять в своем блоге в 2018 году, нет особого смысла показывать заполнители, которые не дают вам представления об окончательном изображении. Используя предложенную здесь методику, мы можем без колебаний показать часть окончательного изображения в качестве изображения для предварительного просмотра, представив пользователю более позднее сканирование прогрессивного JPEG.
При слабом сетевом соединении пользователя может иметь смысл, в зависимости от приложения, не загружать весь JPEG, а, например, пропустить два последних скана. Это дает гораздо меньший JPEG с лишь немного сниженным качеством. Пользователь скажет нам за это спасибо, и нам не нужно хранить дополнительный файл на сервере.
А теперь я желаю вам приятного знакомства с прототипом и с нетерпением жду ваших комментариев.