
Окончательная шпаргалка по науке о данных, которую должен иметь каждый специалист по данным
Опубликовано: 2021-01-29Для всех тех начинающих профессионалов и новичков, которые думают о том, чтобы погрузиться в бурно развивающийся мир науки о данных, мы составили краткую памятку, чтобы вы могли освежить в памяти основы и методологии, лежащие в основе этой области.
Оглавление
Наука о данных — основы
Данные, которые генерируются в нашем мире, имеют необработанную форму, то есть числа, коды, слова, предложения и т. д. Наука о данных использует эти очень необработанные данные для их обработки с использованием научных методов, чтобы преобразовать их в значимые формы для получения знаний и идей. .
Данные
Прежде чем мы углубимся в принципы науки о данных, давайте немного поговорим о данных, их типах и обработке данных.
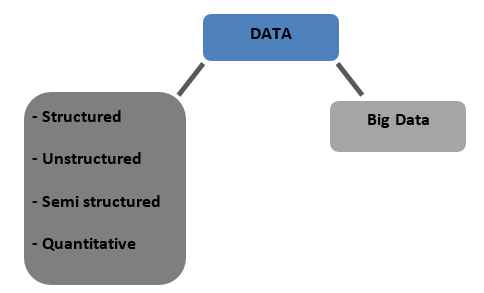
Типы данных
Структурированные — данные, которые хранятся в табличном формате в базах данных. Это может быть как числовое, так и текстовое
Неструктурированные - данные, которые нельзя свести в таблицу с какой-либо определенной структурой, о которой можно говорить, называются неструктурированными данными.
Полуструктурированные — смешанные данные с признаками как структурированных, так и неструктурированных данных.
Количественные - данные с определенными числовыми значениями, которые можно количественно оценить.
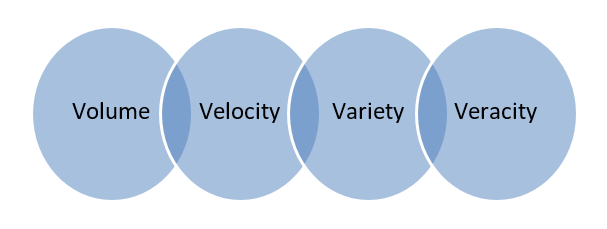
Большие данные . Данные, хранящиеся в огромных базах данных, охватывающих несколько компьютеров или ферм серверов, называются большими данными. Биометрические данные, данные социальных сетей и т. д. считаются большими данными. Большие данные характеризуются 4 V
Предварительная обработка данных
Классификация данных — это процесс категоризации или маркировки данных по классам, таким как числовые, текстовые или графические, текстовые, видео и т. д.
Очистка данных . Она заключается в отсеивании отсутствующих/несогласованных/несовместимых данных или замене данных одним из следующих методов.
- Интерполяция
- Эвристика
- Случайное назначение
- Ближайший сосед
Маскирование данных — сокрытие или маскировка конфиденциальных данных для обеспечения конфиденциальности конфиденциальной информации, при этом сохраняя возможность ее обработки.
Из чего состоит наука о данных?
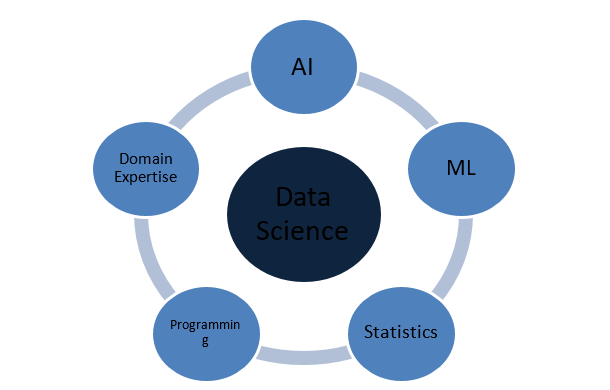
Концепции статистики
Регрессия
Линейная регрессия
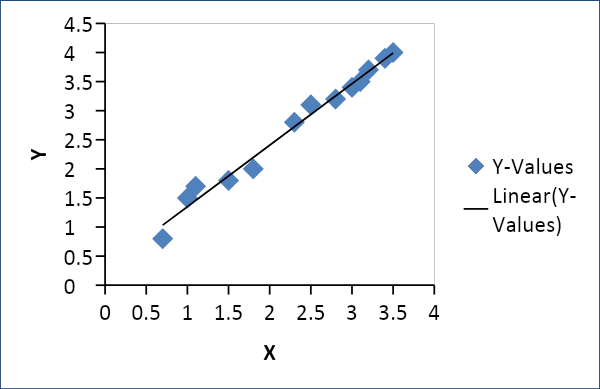
Линейная регрессия используется для установления взаимосвязи между двумя переменными, такими как спрос и предложение, цена и потребление и т. д. Она связывает одну переменную x как линейную функцию другой переменной y следующим образом.
Y = f(x) или Y =mx + c, где m = коэффициент
Логистическая регрессия
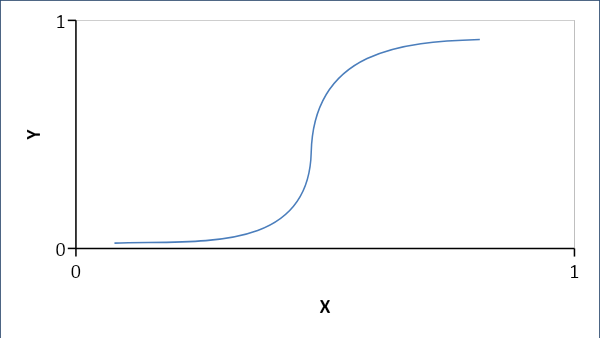
Логистическая регрессия устанавливает вероятностную связь между переменными, а не линейную. В результате получается либо 0, либо 1, и мы ищем вероятности, и кривая имеет S-образную форму.
Если p < 0,5, то 0, иначе 1
Формула:
Y = e^ (b0 + b1x) / (1 + e^ (b0 + b1x))
где b0 = смещение и b1 = коэффициент
Вероятность
Вероятность помогает предсказать вероятность наступления события. Некоторые термины:
Образец: множество вероятных исходов
Событие: это подмножество выборочного пространства
Случайная переменная: случайные переменные помогают сопоставить или количественно оценить вероятные результаты с числами или строкой в выборочном пространстве.
Распределения вероятностей
Дискретные распределения: дает вероятность в виде набора дискретных значений (целых).
Р[Х=х] = р(х)
 Источник изображения
Источник изображения
Непрерывные распределения: дает вероятность по ряду непрерывных точек или интервалов вместо дискретных значений. Формула:
P[a ≤ x ≤ b] = a∫bf(x) dx, где a, b — точки
Источник изображения
Корреляция и ковариация
Стандартное отклонение: изменение или отклонение данного набора данных от его среднего значения.
σ = √ {(Σi=1N ( xi - x )) / (N -1)}
Ковариация
Он определяет степень отклонения случайных величин X и Y от среднего значения набора данных.
Cov(X,Y) = σ2XY= E[(X−μX)(Y−μY)] = E[XY]−μXμY
Корреляция
Корреляция определяет степень линейной зависимости между переменными вместе с их направлением, +ve или -ve.
ρXY= σ2XY/ σX * *σY
Искусственный интеллект
Способность машин приобретать знания и принимать решения на основе входных данных называется искусственным интеллектом или просто ИИ.
Типы
- Реактивные машины: ИИ реактивных машин учится реагировать на предопределенные сценарии, сужая список до самых быстрых и лучших вариантов. Им не хватает памяти, и они лучше всего подходят для задач с определенным набором параметров. Высоконадежный и последовательный.
- Ограниченная память: этому ИИ подаются некоторые реальные данные наблюдений и унаследованные данные. Он может учиться и принимать решения на основе имеющихся данных, но не может приобретать новый опыт.
- Теория разума: это интерактивный ИИ, который может принимать решения на основе поведения окружающих сущностей.
- Самосознание: этот ИИ знает о своем существовании и функционировании независимо от окружения. Он может развивать когнитивные способности, понимать и оценивать влияние своих действий на окружающую среду.
термины ИИ
Нейронные сети
Нейронные сети — это группа или сеть взаимосвязанных узлов, которые передают данные и информацию в системе. NN смоделированы так, чтобы имитировать нейроны в нашем мозгу и могут принимать решения, обучаясь и прогнозируя.
Эвристика
Эвристика — это способность прогнозировать на основе приближений и оценок, быстро используя предыдущий опыт в ситуациях, когда доступная информация неоднородна. Это быстро, но не точно и не точно.
Рассуждение на основе прецедентов
Способность учиться на предыдущих случаях решения проблем и применять их в текущих ситуациях, чтобы прийти к приемлемому решению.
Обработка естественного языка
Это просто способность машины понимать и взаимодействовать непосредственно с человеческой речью или текстом. Например, голосовые команды в автомобиле.
Машинное обучение
Машинное обучение — это просто приложение ИИ, использующее различные модели и алгоритмы для прогнозирования и решения проблем.

Типы
Под наблюдением
Этот метод основан на входных данных, которые ассоциативны с выходными данными. Машина снабжена набором целевых переменных Y, и она должна получить целевую переменную через набор входных переменных X под контролем алгоритма оптимизации. Примерами обучения с учителем являются нейронные сети, случайный лес, глубокое обучение, машины опорных векторов и т. д.
Без присмотра
В этом методе входные переменные не имеют маркировки или ассоциации, а алгоритмы работают над поиском закономерностей и кластеров, что приводит к новым знаниям и идеям.
Усиленный
Усиленное обучение фокусируется на методах импровизации для оттачивания или полировки учебного поведения. Это метод, основанный на вознаграждении, при котором машина постепенно совершенствует свои методы, чтобы получить целевое вознаграждение.
Методы моделирования
Регрессия
Модели регрессии всегда дают числа в качестве выходных данных путем интерполяции или экстраполяции непрерывных данных.
Классификация
Модели классификации предлагают выходные данные в виде класса или метки и лучше предсказывают дискретные результаты, такие как «какой тип».
И регрессия, и классификация являются моделями с учителем.
Кластеризация
Кластеризация — это неконтролируемая модель, которая идентифицирует кластеры на основе признаков, атрибутов, функций и т. д.
Алгоритмы машинного обучения
Деревья решений
Деревья решений используют бинарный подход для получения решения, основанного на последовательных вопросах на каждом этапе, так что результат является одним из двух возможных, таких как «Да» или «Нет». Деревья решений просты в реализации и интерпретации.
Случайный лес или мешок
Random Forest — это усовершенствованный алгоритм деревьев решений. Он использует большое количество деревьев решений, что делает структуру плотной и сложной, как лес. Он генерирует несколько результатов и, таким образом, приводит к более точным результатам и производительности.
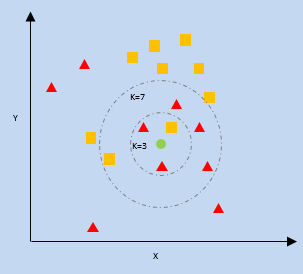
K- Ближайший сосед (KNN)
kNN использует близость ближайших точек данных на графике к новой точке данных, чтобы предсказать, к какой категории она относится. Новая точка данных присваивается категории с большим количеством соседей.
k = количество ближайших соседей
Наивный Байес
Наивный Байес работает на двух столпах: во-первых, каждая характеристика точек данных независима, не связана друг с другом, то есть уникальна, а во-вторых, на теореме Байеса, которая предсказывает результаты на основе условия или гипотезы.
Теорема Байеса:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Где P(X|Y) = условная вероятность X при наличии Y
P(Y|X) = условная вероятность Y при наличии X
P(X), P(Y) = Вероятность X и Y по отдельности
Опорные векторные машины
Этот алгоритм пытается разделить данные в пространстве на основе границ, которые могут быть линиями или плоскостями. Эта граница называется «гиперплоскостью» и определяется ближайшими точками данных каждого класса, которые, в свою очередь, называются «опорными векторами». Максимальное расстояние между опорными векторами любой стороны называется запасом.
Нейронные сети
Персептрон
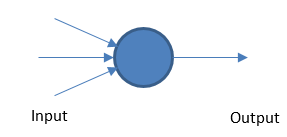
Фундаментальная нейронная сеть работает, взвешивая входные и выходные данные на основе порогового значения.
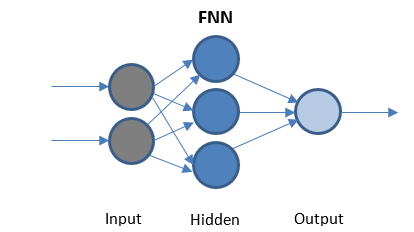
Нейронная сеть с прямой связью
FFN — простейшая сеть, которая передает данные только в одном направлении. Может иметь или не иметь скрытые слои.
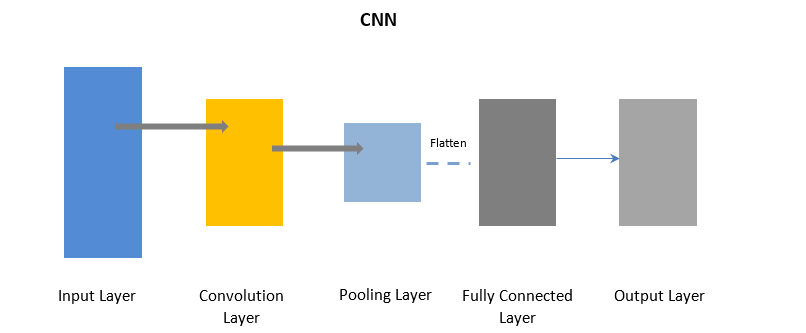
Сверточные нейронные сети
CNN использует слой свертки для обработки определенных частей входных данных в пакетах, за которыми следует слой объединения для завершения вывода.
Рекуррентные нейронные сети
RNN состоит из нескольких повторяющихся слоев между уровнями ввода-вывода, которые могут хранить «исторические» данные. Поток данных является двунаправленным и подается на повторяющиеся уровни для улучшения прогнозов.
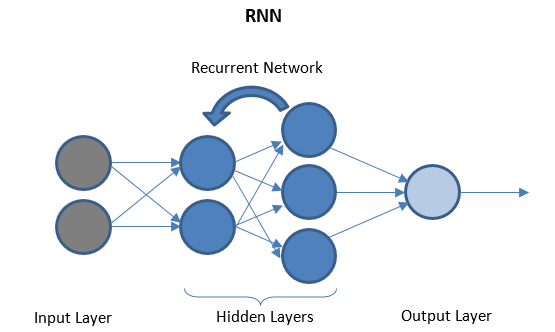
Глубокие нейронные сети и глубокое обучение
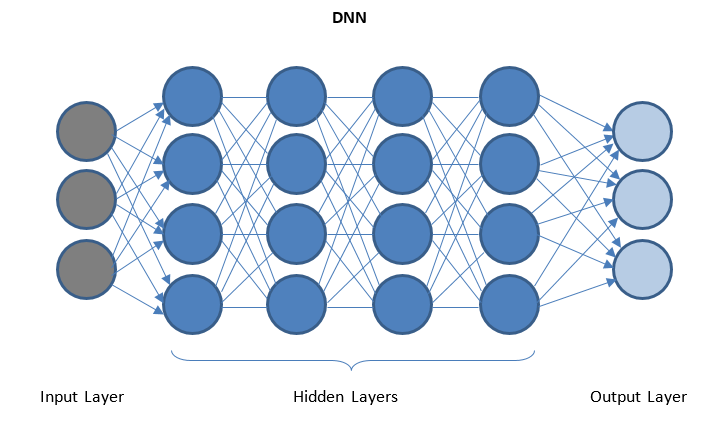
DNN — это сеть с несколькими скрытыми слоями между уровнями ввода-вывода. Скрытые слои применяют последовательные преобразования к данным перед их отправкой на выходной слой.
«Глубокое обучение» облегчается с помощью DNN и может обрабатывать огромные объемы сложных данных и достигать высокой точности благодаря множеству скрытых слоев.
Получите сертификат по науке о данных от лучших университетов мира. Изучите программы Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Заключение
Наука о данных — это обширная область, которая проходит через разные потоки, но становится для нас революцией и откровением. Наука о данных переживает бум и изменит то, как наши системы работают и чувствуют себя в будущем.
Если вам интересно узнать о науке о данных, ознакомьтесь с дипломом IIIT-B & upGrad PG в области науки о данных, который создан для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, 1- on-1 с отраслевыми наставниками, более 400 часов обучения и помощи в трудоустройстве в ведущих фирмах.
Какой язык программирования лучше всего подходит для Data Science и почему?
Существуют десятки языков программирования для науки о данных, но большая часть сообщества специалистов по данным считает, что если вы хотите преуспеть в науке о данных, то Python — правильный выбор. Ниже приведены некоторые из причин, подтверждающих это убеждение:
1. Python имеет широкий спектр модулей и библиотек, таких как TensorFlow и PyTorch, которые упрощают работу с концепциями науки о данных.
2. Обширное сообщество разработчиков Python постоянно помогает новичкам перейти к следующему этапу их пути к науке о данных.
3. Этот язык на сегодняшний день является одним из самых удобных и простых в написании языков с чистым синтаксисом, улучшающим его читабельность.
Какие концепции делают науку о данных полной?
Наука о данных — это обширная область, которая действует как зонтик для различных других важных областей. Ниже приведены наиболее известные концепции, составляющие науку о данных:
Статистика
Статистика — важная концепция, в которой вы должны преуспеть, чтобы двигаться вперед в науке о данных. Кроме того, в нем есть несколько подтем:
1. Линейная регрессия
2. Вероятность
3. Распределение вероятностей
Искусственный интеллект
Наука о том, как обеспечить машины мозгом и позволить им принимать собственные решения на основе входных данных, известна как искусственный интеллект. Реактивные машины, ограниченная память, теория разума и самосознание — вот некоторые из типов искусственного интеллекта.
Машинное обучение
Машинное обучение — еще один важный компонент науки о данных, который занимается обучением машин прогнозировать будущие результаты на основе предоставленных данных. Машинное обучение имеет три известных метода моделирования: кластеризация, регрессия и классификация.
Опишите типы машинного обучения?
Машинное обучение или простое машинное обучение имеют три основных типа в зависимости от их методов работы. Эти типы следующие:
1. Контролируемое обучение
Это самый примитивный тип ML, где входные данные помечены. Машине предоставляется меньший набор данных, который дает машине представление о проблеме и обучается ей.
2. Неконтролируемое обучение
Самым большим преимуществом этого типа является то, что данные здесь не маркируются, а человеческий труд практически незначителен. Это открывает возможности для включения в модель гораздо больших наборов данных.
3. Усиленное обучение . Это самый продвинутый тип машинного обучения, вдохновленный жизнью людей. Желаемые результаты поощряются, в то время как бесполезные результаты обескураживают.