
Предварительная обработка данных в машинном обучении: 7 простых шагов
Опубликовано: 2021-07-15Предварительная обработка данных в машинном обучении — это важный шаг, который помогает повысить качество данных, чтобы способствовать извлечению значимых идей из данных. Предварительная обработка данных в машинном обучении относится к технике подготовки (очистки и организации) необработанных данных, чтобы сделать их пригодными для построения и обучения моделей машинного обучения. Проще говоря, предварительная обработка данных в машинном обучении — это метод интеллектуального анализа данных, который преобразует необработанные данные в понятный и читаемый формат.
Оглавление
Зачем нужна предварительная обработка данных в машинном обучении?
Когда дело доходит до создания модели машинного обучения, предварительная обработка данных является первым шагом, отмечающим начало процесса. Как правило, реальные данные являются неполными, непоследовательными, неточными (содержат ошибки или выбросы) и часто не содержат конкретных значений атрибутов/тенденций. Именно здесь в сценарий вступает предварительная обработка данных — она помогает очищать, форматировать и упорядочивать необработанные данные, тем самым делая их готовыми к работе с моделями машинного обучения. Давайте рассмотрим различные этапы предварительной обработки данных в машинном обучении.
Присоединяйтесь к онлайн- курсу по искусственному интеллекту в ведущих университетах мира — магистерским программам, программам последипломного образования для руководителей и продвинутой сертификационной программе в области машинного обучения и искусственного интеллекта, чтобы ускорить свою карьеру.
Этапы предварительной обработки данных в машинном обучении
В машинном обучении есть семь важных этапов предварительной обработки данных:
1. Получите набор данных
Получение набора данных — это первый шаг в предварительной обработке данных в машинном обучении. Чтобы создавать и разрабатывать модели машинного обучения, вы должны сначала получить соответствующий набор данных. Этот набор данных будет состоять из данных, собранных из нескольких и разрозненных источников, которые затем будут объединены в надлежащем формате для формирования набора данных. Форматы наборов данных различаются в зависимости от вариантов использования. Например, набор бизнес-данных будет полностью отличаться от набора медицинских данных. В то время как набор бизнес-данных будет содержать соответствующие отраслевые и бизнес-данные, набор медицинских данных будет включать данные, связанные со здравоохранением.
Существует несколько онлайн-источников, из которых вы можете скачать наборы данных, такие как https://www.kaggle.com/uciml/datasets и https://archive.ics.uci.edu/ml/index.php . Вы также можете создать набор данных, собирая данные с помощью различных API-интерфейсов Python. Когда набор данных будет готов, вы должны поместить его в файлы форматов CSV, HTML или XLSX.

2. Импортируйте все важные библиотеки
Поскольку Python является наиболее широко используемой библиотекой, а также наиболее предпочтительной для специалистов по данным во всем мире, мы покажем вам, как импортировать библиотеки Python для предварительной обработки данных в машинном обучении. Подробнее о библиотеках Python для Data Science читайте здесь. Предопределенные библиотеки Python могут выполнять определенные задания по предварительной обработке данных. Импорт всех важных библиотек — это второй шаг предварительной обработки данных в машинном обучении. Три основные библиотеки Python, используемые для предварительной обработки данных в машинном обучении:
- NumPy — NumPy — это основной пакет для научных вычислений в Python. Следовательно, он используется для вставки любого типа математической операции в код. Используя NumPy, вы также можете добавлять в свой код большие многомерные массивы и матрицы.
- Pandas — Pandas — отличная библиотека Python с открытым исходным кодом для обработки и анализа данных. Он широко используется для импорта и управления наборами данных. Он включает в себя высокопроизводительные, простые в использовании структуры данных и инструменты анализа данных для Python.
- Matplotlib — Matplotlib — это библиотека двухмерных графиков Python, которая используется для построения любых типов диаграмм в Python. Он может предоставлять показатели качества публикации в многочисленных форматах печатных копий и интерактивных средах на разных платформах (оболочки IPython, блокноты Jupyter, серверы веб-приложений и т. д.).
Читайте : Идеи проекта машинного обучения для начинающих
3. Импортируйте набор данных
На этом этапе вам необходимо импортировать наборы данных, которые вы собрали для проекта ML. Импорт набора данных — один из важных этапов предварительной обработки данных в машинном обучении. Однако, прежде чем вы сможете импортировать набор/ы данных, вы должны установить текущий каталог в качестве рабочего каталога. Вы можете установить рабочий каталог в Spyder IDE, выполнив три простых шага:
- Сохраните файл Python в каталоге, содержащем набор данных.
- Перейдите к опции File Explorer в Spyder IDE и выберите нужный каталог.
- Теперь нажмите кнопку F5 или опцию «Выполнить», чтобы запустить файл.
Источник
Вот как должен выглядеть рабочий каталог.
После того, как вы установили рабочий каталог, содержащий соответствующий набор данных, вы можете импортировать набор данных, используя функцию «read_csv()» библиотеки Pandas. Эта функция может читать CSV-файл (локально или через URL-адрес), а также выполнять с ним различные операции. read_csv() записывается как:
data_set= pd.read_csv('Набор данных.csv')
В этой строке кода «data_set» обозначает имя переменной, в которой вы сохранили набор данных. Функция также содержит имя набора данных. После выполнения этого кода набор данных будет успешно импортирован.
В процессе импорта набора данных необходимо сделать еще одну важную вещь — извлечь зависимые и независимые переменные. Для каждой модели машинного обучения необходимо разделить независимые переменные (матрицу признаков) и зависимые переменные в наборе данных.
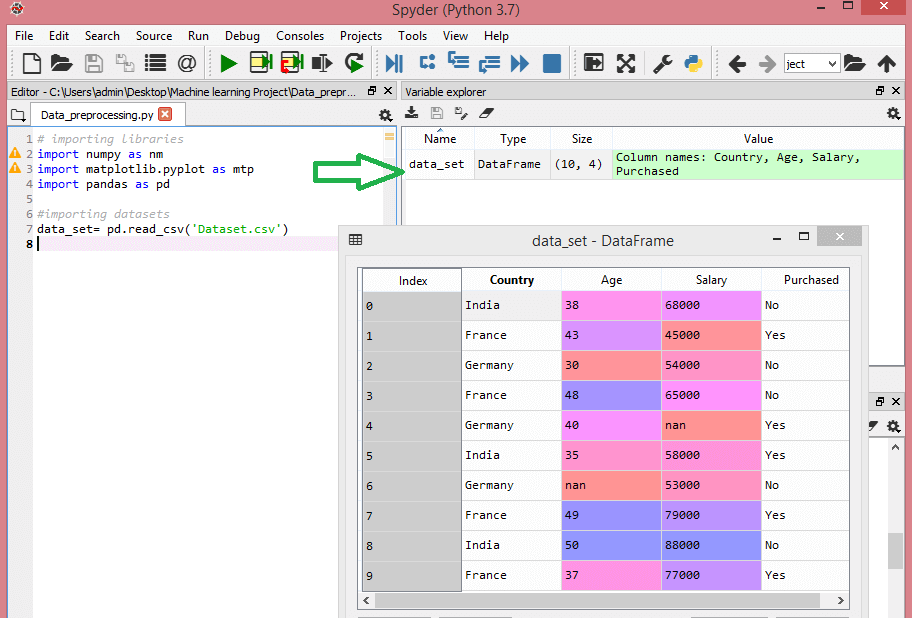
Рассмотрим этот набор данных:
Источник
Этот набор данных содержит три независимые переменные — страна, возраст и зарплата, а также одну зависимую переменную — покупка.
Как извлечь независимые переменные?
Чтобы извлечь независимые переменные, вы можете использовать функцию «iloc[]» библиотеки Pandas. Эта функция может извлекать выбранные строки и столбцы из набора данных.
x= data_set.iloc[:,:-1].значения
В приведенной выше строке кода первое двоеточие (:) учитывает все строки, а второе двоеточие (:) — все столбцы. Код содержит «:-1», так как вы должны пропустить последний столбец, содержащий зависимую переменную. Выполнив этот код, вы получите матрицу функций, например такую:
[['Индия' 38,0 68000,0]
['Франция' 43.0 45000.0]
['Германия' 30.0 54000.0]
['Франция' 48.0 65000.0]
['Германия' 40,0 нано]
['Индия' 35,0 58000,0]
['Германия' нан 53000.0]
['Франция' 49.0 79000.0]
['Индия' 50.0 88000.0]
['Франция' 37.0 77000.0]]
Как извлечь зависимую переменную?
Вы также можете использовать функцию «iloc[]» для извлечения зависимой переменной. Вот как вы это пишете:
y= набор_данных.iloc[:,3].значения
Эта строка кода рассматривает все строки только с последним столбцом. Выполнив приведенный выше код, вы получите массив зависимых переменных, например:
array(['Нет', 'Да', 'Нет', 'Нет', 'Да', 'Да', 'Нет', 'Да', 'Нет', 'Да'],
тип = объект)
4. Определение и обработка пропущенных значений
При предварительной обработке данных крайне важно идентифицировать и правильно обрабатывать отсутствующие значения, в противном случае вы можете сделать неточные и ошибочные выводы и выводы на основе данных. Излишне говорить, что это помешает вашему проекту машинного обучения.
По сути, есть два способа обработки отсутствующих данных:
- Удаление определенной строки. В этом методе вы удаляете определенную строку с нулевым значением для функции или определенного столбца, в котором отсутствует более 75% значений. Однако этот метод не на 100 % эффективен, и его рекомендуется использовать только в том случае, если в наборе данных имеется достаточно выборок. Вы должны убедиться, что после удаления данных не осталось никакого смещения.
- Вычисление среднего — этот метод полезен для функций, имеющих числовые данные, такие как возраст, зарплата, год и т. д. Здесь вы можете вычислить среднее значение, медиану или моду определенной функции, столбца или строки, которая содержит отсутствующее значение, и заменить результат для пропущенного значения. Этот метод может добавить дисперсию в набор данных, и любую потерю данных можно эффективно свести на нет. Следовательно, он дает лучшие результаты по сравнению с первым методом (пропуск строк/столбцов). Другой способ аппроксимации — отклонение соседних значений. Однако это лучше всего работает для линейных данных.
Читайте: Применение приложений машинного обучения с использованием облака
5. Кодирование категориальных данных
Категориальные данные относятся к информации, которая имеет определенные категории в наборе данных. В приведенном выше наборе данных есть две категориальные переменные — страна и покупка.
Модели машинного обучения в основном основаны на математических уравнениях. Таким образом, вы можете интуитивно понять, что сохранение категорийных данных в уравнении вызовет определенные проблемы, поскольку вам понадобятся только числа в уравнениях.
Как закодировать переменную страны?
Как видно из нашего примера набора данных, столбец страны вызовет проблемы, поэтому вы должны преобразовать его в числовые значения. Для этого вы можете использовать класс LabelEncoder() из учебной библиотеки sci-kit. Код будет следующим –
#категориальные данные
#для переменной страны
из sklearn.preprocessing импортировать LabelEncoder
label_encoder_x= LabelEncoder()
х [:, 0] = label_encoder_x.fit_transform (х [:, 0])
А на выходе будет -
Исход[15]:
массив([[2, 38.0, 68000.0],
[0, 43,0, 45000,0],
[1, 30,0, 54000,0],
[0, 48,0, 65000,0],
[1, 40.0, 65222.22222222222],
[2, 35,0, 58000,0],
[1, 41.111111111111114, 53000.0],
[0, 49,0, 79000,0],
[2, 50,0, 88000,0],
[0, 37.0, 77000.0]], dtype=объект)
Здесь мы видим, что класс LabelEncoder успешно закодировал переменные в цифры. Однако есть переменные страны, которые закодированы как 0, 1 и 2 в выходных данных, показанных выше. Таким образом, модель ML может предполагать, что между тремя переменными возникла некоторая корреляция, что приводит к ошибочным результатам. Чтобы устранить эту проблему, мы теперь будем использовать фиктивное кодирование.
Фиктивная переменная — это переменная, принимающая значения 0 или 1, чтобы указать на отсутствие или наличие определенного категориального эффекта, который может изменить результат. В этом случае значение 1 указывает на присутствие этой переменной в конкретном столбце, в то время как другие переменные получают значение 0. В фиктивном кодировании количество столбцов равно количеству категорий.
Поскольку наш набор данных имеет три категории, он создаст три столбца со значениями 0 и 1. Для фиктивного кодирования мы будем использовать класс OneHotEncoder библиотеки scikit-learn. Код ввода будет следующим:
#для переменной страны
из sklearn.preprocessing импортировать LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
х [:, 0] = label_encoder_x.fit_transform (х [:, 0])

#Кодирование фиктивных переменных
onehot_encoder = OneHotEncoder (categorical_features = [0])
х = onehot_encoder.fit_transform(x).toarray()
При выполнении этого кода вы получите следующий вывод:
массив([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0,00000000e+00, 1,00000000e+00, 0,00000000e+00, 3,00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0,00000000e+00, 0,00000000e+00, 1,00000000e+00, 3,50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
В выводе, показанном выше, все переменные разделены на три столбца и закодированы в значения 0 и 1.
Как закодировать купленную переменную?
Для второй категориальной переменной, то есть купленной, можно использовать объект «labelencoder» класса LableEncoder. Мы не используем класс OneHotEncoder, так как купленная переменная имеет только две категории да или нет, обе из которых закодированы в 0 и 1.
Входной код для этой переменной будет –
labelencoder_y= LabelEncoder()
y = labelencoder_y.fit_transform (y)
Выход будет -
Выход[17]: массив([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. Разделение набора данных
Разделение набора данных — это следующий шаг в предварительной обработке данных в машинном обучении. Каждый набор данных для модели машинного обучения должен быть разделен на два отдельных набора — обучающий набор и тестовый набор.
Источник
Обучающий набор обозначает подмножество набора данных, которое используется для обучения модели машинного обучения. Здесь вы уже знаете о выводе. С другой стороны, тестовый набор — это подмножество набора данных, которое используется для тестирования модели машинного обучения. Модель ML использует набор тестов для прогнозирования результатов.
Обычно набор данных делится на соотношение 70:30 или 80:20. Это означает, что вы либо берете 70%, либо 80% данных для обучения модели, а остальные 30% или 20% пропускаете. Процесс разделения зависит от формы и размера рассматриваемого набора данных.
Чтобы разделить набор данных, вам нужно написать следующую строку кода:
из sklearn.model_selection импорта train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0,2, random_state=0)
Здесь первая строка разбивает массивы набора данных на случайные обучающие и тестовые подмножества. Вторая строка кода включает четыре переменные:
- x_train — функции для обучающих данных
- x_test — функции для тестовых данных
- y_train — зависимые переменные для обучающих данных
- y_test — независимая переменная для тестирования данных
Таким образом, функция train_test_split() включает четыре параметра, первые два из которых предназначены для массивов данных. Функция test_size указывает размер набора тестов. test_size может быть 0,5, 0,3 или 0,2 — это определяет соотношение разделения между обучающим и тестовым наборами. Последний параметр «random_state» задает начальное значение для генератора случайных чисел, чтобы выходные данные всегда были одинаковыми.
7. Масштабирование функций
Масштабирование признаков знаменует собой окончание предварительной обработки данных в машинном обучении. Это метод стандартизации независимых переменных набора данных в определенном диапазоне. Другими словами, масштабирование функций ограничивает диапазон переменных, чтобы вы могли сравнивать их на общих основаниях.
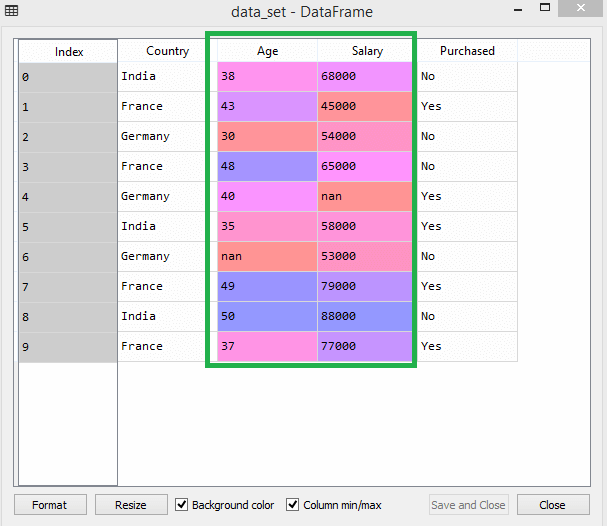
Рассмотрим этот набор данных, например -
Источник
В наборе данных вы можете заметить, что столбцы возраста и зарплаты не имеют одинакового масштаба. В таком сценарии, если вы вычисляете любые два значения из столбцов age и зарплаты, значения зарплаты будут доминировать над значениями возраста и давать неверные результаты. Таким образом, вы должны устранить эту проблему, выполнив масштабирование функций для машинного обучения.
Большинство моделей машинного обучения основаны на евклидовом расстоянии, которое представлено в виде:
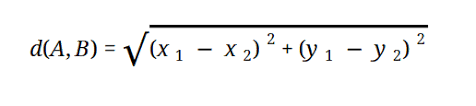
Источник
Вы можете выполнить масштабирование функций в машинном обучении двумя способами:
Стандартизация
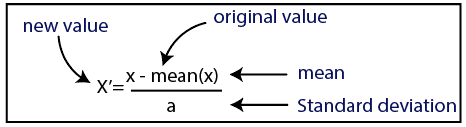
Источник
Нормализация
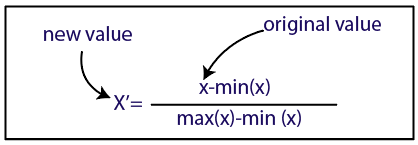
Источник
Для нашего набора данных мы будем использовать метод стандартизации. Для этого мы импортируем класс StandardScaler из библиотеки sci-kit-learn, используя следующую строку кода:
из sklearn.preprocessing импортировать StandardScaler
Следующим шагом будет создание объекта класса StandardScaler для независимых переменных. После этого вы можете подогнать и преобразовать обучающий набор данных, используя следующий код:
st_x= Стандартный масштаб()
x_train = st_x.fit_transform (x_train)
Для тестового набора данных вы можете напрямую применить функцию transform() (вам не нужно использовать функцию fit_transform(), потому что она уже выполнена в тренировочном наборе). Код будет следующим –
x_test = st_x.transform (x_test)
Выходные данные для тестового набора данных будут отображать масштабированные значения для x_train и x_test как:
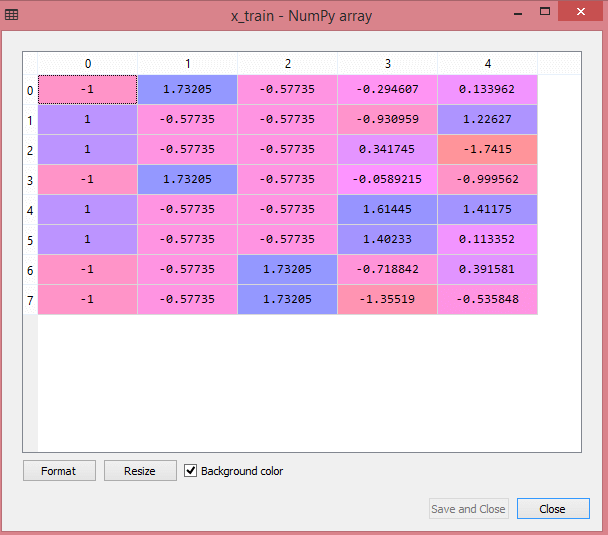
Источник
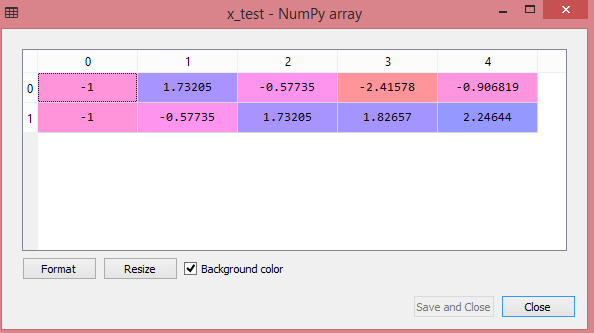
Источник
Все переменные в выводе масштабируются между значениями -1 и 1.
Теперь, чтобы объединить все шаги, которые мы выполнили до сих пор, вы получите:
# импорт библиотек
импортировать numpy как nm
импортировать matplotlib.pyplot как mtp
импортировать панд как pd
#импорт наборов данных
data_set= pd.read_csv('Набор данных.csv')
#Извлечение независимой переменной
x= data_set.iloc[:, :-1].значения
#Извлечение зависимой переменной
y= data_set.iloc[:, 3].значения
# обработка отсутствующих данных (замена отсутствующих данных средним значением)
из sklearn.preprocessing import Imputer
imputer = Imputer (missing_values = 'NaN', стратегия = 'среднее', ось = 0)
# Подгонка объекта импутера к независимым переменным x.
imputerimputer= imputer.fit(x[:, 1:3])
# Замена отсутствующих данных рассчитанным средним значением
х[:, 1:3]= импьютер.преобразование(х[:, 1:3])
#для переменной страны
из sklearn.preprocessing импортировать LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
х [:, 0] = label_encoder_x.fit_transform (х [:, 0])
#Кодирование фиктивных переменных
onehot_encoder = OneHotEncoder (categorical_features = [0])
х = onehot_encoder.fit_transform(x).toarray()
#кодировка купленной переменной
labelencoder_y= LabelEncoder()
y = labelencoder_y.fit_transform (y)
# Разделение набора данных на обучающий и тестовый наборы.
из sklearn.model_selection импорта train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0,2, random_state=0)
#Feature Масштабирование наборов данных
из sklearn.preprocessing импортировать StandardScaler
st_x= Стандартный масштаб()
x_train = st_x.fit_transform (x_train)
x_test = st_x.transform (x_test)
Итак, это обработка данных в машинном обучении в двух словах!
Вы можете ознакомиться с программой Executive PG IIT Delhi в области машинного обучения и искусственного интеллекта совместно с upGrad . IIT Delhi является одним из самых престижных учебных заведений в Индии. С более чем 500+ штатными преподавателями, которые являются лучшими в своих предметах.
В чем важность предварительной обработки данных?
Поскольку ошибки, избыточность, отсутствующие значения и несоответствия — все это ставит под угрозу целостность набора данных, для получения более точного результата необходимо устранить их все. Предположим, вы используете дефектный набор данных для обучения системы машинного обучения работе с покупками ваших клиентов. Система может генерировать предубеждения и отклонения, что приводит к плохому взаимодействию с пользователем. В результате, прежде чем использовать эти данные по прямому назначению, они должны быть организованы и «чисты», насколько это возможно. В зависимости от типа сложности, с которой вы имеете дело, существует множество вариантов.
Что такое очистка данных?
Почти наверняка в ваших наборах данных будут отсутствующие и зашумленные данные. Поскольку процедура сбора данных не идеальна, у вас будет много бесполезной и недостающей информации. Очистка данных — это способ, которым вы должны воспользоваться для решения этой проблемы. Это можно разделить на две категории. В первом обсуждается, как работать с отсутствующими данными. Вы можете игнорировать отсутствующие значения в этом разделе сбора данных (называемом кортежем). Второй метод очистки данных предназначен для зашумленных данных. Крайне важно избавиться от бесполезных данных, которые не могут быть прочитаны системами, если вы хотите, чтобы весь процесс работал гладко.
Что вы подразумеваете под преобразованием и сокращением данных?
Предварительная обработка данных переходит к этапу преобразования после решения проблем. Вы используете его для преобразования данных в соответствующие конформации для анализа. Нормализация, выбор атрибутов, дискретизация и создание иерархии понятий — вот некоторые из подходов, которые можно использовать для достижения этой цели. Даже для автоматизированных методов просеивание больших наборов данных может занять много времени. Именно поэтому этап редукции данных так важен: он уменьшает размер наборов данных, ограничивая их наиболее важной информацией, повышает эффективность хранения при одновременном снижении финансовых и временных затрат на работу с ними.