
Структуры данных в Python — полное руководство
Опубликовано: 2021-06-14Оглавление
Что такое структура данных?
Структура данных относится к вычислительному хранению данных для эффективного использования. Он хранит данные таким образом, чтобы их можно было легко изменить и получить к ним доступ. В совокупности это относится к значениям данных, отношениям между ними и операциям, которые можно выполнять с данными. Важность структуры данных заключается в ее применении для разработки компьютерных программ. Поскольку компьютерные программы в значительной степени зависят от данных, правильное расположение данных для легкого доступа имеет первостепенное значение для любой программы или программного обеспечения.
Четыре основные функции структуры данных:
- Для ввода информации
- Для обработки информации
- Для поддержания информации
- Чтобы получить информацию
Типы структур данных в Python
Python поддерживает несколько структур данных для легкого доступа и хранения данных. Типы структур данных Python можно разделить на примитивные и непримитивные типы данных. К первым типам данных относятся целые числа, числа с плавающей запятой, строки и логические значения, а ко вторым относятся массивы, списки, кортежи, словари, наборы и файлы. Таким образом, структуры данных в python являются как встроенными структурами данных, так и определяемыми пользователем структурами данных. Встроенная структура данных называется непримитивной структурой данных.
Встроенные структуры данных
Python имеет несколько структур данных, которые действуют как контейнеры для хранения других данных. Этими структурами данных Python являются List, Dictionaries, Tuple и Sets.
Пользовательские структуры данных
Эти структуры данных можно запрограммировать как ту же функцию, что и у встроенных структур данных в python . Определяемые пользователем структуры данных: связанный список, стек, очередь, дерево, график и хэш-карта.
Список встроенных структур данных и объяснение
1. Список
Данные, хранящиеся в списке, расположены последовательно и относятся к разным типам данных. Для всех данных назначается адрес, известный как индекс. Значение индекса начинается с 0 и продолжается до последнего элемента. Такой индекс называется положительным. Отрицательный индекс также существует, если доступ к элементам осуществляется в обратном порядке. Это называется отрицательной индексацией.
Создание списка
Список создается в виде квадратных скобок. Затем элементы могут быть добавлены соответственно. Его можно добавить в квадратных скобках, чтобы создать список. Если элементы не добавлены, будет создан пустой список. В противном случае элементы в списке будут созданы.
| Вход my_list = [] #создать пустой список распечатать (мой_список) my_list = [1, 2, 3, 'пример', 3.132] # создание списка с данными распечатать (мой_список) | Выход [] [1, 2, 3, пример, 3.132] |
Добавление элементов в список
Для добавления элементов в список используются три функции. Это функции append(), extend() и insert().
- Все элементы добавляются как один элемент с помощью функции append().
- Для добавления элементов в список по одному используется функция extend().
- Для добавления элементов по значению их индекса используется функция insert().
| Вход мой_список = [1, 2, 3] распечатать (мой_список) my_list.append([555, 12]) #добавить как отдельный элемент распечатать (мой_список) my_list.extend([234, 'more_example']) #добавить как разные элементы распечатать (мой_список) my_list.insert(1, 'insert_example') #добавить элемент i распечатать (мой_список) | Выход: [1, 2, 3] [1, 2, 3, [555, 12]] [1, 2, 3, [555, 12], 234, 'more_example'] [1, 'insert_example', 2, 3, [555, 12], 234, 'more_example'] |
Удаление элементов в списке
Встроенное ключевое слово «del» в python используется для удаления элемента из списка. Однако эта функция не возвращает удаленный элемент.
- Для возврата удаленного элемента используется функция pop(). Он использует значение индекса удаляемого элемента.
- Функция remove() используется для удаления элемента по его значению.
Выход:
[1, 2, 3, пример, 3.132, 30]
[1, 2, 3, 3.132, 30]
Выдвинутый элемент: 2 Осталось списка: [1, 3, 3.132, 30]
[]
Оценка элементов в списке
- Оценить элемент в списке просто. Печать списка сразу отобразит элементы.
- Конкретные элементы можно оценить, передав значение индекса.
Выход:
1
2
3
пример
3.132
10
30
[1, 2, 3, пример, 3.132, 10, 30]
Пример
[1, 2]
[30, 10, 3.132, пример, 3, 2, 1]
Помимо вышеперечисленных операций, в python доступно несколько других встроенных функций для работы со списками.
- len(): функция используется для возврата длины списка.
- index(): эта функция позволяет пользователю узнать значение индекса переданного значения.
- Функция count() используется для определения количества переданного ей значения.
- sort() сортирует значение в списке и изменяет список.
- sorted() сортирует значение в списке и возвращает список.
Выход
6
3
2
[1, 2, 3, 10, 10, 30]
[30, 10, 10, 3, 2, 1]
2. Словарь
Словарь — это тип структуры данных, в которой хранятся пары ключ-значение, а не отдельные элементы. Это можно объяснить на примере телефонного справочника, в котором есть все номера людей вместе с их телефонными номерами. Имя и номер телефона здесь определяют постоянные значения, которые являются «ключом», а числа и имена всех людей являются значениями для этого ключа. Оценка ключа даст доступ ко всем значениям, хранящимся в этом ключе. Эта определенная структура ключ-значение в Python известна как словарь.
Создание словаря
- Цветочные скобки бездействуют, функция dict() может использоваться для создания словаря.
- Пары ключ-значение добавляются при создании словаря.
Модификация в парах ключ-значение
Любые изменения в словаре можно производить только через ключ. Поэтому сначала следует получить доступ к ключам, а затем выполнять модификации.
| Вход my_dict = {'Первый': 'Python', 'Второй': 'Java'} print(my_dict) my_dict['Второй'] = 'C++' #изменение элемента print(my_dict) my_dict['Третий'] = 'Ruby' #добавление пары ключ-значение print(my_dict) | Выход: {'Первый': 'Питон', 'Второй': 'Ява'} {'Первый': 'Питон', 'Второй': 'С++'} {'Первый': 'Python', 'Второй': 'C++', 'Третий': 'Ruby'} |
Удаление словаря
Функция очистки () используется для удаления всего словаря. Словарь можно оценить по ключам, используя функцию get() или передав значения ключей.
| Вход dict = {'Месяц': 'Январь', 'Сезон': 'зима'} печать (дикт ['Первый']) print(dict.get('Второй') | Выход январь Зима |
Другими функциями, связанными со словарем, являются keys(), values() и items().
3. Кортеж
Подобно списку, кортежи представляют собой списки хранения данных, но единственное отличие состоит в том, что данные, хранящиеся в кортеже, не могут быть изменены. Если данные в кортеже изменяемы, только тогда можно изменить данные.
- Кортежи можно создавать с помощью функции tuple().
Вход
новый_кортеж = (10, 20, 30, 40)
печать (новый_кортеж)
Выход
(10, 20, 30, 40)
- Элементы в кортеже можно оценивать так же, как и элементы в списке.
Вход
new_tuple2 = (10, 20, 30, «возраст»)
для x в new_tuple2:
печать (х)
печать (new_tuple2)
печать (new_tuple2 [0])
Выход
10
20
30
Возраст
(10, 20, 30, «возраст»)
10
- Оператор «+» используется для добавления другого кортежа
Вход
кортеж = (1, 2, 3)
кортеж = кортеж + (4, 5, 6
печать (кортеж)
Выход
(1, 2, 3, 4, 5, 6)
4. Установить
Структура данных множества аналогична арифметическим множествам. Это в основном набор уникальных элементов. Если данные продолжают повторяться, наборы учитывают добавление этого элемента только один раз.
- Набор можно создать, просто передав ему значения в фигурных скобках.
Вход
установить = {10, 20, 30, 40, 40, 40}
печать (набор)
Выход
{10, 20, 30, 40}

- Функцию add() можно использовать для добавления элементов в набор.
- Для объединения данных из двух наборов можно использовать функцию union().
- Для идентификации данных, присутствующих в обоих наборах, используется функция пересечения().
- Функция different() выводит только те данные, которые уникальны для набора, удаляя общие данные.
- Функция symmetric_difference() выводит данные, уникальные для обоих наборов.
Список определяемых пользователем структур данных и объяснение
1. Стеки
Стек представляет собой линейную структуру, которая представляет собой либо структуру «последний пришел — первый вышел» (LIFO), либо структуру «первый пришел — последний вышел» (FIFO). В стеке существуют две основные операции: push и pop. Push означает добавление элемента в начало списка, тогда как pop означает удаление элемента из нижней части стека. Процесс хорошо описан на рисунке 1.
Полезность стека
- Предыдущие элементы можно оценить путем обратного отслеживания.
- Сопоставление рекурсивных элементов.
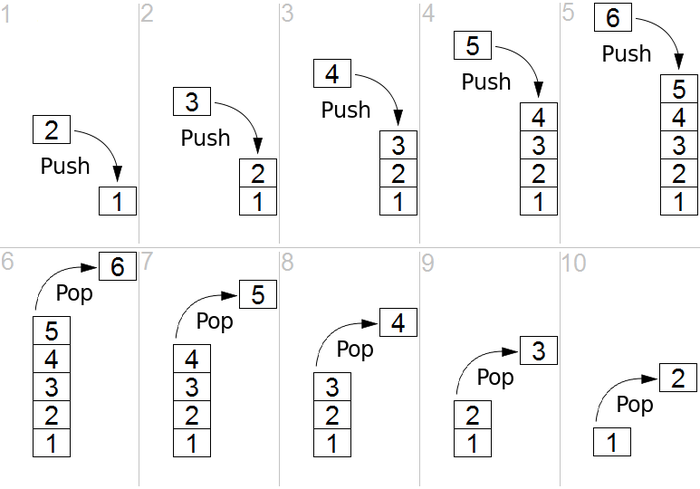
Источник
Рисунок 1: Графическое представление стека
Пример

Выход
['первый второй третий']
['первый второй третий четвертый пятый']
пятый
['первый второй третий четвертый']
2. Очередь
Подобно стекам, очередь представляет собой линейную структуру, которая позволяет вставлять элемент с одного конца и удалять с другого конца. Эти две операции известны как постановка в очередь и удаление из очереди. Недавно добавленный элемент удаляется первым, как и стеки. Графическое представление очереди показано на рис. 2. Одним из основных применений очереди является обработка поступающих вещей.
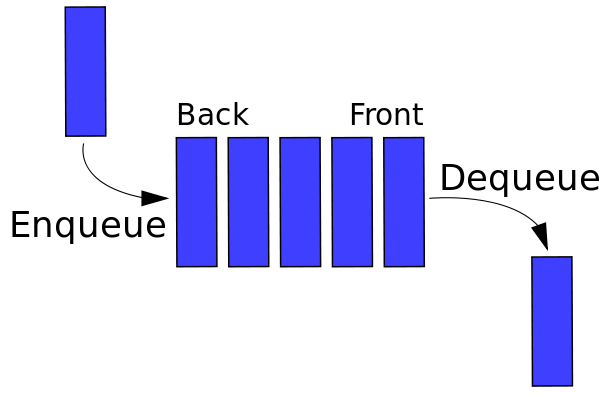
Источник
Рисунок 2 : Графическое представление очередей
Пример

Выход
['первый второй третий']
['первый второй третий четвертый пятый']
первый
пятый
['второй', 'третий', 'четвертый', 'пятый']
3. Дерево
Деревья — это нелинейные и иерархические структуры данных, состоящие из узлов, связанных ребрами. Структура данных дерева Python имеет корневой узел, родительский узел и дочерний узел. Корень — это самый верхний элемент структуры данных. Бинарное дерево — это структура, в которой элементы имеют не более двух дочерних узлов.
Полезность дерева
- Отображает структурные отношения элементов данных.
- Эффективный обход каждого узла
- Пользователи могут вставлять, искать, извлекать и удалять данные.
- Гибкие структуры данных
Рисунок 3: Графическое представление дерева
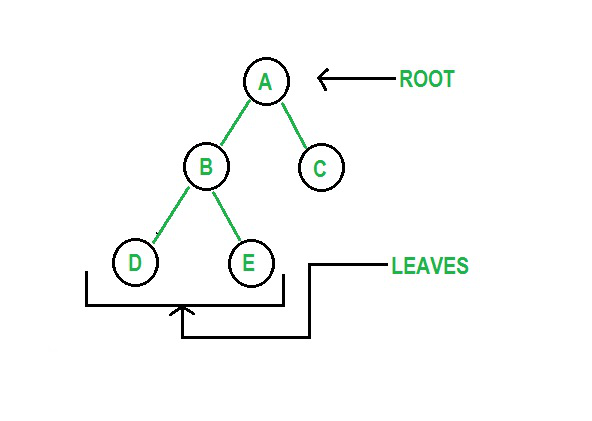
Источник
Пример:

Выход
Первый
Второй
В третьих
4. График
Еще одна нелинейная структура данных в Python — это граф, состоящий из узлов и ребер. Графически отображает набор объектов, причем некоторые объекты связаны ссылками. Вершины являются взаимосвязанными объектами, а связи называются ребрами. Представление графа может быть выполнено через структуру данных словаря Python, где ключ представляет вершины, а значения представляют ребра.
Основные операции, которые можно выполнять над графиками
- Отображение вершин и ребер графа.
- Добавление вершины.
- Добавление ребра.
- Создание графика
Полезность графика
- Представление графа легко понять и использовать.
- Это отличная структура для представления связанных отношений, например друзей в Facebook.
Рисунок 4: Графическое представление графика
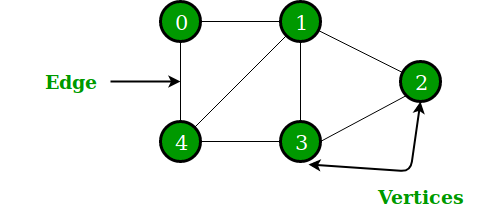
Источник
Пример

г = график (4)
г. край (0, 2)
г. край (1, 3)
г. край (3, 2)
г. край (0, 3)
g.__repr__()
Выход
Список смежности вершины 0
голова -> 3 -> 2
Список смежности вершины 1
голова -> 3
Список смежности вершины 2
голова -> 3 -> 0
Список смежности вершины 3
голова -> 0 -> 2 -> 1
5. Хэш-карта
Hashmaps — это индексированные структуры данных Python, полезные для хранения пар ключ-значение. Данные, хранящиеся в хэш-картах, извлекаются с помощью ключей, которые вычисляются с помощью хэш-функции. Эти типы структур данных полезны для хранения данных учащихся, сведений о клиентах и т. д. Примером хэш-карт являются словари в Python.
Пример

Выход
0 -> первый
1 -> второй
2 -> третий
0 -> первый
1 -> второй
2 -> третий
3 -> четвертый
0 -> первый
1 -> второй
2 -> третий
Полезность
- Это наиболее гибкий и надежный метод получения информации по сравнению с другими структурами данных.
6. Связанный список
Это тип линейной структуры данных. По сути, это ряд элементов данных, объединенных ссылками в python. Элементы в связанном списке связаны через указатели. Первый узел этой структуры данных называется заголовком, а последний узел — хвостом. Следовательно, связанный список состоит из узлов, имеющих значения, и каждый узел состоит из указателя, связанного с другим узлом.
Полезность связанных списков
- По сравнению с фиксированным массивом связанный список представляет собой динамическую форму ввода данных. Память сохраняется, поскольку она выделяет память узлов. В то время как в массиве размер должен быть предопределен, что приводит к потере памяти.
- Связанный список может храниться в любом месте памяти. Узел связанного списка можно обновить и переместить в другое место.
Рисунок 6: Графическое представление связанного списка
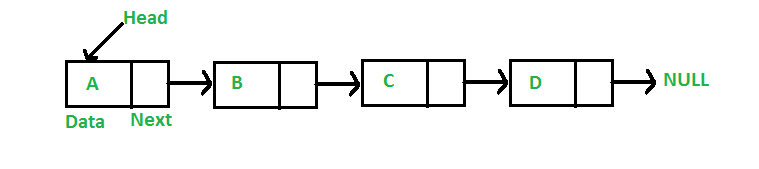
Источник
Пример

Выход:
['первый второй третий']
['первый', 'второй', 'третий', 'шестой', 'четвертый', 'пятый']
['первый', 'третий', 'шестой', 'четвертый', 'пятый']
Заключение
Были изучены различные типы структур данных в Python . Будь то новичок или эксперт, структуры данных и алгоритмы нельзя игнорировать. При выполнении любых операций с данными концепции структур данных играют жизненно важную роль. Структуры данных помогают хранить информацию в организованном порядке, тогда как алгоритмы помогают направлять анализ данных. Следовательно, как структуры данных, так и алгоритмы Python помогают компьютерным ученым или любым пользователям обрабатывать свои данные.
Если вам интересно узнать о структурах данных, ознакомьтесь с программой Executive PG в области науки о данных IIIT-B и upGrad, которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, 1 -на-1 с отраслевыми наставниками, более 400 часов обучения и помощи в трудоустройстве в ведущих фирмах.
Какая структура данных быстрее в Python?
В словарях поиск выполняется быстрее, потому что Python использует для их реализации хеш-таблицы. Если мы используем концепции Big O, чтобы проиллюстрировать различие, словари имеют постоянную временную сложность, O (1), тогда как списки имеют линейную временную сложность, O (n).
В Python словари — это самый быстрый способ частого поиска данных с тысячами записей. Словари очень оптимизированы, потому что они являются встроенным типом отображения в Python. Однако в словарях и списках существует общий компромисс между пространством и временем. Это указывает на то, что, хотя мы можем сократить время, необходимое для нашего подхода, нам потребуется больше памяти.
В списках, чтобы получить то, что вы хотите, вы должны пройти весь список. С другой стороны, словарь вернет искомое значение, не просматривая все ключи.
Что быстрее в списке или массиве Python?
В общем, списки Python невероятно гибки и могут содержать полностью разнородные, случайные данные, а также быстро добавляться и за приблизительно постоянное время. Это то, что вам нужно, если вам нужно быстро и безболезненно сократить и расширить свой список. Однако они занимают намного больше места, чем массивы, отчасти потому, что каждый элемент в списке требует создания отдельного объекта Python.
С другой стороны, тип array.array по сути представляет собой тонкую оболочку для массивов C. Он может переносить только однородные данные (то есть данные одного типа), поэтому память ограничена размером sizeof(один объект) * длина байтов.
В чем разница между массивом NumPy и списком?
Numpy — это основной пакет Python для научных вычислений. Он использует объект большого многомерного массива, а также утилиты для работы с ним. Массив numpy представляет собой сетку значений одинакового типа, индексированных кортежем неотрицательных целых чисел.
Списки были включены в основную библиотеку Python. Список похож на массив в Python, но его размер можно изменять, и он может содержать элементы различных типов. В чем здесь реальная разница? Производительность является ответом. Структуры данных Numpy более эффективны с точки зрения размера, производительности и функциональности.