
«Создайте один раз, публикуйте везде» с WordPress
Опубликовано: 2022-03-10COPE — это стратегия сокращения объема работы, необходимой для публикации нашего контента в различных средах, таких как веб-сайт, электронная почта, приложения и другие. Впервые предложенный NPR, он достигает своей цели, устанавливая единый источник достоверности контента, который можно использовать для всех различных сред.
Наличие контента, который работает везде, — нетривиальная задача, поскольку у каждого носителя будут свои требования. Например, в то время как HTML допустим для печати контента для Интернета, этот язык не подходит для приложений iOS/Android. Точно так же мы можем добавить классы в наш HTML для Интернета, но они должны быть преобразованы в стили для электронной почты.
Решение этой головоломки состоит в том, чтобы отделить форму от содержания: представление и значение содержания должны быть отделены друг от друга, и только значение используется как единственный источник истины. Презентация затем может быть добавлена в другой слой (специфический для выбранного носителя).
Например, в следующем фрагменте HTML-кода <p> — это тег HTML, который применяется в основном для Интернета, а атрибут class="align-center" — представление (размещение элемента «по центру» имеет смысл для для экранного носителя, но не для звукового, такого как Amazon Alexa):
<p class="align-center">Hello world!</p>Следовательно, этот фрагмент контента нельзя использовать как единственный источник правды, и его необходимо преобразовать в формат, который отделяет смысл от представления, например следующий фрагмент кода JSON:
{ content: "Hello world!", placement: "center", type: "paragraph" }Этот фрагмент кода можно использовать в качестве единственного источника достоверности контента, поскольку из него мы можем еще раз воссоздать HTML-код для использования в Интернете и получить соответствующий формат для других сред.
Почему WordPress
WordPress идеально подходит для реализации стратегии COPE по нескольким причинам:
- Он универсален.
Модель базы данных WordPress не определяет фиксированную, жесткую модель контента; напротив, он был создан для универсальности, позволяющей создавать различные модели контента с помощью метаполя, которое позволяет хранить дополнительные фрагменты данных для четырех различных объектов: сообщений и пользовательских типов сообщений, пользователей, комментариев и таксономий ( теги и категории). - Это мощно.
WordPress сияет как CMS (система управления контентом), а его экосистема плагинов позволяет легко добавлять новые функции. - Это широко распространено.
Подсчитано, что 1/3 веб-сайтов работает на WordPress. Кроме того, значительное количество людей, работающих в Интернете, знают и могут использовать WordPress. Не только разработчики, но и блогеры, продавцы, маркетологи и так далее. Тогда множество различных заинтересованных сторон, независимо от их технического образования, смогут создавать контент, который действует как единственный источник правды. - Он безголовый.
Безголовость — это возможность отделить контент от уровня представления, и это фундаментальная функция для реализации COPE (чтобы иметь возможность передавать данные на разные носители).
С момента включения WP REST API в ядро, начиная с версии 4.7, и, что более заметно, с момента запуска Gutenberg в версии 5.0 (для чего пришлось реализовать множество конечных точек REST API), WordPress можно считать безголовой CMS, поскольку большая часть контента WordPress доступ через REST API может быть получен любым приложением, построенным на любом стеке.
Кроме того, недавно созданный WPGraphQL интегрирует WordPress и GraphQL, позволяя передавать контент из WordPress в любое приложение с помощью этого все более популярного API. Наконец, мой собственный проект PoP недавно добавил реализацию API для WordPress, которая позволяет экспортировать данные WordPress в форматах REST, GraphQL или PoP. - В нем есть Gutenberg , блочный редактор, который значительно облегчает реализацию COPE, поскольку он основан на концепции блоков (как объясняется в разделах ниже).
Блобы против блоков для представления информации
Большой двоичный объект — это единая единица информации, хранящаяся вместе в базе данных. Например, при написании приведенного ниже сообщения в блоге на CMS, которая использует большие двоичные объекты для хранения информации, содержимое сообщения в блоге будет храниться в одной записи базы данных, содержащей тот же контент:
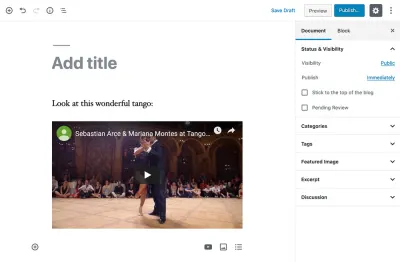
<p>Look at this wonderful tango:</p> <figure> <iframe width="951" height="535" src="https://www.youtube.com/embed/sxm3Xyutc1s" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe> <figcaption>An exquisite tango performance</figcaption> </figure>Как можно понять, важные фрагменты информации из этого сообщения в блоге (такие как содержание абзаца и URL-адрес, размеры и атрибуты видео на Youtube) не легко доступны: если мы хотим получить любой из них сами по себе нам нужно разобрать HTML-код, чтобы извлечь их, что далеко не идеальное решение.
Блоки действуют по-разному. Представляя информацию в виде списка блоков, мы можем хранить контент более понятным и доступным способом. Каждый блок передает свое содержание и свои свойства, которые могут зависеть от его типа (например, это может быть абзац или видео?).
Например, приведенный выше HTML-код можно представить в виде списка таких блоков:
{ [ type: "paragraph", content: "Look at this wonderful tango:" ], [ type: "embed", provider: "Youtube", url: "https://www.youtube.com/embed/sxm3Xyutc1s", width: 951, height: 535, frameborder: 0, allowfullscreen: true, allow: "accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture", caption: "An exquisite tango performance" ] } Благодаря такому способу представления информации мы можем легко использовать любой фрагмент данных самостоятельно и адаптировать его для конкретного носителя, на котором он должен отображаться. Например, если мы хотим извлечь все видео из сообщения в блоге для показа в автомобильной развлекательной системе, мы можем просто перебрать все блоки информации, выбрать блоки с type="embed" и provider="Youtube" и извлечь URL от них. Точно так же, если мы хотим показать видео на Apple Watch, нам не нужно заботиться о размерах видео, поэтому мы можем игнорировать атрибуты width и height простым способом.
Как Гутенберг реализует блоки
До версии WordPress 5.0 WordPress использовал большие двоичные объекты для хранения содержимого сообщений в базе данных. Начиная с версии 5.0, WordPress поставляется с Гутенбергом, блочным редактором, обеспечивающим улучшенный способ обработки контента, упомянутый выше, что представляет собой прорыв в реализации COPE. К сожалению, Gutenberg не был разработан для этого конкретного случая использования, и его представление информации отличается от только что описанного для блоков, что приводит к некоторым неудобствам, с которыми нам придется иметь дело.
Давайте сначала посмотрим, как запись в блоге, описанная выше, сохраняется через Gutenberg:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube -->Из этого фрагмента кода мы можем сделать следующие наблюдения:
Блоки сохраняются все вместе в одной записи базы данных
В приведенном выше коде есть два блока:
<!-- wp:paragraph --> <p>Look at this wonderful tango:</p> <!-- /wp:paragraph --> <!-- wp:core-embed/youtube {"url":"https://www.youtube.com/embed/sxm3Xyutc1s","type":"rich","providerNameSlug":"embed-handler","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} --> <figure class="wp-block-embed-youtube wp-block-embed is-type-rich is-provider-embed-handler wp-embed-aspect-16-9 wp-has-aspect-ratio"> <div class="wp-block-embed__wrapper"> https://www.youtube.com/embed/sxm3Xyutc1s </div> <figcaption>An exquisite tango performance</figcaption> </figure> <!-- /wp:core-embed/youtube --> За исключением глобальных (также называемых «повторно используемыми») блоков, которые имеют собственную запись в базе данных и на которые можно ссылаться напрямую через их идентификаторы, все блоки сохраняются вместе в записи блога в таблице wp_posts .
Следовательно, чтобы получить информацию для определенного блока, нам сначала нужно проанализировать содержимое и изолировать все блоки друг от друга. Для удобства WordPress предоставляет функцию parse_blocks($content) именно для этого. Эта функция получает строку, содержащую содержимое записи блога (в формате HTML), и возвращает объект JSON, содержащий данные для всех содержащихся блоков.
Тип блока и атрибуты передаются через комментарии HTML
Каждый блок отделяется начальным тегом <!-- wp:{block-type} {block-attributes-encoded-as-JSON} --> и конечным тегом <!-- /wp:{block-type} --> которые (будучи комментариями HTML) гарантируют, что эта информация не будет видна при отображении ее на веб-сайте. Однако мы не можем отобразить сообщение в блоге непосредственно на другом носителе, поскольку HTML-комментарий может быть виден как искаженное содержимое. Однако это не имеет большого значения, так как после разбора содержимого с помощью функции parse_blocks($content) комментарии HTML удаляются, и мы можем напрямую работать с данными блока как с объектом JSON.
Блоки содержат HTML
Блок абзаца содержит "<p>Look at this wonderful tango:</p>" вместо "Look at this wonderful tango:" . Следовательно, он содержит HTML-код (теги <p> и </p> ), который бесполезен для других носителей и поэтому должен быть удален, например, с помощью PHP-функции strip_tags($content) .
При удалении тегов мы можем сохранить те HTML-теги, которые явно передают семантическую информацию, такие как теги <strong> и <em> (вместо их аналогов <b> и <i> , которые применяются только к экранному носителю), и удалите все остальные теги. Это связано с тем, что существует большая вероятность того, что семантические теги могут быть правильно интерпретированы и для других носителей (например, Amazon Alexa может распознавать теги <strong> и <em> и соответствующим образом изменять свой голос и интонацию при чтении фрагмента текста). Для этого мы вызываем функцию strip_tags со вторым параметром, содержащим разрешенные теги, и помещаем его в функцию-оболочку для удобства:
function strip_html_tags($content) { return strip_tags($content, '<strong><em>'); }Заголовок видео сохраняется в HTML, а не как атрибут
Как видно из видеоблока Youtube, заголовок "An exquisite tango performance" хранится внутри HTML-кода (заключенного тегом <figcaption /> ), но не внутри объекта атрибутов, закодированного в формате JSON. Как следствие, чтобы извлечь заголовок, нам нужно будет проанализировать содержимое блока, например, с помощью регулярного выражения:
function extract_caption($content) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $content, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; }Это препятствие, которое мы должны преодолеть, чтобы извлечь все метаданные из блока Гутенберга. Это происходит на нескольких блоках; поскольку не все части метаданных сохраняются как атрибуты, мы должны сначала определить, какие части метаданных являются этими частями, а затем проанализировать содержимое HTML, чтобы извлечь их поблочно и по частям.
Что касается COPE, то это упущенный шанс найти действительно оптимальное решение. Можно возразить, что альтернативный вариант тоже не идеален, так как будет дублировать информацию, сохраняя ее как внутри HTML, так и в качестве атрибута, что нарушает принцип DRY (не повторяй себя ). Однако это нарушение уже имеет место: например, атрибут className содержит значение "wp-embed-aspect-16-9 wp-has-aspect-ratio" , которое также печатается внутри содержимого в атрибуте HTML class .
Внедрение COPE
Примечание. Я выпустил эту функциональность, включая весь код, описанный ниже, как блок метаданных плагина WordPress. Вы можете установить его и поиграть с ним, чтобы ощутить мощь COPE. Исходный код доступен в этом репозитории GitHub.
Теперь, когда мы знаем, как выглядит внутреннее представление блока, давайте приступим к реализации COPE через Gutenberg. Процедура будет включать следующие этапы:
- Поскольку функция
parse_blocks($content)возвращает объект JSON с вложенными уровнями, мы должны сначала упростить эту структуру. - Мы повторяем все блоки и для каждого идентифицируем их части метаданных и извлекаем их, преобразовывая их в независимый от среды формат в процессе. Какие атрибуты добавляются к ответу, могут различаться в зависимости от типа блока.
- Наконец, мы делаем данные доступными через API (REST/GraphQL/PoP).
Давайте реализуем эти шаги один за другим.
1. Упрощение структуры объекта JSON
Возвращенный объект JSON из функции parse_blocks($content) имеет вложенную архитектуру, в которой данные для обычных блоков отображаются на первом уровне, но данные для ссылочного повторно используемого блока отсутствуют (добавляются только данные для ссылочного блока), а данные для вложенных блоков (которые добавляются в другие блоки) и для сгруппированных блоков (где несколько блоков могут быть сгруппированы вместе) отображаются на одном или нескольких подуровнях. Такая архитектура затрудняет обработку блочных данных из всех блоков в контенте поста, так как с одной стороны некоторые данные отсутствуют, а с другой мы априори не знаем, под сколькими уровнями расположены данные. Кроме того, есть разделитель блоков, размещенный через каждую пару блоков, не содержащих контента, который можно смело игнорировать.
Например, ответ, полученный от сообщения, содержащего простой блок, глобальный блок, вложенный блок, содержащий простой блок, и группу простых блоков в указанном порядке, выглядит следующим образом:
[ // Simple block { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Reference to reusable block { "blockName": "core/block", "attrs": { "ref": 218 }, "innerBlocks": [], "innerHTML": "", "innerContent": [] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Nested block { "blockName": "core/columns", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], // Contained nested blocks "innerBlocks": [ { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, // Empty block divider { "blockName": null, "attrs": [], "innerBlocks": [], "innerHTML": "\n\n", "innerContent": [ "\n\n" ] }, // Block group { "blockName": "core/group", "attrs": [], // Contained grouped blocks "innerBlocks": [ { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerBlocks": [], "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerBlocks": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] } ]Лучшее решение — иметь все данные на первом уровне, что значительно упрощает логику перебора всех данных блока. Следовательно, мы должны получить данные для этих повторно используемых/вложенных/сгруппированных блоков, а также добавить их на первый уровень. Как видно из приведенного выше кода JSON:
- Пустой разделительный блок имеет атрибут
"blockName"со значениемNULL. - Ссылка на повторно используемый блок определяется через
$block["attrs"]["ref"] - Вложенные и групповые блоки определяют содержащиеся в них блоки в
$block["innerBlocks"]
Следовательно, следующий PHP-код удаляет пустые блоки-разделители, идентифицирует повторно используемые/вложенные/сгруппированные блоки и добавляет их данные на первый уровень, а также удаляет все данные со всех подуровней:
/** * Export all (Gutenberg) blocks' data from a WordPress post */ function get_block_data($content, $remove_divider_block = true) { // Parse the blocks, and convert them into a single-level array $ret = []; $blocks = parse_blocks($content); recursively_add_blocks($ret, $blocks); // Maybe remove blocks without name if ($remove_divider_block) { $ret = remove_blocks_without_name($ret); } // Remove 'innerBlocks' property if it exists (since that code was copied to the first level, it is currently duplicated) foreach ($ret as &$block) { unset($block['innerBlocks']); } return $ret; } /** * Remove the blocks without name, such as the empty block divider */ function remove_blocks_without_name($blocks) { return array_values(array_filter( $blocks, function($block) { return $block['blockName']; } )); } /** * Add block data (including global and nested blocks) into the first level of the array */ function recursively_add_blocks(&$ret, $blocks) { foreach ($blocks as $block) { // Global block: add the referenced block instead of this one if ($block['attrs']['ref']) { $ret = array_merge( $ret, recursively_render_block_core_block($block['attrs']) ); } // Normal block: add it directly else { $ret[] = $block; } // If it contains nested or grouped blocks, add them too if ($block['innerBlocks']) { recursively_add_blocks($ret, $block['innerBlocks']); } } } /** * Function based on `render_block_core_block` */ function recursively_render_block_core_block($attributes) { if (empty($attributes['ref'])) { return []; } $reusable_block = get_post($attributes['ref']); if (!$reusable_block || 'wp_block' !== $reusable_block->post_type) { return []; } if ('publish' !== $reusable_block->post_status || ! empty($reusable_block->post_password)) { return []; } return get_block_data($reusable_block->post_content); } Вызов функции get_block_data($content) с передачей содержимого поста ( $post->post_content ) в качестве параметра, теперь мы получаем следующий ответ:
[[ { "blockName": "core/image", "attrs": { "id": 70, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/sandwich-1024x614.jpg\" alt=\"\" class=\"wp-image-70\"/><figcaption>This is a normal block</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n", "innerContent": [ "\n<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>\n" ] }, { "blockName": "core/columns", "attrs": [], "innerHTML": "\n<div class=\"wp-block-columns\">\n\n</div>\n", "innerContent": [ "\n<div class=\"wp-block-columns\">", null, "\n\n", null, "</div>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 69, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/espresso-1024x614.jpg\" alt=\"\" class=\"wp-image-69\"/></figure>\n" ] }, { "blockName": "core/column", "attrs": [], "innerHTML": "\n<div class=\"wp-block-column\"></div>\n", "innerContent": [ "\n<div class=\"wp-block-column\">", null, "</div>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>This is how I wake up every morning</p>\n", "innerContent": [ "\n<p>This is how I wake up every morning</p>\n" ] }, { "blockName": "core/group", "attrs": [], "innerHTML": "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">\n\n</div></div>\n", "innerContent": [ "\n<div class=\"wp-block-group\"><div class=\"wp-block-group__inner-container\">", null, "\n\n", null, "</div></div>\n" ] }, { "blockName": "core/image", "attrs": { "id": 71, "sizeSlug": "large" }, "innerHTML": "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n", "innerContent": [ "\n<figure class=\"wp-block-image size-large\"><img src=\"https://localhost/wp-content/uploads/2017/12/coffee-1024x614.jpg\" alt=\"\" class=\"wp-image-71\"/><figcaption>First element of the group</figcaption></figure>\n" ] }, { "blockName": "core/paragraph", "attrs": [], "innerHTML": "\n<p>Second element of the group</p>\n", "innerContent": [ "\n<p>Second element of the group</p>\n" ] } ] Хотя это и не является строго необходимым, очень полезно создать конечную точку REST API для вывода результата нашей новой функции get_block_data($content) , что позволит нам легко понять, какие блоки содержатся в конкретном сообщении и как они структурированный. Код ниже добавляет такую конечную точку в /wp-json/block-metadata/v1/data/{POST_ID} :

/** * Define REST endpoint to visualize a post's block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }/** * Define REST endpoint to visualize a post's block data */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'data/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_blocks' ]); }); function get_post_blocks($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $response = new WP_REST_Response($block_data); $response->set_status(200); return $response; }
Чтобы увидеть его в действии, перейдите по этой ссылке, которая экспортирует данные для этого поста.
2. Извлечение всех метаданных блока в независимый от среды формат
На данном этапе у нас есть данные блока, содержащие HTML-код, который не подходит для COPE. Следовательно, мы должны удалить несемантические теги HTML для каждого блока, чтобы преобразовать его в независимый от среды формат.
Мы можем решить, какие атрибуты должны извлекаться для каждого типа блока (например, извлекать свойство выравнивания текста для блоков "paragraph" , свойство URL-адреса видео для блока "youtube embed" и т. д.) .
Как мы видели ранее, не все атрибуты на самом деле сохраняются как атрибуты блока, а во внутреннем содержимом блока, поэтому в этих ситуациях нам нужно будет проанализировать содержимое HTML с помощью регулярных выражений, чтобы извлечь эти фрагменты метаданных.
После проверки всех блоков, отправленных через ядро WordPress, я решил не извлекать метаданные для следующих блоков:
"core/columns""core/column""core/cover" | Они применимы только к носителям на основе экрана и (будучи вложенными блоками) с ними трудно иметь дело. |
"core/html" | Это имеет смысл только для сети. |
"core/table""core/button""core/media-text" | Я понятия не имел, как представить их данные в стиле, не зависящем от среды, и имеет ли это вообще смысл. |
Это оставляет мне следующие блоки, для которых я приступлю к извлечению их метаданных:
-
'core/paragraph' -
'core/image' -
'core-embed/youtube'(как представитель всех блоков'core-embed') -
'core/heading' -
'core/gallery' -
'core/list' -
'core/audio' -
'core/file' -
'core/video' -
'core/code' -
'core/preformatted' -
'core/quote'и'core/pullquote' -
'core/verse'
Чтобы извлечь метаданные, мы создаем функцию get_block_metadata($block_data) , которая получает массив с данными блока для каждого блока (т. е. вывод из нашей ранее реализованной функции get_block_data ) и, в зависимости от типа блока (предоставленного в свойстве "blockName" ), решает, какие атрибуты требуются и как их извлечь:
/** * Process all (Gutenberg) blocks' metadata into a medium-agnostic format from a WordPress post */ function get_block_metadata($block_data) { $ret = []; foreach ($block_data as $block) { $blockMeta = null; switch ($block['blockName']) { case ...: $blockMeta = ... break; case ...: $blockMeta = ... break; ... } if ($blockMeta) { $ret[] = [ 'blockName' => $block['blockName'], 'meta' => $blockMeta, ]; } } return $ret; }Давайте приступим к извлечению метаданных для каждого типа блока, один за другим:
“core/paragraph”
Просто удалите теги HTML из контента и удалите конечные линии разрыва.
case 'core/paragraph': $blockMeta = [ 'content' => trim(strip_html_tags($block['innerHTML'])), ]; break; 'core/image'
Блок либо имеет идентификатор, относящийся к загруженному медиафайлу, либо, если нет, источник изображения должен быть извлечен из-под <img src="..."> . Некоторые атрибуты (заголовок, linkDestination, ссылка, выравнивание) являются необязательными.
case 'core/image': $blockMeta = []; // If inserting the image from the Media Manager, it has an ID if ($block['attrs']['id'] && $img = wp_get_attachment_image_src($block['attrs']['id'], $block['attrs']['sizeSlug'])) { $blockMeta['img'] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } elseif ($src = extract_image_src($block['innerHTML'])) { $blockMeta['src'] = $src; } if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } if ($linkDestination = $block['attrs']['linkDestination']) { $blockMeta['linkDestination'] = $linkDestination; if ($link = extract_link($block['innerHTML'])) { $blockMeta['link'] = $link; } } if ($align = $block['attrs']['align']) { $blockMeta['align'] = $align; } break; Имеет смысл создать функции extract_image_src , extract_caption и extract_link , так как их регулярные выражения будут использоваться снова и снова для нескольких блоков. Обратите внимание, что заголовок в Гутенберге может содержать ссылки ( <a href="..."> ), однако при вызове strip_html_tags они удаляются из заголовка.
Несмотря на сожаление, я считаю эту практику неизбежной, поскольку мы не можем гарантировать, что ссылка будет работать на платформах, отличных от веб-сайтов. Следовательно, несмотря на то, что контент становится универсальным, поскольку его можно использовать для разных сред, он также теряет специфичность, поэтому его качество становится хуже по сравнению с контентом, созданным и адаптированным для конкретной платформы.
function extract_caption($innerHTML) { $matches = []; preg_match('/<figcaption>(.*?)<\/figcaption>/', $innerHTML, $matches); if ($caption = $matches[1]) { return strip_html_tags($caption); } return null; } function extract_link($innerHTML) { $matches = []; preg_match('/<a href="(.*?)">(.*?)<\/a>>', $innerHTML, $matches); if ($link = $matches[1]) { return $link; } return null; } function extract_image_src($innerHTML) { $matches = []; preg_match('/<img src="(.*?)"/', $innerHTML, $matches); if ($src = $matches[1]) { return $src; } return null; } 'core-embed/youtube'
Просто извлеките URL-адрес видео из атрибутов блока и извлеките его заголовок из содержимого HTML, если он существует.
case 'core-embed/youtube': $blockMeta = [ 'url' => $block['attrs']['url'], ]; if ($caption = extract_caption($block['innerHTML'])) { $blockMeta['caption'] = $caption; } break; 'core/heading'
Как размер заголовка (h1, h2, …, h6), так и текст заголовка не являются атрибутами, поэтому они должны быть получены из содержимого HTML. Обратите внимание, что вместо того, чтобы возвращать HTML-тег для заголовка, атрибут size является просто эквивалентным представлением, которое более независимо и лучше подходит для платформ, отличных от Интернета.
case 'core/heading': $matches = []; preg_match('/<h[1-6])>(.*?)<\/h([1-6])>/', $block['innerHTML'], $matches); $sizes = [ null, 'xxl', 'xl', 'l', 'm', 'sm', 'xs', ]; $blockMeta = [ 'size' => $sizes[$matches[1]], 'heading' => $matches[2], ]; break; 'core/gallery'
К сожалению, для галереи изображений мне не удалось извлечь подписи из каждого изображения, так как это не атрибуты, и извлечь их с помощью простого регулярного выражения может не получиться: Если для первого и третьего элементов есть подпись, а для второй, то я бы не знал, какой заголовок соответствует какому изображению (и я не тратил время на создание сложного регулярного выражения). Точно так же в приведенной ниже логике я всегда получаю "full" размер изображения, однако это не обязательно так, и я не знаю, как можно вывести более подходящий размер.
case 'core/gallery': $imgs = []; foreach ($block['attrs']['ids'] as $img_id) { $img = wp_get_attachment_image_src($img_id, 'full'); $imgs[] = [ 'src' => $img[0], 'width' => $img[1], 'height' => $img[2], ]; } $blockMeta = [ 'imgs' => $imgs, ]; break; 'core/list'
Просто преобразуйте элементы <li> в массив элементов.
case 'core/list': $matches = []; preg_match_all('/<li>(.*?)<\/li>/', $block['innerHTML'], $matches); if ($items = $matches[1]) { $blockMeta = [ 'items' => array_map('strip_html_tags', $items), ]; } break; 'core/audio'
Получите URL-адрес соответствующего загруженного медиафайла.
case 'core/audio': $blockMeta = [ 'src' => wp_get_attachment_url($block['attrs']['id']), ]; break; 'core/file'
Поскольку URL-адрес файла является атрибутом, его текст должен быть извлечен из внутреннего содержимого.
case 'core/file': $href = $block['attrs']['href']; $matches = []; preg_match('/<a href="'.str_replace('/', '\/', $href).'">(.*?)<\/a>/', $block['innerHTML'], $matches); $blockMeta = [ 'href' => $href, 'text' => strip_html_tags($matches[1]), ]; break; 'core/video'
Получите URL-адрес видео и все свойства, чтобы настроить воспроизведение видео с помощью регулярного выражения. Если Гутенберг когда-либо изменит порядок, в котором эти свойства печатаются в коде, то это регулярное выражение перестанет работать, что свидетельствует об одной из проблем, связанной с тем, что метаданные не добавляются напрямую через атрибуты блока.
case 'core/video': $matches = []; preg_match('/ 'core/code'
Simply extract the code from within <code /> .
case 'core/code': $matches = []; preg_match('/<code>(.*?)<\/code>/is', $block['innerHTML'], $matches); $blockMeta = [ 'code' => $matches[1], ]; break; 'core/preformatted'
Similar to <code /> , but we must watch out that Gutenberg hardcodes a class too.
case 'core/preformatted': $matches = []; preg_match('/<pre class="wp-block-preformatted">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break; 'core/quote' and 'core/pullquote'
We must convert all inner <p /> tags to their equivalent generic "\n" character.
case 'core/quote': case 'core/pullquote': $matches = []; $regexes = [ 'core/quote' => '/<blockquote class=\"wp-block-quote\">(.*?)<\/blockquote>/', 'core/pullquote' => '/<figure class=\"wp-block-pullquote\"><blockquote>(.*?)<\/blockquote><\/figure>/', ]; preg_match($regexes[$block['blockName']], $block['innerHTML'], $matches); if ($quoteHTML = $matches[1]) { preg_match_all('/<p>(.*?)<\/p>/', $quoteHTML, $matches); $blockMeta = [ 'quote' => strip_html_tags(implode('\n', $matches[1])), ]; preg_match('/<cite>(.*?)<\/cite>/', $quoteHTML, $matches); if ($cite = $matches[1]) { $blockMeta['cite'] = strip_html_tags($cite); } } break; 'core/verse'
Similar situation to <pre /> .
case 'core/verse': $matches = []; preg_match('/<pre class="wp-block-verse">(.*?)<\/pre>/is', $block['innerHTML'], $matches); $blockMeta = [ 'text' => strip_html_tags($matches[1]), ]; break;3. Exporting Data Through An API
Now that we have extracted all block metadata, we need to make it available to our different mediums, through an API. WordPress has access to the following APIs:
- REST, through the WP REST API (integrated in WordPress core)
- GraphQL, through WPGraphQL
- PoP, through its implementation for WordPress
Let's see how to export the data through each of them.
ОТДЫХ
The following code creates endpoint /wp-json/block-metadata/v1/metadata/{POST_ID} which exports all block metadata for a specific post:
/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }/** * Define REST endpoints to export the blocks' metadata for a specific post */ add_action('rest_api_init', function () { register_rest_route('block-metadata/v1', 'metadata/(?P \d+)', [ 'methods' => 'GET', 'callback' => 'get_post_block_meta' ]); }); function get_post_block_meta($request) { $post = get_post($request['post_id']); if (!$post) { return new WP_Error('empty_post', 'There is no post with this ID', array('status' => 404)); } $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); $response = new WP_REST_Response($block_metadata); $response->set_status(200); return $response; }
To see it working, this link (corresponding to this blog post) displays the metadata for blocks of all the types analyzed earlier on.
GraphQL (Through WPGraphQL)
GraphQL works by setting-up schemas and types which define the structure of the content, from which arises this API's power to fetch exactly the required data and nothing else. Setting-up schemas works very well when the structure of the object has a unique representation.
In our case, however, the metadata returned by a new field "block_metadata" (which calls our newly-created function get_block_metadata ) depends on the specific block type, so the structure of the response can vary wildly; GraphQL provides a solution to this issue through a Union type, allowing to return one among a set of different types. However, its implementation for all different variations of the metadata structure has proved to be a lot of work, and I quit along the way .
As an alternative (not ideal) solution, I decided to provide the response by simply encoding the JSON object through a new field "jsonencoded_block_metadata" :
/** * Define WPGraphQL field "jsonencoded_block_metadata" */ add_action('graphql_register_types', function() { register_graphql_field( 'Post', 'jsonencoded_block_metadata', [ 'type' => 'String', 'description' => __('Post blocks encoded as JSON', 'wp-graphql'), 'resolve' => function($post) { $post = get_post($post->ID); $block_data = get_block_data($post->post_content); $block_metadata = get_block_metadata($block_data); return json_encode($block_metadata); } ] ); });PoP
Note: This functionality is available on its own GitHub repo.
The final API is called PoP, which is a little-known project I've been working on for several years now. I have recently converted it into a full-fledged API, with the capacity to produce a response compatible with both REST and GraphQL, and which even benefits from the advantages from these 2 APIs, at the same time: no under/over-fetching of data, like in GraphQL, while being cacheable on the server-side and not susceptible to DoS attacks, like REST. It offers a mix between the two of them: REST-like endpoints with GraphQL-like queries.
The block metadata is made available through the API through the following code:
class PostFieldValueResolver extends AbstractDBDataFieldValueResolver { public static function getClassesToAttachTo(): array { return array(\PoP\Posts\FieldResolver::class); } public function resolveValue(FieldResolverInterface $fieldResolver, $resultItem, string $fieldName, array $fieldArgs = []) { $post = $resultItem; switch ($fieldName) { case 'block-metadata': $block_data = \Leoloso\BlockMetadata\Data::get_block_data($post->post_content); $block_metadata = \Leoloso\BlockMetadata\Metadata::get_block_metadata($block_data); // Filter by blockName if ($blockName = $fieldArgs['blockname']) { $block_metadata = array_filter( $block_metadata, function($block) use($blockName) { return $block['blockName'] == $blockName; } ); } return $block_metadata; } return parent::resolveValue($fieldResolver, $resultItem, $fieldName, $fieldArgs); } }To see it in action, this link displays the block metadata (+ ID, title and URL of the post, and the ID and name of its author, a la GraphQL) for a list of posts.
Кроме того, аналогично аргументам GraphQL, наш запрос можно настраивать с помощью аргументов поля, что позволяет получать только те данные, которые имеют смысл для конкретной платформы. Например, если мы хотим извлечь все видео Youtube, добавленные ко всем сообщениям, мы можем добавить модификатор (blockname:core-embed/youtube) в поле block-metadata в URL-адресе конечной точки, как в этой ссылке. Или, если мы хотим извлечь все изображения из определенного поста, мы можем добавить модификатор (blockname:core/image) , как в этой другой ссылке|идентификатор|заголовок).
Заключение
Стратегия COPE («Создать один раз, опубликовать везде») помогает нам сократить объем работы, необходимой для создания нескольких приложений, которые должны работать в разных средах (Интернет, электронная почта, приложения, домашние помощники, виртуальная реальность и т. д.), создавая единый источник. истины для нашего содержания. Что касается WordPress, несмотря на то, что он всегда блистал как система управления контентом, реализация стратегии COPE исторически оказалась сложной задачей.
Тем не менее, несколько недавних разработок сделали реализацию этой стратегии для WordPress более осуществимой. С одной стороны, с момента интеграции в ядро WP REST API и, что более важно, с момента запуска Gutenberg, большая часть контента WordPress доступна через API, что делает его настоящей безголовой системой. С другой стороны, Gutenberg (который является новым редактором контента по умолчанию) основан на блоках, что делает все метаданные внутри сообщения в блоге легкодоступными для API.
Как следствие, реализовать COPE для WordPress несложно. В этой статье мы увидели, как это сделать, и весь соответствующий код был доступен в нескольких репозиториях. Несмотря на то, что это решение не является оптимальным (поскольку оно включает в себя большое количество операций синтаксического анализа HTML-кода), оно по-прежнему работает довольно хорошо, в результате чего усилия, необходимые для выпуска наших приложений для нескольких платформ, могут быть значительно уменьшены. Слава этому!