
Что такое структуры данных в C и как их использовать?
Опубликовано: 2021-02-26Оглавление
Введение
Начнем с того, что структура данных представляет собой набор элементов данных, которые хранятся вместе под одним именем или заголовком и представляют собой особый способ хранения и компоновки данных, позволяющий эффективно использовать данные.
Типы
Структуры данных широко распространены и используются почти во всех программных системах. Одними из наиболее распространенных примеров структур данных являются массивы, очереди, стеки, связанные списки и деревья.
Приложения
При разработке компиляторов, операционных систем, создании баз данных, приложений искусственного интеллекта и многого другого.
Классификация
Структуры данных делятся на две категории: примитивные структуры данных и непримитивные структуры данных.
1. Примитивные: это основные типы данных, поддерживаемые языком программирования. Типичным примером этой классификации являются целые числа, символы и логические значения.
2. Непримитивные: эти категории структур данных создаются с использованием примитивных структур данных. Примеры включают связанные стеки, связанные списки, графики и деревья.

Массивы
Массив — это простая коллекция элементов данных, имеющих один и тот же тип данных. Это означает, что массив целых чисел может хранить только целочисленные значения. Массив данных типа float может хранить значения, соответствующие типу данных float и ничего больше.
Элементы, хранящиеся в массиве, доступны линейно и находятся в смежных блоках памяти, на которые можно ссылаться с помощью индекса.
Объявление массива
В C массив может быть объявлен как:
имя_типа_данных[длина];
Например,
целые заказы[10];
Приведенная выше строка кода создает массив из 10 блоков памяти, в которых может храниться целочисленное значение. В C значение индекса массива начинается с 0. Таким образом, значения индекса будут варьироваться от 0 до 9. Если мы хотим получить доступ к какому-либо конкретному значению в этом массиве, нам просто нужно ввести:
printf(заказ[номер_индекса]);
Другой способ объявить массив выглядит следующим образом:
data_type имя_массива[размер]={список значений};
Например,
целые отметки [5] = {9, 8, 7, 9, 8};
Приведенная выше строка команды создает массив, содержащий 5 блоков памяти с фиксированными значениями в каждом из блоков. В 32-битном компиляторе 32-битная память, занимаемая типом данных int, составляет 4 байта. Таким образом, 5 блоков памяти займут 20 байт памяти.
Другой законный способ инициализации массивов:
метки целых чисел [5] = {9, 45};
Эта команда создаст массив из 5 блоков, причем последние 3 блока будут иметь значение 0.
Другой законный способ:
метки int [] = {9, 5, 2, 1, 3,4};
Компилятор C понимает, что для размещения этих данных в массиве требуется всего 5 блоков. Поэтому он инициализирует массив именных меток размером 5.
Точно так же двумерный массив можно инициализировать следующим образом.
метки int[2][3]={{9,7,7},{6, 2, 1}};
Приведенная выше команда создаст двумерный массив, состоящий из 2 строк и 3 столбцов.
Читайте: Идеи и темы проекта структуры данных
Операции
Есть некоторые операции, которые можно выполнять над массивами. Например:
- обход массива
- Вставка элемента в массив
- Поиск определенного элемента в массиве
- Удаление определенного элемента из массива
- Объединение двух массивов и,
- Сортировка массива — по возрастанию или по убыванию.
Недостатки
Память, выделенная массиву, фиксирована. Это на самом деле проблема. Скажем, мы создали массив размером 50 и получили доступ только к 30 блокам памяти. Остальные 20 блоков занимают память без использования. Поэтому для решения этой проблемы у нас есть связанный список.
Связанный список
Связанный список, очень похожий на массивы, хранит данные последовательно. Основное отличие в том, что он не хранит все сразу. Вместо этого сохраняет данные или делает блок памяти доступным по мере необходимости. В связанном списке блоки разделены на две части. Первая часть содержит фактические данные.
Вторая часть представляет собой указатель, указывающий на следующий блок в связанном списке. Указатель хранит адрес следующего блока, содержащего данные. Есть еще один указатель, известный как головной указатель. head указывает на первый блок памяти в связанном списке. Ниже приведено представление связанного списка. Эти блоки также называются «узлами».
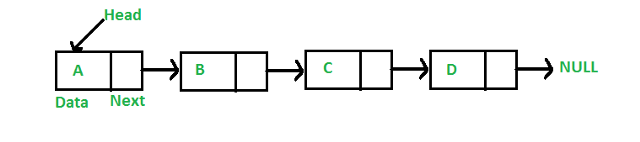
источник
Инициализация связанных списков
Для инициализации списка ссылок мы создаем узел имен структур. В структуре есть две вещи. 1. Данные, которые он содержит, и 2. Указатель, указывающий на следующий узел. Тип данных указателя будет типом данных структуры, поскольку он указывает на узел структуры.

узел структуры
{
внутренние данные;
узел структуры *next;
};
В связанном списке указатель последнего узла не будет указывать ни на что или просто будет указывать на ноль.
Читайте также: Графики в структуре данных
Обход связанного списка
В связанном списке указатель последнего узла не будет указывать ни на что, или просто будет указывать на ноль. Таким образом, чтобы обойти весь связанный список, мы создаем фиктивный указатель, который изначально указывает на голову. И для длины связанного списка указатель продолжает двигаться вперед, пока не укажет на нуль или не достигнет последнего узла связанного списка.
Добавление узла
Алгоритм добавления узла перед конкретным узлом будет следующим:
- установить два фиктивных указателя (ptr и preptr), которые изначально указывают на голову
- переместите ptr до тех пор, пока ptr.data не станет равным данным, прежде чем мы собираемся вставить узел. preptr будет на 1 узел позади ptr.
- Создать узел
- Узел, на который указывал фиктивный preptr, следующий узел этого узла будет указывать на этот новый узел.
- Next нового узла будет указывать на ptr.
Алгоритм добавления узла после определенных данных будет выполнен аналогичным образом.
Преимущества связанного списка
- Динамический размер в отличие от массива
- Выполнение вставки и удаления проще в связанном списке, чем в массиве.
Очередь
Очередь следует системе типа «первым пришел — первым обслужен» или FIFO. В реализации массива у нас будет два указателя для демонстрации варианта использования Queue.
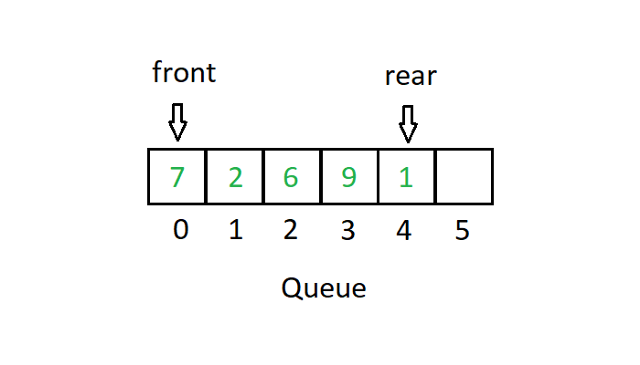
Источник
FIFO в основном означает, что значение, которое входит в стек первым, покидает массив первым. На приведенной выше диаграмме очереди передняя часть указателя указывает на значение 7. Если мы удалим первый блок (удалить из очереди), передняя часть теперь будет указывать на значение 2. Точно так же, если мы введем число (поставить в очередь), скажем, 3 в положение 5. Затем задний указатель укажет на положение 5.
Условия переполнения и недополнения
Тем не менее, прежде чем ввести значение данных в очередь, мы должны проверить условия переполнения. Переполнение произойдет при попытке вставить элемент в уже заполненную очередь. Очередь будет заполнена, когда сзади = max_size–1.
Точно так же перед удалением данных из очереди мы должны проверить наличие условий потери значимости. Потеря значимости произойдет при попытке удалить элемент из очереди, которая уже пуста, т. е. если передний = null и задний = нулевой, то очередь пуста.
Куча
Стек — это структура данных, в которую мы вставляем и удаляем элементы только на одном конце, также известном как вершина стека. Поэтому реализация стека называется реализацией по принципу «последним пришел — первым ушел» (LIFO). В отличие от очереди, для стека нам нужен только один верхний указатель.
Если мы хотим ввести (втолкнуть) элементы в массив, верхний указатель перемещается вверх или увеличивается на 1. Если мы хотим удалить (выталкивать) элемент, верхний указатель уменьшается на 1 или опускается на 1 единицу. Стек поддерживает три основные операции: push, pop и peep. Операция Peep просто отображает самый верхний элемент в стеке.
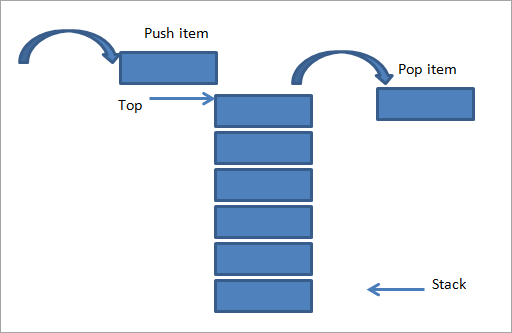
Источник
Изучайте онлайн-курсы по программному обеспечению от лучших университетов мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Заключение
В этой статье мы говорили о 4 типах структур данных, а именно о массивах, связанных списках, очередях и стеках. Надеюсь, вам понравилась эта статья, и оставайтесь с нами для более интересных чтений. До скорого.
Если вам интересно узнать больше о Javascript и разработке полного стека, ознакомьтесь с программой Executive PG upGrad и IIIT-B по разработке программного обеспечения с полным стеком, которая предназначена для работающих профессионалов и предлагает более 500 часов тщательного обучения, 9+ проектов. и задания, статус выпускника IIIT-B, практические практические проекты и помощь в трудоустройстве в ведущих фирмах.
Что такое структуры данных в программировании?
Структуры данных — это то, как мы упорядочиваем данные в программе. Двумя наиболее важными структурами данных являются массивы и связанные списки. Массивы — самая знакомая структура данных, и ее проще всего понять. Массивы в основном представляют собой пронумерованные списки связанных элементов. Они просты для понимания и использования, но не очень эффективны при работе с большими объемами данных. Связанные списки более сложны, но они могут быть очень эффективными при правильном использовании. Это хороший выбор, когда вам нужно добавить или удалить элементы в середине большого списка или когда вам нужно искать элементы в большом списке.
В чем разница между связанным списком и массивом?
В массивах индекс используется для доступа к элементу. Элементы в массиве организованы в последовательном порядке, что упрощает доступ к элементам и их изменение, если используется индекс. Массив также имеет фиксированный размер. Элементы выделяются в момент его создания. В связанном списке для доступа к элементу используется указатель. Элементы связанного списка не обязательно хранятся в последовательном порядке. Связанный список имеет неизвестный размер, поскольку он может содержать узлы во время своего создания. Указатель используется для доступа к элементу, поэтому выделение памяти упрощается.
Что такое указатель в C?
Указатель — это тип данных в C, который хранит адрес любой переменной или функции. Обычно он используется как ссылка на другую ячейку памяти. Указатель может содержать адрес памяти массива, структуры, функции или любого другого типа. C использует указатели для передачи значений и получения значений от функций. Указатели используются для динамического выделения памяти.