
Руководство по этичному парсингу динамических веб-сайтов с помощью Node.js и Puppeteer
Опубликовано: 2022-03-10Давайте начнем с небольшого раздела о том, что на самом деле означает веб-скрапинг. Все мы используем парсинг в повседневной жизни. Он просто описывает процесс извлечения информации с веб-сайта. Следовательно, если вы копируете и вставляете рецепт вашего любимого блюда из лапши из Интернета в свой личный блокнот, вы выполняете веб-скрейпинг .
При использовании этого термина в индустрии программного обеспечения мы обычно имеем в виду автоматизацию этой ручной задачи с помощью программного обеспечения. Придерживаясь нашего предыдущего примера с блюдом из лапши, этот процесс обычно включает два этапа:
- Получение страницы
Сначала нам нужно загрузить страницу целиком. Этот шаг аналогичен открытию страницы в веб-браузере при очистке вручную. - Разбор данных
Теперь нам нужно извлечь рецепт из HTML-кода веб-сайта и преобразовать его в машиночитаемый формат, такой как JSON или XML.
В прошлом я работал во многих компаниях в качестве консультанта по данным. Я был поражен, увидев, как много задач по извлечению, агрегации и обогащению данных по-прежнему выполняются вручную, хотя их легко можно автоматизировать всего несколькими строками кода. Это именно то, что для меня означает веб-скрапинг: извлечение и нормализация ценных фрагментов информации с веб-сайта для подпитки другого бизнес-процесса, создающего ценность.
За это время я видел, как компании используют парсинг в самых разных случаях. Инвестиционные фирмы были в основном сосредоточены на сборе альтернативных данных, таких как обзоры продуктов , информация о ценах или сообщения в социальных сетях, для поддержки своих финансовых вложений.
Вот один пример. Клиент обратился ко мне с просьбой собрать данные обзора продуктов для обширного списка продуктов с нескольких веб-сайтов электронной коммерции, включая рейтинг, местонахождение рецензента и текст обзора для каждого отправленного обзора. Полученные данные позволили клиенту определить тенденции популярности продукта на различных рынках. Это отличный пример того, как, казалось бы, «бесполезная» отдельная информация может стать ценной по сравнению с большим количеством.
Другие компании ускоряют процесс продаж, используя веб- скрапинг для лидогенерации. Этот процесс обычно включает в себя извлечение контактной информации, такой как номер телефона, адрес электронной почты и имя контакта для данного списка веб-сайтов. Автоматизация этой задачи дает отделам продаж больше времени для работы с потенциальными клиентами. Следовательно, повышается эффективность процесса продаж.
Придерживайтесь правил
В целом, веб-скрапинг общедоступных данных является законным, что подтверждается юрисдикцией дела Linkedin против HiQ. Тем не менее, я установил для себя этический набор правил, которых мне хотелось бы придерживаться при запуске нового проекта веб-скрейпинга. Это включает в себя:
- Проверка файла robots.txt.
Обычно он содержит четкую информацию о том, к каким частям сайта владелец страницы может получить доступ для роботов и парсеров, и выделяет разделы, к которым доступ запрещен. - Читаем условия.
По сравнению с robots.txt, эта часть информации доступна не реже, но обычно указывает, как они относятся к парсерам данных. - Стирание с умеренной скоростью.
Скрапинг создает серверную нагрузку на инфраструктуру целевого сайта. В зависимости от того, что вы очищаете, и на каком уровне параллелизма работает ваш парсер, трафик может вызвать проблемы для серверной инфраструктуры целевого сайта. Конечно, большую роль в этом уравнении играет мощность сервера. Следовательно, скорость моего парсера всегда является балансом между объемом данных, которые я собираюсь собрать, и популярностью целевого сайта. Найти этот баланс можно, ответив на один-единственный вопрос: «Существенно ли запланированная скорость изменит органический трафик сайта?». В тех случаях, когда я не уверен в объеме естественного трафика сайта, я использую такие инструменты, как Ahrefs, чтобы получить приблизительное представление.
Выбор правильной технологии
На самом деле парсинг с помощью безголового браузера — одна из наименее производительных технологий, которые вы можете использовать, поскольку она сильно влияет на вашу инфраструктуру. Одно ядро процессора вашего компьютера может приблизительно обрабатывать один экземпляр Chrome.
Давайте сделаем быстрый пример расчета , чтобы увидеть, что это означает для реального проекта веб-скрейпинга.
Сценарий
- Вы хотите очистить 20 000 URL-адресов.
- Среднее время отклика с целевого сайта составляет 6 секунд.
- Ваш сервер имеет 2 ядра процессора.
Работа над проектом займет 16 часов .
Следовательно, я всегда стараюсь избегать использования браузера при проведении проверки осуществимости парсинга для динамического веб-сайта.
Вот небольшой контрольный список, который я всегда просматриваю:
- Могу ли я форсировать требуемое состояние страницы с помощью GET-параметров в URL-адресе? Если да, мы можем просто запустить HTTP-запрос с добавленными параметрами.
- Является ли динамическая информация частью источника страницы и доступна ли она через объект JavaScript где-то в DOM? Если да, мы снова можем использовать обычный HTTP-запрос и парсить данные из строкового объекта.
- Данные извлекаются через XHR-запрос? Если да, могу ли я получить прямой доступ к конечной точке с помощью HTTP-клиента? Если да, мы можем отправить HTTP-запрос на конечную точку напрямую. Часто ответ даже отформатирован в формате JSON, что значительно упрощает нашу жизнь.
Если на все вопросы ответить однозначным «Нет», мы официально исчерпали возможные варианты использования HTTP-клиента. Конечно, может быть больше настроек для конкретных сайтов, которые мы могли бы попробовать, но обычно время, необходимое для их понимания, слишком велико по сравнению с более низкой производительностью безголового браузера. Прелесть парсинга в браузере в том, что вы можете парсить все, что подчиняется следующему основному правилу:
Если вы можете получить к нему доступ через браузер, вы можете очистить его.
В качестве примера для нашего парсера возьмем следующий сайт: https://quotes.toscrape.com/search.aspx. Он содержит цитаты из списка заданных авторов по списку тем. Все данные извлекаются через XHR.
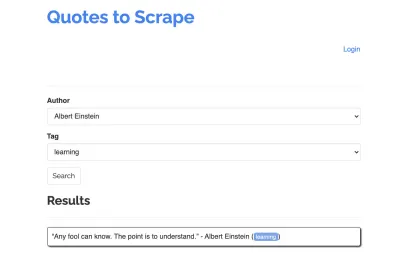
Тот, кто внимательно изучил функционирование сайта и прошел контрольный список выше, вероятно, понял, что котировки на самом деле могут быть извлечены с помощью HTTP-клиента, поскольку их можно получить, отправив POST-запрос на конечную точку котировок напрямую. Но поскольку в этом руководстве предполагается, как очистить веб-сайт с помощью Puppeteer, мы притворимся, что это невозможно.
Установка необходимых компонентов
Поскольку мы собираемся строить все с помощью Node.js, давайте сначала создадим и откроем новую папку, а внутри создадим новый проект Node, выполнив следующую команду:
mkdir js-webscraper cd js-webscraper npm initПожалуйста, убедитесь, что вы уже установили npm. Установщик задаст нам несколько вопросов о мета-информации об этом проекте, которые мы все можем пропустить, нажав Enter .
Установка Кукловода
Мы уже говорили о парсинге с помощью браузера. Puppeteer — это API Node.js, который позволяет нам программно взаимодействовать с безголовым экземпляром Chrome .
Давайте установим его с помощью npm:
npm install puppeteerСоздание нашего скребка
Теперь давайте начнем создавать наш парсер, создав новый файл с именем scraper.js .
Сначала мы импортируем ранее установленную библиотеку Puppeteer:
const puppeteer = require('puppeteer');В качестве следующего шага мы говорим Puppeteer открыть новый экземпляр браузера внутри асинхронной и самовыполняющейся функции:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Примечание . По умолчанию безголовый режим отключен, так как это повышает производительность. Однако при создании нового парсера мне нравится отключать безголовый режим. Это позволяет нам следить за процессом, через который проходит браузер, и видеть весь отображаемый контент. Это поможет нам отладить наш скрипт позже.
Внутри нашего открытого экземпляра браузера мы теперь открываем новую страницу и направляемся к нашему целевому URL-адресу:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Как часть асинхронной функции, мы будем использовать оператор await для ожидания выполнения следующей команды, прежде чем переходить к следующей строке кода.
Теперь, когда мы успешно открыли окно браузера и перешли на страницу, мы должны создать состояние веб-сайта , чтобы нужные фрагменты информации стали видимыми для очистки.
Доступные темы генерируются динамически для выбранного автора. Следовательно, мы сначала выберем «Альберт Эйнштейн» и дождемся сгенерированного списка тем. Как только список будет полностью сгенерирован, мы выбираем «обучение» в качестве темы и выбираем его в качестве второго параметра формы. Затем мы нажимаем «Отправить» и извлекаем полученные котировки из контейнера, в котором хранятся результаты.

Поскольку теперь мы преобразуем это в логику JavaScript, давайте сначала составим список всех селекторов элементов, о которых мы говорили в предыдущем абзаце:
| Поле выбора автора | #author |
| Поле выбора тега | #tag |
| кнопка отправки | input[type="submit"] |
| Контейнер цитаты | .quote |
Прежде чем мы начнем взаимодействовать со страницей, мы обеспечим видимость всех элементов, к которым мы будем обращаться, добавив в наш скрипт следующие строки:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');Далее мы выберем значения для двух наших полей выбора:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Теперь мы готовы провести поиск, нажав кнопку «Поиск» на странице и дождавшись появления котировок:
await page.click('.btn'); await page.waitForSelector('.quote'); Поскольку теперь мы собираемся получить доступ к HTML DOM-структуре страницы, мы вызываем предоставленную page.evaluate() , выбирая контейнер, содержащий кавычки (в данном случае он только один). Затем мы создаем объект и определяем null как резервное значение для каждого параметра object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Мы можем сделать все результаты видимыми в нашей консоли, записав их в журнал:
console.log(quotes);Наконец, давайте закроем наш браузер и добавим оператор catch:
await browser.close();Полный скребок выглядит следующим образом:
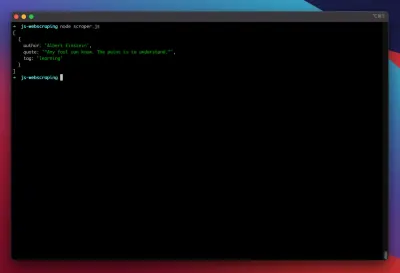
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Давайте попробуем запустить наш парсер с помощью:
node scraper.jsИ вот мы идем! Скребок возвращает наш объект цитаты, как и ожидалось:
Расширенная оптимизация
Наш основной парсер теперь работает. Давайте добавим некоторые улучшения, чтобы подготовить его к более серьезным задачам парсинга.
Настройка пользовательского агента
По умолчанию Puppeteer использует пользовательский агент, содержащий строку HeadlessChrome . Довольно много веб-сайтов обращают внимание на такую подпись и блокируют входящие запросы с такой подписью. Чтобы это не стало потенциальной причиной сбоя парсера, я всегда устанавливаю собственный пользовательский агент, добавляя следующую строку в наш код:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Это можно улучшить еще больше, выбирая случайный пользовательский агент для каждого запроса из массива 5 самых распространенных пользовательских агентов. Список наиболее распространенных пользовательских агентов можно найти в разделе «Самые распространенные пользовательские агенты».
Реализация прокси
Puppeteer упрощает подключение к прокси-серверу, так как адрес прокси-сервера может быть передан Puppeteer при запуске, например:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxy предоставляет большой список бесплатных прокси, которые вы можете использовать. В качестве альтернативы можно использовать чередующиеся прокси-сервисы. Поскольку прокси-серверы обычно используются многими клиентами (или бесплатными пользователями в данном случае), соединение становится гораздо более ненадежным, чем оно уже есть при нормальных обстоятельствах. Это идеальный момент, чтобы поговорить об обработке ошибок и управлении повторными попытками.
Управление ошибками и повторами
Многие факторы могут привести к тому, что ваш скребок выйдет из строя. Следовательно, важно обрабатывать ошибки и решать, что должно произойти в случае сбоя. Поскольку мы подключили наш парсер к прокси-серверу и ожидаем, что соединение будет нестабильным (особенно потому, что мы используем бесплатные прокси-серверы), мы хотим повторить попытку четыре раза , прежде чем сдаться.
Кроме того, нет смысла повторно повторять запрос с тем же IP-адресом, если ранее он не удался. Следовательно, мы собираемся построить небольшую систему ротации прокси .
Прежде всего, мы создаем две новые переменные:
let retry = 0; let maxRetries = 5; Каждый раз, когда мы запускаем нашу функцию scrape() , мы увеличиваем нашу переменную повтора на 1. Затем мы оборачиваем нашу полную логику очистки оператором try and catch, чтобы мы могли обрабатывать ошибки. Управление повторами происходит внутри нашей функции catch :
Предыдущий экземпляр браузера будет закрыт, и если наша переменная повтора меньше, чем наша переменная maxRetries , функция очистки вызывается рекурсивно.
Теперь наш парсер будет выглядеть так:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Теперь давайте добавим ранее упомянутый прокси-ротатор.
Давайте сначала создадим массив, содержащий список прокси:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Теперь выберите случайное значение из массива:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Теперь мы можем запустить динамически сгенерированный прокси вместе с нашим экземпляром Puppeteer:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Конечно, этот ротатор прокси-серверов можно дополнительно оптимизировать, чтобы помечать мертвые прокси-серверы и так далее, но это определенно выходит за рамки данного руководства.
Это код нашего парсера (включая все улучшения):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();Вуаля! Запуск нашего парсера внутри нашего терминала вернет кавычки.
Драматург как альтернатива кукловоду
Puppeteer был разработан Google. В начале 2020 года Microsoft выпустила альтернативу под названием Playwright. Microsoft наняла много инженеров из команды Puppeteer. Следовательно, Playwright был разработан многими инженерами, которые уже работали над Puppeteer. Помимо того, что Playwright новичок в блоге, самым большим отличием Playwright является кросс-браузерная поддержка, поскольку он поддерживает Chromium, Firefox и WebKit (Safari).
Тесты производительности (такие, как этот, проведенный Checkly) показывают, что Puppeteer обычно обеспечивает примерно на 30% лучшую производительность по сравнению с Playwright, что соответствует моему собственному опыту — по крайней мере, на момент написания.
Другие отличия, такие как тот факт, что вы можете запускать несколько устройств с одним экземпляром браузера, не очень важны для контекста парсинга веб-страниц.
Ресурсы и дополнительные ссылки
- Документация Кукловода
- Обучение кукловоду и драматургу
- Парсинг веб-страниц с помощью Javascript от Zenscrape
- Наиболее распространенные пользовательские агенты
- Кукольник против драматурга