
Фреймы данных в Python: подробное руководство по Python 2022
Опубликовано: 2021-01-09Если вы разработчик или кодер, работающий на языке программирования Python, вы должны быть знакомы с одной из самых замечательных библиотек управления данными — Pandas, одной из лучших библиотек Python. За прошедшие годы Pandas превратился в стандартный инструмент для анализа данных и управления ими с использованием Python. Прочтите о других важных инструментах Python.
Pandas, несомненно, является самым универсальным пакетом Python для науки о данных, и это правильно. Он предоставляет мощные, выразительные и гибкие структуры данных для удобной обработки и анализа данных, и кадры данных в Python — одна из таких структур.
Это как раз и есть наша тема для обсуждения в этом посте — мы познакомим вас с базовым форматом данных для Pandas, то есть с фреймом данных Pandas.
Оглавление
Что такое фрейм данных?
Согласно документации библиотеки Pandas , Data Frame — это «двумерная, изменяемая по размеру, потенциально гетерогенная табличная структура данных с помеченными осями (строками и столбцами)». Проще говоря, фрейм данных — это структура данных, в которой данные выровнены в виде таблицы, то есть в строках и столбцах.
Фрейм данных обычно имеет следующие характеристики:
- Он может иметь несколько строк и столбцов.
- Хотя каждая строка представляет выборку данных, каждый столбец содержит другую переменную, описывающую выборки (строки).
- Данные в каждом столбце обычно представляют собой данные одного типа (например, числа, строки, даты и т. д.).
- В отличие от наборов данных Excel, он позволяет избежать пропущенных значений, поэтому между строками или столбцами нет пробелов или пустых значений.
Во фрейме данных Pandas вы также можете указать индекс и имена столбцов для вашего фрейма данных. В то время как индекс указывает на разницу в строках, имена столбцов показывают разницу в столбцах.
Как создать фрейм данных в Python (с использованием Pandas)
Создание фрейма данных — это первый шаг к обработке данных в Python. Вы можете создать фрейм данных Pandas, используя такие входные данные, как:
- Дикт
- Списки
- Ряд
- Numpy «ндаррай»
- Другой фрейм данных
- Внешние файлы, такие как CS
- Создание пустого фрейма данных
Довольно легко создать базовый фрейм данных, также известный как пустой фрейм данных. Вот пример:
Вход -

Выход -

- Создание фрейма данных из списков
Вы можете создать фрейм данных, используя один список или несколько списков.
Вход -

Выход -

- Создание кадра данных из Dict «ndarrays» или списков
Чтобы создать фрейм данных из набора ndarray, все ndarray должны иметь одинаковую длину. Также, если он индексируется, длина индекса должна быть равна длине массивов. Однако, если он не проиндексирован, по умолчанию индекс будет равен диапазону (n), где «n» обозначает длину массива.
Вход -

Выход -

Здесь значения 0,1,2,3 являются индексом по умолчанию, назначаемым каждой строке с помощью функции range(n).
Каковы основные операции с фреймами данных?
Теперь, когда мы рассмотрели три способа создания фреймов данных в Python, пришло время узнать о различных операциях внутри фрейма данных.
- Выбор индекса или столбца из фрейма данных Pandas
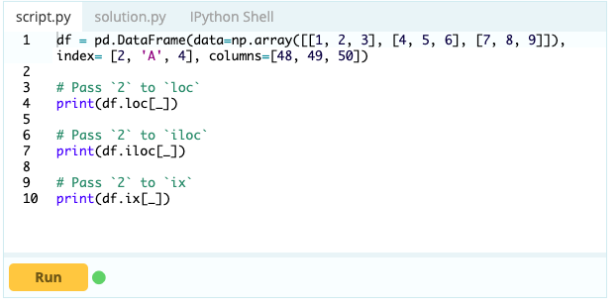
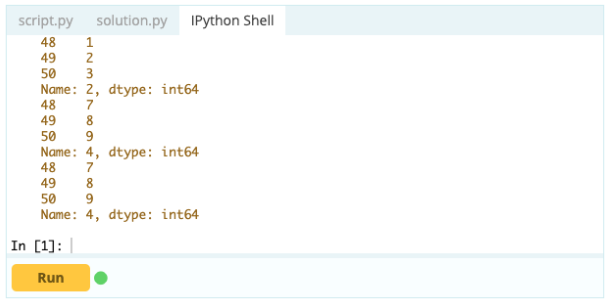
Важно знать, как выбрать индекс или столбец, прежде чем можно будет начать добавлять, удалять и переименовывать компоненты в DataFrame. Предположим, это ваш фрейм данных:

Вы хотите получить доступ к значению под индексом 0 в столбце «A» — значение равно 1. Есть много способов получить доступ к этому значению, но два самых важных — .loc[] и .iloc[].
Вход -
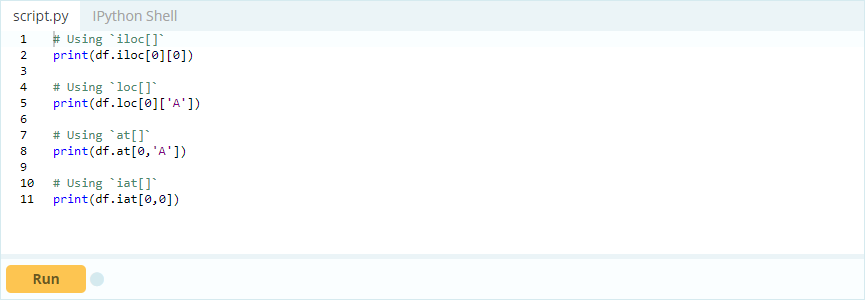
Выход -
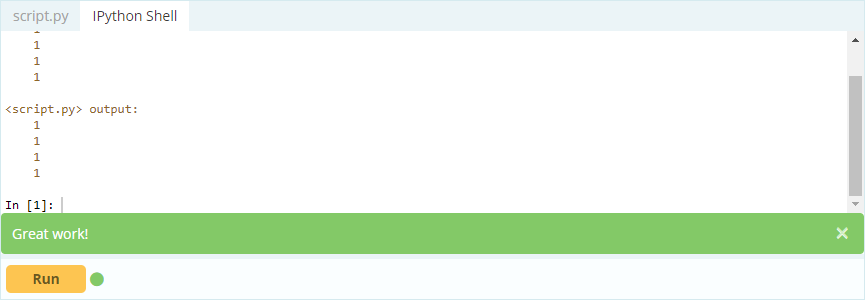
Итак, как видите, вы можете получить доступ к значениям, либо вызывая их по их меткам, либо объявляя их позицию в индексе или столбце. Хотя это был выбор значения из фрейма данных, как вы можете выбрать строки и столбцы из него?
Вот как:
Вход -
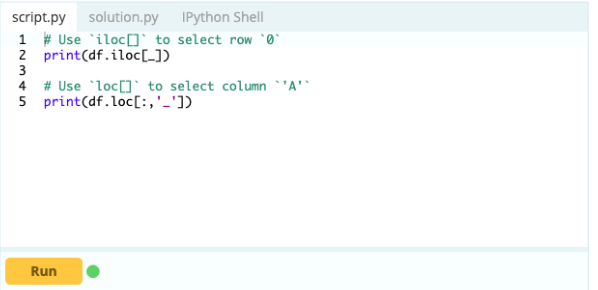
Выход-
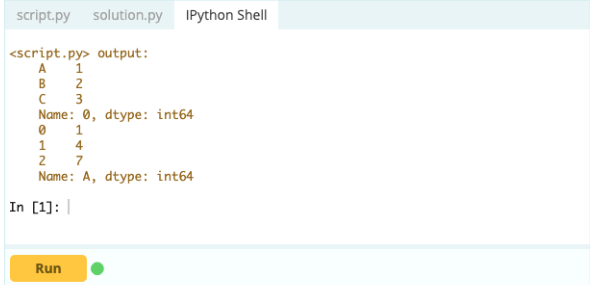
- Как добавить индекс, строку или столбец в фрейм данных Pandas
Как только вы научитесь получать доступ к значениям и выбирать столбцы из фрейма данных, вы сможете научиться добавлять индекс, строку или столбец в фрейм данных Pandas.
Добавление индекса:
При создании фрейма данных вы можете добавить ввод в аргумент «индекс». Это гарантирует, что вы можете легко получить доступ к нужному индексу. Если вы не укажете индекс, по умолчанию к нему будет добавлен числовой индекс, который начинается с 0 и продолжается до последней строки DataFrame. Хотя даже после того, как индекс указан по умолчанию, вы можете использовать столбец и преобразовать его в индекс, вызвав функцию set_index() во фрейме данных.

Добавление строки:
Вы можете добавлять строки в DataFrame, используя функцию добавления.
Вход -

Выход -

Вы также можете использовать .loc для вставки строк в свой DataFrame следующим образом:
Вход -
Выход -
Добавление столбца
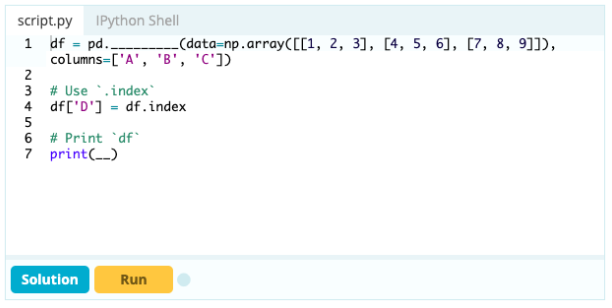
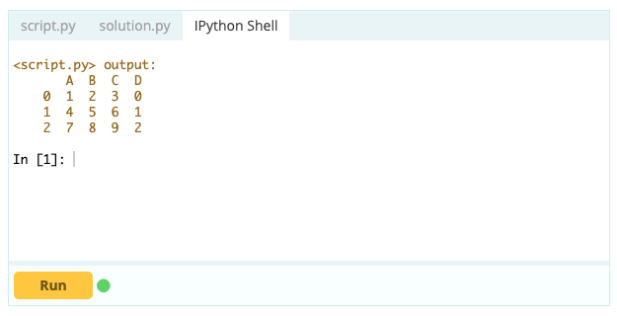
Если вы хотите сделать индекс частью фрейма данных, вы можете взять столбец из фрейма данных или обратиться к столбцу, который еще не создан, и назначить его свойству .index следующим образом:
Вход -
Выход -
Для добавления столбцов в фрейм данных вы также можете использовать тот же подход, который вы использовали бы для добавления индекса в фрейм данных, то есть вы можете использовать функцию .loc[] или .iloc[]. Например:
Вход -
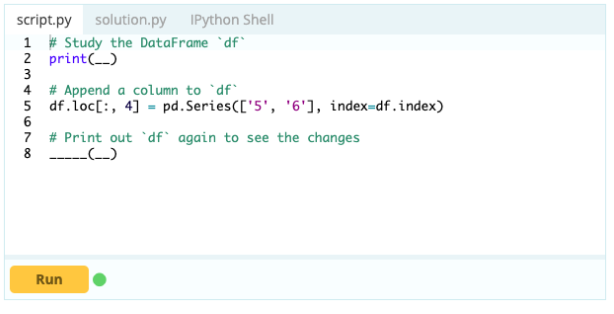
Выход
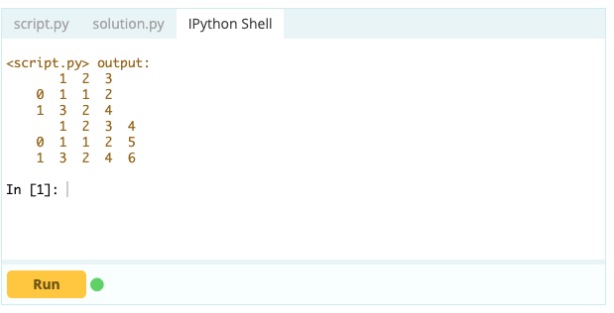
С помощью .loc[] вы можете добавить серию в существующий кадр данных. Поскольку объект серии очень похож на столбец фрейма данных, добавить серию в существующий фрейм данных очень просто.
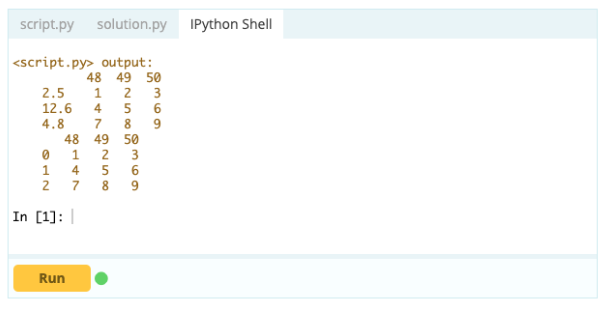
- Как сбросить индекс фрейма данных?
Вы можете сбросить индекс фрейма данных, если он выглядит не так, как вы хотели. Для этого вы можете использовать функцию .reset_index().
Вход -
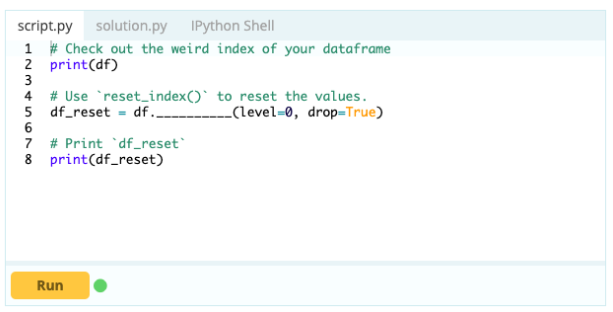
Выход -
- Как удалить индекс, строку или столбец в кадре данных Pandas
Удаление индекса
- Сброс индекса фрейма данных.
- Удалите имя индекса (если есть) с помощью функции del df.index.name.
- Удалить индекс вместе со строкой.
- Удалите все повторяющиеся значения индекса, сбросив индекс, удалив дубликаты столбца индекса, который был добавлен во фрейм данных, и снова восстановив новый столбец (без дублирующегося индекса) в качестве индекса.
Удаление столбца
Для удаления столбцов из фрейма данных вы можете использовать функцию drop().
Вход -
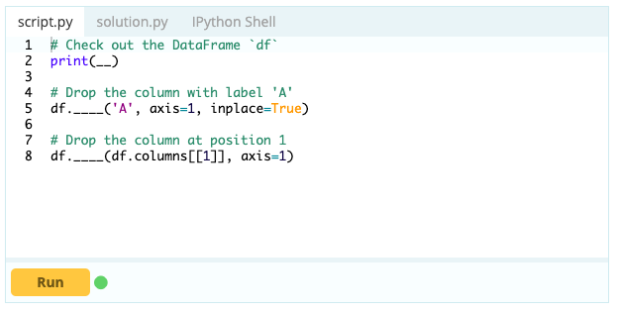
Выход -
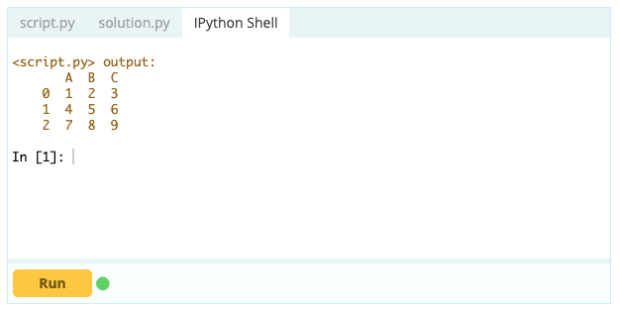
Удаление строки
Чтобы удалить строку из фрейма данных, вы можете использовать функцию drop(), используя свойство index, чтобы указать индекс строк, которые вы хотите удалить из фрейма данных.
Вход -
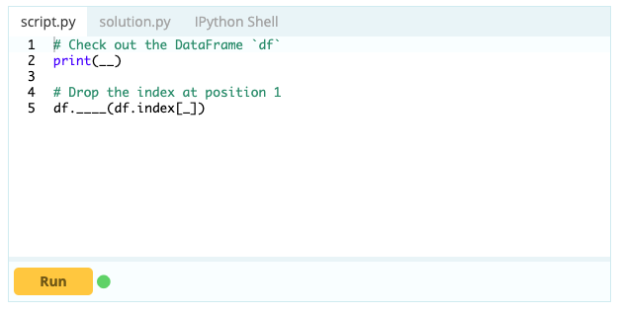
Выход -
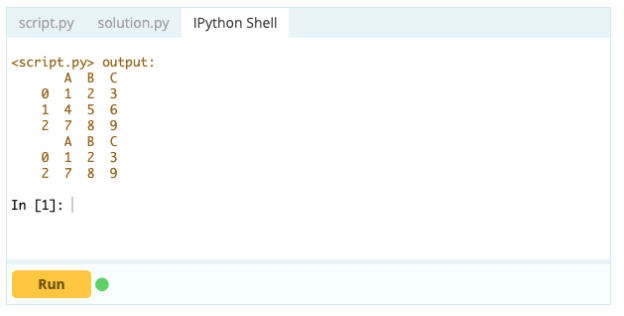
Однако для удаления повторяющихся строк вы можете использовать функцию df.drop_duplicates().
Вход -
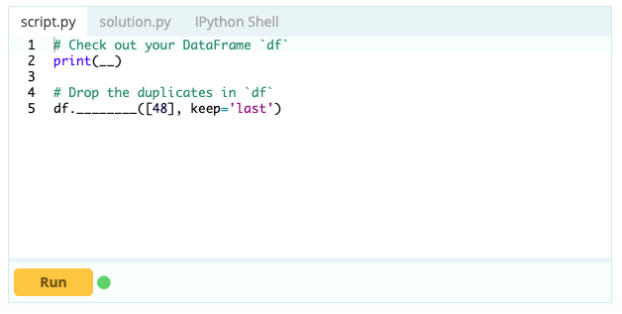
Выход -
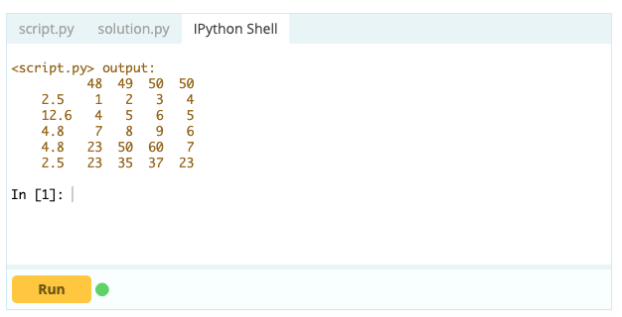
Источники: Tutorialspoint Datacamp
Заключение
Итак, вот ваш базовый учебник по фрейму данных в Python с использованием Pandas.
Если вы заинтересованы в изучении Python, науке о данных, ознакомьтесь с дипломом IIIT-B & upGrad PG в области науки о данных, который создан для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, Индивидуальные встречи с отраслевыми наставниками, более 400 часов обучения и помощь в трудоустройстве в ведущих фирмах.
Почему Pandas является одной из наиболее предпочтительных библиотек для создания фреймов данных в Python?
Библиотека Pandas считается наиболее подходящей для создания фреймов данных, поскольку она предоставляет различные функции, которые делают создание фрейма данных более эффективным. Вот некоторые из этих функций: Pandas предоставляет нам различные фреймы данных, которые не только обеспечивают эффективное представление данных, но и позволяют нам манипулировать ими. Он обеспечивает эффективные функции выравнивания и индексации, которые обеспечивают интеллектуальные способы маркировки и организации данных. Некоторые функции Pandas делают код чистым и повышают его читабельность, что делает его более эффективным. Он также может читать несколько форматов файлов. JSON, CSV, HDF5 и Excel — это некоторые из форматов файлов, поддерживаемых Pandas. Слияние нескольких наборов данных стало настоящей проблемой для многих программистов. Панды преодолевают и это и очень эффективно объединяют несколько наборов данных.
Какие другие библиотеки и инструменты дополняют библиотеку Pandas?
Pandas работает не только как центральная библиотека для создания фреймов данных, но и работает с другими библиотеками и инструментами Python для большей эффективности. Pandas построен на основе пакета NumPy Python, что указывает на то, что большая часть структуры библиотеки Pandas реплицирована из пакета NumPy. Статистический анализ данных в библиотеке Pandas выполняется SciPy, функции построения графиков — в Matplotlib, а алгоритмы машинного обучения — в Scikit-learn. Jupyter Notebook — это интерактивная веб-среда, которая работает как IDE и предлагает хорошую среду для Pandas.
Каковы основные операции с фреймами данных?
Важно выбрать индекс или столбец перед началом любой операции, такой как добавление или удаление. Как только вы научитесь получать доступ к значениям и выбирать столбцы из фрейма данных, вы сможете научиться добавлять индекс, строку или столбец в фрейм данных Pandas. Если индекс во фрейме данных не соответствует вашим ожиданиям, вы можете сбросить его. Для сброса индекса вы можете использовать функцию «reset_index()».