
Исследовательский анализ данных в Python: что вам нужно знать?
Опубликовано: 2021-03-12Исследовательский анализ данных (EDA) — очень распространенная и важная практика, которой следуют все специалисты по данным. Это процесс просмотра таблиц и таблиц данных под разными углами, чтобы полностью их понять. Получение хорошего понимания данных помогает нам очищать и обобщать их, что затем выявляет идеи и тенденции, которые в противном случае были бы неясны.
В EDA нет жесткого набора правил, которым необходимо следовать, как, например, в «анализе данных». Люди, которые плохо знакомы с этой областью, всегда склонны путать два термина, которые в основном похожи, но различаются по своему назначению. В отличие от EDA, анализ данных больше склоняется к реализации вероятностных и статистических методов для выявления фактов и взаимосвязей между различными вариантами.
Возвращаясь, нет правильного или неправильного способа выполнения EDA. Это варьируется от человека к человеку, однако есть некоторые основные рекомендации, которые обычно соблюдаются, которые перечислены ниже.
- Обработка отсутствующих значений: Нулевые значения могут быть видны, когда не все данные могут быть доступны или записаны во время сбора.
- Удаление повторяющихся данных: важно предотвратить любое переоснащение или смещение, возникающее во время обучения алгоритма машинного обучения с использованием повторяющихся записей данных .
- Обработка выбросов: выбросы — это записи, которые резко отличаются от остальных данных и не следуют тенденции. Может возникнуть из-за определенных исключений или неточностей при сборе данных.
- Масштабирование и нормализация: это делается только для числовых переменных данных. В большинстве случаев переменные сильно различаются по своему диапазону и масштабу, что затрудняет их сравнение и поиск корреляций.
- Одномерный и двумерный анализ. Одномерный анализ обычно проводится путем наблюдения за тем, как одна переменная влияет на целевую переменную. Двумерный анализ проводится между любыми 2 переменными, он может быть либо числовым, либо категориальным, либо тем и другим.
Мы рассмотрим, как некоторые из них реализованы, используя очень известный набор данных «Риск дефолта домашнего кредита», доступный на Kaggle здесь . Данные содержат информацию о соискателе кредита на момент подачи заявки на кредит. Он содержит два типа сценариев:
- Клиент с трудностями оплаты : у него/нее была задержка платежа более чем на X дней
хотя бы на один из первых Y платежей по кредиту в нашей выборке,
- Все остальные случаи : Все остальные случаи, когда оплата производится вовремя.
В этой статье мы будем работать только с файлами данных приложения.
Связанный: Идеи и темы проекта Python для начинающих
Оглавление
Глядя на данные
app_data = pd.read_csv('application_data.csv')
app_data.info()
После чтения данных приложения мы используем функцию info(), чтобы получить краткий обзор данных, с которыми мы будем иметь дело. Вывод ниже сообщает нам, что у нас есть около 300 000 кредитных записей со 122 переменными. Из них 16 категориальных переменных, а остальные числовые.
<класс 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 записей, от 0 до 307510
Столбцы: 122 записи, от SK_ID_CURR до AMT_REQ_CREDIT_BUREAU_YEAR.
dtypes: float64(65), int64(41), объект(16)
использование памяти: 286,2+ МБ
Всегда рекомендуется обрабатывать и анализировать числовые и категориальные данные отдельно.
категориальный = app_data.select_dtypes(include = object).columns
app_data[категориальный].apply(pd.Series.nunique, ось = 0)
Глядя только на категориальные признаки ниже, мы видим, что у большинства из них есть только несколько категорий, которые облегчают их анализ с помощью простых графиков.
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
ИМЯ_HOUSING_TYPE 6
ПРОФЕССИЯ_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ОРГАНИЗАЦИЯ_ТИП 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
тип: int64
Теперь о числовых характеристиках: метод описать() дает нам статистику наших данных:
число= app_data.describe()
числовой= число.столбцы
нумер
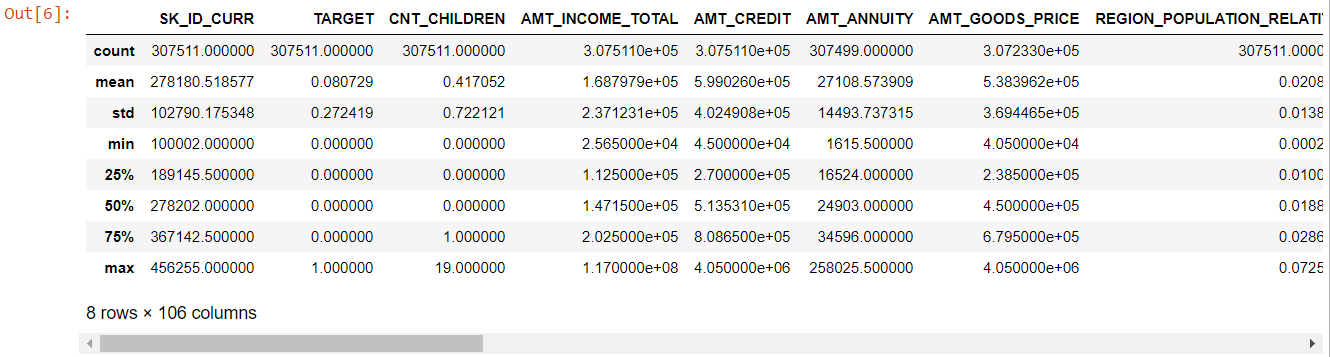
Глядя на всю таблицу, становится очевидным, что:
- days_birth имеет отрицательное значение: возраст заявителя (в днях) по отношению к дню подачи заявки.
- days_employed имеет выбросы (максимальное значение составляет около 100 лет) (635243)
- amt_annuity - означает намного меньше, чем максимальное значение
Итак, теперь мы знаем, какие функции придется анализировать дальше.
Отсутствующие данные
Мы можем построить точечный график всех функций, имеющих пропущенные значения, отложив процент отсутствующих данных по оси Y.
отсутствует = pd.DataFrame((app_data.isnull().sum()) * 100/app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
топор = sns.pointplot («индекс», 0, данные = отсутствуют)
plt.xticks (поворот = 90, размер шрифта = 7)

plt.title («Процент отсутствующих значений»)
plt.ylabel("ПРОЦЕНТ")
plt.show()
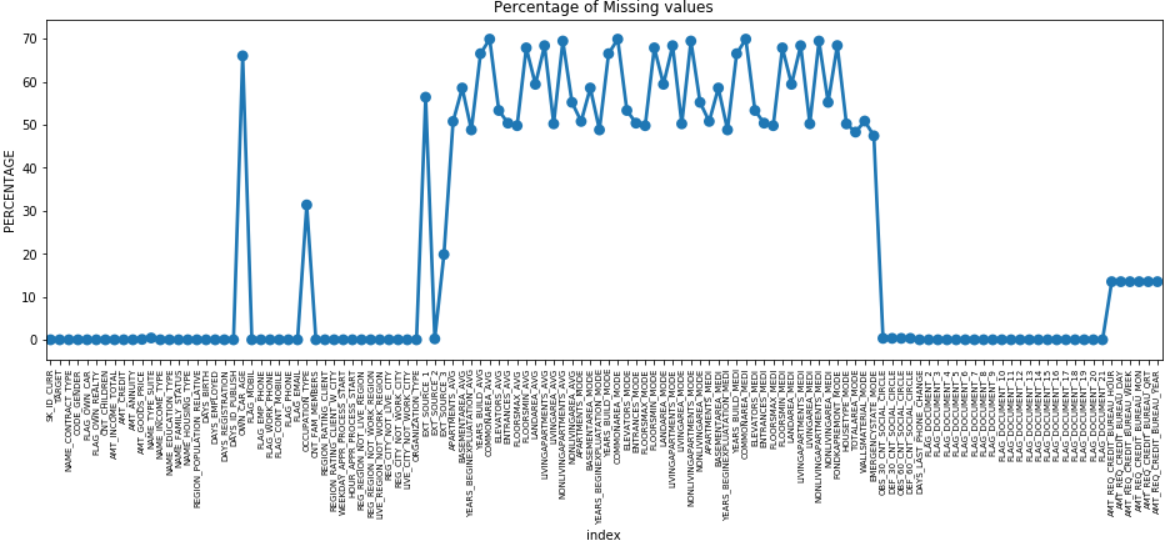
Во многих столбцах много отсутствующих данных (30–70%), в некоторых недостающих данных мало (13–19%), а во многих столбцах вообще нет отсутствующих данных. На самом деле нет необходимости изменять набор данных, когда вам просто нужно выполнить EDA. Однако, приступая к предварительной обработке данных, мы должны знать, как обрабатывать пропущенные значения.
Для функций с меньшим количеством пропущенных значений мы можем использовать регрессию, чтобы предсказать пропущенные значения или заполнить их средним значением имеющихся значений, в зависимости от функции. А для функций с очень большим количеством пропущенных значений лучше отказаться от этих столбцов, так как они дают очень мало информации для анализа.
Дисбаланс данных
В этом наборе данных неплательщики по кредиту идентифицируются с помощью двоичной переменной «TARGET».
100 * app_data['ЦЕЛЬ'].value_counts() / len(app_data['ЦЕЛЬ'])
0 91.927118
1 8.072882
Имя: ЦЕЛЬ, dtype: float64
Мы видим, что данные сильно несбалансированы с соотношением 92:8. Большинство кредитов были возвращены вовремя (цель = 0). Поэтому всякий раз, когда возникает такой огромный дисбаланс, лучше взять характеристики и сравнить их с целевой переменной (целевой анализ), чтобы определить, какие категории в этих характеристиках имеют тенденцию к невыплате кредитов больше, чем другие.
Ниже приведены лишь несколько примеров графиков, которые можно построить с помощью библиотеки Python Seaborn и простых пользовательских функций.
Пол
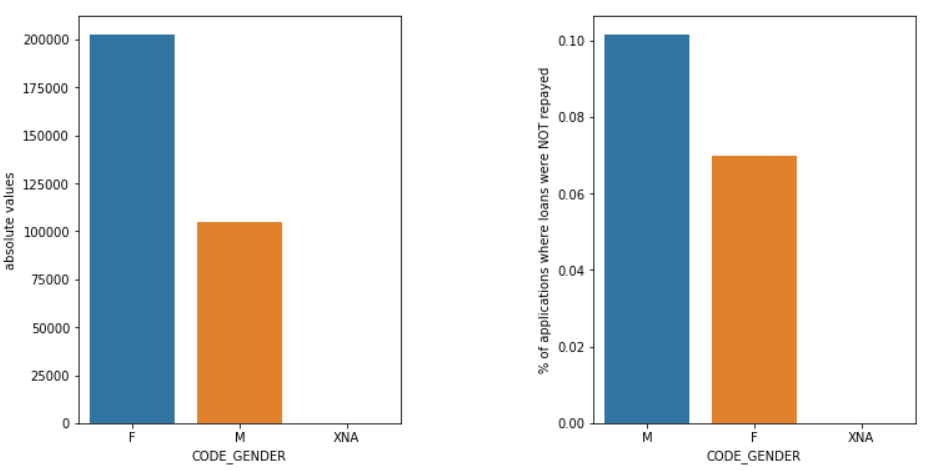
У мужчин (M) больше шансов не заявить о своих правах по сравнению с женщинами (F), даже несмотря на то, что женщин-кандидатов почти в два раза больше. Таким образом, женщины более надежны, чем мужчины, для погашения своих кредитов.
Тип образования
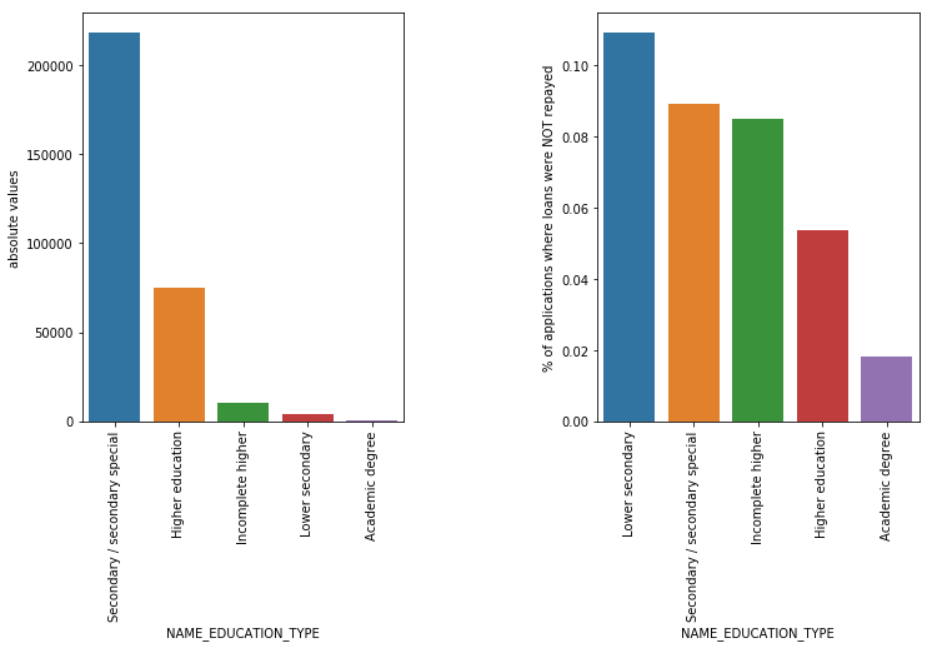
Несмотря на то, что большинство студенческих ссуд предназначены для их среднего образования или высшего образования, именно ссуды на неполное среднее образование являются самыми рискованными для компании, за которыми следует среднее образование.
Читайте также: Карьера в науке о данных
Заключение
Такой вид анализа, показанный выше, широко используется в аналитике рисков в банковских и финансовых услугах. Таким образом, архивы данных можно использовать для минимизации риска потери денег при кредитовании клиентов. Сфера применения EDA во всех других секторах безгранична, и ее следует использовать широко.
Если вам интересно узнать о науке о данных, ознакомьтесь с программой IIIT-B & upGrad Executive PG по науке о данных, которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, 1- on-1 с отраслевыми наставниками, более 400 часов обучения и помощи в трудоустройстве в ведущих фирмах.
Исследовательский анализ данных считается начальным уровнем, когда вы начинаете моделировать свои данные. Это довольно проницательный метод для анализа лучших практик моделирования ваших данных. Вы сможете извлекать визуальные графики, графики и отчеты из данных, чтобы получить полное представление о них. Выбросы относятся к аномалиям или небольшим отклонениям в ваших данных. Это может произойти во время сбора данных. Есть 4 способа, которыми мы можем обнаружить выброс в наборе данных. Эти методы следующие: В отличие от анализа данных, для EDA не существует жестких и быстрых правил и положений, которым необходимо следовать. Нельзя сказать, что это правильный или неправильный метод выполнения EDA. Новичков часто неправильно понимают, и они путаются между EDA и анализом данных.Зачем нужен исследовательский анализ данных (EDA)?
EDA включает в себя определенные шаги для полного анализа данных, включая получение статистических результатов, поиск отсутствующих значений данных, обработку ошибочных записей данных и, наконец, вывод различных графиков и графиков.
Основная цель этого анализа — убедиться, что набор данных, который вы используете, подходит для начала применения алгоритмов моделирования. Вот почему это первый шаг, который вы должны выполнить с вашими данными, прежде чем переходить к этапу моделирования. Что такое выбросы и как с ними бороться?
1. Блочная диаграмма. Блочная диаграмма — это метод обнаружения выбросов, при котором мы разделяем данные по их квартилям.
2. Точечная диаграмма. Точечная диаграмма отображает данные двух переменных в виде набора точек, отмеченных на декартовой плоскости. Значение одной переменной представляет горизонтальную ось (x-ais), а значение другой переменной представляет вертикальную ось (ось y).
3. Z-оценка. При расчете Z-оценки мы ищем точки, которые находятся далеко от центра, и рассматриваем их как выбросы.
4. Межквартильный размах (IQR). Межквартильный размах или IQR представляет собой разницу между верхним и нижним квартилями или 75-м и 25-м квартилями, часто называемую статистической дисперсией. Каковы рекомендации по выполнению EDA?
Тем не менее, есть некоторые рекомендации, которые обычно практикуются:
1. Обработка пропущенных значений
2. Удаление повторяющихся данных
3. Обработка выбросов
4. Масштабирование и нормализация
5. Одномерный и двумерный анализ