
Создание рабочего процесса непрерывного интеграционного тестирования с использованием действий GitHub
Опубликовано: 2022-03-10При участии в проектах на платформах управления версиями, таких как GitHub и Bitbucket, принято, что существует основная ветвь, содержащая функциональную кодовую базу. Затем есть другие ветки, в которых несколько разработчиков могут работать над копиями основного, чтобы добавить новую функцию, исправить ошибку и так далее. Это имеет большой смысл, потому что становится легче отслеживать, какое влияние входящие изменения окажут на существующий код. Если есть какая-то ошибка, ее можно легко отследить и исправить, прежде чем интегрировать изменения в основную ветку. Просмотр каждой строки кода вручную в поисках ошибок или багов может занять много времени — даже для небольшого проекта. Вот где начинается непрерывная интеграция.
Что такое непрерывная интеграция (CI)?
«Непрерывная интеграция (CI) — это практика автоматизации интеграции изменений кода от нескольких участников в один программный проект».
— Atlassian.com
Общая идея непрерывной интеграции (CI) состоит в том, чтобы гарантировать, что изменения, внесенные в проект, не «сломают сборку», то есть не разрушат существующую кодовую базу. Реализация непрерывной интеграции в вашем проекте, в зависимости от того, как вы настроили свой рабочий процесс, будет создавать сборку всякий раз, когда кто-либо вносит изменения в репозиторий.
Итак, что такое сборка?
Сборка — в данном контексте — это компиляция исходного кода в исполняемый формат. Если это успешно, это означает, что входящие изменения не окажут негативного влияния на кодовую базу, и их можно использовать. Однако, если сборка завершится ошибкой, изменения придется переоценить. Вот почему рекомендуется вносить изменения в проект, работая над копией проекта в другой ветке, прежде чем включать его в основную кодовую базу. Таким образом, если сборка сломается, будет проще понять, откуда берется ошибка, и это также не повлияет на ваш основной исходный код.
«Чем раньше вы обнаружите дефекты, тем дешевле их исправить».
— Дэвид Фарли, «Непрерывная поставка: надежные выпуски программного обеспечения посредством автоматизации сборки, тестирования и развертывания».
Существует несколько доступных инструментов, которые помогут создать непрерывную интеграцию для вашего проекта. К ним относятся Jenkins, TravisCI, CircleCI, GitLab CI, GitHub Actions и т. д. В этом руководстве я буду использовать GitHub Actions.
Действия GitHub для непрерывной интеграции
CI Actions — это довольно новая функция на GitHub, которая позволяет создавать рабочие процессы, которые автоматически запускают сборку и тесты вашего проекта. Рабочий процесс содержит одно или несколько заданий, которые можно активировать при возникновении события. Это событие может быть отправкой в любую из веток репозитория или созданием запроса на вытягивание. Я объясню эти термины подробно, как мы продолжим.
Давайте начнем!
Предпосылки
Это руководство для начинающих, поэтому я в основном буду говорить о GitHub Actions CI на поверхностном уровне. Читатели уже должны быть знакомы с созданием Node JS REST API с использованием базы данных PostgreSQL, Sequelize ORM и написанием тестов с помощью Mocha и Chai.
Также на вашем компьютере должно быть установлено следующее:
- узелJS,
- постгрескл,
- НПМ,
- VSCode (или любой редактор и терминал по вашему выбору).
Я буду использовать REST API, который я уже создал, под названием countries-info-api . Это простой API без авторизации на основе ролей (как на момент написания этого руководства). Это означает, что любой может добавлять, удалять и/или обновлять данные о стране. Каждая страна будет иметь идентификатор (автоматически сгенерированный UUID), название, столицу и население. Для этого я использовал Node js, фреймворк Express JS и Postgresql для базы данных.
Я кратко объясню, как я настроил сервер, базу данных, прежде чем я начну писать тесты для тестового покрытия и файл рабочего процесса для непрерывной интеграции.
Вы можете клонировать репозиторий countrys countries-info-api , чтобы следовать ему, или создать свой собственный API.
Используемые технологии : Node Js, NPM (менеджер пакетов для Javascript), база данных Postgresql, sequenceize ORM, Babel.
Настройка сервера
Перед настройкой сервера я установил некоторые зависимости от npm.
npm install express dotenv cors npm install --save-dev @babel/core @babel/cli @babel/preset-env nodemonЯ использую экспресс-фреймворк и пишу в формате ES6, поэтому для компиляции кода мне понадобится Babeljs. Вы можете прочитать официальную документацию, чтобы узнать больше о том, как это работает и как настроить его для вашего проекта. Nodemon обнаружит любые изменения, внесенные в код, и автоматически перезапустит сервер.
Примечание . Пакеты Npm, установленные с использованием --save-dev , требуются только на этапах разработки и отображаются в разделе devDependencies в файле package.json .
Я добавил в свой файл index.js :
import express from "express"; import bodyParser from "body-parser"; import cors from "cors"; import "dotenv/config"; const app = express(); const port = process.env.PORT; app.use(bodyParser.json()); app.use(bodyParser.urlencoded({ extended: true })); app.use(cors()); app.get("/", (req, res) => { res.send({message: "Welcome to the homepage!"}) }) app.listen(port, () => { console.log(`Server is running on ${port}...`) }) Это настраивает наш API для работы с тем, что назначено переменной PORT в файле .env . Здесь мы также будем объявлять переменные, к которым мы не хотим, чтобы другие имели легкий доступ. Пакет dotenv npm загружает переменные среды из .env .
Теперь, когда я запускаю npm run start в своем терминале, я получаю следующее:
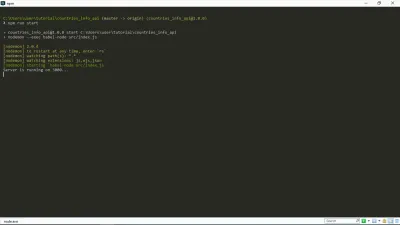
Как видите, наш сервер запущен и работает. Ура!
Эта ссылка https://127.0.0.1:your_port_number/ в вашем веб-браузере должна возвращать приветственное сообщение. То есть, пока сервер работает.
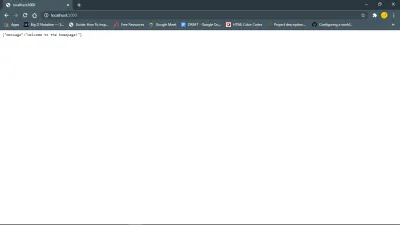
Далее, база данных и модели.
Я создал модель страны с помощью Sequelize и подключился к своей базе данных Postgres. Sequelize — это ORM для Nodejs. Основное преимущество заключается в том, что это экономит время на написание необработанных SQL-запросов.
Поскольку мы используем Postgresql, базу данных можно создать через командную строку psql с помощью команды CREATE DATABASE database_name . Это также можно сделать на вашем терминале, но я предпочитаю PSQL Shell.
В файле env мы настроим строку подключения к нашей базе данных в следующем формате.
TEST_DATABASE_URL = postgres://<db_username>:<db_password>@127.0.0.1:5432/<database_name>Для моей модели я следовал этому руководству по продолжению. За ним легко следить, и он объясняет все о настройке Sequelize.
Далее напишу тесты для только что созданной модели и настрою покрытие на Coverall.
Написание тестов и отчетность о покрытии
Зачем писать тесты? Лично я считаю, что написание тестов поможет вам как разработчику лучше понять, как ваше программное обеспечение будет работать в руках вашего пользователя, потому что это процесс мозгового штурма. Это также помогает вовремя обнаруживать ошибки.
Тесты:
Однако существуют разные методы тестирования программного обеспечения. В этом руководстве я использовал модульное и сквозное тестирование.
Я написал свои тесты, используя тестовую среду Mocha и библиотеку утверждений Chai. Я также установил sequelize-test-helpers чтобы помочь протестировать модель, которую я создал с помощью sequelize.define .
Тестовое покрытие:
Рекомендуется проверить покрытие тестами, потому что результат показывает, действительно ли наши тестовые примеры покрывают код, а также сколько кода используется при выполнении наших тестовых случаев.

Я использовал Istanbul (инструмент для проведения тестов), nyc (клиент интерфейса командной строки Instabul) и Coveralls.
Согласно документам, Istanbul оснащает ваш код JavaScript ES5 и ES2015+ счетчиками строк, чтобы вы могли отслеживать, насколько хорошо ваши модульные тесты работают с кодовой базой.
В моем файле package.json тестовый скрипт запускает тесты и создает отчет.
{ "scripts": { "test": "nyc --reporter=lcov --reporter=text mocha -r @babel/register ./src/test/index.js" } } В процессе будет создана папка .nyc_output , содержащая необработанную информацию о coverage , и папка о покрытии, содержащая файлы отчета о покрытии. Оба файла не нужны в моем репо, поэтому я поместил их в файл .gitignore .
Теперь, когда мы создали отчет, мы должны отправить его в Coveralls. Одна интересная вещь в комбинезонах (и, я полагаю, в других инструментах покрытия) заключается в том, как они сообщают о вашем тестовом покрытии. Покрытие разбито по файлам, и вы можете увидеть соответствующее покрытие, закрытые и пропущенные строки, а также изменения в покрытии сборки.
Для начала установите пакет npm для комбинезонов. Вам также необходимо войти в комбинезон и добавить в него репозиторий.
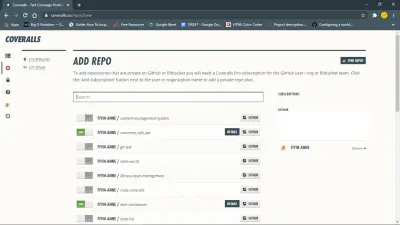
Затем настройте комбинезоны для своего проекта javascript, создав файл coveralls.yml в корневом каталоге. В этом файле будет храниться ваш repo-token полученный из раздела настроек вашего репо на комбинезоне.
Еще один сценарий, необходимый в файле package.json, — это сценарии покрытия. Этот скрипт пригодится, когда мы будем создавать сборку через Actions.
{ "scripts": { "coverage": "nyc npm run test && nyc report --reporter=text-lcov --reporter=lcov | node ./node_modules/coveralls/bin/coveralls.js --verbose" } }По сути, он проведет тесты, получит отчет и отправит его в комбинезон для анализа.
Теперь к главному пункту этого урока.
Создать файл рабочего процесса Node JS
На данный момент мы настроили необходимые задания, которые будем запускать в нашем действии GitHub. (Интересно, что означает «работа»? Продолжайте читать.)
GitHub упростил создание файла рабочего процесса, предоставив начальный шаблон. Как видно на странице «Действия», существует несколько шаблонов рабочих процессов, предназначенных для разных целей. В этом руководстве мы будем использовать рабочий процесс Node.js (который уже любезно предложил GitHub).
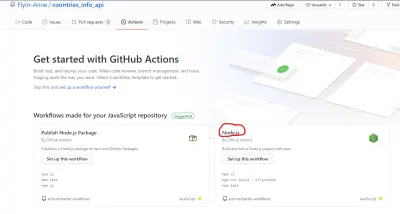
Вы можете редактировать файл прямо на GitHub, но я создам файл вручную в своем локальном репозитории. Папка .github/workflows , содержащая файл node.js.yml , будет находиться в корневом каталоге.
Этот файл уже содержит некоторые основные команды, и первый комментарий объясняет, что они делают.
# This workflow will do a clean install of node dependencies, build the source code and run tests across different versions of nodeЯ внесу в него некоторые изменения, чтобы в дополнение к приведенному выше комментарию он также запускал покрытие.
Мой файл .node.js.yml :
name: NodeJS CI on: ["push"] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run coverage - name: Coveralls uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} COVERALLS_GIT_BRANCH: ${{ github.ref }} with: github-token: ${{ secrets.GITHUB_TOKEN }}Что это значит?
Давайте сломаем это.
-
name
Это будет имя вашего рабочего процесса (NodeJS CI) или задания (сборка), и GitHub отобразит его на странице действий вашего репозитория. -
on
Это событие запускает рабочий процесс. Эта строка в моем файле в основном говорит GitHub запускать рабочий процесс всякий раз, когда в моем репозитории делается толчок. -
jobs
Рабочий процесс может содержать как минимум одно или несколько заданий, и каждое задание выполняется в среде, указанной параметромruns-on. В приведенном выше примере файла есть только одно задание, которое запускает сборку, а также выполняет покрытие, и оно выполняется в среде Windows. Я также могу разделить его на две разные задачи, например:
Обновлен файл Node.yml.
name: NodeJS CI on: [push] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run test coverage: name: Coveralls runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} with: github-token: ${{ secrets.GITHUB_TOKEN }}-
env
Он содержит переменные среды, доступные для всех или определенных заданий и шагов рабочего процесса. В задании покрытия вы можете видеть, что переменные среды были «скрыты». Их можно найти на странице секретов вашего репо в настройках. -
steps
По сути, это список шагов, которые необходимо предпринять при выполнении этого задания. - Задание
buildвыполняет ряд действий:- Он использует действие извлечения (v2 означает версию), которое буквально извлекает ваш репозиторий, чтобы он был доступен вашему рабочему процессу;
- Он использует действие setup-node, которое настраивает используемую среду узла;
- Он запускает сценарии установки, сборки и тестирования, найденные в нашем файле package.json.
-
coverage
При этом используется действие coverallsapp, которое отправляет данные о покрытии LCOV вашего набора тестов на coveralls.io для анализа.
Сначала я сделал толчок в свою ветку feat-add-controllers-and-route и забыл добавить repo_token из Coveralls в мой файл .coveralls.yml , поэтому я получил ошибку, которую вы можете увидеть в строке 132.
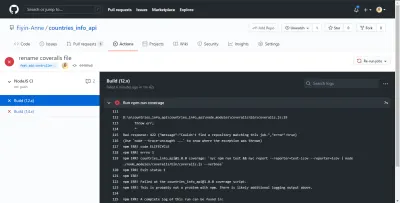
Bad response: 422 {"message":"Couldn't find a repository matching this job.","error":true} Как только я добавил repo_token , моя сборка смогла успешно запуститься. Без этого токена комбинезоны не смогли бы должным образом сообщить об анализе покрытия тестами. Хорошо, что наш GitHub Actions CI указал на ошибку до того, как она попала в основную ветку.
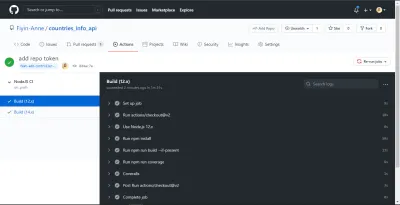
NB: Они были сделаны до того, как я разделил работу на две части. Кроме того, я смог увидеть сводку покрытия и сообщение об ошибке на своем терминале, потому что я добавил флаг --verbose в конце своего сценария покрытия.
Заключение
Мы можем увидеть, как настроить непрерывную интеграцию для наших проектов, а также интегрировать тестовое покрытие с помощью действий, доступных на GitHub. Есть так много других способов, которыми это можно настроить в соответствии с потребностями вашего проекта. Хотя образец репозитория, использованный в этом руководстве, является очень небольшим проектом, вы можете видеть, насколько важна непрерывная интеграция даже в более крупном проекте. Теперь, когда мои задания выполнены успешно, я уверен, что объединяю ветку с моей основной веткой. Я бы все же посоветовал вам также читать результаты шагов после каждого запуска, чтобы убедиться, что он полностью успешен.