
Что такое исследовательский анализ данных в Python? Учиться с нуля
Опубликовано: 2021-03-04Короче говоря, исследовательский анализ данных или EDA составляет почти 70% проекта Data Science. EDA — это процесс изучения данных с использованием различных инструментов аналитики для получения выводной статистики из данных. Эти исследования выполняются либо путем просмотра простых чисел, либо путем построения графиков и диаграмм различных типов.
Каждый график или диаграмма изображают разные истории и точки зрения на одни и те же данные. Для большей части анализа и очистки данных наиболее часто используемым инструментом является Pandas. Для визуализации и построения графиков/диаграмм используются графические библиотеки, такие как Matplotlib, Seaborn и Plotly.
EDA крайне необходимо проводить, так как он заставляет данные признаться вам. Data Scientist, который делает очень хороший EDA, много знает о данных, и, следовательно, модель, которую он построит, будет автоматически лучше, чем Data Scientist, который не делает хорошего EDA.
К концу этого урока вы будете знать следующее:
- Проверка основного обзора данных
- Проверка описательной статистики данных
- Управление именами столбцов и типами данных
- Обработка пропущенных значений и повторяющихся строк
- Двумерный анализ
Оглавление
Базовый обзор данных
В этом уроке мы будем использовать набор данных Cars, который можно загрузить с Kaggle. Первым шагом почти для любого набора данных является его импорт и проверка его основного обзора — его формы, столбцов, типов столбцов, первых 5 строк и т. д. Этот шаг дает вам краткий обзор данных, с которыми вы будете работать. Давайте посмотрим, как это сделать в Python.
| # Импорт необходимых библиотек импортировать панд как pd импортировать numpy как np импортировать Seaborn как sns #visualisation импортировать matplotlib.pyplot как plt #visualisation %matplotlib встроенный sns.set (color_codes = Истина ) |
Голова и хвост данных
| данные = pd.read_csv ( «путь/набор данных.csv» ) # Проверяем верхние 5 строк фрейма данных данные.голова() |
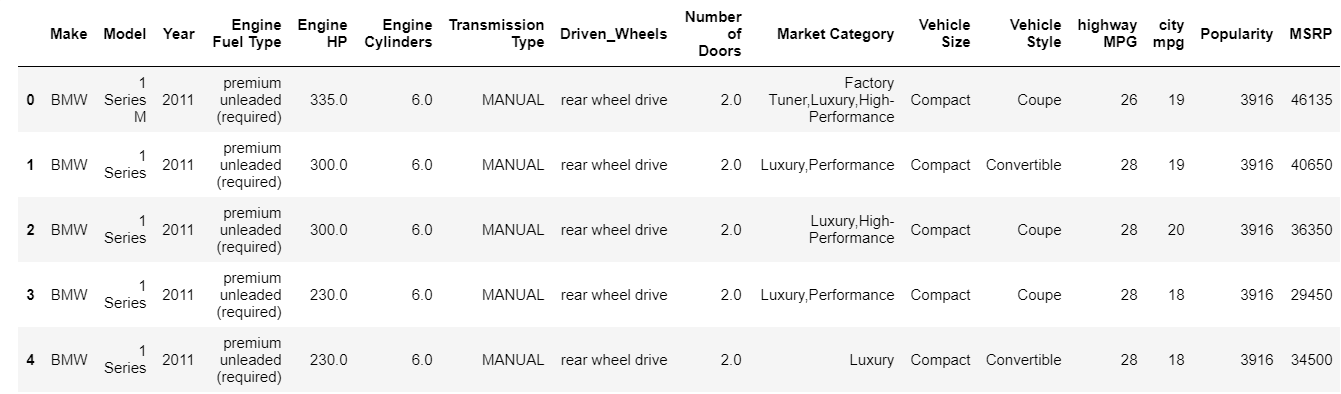
Функция head по умолчанию печатает 5 верхних индексов фрейма данных. Вы также можете указать, сколько верхних индексов вам нужно увидеть, минуя это значение в голове. Печать головы мгновенно дает нам быстрый взгляд на то, какой тип данных у нас есть, какие типы функций присутствуют и какие значения они содержат. Конечно, это не раскрывает всей истории данных, но позволяет быстро взглянуть на данные. Вы можете аналогичным образом распечатать нижнюю часть фрейма данных, используя функцию хвоста.
| # Печатаем последние 10 строк фрейма данных данные.хвост( 10 ) |
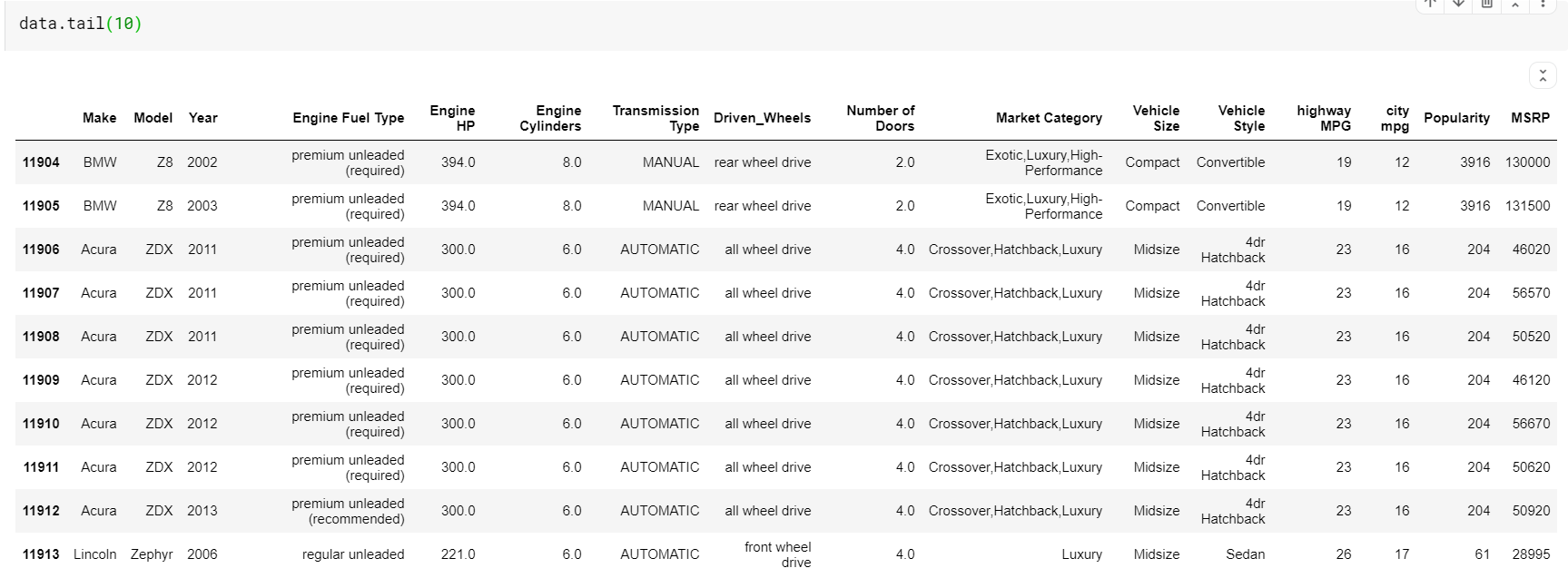
Здесь следует обратить внимание на то, что обе функции — head и tail — дают нам верхний или нижний индексы. Но верхняя или нижняя строки не всегда являются хорошим предварительным просмотром данных. Таким образом, вы также можете распечатать любое количество строк, случайно выбранных из набора данных, с помощью функции sample().
| # Напечатать 5 случайных строк data.sample( 5 ) |
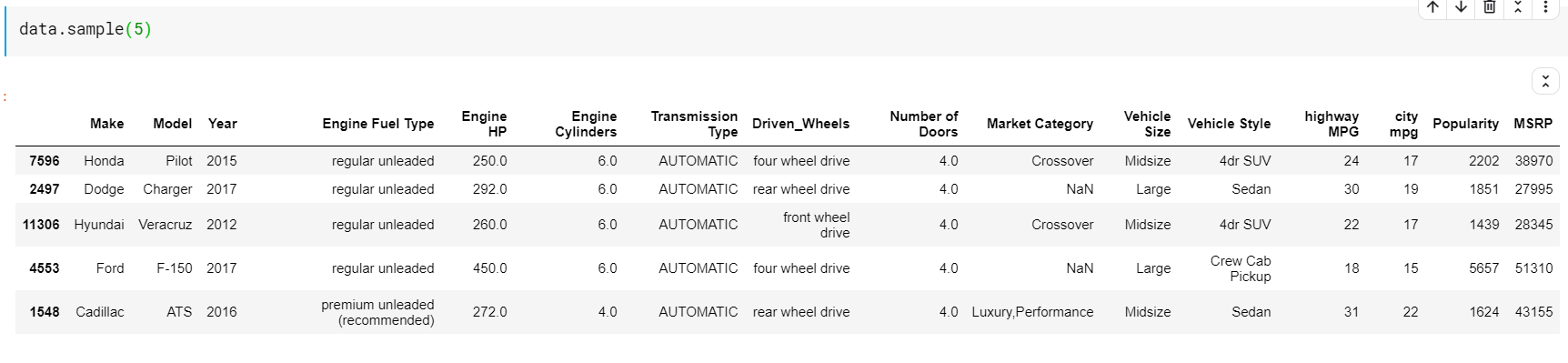
Описательная статистика
Далее давайте проверим описательную статистику набора данных. Описательная статистика состоит из всего, что «описывает» набор данных. Мы проверяем форму фрейма данных, какие все столбцы присутствуют, какие есть все числовые и категориальные признаки. Мы также увидим, как все это сделать в простых функциях.
Форма
| # Проверка формы кадра данных (mxn) # m=количество строк # n=количество столбцов данные.форма |

Как мы видим, этот фрейм данных содержит 11914 строк и 16 столбцов.
Столбцы
| # Напечатать имена столбцов столбцы данных |
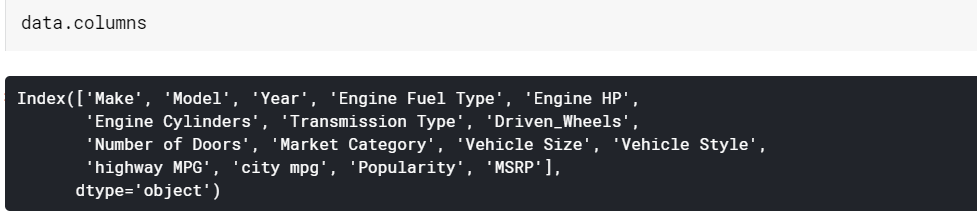
Информация о фрейме данных
| # Вывести типы данных столбца и количество непропущенных значений данные.информация() |
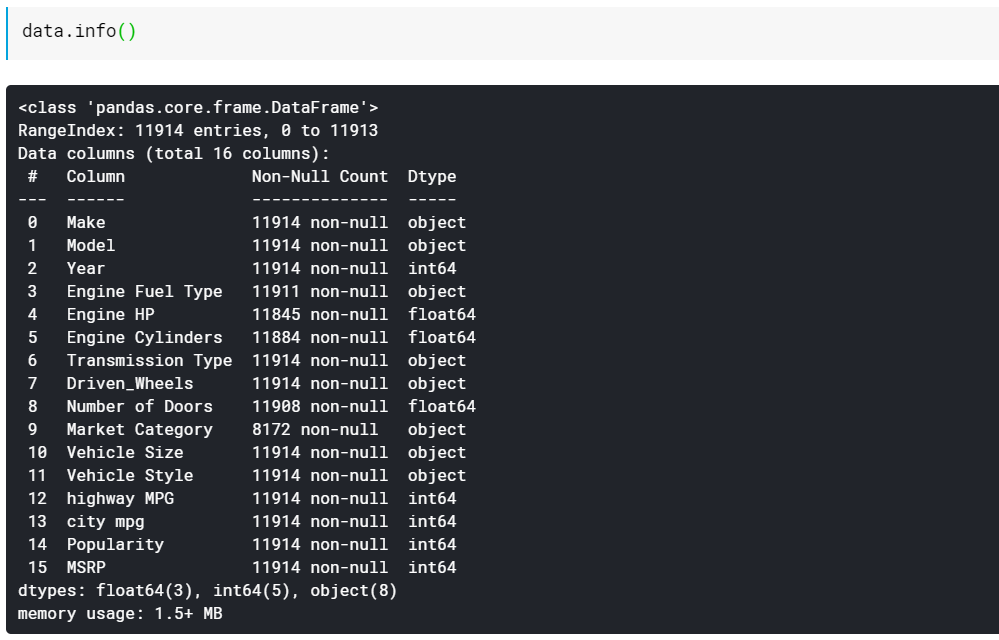
Как видите, функция info() дает нам все столбцы, сколько ненулевых или не пропущенных значений в этих столбцах и, наконец, тип данных этих столбцов. Это хороший быстрый способ увидеть, какие функции являются числовыми, а какие — категориальными/текстовыми. Кроме того, теперь у нас есть информация о том, в каких столбцах отсутствуют значения. Позже мы рассмотрим, как работать с пропущенными значениями.
Управление именами столбцов и типами данных
Тщательная проверка и манипулирование каждым столбцом чрезвычайно важны в EDA. Нам нужно увидеть, какой тип содержимого содержит столбец/функция и какие типы данных Pandas прочитали. Типы числовых данных в основном int64 или float64. Текстовым или категориальным функциям назначается тип данных «объект».
Назначаются функции на основе даты и времени. Бывают случаи, когда Pandas не понимает тип данных функции. В таких случаях он просто лениво присваивает ему тип данных «объект». Мы можем явно указать типы данных столбца при чтении данных с помощью read_csv.
Выбор категориальных и числовых столбцов
| # Добавить все категориальные и числовые столбцы в отдельные списки категориальный = data.select_dtypes( 'объект' ).columns числовой = data.select_dtypes( 'число' ).columns |

Здесь тип, который мы передали как «число», выбирает все столбцы с типами данных, которые имеют любое число — будь то int64 или float64.

Переименование столбцов
| # Переименование имен столбцов data = data.rename(columns={ «Мощность двигателя» : «HP» , «Цилиндры двигателя» : «Цилиндры» , «Тип передачи» : «Передача» , «Driven_Wheels» : «Режим движения» , «Шоссе MPG» : «MPG-H» , «Рекомендованная розничная цена» : «Цена» }) данные.голова( 5 ) |

Функция переименования просто принимает словарь с именами столбцов, которые нужно переименовать, и их новыми именами.
Обработка пропущенных значений и повторяющихся строк
Отсутствующие значения — одна из наиболее распространенных проблем/несоответствий в любом реальном наборе данных. Обработка пропущенных значений сама по себе является обширной темой, поскольку существует несколько способов сделать это. Некоторые способы являются более общими, а некоторые более специфичны для набора данных, с которым можно иметь дело.
Проверка пропущенных значений
| # Проверка пропущенных значений данные.isnull().сумма() |
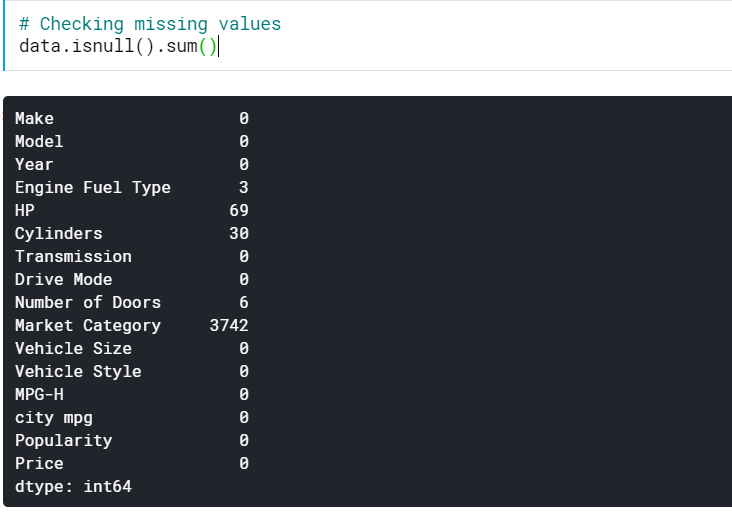
Это дает нам количество значений, отсутствующих во всех столбцах. Мы также можем увидеть процент отсутствующих значений.
| # Процент пропущенных значений данные.isnull().среднее()* 100 |
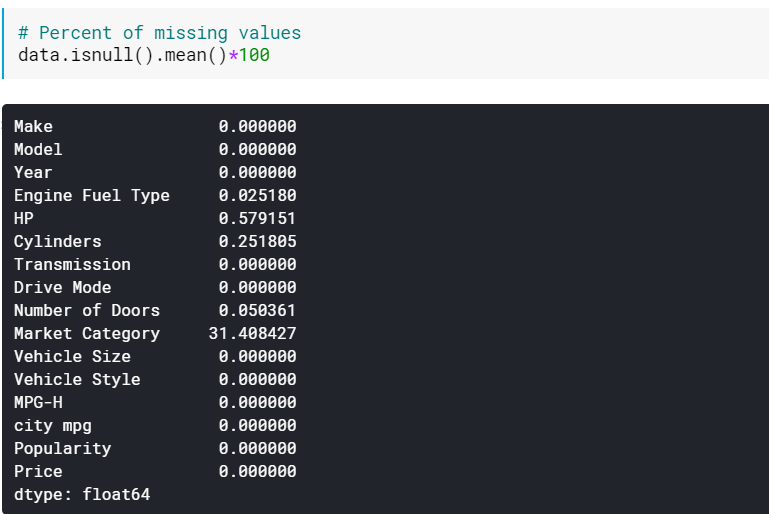
Проверка процентов может быть полезна, когда во многих столбцах отсутствуют значения. В таких случаях столбцы с большим количеством отсутствующих значений (например, отсутствующих > 60%) можно просто удалить.
Вменение пропущенных значений
| #Ввод отсутствующих значений числовых столбцов по среднему значению данные[числовые] = данные[числовые].fillna(данные[числовые].среднее().iloc[ 0 ]) #Ввод отсутствующих значений категориальных столбцов по режиму данные[категориальные] = данные[категориальные].fillna(данные[категориальные].mode().iloc[ 0 ]) |
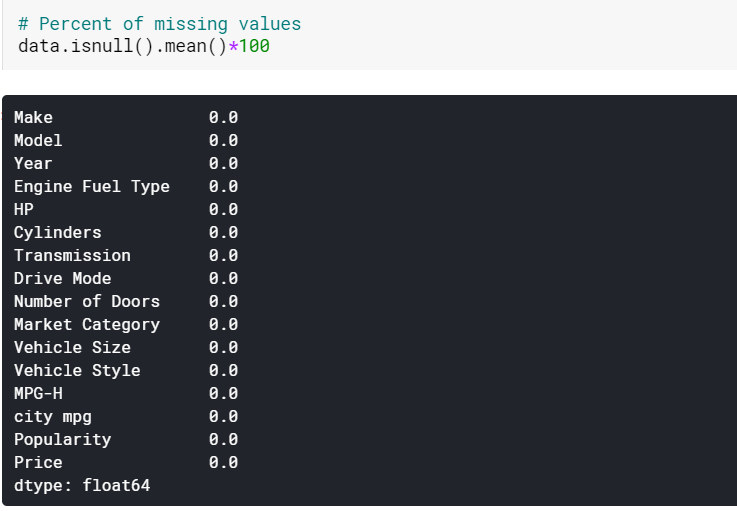
Здесь мы просто вменяем пропущенные значения в числовых столбцах по их соответствующим значениям, а значения в категориальных столбцах — по их модусам. И как мы видим, пропущенных значений теперь нет.
Обратите внимание, что это самый примитивный способ вменения значений и не работает в реальных случаях, когда разработаны более изощренные способы, например, интерполяция, KNN и т.д.
Обработка повторяющихся строк
| # Удалить повторяющиеся строки data.drop_duplicates (inplace = True ) |
Это просто удаляет повторяющиеся строки.
Оформить заказ: идеи и темы проекта Python
Двумерный анализ
Теперь давайте посмотрим, как получить больше информации, выполнив двумерный анализ. Двумерный означает анализ, который состоит из 2 переменных или признаков. Существуют различные типы графиков, доступных для различных типов объектов.
Для числового – числовой
- График рассеяния
- Линейный сюжет
- Тепловая карта для корреляций
Для категориально-числового
- Гистограмма
- Сюжет для скрипки
- Сюжет роя
Категорически-категорично
- Гистограмма
- Точечный сюжет
Тепловая карта для корреляций
| # Проверка корреляций между переменными. plt.figure(figsize=( 15 , 10 )) c= данные.corr() sns.heatmap (c, cmap = «BrBG» , annot = True ) |
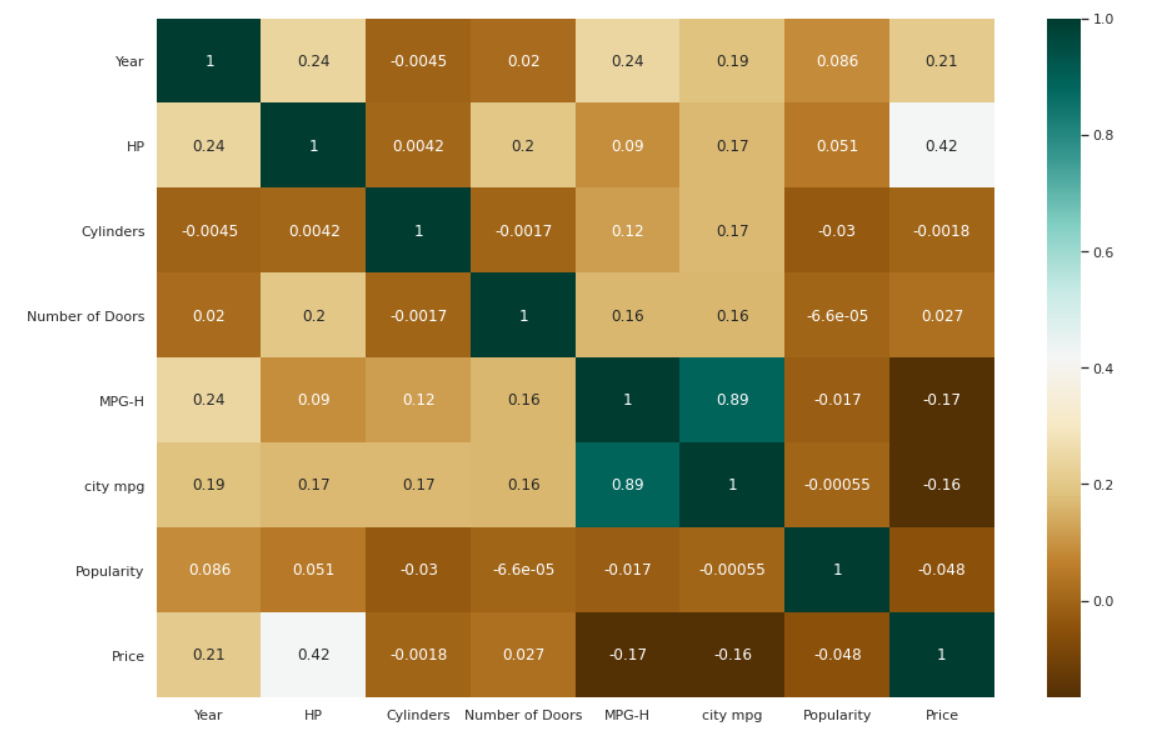
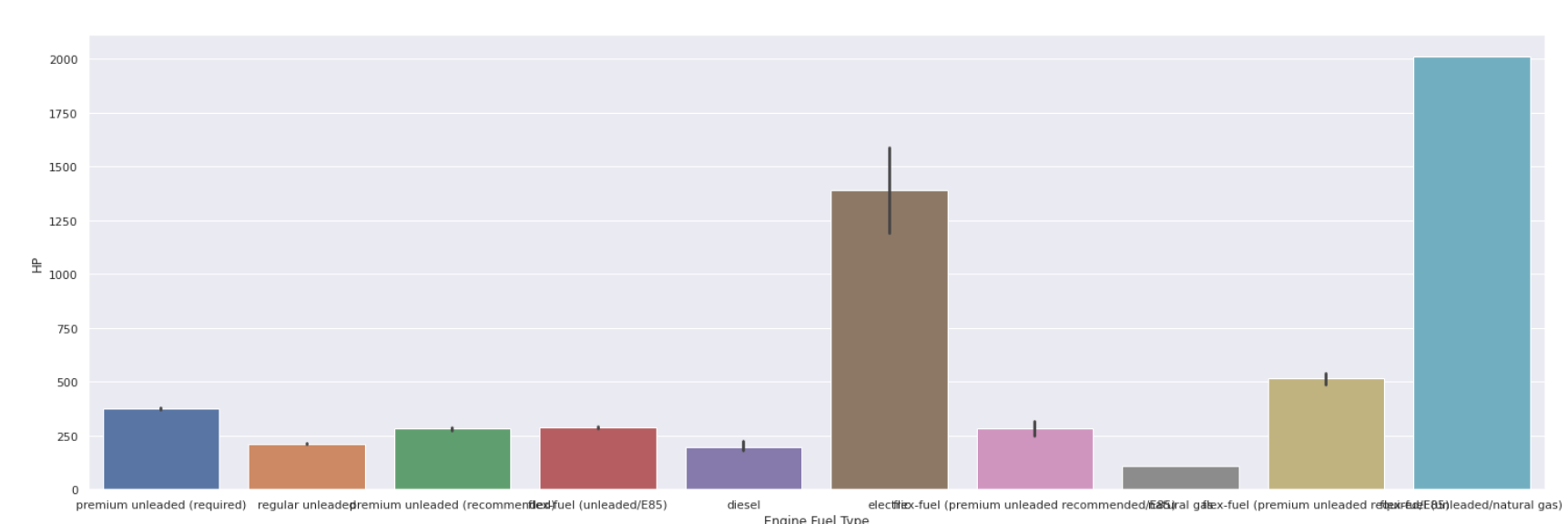
Бар Участок
| sns.barplot(data[ 'Тип топлива двигателя' ], data[ 'HP' ]) |
Получите сертификат по науке о данных от лучших университетов мира. Изучите программы Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Заключение
Как мы видели, при изучении набора данных необходимо выполнить множество шагов. В этом руководстве мы рассмотрели лишь несколько аспектов, но это даст вам больше, чем просто базовые знания о хорошем EDA.
Если вам интересно узнать о Python, все о науке о данных, ознакомьтесь с дипломом IIIT-B & upGrad PG по науке о данных, который создан для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические практические семинары, наставничество в отрасли. экспертов, общение один на один с отраслевыми наставниками, более 400 часов обучения и помощь в трудоустройстве в ведущих фирмах.
Каковы этапы исследовательского анализа данных?
Основные шаги, которые необходимо выполнить для проведения исследовательского анализа данных:
Переменные и типы данных должны быть идентифицированы.
Анализ основных показателей
Одномерный неграфический анализ
Одномерный графический анализ
Анализ двумерных данных
Преобразования, которые являются переменными
Обработка пропущенного значения
Обработка выбросов
Анализ корреляции
Уменьшение размерности
Какова цель исследовательского анализа данных?
Основная цель EDA — помочь в анализе данных, прежде чем делать какие-либо предположения. Это может помочь в обнаружении очевидных ошибок, а также в лучшем понимании шаблонов данных, обнаружении выбросов или необычных событий, а также в обнаружении интересных взаимосвязей между переменными.
Исследователи данных могут использовать исследовательский анализ, чтобы гарантировать, что создаваемые ими результаты точны и соответствуют любым намеченным бизнес-результатам и целям. EDA также помогает заинтересованным сторонам, гарантируя, что они решают соответствующие вопросы. Стандартные отклонения, категориальные данные и доверительные интервалы можно получить с помощью EDA. После завершения EDA и извлечения информации его функции могут быть применены к более сложному анализу данных или моделированию, включая машинное обучение.
Какие существуют виды исследовательского анализа данных?
Существует два вида методов EDA: графические и количественные (неграфические). Количественный подход, с другой стороны, требует составления сводной статистики, в то время как графические методы подразумевают сбор данных в виде диаграммы или визуального представления. Одномерный и многомерный подходы являются подмножествами этих двух типов методологий.
Чтобы исследовать отношения, одномерные подходы рассматривают одну переменную (столбец данных) за раз, тогда как многомерные методы рассматривают две или более переменных одновременно. Одномерные и многомерные графические и неграфические - это четыре формы EDA. Количественные методы более объективны, тогда как изобразительные методы более субъективны.