
Обнаружение поддельных новостей в машинном обучении [объяснено на примере кода]
Опубликовано: 2021-02-08Фейковые новости — одна из самых больших проблем в нынешнюю эпоху Интернета и социальных сетей. Хотя это благословение, что новости передаются из одного уголка мира в другой в течение нескольких часов, также неприятно видеть, как многие люди и группы распространяют фальшивые новости.
Методы машинного обучения с использованием обработки естественного языка и глубокого обучения могут в некоторой степени использоваться для решения этой проблемы. В этом руководстве мы создадим модель обнаружения поддельных новостей с использованием машинного обучения.
К концу этой статьи вы будете знать следующее:
- Обработка текстовых данных
- Методы обработки НЛП
- Векторизация счета и TF-IDF
- Делать прогнозы и классифицировать текст новостей
Присоединяйтесь к онлайн- курсу по искусственному интеллекту и машинному обучению в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и продвинутой сертификационной программе по машинному обучению и искусственному интеллекту, чтобы ускорить свою карьеру.
Оглавление
Данные и проблема
Мы будем использовать данные вызова Kaggle Fake News для создания классификатора. Набор данных состоит из 4 функций и 1 бинарной цели. 4 особенности следующие:
- id : уникальный идентификатор новостной статьи
- title : название новостной статьи
- автор : автор новостной статьи
- text : текст статьи; может быть неполным
И целью является «метка», которая содержит двоичные значения 0 и 1. Где 0 означает, что это надежный источник новостей, или, другими словами, не подделка. 1 означает, что это потенциально фальшивая новость и ненадежная. Набор данных у нас состоял из 20800 экземпляров. Давайте погрузимся прямо в.

Предварительная обработка и очистка данных
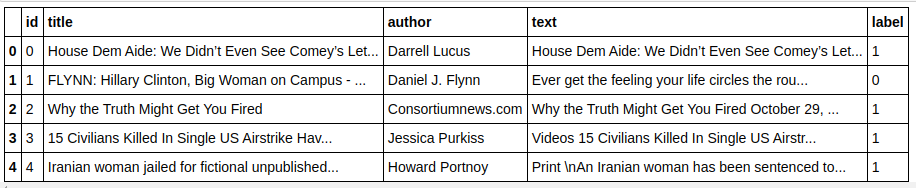
| импортировать панд как pd df=pd.read_csv( 'поддельные новости/поезд.csv' ) дф.голова() |
| X=df.drop( 'label' , axis= 1 ) # Возможности y=df[ 'label' ] # Цель |
Теперь нам нужно удалить экземпляры с отсутствующими данными.
| df=df.dropna() |
![]()
Как мы видим, он отбросил все экземпляры с отсутствующими данными.
| сообщения = df.copy () messages.reset_index (inplace = True ) сообщения.head( 10 ) |
Давайте взглянем на данные один раз.
| сообщения['текст'][6] |

Как мы видим, необходимо выполнить следующие шаги:
- Удаление стоп-слов: есть много слов, которые не добавляют значения любому тексту, независимо от данных. Например, «я», «а», «есть» и т. д. Эти слова не имеют информационной ценности и, следовательно, могут быть удалены, чтобы уменьшить размер нашего корпуса, чтобы мы могли сосредоточиться только на словах/токенах, которые имеют реальную ценность. .
- Основополагающие слова: Стемминг и лемматизация — это методы сведения слов к их основам или корням. Основное преимущество этого шага заключается в уменьшении размера словарного запаса. Например, такие слова, как Play, Playing, Played, будут сокращены до «Play». Stemming просто обрезает слова до самого короткого слова и не принимает во внимание грамматический аспект текста. Лемматизация, с другой стороны, также учитывает грамматику и, следовательно, дает гораздо лучшие результаты. Однако лемматизация обычно выполняется медленнее, чем поиск корней, поскольку она требует обращения к словарю и учета грамматического аспекта.
- Удаление всего, кроме буквенных значений: неалфавитные значения здесь не очень полезны, поэтому их можно удалить. Однако вы можете продолжить исследование, чтобы увидеть, влияет ли наличие числовых или других типов данных на цель.
- Нижний регистр слов: Нижний регистр слов для сокращения словарного запаса.
- Токенизируйте предложения: Генерация токенов из предложений.
| из sklearn.feature_extraction.text импортировать CountVectorizer, TfidfVectorizer, HashingVectorizer из nltk.corpus импортировать стоп-слова из nltk.stem.porter импортировать PorterStemmer импортировать повторно ps = ПортерСтеммер() corpus = [] для i в диапазоне (0, len (сообщения)): обзор = re.sub('[^a-zA-Z]', ' ', messages['text'][i]) обзор = обзор.нижний() обзор = обзор.split() обзор = [ps.stem(слово) для слова в обзоре, если нет слова в стоп-словах.слова('английский')] обзор = ' '.join(обзор) corpus.append(обзор) |
Давайте теперь посмотрим на наш корпус.
| корпус [ 3 ] |
![]()
Как мы видим, слова теперь основаны на корневых словах.
Векторизатор TF-IDF
Теперь нам нужно векторизовать слова в числовые данные, что также называется векторизацией. Самый простой способ векторизации — использовать Bag of Words. Но Bag of Words создает разреженную матрицу и, следовательно, требуется много памяти для обработки. Кроме того, BoW не учитывает частоту слов, что делает его плохим алгоритмом.
TF-IDF (частота терминов — обратная частота документа) — это еще один способ векторизации слов, учитывающий частоты слов. Например, общие слова, такие как «мы», «наш», «тот», присутствуют в каждом документе/экземпляре, поэтому значение BoW будет слишком высоким и, следовательно, вводит в заблуждение. Это приведет к плохой модели. TF-IDF — это произведение частоты термина и обратной частоты документа.
Частота терминов учитывает частоту слов в документе, а обратная частота документов учитывает слова, присутствующие во всем корпусе. Слова, которые присутствуют во всем корпусе, имеют меньшее значение, так как значение IDF намного ниже. Слова, которые присутствуют конкретно в одном документе, имеют высокое значение IDF, что делает общее значение TF-IDF высоким.
| ## Векторизатор TFi df из sklearn.feature_extraction.text импортировать TfidfVectorizer tfidf_v = TfidfVectorizer (max_features = 5000 , ngram_range = ( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'label' ] |
В приведенном выше коде мы импортируем векторизатор TF-IDF из модуля извлечения признаков Sklearn. Мы создаем его объект, передавая max_features как 5000 и ngram_range как (1,3). Параметр max_features определяет максимальное количество векторов признаков, которые мы хотим создать, а параметр ngram_range определяет комбинации ngram, которые мы хотим включить. В нашем случае мы получим 3 комбинации из 1 слова, 2 слов и 3 слов. Давайте посмотрим на некоторые из созданных функций.

| tfidf_v.get_feature_names()[: 20 ] |

Как мы видим, образовалось несколько типов комбинаций. Есть имена функций с 1 токеном, 2 токенами, а также с 3 токенами.
Создание кадра данных
| ## Разделить набор данных на обучающий и тестовый из sklearn.model_selection импорта train_test_split X_train, X_test, y_train, y_test = train_test_split (X, y, test_size = 0,33 , random_state = 0 ) count_df = pd.DataFrame(X_train, columns=tfidf_v.get_feature_names()) count_df.head() |
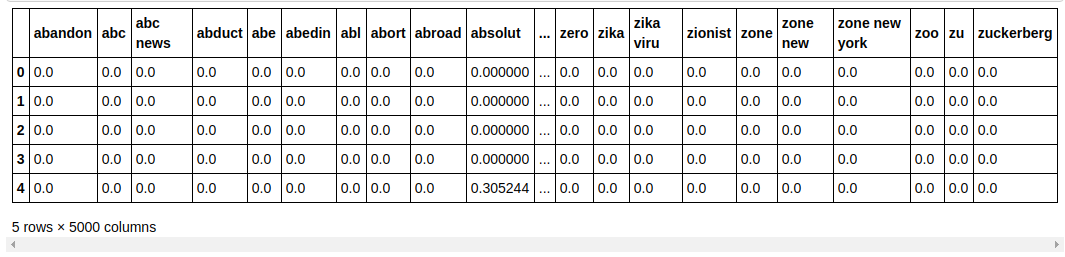
Мы разделяем набор данных на обучение и тестирование, чтобы мы могли проверить производительность модели на невидимых данных. Затем мы создаем новый кадр данных, который содержит в себе новые векторы признаков.
Моделирование и настройка
Полиномиальный алгоритм NB
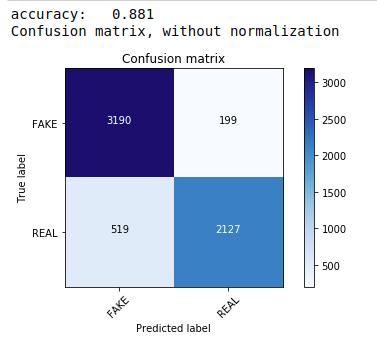
Во-первых, мы используем мультиномиальную наивную теорему Байеса, которая является наиболее распространенным и простым алгоритмом, предпочитаемым для классификации текстовых данных. Мы подходим к обучающим данным и прогнозируем по тестовым данным. Позже мы вычисляем и строим матрицу путаницы и получаем точность 88,1%.
| из sklearn.naive_bayes импортировать MultinomialNB из показателей импорта sklearn импортировать numpy как np импортировать itertools из sklearn.metrics импорта plot_confusion_matrix классификатор = многочленNB() classifier.fit(X_train, y_train) pred = классификатор.predict(X_test) оценка = metrics.accuracy_score (y_test, пред) print( "точность: %0.3f" % оценка) см = metrics.confusion_matrix (y_test, пред) plot_confusion_matrix (см, классы = [ 'FAKE' , 'REAL' ]) |
Полиномиальный классификатор с настройкой гиперпараметров
MultinomialNB имеет параметр альфа, который можно дополнительно настроить. Следовательно, мы запускаем цикл, чтобы опробовать несколько классификаторов MultinomialNB с разными значениями альфа и проверить их оценки точности. И мы проверяем, больше ли текущий счет, чем предыдущий счет. Если да, то устанавливаем классификатор текущим.
| предыдущая_оценка = 0 для альфа в np.arange( 0 , 1 , 0.1 ): sub_classifier = Многочлен NB (альфа = альфа) sub_classifier.fit (X_train, y_train) y_pred=sub_classifier.predict(X_test) оценка = metrics.accuracy_score (y_test, y_pred) если оценка>предыдущая_оценка: классификатор = под_классификатор print( "Alpha: {}, Score: {}" .format(alpha,score)) |
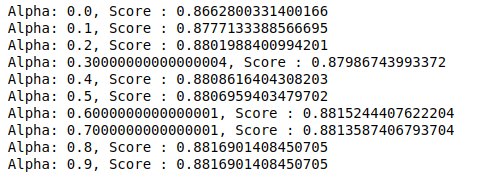
Следовательно, мы видим, что альфа-значение 0,9 или 0,8 дало наивысшую оценку точности.
Интерпретация результатов
Теперь посмотрим, что означают эти значения коэффициентов классификатора. Сначала мы сохраним все имена функций в другой переменной.
| ## Названия G et F eatures feature_names = cv.get_feature_names() |
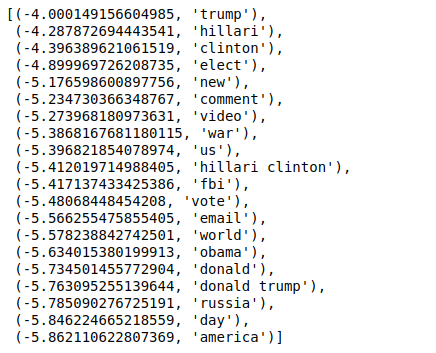
Теперь, когда мы сортируем значения в обратном порядке, мы получаем значения с минимальным значением -4. Они обозначают слова, которые являются наиболее реальными или наименее поддельными.
| ### Самый настоящий sorted(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
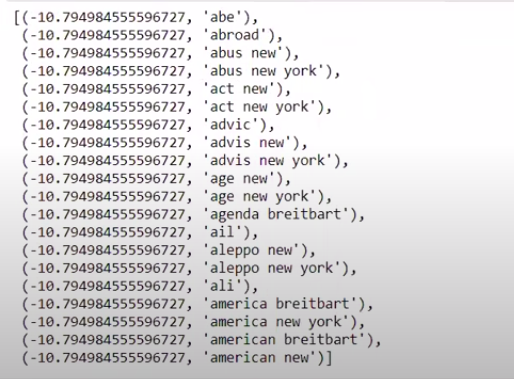
Когда мы сортируем значения в необратном порядке, мы получаем значения с минимальным значением -10. Они обозначают слова, которые являются наименее реальными или наиболее поддельными.
| ### Самый настоящий sorted(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
Заключение
В этом уроке мы использовали только алгоритмы ML, но вы также используете другие методы нейронных сетей. Более того, для векторизации текстовых данных мы использовали векторизатор TF-IDF. Есть больше векторизаторов, таких как Count Vectorizer, Hashing Vectorizer и т. Д., Которые могут лучше выполнять свою работу. Попробуйте и поэкспериментируйте с другими алгоритмами и методами, чтобы увидеть, сможете ли вы добиться лучших результатов или нет.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с программой Executive PG IIIT-B и upGrad по машинному обучению и искусственному интеллекту , которая предназначена для работающих профессионалов и предлагает более 450 часов интенсивного обучения, более 30 тематических исследований и заданий, IIIT -B статус выпускника, 5+ практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Зачем нужно выявлять фейковые новости?
В своем нынешнем состоянии платформы социальных сетей очень эффективны и ценны, поскольку они позволяют пользователям обсуждать и обмениваться идеями, а также обсуждать такие темы, как демократия, образование и здоровье. Тем не менее, некоторые организации плохо используют такие платформы, для получения денежной выгоды в одних обстоятельствах и для создания предвзятых точек зрения, изменения мышления и распространения сатиры или нелепости в других. Фейковые новости — термин для обозначения этого явления. Распространение в Интернете материалов, не соответствующих действительности, привело к множеству проблем в политике, спорте, здравоохранении, науке и других областях.
Какие компании в основном используют обнаружение фейковых новостей?
Обнаружение фальшивых новостей используется на таких платформах, как социальные сети и новостные сайты. Бегемоты социальных сетей, такие как Facebook, Instagram и Twitter, уязвимы для фейковых новостей, поскольку большинство их пользователей полагаются на них как на источники ежедневных новостей, чтобы получать самую свежую информацию. Методы обнаружения фейков также используются медиа-компаниями для определения подлинности имеющейся у них информации. Электронная почта является еще одним средством, через которое люди могут получать новости, что затрудняет идентификацию и проверку их достоверности. Обманы, спам и нежелательная почта хорошо известны тем, что передаются по электронной почте. В результате большинство почтовых платформ используют обнаружение ложных новостей для выявления спама и нежелательной почты.